前言
大家好,我是程式員manor,我希望自己能成為國家復興道路的鋪路人,大資料領域的耕耘者,平凡但不甘于平庸的人,
事情是這樣的
我在實習僧App上發現一家公司非常匹配我的需求~

城市匹配
技能匹配
福利匹配
還是一家游戲公司
(典型的錢多離家近,事估計少不了了 )
三配下來我不得不認真研究該公司的職位要求:

一番自我檢查發現,竟然有一項大資料組件聽都沒聽過:presto
這到底是個啥?
有什么用?
適合在哪些業務場景?
如此靈魂三問后,好學如本碼農自當好好研究一番,

Presto是什么
1. Presto簡介
- 1 Presto概念
Presto 是由 Facebook 開源的大資料分布式 SQL 查詢引擎,適用于互動式分析查詢,可支持眾多的資料源,包括 HDFS,RDBMS,KAFKA 等,而且提供了非常友好的介面開發資料源連接器,資料規模可以支持GB到PB級,主要應用于處理秒級查詢的場景,Presto 的設計和撰寫完全是為了解決像 Facebook 這樣規模的商業資料倉庫的互動式分析和處理速度的問題,
注意: 雖然 Presto 可以決議 SQL,但它不是一個標準的資料庫,不是 MySQL、Oracle的代替品,也不能用來處理在線事務(
OLTP),
1.2 Presto 應用場景
Presto 支持在線資料查詢,包括 Hive,關系資料庫(MySQL、Oracle)以及專有資料存盤,一條 Presto 查詢可以將多個資料源的資料進行合并,可以跨越整個組織進行分析,
Presto 主要用來處理 回應時間小于 1 秒到幾分鐘的場景 ,
1.3 Presto架構
在談presto架構之前,先回顧下hive的架構
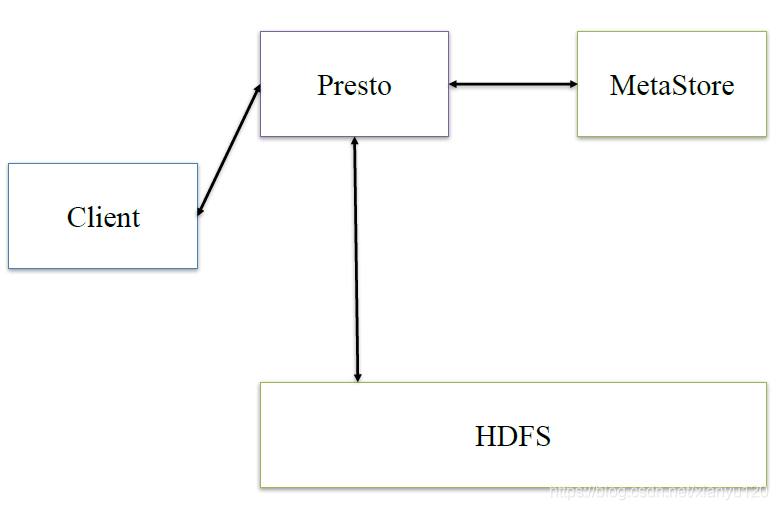
hive:client將查詢請求發送到hive server,它會和metastor互動,獲取表的元資訊,如表的位置結構等,之后hive server會進行語法決議,決議成語法樹,變成查詢計劃,進行優化后,將查詢計劃交給執行引擎,默認是MR,然后翻譯成MR
presto:presto是在它內部做hive類似的邏輯
接下來,深入看下presto的內部架構
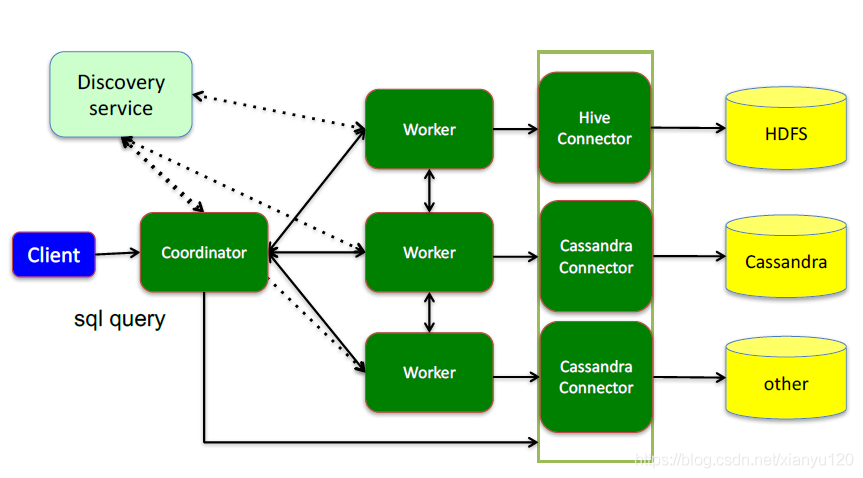
這里面三個服務:
Coordinator,是一個中心的查詢角色,它主要的一個作用是接受查詢請求,將他們轉換成各種各樣的任務,將任務拆解后分發到多個worker去執行各種任務的節點
1、決議SQL陳述句
2、?成執?計劃
3、分發執?任務給Worker節點執?
Worker,是一個真正的計算的節點,執行任務的節點,它接收到task后,就會到對應的資料源里面,去把資料提取出來,提取方式是通過各種各樣的Connector:
負責實際執?查詢任務
Discovery service,是將coordinator和woker結合到一起的服務:
1、Worker節點啟動后向Discovery Server服務注冊
2、Coordinator從Discovery Server獲得Worker節點
coordinator和woker之間的關系是怎么維護的呢?是通過Discovery Server,所有的worker都把自己注冊到Discovery Server上,Discovery Server是一個發現服務的service,Discovery Server發現服務之后,coordinator便知道在我的集群中有多少個worker能夠給我作業,然后我分配作業到worker時便有了根據
最后,presto是通過connector plugin獲取資料和元資訊的,它不是?個資料存盤引擎,不需要有資料,presto為其他資料存盤系統提供了SQL能?,客戶端協議是HTTP+JSON
1.3 Presto與大資料OLAP引擎對比
-
Presto:記憶體計算,mpp架構
-
Druid:時序,資料放記憶體,索引,預計算
-
Spark SQL:基于Spark Core,mpp架構
-
Kylin:Cube預計算
(mpp架構即大規模并行處理結構)
Presto由于是基于記憶體的,而Hive是在磁盤上讀寫的,因此Presto比Hive快很多,但是由于是基于記憶體的計算當多張大表關聯操作時易引起記憶體溢位錯誤,
1.4 Presto特點
(1)完全基于記憶體的并行計算
(2)流水線
(3)本地化計算
(4)動態編譯執行計劃
(5)小心使用記憶體和資料結構
(6)類BlinkDB的近似查詢
(7)GC控制
(8)擴展性
擴展性是在設計Presto時的另一個要點,
Presto不僅可以訪問HDFS,也可以操作不同的資料源,包括:RDBMS和其他的資料源(例如:Cassandra),目前已經 被支持的RDBMS有:MySQL、SQLServer、PostgreSQL等,
1.5 官網變化
就在 2020 年 12 月 27 日,prestosql 與 facebook 正式分裂,并改名為trino,分裂之前和之后的官網分別是:https://prestosql.io/ 和 https://trino.io,
參考文章:
https://blog.csdn.net/weixin_44318830/article/details/114339496
這篇文章全面的介紹了Presto從介紹到跑起第一行代碼,從Presto的簡介,安裝部署,命令列 Client 的安裝,基本使用,可視化客戶端的安裝與基本使用,以及使用任何一個組件我們都很注重的優化都講的非常清楚了,珠玉在前,我也就不重復造輪子了,
需要做一點補充的是,我在油管爬了官方的Presto的介紹視頻
并上傳了雙語機翻字幕
感興趣的,可以到B站看一看~

Presto簡要介紹及Presto上運行SQL
小結
本篇內容為大家介紹的是關于Presto到底是個什么東西,希望大家看完之后能夠有所識訓!你知道的越多,你不知道的也越多,我是manor,我們下一期見!

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/291427.html
標籤:其他
下一篇:大資料入門-大資料技術概述(一)