目錄
大資料入門系列文章
1.大資料入門-大資料是什么
一、概念
二、技術詳解
1.基礎架構:Hadoop
2.分布式檔案系統:HDFS
3.資料倉庫:Hive
4.存盤引擎:Kudu
5.分布式資料庫:HBase
6.實時框架:Flink
三、其他
大資料入門系列文章
1.大資料入門-大資料是什么
大資料入門系列文章
你知道什么是大資料嗎,請走傳送門,
1.大資料入門-大資料是什么
1.大資料入門-大資料是什么
一、概念
大資料技術是指在構架大資料平臺的時候需要的技術,包含存盤系統,資料庫,資料倉庫,資源調度,查詢引擎,實時框架等,下面以我目前所了解到的一些技術做簡要介紹,目前之介紹簡單概念,
二、技術詳解
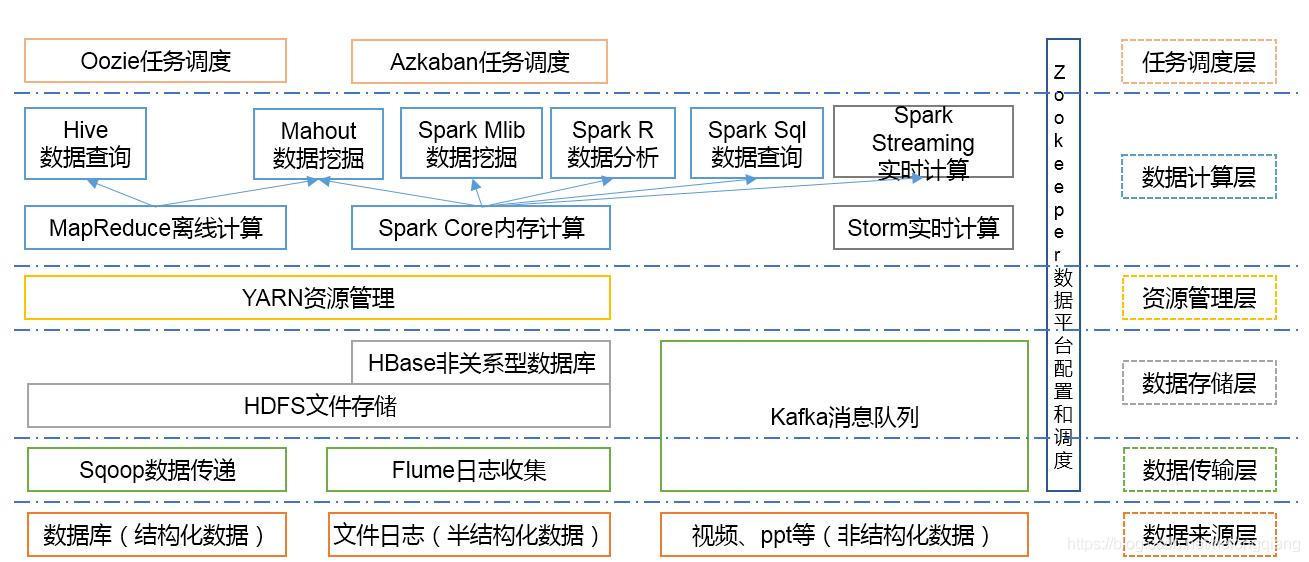
1.基礎架構:Hadoop
1.架構
2.簡介
Hadoop是一個由Apache基金會所開發的分布式系統基礎架構,用戶可以在不了解分布式底層細節的情況下,開發分布式程式,充分利用集群的威力進行高速運算和存盤,
2.分布式檔案系統:HDFS
1.HDFS架構
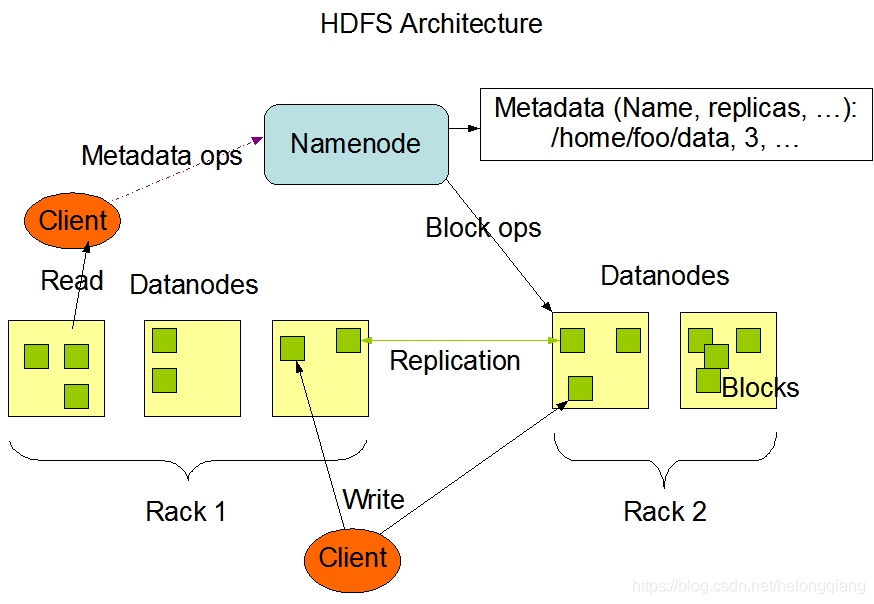
2.簡介
指被設計成適合運行在通用硬體上的分布式檔案系統,
3.特點
HDFS有著高容錯性的特點,并且設計用來部署在低廉的硬體上,而且它提供高吞吐量來訪問應用程式的資料,適合那些有著超大資料集的應用程式,
3.資料倉庫:Hive
1.架構
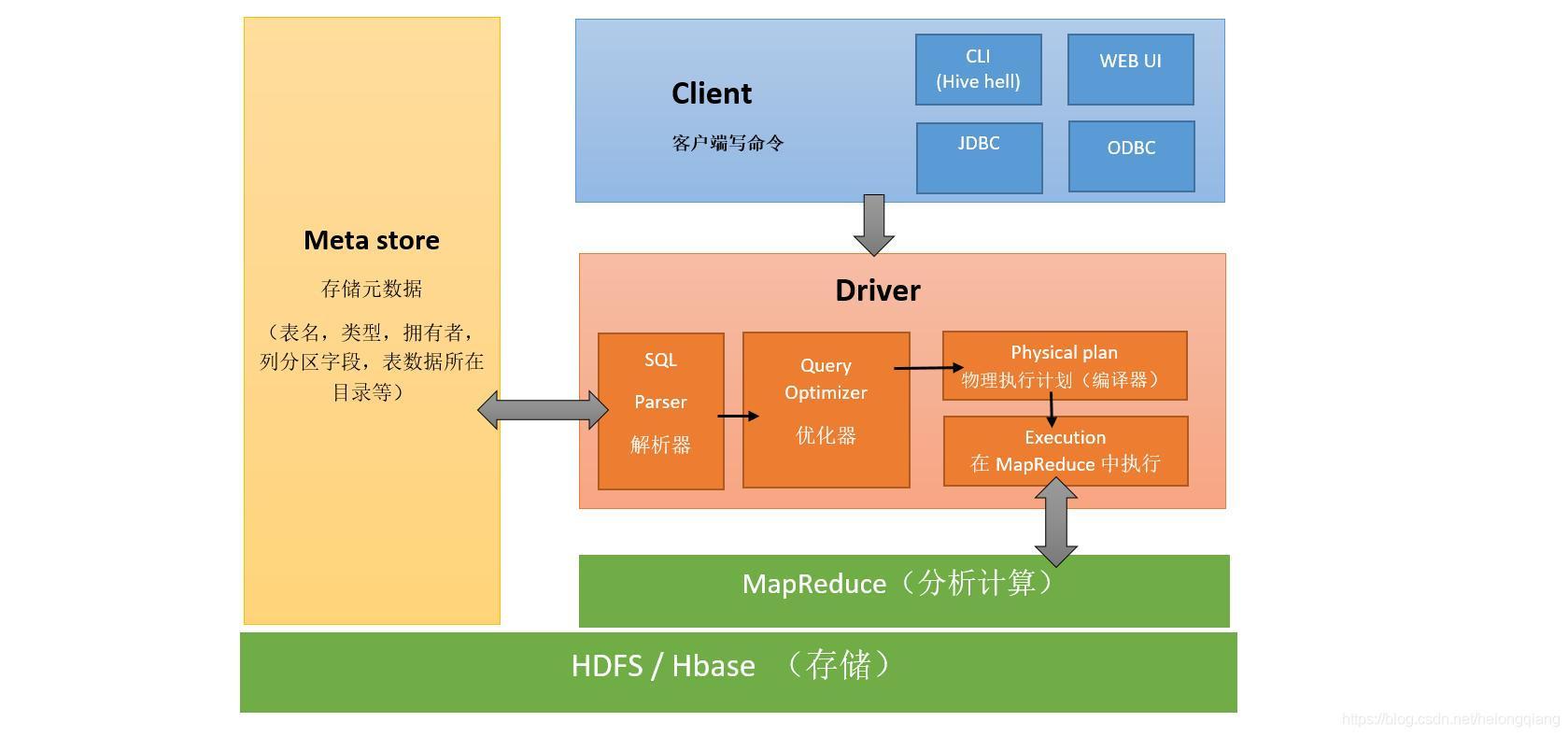
2.簡介
Hive是基于Hadoop的一個資料倉庫工具,用來進行資料提取、轉化、加載,這是一種可以存盤、查詢和分析存盤在Hadoop中的大規模資料的機制,
3.特點
執行程序走MapReduce比較慢,處理規模大,可擴展性高,加載模式為讀時模式,后面就MapReduce會做專門的解釋,
4.存盤引擎:Kudu
1.架構
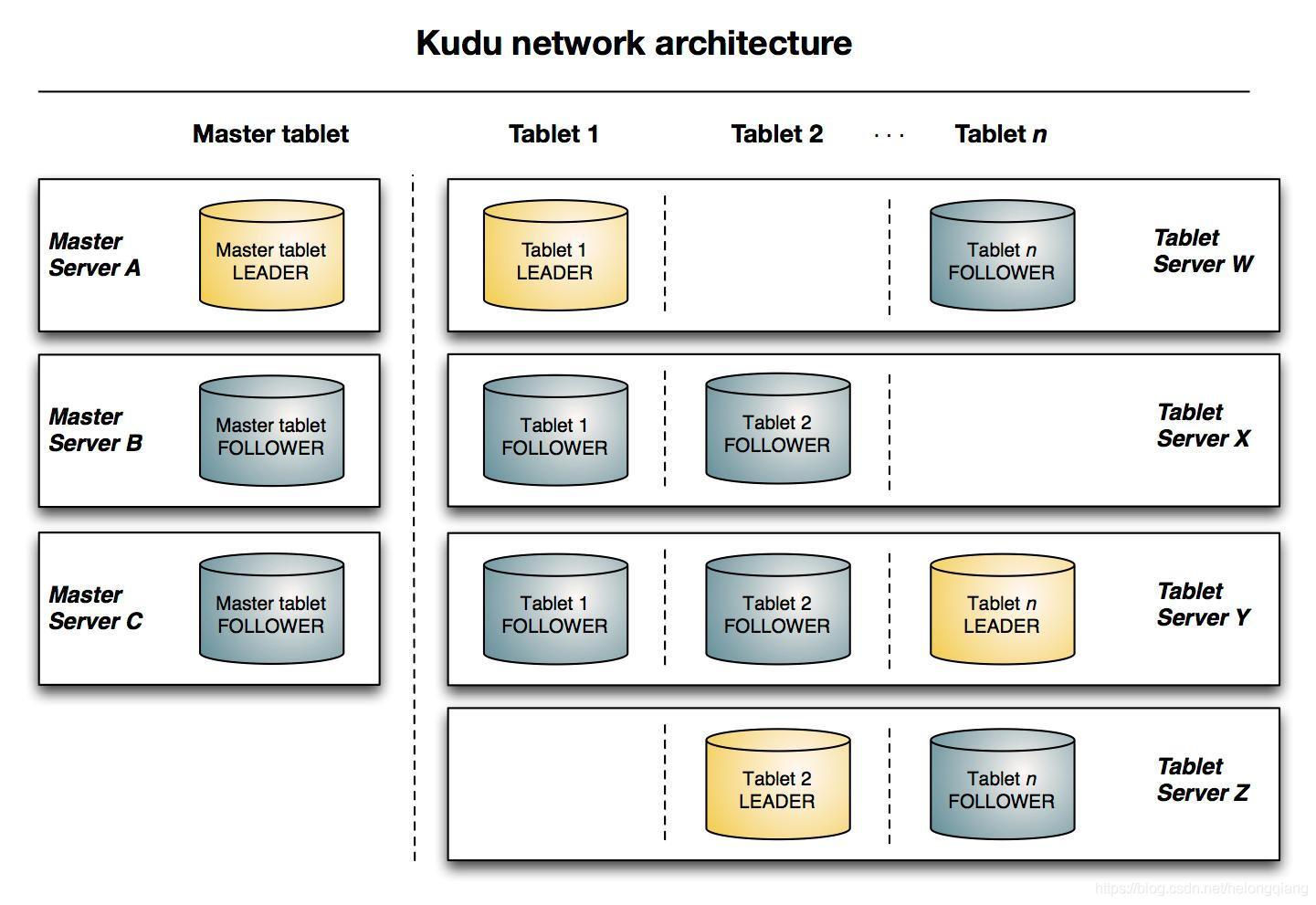
2.簡介
Apache Kudu是由Cloudera開源的存盤引擎,可以同時提供低延遲的隨機讀寫和高效的資料分析能力,Kudu支持水平擴展,使用Raft協議進行一致性保證,并且與Cloudera Impala和Apache Spark等當前流行的大資料查詢和分析工具結合緊密,
3.特點
支持隨機讀寫,支持OLAP 分析,太多列查詢時性能下降,跟關系型資料有點類似,其存盤檔案不在HDFS上面,有自己的存盤檔案系統,
5.分布式資料庫:HBase
1.架構
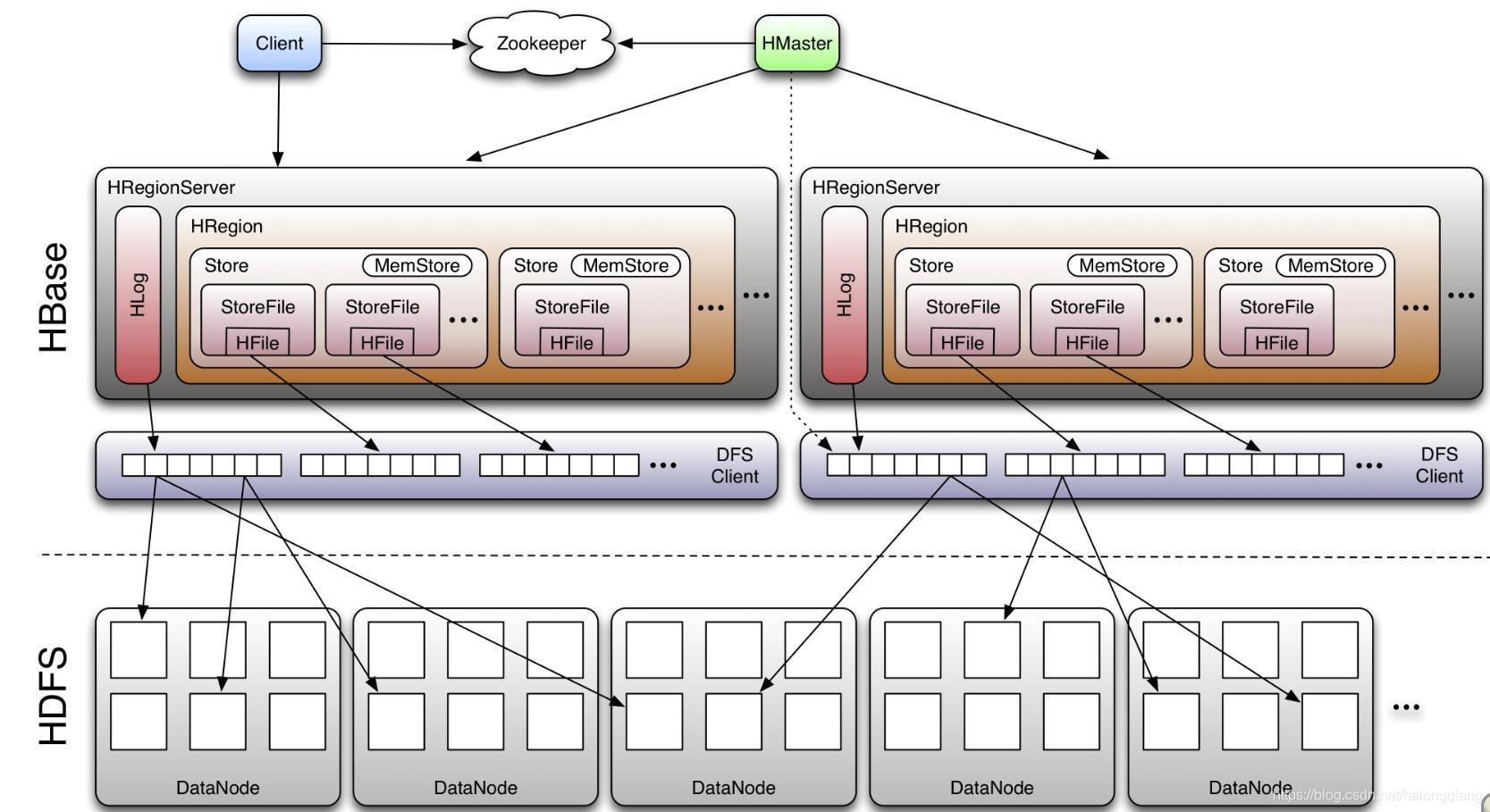
2.簡介
HBase是一個開源的非關系型分布式資料庫,它參考了谷歌的BigTable建模,實作的編程語言為Java,它是Apache軟體基金會的Hadoop專案的一部分,運行于HDFS檔案系統之上,為 Hadoop 提供類似于BigTable 規模的服務,因此,它可以容錯地存盤海量稀疏的資料,
3.特點
高可靠、高性能、面向列、可伸縮,
6.實時框架:Flink
1.架構
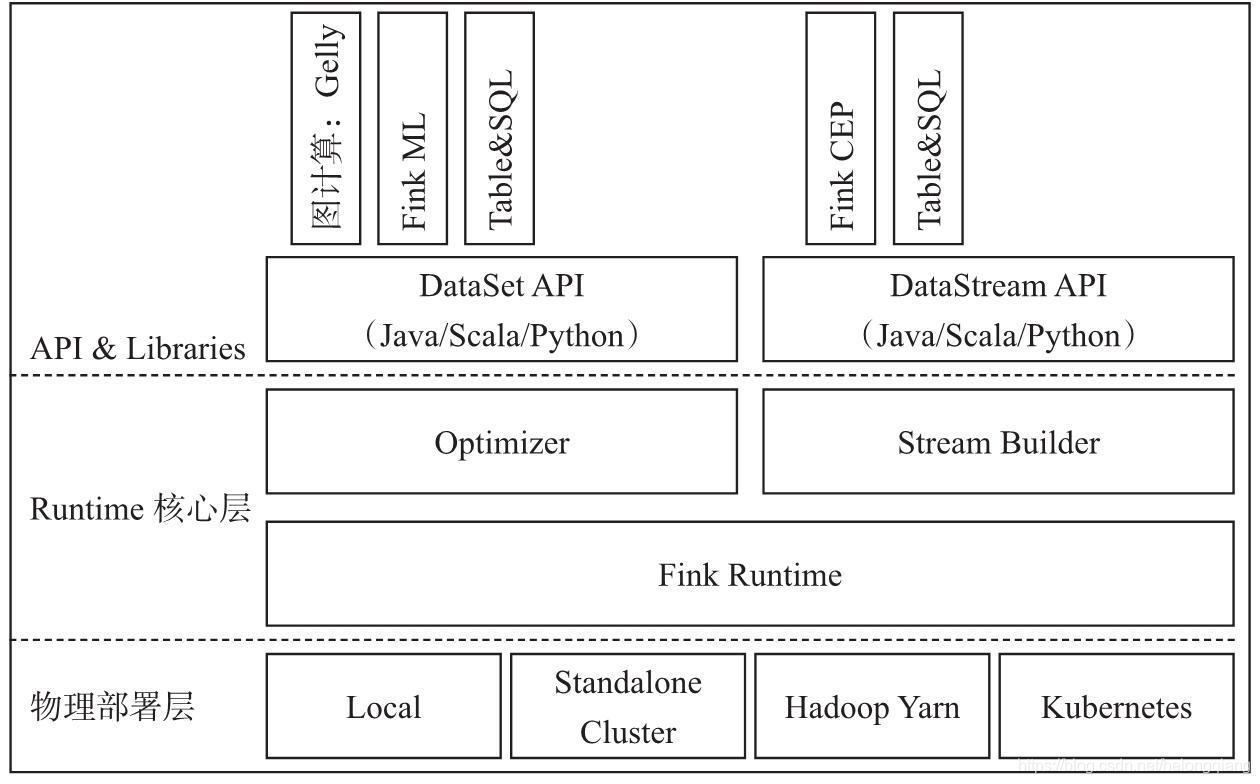
2.簡介
Apache Flink是一個框架和分布式處理引擎,用于對無界和有界資料流進行有狀態計算,Flink設計為在所有常見的集群環境中運行,以記憶體速度和任何規模執行計算,
3.特點
流處理特性、API支持、Libraries支持、整合支持,
三、其他
以上就是我目前涉及到的部分技術,下一篇出Zookpeer、Yarn、Spark、Impala、Kafka、Flume,
大資料入門系列文章
你知道什么是大資料嗎,請走傳送門,
1.大資料入門-大資料是什么
1.大資料入門-大資料是什么
如果你覺得這篇文章對您有幫助,請關注點贊加收藏,想要了解更多請關注公眾號聯系博主,祝您生活愉快,身心健康!
備注:以上資源來自網路,侵刪,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/291428.html
標籤:其他