? 本文主要討論一下為什么卷積加速更加喜歡 NHWC 的資料排布,
? 我目前接觸過的資料排布型別(主要針對卷積)有 NCHW (pytorch、caffe),NHWC (Tensorflow,也是 TVM GPU 和 寒武紀 MLU Core 上更喜歡的 data Layout), CHW (TensorRT里不考慮動態batch的話是把 N 拿出來了,只剩三維),NCHWC0 (華為昇騰 AI Core 的五維 Layout,C0 INT8時為32,FP16時為16),為什么會有這么多資料型別排布呢,原因可能是源于不同的訓練框架,比如 pytorch 和 tensorflow (大部分人的煉丹爐) 就不一樣,而在推理時,更多的會考慮硬體 / 推理性能更喜歡什么樣的資料型別排布,
? 這里主要談談對于 img2col+gemm 和 winograd 卷積加速演算法來說,為什么 NHWC 比 NCHW 更合適 (GPU上),也是我個人的理解,
文章目錄
- 1、img2col+gemm 和 winograd 演算法原理
- 2、為什么 NHWC 更好
1、img2col+gemm 和 winograd 演算法原理
? img2col+gemm 的詳細原理可以看我的這篇《【模型推理】一文看懂Img2Col卷積加速演算法》,就是先把 feature map 按卷積核走過的 “蹤跡” 展開、拼接 與 拉扁拉長的卷積核 進行 gemm 就好了,winograd 應該是比較常用的,Cudnn 里也會用到,這里大致說一下,后面會寫篇詳細的,winograd 做 conv_2d_3x3 加速的本質是降低乘加計算次數 (主要是乘),最開始還是會做 img2col,然后進行計算切塊、轉換及卷積核常量先計算,最終達到降低乘加次數的目的,也就是能加速,
2、為什么 NHWC 更好
? 我的觀點是 NHWC 相比 NCHW 優化了 feature map 資料取的程序,因為不管 img2col+gemm 還是 winograd,最開始就是把 feature map 和 kernel 展開,類似這樣:
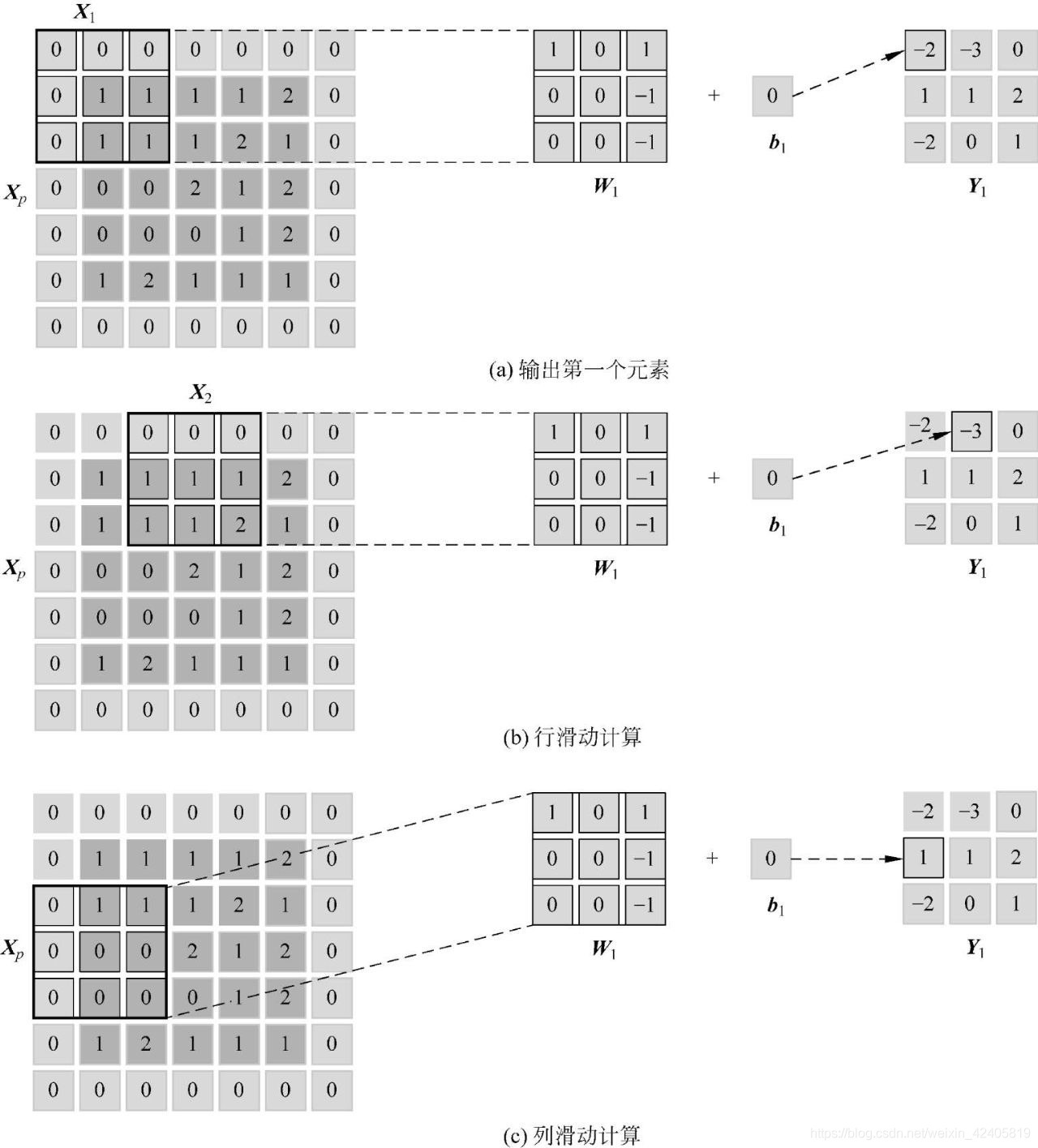
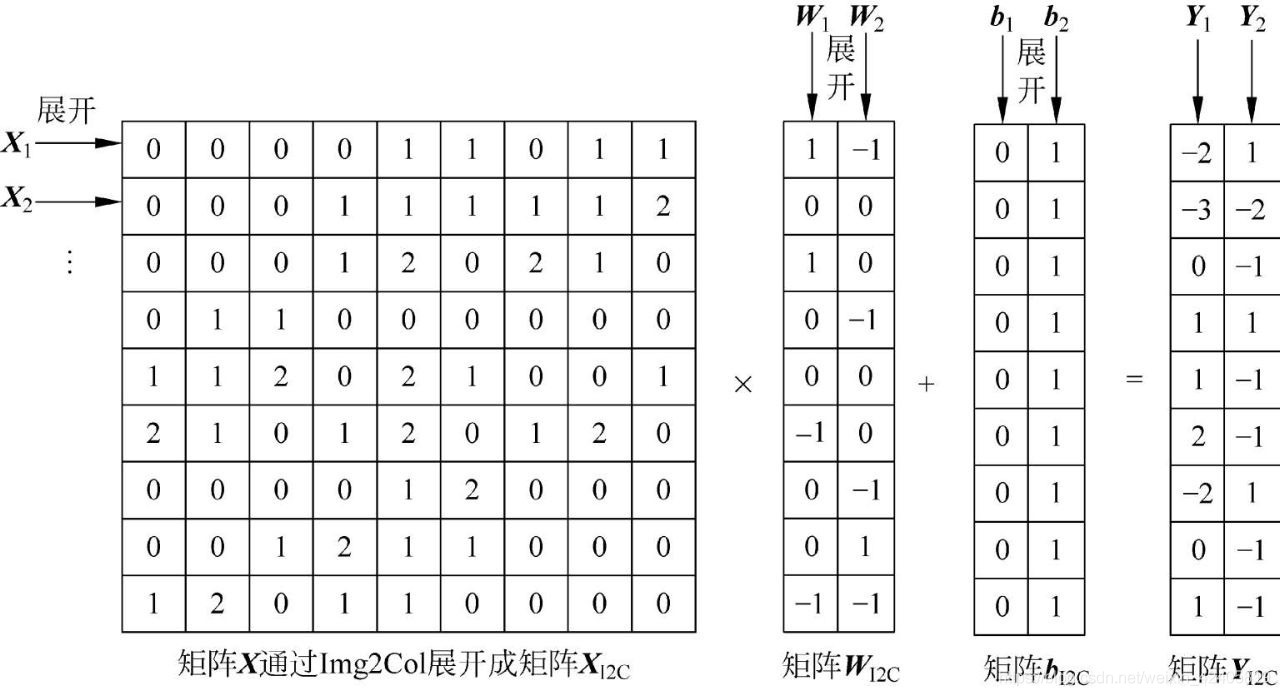
? 卷積程序最開始會涉及到你是怎么取 feature map 中卷積塊資料的問題,NCHW 的實際存盤方式是 "RRRGGGBBB",同一通道的所有像素存盤在一起;而 NHWC 的實際存盤方式是 "RGBRGBRGB",多個通道的同一位置的像素值順序存盤在一起,(本來想畫個圖的,懶得畫了哈哈,用代碼替代吧)
# feature map NCHW 通道C=3
# 通道C=0 通道C=1 通道C=2
a0 b0 c0 d0 a1 b1 c1 d1 a2 b2 c2 d2
e0 f0 g0 h0 e1 f1 g1 h1 e2 f2 g2 h2
i0 j0 k0 l0 i1 j1 k1 l1 i2 j2 k2 l2
m0 n0 o0 p0 m1 n1 o1 p1 m2 n2 o2 p2
# kernel
A0 B0 C0 A1 B1 C1 A2 B2 C2
D0 E0 F0 D1 E1 F1 D2 E2 F2
G0 H0 I0 G1 H1 I1 G2 H2 I2
? 如果用 NCHW 的 Layout,行主序存盤(row major)來說,feature map 的資料存盤方式為a0b0c0d0e0f0g0h0i0j0k0l0m0no0p0a1b1c1d1e1f1g1h1i1j1k1l1m1n1o1p1a2b2c2d2e2f2g2h2i2j2k2l2m2n2o2p2,以 3_x_3 的卷積核,對于一次卷積動作來說,feature map 需要 n * kernel_size 次資料取動作,分別是 a0b0c0、e0f0g0、i0j0k0、a1b1c1、e1f1g1、i1j1k1、a2b2c2、e2f2g2、i2j2k2,這里 n=3,kernel_size=3 就是 9 次取資料,
? 下面來看看 NHWC 的情況,如下
# feature map NHWC C=3
a2 b2 c2 d2
a1 b1 c1 d1 h2
a0 b0 c0 d0 h1 l2
e0 f0 g0 h0 l1 p2
i0 j0 k0 l0 p1
m0 n0 o0 p0
? 把上面的想象成長方體,畫的是三維的,哈哈,能想象嗎,直觀上看就是第一個平面是第一個通道,也就是 C=0,往后第二個平面是第二個通道 C=1,最后是第三個通道 C=2,有點抽象哈哈,kernel 還是一樣,如下:
# kernel
A0 B0 C0 A1 B1 C1 A2 B2 C2
D0 E0 F0 D1 E1 F1 D2 E2 F2
G0 H0 I0 G1 H1 I1 G2 H2 I2
? 對于 NHWC Layout 來說,feature map 的資料存盤方式為 a0a1a2b0b1b2c0c1c2d0d1d2e0e1e2f0f1f2g0g1g2h0h1h2i0i1i2j0j1j2k0k1k2l0l1l2m0m1m2n0n1n2o0o1o2p0p1p2,以 3_x_3 卷積,對于一次卷積動作來說,feature map 只需要 3 次資料取動作,分別是 a0a1a2b0b1b2c0c1c2、e0e1e2f0f1f2g0g1g2、i0i1i2j0j1j2k0k1k2,這樣,僅一個卷積動作,NHWC 就比 NCHW 減少了 6 次資料取操作,
? 分析得出,對于一次卷積動作來說,NHWC 取資料的次數為 kernel_size 次,而 NCHW 取資料的次數為 kernel_size * n 次,所以 NHWC 對于卷積加速資料訪存來說是更好的,而且這種好,隨著 n 的增大會更更加好,
? 收工了~
掃描下方二維碼即可關注我的微信公眾號【極智視界】,獲取更多AI經驗分享,讓我們用極致+極客的心態來迎接AI !

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/291768.html
標籤:AI