本專欄用于記錄關于深度學習的筆記,不光方便自己復習與查閱,同時也希望能給您解決一些關于深度學習的相關問題,并提供一些微不足道的人工神經網路模型設計思路,
專欄地址:「深度學習一遍過」必修篇
目錄
1 Tensor生成
2 Tensor基本操作
形狀查看
形狀更改
增加維度
壓縮維度
3 Tensor其他操作
4 Pytorch網路定義與優化
4.1 基礎網路定義介面
4.2 網路結構定義與前向傳播
4.3 優化器定義
4.4 優化器使用流程
4.5 Tensor 的自動微分 autograd
5 pytorch資料與模型介面
5.1 資料介面
5.2 計算機視覺資料集與模型讀取
5.3 資料增強介面
5.4 模型保存
1 Tensor生成
類似于
的
,可以使用
進行計算,
import torch構造一個默認 型的
張量
torch.Tensor(5, 3)
構造一個 矩陣,不初始
torch.empty(5, 3)
構造一個隨機初始化的矩陣
torch.rand(5, 3)
構造一個矩陣全為 ,而且資料型別是
torch.zeros(5, 3, dtype=torch.long)
torch.long
基于已經存在的 創建一個
x = torch.zeros(5, 3, dtype=torch.long)x.new_ones(5, 3, dtype=torch.double)
構造一個張量,為 ,從資料中推斷資料型別
torch.tensor([5.5, 3])
2 Tensor基本操作
在張量做加減乘除等運算時,需要保證張量的形狀一致,往往需要對某些張量進行更改
import torch構造一個默認 型的
張量
x = torch.Tensor(5, 3)
x
形狀查看
x.size()
x.shape
x.dim() # dim維度
形狀更改
展為 矩陣,共享記憶體
x.view(3,5)
展為 維向量
x.view(-1)
增加維度
torch.unsqueeze(x,1)
壓縮維度
torch.squeeze(x,1)
3 Tensor其他操作
拼接與拆分,基本數學操作:對多個分支的張量加以融合或拆分
torch.cat() #拼接
torch.stack() #堆疊
torch.chunk() #分塊
torch.split() #切分z = x + y # torch加法z = torch.add(x, y) # torch加法 y.add_(x) # 下劃線版本,in-place加法,原地運算,結果存在y中4 Pytorch網路定義與優化
4.1 基礎網路定義介面
通過 包來構建網路, 包含
,
:純函式,不包含可學習引數,如激活函式,池化層
:
的核心資料結構,可以是一個
或者一個網路,其中
4.2 網路結構定義與前向傳播
通過 包來構建網路
import torch
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__() #繼承Net類,并進行初始化
self.conv1 = nn.Conv2d(1, 6, 5) #繼承nn.Module的需要實體化
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x): #前向傳播函式
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2)) #relu,max_pool2d,不需要實體化
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(-1, self.num_flat_features(x))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x配合使用,
,
,
層狀態自動切換,
import torch.nn as nn
# 創建一個Model類, 這個模型的功能就是給輸入的數加上1
class Model(nn.Module):
def __init__(self):
super().__init__()
def forward(self, input):
output = input + 1
print(output)
model = Model() # 實體化
input = torch.tensor(1) # 輸入為1
model(input) # 輸出為0 和
都是和輸入共享記憶體的,
的好處是不用輸入形狀引數,直接指定維度,在這之后的都被拉平,
則是更加靈活.
4.3 優化器定義
通過 包來構建(優化目標與方法定義)
import torch.optim as
optim criterion = nn.CrossEntropyLoss() #交叉熵損失
optimizer_ft = optim.SGD(modelclc.parameters(), lr=0.1, momentum=0.9) #SGD優化方法
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=100, gamma=0.1) #學習率4.4 優化器使用流程
三個步驟:清空梯度、反向傳播、更新引數
for input, target in dataset:
optimizer.zero_grad() #清空梯度
output = model(input) #自動執行forward函式
loss = loss_fn(output, target) #計算損失
loss.backward() #反向傳播
optimizer.step() #更新引數前向計算
out = net(img) #自動執行forward函式
loss = criterion(out,label) #計算損失反向傳播
loss.backward() #反向傳播
optimizer.step() #更新引數4.5 Tensor 的自動微分 autograd
和
互相連接并構建一個非回圈圖,它保存完整計算程序,
完成自動求導的步驟:
- 將
的屬性
設定為
,開始跟蹤針對
的所有操作,
- 完成計算后呼叫
自動計算所有梯度,
- 將該張量的梯度將累積到
屬性中,
,
,
,
是輸入葉子結點,
和
需要進行引數更新,
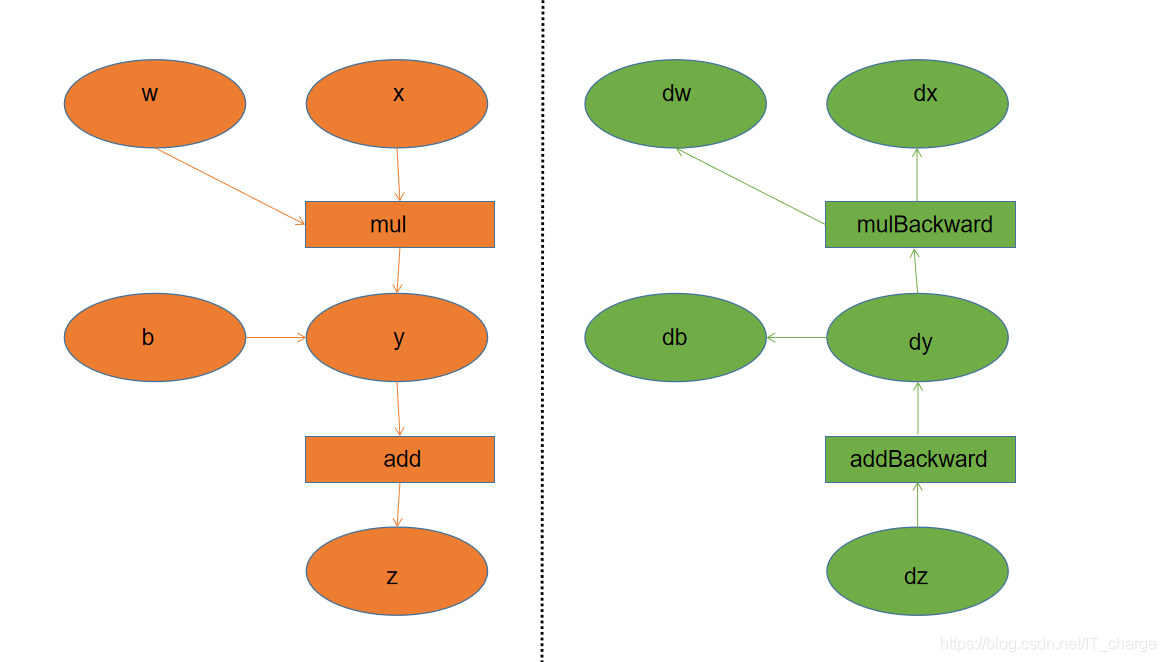
import torch
import numpy as np
x=torch.Tensor([2]) #定義輸入張量x
#初始化權重引數W,偏移量b、并設定require_grad為True, 為自動求導
w=torch.randn(1,requires_grad=True)
b=torch.randn(1,requires_grad=True)
y=torch.mul(w,x)
z=torch.add(y,b) #等價于y+b
z.backward() #標量進行反向傳播,向量則需要構建梯度矩陣
print("x,w,b,y,z的require_grad屬性分別為:{},{},{},{},{}".format(x.requires_grad, w.requires_grad,b.requires_grad,y.requires_grad,z.requires_grad)) 
如何取消求導?
- 呼叫
修改
為
,它將其與計算歷史記錄分離
- 呼叫
停止
模塊的作業
# 推理案例
torch.no_grad() #停止autograd模塊的作業,加速和節省顯存
image = Image.open(imagepath)
imgblob = data_transforms(img).unsqueeze(0) #填充資料維度
imgblob = Variable(imgblob)
predict = F.softmax(net(imgblob))
index = np.argmax(predict.detach().numpy())5 pytorch資料與模型介面
5.1 資料介面
通過 包來構建資料集
讀取資料的 個必須實作的函式:
- __init__:相關引數定義
- __len __:獲取資料集樣本總數
- __getitem __:讀取每個樣本及標簽
class TestDataset(torch.utils.data.Dataset):
#繼承Dataset
def __init__(self):
self.Data=np.asarray([[1,2],[3,4],[2,1],[3,4],[4,5]])#資料
self.Label=np.asarray([0,1,0,1,2])#標簽
def __getitem__(self, index):
data=torch.from_numpy(self.Data[index]) #把numpy轉換為Tensor
label=torch.tensor(self.Label[index])
return data,label
def __len__(self):
return len(self.Data)# 使用index取資料
Test=TestDataset()
print(Test[2]) #結果是(tensor([2, 1]), tensor(0))
print(Test.__len__()) #結果是5使用 迭代器提取資料(實作批量讀取,打亂資料等)
# 獲得資料指標
test_loader = data.DataLoader(Test, batch_size=2,shuffle=False, num_workers=2) - batch_size:batch大小
- shuffle=False:是否打亂
- num_workers=2:加載資料執行緒數
引數:
- 當加載
的時間
資料訓練的時間,
每次訓練完都可以直接從
中取到
,即使增加
- 當加載
資料訓練的時間,
個
5.2 計算機視覺資料集與模型讀取
通過 包來讀取已有的資料集和模型
(
等,
)
# 資料集讀取
import torchvision.dataset as dataset
data_dir = './data/'
data = datasets.ImageFolder('./data',data_transform)
dataloader = data.DataLoader(data)5.3 資料增強介面
每一次訓練時,需要輸入同樣大小的圖片進行訓練,一般使用裁剪 縮放操作,
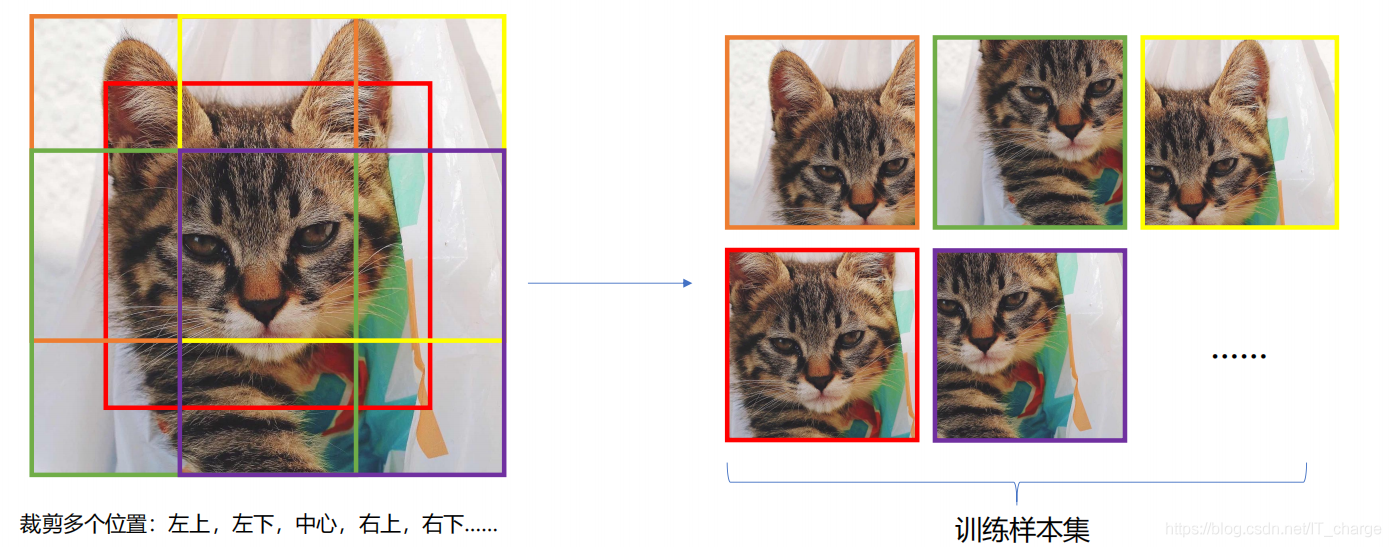
torchvision 資料增強介面
通過 包的
進行資料預處理和增強:包括縮放,裁剪等資料增強函式,標準化等預處理函式
data_transforms = {
'train': transforms.Compose([
transforms.Scale(64), # 縮放的影像大小:64*64
transforms.RandomSizedCrop(48), # 實際用于訓練的影像大小:48*48,采用隨機裁剪與縮放操作(此時Scale為冗余操作)
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.5,0.5,0.5], [0.5,0.5,0.5]) ]),
'val': transforms.Compose([
transforms.Scale(64),
transforms.CenterCrop(48), # 實際用于測驗的影像大小:48*48,采用中心裁剪操作
transforms.ToTensor(),
transforms.Normalize([0.5,0.5,0.5], [0.5,0.5,0.5]) ]), }常見的資料預處理與增強相關的操作
CenterCrop,ColorJitter,FiveCrop,Grayscale,Pad,RandomAffine,RandomApply, RandomCrop,RandomGrayscale, RandomHorizontalFlip,RandomPerspective,RandomResizedCrop,RandomRotation, RandomSizedCrop, RandomVerticalFlip, Resize,Scale,TenCrop,GaussianBlur,RandomChoice,RandomOrder, LinearTransformation,Normalize,RandomErasing,ConvertImageDtype, ToPILImage,ToTensor,Lambda
通過 包的
介面,自定義資料增強函式
import torchvision.transforms.functional as TF
import random
def my_segmentation_transforms(image, segmentation):
if random.random() > 0.5:
angle = random.randint(-30, 30)
image = TF.rotate(image, angle)
segmentation = TF.rotate(segmentation, angle)
# more transforms ...
return image, segmentationtorchvision 模型介面
通過 包來讀取已有的模型,
(
等)
# 模型讀取、匯出
import torchvision.models as models
model = models.alexnet(pretrained=True).cuda()
torch.save(model.state_dict(),'models/model.ckpt')
dummy_input = torch.randn(10, 3, 224, 224).cuda()
torch.onnx.export(model, dummy_input, "alexnet.proto", verbose=True)5.4 模型保存
保存或加載整個模型
#保存
torch.save(model, '\model.pkl’)
#加載
model = torch.load('\model.pkl’)保存或加載模型引數
# 保存
torch.save(model.state_dict(), '\parameter.pkl')
# 加載
model = TheModelClass(...)
model.load_state_dict(torch.load('\parameter.pkl’)) 是一個
字典物件,將每個圖層映射到其引數
,
只有具有可學習引數的層(卷積層,線性層等)和已注冊的緩沖區( 的
)才存在,
歡迎大家交流評論,一起學習
希望本文能幫助您解決您在這方面遇到的問題
感謝閱讀
END
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/291770.html
標籤:AI