1.影像著色演算法原理
影像著色,通俗講就是對黑白的照片進行處理,生成為彩色的影像,有點像買的圖框畫,自己用顏料在圖框中進行填色,
演算法原理上用到了上一節講到的Lab顏色空間,具體模型架構如下圖所示:
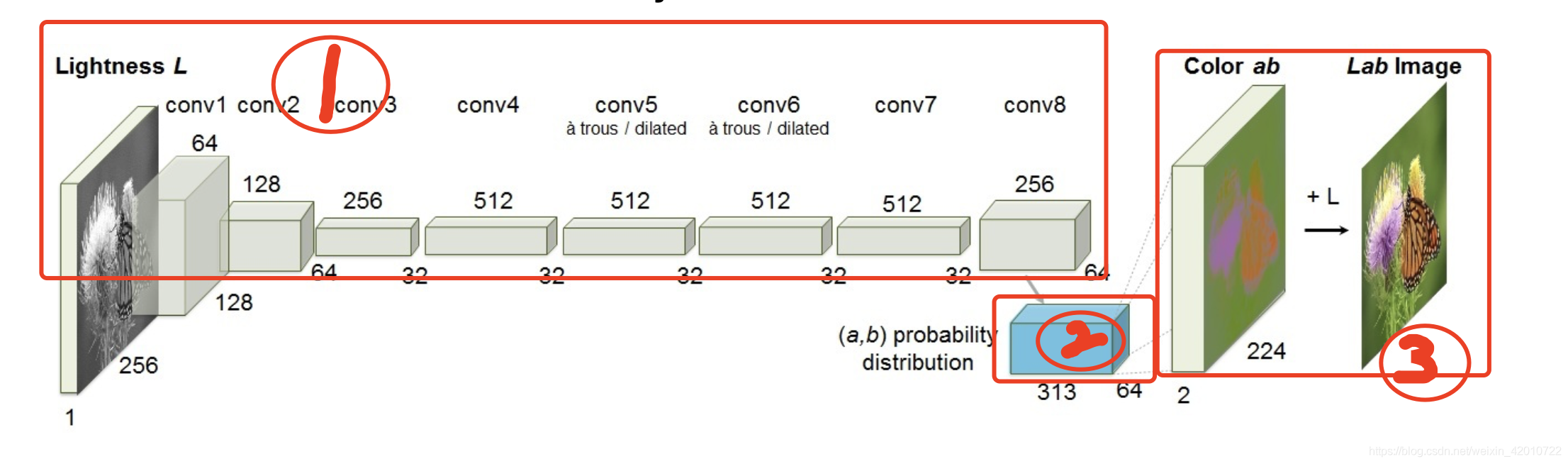
1.1 模型架構
這里我把模型分為三個部分,對這三部分進行詳細解釋,
第一部分
第一部分實際是一個典型的VGG16模型,只不過去掉了VGG16后面池化層部分,在后面加上如下表的卷積層
| 卷積層 | 通道數 | 卷積核 | 步長 | 填充padding | 備注 |
|---|---|---|---|---|---|
| Conv7_1 | 512 | 3x3 | 1 | 1 | 卷積后進行ReLU |
| Conv7_2 | 512 | 3x3 | 1 | 1 | 卷積后進行ReLU |
| Conv7_3 | 512 | 3x3 | 1 | 1 | 卷積后進行ReLU,再進行一次批次歸一化處理nn.BatchNorm2d |
| Conv8_1 | 256 | 4x4 | 2 | 1 | 卷積后進行ReLU |
| Conv8_2 | 256 | 3x3 | 1 | 1 | 卷積后進行ReLU |
| Conv8_3 | 256 | 3x3 | 1 | 1 | 卷積后進行ReLU |
注意這里Conv8_1使用的是反卷積,
反卷積函式如下:
class torch.nn.ConvTranspose2d(in_channels, out_channels,kernel_size, stride=1, padding=0, output_padding=0, groups=1, bias=True, dilation=1)
反卷積公式如下:
o u t p u t = ( i n p u t ? 1 ) ? s t r i d e + o u t p u t p a d d i n g ? 2 ? p a d d i n g + k e r n e l s i z e output=(input-1)*stride+outputpadding-2*padding+kernelsize output=(input?1)?stride+outputpadding?2?padding+kernelsize
第二部分
第二部分為一個簡單的卷積運算,卷積層通道數為313,1x1,步長為1,padding為0,
第三部分
- 首先將輸入的影像進行一次softmax,得到每一個通道下各像素值的概率分布,其中每一個通道下的像素值的和為1,
- 再進行一次卷積,卷積層通道數為2,padding為0,步長為1,并對影像的紋理邊緣進行一次加強dilation,
- 在前面卷積后對影像,再進行一次向上采樣恢復原始影像尺寸,最后乘以固定引數值110,得到通道ab的影像,
1.2 演算法步驟
- 將所有訓練影像從RGB顏色空間轉換為Lab顏色空間,通過原始影像的ab值
Z
Z
Z和模型訓練預測的ab值
Z
^
\hat{Z}
Z^,計算loss
L ( Z ^ , Z ) = ? 1 H W ∑ h , w ∑ q Z h , w , q l o g ( Z ^ h , w , q ) L(\hat{Z},Z)=-\frac{1}{HW}\sum_{h,w}\sum_{q}Z_{h,w,q}log(\hat{Z}_{h,w,q}) L(Z^,Z)=?HW1?∑h,w?∑q?Zh,w,q?log(Z^h,w,q?) - 將想要著色的影像的L通道作為輸入,輸入到模型網路中,來預測ab通道,
- 將輸入的L通道與預測出來的ab通道進行結合
- 將Lab影像轉換回RGB
pytorch實作影像著色
由于模型訓練太長了 這里選擇下載別人已經訓練好的模型
訓練模型
代碼目錄
\colorizers
\img
\imgout
\main.py
\model.py
\util.py
其中img存放需要著色的圖片,imgout保存生成的圖片,util實作影像處理,model.py定義模型代碼,
model.py
class model():
def __init__(self, norm_layer=nn.BatchNorm2d):
super(model, self).__init__()
self.ab_norm=110
model1=[nn.Conv2d(1, 64, kernel_size=3, stride=1, padding=1, bias=True),]
model1+=[nn.ReLU(True),]
model1+=[nn.Conv2d(64, 64, kernel_size=3, stride=2, padding=1, bias=True),]
model1+=[nn.ReLU(True),]
model1+=[norm_layer(64),]
model2=[nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1, bias=True),]
model2+=[nn.ReLU(True),]
model2+=[nn.Conv2d(128, 128, kernel_size=3, stride=2, padding=1, bias=True),]
model2+=[nn.ReLU(True),]
model2+=[norm_layer(128),]
model3=[nn.Conv2d(128, 256, kernel_size=3, stride=1, padding=1, bias=True),]
model3+=[nn.ReLU(True),]
model3+=[nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1, bias=True),]
model3+=[nn.ReLU(True),]
model3+=[nn.Conv2d(256, 256, kernel_size=3, stride=2, padding=1, bias=True),]
model3+=[nn.ReLU(True),]
model3+=[norm_layer(256),]
model4=[nn.Conv2d(256, 512, kernel_size=3, stride=1, padding=1, bias=True),]
model4+=[nn.ReLU(True),]
model4+=[nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1, bias=True),]
model4+=[nn.ReLU(True),]
model4+=[nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1, bias=True),]
model4+=[nn.ReLU(True),]
model4+=[norm_layer(512),]
model5=[nn.Conv2d(512, 512, kernel_size=3, dilation=2, stride=1, padding=2, bias=True),]
model5+=[nn.ReLU(True),]
model5+=[nn.Conv2d(512, 512, kernel_size=3, dilation=2, stride=1, padding=2, bias=True),]
model5+=[nn.ReLU(True),]
model5+=[nn.Conv2d(512, 512, kernel_size=3, dilation=2, stride=1, padding=2, bias=True),]
model5+=[nn.ReLU(True),]
model5+=[norm_layer(512),]
model6=[nn.Conv2d(512, 512, kernel_size=3, dilation=2, stride=1, padding=2, bias=True),]
model6+=[nn.ReLU(True),]
model6+=[nn.Conv2d(512, 512, kernel_size=3, dilation=2, stride=1, padding=2, bias=True),]
model6+=[nn.ReLU(True),]
model6+=[nn.Conv2d(512, 512, kernel_size=3, dilation=2, stride=1, padding=2, bias=True),]
model6+=[nn.ReLU(True),]
model6+=[norm_layer(512),]
model7=[nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1, bias=True),]
model7+=[nn.ReLU(True),]
model7+=[nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1, bias=True),]
model7+=[nn.ReLU(True),]
model7+=[nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1, bias=True),]
model7+=[nn.ReLU(True),]
model7+=[norm_layer(512),]
model8=[nn.ConvTranspose2d(512, 256, kernel_size=4, stride=2, padding=1, bias=True),]
model8+=[nn.ReLU(True),]
model8+=[nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1, bias=True),]
model8+=[nn.ReLU(True),]
model8+=[nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1, bias=True),]
model8+=[nn.ReLU(True),]
model8+=[nn.Conv2d(256, 313, kernel_size=1, stride=1, padding=0, bias=True),]
self.model1 = nn.Sequential(*model1)
self.model2 = nn.Sequential(*model2)
self.model3 = nn.Sequential(*model3)
self.model4 = nn.Sequential(*model4)
self.model5 = nn.Sequential(*model5)
self.model6 = nn.Sequential(*model6)
self.model7 = nn.Sequential(*model7)
self.model8 = nn.Sequential(*model8)
self.softmax = nn.Softmax(dim=1)
self.model_out = nn.Conv2d(313, 2, kernel_size=1, padding=0, dilation=1, stride=1, bias=False)
self.upsample4 = nn.Upsample(scale_factor=4, mode='bilinear')
def forward(self, x):
conv1_2 = self.model1(self.normalize_l(x))
conv2_2 = self.model2(conv1_2)
conv3_3 = self.model3(conv2_2)
conv4_3 = self.model4(conv3_3)
conv5_3 = self.model5(conv4_3)
conv6_3 = self.model6(conv5_3)
conv7_3 = self.model7(conv6_3)
conv8_3 = self.model8(conv7_3)
out_reg = self.model_out(self.softmax(conv8_3))
return self.upsample4(out_reg)*self.ab_norm
def model(pretrained=True):
model = model()
if(pretrained):
import torch.utils.model_zoo as model_zoo
model.load_state_dict(model_zoo.load_url('https://colorizers.s3.us-east-2.amazonaws.com/colorization_release_v2-9b330a0b.pth',map_location='cpu',check_hash=True))
return model
這里解釋幾個函式:
nn.BatchNorm2d
模型訓練之前,需對資料做歸一化處理,使其分布一致
class torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True)
- num_features: 一般輸入引數為batch_sizenum_featuresheight*width,即為其中特征的數量,channel數,
- eps: 為保證數值穩定性(分母不能趨近或取0),給分母加上的值,默認為1e-5,
- momentum: 動態均值和動態方差所使用的動量,即一個用于運行程序中均值和方差的一個估計引數,默認值為0.1,
- affine: 一個布林值,當設為true,給該層添加可學習的仿射變換引數,即給定可以學習的系數矩陣 (gamma)和 (beta),
nn.Softmax(dim)
dim值一般有0,1,2,分別對應的就是三維陣列的0,1,2,
import torch.nn as nn
m = nn.Softmax(dim=0)
n = nn.Softmax(dim=1)
k = nn.Softmax(dim=2)
input = torch.randn(2, 2, 3)
print(input)
print(m(input))
print(n(input))
print(k(input))
對dim=0時,m[0][0][0]+m[1][0][0]=1
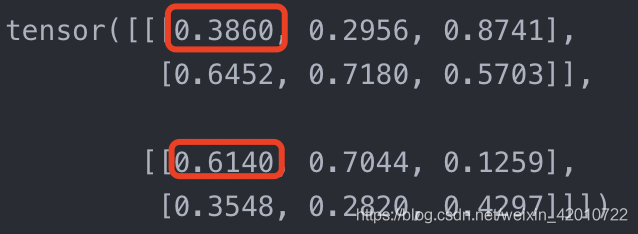
對dim=1時,n[0][1][0]+n[0][0][0]=1
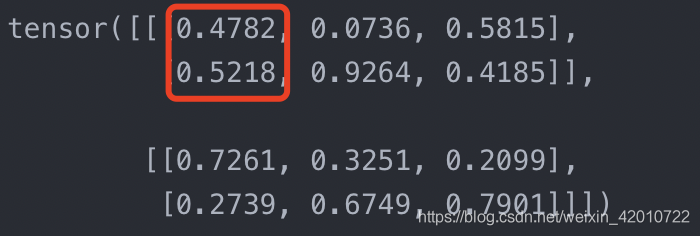
對dim=2時,k[0][0][0]+k[0][0][1]+k[0][0][2]=1
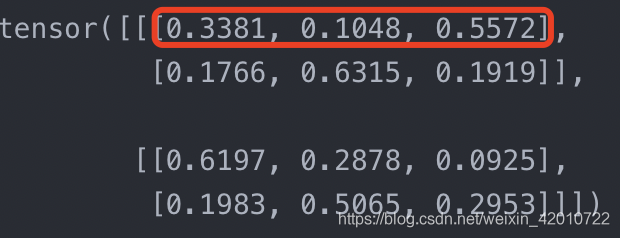
nn.Upsample
實作向上采樣
Class nn.Upsample(size=None, scale_factor=None, mode='nearest', align_corners=None)
- size:根據不同的輸入型別制定的輸出大小,
- scale_factor:指定輸出為輸入的多少倍數,如果輸入為tuple,其也要制定為tuple型別
- mode:可使用的上采樣演算法,有’nearest’, ‘linear’, ‘bilinear’, ‘bicubic’ and ‘trilinear’. 默認使用’nearest’
- align_corners:如果為True,輸入的角像素將與輸出張量對齊,因此將保存下來這些像素的值,僅當使用的演算法為’linear’, 'bilinear’or’trilinear’時可以使用,默認設定為False
util.py
import cv2
import numpy as np
from skimage import color
import torch
import torch.nn.functional as F
from IPython import embed
def load_img(img_path):
out_np = np.asarray(cv2.imread(img_path))
if(out_np.ndim==2):
out_np = np.tile(out_np[:,:,None],3)
return out_np
def resize_img(img, HW=(256,256), resample=3):
return np.asarray(cv2.resize(img,(HW[1],HW[0])))
def preprocess_img(img_rgb_orig, HW=(256,256), resample=3):
# return original size L and resized L as torch Tensors
img_rgb_rs = resize_img(img_rgb_orig, HW=HW, resample=resample)
img_lab_orig = color.rgb2lab(img_rgb_orig)
img_lab_rs = color.rgb2lab(img_rgb_rs)
img_l_orig = img_lab_orig[:,:,0]
img_l_rs = img_lab_rs[:,:,0]
tens_orig_l = torch.Tensor(img_l_orig)[None,None,:,:]
tens_rs_l = torch.Tensor(img_l_rs)[None,None,:,:]
return (tens_orig_l, tens_rs_l)
def postprocess_tens(tens_orig_l, out_ab, mode='bilinear'):
# tens_orig_l 1 x 1 x H_orig x W_orig
# out_ab 1 x 2 x H x W
HW_orig = tens_orig_l.shape[2:]
HW = out_ab.shape[2:]
# call resize function if needed
if(HW_orig[0]!=HW[0] or HW_orig[1]!=HW[1]):
out_ab_orig = F.interpolate(out_ab, size=HW_orig, mode='bilinear')
else:
out_ab_orig = out_ab
out_lab_orig = torch.cat((tens_orig_l, out_ab_orig), dim=1)
return color.lab2rgb(out_lab_orig.data.cpu().numpy()[0,...].transpose((1,2,0)))
main.py
import argparse
from model import *
from util import *
parser = argparse.ArgumentParser()
parser.add_argument('-i','--img_path', type=str, default='img/10.jpg')
parser.add_argument('-o','--save_path', type=str, default='imgout')
opt = parser.parse_args()
# 加載模型
model = model(pretrained=True).eval()
img = load_img(opt.img_path)
(tens_l_orig, tens_l_rs) = preprocess_img(img, HW=(256,256))
#著色器輸出256x256 ab映射
#調整大小并連接到原始L通道
img_bw = postprocess_tens(tens_l_orig, torch.cat((0*tens_l_orig,0*tens_l_orig),dim=1))
out_img_model = postprocess_tens(tens_l_orig, model(tens_l_rs))
plt.imsave('%s/img.png'%opt.save_path, out_img_model)


轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/291958.html
標籤:其他
上一篇:OpenCV4 三、四章函式合計
下一篇:【論文學習】《On Prosody Modeling For ASR+TTS Based Voice Conversion》