《On Prosody Modeling For ASR+TTS Based Voice Conversion》論文學習
文章目錄
- 《On Prosody Modeling For ASR+TTS Based Voice Conversion》論文學習
- 摘要
- 1 介紹
- 2 基于 ASR + TTS 的語音轉換
- 2.1 整體框架和轉換程序
- 2.2 中間表示
- 2.3 訓練
- 3 基于 ASR + TTS 的語音韻律建模轉換
- 3.1 全域樣式標記和文本預測
- 3.2 源韻律轉移
- 3.3 目標文本預測
- 4 實驗設定
- 4.1 資料
- 4.2 實作
- 5 實驗評估
- 5.1 客觀評價
- 5.1.1 任務 1 的結果
- 5.1.2 任務 2 的結果
- 5.2 主觀評價
- 5.2.1 自然度測驗
- 5.2.2 相似度測驗
- 5.3 風格嵌入的可視化
- 6 結論
摘要
在語音轉換(VC)中,一種在最新的語音轉換挑戰(VCC) 2020中顯示出良好結果的方法是:首先使用自動語音識別(ASR)模型將源語音轉錄為潛在的語言內容;然后,這些資料被文本到語音(TTS)系統用作輸入,以生成轉換后的語音,這種范式被稱為ASR+TTS,它忽略了韻律的建模,而韻律在語音自然度和轉換相似度方面起著重要作用,雖然一些研究者已經考慮過從源語中轉移韻律線索,但在訓練和轉換程序中會出現說話人不匹配的情況,
為了解決這一問題,本文提出了一種基于目標說話人的語言表征直接預測韻律的方法,即目標文本預測,我們在VCC2020基準上評估了這兩種方法,并考慮了不同的語言表征,結果表明,在客觀評價和主觀評價中,TTP都是有效的,
關鍵詞:語音轉換,自動語音識別,文本到語音,韻律,全域風格標記
1 介紹
在語音轉換(voice conversion,VC)中,目的是在不改變語言內容的情況下,將源語轉換為目標語(《Continuous probabilistic transform for voice conversion》,《Voice Conversion Based on Maximum-Likelihood Estimation of Spectral Parameter Trajectory》),從資訊的角度來看,VC的目標是從源語音中提取語音內容,然后將提取的內容與目標說話人的身份合成轉換后的語音,一個理想的VC系統將由識別模塊和合成模塊兩部分組成,這兩部分分別執行上述的操作,
這種范式可以通過自動語音識別(ASR)模型和文本語音轉換(TTS)系統的級聯直接實作,即ASR+TTS,在最新的語音轉換挑戰賽2020 (VCC2020)(《Voice Conversion Challenge 2020 - Intra-lingual semi-parallel and cross-lingual voice conversion》)中,ASR+TTS作為基準系統(《The Sequence-to-Sequence Baseline for the Voice Conversion Challenge 2020: Cascading ASR and TTS》),表現最好的系統也實作了這樣的框架(《Voice Conversion by Cascading Automatic Speech Recognition and Text-to-Speech Synthesis with Prosody Transfer》),在自然性和相似性方面都展現了最先進的性能,
盡管ASR+TTS范式的研究取得了可喜的成果,但韻律的轉換和建模往往被忽視,韻律是講話中幾個基本的前期成分的組合,如音高、重音和停頓,它影響后續的高層次特征,包括情緒和風格,從前文所述的資訊角度來看,ASR+TTS中的合成模塊負責恢復識別模塊丟棄的所有資訊,在基于文本的ASR+TTS基線系統(《The Sequence-to-Sequence Baseline for the Voice Conversion Challenge 2020: Cascading ASR and TTS》)中,由于文本到韻律的映射是一對多的,特定的韻律或風格在文本中是不可預測的,因此TTS模型只能從訓練資料的統計屬性隱式建模韻律模式,導致崩潰,平均韻律風格,
表達性言語合成是一個與之密切相關的研究領域,其目的之一就是控制言語的變異性,最廣泛使用的方法之一是使用全域風格標記(GST)(《Style Tokens: Unsupervised Style Modeling, Control and Transfer in End-to-End Speech Synthesis》),使用該標記將參考語音編碼到一個固定維度的嵌入(《Towards Endto-End Prosody Transfer for Expressive Speech Synthesis with Tacotron》)中,該嵌入表示為一組預定義風格標記的加權和,因此,在給定文本、說話人身份和參考語音韻律編碼的條件生成模型的基礎上,構建了一個帶有GST的TTS模型(GST-TTS),許多人將這種框架推廣到變分自編碼器(VAEs)(《Learning Latent Representations for Style Control and Transfer in End-to-end Speech Synthesis》,《Hierarchical Generative Modeling for Controllable Speech Synthesis》),以增加學習到的嵌入空間的泛化性,另一項作業是通過學習可變長度的韻律嵌入來實作細粒度韻律控制(《Robust and Fine-grained Prosody Control of End-to-end Speech Synthesis》,《FineGrained Robust Prosody Transfer for Single-Speaker Neural Text-To-Speech》),
上述方法首次應用于(《Transferring Source Style in Non-Parallel Voice Conversion》)中的VC中,稱之為源韻律轉移(source prosody transfer,SPT),如圖1a所示,參考編碼器將源語音作為輸入,生成全域韻律嵌入,使轉換后的語音的韻律跟隨源語音,這一程序在表達性TTS文獻(《Towards Endto-End Prosody Transfer for Expressive Speech Synthesis with Tacotron》)中也被稱為同文本韻律遷移,因為參考語音和TTS的輸入語音包含相同的語言內容,而TTS的輸入語音也來源于源語音,在VCC2020中,幾個表現最好的團隊通過采用帶有對抗層的變分參考編碼器來幫助解糾纏,從而擴展了SPT(《Voice Conversion by Cascading Automatic Speech Recognition and Text-to-Speech Synthesis with Prosody Transfer》,《Submission from SRCB for Voice Conversion Challenge 2020》),顯示了SPT的競爭力,
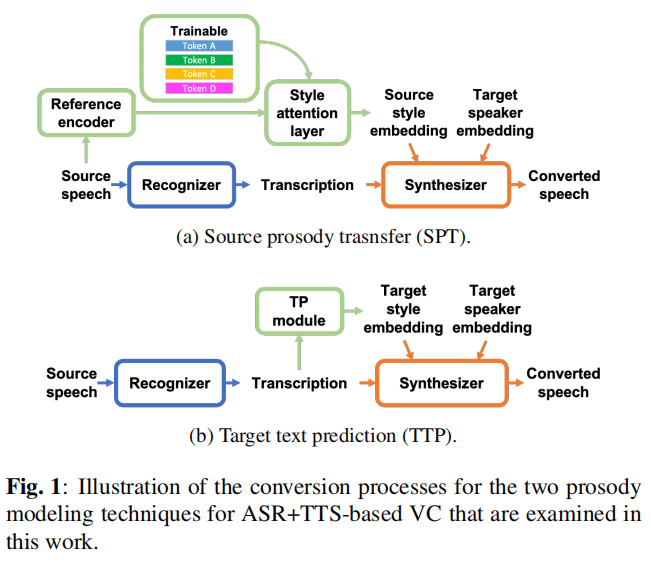
盡管如此,(《Voice Conversion by Cascading Automatic Speech Recognition and Text-to-Speech Synthesis with Prosody Transfer》)的消融研究表明SPT對任務1并沒有帶來任何顯著的改善,在基于ASR+TTS的VC中,SPT可能是一個次優的韻律建模策略,首先,依賴于目標說話人的TTS訓練導致了訓練和轉換之間的不匹配,因為在訓練時目標說話人的語音作為參考編碼器的輸入,而在轉換時使用源說話人的語音,揚聲器對抗分類器可以緩解這個問題(《Voice Conversion by Cascading Automatic Speech Recognition and Text-to-Speech Synthesis with Prosody Transfer》,《Submission from SRCB for Voice Conversion Challenge 2020》),但需要仔細的超引數調整,第二,有些情況下SPT是不需要的,如情感VC或重音轉換,
在本研究中,我們研究了兩種基于ASR+TTS的VC韻律建模方法,除了SPT,我們提出了一種新的技術,我們稱之為目標文本預測(TTP),我們借鑒(《Predicting Expressive Speaking Style from Text in End-To-End Speech Synthesis》)的思想,訓練一個文本預測(TP)模塊,從源語音衍生的文本中生成韻律嵌入,圖1b說明了這個程序,TP模塊首先在多說話人資料集上使用GST-TTS進行預訓練,然后以依賴目標說話人的方式進一步進行微調,因此,與SPT不同,TTP不存在訓練和轉換之間的不匹配,我們對這項作業的貢獻如下:
(1)我們提出了一種新的基于ASR+TTS的VC韻律建模技術TTP,該技術以目標說話人依賴的方式預測韻律,
(2)我們將SPT和TTP兩種韻律建模方法應用于三個不同表征的ASR-TTS系統,并在VCC2020的兩個任務中對其進行評估,結果表明,TTP總是優于SPT,
2 基于 ASR + TTS 的語音轉換
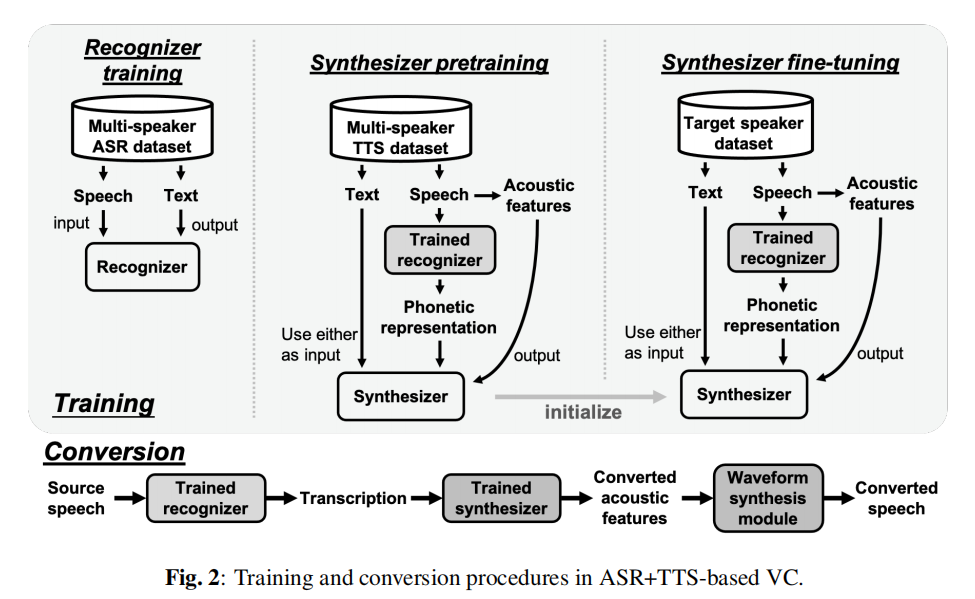
2.1 整體框架和轉換程序
本作業中基于ASR+TTS的VC系統是建立在VCC2020的基線系統之上的,如圖2所示,該系統由三個模塊組成:獨立于說話人的識別器,依賴于目標說話人的合成器,以及生成最終語音波形的神經聲碼器,識別器首先從源語音
X
X
X開始提取語音內容:
Y
^
=
R
e
c
o
g
n
i
z
e
r
(
X
)
\hat{Y}=Recognizer(X)
Y^=Recognizer(X),合成器采用轉錄和合成轉換的聲學特征:
X
^
=
S
y
n
t
h
e
s
i
z
e
r
(
Y
^
)
\hat{X}=Synthesizer(\hat{Y})
X^=Synthesizer(Y^),神經聲碼器最終使用轉換后的聲學特征作為輸入來重建波形,
2.2 中間表示
語音內容
Y
Y
Y可以是任何中間表征,除了像在(《The Sequence-to-Sequence Baseline for the Voice Conversion Challenge 2020: Cascading ASR and TTS》)中那樣使用文本外,在本作業中,我們還評估以下兩種表示,請注意,這項作業的目標是檢查三種表現形式的韻律建模技術的有效性,而不是提供它們之間的公平比較,
瓶頸特征(BNF):
由ASR模型衍生出來的與說話人無關的框架級語音瓶頸特征為內容提供了強有力的線索,這些特征首先在(《Phonetic posteriorgrams for many-to-one voice conversion without parallel data training》)中使用,其中使用了語音后驗圖(PPG),這是一種時間-類別矩陣,代表每一幀每個語音類別(指單詞、音素或多音素)的后驗概率,在這項作業中,就像在(《Sequence-to-Sequence Acoustic Modeling for Voice Conversion》)中一樣,我們使用ASR模型中最后一個softmax層之前的隱藏表示,
VQW2V:
BNF等特征源自ASR模型,需要使用標簽進行監督;這增加了構建這樣一個系統的成本,特別是在低資源或跨語言的環境中,另外,一些研究(《Anyto-One Sequence-to-Sequence Voice Conversion using SelfSupervised Discrete Speech Representations》,《The Academia Sinica Systems of Voice Conversion for VCC2020》,《FragmentVC: Any-to-Any Voice Conversion by End-to-End Extracting and Fusing Fine-Grained Voice Fragments With Attention》)采用了在訓練中不需要任何標簽的自我監督表征,但仍然是說話者獨立的和框架上的,在本作業中,我們采用矢量量化的wav2vec (VQW2V)(《vq-wav2vec: Self-Supervised Learning of Discrete Speech Representations》),
2.3 訓練
ASR:多揚聲器資料集
D
A
S
R
D_{ASR}
DASR?確保識別器的揚聲器獨立性,
TTS:合成器訓練包括預訓練和微調階段,先對多說話人TTS資料集
D
T
T
S
D_{TTS}
DTTS?進行預訓練,然后對有限目標說話人資料集
D
t
r
g
D_{trg}
Dtrg?進行微調,這是建立現代神經TTS模型的常見做法,因為前訓練確保了穩定的質量,微調保持了高說話者相似度(《Semi-Supervised Speaker Adaptation for Endto-End Speech Synthesis with Pretrained Models》),這樣的訓練策略甚至允許對大約5分鐘的資料進行訓練,為了訓練基于文本的合成器,使用了人類標記的文本,然而,由于不可能標注ground-truth BNF和VQW2V,我們使用訓練過的識別器提取表示進行合成器訓練,
ASR和TTS模型采用序列到序列(seq2seq)結構,通過建模語音中的長期依賴關系,提高了轉換相似性,請注意,這兩個模型可以分別訓練,從而受益于它們各自領域的高級技術和各種各樣的資料集,
3 基于 ASR + TTS 的語音韻律建模轉換
本文研究了兩種韻律建模技術,即SPT和TTP,在本節中,我們首先介紹了GST和TP這兩個基本的構建模塊,然后描述了SPT和TTP中的訓練程序,我們省略了在第1節中討論過的轉換程序的描述,
3.1 全域樣式標記和文本預測
GST-TTS旨在使用從參考語音編碼的全域風格嵌入(與《Robust and Fine-grained Prosody Control of End-to-end Speech Synthesis》中的細粒度嵌入不同),以捕獲其他輸入流(包括文本:
Y
Y
Y和說話者標簽:
s
s
s(《Style Tokens: Unsupervised Style Modeling, Control and Transfer in End-to-End Speech Synthesis》))未指定的殘留屬性,形式上,給定
D
T
T
S
D_{TTS}
DTTS?的訓練樣本
{
(
X
,
Y
,
s
)
}
\{(X, Y, s)\}
{(X,Y,s)},其中
X
X
X表示語音發音,訓練包括最小化以下
L
1
?
l
o
s
s
L1-loss
L1?loss:
L
G
S
T
=
∥
X
?
S
y
n
t
h
e
s
i
z
e
r
(
Y
,
s
,
R
e
f
E
n
c
(
X
)
)
∥
1
(1)
L_{GST}=\Vert X-Synthesizer(Y,s,RefEnc(X))\Vert_1 \tag{1}
LGST?=∥X?Synthesizer(Y,s,RefEnc(X))∥1?(1) 其中RefEnc函式由一個參考編碼器、一個樣式注意層和一組稱為GSTs的可訓練標識組成,具體來說,參考編碼器首先將參考語音作為輸入,并生成一個固定維的輸出向量,然后將其用作對注意層的查詢,以生成預定義GSTs之上的一組權重,最終的風格嵌入本質上是GSTs的加權和,并與TTS編碼器的隱藏狀態融合,
在推理程序中,原始GST-TTS要么需要參考語音,要么需要手動設定一組權重,在《Predicting Expressive Speaking Style from Text in End-To-End Speech Synthesis》中,為了單獨操作給定的文本輸入,提出了使用額外的TP模塊,該模塊以TTS編碼器的隱藏狀態作為輸入,以近似ground-truth風格權重或從目標語音中提取的風格嵌入,TP模塊的訓練目標可以將式1改寫為:
L
T
P
=
∥
X
?
S
y
n
t
h
e
s
i
z
e
r
(
Y
,
s
,
T
P
(
X
)
)
∥
1
(2)
L_{TP}=\Vert X-Synthesizer(Y,s,TP(X))\Vert_1 \tag{2}
LTP?=∥X?Synthesizer(Y,s,TP(X))∥1?(2) TP模塊可以通過一個停止梯度算子與GST-TTS聯合訓練,實驗結果表明,TP模塊能夠很好地反映訓練資料的變化,且僅使用文本輸入,
3.2 源韻律轉移
SPT最早在(《Transferring Source Style in Non-Parallel Voice Conversion》)中提出,并在后續作業中得到進一步利用(《Voice Conversion by Cascading Automatic Speech Recognition and Text-to-Speech Synthesis with Prosody Transfer》,《Submission from SRCB for Voice Conversion Challenge 2020》,《CASIA Voice Conversion System for the Voice Conversion Challenge 2020》,《Towards FineGrained Prosody Control for Voice Conversion》),SPT的訓練程序包括兩個階段:
1. 在
D
T
T
S
D_{TTS}
DTTS?上使用
L
G
S
T
L_{GST}
LGST?預訓練GST-TTS,如公式1所示,
2. 在
D
t
r
g
D_{trg}
Dtrg?上使用
L
G
S
T
L_{GST}
LGST?對GST-TTS進行微調,如公式1所示,
SPT的轉化程序可以表示為:
X
^
=
S
y
n
t
h
e
s
i
z
e
r
(
R
e
c
o
g
n
i
z
e
r
(
X
)
,
S
t
r
g
,
R
e
f
E
n
c
(
X
)
)
(3)
\hat{X}=Synthesizer(Recognizer(X),S_{trg},RefEnc(X)) \tag{3}
X^=Synthesizer(Recognizer(X),Strg?,RefEnc(X))(3) 比較方程1和方程3,可以發現RefEnc的輸入是不同的,訓練時使用目標說話人的講話,轉換時使用源說話人的講話,如第1節所討論的,如果RefEnc對目標說話人進行了過度微調,SPT可能會遇到說話人不匹配的問題,在微調程序中凍結RefEnc可能是一種補救措施,但正如我們將在實驗部分顯示的那樣,這并不能緩解問題,
3.3 目標文本預測
我們提出TTP來解決前面提到的次最優問題,TTP的訓練程序包括三個階段:
1. 對GST-TTS進行
D
T
T
S
D_{TTS}
DTTS?預訓練,
2. 使用
L
T
P
L_{TP}
LTP?在
D
T
T
S
D_{TTS}
DTTS?上預訓練TP,如公式2中所示,所有其他模型引數固定,注意,在此階段不再需要GST模塊,
3.使用
L
T
P
L_{TP}
LTP?在
D
t
r
g
D_{trg}
Dtrg?上微調TP和TTS,如公式2所示,
TTP的轉換程序可以表示為:
X
^
=
S
y
n
t
h
e
s
i
z
e
r
(
R
e
c
o
g
n
i
z
e
r
(
X
)
,
S
t
r
g
,
T
P
(
R
e
f
E
n
c
(
X
)
)
)
(4)
\hat{X}=Synthesizer(Recognizer(X),S_{trg},TP(RefEnc(X))) \tag{4}
X^=Synthesizer(Recognizer(X),Strg?,TP(RefEnc(X)))(4) 通過比較公式2和公式4可知,TP模塊使用
Y
Y
Y作為輸入,識別器保證了
Y
Y
Y與說話人無關,因此可以避免說話人失配,因此,正如我們將在實驗中展示的那樣,TTP比SPT更健壯,
4 實驗設定
4.1 資料
我們使用了VCC2020資料集(《Voice Conversion Challenge 2020 - Intra-lingual semi-parallel and cross-lingual voice conversion -》),在我們的評估中包含兩個任務,資料條件匯總于表1,這兩個任務都使用同樣的兩個源英語男性和女性說話者,他們的資料沒有被使用,在任務1中,說英語的有兩個目標群體,男性和女性,而在任務2中,說芬蘭語、德語和普通話的分別有一個男性和一個女性,在轉換程序中,原語說話人的聲音在保持語言內容不變的情況下,被轉換成目標語說話人的聲音,對于每個目標講話者,提供了70個各自語言和內容的話語,在任務1和任務2中分享了用于評價的25個測驗句子,

所有的識別器都使用LibriSpeech資料集(《LibriSpeech: An ASR corpus based on public domain audio books》)進行訓練,對于多語音TTS資料集,我們使用干凈子集LibriTTS資料集(《LibriTTS: A Corpus Derived from LibriSpeech for Text-to-Speech》),除了在基于文本的任務2系統中,我們合并了芬蘭語(《CSS10: A Collection of Single Speaker Speech Datasets for 10 Languages》)、德語(《The MAILABS speech dataset》)和漢語(《Chinese standard mandarin speech corpus》)的開源單語音TTS資料集,如(《The Sequence-to-Sequence Baseline for the Voice Conversion Challenge 2020: Cascading ASR and TTS》),對于每一個任務,使用源和目標說話人的訓練資料分別訓練一個單獨的神經聲碼器,
4.2 實作
該系統使用ESPnet實作,ESPnet是一個開發良好的開源端到端(E2E)語音處理工具包(《ESPnet: End-to-End Speech Processing Toolkit》,《Espnet-TTS: Unified, Reproducible, and Integratable Open Source End-toEnd Text-to-Speech Toolkit》),繼(《The Sequence-to-Sequence Baseline for the Voice Conversion Challenge 2020: Cascading ASR and TTS》)之后,基于文本系統的ASR模型是基于聯合CTC/attention loss(《Hybrid CTC/Attention Architecture for End-to-End Speech Recognition》)的Transformer(《Attention is All you Need》,《Speech-Transformer: A No-Recurrence Sequence-to-Sequence Model for Speech Recognition》,《Improving Transformer-Based End-to-End Speech Recognition with Connectionist Temporal Classification and Language Model Integration》),以及基于RNN的語言模型用于解碼,BNF提取的ASR模型基于TDNNF-HMM(《Semi-Orthogonal Low-Rank Matrix Factorization for Deep Neural Networks》),其中我們將40維MFCCs和400維i向量連接起來作為輸入,對于VQW2V,我們使用fairseq(《fairseq: A Fast, Extensible Toolkit for Sequence Modeling》)提供的公開可用的預訓練模型,如(《Any-to-One Sequence-to-Sequence Voice Conversion using SelfSupervised Discrete Speech Representations》),
所有合成器將它們各自的輸入映射到80維mel濾波器組,具有1024個FFT點和256點幀移(16毫秒),我們使用x向量(《X-vectors: Robust dnn embeddings for speaker recognition》)作為說話人的嵌入,我們使用Kaldi提供的預訓練模型,在推理程序中使用每個說話人訓練話語的所有x向量的平均值,離散輸入包括文本和VQW2V的合成器具有Transformer-TTS架構(《Neural Speech Synthesis with Transformer Network》),具有詳細設定(《The Sequence-to-Sequence Baseline for the Voice Conversion Challenge 2020: Cascading ASR and TTS》,《Any-to-One Sequence-to-Sequence Voice Conversion using SelfSupervised Discrete Speech Representations》),對于基于BNF的合成器,我們采用了Voice Transformer Network (VTN)(《Voice Transformer Network: Sequence-to-Sequence Voice Conversion Using Transformer with Text-to-Speech Pretraining》,《Pretraining Techniques for Sequence-to-Sequence Voice Conversion》),并遵循了官方的實作,對于神經聲碼器,我們采用Parallel WaveGAN (PWG)(《Parallel WaveGAN: A Fast Waveform Generation Model Based on Generative Adversarial Networks with Multi-Resolution Spectrogram》),并遵循開源實作,
5 實驗評估
5.1 客觀評價
我們進行了三種型別的客觀評價指標,從現成的ASR系統中得到的字符/單詞錯誤率(CER/WER)不僅是可理解性的估價值,而且在VC中也是一個強有力的質量指標,如(《Predictions of Subjective Ratings and Spoofing Assessments of Voice Conversion Challenge 2020 Submissions》)所示,我們的ASR引擎是基于Transformer(《Speech-Transformer: A No-Recurrence Sequence-to-Sequence Model for Speech Recognition》)和LibriSpeech訓練,報道了24維梅爾倒譜失真(MCD)和F0均方根誤差(F0RMSE)來評估譜失真和韻律轉換精度,其中兩項指標的計算都是基于WORLD聲碼器(《WORLD: A Vocoder-Based High-Quality Speech Synthesis System for Real-Time Applications》),請注意,在任務2中,只報告了CER/WER,因為無法訪問ground-truth語音,任務1和任務2的模型選擇分別基于MCD和CER,表現最好的模型生成樣本進行主觀測驗,
5.1.1 任務 1 的結果
表2顯示了任務1的客觀結果,在基于文本的系統中,引入韻律建模顯著改善了CER/WER,我們懷疑改進的韻律模式使ASR模型能夠輕松正確地識別內容,與SPT相比,TTP被證明更有效,因為它優于所有系統,但對于BNF和VQW2V等幀級特征,SPT和TTP的改進并不顯著,這一結果表明,細粒度表示已經攜帶了大量的韻律資訊,這些資訊在識別程序中并沒有被丟棄,因此GST無法對其進行正確的建模,
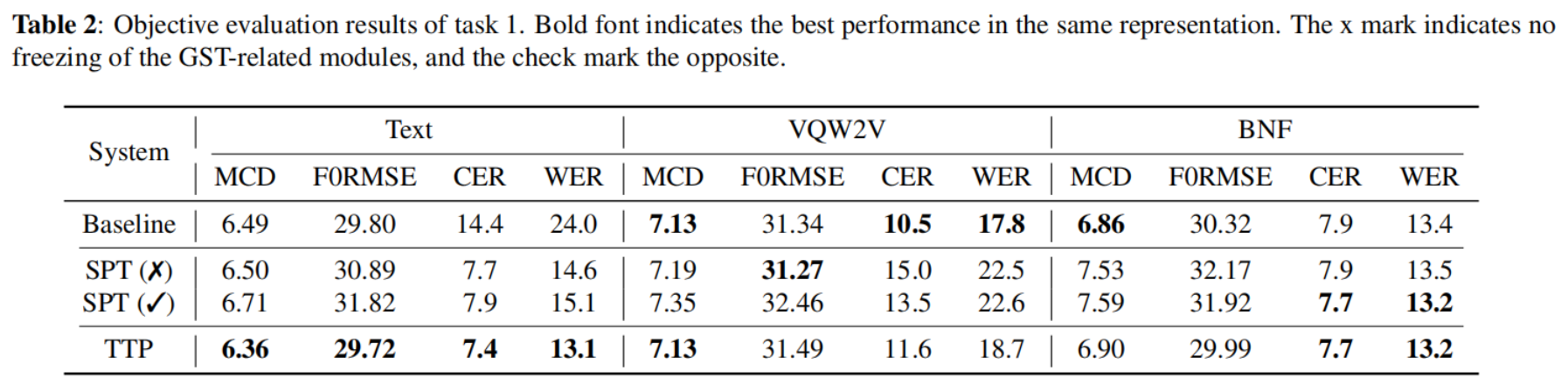
我們還發現,在微調期間凍結GST模塊會降低性能,一個可能的原因是,GST不僅捕獲韻律,還捕獲其他殘留屬性,如通道和噪聲,這種不匹配必須通過微調程序處理,最后,與未凍結的SPT相比,TTP的性能不斷優于所有表征,證明了其優越的有效性,
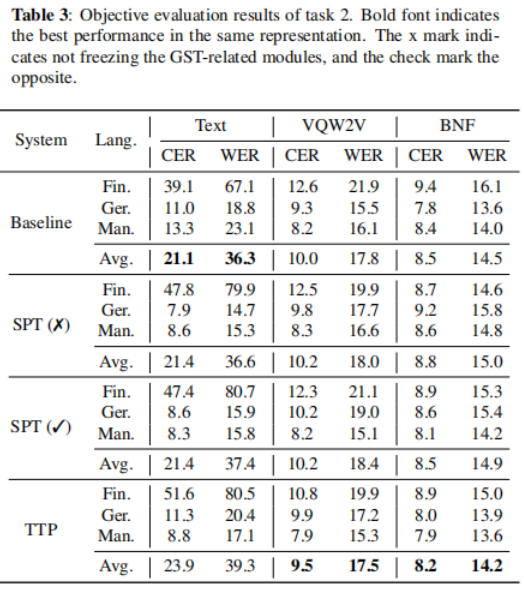
5.1.2 任務 2 的結果
表3顯示了任務2的客觀結果,首先,對于基于文本的系統而言,SPT提高了德語和漢語目標使用者的表現,TTP則有利于漢語目標使用者,通過聽幾個樣本,我們發現SPT和TTP都有助于模型插入適當的短停頓,這顯著提高了可理解性,另一方面,這兩種方法降低了說芬蘭語的人的成績;我們假設芬蘭語的文本預處理不當,使得聲學和韻律建模都很困難,在框架表征方面,我們認為SPT和TTP對可理解性影響不大,注意,在SPT中凍結GST不會像在任務1中那樣導致降級,
5.2 主觀評價
我們遵循《Voice Conversion Challenge 2020 - Intra-lingual semi-parallel and cross-lingual voice conversion -》中描述的主觀評價方法,從自然度和說話人相似度兩個方面進行評價,在自然程度方面,參與者被要求通過平均意見評分(MOS)測驗來評估演講的自然程度,對于轉換相似度,給每個聽者呈現一個自然目標演講和一個轉換后的演講,并要求他們在四分量表上判斷它們是否由同一個演講者產生,
對于每個系統,每個轉換對隨機選擇5個話語,在自然度測驗中,也包括目標說話人的錄音,并將其作為上限,在《Voice Conversion Challenge 2020 - Intra-lingual semi-parallel and cross-lingual voice conversion -》之后的任務2相似性測驗中,我們選擇了三段英語錄音和兩段L2語言錄音作為五個轉換話語的自然參考,所有的主觀評價都是使用開源工具包《An Open Source Implementation of ITU-T Recommendation P.808 with Validation》進行的,該工具包實作了ITU-T建議P.808(《Subjective evaluation of speech quality with a crowdsourcing approach》),用于在使用Amazon Mechanical Turk (Mturk)的人群中進行主觀語音質量評估,并對獲得的資料進行不可靠評級的篩選,我們從美國招募了100多名聽眾,并讓五名不同的參與者對每個樣本平均打分,請注意,為了降低成本,我們消除了在試聽測驗中凍結GST的SPT系統,因為與不凍結GST的系統相比,它們產生的性能較差,如5.1節所示,音頻樣本可以在網上找到,
5.2.1 自然度測驗
圖3顯示了自然度結果,我們首先關注任務1,對于基于文本的系統,與第5.1.1節的結果相反,SPT和TTP結果與基線具有可對比性,對于幀級特性,SPT在很大程度上降低了性能,而TTP可以彌補這種降低,但只是使其與基線持平,我們仍然可以得出結論,在任務1中,TTP優于SPT,但與基線相比沒有顯著改善,這些結果與《Voice Conversion by Cascading Automatic Speech Recognition and Text-to-Speech Synthesis with Prosody Transfer》的發現有些一致,
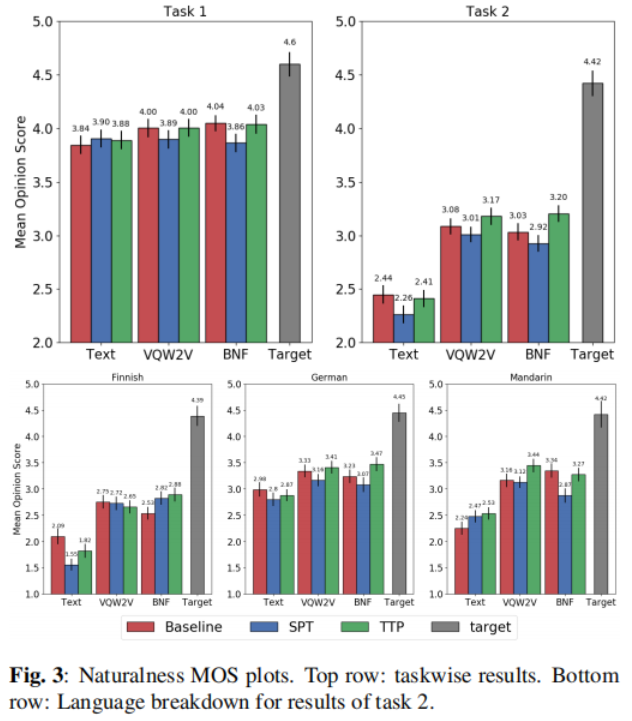
對于任務2,所有系統都顯示出SPT帶來的性能下降,在所有表示中,TTP的性能顯著優于SPT,對于基于幀級特征的系統,TTP甚至可以超過基線,也可以與基于文本的系統相媲美,為了研究這種差異,我們在圖3的底部圖中繪制了每種目標語言的分解,我們懷疑相對的性能變化再次與文本預處理相關,如第5.1.2節所述,在《The Sequence-to-Sequence Baseline for the Voice Conversion Challenge 2020: Cascading ASR and TTS》中,得益于開源社區,我們利用G2P工具將英語和普通話文本轉換成音素,從而得到了更好的聲學模型,TTP帶來了更大的改進,另一方面,由于缺乏語言知識,芬蘭語和德語中使用了漢字,與TTP結合使用時出現了退化現象,因此,如果正確處理輸入表征,TTP是提高任務2自然度的有效方法,
5.2.2 相似度測驗
圖4顯示了相似度結果,在任務1中,SPT和TTP在基于文本和基于VQW2V的系統中表現出了相當的性能,而SPT在基于BNF的系統中表現得明顯更差,對于任務2,所有三種表示都產生了相似的趨勢,因此任何韻律建模方法都無法區分明顯的性能增益,雖然人們普遍認為韻律與說話人的身份高度相關,但在此我們只能得出結論,韻律建模只是提高了自然度,
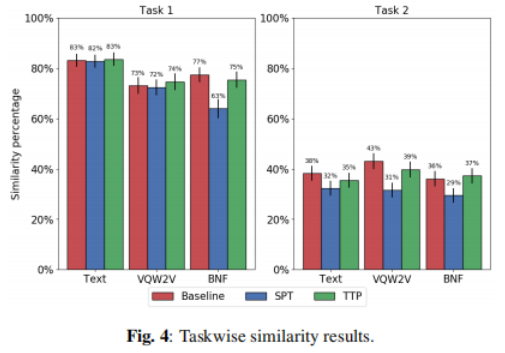
另一方面,在使用第二語言錄音作為參考講話的情況下,有必要想象目標說話人的英語聲音,以判斷與轉換后的講話的相似性,在這樣的主觀評價協議下,我們懷疑聽者只能依靠粗糙的韻律線索,如整體的音高水平和音色,而不受韻律建模技術的影響,
5.3 風格嵌入的可視化
我們使用在LibriTTS上預先訓練的不同表示(LibriTTS是3.2節中階段1的結果模型)來可視化GST-TTS模型的風格嵌入空間,我們輸入10個目標說話人的訓練話語,獲得風格嵌入,并通過t-SNE方法(《Parallel WaveGAN: A Fast Waveform Generation Model Based on Generative Adversarial Networks with Multi-Resolution Spectrogram》)進行降維可視化,作為參考,我們也把x向量形象化了,最后,我們根據每個目標演講者給點上色,結果圖如圖5所示,

首先,可以觀察到所有表示(文本、VQW2V和BNF)都以某種方式對說話者進行了聚集,一個可能的原因可能是韻律是依賴于說話人的(《Effective use of variational embedding capacity in expressive end-to-end speech synthesis》),我們也可以推斷,使用x向量來嵌入說話人并不能完全捕獲所有與說話人相關的變化,因此GST-TTS模型依賴于風格嵌入的幫助,這為使用說話人對抗性分類器提供了理由(《Voice Conversion by Cascading Automatic Speech Recognition and Text-to-Speech Synthesis with Prosody Transfer》,《Submission from SRCB for Voice Conversion Challenge 2020》),
我們進一步觀察到視覺聚類程度(說話人的點在一起的距離)從低到高依次為文本、VQW2V、BNF和x向量,我們認為,聚類程度反映了風格嵌入可以解釋的變異量,正如我們所知,文本包含的韻律資訊最少,我們可以推斷,由于框架級別的性質,VQW2V和BNF等表示已經包含了很多韻律資訊,因此樣式嵌入需要捕獲的內容已經不多了,盡管如此,從任務2中自然度的改善,如第5.2.1節所述,我們注意到韻律建模在捕獲殘留資訊方面仍然是有效的,
6 結論
本文研究了基于ASR+TTS的VC中兩種韻律建模方法:SPT和TTP,SPT在VCC2020中已經被幾個頂級系統應用,而TTP在本作業中是新提出的,其動機是防止SPT中培訓和轉換之間的不匹配,我們在VCC2020基準上進行了實驗,考慮了三種中間表示:文本、BNF和VQW2V,結果表明,TTP始終優于SPT,并能在適當的輸入表征下優于基線,最后,通過對不同表示學習的風格嵌入的可視化,揭示了SPT和TTP帶來的有限改進,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/291959.html
標籤:其他