[TensorFlow]Embedding Layer 和 Globalaveragepooling1d Layer原理及作用
- 前言
- GlobalAveragePooling1D 的作用和原理
- Embedding 的作用
- Embedding 的原理
前言
序列模型主要針對文字,音樂,語言等這種背景關系關系比較強的輸入資料進行分類、預測作業,但是這類資料有一個很值得關注的問題:不同的元素之間并不是孤立的,而是存在復雜關系的,比如,“我很好”,"我很棒"中,"棒"和"好"可能是意義相近的,再比如,主語之后一般會加謂語,這是一種背景關系的關系,"一般會"表示兩者關系接近,所以,如果在模型進行訓練之前,將意義接近或者關系緊密的詞進行再整理,將會極大方便模型進行訓練和學習,為了達到這樣的效果,Embedding Layer 和 Globalaveragepooling1d Layer 被加入到了TF的常用組件中,
GlobalAveragePooling1D 的作用和原理
首先Pooling的意義就是把不同的維度的資料整合成一個資料,根據整合的方法不同,有不同型別的Pooling演算法,如:
AveragePooling
[
x
1
,
x
2
,
x
3
]
?
[
y
1
=
1
3
∑
3
x
i
]
[x_{1},x_{2},x_{3}] \longrightarrow [y_{1}=\frac{1}{3}\sum^{3}x_{i}]
[x1?,x2?,x3?]?[y1?=31?∑3?xi?]
MaxPooling
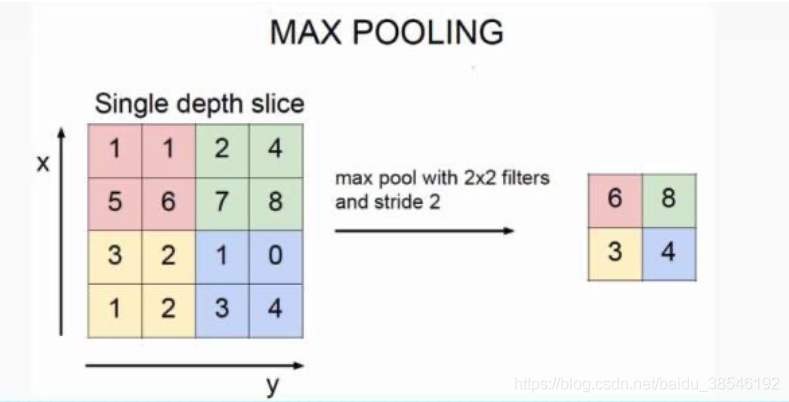
該圖參考了知乎高分回答,作者@G-kdom
在該圖中,左邊的圖片被分成了四部分,每一部分取最大值,重新組成一個新的規模更小的二維陣列,這樣可以突出圖片的關鍵特征,并降低資料規模,減少模型訓練難度,
綜上,GlobalAveragePooling1D 的作用就是對向量化的輸入資料進行池化,來降低訓練難度,
Embedding 的作用
簡單說就是將輸入的資料向量化,并計算不同的向量之間的coefficient,然后通過引數迭代使關系緊密的詞匯向量靠在一起,實作一種聚類,
Embedding 的原理
其實Embedding的原理展開細說也沒有什么必要,但是這里會簡單說一下它的作業原理和學習程序,
Youtube博主 @TechwithTim 分享了自己的觀點我認為很好理解,所以在這里我主要總結一下Tim的觀點,
在此之前,先來理解Embedding將要收到的資料是什么樣子,
對于序列化輸入資料來說,有幾個關鍵的元素:單元(unit)、句長(Sequence)、包(batch),這里因為中文翻譯的問題,有些說法可能不一致,但是重要的是理解其作用,單元是輸入資料語料庫中的最小單位,如文字中的詞匯(vocabulary),樂譜中的音符(notations),句長是每次輸入到模型中的資料是由多少個單位組成的,關于如何組合句子,可以參考實體:XXX,(好吧,其實這個實體我還沒寫完,以后會更新的哈哈哈)包是指對總體樣本進行的隨機抽樣,由于資料的樣本規模大,每次都窮盡所有資料進行訓練效率太低,但是如果分部分進行訓練,無法得到總體的分布,所以,一種折中的方法就是,每次隨機提取資料中的一部分資料,保證每一個抽樣樣本獨立同分布,進行多次快速迭代,也就是minibatch方法,
所以序列模型的資料預處理一般是:
當資料到達embedding的時候,每一個資料是一個一維的由整型數構成的陣列,定義embedding的兩個重要的引數:語料庫規模,詞匯向量化維度:
emb_layer = tf.keras.layers.Embedding(vocal_size, dim_num)
然后句子中每一個詞會被分解成dim_num個維度的向量,如
I
h
a
v
e
a
p
e
n
?
[
a
1
?
,
a
2
?
,
a
3
?
,
a
4
?
]
I have a pen\longrightarrow [\vec{a_1},\vec{a_2} ,\vec{a_3} ,\vec{a_4} ]
Ihaveapen?[a1?
?,a2?
?,a3?
?,a4?
?]
其中
a
1
?
=
[
x
1
,
x
2
,
.
.
.
x
i
]
,
i
?
d
i
m
_
n
u
m
\vec{a_1}=[x_1,x_2,...x_i],i\Leftarrow dim\_num
a1?
?=[x1?,x2?,...xi?],i?dim_num
如果給向量中各個維度加入可以被優化的引數,那么
a
1
?
\vec{a_1}
a1?
?就可以被表示為:
a
1
?
^
=
a
1
?
?
w
1
?
=
[
w
1
x
1
,
w
2
x
2
.
.
.
w
i
x
i
]
\hat{\vec{a_1}}=\vec{a_1}\bigodot \vec{w_1} =[w_1 x_1, w_2 x_2...w_ix_i]
a1?
?^?=a1?
??w1?
?=[w1?x1?,w2?x2?...wi?xi?]
之后這樣的新向量
a
1
?
^
\hat{\vec{a_1}}
a1?
?^?會被作為輸出進入到GlobalAveragePooling1d Layer進行池化,而根據上文提到的GAPL(省事兒寫的縮寫)的原理,可以將資料變成一維的新輸出,其實就是把
a
1
?
^
\hat{\vec{a_1}}
a1?
?^?各個維度數字加總平均了:
b
=
1
n
∑
i
=
1
n
w
i
x
i
=
1
n
W
X
b=\frac{1}{n}\sum^{n}_{i=1}w_ix_i=\frac{1}{n}WX
b=n1?i=1∑n?wi?xi?=n1?WX
等會,是不是和深度學習啟蒙BP的 線性結構一樣?確實除了平均和偏置,其余是一樣的,這樣就構成點到點的線性結構,就能夠通過梯度下降來學習優化引數了(Ohhhhhhhhh!)
那么資料未進入模型之前就已經先上了學前班,在向量空間里找到了相似關系,進入模型后學習效果就會好很多,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/292297.html
標籤:AI