深度學習
(deep learning)系列 筆記

優化通俗來講其實是求函式的最大值最小值問題,而最大值問題又可以轉化為求最小值問題,因此,優化往往聚焦于最小化某個函式的值,
我們借助于導數這個工具,用到函式的極限與連續的基本知識,我們可以得到,對一個足夠小的,下面的式子恒成立(具體分析用到數學知識)
![]()
( sign(x)或者Sign(x)叫做符號函式,在數學和計算機運算中,其功能是取某個數的符號(正或負):
當x>0,sign(x)=1;
當x=0,sign(x)=0;
當x<0, sign(x)=-1;)
因此我們受到啟發,通過更改x的大小,來實作改善y目標函式的值,即梯度下降法,
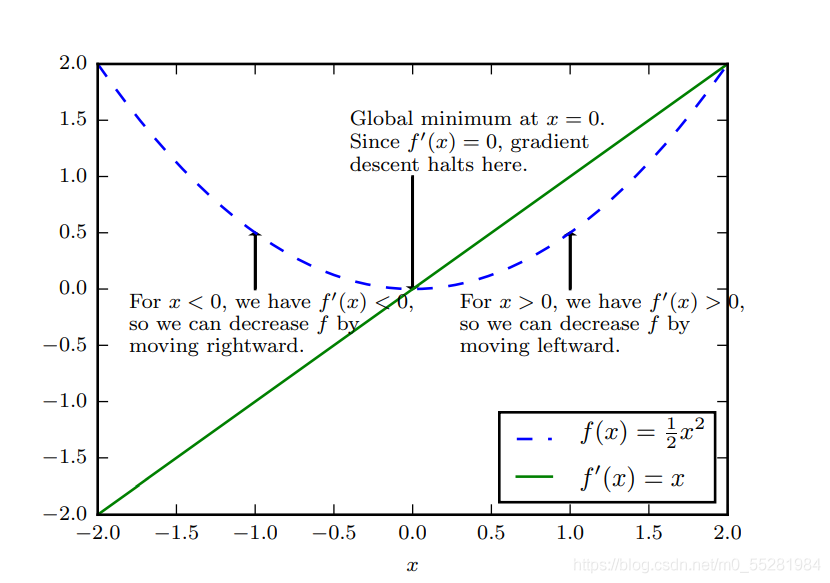
簡單來講,沿著函式的下降方向移動,尋求全域最小點,
我們不可避免地會遇到的問題是,在數學上我們叫極值與最值的問題,在深度學習領域,尤其是在對目標函式進行優化時,我們往往要面對全域最小點無法實作,此時,我們采取區域最小化的辦法,只要能達到一個相對較低的水平,我們也可以采用區域最小值來代替全域最小值,
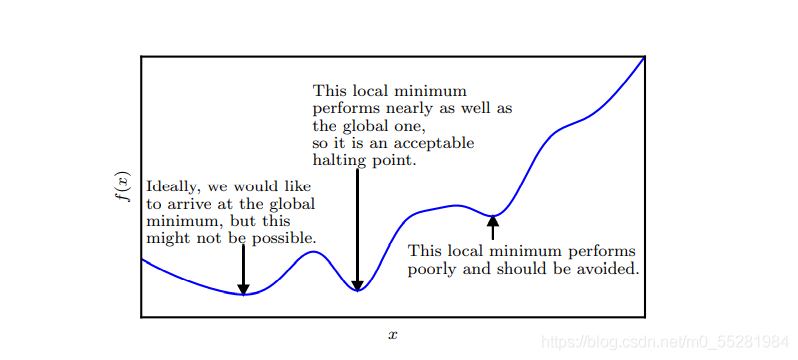
在應對多維的輸入時,問題會變得更加有趣,
此時的輸入為一個n維向量,梯度相應的變為對向量的求導,得到的也是一個向量,我們用上文討論的一維梯度下降中的思路,考慮方向導數,這里囿于公式編輯的問題,我直接摘錄了書中的原話,我認為已經闡述的非常清晰,

其中會用到標量對多矩陣的鏈式求導,(這里參考某位大佬的一篇博文)
具體地址

有了這個公式,上面的推導就一目了然了,
注意我們討論的都是在連續空間中,在離散空間中的操作成為爬山,感興趣可以自行搜索,等我學了離散數學再來寫,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/292299.html
標籤:AI