強化學習
強化學習入門這一篇就夠了萬字長文帶你明明白白學習強化學習...強化學習入門這一篇就夠了
- 強化學習
- 前言
- 一、概率統計知識回顧
- 1.1 隨機變數和觀測值
- 1.2 概率密度函式
- 1.3 期望
- 1.4 隨機抽樣
- 二、強化學習的專業術語
- 2.1 State and action
- 2.2 policy-策略
- 2.3 reward
- 2.4 狀態轉移
- 2.5 agent與環境互動
- 三、強化學習的隨機性
- 3.1 動作隨機
- 3.2 狀態轉移的隨機性
- 四、如何讓AI自動打游戲?
- 五、強化學習基本概念
- 5.1 Return
- 5.2 價值函式
- 5.3 Q~π~
- 5.4 State-value function-狀態價值函式
- 六、兩種價值函式
- 6.1 動作價值函式
- 6.2 狀態價值函式V~π~
- 七、強化學習如何打游戲
- 7.1 OpenAI Gym
- 總結
前言
學習強化學習,需要懂一些關于概率統計的知識,還要注意的就是基本概念的理解和記憶, 說明一下:這是我的一個學習筆記,課程鏈接如下:最易懂的強化學習課程
公眾號:AI那些事

一、概率統計知識回顧
1.1 隨機變數和觀測值
??隨機變數:它是一個未知的量,它的值取決于一個隨機事件的結果,
??例如:我拋一個硬幣,正面朝上為0,反面朝上記為1.拋硬幣是一個隨機事件,拋硬幣的結果就記為隨機變數X,隨機變數有兩種取值,有可能為0,也有可能為1,拋硬幣之前我是不知道X是什么的,但是我知道這個隨機事件的概率,P(X=0)=0.5,P(X=1)=0.5,
??通常我們使用小寫字母表示觀測值,概率統計中普遍使用大小寫來區分隨機變數和它的觀測值,
??上面說到觀測值?那么觀測值是什么意思呢?當隨機事件結束,會觀測到硬幣的哪一面朝上,這個觀測值就記為字母x,x只是一個數而已沒有隨機性,舉個例子我扔了4次硬幣就得到了4個觀測值,如下圖:x1=1,x2=1,x3=0,x4=1,

1.2 概率密度函式
下面我們講一下概率密度函式:
??首先我們要了解概率密度函式物理意義:它意味著隨機變數在某個確定的取值點附近的可能性,這聽起來有點繞,我們來看一個例子:
??我們用高斯分布來進行舉例說明:
??高斯分布,也叫正態分布,是一個連續的概率分布,隨機變數的取值X可以使任何一個實數,高斯分布的概率密度函式為:
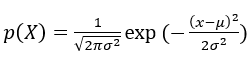
??這里面μ是均值,σ是標準差, 下圖坐標系中的橫軸為隨機變數的取值,縱軸為概率密度,其中的曲線為高斯分布的概率密度函式p(X),這個概率密度說明X在原點附近取值的概率比較大,遠離原點的地方取值的概率比較小,

??下圖為:離散的概率分布,隨機變數只能取{1,3,7}這幾個值,如圖右下角,X=1時的概率為0.2,X=3的概率為0.5,X=7的概率為0.3,其它任何地方概率都為0,

??概率密度函式有這樣的性質,把隨機變數的定義域記作χ,如果p是個連續的概率分布,可以對p(X)做定積分,把所有X的取值都演算法定積分得到的值為1,如果p是個離散的概率分布呢,隨機變數在離散的χ取值,可以對p(x)做一個加和,把所有可能的取值都算上,結果等于1,這就是概率密度函式的基本性質,把所有可能的取值都算上,概率的積分和加和會等于1,

1.3 期望
接下來我們來了解一些期望是怎么定義的,這分為兩種情況:
??對于連續分布,函式f(x)的期望是這樣定義的對p(x)和f(x)的乘積做定積分,這樣就得到了f(x)的期望,這里的p(x)是概率密度函式,
??對于離散分布,期望是用連加進行定義的,對p(x)和f(x)的乘積進行連加,這樣就得到f(x)的期望,

1.4 隨機抽樣
??對于隨機抽樣,我舉個例子,箱子里面有10個球2個紅色,5個綠色,3個藍色,我現在把箱子搖一搖,把手伸進箱子里,閉著眼睛摸出來一個球,這個球是什么顏色的呢?
??三種球都有可能被我摸到,摸到紅色概率為0.2,摸到綠色的為0.5,摸到藍色為0.3,在我摸之前,摸到的顏色就是隨機變數X,現在我摸出來一個球,我睜開眼睛看到球是紅色的,紅色就是觀測值x,這個程序就稱為隨機抽樣,
??我從箱子里面摸出來一個球,并且觀測到它的顏色,這樣一次隨機抽樣就完成了,

??現在我換一種問法,箱子里面有很多個球,但我也不知道多少個,我現在做隨機抽樣,抽到紅色球的概率為0.2,綠色球的概率為0.5,藍色為0.3,我現在把手伸進箱子里摸一個球,摸到球是什么顏色的呢?這個問題其實和剛才的問題是一樣的,所以應該和剛才有一樣的答案,三種球都有可能被摸到,如果我只摸一次,什么球都可能被摸到,
??假如我現在摸出來一個球,記錄它的顏色,然后放回去,然后把箱子使勁搖,把球打散,然后重新摸一次,我重復這個程序100次,那我記錄下來的顏色有什么特點呢,由于記錄了100次具有統計意義了,大約20次是紅色,50次是綠色,30次是藍色,用0.2,0.3,0.5的概率來抽一個彩球,就是Random Sampling-隨機抽樣,
??如下圖,用python語言當中的numpy.random包里面的choice函式就能做這種抽樣,

二、強化學習的專業術語
2.1 State and action
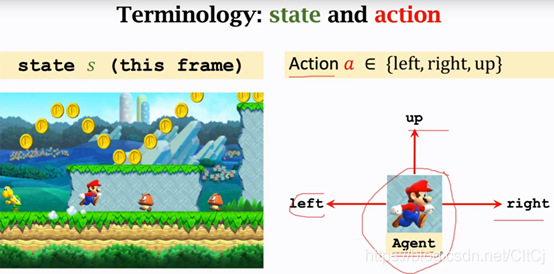
??State可以理解成狀態(環境狀態),當我們在玩超級瑪麗我們可以認為當前的狀態就是下圖中,超級瑪麗游戲的畫面,當然這樣說不太嚴謹,我們觀測的observation和state未必是相同的東西,為了方便我們理解,我們認為這張圖片就是當前的狀態,我們玩超級瑪麗的時候觀測到螢屏上的狀態,就可以操縱馬里奧做出相應的動作,馬里奧做的動作就是action,假設馬里奧會做三個動作,向左走、向右走和向上跳,這個例子里面馬里奧就是agent,如果在自動駕駛的領域中汽車就是agent,總之在一個應用里面動作是誰做的誰就是agent,agent通常被翻譯為智能體,
2.2 policy-策略
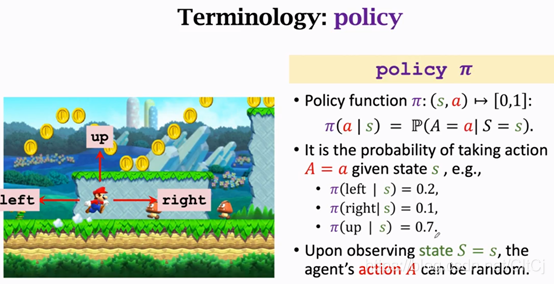
??下面一個概念policy記為 π函式,policy是什么意思呢就是我們觀測到螢屏上這個畫面的時候,你該讓馬里奧做什么樣的action呢,是往上還是左還是右,policy的意思就是根據觀測到的狀態來進行決策,來控制agent運動,
??在數學上policy函式π是這樣定義的,這個policy函式π是個概率密度函式:
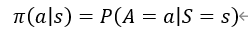
??這個公式的意思就是給定狀態s做出動作a的概率密度,
??我舉個例子,觀測到馬里奧這張圖片agent(馬里奧)會做出三種動作中的一種,把這張圖片輸入到policy函式π它會告訴我向左的概率為0.2,向右的概率為0.1,向上跳的概率為0.7,如果你讓這個policy函式自動操作它就會做一個隨機抽樣,以0.2的概率向左走,0.1的概率向右走,0.2的概率向上跳,三種動作都有可能發生,但是向上跳的概率最大,向左的概率較小,向右的概率更小,強化學習學什么呢就是學這個policy函式只要有了這個policy函式,就可以讓它自動操作馬里奧打游戲了,我舉的這個例子里agent的動作是隨機的,根據policy函式輸出的概率來做動作,當然也有確定的policy,那樣的話動作就是確定的,為什么讓agent動作隨機呢,超級瑪麗這個游戲里面馬里奧的動作不管是隨機還是確定都還沒有問題都可以,但如果是和人博弈最好還是要隨機,要是你的動作很確定別人就有辦法贏,我們來想想剪刀石頭布的例子,要是你出拳的策略是固定的那就有規律可循了,你的對手就能猜出你下一步要做什么,你很定會輸,只有讓你的策略隨機,別人無法猜測你的下一步動作,你就會贏,所以很多應用里面policy是一個概率密度,最好是隨機抽樣得到的要有隨機性,
2.3 reward
下一個知識點是獎勵reward:
??Agent做出一個動作,游戲就會給一個獎勵,這個獎勵通常需要我們來定義,獎勵定義的好壞非常容易影響強化學習的結果,如何定義獎勵就見人見智了,我舉個例子:
??馬里奧吃到一個金幣獎勵R=+1,如果贏了這場游戲獎勵R=+10000,我們應該把打贏游戲的獎勵定義的大一些,這樣才能激勵學到的policy打贏游戲而不是一味的吃金幣,如果馬里奧碰到敵人Goomba,馬里奧就會死,游戲結束,這時獎勵就設為R=-10000,如果這一步什么也沒發生,獎勵就是R=0,強化學習的目標就是使獲得的獎勵總和盡量要高,

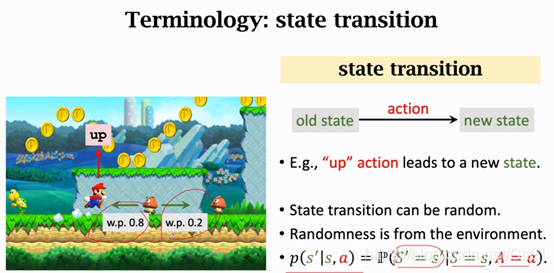
2.4 狀態轉移
??當前狀態下,馬里奧做一個動作,游戲就會給出一個新的狀態,比如馬里奧跳一下,螢屏上下一個畫面就不一樣了,也就是狀態變了,這個程序就叫做State transition(狀態轉移)狀態轉移可以是固定的也可以是隨機的,通常我們認為狀態轉移是隨機的,如果你學過馬爾科夫鏈狀態轉移的隨機性應該很容易理解,狀態轉移的隨機性是從環境里來的,環境是什么呢?在這里環境就是游戲的程式,游戲程式決定下一個狀態是什么,我舉個例子來說明狀態轉移的隨機性,
??如果馬里奧向上跳,馬里奧就到上面去了,這個地方是確定的,而敵人Goomba可能往左,也可能往右,Goomba的狀態是隨機的這也造成下一狀態的隨機性,可以將狀態轉移用p函式來表示:
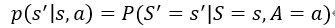
??這是一個條件概率密度函式,意思是如果觀測到當前的狀態s以及動作a,p函式輸出s’的概率,我舉的這個例子里,馬里奧跳到上面,Goomba往左的概率為0.8,往右為0.2,但是我們不知道這個狀態轉移函式,我知道Goomba可能往左也可能往右,但是我不確定它往左或者往右的概率有多大,這個概率轉移函式只有環境自己知道,我們玩家是不知道的,
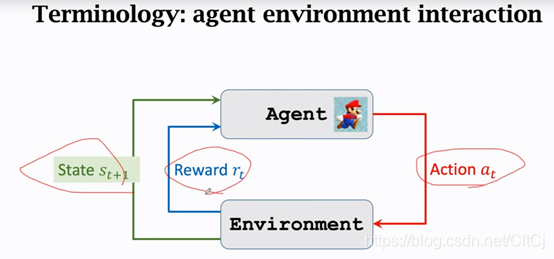
2.5 agent與環境互動
??最基本的概念講的差不多了,我們來看一下agent和環境是怎么進行互動的,agent是馬里奧,狀態St是環境告訴我們的,在超級瑪麗的例子里面,我們可以把當前螢屏上顯示的圖片看做狀態St,agent看到狀態St之后要做出一個動作at,動作可以是向左走、向右走和向上跳,agent做出動作at之后環境會更新狀態St+1,同時環境還會給agent一個獎勵rt,
要是吃到金幣獎勵是正的,要是贏了游戲獎勵就是一個很大的正數,要是馬里奧over了獎勵就是一個很大的負數,
三、強化學習的隨機性
??我們來看一下強化學習的隨機性,搞明白隨機性的兩個來源,對之后的學習很有幫助,
3.1 動作隨機
??第一個隨機性是根據動作來的,因為動作函式是根據policy函式π隨機抽樣得到的,我們用policy函式來控制agent,給定當前狀態 S, agent的動作A是按照policy函式輸出的概率來隨機抽樣,比如當前觀測到的狀態s,policy函式會告訴我們每個動作的概率有多大,agent有可能做其所存在的任何一種動作(向左,右,上)但這些動作的概率有大有小,

3.2 狀態轉移的隨機性
??另外一個隨機性是狀態轉移,假定agent做出了向上跳的動作,環境就要生成下一個狀態S’,這個狀態S’具有隨機性,環境用狀態轉移函式p算出概率,然后用隨機抽樣得到下一個狀態S^’,比如說下一個狀態有兩種可能,根據狀態轉移函式的計算,一種狀態的概率是0.8,另外一種狀態的概率是0.2,這兩個都有可能成為下一種狀態,系統會做一個隨機抽樣來決定下一個狀態是什么,
??概括一下,強化學習中有兩種隨機性的來源,一種來源是agent的動作,,因為動作函式是根據policy函式π隨機抽樣得到的,另一種來源是狀態轉移,下一個狀態是環境跟狀態轉移函式p來隨機抽樣的,

四、如何讓AI自動打游戲?
??怎么讓AI自動打贏游戲呢?
??我們通過強化學習學出policy函式π,我之后會講怎么樣學習policy函式,AI就是用policy函式來控制agent的,觀測到游戲當前這一幀的狀態s1,AI用policy函式來計算概率,然后隨機抽樣得到動作a1,然后環境會生成下一狀態s2,并且給agent一個獎勵r1,再然后AI就會拿新的狀態作為輸入,用policy函式來算概率然后隨機抽樣得到新的動作a2,這樣一直回圈下去直到打贏游戲或者game over,這樣我們就會得到一個游戲的trajectory(軌跡),這個軌跡是每一步的狀態,動作,獎勵,

??接下來我要講幾個很重要的概念,reward、return、,后面的課要反復使用這幾個概念,我們需要記住,對于初學者來說這幾個概念非常容易混淆,所以我們需要理解記憶,
五、強化學習基本概念
5.1 Return
??Return翻譯為回報,Return的另一個名字是cumulative future reward(未來的累計獎勵),我們把t時刻的return叫做Ut,return這樣定義的把t時刻的獎勵全都累計加起來,一直加到游戲結束時的最后一個獎勵,
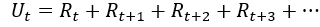
??這里,我問一個問題,你們覺得獎勵R_t和+R_(t+1)同樣重要嗎?
??假如,我給你兩個選項:
??1、 我立刻給你100塊錢和我一年后我給你100塊錢,你會選擇哪一個?
??理性的人應該都會選擇現在立刻得到100塊錢,這是因為未來的不確定性很大,即使我現在答應給你明年給你100,你也未必拿得到,大家都明白這個道理,明年得到這100塊錢不如現在立刻得到這100塊錢,
??2、 是我換一個問題,現在我立刻給你80塊錢,和我明年給你100塊錢,你會選擇哪一個,或許大家會做不同的選擇,有人選擇前者,有人選擇后者,
??所以呢,未來的獎勵100不如現在的100好,未來的100恐怕只值現在的80,因此我該給未來的獎勵打一個折扣,比如打一個8折,未來Rt+1的權重要比Rt低才可以,由于未來的獎勵不如現在的獎勵值錢,所以強化學習中常使用Discounted return(折扣回報),把折扣率記作𝛾,這個值要介于0和1之間,如果未來和現在的權重一樣那么γ=1要是未來的獎勵不重要γ就比較小,這就是折扣回報的定義:當前的獎勵Rt沒有折扣,下一時刻Rt+1的折扣率是𝛾,依次類推,折扣率是一個超引數需要我們自己來調,折扣率的設定對強化學習有一定的影響,

??我們來看一下return Ut的隨機性,假如游戲已經結束了,所有的獎勵都觀測到了,那么獎勵就是數值用小寫字母表示,如果在t時刻游戲還沒有結束,這些獎勵還是隨機變數,還沒有被觀測到,我們就用大寫字母R來表示獎勵,由于return Ut依賴于獎勵R所以return Ut也是一個隨機變數,也用大寫字母表示,隨機變數有兩個來源:
??第一個是動作A,我們回憶一下,policy函式π,用狀態S作為輸入,輸出一個正概率分布,動作a就是從這個隨機抽樣中得到的,
??第二個隨機性的來源的狀態轉移-下一個狀態,給定了當前的狀態s和動作a下一個狀態s’是隨機的,這個狀態轉移函式p輸出一個概率分布,環境從這個概率分布中隨機抽樣得到新的狀態s’,
??對于任意的未來時刻i獎勵Ri,會取決于狀態Si和動作Ai
??這是為什么呢?我們想一下超級瑪麗游戲,當前馬里奧處在一個狀態,馬里奧做什么動作就決定了獎勵是什么,馬里奧往上跳得到金幣就得到一個正的獎勵,馬里奧往右走碰到了敵人掛掉了就得到一個很大的負的獎勵,所以得到什么獎勵和現在的狀態和動作有關,我們回顧一下一下return的定義:
??剛才說了,每一個獎勵Ri,都和狀態Si和動作Ai有關,那么Ut就跟t時刻開始未來所有的狀態和動作都有關,return Ut的隨機性就是和未來所有的狀態和動作有關,
??假設我們觀測到狀態St,那么return Ut 就依賴于這些隨機變數未來的動作和狀態,

5.2 價值函式
??我們剛才定義了折扣回報Ut是未來獎勵的總和,當要打個折扣,越久遠的未來折扣越大,權重越低,為什么我們要定義return Ut呢,Ut非常有用,Ut是未來獎勵的總和,所以agent就是讓Ut盡量大,越大越好,除此之外,我從知道的Ut我就知道是快贏了還是快數輸了,其實我是逗你玩的,(臥槽!!!)
??其實Ut只是個隨機變數,在t時刻你并不知道Ut是什么,打個比方你拋硬幣,正面記為1,反面為0,在t時刻你還沒有將硬幣拋出去,你并不知道你是得到1還是0,
??Ut是一個隨機變數,它依賴所有的動作和狀態,由于Ut是一個隨機變數,在t時刻我并不知道Ut是什么,那我該如何去評估當前的形式呢?
??我們可以對Ut求期望,把里面的隨機性都積掉,得到的就是個實數,打個比方雖然在拋硬幣之前你并不知道會得到什么,但你知道正反面各有一半的概率,如果正面記作1反面為0得到的期望就是0.5,同樣得到了對隨機變數Ut求期望會得到一個數記作Qπ,這個期望是怎么求的呢,把期望Ut當中未來所有的狀態S和所有的動作A的一個函式,未來的動作A和狀態S都有隨機性,動作A的概率密度函式是policy函式π(a|s),狀態S的概率密度函式是狀態轉移函式p(s’ |s,a),期望就是對未來的動作和狀態求的,把這些隨機變數都用積分積掉除了St和At其余的隨機變數都被積掉了,被積掉的隨機變數是A(t+1),A(t+2)…等動作和S(t+1),S(t+2)…等狀態,求期望函式得到的Qπ稱為Action-value function(動作價值函式),Qπ和當前的狀態和動作(St和At)有關,為什么呢?因為其余的動作和價值都被積掉了,但是St和At沒有被積掉,St和At被作為觀測到的數值來對待,而不是作為隨機變數,
??Qπ的值依賴于St和At,函式Qπ還和policy函式π有關,為什么呢?因為積分的時候會用到policy函式,如果policy函式不一樣,積分得到的函式Qπ就不一樣,
5.3 Qπ
??動作價值函式Qπ有什么直觀意義呢?函式Qπ告訴我們如果用policy函式π,那么在t時刻這個狀態St下做at這個動作是好還是壞,已知policy函式π,Qπ就會給當前狀態下所有的動作進行打分,然后我們就知道哪個動作好,哪個動作不好,

??剛才我們講了動作價值函式Qπ和policy函式π有關,用不同policy函式就會得到不同Qπ,怎么樣把動作價值函式中的π去掉呢,可以對π關于Qπ求最大化,意思就是我們有無數種policy函式π,但是我們應該使用最好的那一種函式,最好的policy函式是什么呢?就是讓Qπ最大化的那個π,我們把得到的函式Q* 稱為Optimal action-value function(最優動作價值函式),Q和policy函式π無關因為π已經被這個最大化max去掉了,
??Q 有什么意義呢,它可以對動作a做評價,如果當前的狀態是st,這個Q* 函式就會告訴我們這個動作at好不好,比如下圍棋的時候狀態就是這個棋盤,Q* 函式就會告訴我們了,如果你把棋子放在這個位置你的勝算有多大,如果把棋子放在別的位置你的勝算有多大,Q* 函式非常有用,假如有了Q* ,agent就能根據Q* 對動作的評價來做決策了,觀測到一個狀態,如果Q* 認為往上跳這個動作的分數最高,agent就應該往上跳,總之Q* 認為哪個動作的分數最高,agent就怎么動,

Note:強化學習里面概念比較多,沒有捷徑,我們只有理解然后記住,接下來介紹狀態價值函式,
5.4 State-value function-狀態價值函式
狀態價值函式:
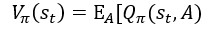
??Vπ是動作價值函式Qπ的期望,Qπ和policy函式π,狀態St,動作At有關,可以把這里的動作A作為隨機變數,然后關于A求期望把A消掉,求期望得到的Vπ只和π和s有關,
函式Vπ有什么直觀的意義呢?它能告訴我們當前的局勢好不好,
??假如我來根據policy函式π來下圍棋,讓Vπ看一下棋盤,它就會告訴我,當前我的勝算有多大,是快贏了快輸了還是和對手不分高下,這里的期望都是根據隨機變數A來求的,A的概率密度函式是π,根據期望的定義能夠把期望寫成連加或積分的形式,
??如果動作都是離散的,比如上下左右,這樣就能把期望寫成連加,把π和Q的乘積做連加把所有的動作a都算上,
??如果動作是連續的那么就可以把期望寫成積分形式,期望等于π和Q的乘積做積分把a積掉,
六、兩種價值函式
總結一下,主要有兩種價值函式value-function:
6.1 動作價值函式
??一種是動作價值函式,它主要和policy函式π有關,和狀態s和動作a有關,它是Ut的條件期望,這里的Ut是個隨機變數,它等于未來所有獎勵的加權求和,期望把未來的動作和狀態都消除了,只留下St和At這兩個變數,
??函式Qπ能告訴我們什么資訊呢?如果使用policy函式π,那么Qπ說明agent處在狀態s時做出動作a是否明智,Qπ可以給動作a打分,

6.2 狀態價值函式Vπ
??我們還定義了狀態價值函式Vπ,Vπ是把Qπ中的變數A用積分去掉,這樣變數就只剩下狀態s,Vπ跟policy函式π和狀態s有關和動作a無關,
??如果使用policy函式π,那么Vπ能夠評價當前狀況是好是壞,我們是快贏了還是其它,如果π是固定的那么狀態s越好Vπ的數值就越大,Vπ還能評價policy函式π的好壞,如果π越好,那么Vπ的平均值就越大,

七、強化學習如何打游戲
??如果我們玩超級瑪麗,那么我們的目標是什么呢?我們的目標就是操作馬里奧多吃金幣,避開敵人,向前走,打贏每一關,我們想寫個程式用AI來控制agent,我們應該怎么做呢?
??一種辦法是學習policy函式π,這在強化學習里面叫做policy-based learning 基于策略的學習,我后面會講,假如我們有了policy函式π,我們就可以用π函式控制agent做動作了,每觀測到一個狀態st就將st作為π函式的輸入,π函式會輸出每一個動作的概率,然后用這些概率做隨機抽樣得到at,最后agent執行這個動作at,AI就是用這種方式控制agent打游戲的,

??另外一種方法是optimal action-value function(最優動作-價值函式)Q* ,這在強化學習里面稱為value-based learning 價值學習,我們將在下一章講,假如我們有了Q* agent就能根據Q* 函式來做動作了,Q* 函式告訴我們如果處在狀態s,那么做動作a是好還是壞,每觀測到一個狀態st就將這個狀態st作為Q* 函式的輸入,讓Q* 函式對每一個動作進行評價,這樣我們就知道向左、向右、向上每一個動作的Q值,假如向上跳的Q值最大,那么agent就應該向上跳,為什么呢?Q值是對未來獎勵的期望,如果向上跳這個動作的Q值比其它動作的Q值大,就意味著向上跳這個動作將在未來獲得更多的獎勵,我們需要馬里奧吃到更多的金幣打贏游戲,所以就應該選擇向上跳這個動作,用數學公式可以這樣表示,有了Q* 函式,選擇讓Q* 函式最大化的a作為下一個動作at,

??概括一下有兩種方式用AI控制agent玩游戲,一種是policy函式π,另外一種是optimal action-value function(最優動作-價值函式)Q* ,兩種方法都可行,所以強化學習的任務就學習π函式或學習Q* 函式,只要學到兩者之一就可以了,

??后面我們就是講怎么樣學習這兩種函式:
??如果你設計的一種演算法是學到了π函式或者Q*函式,你就可以把演算法用在控制問題上或者用在小游戲上,
7.1 OpenAI Gym
??OpenAI Gym是強化學習常用的標準庫如果你用強化學習,你很定會用到這個
??Gym有幾大控制問題如:
Cart Pole、Pendulum
Pong、Space Invader
連續問題:Ant、Humanoid、Half Cheetah

總結
期待大家和我交流,留言或者私信,一起學習,一起進步!麻煩大家可用關注公眾號:AI那些事,感謝!!!

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/292444.html
標籤:其他