一.第一步,對于小白來說,用什么編輯很難選擇,怎么下載免費的編輯器也不會,會用電腦下載的又總是被下載許多附帶的垃圾軟體,這個問題讓我來解決,這里我們首先需要安裝兩個軟體以及配置一個pip豆瓣源,第一個python 3.6.5的軟體,然后安裝pycharm-community編輯軟體,
給上百度網盤鏈接,絕對無垃圾軟體安裝,小白們放心安裝:
鏈接:https://pan.baidu.com/s/1WKpEG9qBPRZW-V1UTemUpQ
提取碼:y6z2
pip豆瓣源配置
介紹:
pip豆瓣源配置是為了之后在搭環境時候可以直接用pip install xxx(這里寫python庫的名字)的命令加速下載所需要的各種python庫,如果不配置pip源的話,直接下載庫速度會很慢,而且還會經常下載失敗,pip源也分為阿里云、豆瓣、清華大學、中國科學技術大學四種,在這里我們配置pip豆瓣源,豆瓣源內python庫比較種類全而且相對較穩定,
步驟:
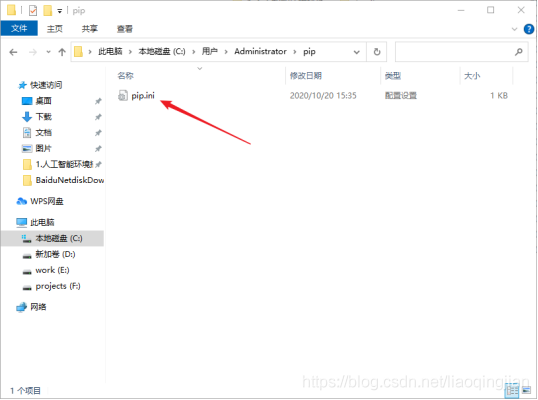
1.下載好網盤內的三個檔案后,找到pip檔案夾
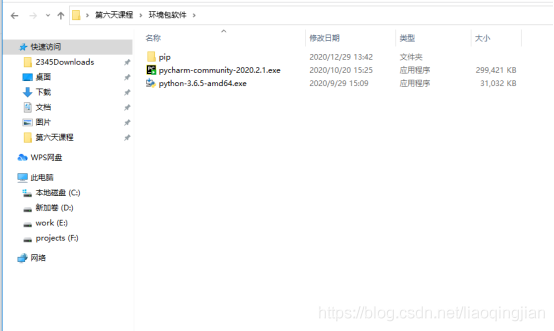
2.將pip檔案復制后,找到C盤的用戶檔案夾
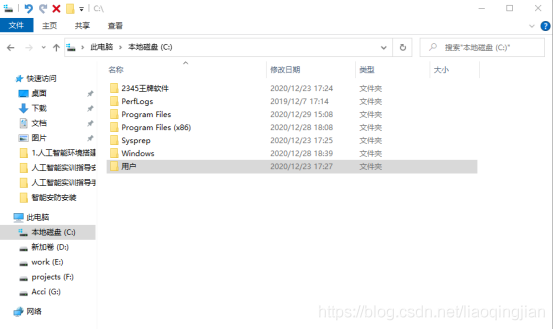
3.將用戶檔案夾打開,找到Administrator檔案夾
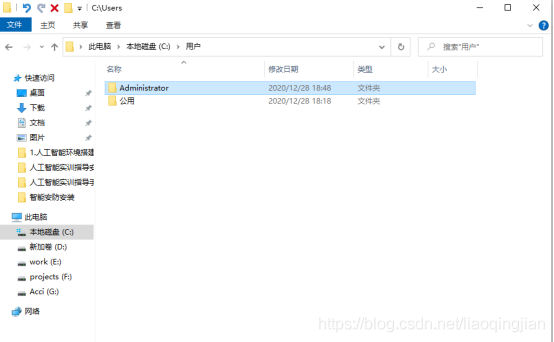
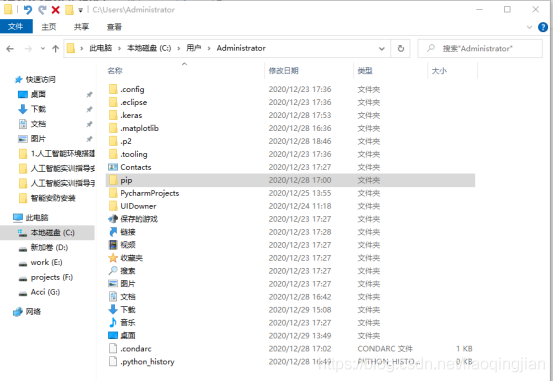
4.打開Administrator檔案夾,將復制的pip檔案夾放入該Administrator目錄下,完成pip豆瓣源的配置,
python軟體安裝
介紹:
python軟體是最基礎的python運行的軟體,安裝python能夠實作一般的python程式運行,
步驟:
1.找到python-3.6.5-amd64.exe軟體,點擊開始安裝python3.6.5軟體
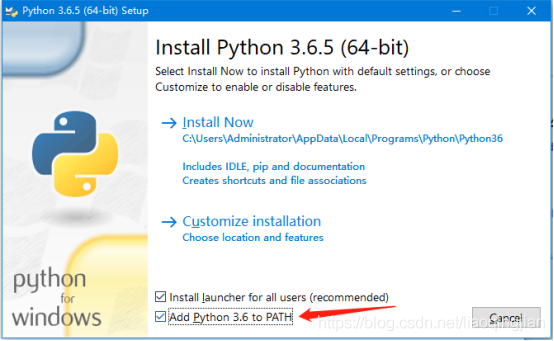
2.勾上Add Python 3.6 to PATH
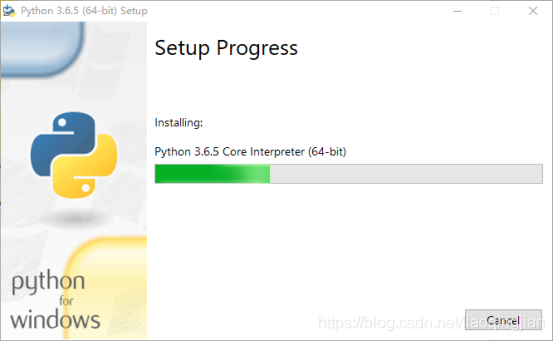
3.點擊Install Now
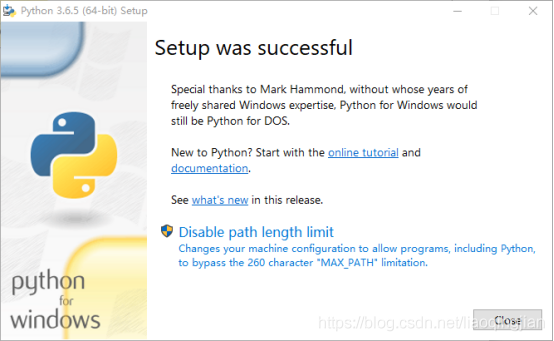
4.出現Close說明安裝完成,點擊Close完成安裝
Pycharm-Community軟體安裝
介紹:
pycharm-community軟體是python的可視化軟體,能夠在其中展現運行的界面和運行的程序,并且能夠在其中配置python軟體的環境,實作兩個軟體同時實作可視化編程,
步驟:
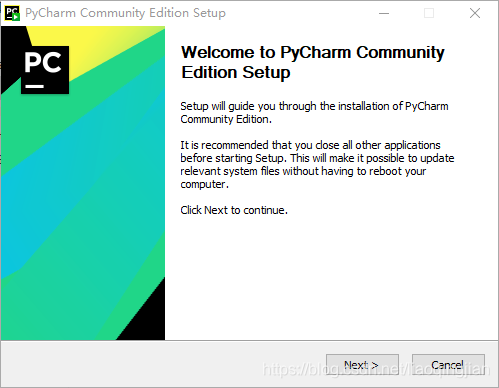
1.找到pycharm-community-2020.2.1.exe檔案,點擊開始安裝pycharm-community軟體,
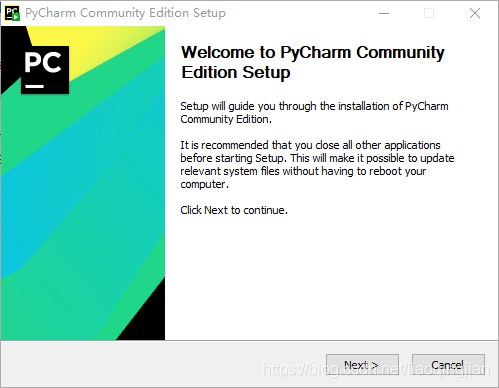
2.點擊Next
3.選擇你安裝的路徑,在這里我安裝在默認的路徑中,繼續點擊Next
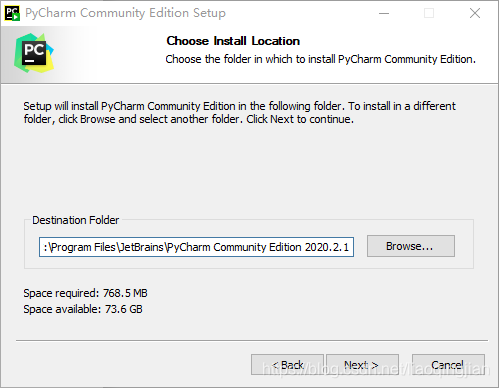
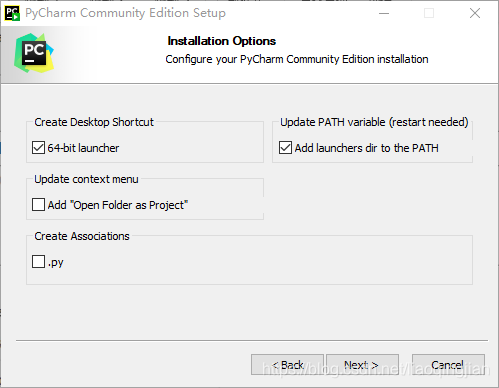
4.勾選64-bit launcher和Add launchers dir to the PATH,繼續點擊Next
在這里插入圖片描述
5.點擊Install
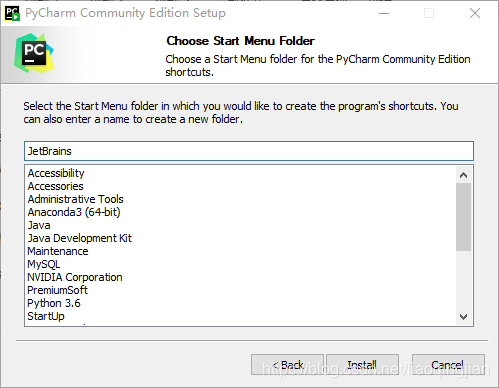
6.等待安裝
7.出現Finish,說明完成安裝,點擊Finish結束安裝
8.在桌面找到pycharm圖示,雙擊圖示

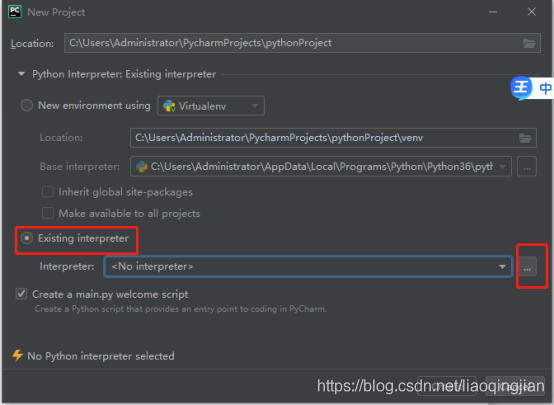
9.選擇New Project,打開新專案

10.選擇Esting interpreter,選擇python路徑
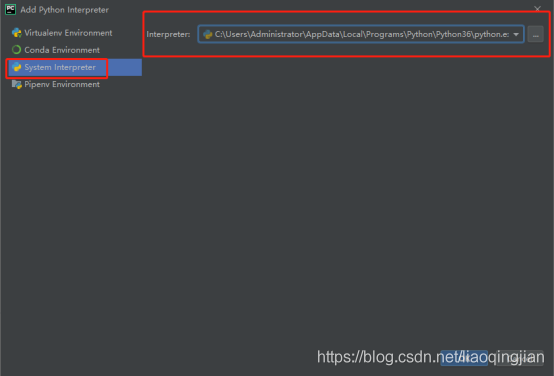
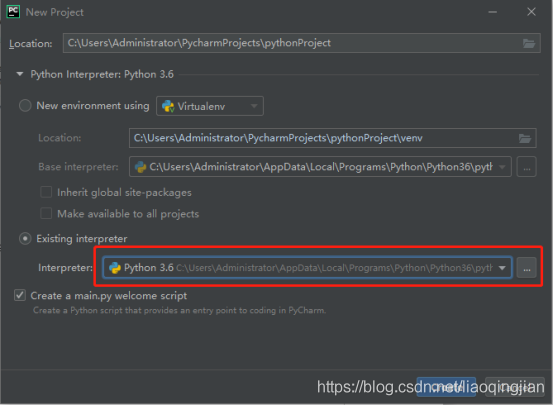
11.點擊Creat創建第一個新專案
二.環境終于安裝成功了吧,現在開始我們的專案實操,從人臉識別做到車牌識別,
人臉識別部分,素材和模型我們需要獲取,同樣給你們網盤鏈接,永久有效
鏈接:https://pan.baidu.com/s/1iRwQ1pLTErgrwohzqH_V8A
提取碼:5w1s
人臉圖片識別
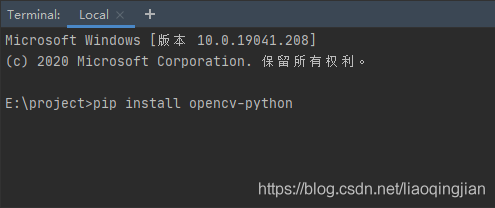
1.下載opencv-python庫,在Terminal中使用命令pip install opencv-python
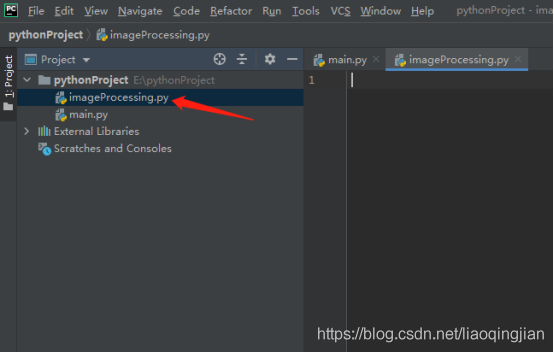
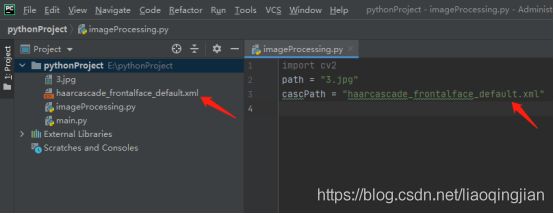
2.右鍵點擊pythonProject,新建一個imageProcessing.py檔案,如下圖
3.在imageProcessing.py檔案中開始寫代碼,首先匯入cv2庫,如下圖
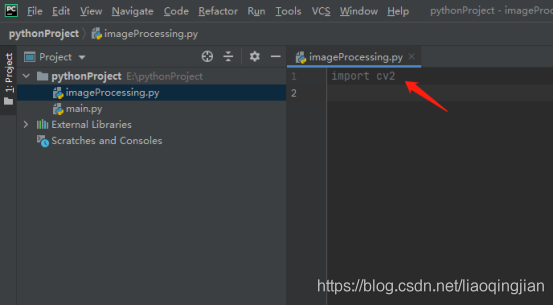
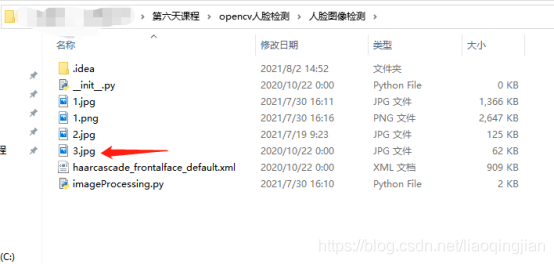
4.輸入素材圖片的路徑,素材在發的檔案里面找,名字是3.jpg
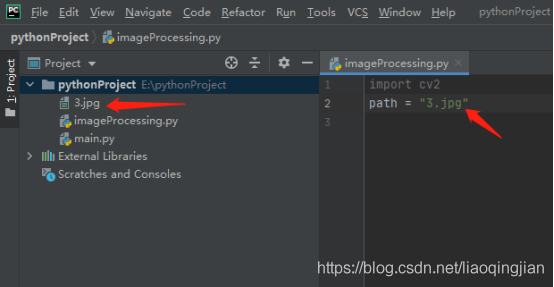
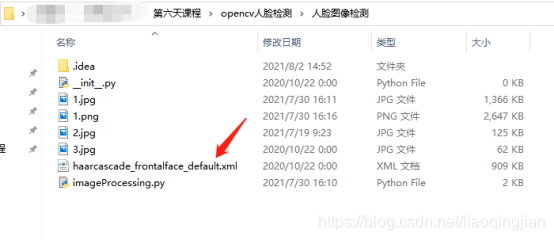
5.找到人臉識別的型別器,將型別器復制到專案中,寫入型別器的路徑并賦予變數cascPath
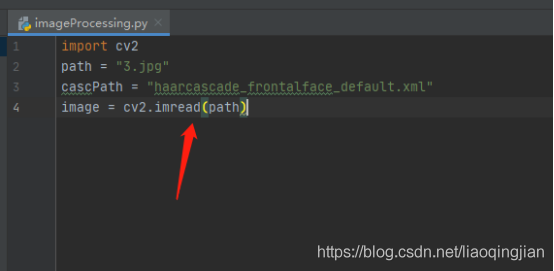
6.使用cv2庫讀取圖片的路徑
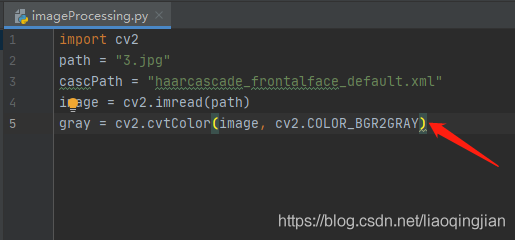
7.將圖片從rgb顏色格式轉成gray灰色格式
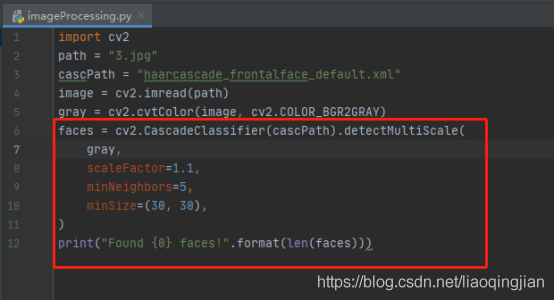
8.通過cv2.CascadeClassifier(cascPath).detectMultiScale函式進行人臉識別處理,并且輸出該圖片有幾張人臉,引數scaleFactor是影像長寬同時按照一定比例(默認1.1)逐步縮小,然后檢測,引數設定的越大,計算速度越快,引數minNeighbors 是模糊度引數,設定越小越容易識別,越大越不容易識別,引數minSize是最小的長和寬像素,
9.在原圖的人臉上畫出識別的矩形區域,(0, 0, 255)是紅色、(0, 255, 0)是綠色、(255, 0, 0)是藍色,
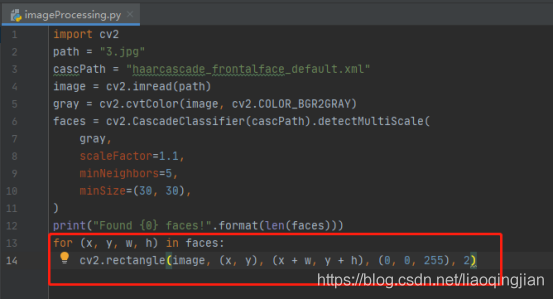
10.展示識別出人臉的圖片
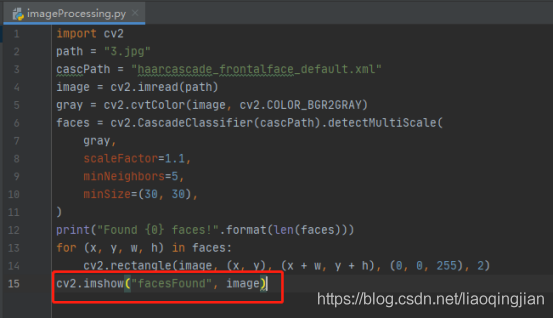
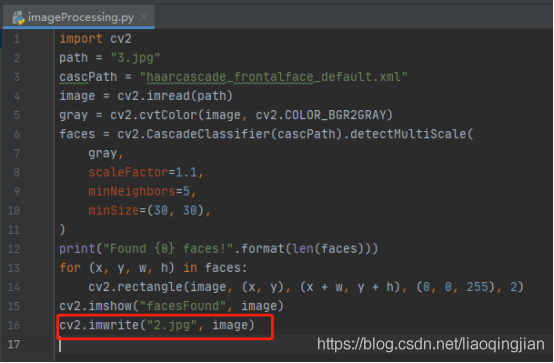
11.將識別人臉后的圖片保存成2.jpg檔案
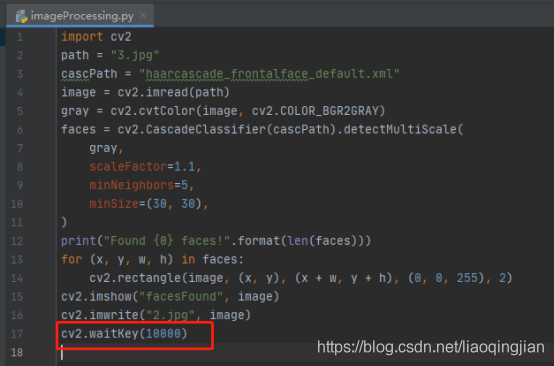
12.等待視窗展示10秒
13.銷毀所有的視窗,避免占用記憶體
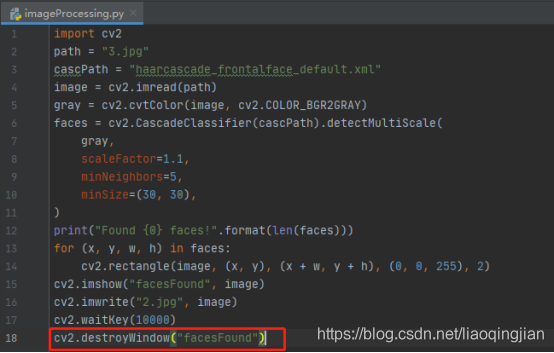
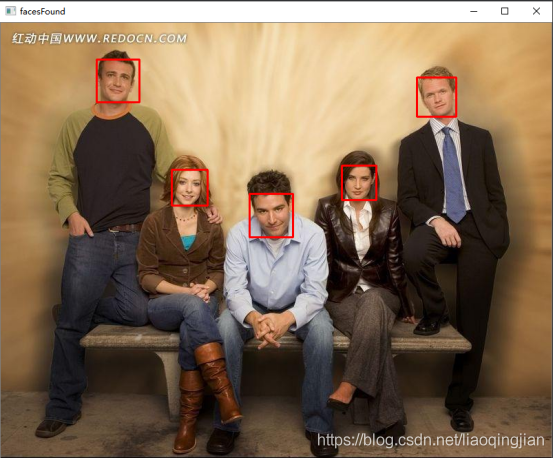
14.運行展示
完整代碼展示
import cv2 # 匯入opencv-python庫即cv2庫
path = "3.jpg" # 寫入圖片的路徑并賦予變數path
cascPath = "haarcascade_frontalface_default.xml" # 寫入型別器的路徑并賦予變數cascPath
image = cv2.imread(path) # 讀取圖片的路徑
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) # 把圖片轉為灰色以便進行人臉識別處理
# scaleFactor 影像長寬同時按照一定比例(默認1.1)逐步縮小,然后檢測,引數設定的越大,計算速度越快
# minNeighbors 模糊度引數,設定越小越容易識別,越大越不容易識別
# minSize是最小的長和寬像素
faces = cv2.CascadeClassifier(cascPath).detectMultiScale(
gray,
scaleFactor=1.1,
minNeighbors=5,
minSize=(30, 30),
)
print("Found {0} faces!".format(len(faces)))
# 通過cv2.CascadeClassifier(cascPath).detectMultiScale函式進行人臉識別處理,并且輸出該圖片有幾張人臉
for (x, y, w, h) in faces:
cv2.rectangle(image, (x, y), (x + w, y + h), (0, 0, 255), 2) # (0, 0, 255)紅色、(0, 255, 0)綠色、(255, 0, 0)藍色
# 在原圖的人臉上畫出識別的矩形區域
cv2.imshow("facesFound", image) # 展示識別出人臉的圖片
cv2.imwrite("2.jpg", image) # 將識別人臉后的圖片寫入該路徑的2.jpg檔案
cv2.waitKey(10000) # 等待視窗展示,防止一閃而過
cv2.destroyWindow("facesFound") # 銷毀創造的facesFound視窗
人臉視頻檢測
1.重新創建一個專案,從File->New Project
2.專案名字可以自己取,這里我默認
3.開始創建的時候這里我們選擇This Window,This Window和New Window的區別就是This Window覆寫原先的視窗、New Window是新打開一個視窗,

4.打開專案后右鍵點擊pythonProjec1,新建一個videoProcessing.py檔案
5.匯入cv2庫
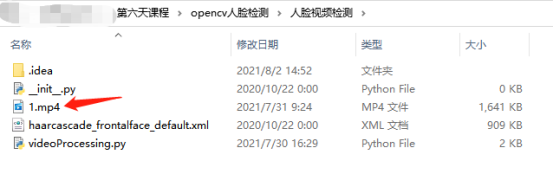
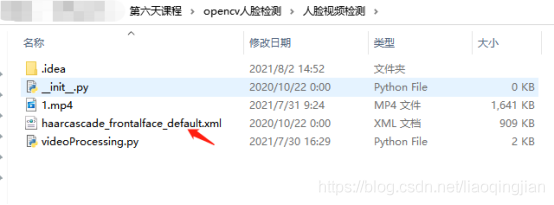
6.找到1.mp4素材,復制在專案中
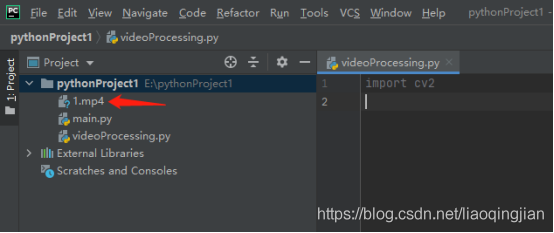
7.寫入視頻的路徑并賦予變數cap
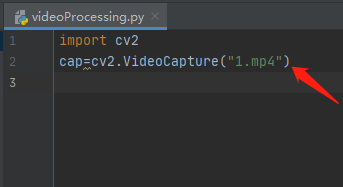
8.找到人臉識別的型別器,將型別器復制到專案中,寫入型別器的路徑并賦予變數cascPath
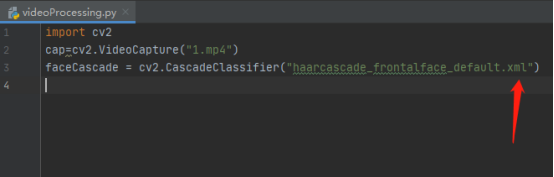
9.寫一個視頻播放的回圈while函式,cap.isOpened()函式是判斷該視頻是否正確播放
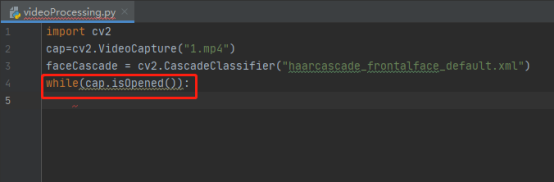
10.讀取視頻,第一個引數ret 為True 或者False,代表有沒有讀取到圖片,第二個引數frame表示讀取到每一幀的圖片
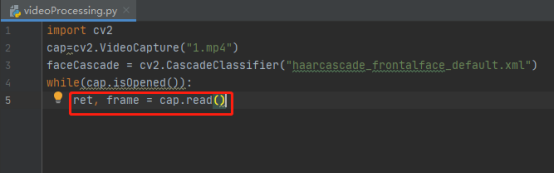
11.判斷圖片是否正常讀取
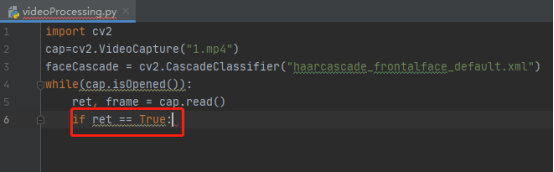
12.將圖片從rgb格式轉成gray灰色格式
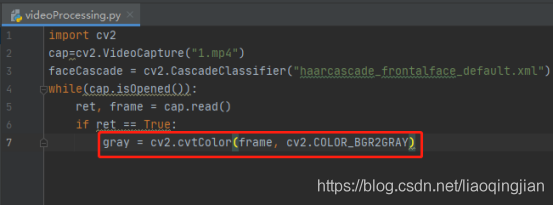
13.通過cv2.CascadeClassifier(cascPath).detectMultiScale函式進行人臉識別處理,并且輸出該圖片有幾張人臉,引數scaleFactor是影像長寬同時按照一定比例(默認1.1)逐步縮小,然后檢測,引數設定的越大,計算速度越快,引數minNeighbors 是模糊度引數,設定越小越容易識別,越大越不容易識別,引數minSize是最小的長和寬像素,
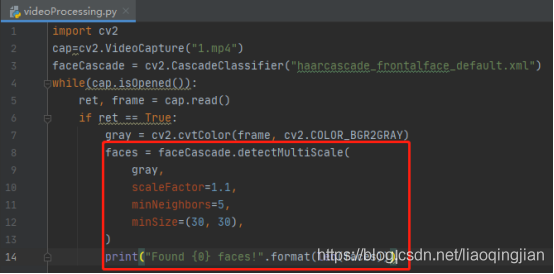
14.在視頻的每一幀上畫矩形
15.創建一個叫facesFound的視窗,播放處理后的視頻
16.視頻正常播放時等待,當按“q”鍵時停止運行
17.如果讀取的視頻幀不正常將會自動停止運行,不會報錯
18.運行完成,將所有的視頻釋放,并且銷毀所有的視窗
19.運行結果

完整代碼展示
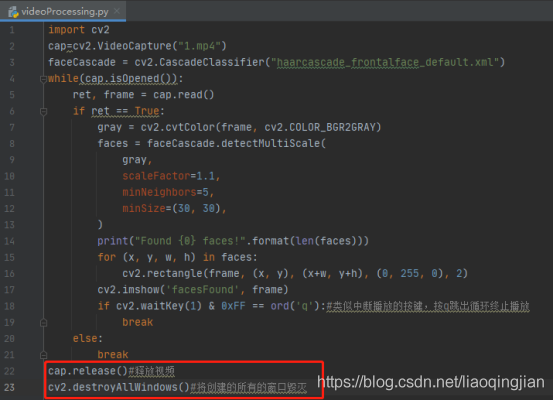
import cv2#匯入opencv-python庫即cv2庫
# cap = cv2.VideoCapture(0)#打開內置攝像頭
cap=cv2.VideoCapture("1.mp4")#寫入視頻的路徑并賦予變數cap
faceCascade = cv2.CascadeClassifier("haarcascade_frontalface_default.xml")#寫入型別器的路徑并給cv2.CascadeClassifier函式進行處理
while(cap.isOpened()):#cap.isOpened()函式是判斷該視頻是否正確播放
ret, frame = cap.read()#讀取視頻,第一個引數ret 為True 或者False,代表有沒有讀取到圖片,第二個引數frame表示截取到一幀的圖片
if ret==True:
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# scaleFactor 影像長寬同時按照一定比例(默認1.1)逐步縮小,然后檢測,引數設定的越大,計算速度越快
# minNeighbors 模糊度引數,設定越小越容易識別,越大越不容易識別
# minSize是最小的長和寬像素
faces = faceCascade.detectMultiScale(
gray,
scaleFactor=1.1,
minNeighbors=5,
minSize=(30, 30),
)
print("Found {0} faces!".format(len(faces)))
# 通過cv2.CascadeClassifier(cascPath).detectMultiScale函式進行人臉識別處理,并且輸出每幀圖片有幾張人臉
for (x, y, w, h) in faces:
cv2.rectangle(frame, (x, y), (x+w, y+h), (0, 255, 0), 2)
# 在原圖的人臉上畫出識別的矩形區域
cv2.imshow('facesFound', frame)#創造一個facesFound視窗來展示每一幀的圖片,使其類似以視頻方式播放
if cv2.waitKey(1) & 0xFF == ord('q'):#類似中斷播放的按鍵,按q跳出回圈終止播放
break
else:
break#如果視頻結束正常跳出回圈終止播放
cap.release()#釋放視頻
cv2.destroyAllWindows()#將創建的所有的視窗毀滅
車牌識別素材網盤獲取
鏈接:https://pan.baidu.com/s/1p82yY7X_c2tHWD9A37kk6g
提取碼:p7zf
車牌圖片識別
1.重新創建一個專案,從File->New Project
2.專案名字可以自己取,這里我默認
3.開始創建的時候這里我們選擇This Window,This Window和New Window的區別就是This Window覆寫原先的視窗、New Window是新打開一個視窗,

4.打開專案后右鍵點擊pythonProjec2,新建一個licenseImage.py檔案
5.使用命令pip install hyperlpr下載識別車牌號碼的python庫
6.繼續使用命令pip install opencv-python==3.4.8.29下載版本為3.4.8.29的opencv庫

7.繼續使用命令pip install pillow下載該python庫
8.下載好這兩個庫后匯入這四個庫
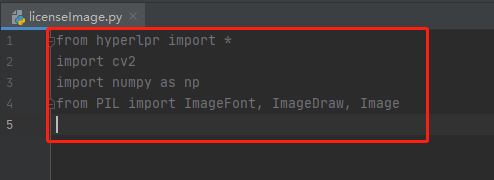
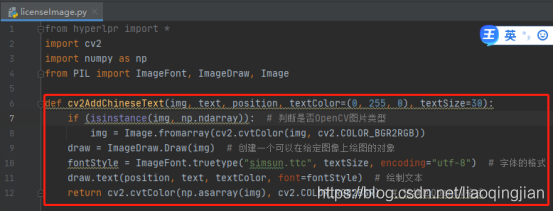
9.定義一個函式cv2AddChineseText,這個函式的目的是在影像上寫出中文字符,該函式內的引數分別是影像、文本內容、像素位置,文本顏色,文本大小
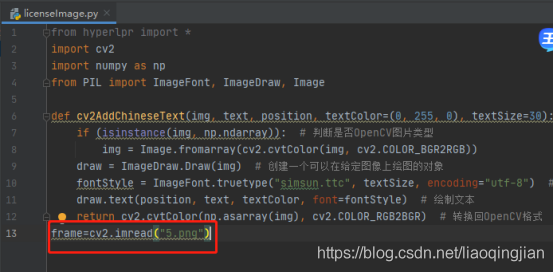
10.找到素材圖片并且復制到專案中,然后讀取圖片
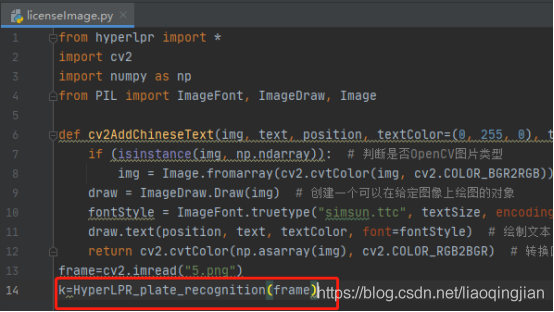
11.讀取圖片內車牌的識別度和車牌的號碼以及車牌的位置
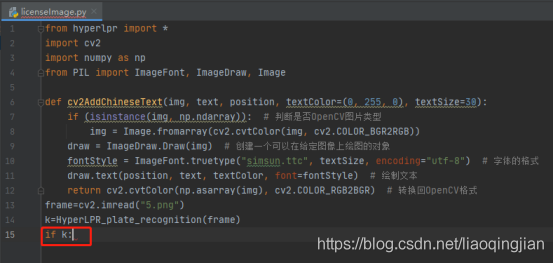
12.做一個判斷,如果存在車牌資訊的話就進行下一步操作
13.將車牌的識別度和車牌的號碼以及車牌的位置分開
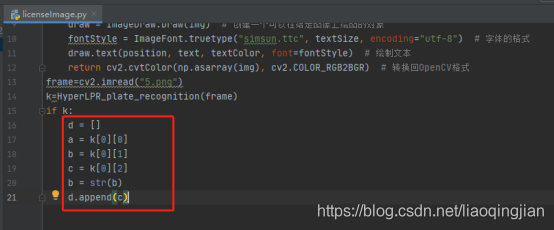
14.在車牌位置中回圈
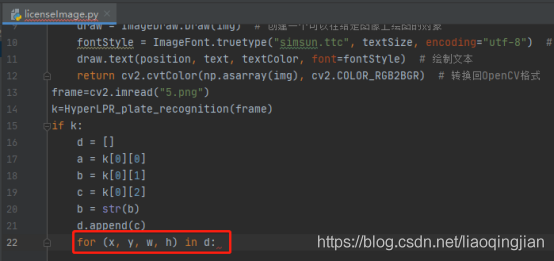
15.在車牌位置畫矩形
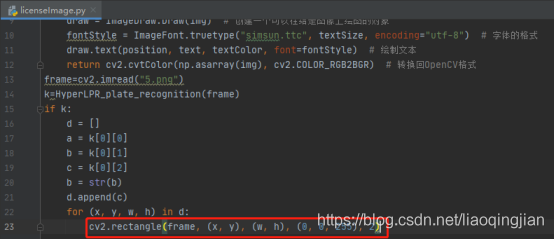
16.呼叫定義的函式來在圖片上車牌號寫進圖片中
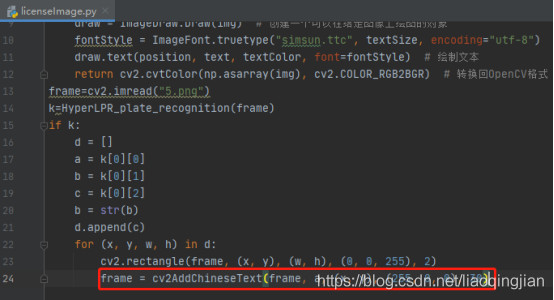
17.將圖片中的識別度寫進圖片中,各引數依次是:圖片,添加的文字,左上角坐標,字體,字體大小,顏色,字體粗細,cv2.FONT_HERSHEY_SIMPLEX:標準大小無襯線字體
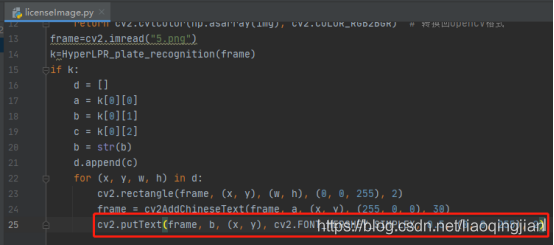
18.將圖片展現出來,并且等待十秒
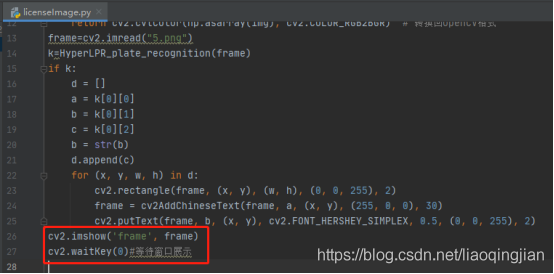
19.運行展現

完整代碼展示
from hyperlpr import *#匯入hyperlpr庫,處理車牌識別
import cv2#匯入CV2庫,處理圖片或視頻,版本號為3.4.8.29
import numpy as np
from PIL import ImageFont, ImageDraw,Image
def cv2AddChineseText(img, text, position, textColor=(0, 255, 0), textSize=30):
if (isinstance(img, np.ndarray)): # 判斷是否OpenCV圖片型別
img = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(img) # 創建一個可以在給定影像上繪圖的物件
fontStyle = ImageFont.truetype("simsun.ttc", textSize, encoding="utf-8") # 字體的格式
draw.text(position, text, textColor, font=fontStyle) # 繪制文本
return cv2.cvtColor(np.asarray(img), cv2.COLOR_RGB2BGR) # 轉換回OpenCV格式
frame=cv2.imread("5.png")#讀取圖片
k=HyperLPR_plate_recognition(frame)#使用HyperLPR_plate_recognition函式識別圖片內車牌號
print(k)
if k:
d = []
a = k[0][0]
b = k[0][1]
c = k[0][2]
b = str(b)
d.append(c)
for (x, y, w, h) in d:
cv2.rectangle(frame, (x, y), (w, h), (0, 0, 255), 2)
frame = cv2AddChineseText(frame, a, (x, y), (255, 0, 0), 30)
cv2.putText(frame, b, (x, y), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 255), 2)#各引數依次是:圖片,添加的文字,左上角坐標,字體,字體大小,顏色,字體粗細,cv2.FONT_HERSHEY_SIMPLEX:標準大小無襯線字體
cv2.imshow('frame', frame)
cv2.waitKey(10000)#等待視窗展示
車輛視頻識別
1.重新創建一個專案,從File->New Project
2.專案名字可以自己取,這里我默認
3.開始創建的時候這里我們選擇This Window,This Window和New Window的區別就是This Window覆寫原先的視窗、New Window是新打開一個視窗,

4.打開專案后右鍵點擊pythonProjec3,新建一個licenseVideo.py檔案
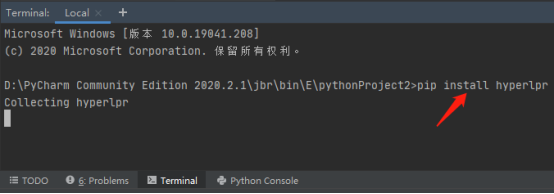
5.使用命令pip install hyperlpr下載識別車牌號碼的python庫
6.繼續使用命令pip install opencv-python==3.4.8.29下載版本為3.4.8.29的opencv庫

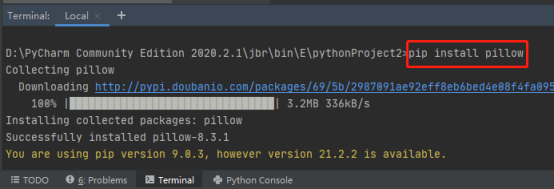
7.繼續使用命令pip install pillow下載該python庫
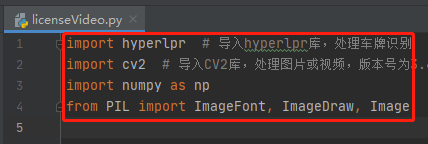
8.下載好這兩個庫后匯入這四個庫
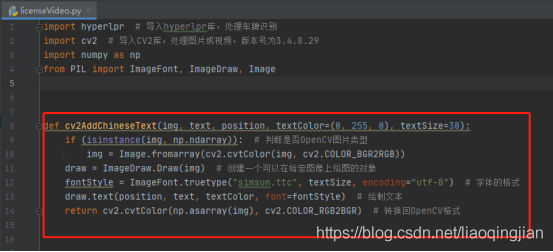
9.定義一個函式cv2AddChineseText,這個函式的目的是在影像上寫出中文字符,該函式內的引數分別是影像、文本內容、像素位置,文本顏色,文本大小
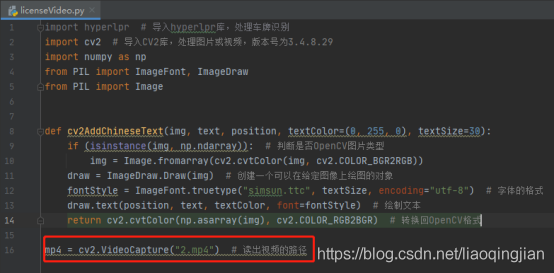
10.找到素材視頻并且復制到專案中,然后讀取視頻
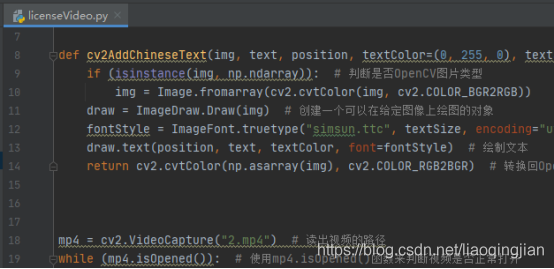
11.寫一個while回圈,看看能否正常讀取圖片
12.讀取視頻,第一個引數ret 為True 或者False,代表有沒有讀取到圖片,第二個引數frame表示截取到一幀的圖片
13.判斷視頻有沒有正常讀取
14.操作跟圖片識別一樣
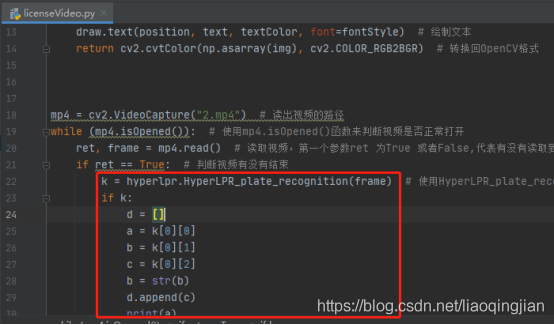
15.在每一幀圖片中都進行畫圖操作,操作情況跟圖片識別一樣
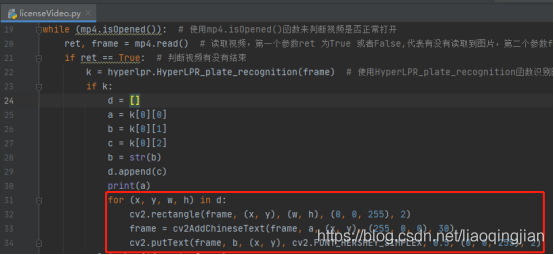
16.展現每一幀圖片以及增加一個中斷操作
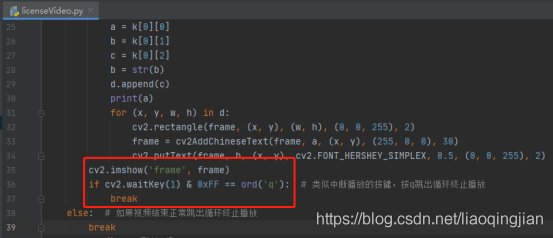
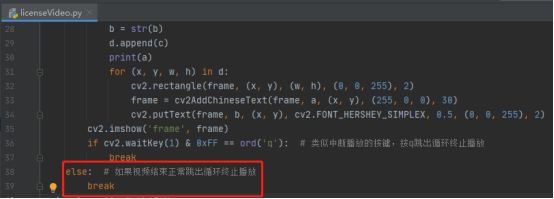
17.如果視頻結束則跳出回圈
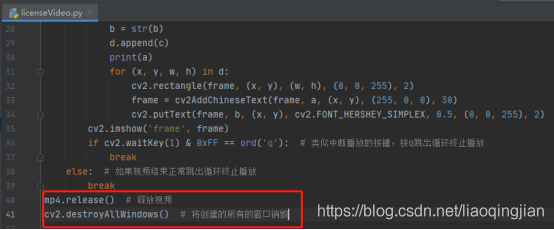
18.釋放視頻以及銷毀視窗操作
19.運行展現

完整代碼展示
import hyperlpr # 匯入hyperlpr庫,處理車牌識別
import cv2 # 匯入CV2庫,處理圖片或視頻,版本號為3.4.8.29
import numpy as np
from PIL import ImageFont, ImageDraw, Image
def cv2AddChineseText(img, text, position, textColor=(0, 255, 0), textSize=30):
if (isinstance(img, np.ndarray)): # 判斷是否OpenCV圖片型別
img = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(img) # 創建一個可以在給定影像上繪圖的物件
fontStyle = ImageFont.truetype("simsun.ttc", textSize, encoding="utf-8") # 字體的格式
draw.text(position, text, textColor, font=fontStyle) # 繪制文本
return cv2.cvtColor(np.asarray(img), cv2.COLOR_RGB2BGR) # 轉換回OpenCV格式
mp4 = cv2.VideoCapture("2.mp4") # 讀出視頻的路徑
while (mp4.isOpened()): # 使用mp4.isOpened()函式來判斷視頻是否正常打開
ret, frame = mp4.read() # 讀取視頻,第一個引數ret 為True 或者False,代表有沒有讀取到圖片,第二個引數frame表示截取到一幀的圖片
if ret == True: # 判斷視頻有沒有結束
k = hyperlpr.HyperLPR_plate_recognition(frame) # 使用HyperLPR_plate_recognition函式識別圖片內車牌號
if k:
d = []
a = k[0][0]
b = k[0][1]
c = k[0][2]
b = str(b)
d.append(c)
print(a)
for (x, y, w, h) in d:
cv2.rectangle(frame, (x, y), (w, h), (0, 0, 255), 2)
frame = cv2AddChineseText(frame, a, (x, y), (255, 0, 0), 30)
cv2.putText(frame, b, (x, y), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 255), 2)
cv2.imshow('frame', frame)
if cv2.waitKey(1) & 0xFF == ord('q'): # 類似中斷播放的按鍵,按q跳出回圈終止播放
break
else: # 如果視頻結束正常跳出回圈終止播放
break
mp4.release() # 釋放視頻
cv2.destroyAllWindows() # 將創建的所有的視窗銷毀
到此結束,運行成功的小伙伴們拜托一鍵三連!!!

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/292446.html
標籤:其他