Voice Recognition
2021年3月21日
HowardXue
語音模型發展:模板匹配(DTW) -> 統計模型(GMM高斯-HMM隱馬) -> 深度學習(DNN-HMM,E2E)
音頻編碼:常用格式PCM的wav格式
語音采樣率8khz 或16khz
6陣列mac 聲源定位 有空間指向性,定位后,可有效抑制其他方向的聲音干擾(旁邊的其他人聲音)
開源工具:HTK,Kaldi, Espnet(python)
音速序列:英語48個音素 20元音 28輔音,漢語32個音素,10個元音
離散傅里葉變換(DFT) 時域信號 -> 頻域信號, 逆傅里葉變換 將頻域信號恢復為時域
實際可以用快速傅里葉變換(FFT) 簡化計算復雜度
加窗:分幀處理
常用的聲學特征:MFCC,FBank,語譜圖
HMM馬爾科夫鏈:只根據當前事件,預測下一事件, --雙重隨機程序
HMM是聲學模型 -> 語音資料
RNN是語言模型 -> 文本資料,詞與詞之間的組合概率關系,基于統計語言模型
解碼器:傳統動態網路解碼器Viterbi -> WFST靜態網路解碼器
WFST把發音詞典、聲學模型、語言模型(三大組件)合并成統一的靜態網路 ->解碼速度快
DNN的輸出節點與HMM的狀態節點一一對應,通過DNN的輸出得到每個狀態的觀察值概率
不同音素(a e I …o)統一關聯到DNN的輸出節點
DNN使用CNN:語譜圖 -> 變為影像處理,提取時域、頻域feature map區域特征
RNN - LSTM, GRU
TDNN時延神經網路
CNN - TDNN-F 組合網路,CNN先提取區域頻域特征,然后TDNN-F提取背景關系的時域特征
E2E ASR Model,只需要輸入端的語音特征和輸出端的文本資訊,將傳統ASR三大組件融合成一個網路模型
E2E常用模型:CTC、RNN-T、Transformer
RNN-T聯合建模:語音識別+說話人區別(識別后的文字后帶有說話人ID)
Attention機制跟人類翻譯文章時候的思路有些類似,即將注意力關注于我們翻譯部分對應的背景關系
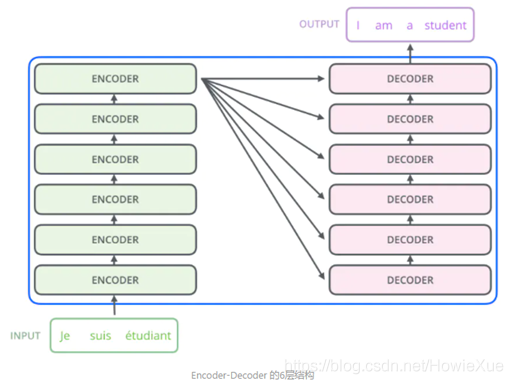
序列對序列問題(sequence-to-sequence, seq2seq),通過Encoder/Decoder對輸入特征和輸出結果進行序列建模
加入Attention機制,改進了seq2seq,
Espnet,特征提取:直接用kaldi原生腳本,可以進行MFCC/FBank/PLP特征的提取
特征提取后,還需對特征進行倒普均值歸一化(CMVN)來使特征服從高斯分布(均值為0,方差為1)
語音資料增強:音量擾動和速度擾動(變速)
詞典生成:數字對應字符
data2json.sh: 映射檔案都打包保存在data2json.sh腳本中
Train.yaml:訓練組態檔,例如選擇哪個聲學模型,選擇CTC/Attention/Transformer結構等
Lm_train.py:語言模型訓練,輸出是:rnnlm.model.best
Asr_train.py: 聲學模型訓練
默認使用的編碼器:BLSTM
Asr.recog.py: 語言識別解碼器
模型部署到Edge:編譯Kaldi生成動態庫.so/dll -> 嵌入式ARM Linux平臺編譯移植Kaldi
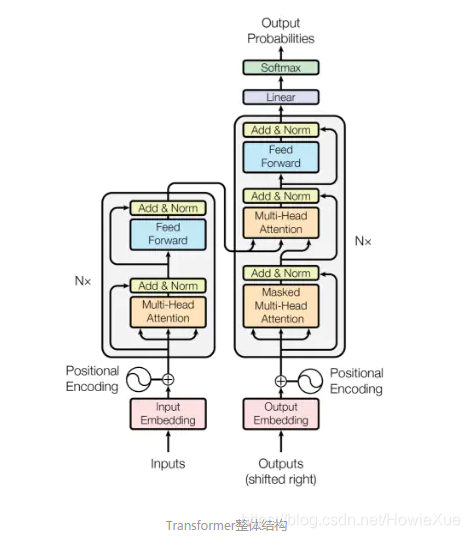
Transformer:
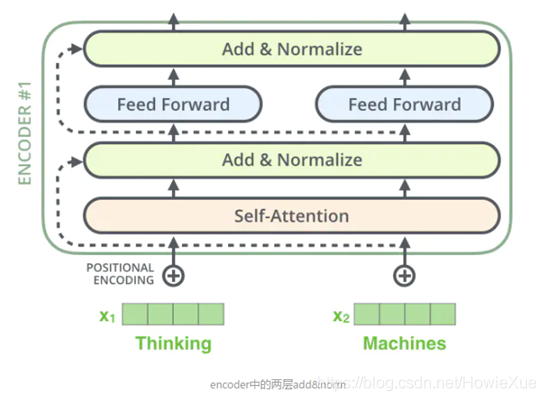
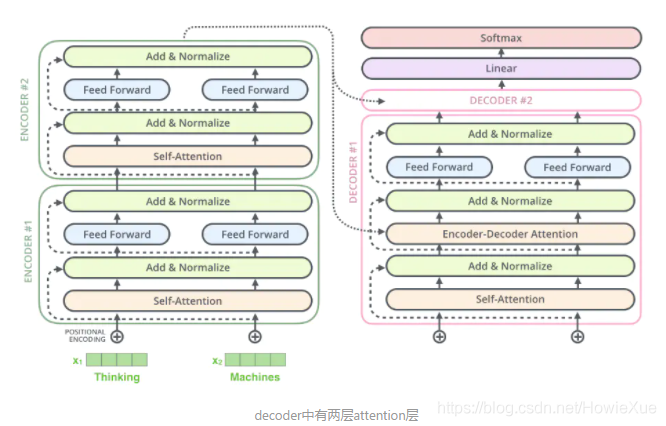
Transformer: 在每個Decoder和Encoder中都采用Attention機制,特別是在Encoder,把傳統的RNN完全用Attention替代
Transformer 本質上還是seq2seq結構:
未完待續,,,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/292449.html
標籤:其他