以下參考論文SSD: Single Shot MultiBox Detector
SSD:
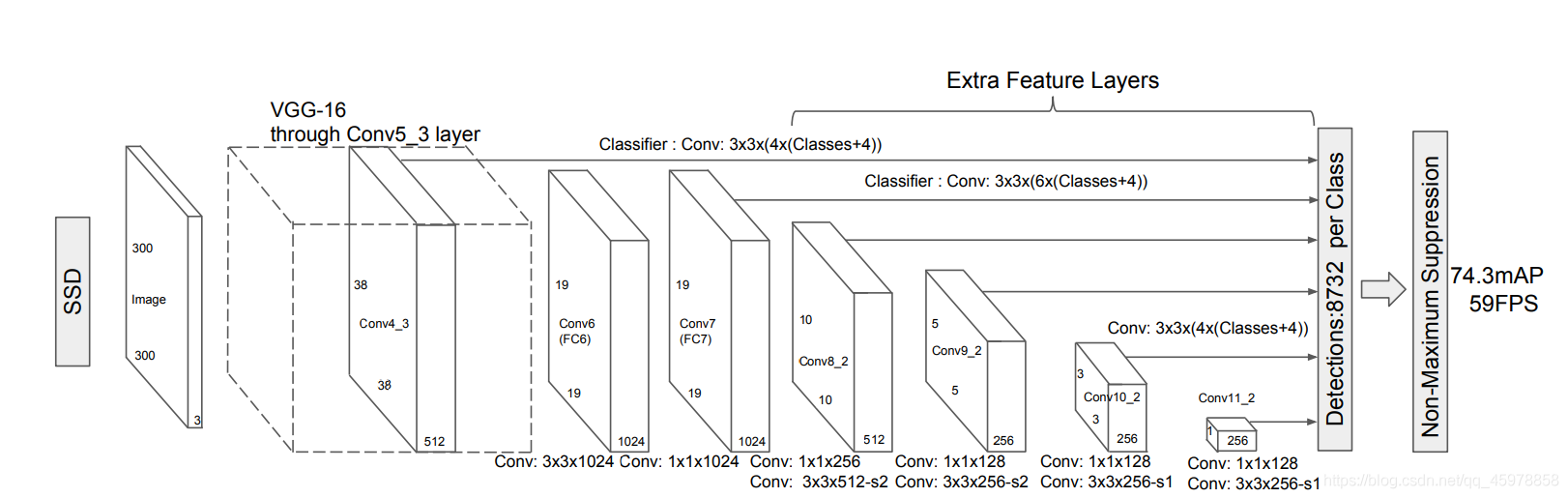
SSD只需要一個輸入影像和參考標準即可
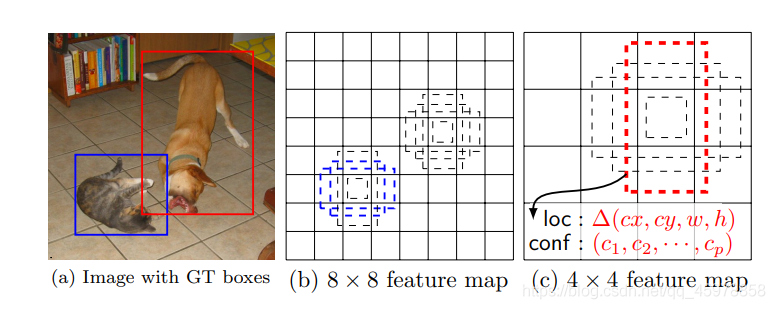
我們在特征地圖中每個位置上評估了幾個不同比例的默認框(8 × 8和4 × 4)
對于每個默認框,我們預測所有物件類別的形狀偏移量和置信度((c1, c2,···,cp))
在訓練時,我們首先將這些默認框與參考標準進行匹配
例如,我們將兩個默認的盒子分別與貓和狗進行了匹配
模型損失是一個在定位損失(如L1)和置信度損失(如Softmax)之間的加權和
SSD方法基于前饋卷積網路,生成一個固定大小的包圍盒集合,并為這些盒中存在的物件類實體評分,然后根據非極大值抑制(Non-Maximum Suppression),以產生最終檢測,
PS:非極大值抑制(Non-Maximum Suppression),目標檢測的程序中在同一目標的位置上會產生大量的候選框,這些候選框相互之間可能會有重疊,此時我們需要利用非極大值抑制找到最佳的目標邊界框,消除冗余的邊界框,
Multi-scale feature maps for detection(多尺度特征圖檢測)
我們在截斷的基礎網路的末端添加了卷積特征層,這些層的大小逐漸減少,并允許在多個尺度上預測探測,對于每個特征層,預測檢測的卷積模型是不同的
Convolutional predictors for detection(用于檢測的卷積預測器)
每一個添加的特征層(或可選的來自基礎網路的現有特征層)都可以使用一組卷積過濾器產生一組固定的檢測預測,這些都顯示在SSD網路架構之上,對于大小為m × n、有p個通道的特征層,預測潛在檢測引數的基本元素是一個3 × 3 × p的小核,它產生一個類別得分,或相對于默認框坐標的形狀偏移,在每個m × n的位置應用核,它產生一個輸出值,
我們的SSD模型在基礎網路的末端添加了幾個特征層,這些特征層可以預測不同規模、寬高比和相關置信度的默認框的偏移量,在VOC2007測驗中,300 × 300輸入尺寸的SSD在準確性上顯著優于其448 × 448YOLO對應版本,同時也提高了速度
Default boxes and aspect ratios(默認框和寬高比)
對于網路頂部的多個特征圖,我們將一組默認的邊界框與每個特征圖單元關聯起來,默認的盒子以一種卷積的方式平鋪特征圖,這樣每個盒子相對于它相應的單元格的位置是固定的,在每個特征映射單元格中,我們預測相對于單元格中默認框形狀的偏移量,以及在每個框中存在類實體的每個類得分,具體來說,對于給定位置k之外的每個方框,我們計算c類得分和相對于初始默認方框形狀的4個偏移量,這將導致在特征圖的每個位置周圍應用的(c + 4)k個濾波器,會生成m × n特征圖的(c + 4)kmn輸出,
Training:
訓練SSD和訓練使用區域建議的典型檢測器之間的關鍵區別是,參考資訊需要分配到檢測器輸出的固定集合中的特定輸出,
Matching strategy(匹配策略)
在訓練期間,我們需要確定哪些默認框和參考目標有聯系,并相應地訓練網路,對于每個參考目標,我們從默認框中選擇,這些默認框會根據位置、寬高比和比例變化,我們首先將每個參考目標匹配到具有最佳jaccard overlap的默認box(如MultiBox[7]),與MultiBox不同的是,我們將默認框匹配到所有具有大于閾值(0.5)的jaccard overlap的參考目標,這簡化了學習問題,允許網路預測多個重疊默認框的高分,而不是只選擇最大重疊的那個,
jaccard overlap:

Training objective
總體目標損失函式為定位損失(loc)和置信度損失(conf)的加權和:
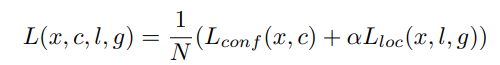
設
x
i
j
p
x^p_{ij}
xijp?={
0
,
1
0,1
0,1}是匹配類別p的第i個默認框和第j個參考目標框的指示符,所以
∑
i
x
i
j
p
\sum_ix_{ij}^p
∑i?xijp?>=1
其中N是匹配的默認框數,如果N = 0,設定損失為0,
L
l
o
c
L_{loc}
Lloc?定位損耗在預測框(l)和參考框(g)引數之間為平滑L1損耗,我們回歸到默認邊界框(d)的中心(cx, cy)以及它的寬度(w)和高度(h)的偏移量
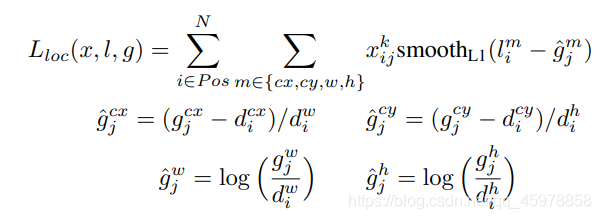
置信損失是多個類的置信( c )上的softmax損失,
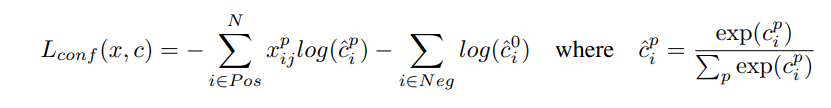
通過交叉驗證將權重項α設為1,
Choosing scales and aspect ratios for default boxes(為默認框選擇比例和寬高比)
為了處理不同的目標尺度,建議對影像進行不同大小的處理,然后將結果進行合并,然而,通過利用單一網路中不同層次的特征圖進行預測,我們可以模擬相同的效果,同時還可以共享所有物件尺度的引數,以往的研究表明,使用較低層的特征圖可以提高語意分割的質量,因為較低層能捕獲輸入物件的更多細節,同樣,從特征圖中加入全域背景關系池可以幫助平滑分割結果,
在這些方法的推動下,我們同時使用上下特征圖來檢測,上圖顯示了框架中使用的兩個示例特性映射(8×8和4×4),在實踐中,我們可以用較小的計算開銷使用更多,
已知來自網路內不同層次的特征圖具有不同的(經驗的)接受域大小,幸運的是,在SSD框架中,默認框不需要對應每一層的實際接收欄位,我們設計了默認盒子的平鋪,以便特定的特征地圖能夠對特定的物體比例做出回應,假設我們要使用m個特征圖進行預測,每個feature map的默認方框的比例計算為:
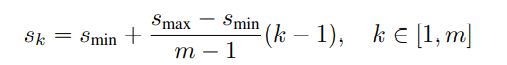
其中
s
m
i
n
s_{min}
smin?是0.2,
s
m
a
x
s_{max}
smax?是0.9,這意味著最低層的比例為0.2,最高層的比例為0.9,中間各層之間的間隔是有規律的,我們對默認框施加不同的長寬比,并將它們表示為ar∈{
1
,
2
,
3
,
1
/
2
,
1
/
3
1,2,3,1/2,1/3
1,2,3,1/2,1/3},我們可以計算每個默認框的寬度(
W
k
a
=
s
k
a
r
W_k^a = s_k\sqrt{a_r}
Wka?=sk?ar?
?)和高度(
H
k
a
=
s
k
/
a
r
H_k^a = s_k/\sqrt{a_r}
Hka?=sk?/ar?
?),對于寬高比為1的情況,我們還添加了一個默認的比例為
s
k
′
=
s
k
s
k
+
1
s_k^{'}= \sqrt{s_ks_{k+1}}
sk′?=sk?sk+1?
?導致每個特征地圖位置有6個默認方框
我們將每個默認框的中心設定為(
i
+
0.5
∣
f
k
∣
,
j
+
0.5
∣
f
k
∣
\frac{i+0.5}{|f_k|},\frac{j+0.5}{|f_k|}
∣fk?∣i+0.5?,∣fk?∣j+0.5?),其中|fk|為第k個正方形特征映射的大小 i, j∈[0,|fk|)
在實踐中,還可以設計默認框的分布,以最適合特定的資料集
通過結合許多特征地圖的所有位置的不同比例和寬高比的所有默認框的預測,我們有了一套不同的預測,涵蓋了各種輸入物件的大小和形狀,例如,在圖1中,狗被匹配到4 × 4特征圖中的一個默認框,而沒有匹配到8 × 8特征圖中的任何默認框,這是因為這些盒子有不同的規模并且不匹配的狗的盒子,因此被認為是消極的訓練,
Hard negative mining
在匹配步驟之后,大多數默認框都是負數,特別是當可能的默認框的數量很大時,這在積極和消極的訓練例子之間引入了嚴重的不平衡,我們不使用所有的負面例子,而是使用每個默認框的最高置信度損失來排序,并選擇最上面的,這樣消極和積極的比例最多為3:1,我們發現,這將導致更快的優化和更穩定的訓練,
Data augmentation(資料增強)
為了使模型對不同的輸入物件大小和形狀具有更強的魯棒性,每個訓練影像都被以下選項之一隨機采樣:
-使用整個原始輸入影像,
-采樣一個補丁,使 jaccard overlap的物件是0.1,0.3,0.5,0.7或0.9,
-隨機采樣一個補丁,
每個采樣patch的大小為原始影像大小的[0.1,1],長寬比介于1和2之間,如果參考樣例的中心在采樣的patch中,我們保留參考樣例的重疊部分,在上述采樣步驟之后,每個采樣的補丁大小調整為固定大小,并以0.5的概率水平翻轉,此外還應用一些類似于photo-metric deformation,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/292597.html
標籤:其他