本筆記是依據周浦城等教授編著的《深度卷積神經網路原理與實踐》的個人筆記(Version:1.0.2)
整理作者:sq_csl
第一章 機器學習基礎
1.1 機器學習概述
1.1.1 概念
概念
ML(Machine Learning)是一門發展了比較長時間的學科,其在發展程序中定義也發生了一些變化
早期概念源于Tom Mitchell:假設用
P
P
P來評估計算機程式在某個任務類
T
T
T上的性能,若某程式利用經驗
E
E
E在任務類
T
T
T上獲得了性能改善,那么認為關于
T
T
T和
P
P
P,這個程式對
E
E
E進行了學習,
但隨著研究深入,內涵和外延也在發生變化,目前大家的普遍認知:ML專門研究計算機如何模擬、實作人的學習行為用來獲得新的知識、技能,重新組織已有的知識結構使得其不斷改善系統自身的性能,
目的
機器學習的目的:學習到的模型能夠很好的適用于新樣本,而不僅僅是訓練集本身(所以也需要測驗集),
1.1.2 機器學習的任務
分類
D
a
t
a
?
Data?
Data?
f
:
R
d
?
Z
f:R^d?Z
f:Rd?Z,它是一種從向量到整數的映射,
其中
R
d
R^d
Rd為樣本集,
Z
Z
Z為標簽集,
如果標簽數量為2,那么是二分類問題,一般類別標簽設定為 + 1 、 ? 1 +1、-1 +1、?1,如果涉及到多個類別,則為多分類問題
舉例:身高1.75m,體重100kg的男人肥胖嗎? 根據腫瘤的體積、患者的年齡來判斷腫瘤的良性或惡性?
回歸
D
a
t
a
?
Data?
Data?
f
:
R
d
?
R
f:R^d?R
f:Rd?R,它是一種從自變數到因變數的映射,
其中
R
d
R^d
Rd為自變數集,
R
R
R為因變數集,
根據函式運算式的不同,可將回歸分為線性回歸和非線性回歸,也可根據因變數和自變數的數量不同,將回歸分為一元回歸和多元回歸,
舉例:如何預測曹縣的房價?未來一個月的某板塊股票的走向?
排序
使用機器學習方法,得到資料特征排序的模型,通過模型來得到排序結果,
根據訓練資料的不同,排序學習方法可分為:pointwise(基于單個樣本)、pairwise(基于樣本對)、listwise(基于樣本串列)
聚類
聚類演算法將樣本集根據樣本之間的相似性,將樣本之間劃分成多個不相交的簇,
常見的聚類演算法:
劃分聚類:K-Means、K-Medoids等
層次聚類:BIRCH、ROCK等
密度聚類:DBSCAN(可參考周志華教授《機器學習》)、OPTICS、DENCLUE等
網路聚類:STING、CLIQUE、waveCluster等
模型聚類分基于概率模型聚類和基于神經網路模型聚類兩種,主要有:GMM、基于PagerRank的聚類、SOM
舉例:如何將教室里的學生按性格、愛好劃分為5類?
降維
通過某種數學變換將原始的高維度屬性空間的樣本映射到低維度的子空間,并保證其中所包含的有效資訊不會丟失,這是一種預處理的重要手段,
降維演算法可以根據策略的不同進行不同的分類:
根據樣本資訊是否可利用:監督降維、半監督降維、無監督降維
處理的型別:線性降維(PCA、ICA、LDA等)、非線性降維(Isomap、LLE、kernel PCA等)
1.1.3 機器學習的發展簡史
機器學習的發展大致可以分為以下五個階段:(以下不講歷史,列出一些此時期出現的方法)
奠基時期
Adaline模型和學習方法
瓶頸時期
感知機
重振時期
反向傳播(BP)
決策樹:ID3、C4.5、CART
成型時期
Boosting:AdaBoost演算法等
支持向量機(SVM)
隨機森林(RF)
在此時期,研究發現,在應用反向傳播(BP)演算法進行神經網路的訓練時,易出現由于神經元飽和而導致的梯度消失的現象,
爆發時期
通過無監督學習方法逐層訓練演算法,再使用有監督的BP演算法進行調優解決深度神經網路在訓練上的問題,
DL(Deep Learning)發展
1.2 機器學習策略
有監督學習(SL)
常見:決策樹、k鄰接演算法(kNN)、樸素貝葉斯分類器(NBC)等
無監督學習(UL)
常見:稀疏自編碼(SAE)、主成分分析(PCA)、K-Means、最大期望(EM)
半監督學習(SSL)
可分為:半監督分類、半監督回歸、半監督聚類和半監督降維
常見的半監督學習有直推式和歸納式兩種模式,
強化學習(RL)
將DL應用于RL,可形成深度強化學習,
1.3 模型評估與選擇
1.3.1 歸納偏好
丑小鴨定理:不存在與問題無關的“優越”的或“最好”的特征集合或屬性集合,
沒有免費的午餐:所有搜索代價函式極值的演算法在平均到所有可能的代價函式上時,其表現都恰好是相同的;特別地,如果演算法A在一些代價函式上優于演算法B,那么一定存在其它一些函式,使得B優于A,
最小描述長度(MDL):必須使模型的演算法復雜度及與該模型相適應的訓練資料的描述長度的和最小,(體現了“奧卡姆剃刀”原理)
1.3.2 資料集劃分
誤差:預測輸出與真實輸出之間的差異
訓練誤差、經驗誤差:演算法模型在訓練集上的差異
泛化誤差:演算法模型在新樣本上的誤差
通常將資料集 D D D拆分成訓練集 S S S和測驗集 T T T,假設 T T T是從樣本真實分布中獨立采樣得到的,就可以將 T T T上的誤差近似為泛化誤差,從而同時根據訓練誤差和測驗誤差對學習演算法進行性能評估,
要充分利用已有的有限數量的資料集來構造一個規模盡量大的資料集,主要的技術包括留出法、自助法、交叉驗證法等
1.3.3 性能度量
性能度量不僅取決于演算法和資料,還應該反映具體的任務需求,
錯誤率和精度
錯誤率(error rate):錯分樣本的數量占樣本總量的比例
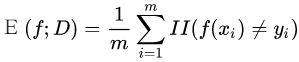
精度(accuracy):分對的樣本的數量占樣本總數的比例
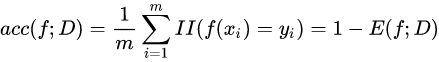
這里的 I I ( . ) II(.) II(.)是指示函式,若 . . .為真則取1,否則取值為0,
查準率、查全率和F1度量
查準率P(Precision)與查全率R(Recall)分別定義為:
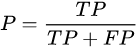
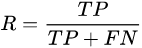
其中:
TP:真正例(true positive),即真實結果和預測結果都是正例,
FP:假正例(false positive),即真實結果是反例,預測結果是正例,
TN:真反例(true negative),即真實結果和預測結果都是反例,
FN:假反例(false negative),即真實結果是正例,預測結果是反例,
真實標簽值與預測結果可形成混淆矩陣,矩陣如下: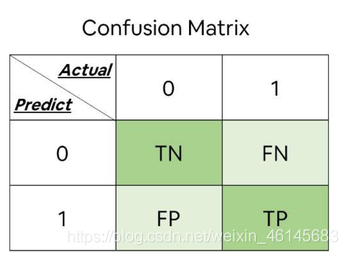
因此,學習模型對測驗資料集輸出一系列為正樣本的概率,根據概率由大到小排列,然后依次設定閾值,若大于該閾值,則為正樣本;反之則為負樣本,每次閾值的設定都有對應的查準率和查全率,因此以查全率為橫坐標,查準率為縱坐標,就可以得到查準率-查全率曲線,也稱作”P-R"曲線,
在實際應用中,更常用的是F1度量:

1.3.4 過擬合、欠擬合
如果模型沒有很好的捕捉到資料特征,對訓練樣本的一般性質尚未學習好,不能很好擬合資料,導致得到的模型在訓練集上的表現差,就被稱為欠擬合,(可能原因:模型本身過于簡單;特征數量太少)
如果在訓練集上表現好,但在測驗集上表現差(可能原因:模型本身過于復雜;訓練樣本缺乏代表性)
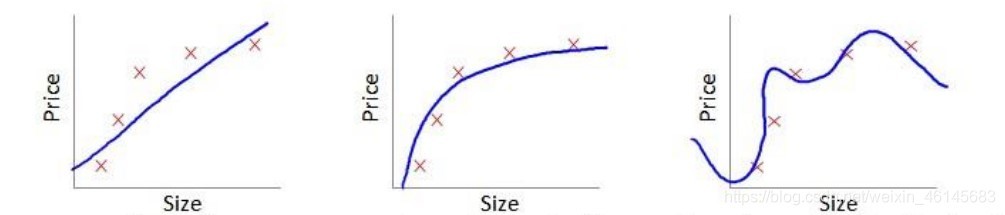
(從左到右分別為:欠擬合、好的擬合、過擬合)
1.4 神經網路與深度學習
1.4.1 生物神經元(略)
1.4.2 人工神經網路
M-P模型

其中,
x
1
x_1
x1?,
x
2
x_2
x2?,…,
x
n
x_n
xn?為神經元P的n個輸入節點;
w
1
w_1
w1?,
w
2
w_2
w2?,…,
w
n
w_n
wn?為權值,
θ
θ
θ是神經元閾值;
y
y
y是神經元的輸出,那么輸出函式為下式:
y
=
f
(
(
∑
i
=
1
n
w
i
x
i
)
+
θ
y=f(\displaystyle \left( \sum_{i=1}^n w_i x_i \right)+θ
y=f((i=1∑n?wi?xi?)+θ
其中,
f
f
f為激活函式,激活函式的不同,神經元模型也不同,
感知機
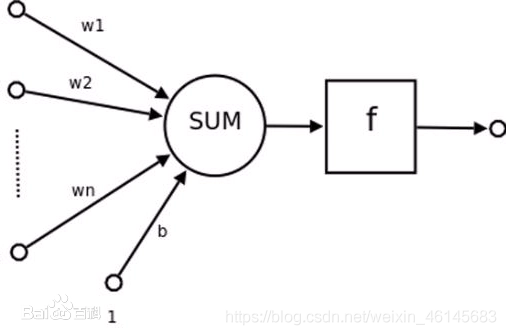
假設輸入特征向量空間為
x
∈
R
n
x∈R^n
x∈Rn,輸出的類標簽空間為
y
=
y=
y={
?
1
,
+
1
-1,+1
?1,+1},
f
f
f為符號函式(有文獻記作
s
g
n
sgn
sgn函式),
W
=
(
w
1
,
w
2
,
.
.
.
,
w
n
)
T
W=(w1,w2,...,wn)^T
W=(w1,w2,...,wn)T,
x
x
x和
b
b
b分別為神經元的神經向量和偏置(bias),則模型為:
y
=
f
(
W
T
x
+
b
)
y=f(W^Tx+b)
y=f(WTx+b)
多層感知機
在輸入層和輸出層之間加上隱藏層(Hidden Layer),就構成了多層感知機,
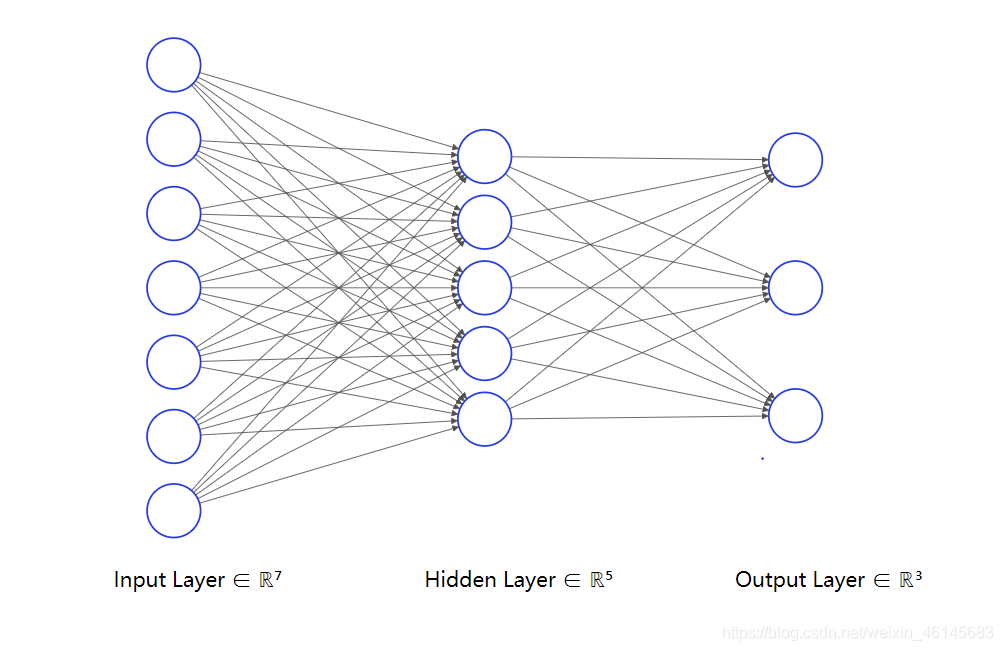
1.4.3 深度學習
產生背景
為了解決傳統機器學習中人工設計特征的不足,采用類似大腦皮層的分層結構,不僅極大的降低了視覺系統處理的資料量,而且顯著提升了魯棒性和認知效率,
深度學習的提出(略)
與淺層學習的區別
模型結構方面:學得的模型中非線性操作的層級數變得更多
特征學習方面:對原始信號逐層進行特征變換,得到層次化的特征表示,可更好的刻畫資料的內在資訊
避免了繁雜的特征提取,更好的實作了復雜的函式逼近,
深度學習模型
DAE
CNN
RNN
(第一章 完結)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/292631.html
標籤:AI