大資料簡介
大資料是指無法在一定時間內用常規軟體工具進行捕捉、管理和處理的資料集合,是需要新處理模式才能具有更強的決策力、洞察發現力和流程優化能力的海量、高增長率和多樣化的資訊資產,目前大資料技術已經廣泛應用于眾多行業,如倉儲物流、電商銷售、汽車、電信、生物醫學、人工智能、智慧城市等等,
大資料的特點(5V)
1. Volume(大量)
資料單位:GB -> TB -> PB -> ZB -> YB -> BB -> NB -> DB
IDC預測,2020年全球資料達到44ZB,2025年全球資料量將達到163ZB,平均每40個月,全球資料量就會翻倍!傳統的關系型資料庫已經無法處理如此海量的資料,
2. Velocity(高速)
在大資料時代,資料的創建、存盤、分析都需要被高速處理,如電商網站的個性化推薦,需要盡可能實時完成推薦,這也是大資料區別于傳統資料挖掘的顯著特征,
3. Variety(多樣)
資料形式和來源多種多樣,包括結構化、非結構化、半結構化的資料,有網路日志、音頻、視頻、圖片、地理位置等等,多資料型別對資料的處理能力提出了更高的要求,
4. Veracity(真實)
必須確保資料的真實性,才能保證資料分析的正確性,
5. Value(低價值)
資料價值密度相對低,猶如淘金,資料的價值是彌足珍貴的但是需要強大的機器演算法才能挖掘,
Hadoop簡介
Hadoop是一個適合大資料的分布式(也就是說Hadoop一定是要搭建集群的)存盤和計算平臺,狹義的Hadoop是指一個框架平臺,廣義上講Hadoop代表大資料的一個技術生態圈,包括很多其他軟體框架,
Hadoop生態圈技術堆疊包括:
- Hadoop(HDFS+MapReduce+Yarn)
- Hive資料倉庫工具
- Hbase海量列式非關系型資料庫
- Flume資料采集工具
- Sqoop ETL工具
- Kafka高吞吐訊息中間件
- ……
Hadoop學習資料
1. 官方檔案:https://hadoop.apache.org/docs/r3.3.1/
2. github教程(推薦):https://github.com/heibaiying/BigData-Notes
3. 視頻教程:https://www.bilibili.com/video/BV1Qp4y1n7EN
Hadoop的優缺點(SEER)
優點
1. 擴容能力(Scalable)
Hadoop是在計算機集群內分配資料并完成計算任務,集群可方便的擴展數萬節點,
2. 低成本(Economical)
Hadoop通過普通廉價的機器組成服務器集群來分發和處理資料,
3. 高效率(Efficient)
Hadoop可以在節點之間動態并行的移動資料,使得速度非常快,(這點是相對的)
4. 可靠性(Reliable)
自動維護資料的多份副本,并且在任務失敗后能自動重新部署計算任務,
缺點
1. 不適合低延遲的資料訪問
2. 不能高效存盤大量小檔案
3. 不支持用戶寫入和任意修改檔案
Hadoop的發行版本
1. Apache Hadoop(免費):http://hadoop.apache.org/
優點:開源、免費,學習非常方便,代碼更新版本快
缺點:版本的升級、維護、兼容性問題
2. CloudManager(收費):https://www.cloudera.com
CloudManager通過各種補丁,實作版本之間的穩定運行,解決了版本升級困難和版本兼容性的各種問題,生產推薦使用CloudManager的CHD版本
3. HortonWorks(免費):https://hortonWorks.com
Hortonworks主要是雅虎主導的(目前被上面的Cloudera收購),核心產品HDP,免費開源,并且提供一套web管理界面HDF,方便通過界面管理集群狀態,web管理界面地址:http://ambari.apache.com
Apache Hadoop的重要組成 ★
Hadoop = DHFS(分布式檔案系統) + MapReduce(分布式計算框架)+ Yarn(資源協調框架)+ Common(公用的模塊,如RPC、Configuration、序列化機制和日志操作)
HDFS檔案存盤
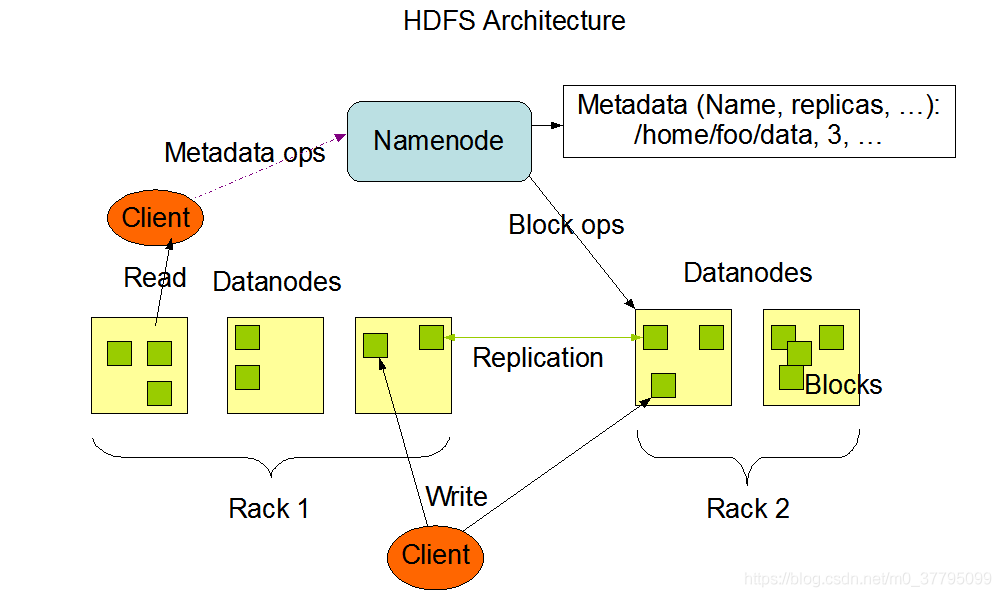
HDFS 遵循主/從架構,由單個 NameNode(NN) 和多個 DataNode(DN) 組成:
- NameNode : 負責執行有關
檔案系統命名空間的操作,例如打開,關閉、重命名檔案和目錄等,它同時還負責集群元資料的存盤,記錄著檔案中各個資料塊的位置資訊, - DataNode:負責提供來自檔案系統客戶端的讀寫請求,執行塊的創建,洗掉等操作,
MapReduce計算
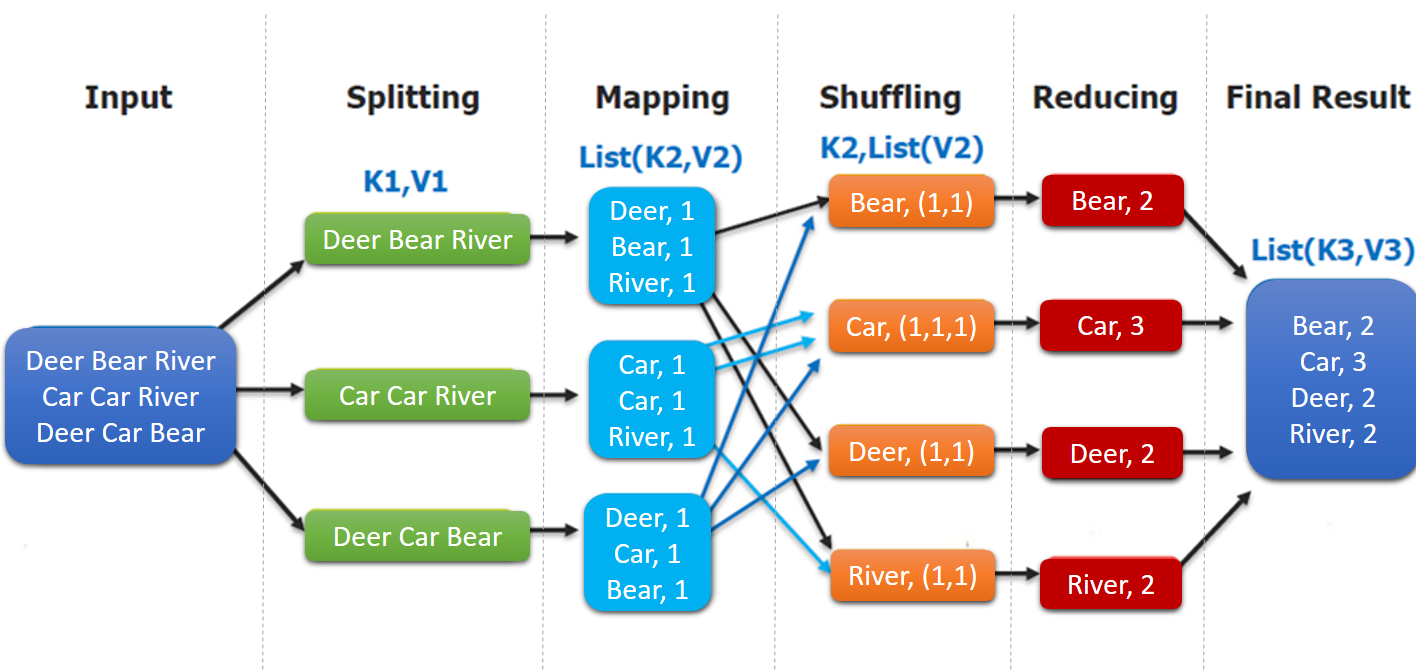
以詞頻統計(WordCount)為例:
-
input : 讀取文本檔案;
-
splitting : 將檔案按照行進行拆分,此時得到的
K1行數,V1表示對應行的文本內容; -
mapping : 并行將每一行按照空格進行拆分,拆分得到的
List(K2,V2),其中K2代表每一個單詞,由于是做詞頻統計,所以V2的值為 1,代表出現 1 次; -
shuffling:由于
Mapping操作可能是在不同的機器上并行處理的,所以需要通過shuffling將相同key值的資料分發到同一個節點上去合并,這樣才能統計出最終的結果,此時得到K2為每一個單詞,List(V2)為可迭代集合,V2就是 Mapping 中的 V2; -
Reducing : 這里的案例是統計單詞出現的總次數,所以
Reducing對List(V2)進行歸約求和操作,最終輸出,
MapReduce 編程模型中 splitting 和 shuffing 操作都是由框架實作的,需要我們自己編程實作的只有 mapping 和 reducing,這也就是 MapReduce 這個稱呼的來源,
Yarn資源調度
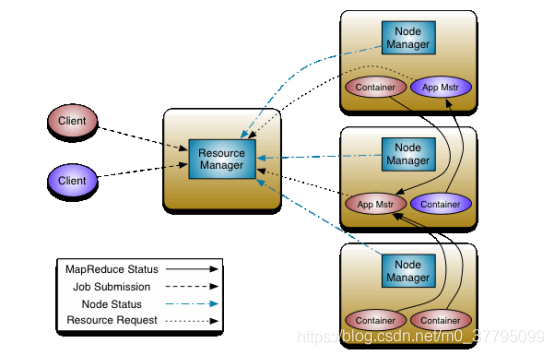
YARN 的基本思想是將資源管理和作業調度/監控的功能拆分為單獨的守護行程,
1. ResourceManager
ResourceManager 通常在獨立的機器上以后臺行程的形式運行,它是整個集群資源的主要協調者和管理者,ResourceManager 負責給用戶提交的所有應用程式分配資源,它根據應用程式優先級、佇列容量、ACLs、資料位置等資訊,做出決策,然后以共享的、安全的、多租戶的方式制定分配策略,調度集群資源,
2. NodeManager
NodeManager 是 YARN 集群中的每個具體節點的管理者,主要負責該節點內所有容器的生命周期的管理,監視資源和跟蹤節點健康,具體如下:
- 啟動時向
ResourceManager注冊并定時發送心跳訊息,等待ResourceManager的指令; - 維護
Container的生命周期,監控Container的資源使用情況; - 管理任務運行時的相關依賴,根據
ApplicationMaster的需要,在啟動Container之前將需要的程式及其依賴拷貝到本地,
3. ApplicationMaster
在用戶提交一個應用程式時,YARN 會啟動一個輕量級的行程 ApplicationMaster,ApplicationMaster 負責協調來自 ResourceManager 的資源,并通過 NodeManager 監視容器內資源的使用情況,同時還負責任務的監控與容錯,具體如下:
- 根據應用的運行狀態來決定動態計算資源需求;
- 向
ResourceManager申請資源,監控申請的資源的使用情況; - 跟蹤任務狀態和進度,報告資源的使用情況和應用的進度資訊;
- 負責任務的容錯,
4. Container
Container 是 YARN 中的資源抽象,它封裝了某個節點上的多維度資源,如記憶體、CPU、磁盤、網路等,當 AM 向 RM 申請資源時,RM 為 AM 回傳的資源是用 Container 表示的,YARN 會為每個任務分配一個 Container,該任務只能使用該 Container 中描述的資源,ApplicationMaster 可在 Container 內運行任何型別的任務,例如,MapReduce ApplicationMaster 請求一個容器來啟動 map 或 reduce 任務,而 Giraph ApplicationMaster 請求一個容器來運行 Giraph 任務,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/292661.html
標籤:其他