文章目錄
- 什么是ElasticSearch?
- Lucene
- ELK
- Elasticsearch的特點
- 應用場景
- 架構設計
- 基本概念
- 檔案
- 型別
- 索引
什么是ElasticSearch?

Elasticsearch是一個分布式的免費開源搜索和分析引擎,適用于包括文本、數字、地理空間、結構化和非結構化資料等在內的所有型別的資料,
Elasticsearch在Apache Lucene的基礎上開發而成,然而,Elasticsearch不僅僅是Lucene,并且也不僅僅只是一個全文搜索引擎, 它可以被下面這樣準確的形容:
- 一個分布式的實時檔案存盤,每個欄位都可以被索引與搜索
- 一個分布式實時分析搜索引擎
- 能勝任上百個服務節點的擴展,并支持PB級別的結構化或者非結構化資料
Lucene
Lucene是一套用于全文索引和搜索的開源程式庫,由Apache軟體基金會支持和提供,Lucene提供了一個簡單卻強大的應用程式介面,能夠做全文索引和搜索,但它不是一個完整的全文檢索引擎,而是一個全文檢索引擎的架構,提供了完整的查詢引擎和索引引擎,部分文本分析引擎(英文與德文兩種西方語言),
Lucene的目的是為軟體開發人員提供一個簡單易用的工具包,以方便的在目標系統中實作全文檢索的功能,或者是以此為基礎建立起完整的全文檢索引擎,
在Java開發環境里Lucene是一個成熟的免費開源工具,就其本身而言,Lucene是當前以及最近幾年最受歡迎的免費Java資訊檢索程式庫,人們經常提到資訊檢索程式庫,雖然與搜索引擎有關,但不應該將資訊檢索程式庫與搜索引擎相混淆,
ELK
Elastic Stack是一套適用于資料采集、擴充、存盤、分析和可視化的免費開源工具,人們通常將Elastic Stack稱為ELK Stack(代指 Elasticsearch、Logstash 和 Kibana),
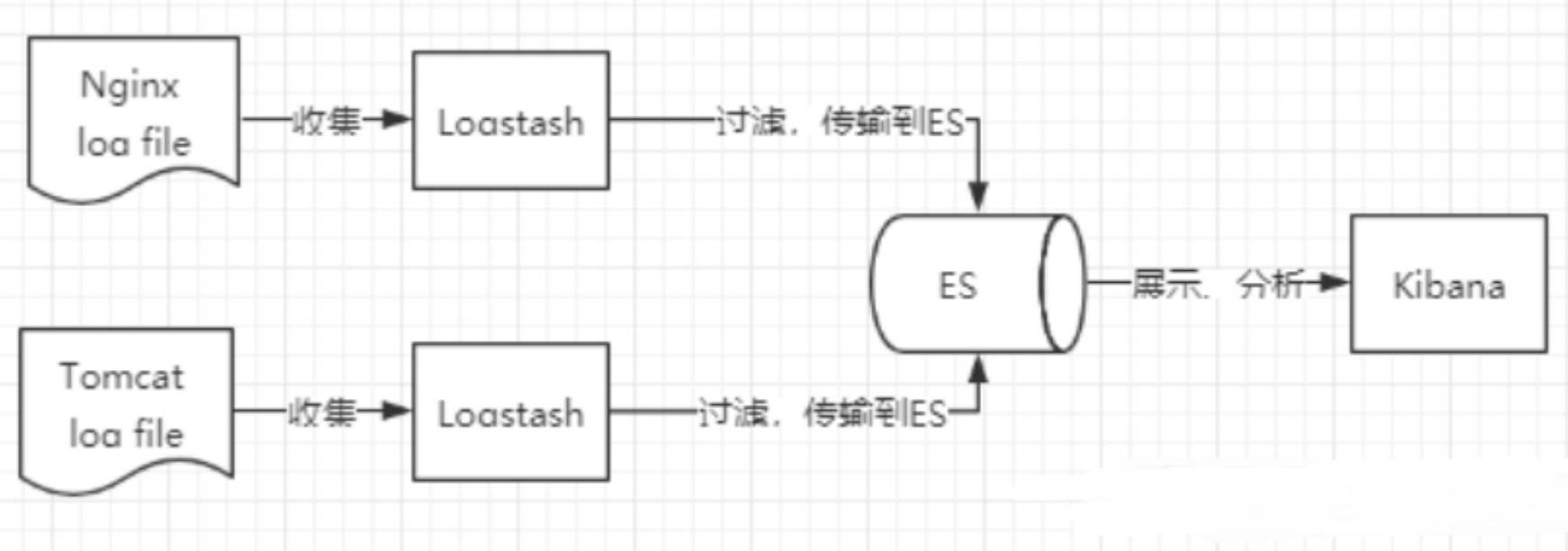
Logstash是什么?
Logstash 是 Elastic Stack 的核心產品之一,可用來對資料進行聚合和處理,并將資料發送到 Elasticsearch,Logstash 是一個開源的服務器端資料處理管道,允許您在將資料索引到 Elasticsearch 之前同時從多個來源采集資料,并對資料進行充實和轉換,
Kibana是什么?
Kibana 是一款適用于Elasticsearch的資料可視化和管理工具,可以提供實時的直方圖、線形圖、餅狀圖和地圖,Kibana同時還包括諸如 Canvas和Elastic Maps等高級應用程式
- Canvas允許用戶基于自身資料創建定制的動態資訊圖表,
- Elastic Maps用來對地理空間資料進行可視化,
Elasticsearch的特點
- Elasticsearch 很快, 由于Elasticsearch是在Lucene基礎上構建而成的,所以在全文本搜索方面表現十分出色,Elasticsearch同時還是一個近實時的搜索平臺,這意味著從檔案索引操作到檔案變為可搜索狀態之間的延時很短,一般只有一秒,因此,Elasticsearch 非常適用于對時間有嚴苛要求的用例,例如安全分析和基礎設施監測,
- Elasticsearch 具有分布式的本質特征,Elasticsearch中存盤的檔案分布在不同的容器中,這些容器稱為分片,可以進行復制以提供資料冗余副本,以防發生硬體故障,Elasticsearch的分布式特性使得它可以擴展至數百臺(甚至數千臺)服務器,并處理 PB 量級的資料,
- Elasticsearch 包含一系列廣泛的功能, 除了速度、可擴展性和彈性等優勢以外,Elasticsearch 還有大量強大的內置功能(例如資料匯總和索引生命周期管理),可以方便用戶更加高效地存盤和搜索資料,
- Elastic Stack 簡化了資料采集、可視化和報告程序, 通過與 Beats 和 Logstash 進行集成,用戶能夠在向 Elasticsearch 中索引資料之前輕松地處理資料,同時,Kibana 不僅可針對 Elasticsearch 資料提供實時可視化,同時還提供 UI 以便用戶快速訪問應用程式性能監測 (APM)、日志和基礎設施指標等資料,
應用場景
Elasticsearch在速度和可擴展性方面都表現出色,而且還能夠索引多種型別的內容,這意味著其可用于多種用例:
- 應用程式搜索
- 網站搜索
- 企業搜索
- 日志處理和分析
- 基礎設施指標和容器監測
- 應用程式性能監測
- 地理空間資料分析和可視化
- 安全分析
- 業務分析
架構設計
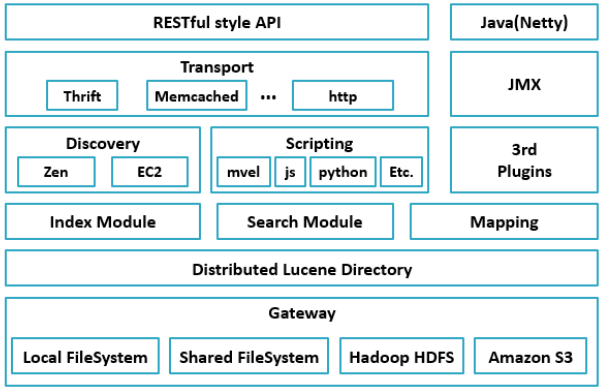
- Gateway:Elasticsearch用來存盤索引的檔案系統,支持多種型別,ElasticSearch默認先把索引存盤在記憶體中,然后當記憶體滿的時候,再持久化到Gateway里,當ES集群關倍訓重啟的時候,它就會從Gateway里去讀取索引資料,比如LocalFileSystem和HDFS、AS3等,
- DistributedLucene Directory:Lucene里的一些列索引檔案組成的目錄,它負責管理這些索引檔案,包括資料的讀取、寫入,以及索引的添加和合并等,
- Mapping:映射決議模塊,
- Search Moudle:搜索模塊,
- Index Moudle:索引模塊,
- Disvcovery:節點發現模塊,不同機器上的節點要組成集群需要進行訊息通信,集群內部需要選舉master節點,這些作業都是由Discovery模塊完成,支持多種發現機制,如 Zen 、EC2、gce、Azure,
- Scripting:Scripting用來支持在查詢陳述句中插入javascript、python等腳本語言,
- 3rd plugins:第三方插件,
- Transport:傳輸模塊,支持多種傳輸協議,如 Thrift、memecached、http,默認使用http,
- JMX:JMX是java的管理框架,用來管理ES應用,
- Java(Netty):java的通信框架,
- RESTful Style API:提供給用戶的介面,通過RESTful方式來實作API編程,
基本概念
Elasticsearch是一個檔案型資料庫,為了方便理解,下面給出其與傳統的關系型資料庫的對比
| Relational DB | Elasticsearch |
|---|---|
| 資料庫 Database | 索引 Index |
| 表 Table | 型別 Type |
| 行 Rows | 檔案 Document |
| 列 columns | 欄位 fields |
| 表結構 schema | 映射 mapping |
檔案
Elasticsearch是面向檔案的,索引和搜索資料的最小單位是檔案,并且使用JSON來作為檔案的序列化格式,每個檔案可以由一個或多個欄位組成,類似于關系型資料庫中的一行記錄,在Elasticsearch中,檔案有幾個重要屬性
- 自我包含:一篇檔案同時包含欄位和對應的值,
- 層次型:檔案中還可以包含新的檔案,一個欄位的取值也可以包含其他欄位和取值,
- 結構靈活:檔案不依賴預先定義的模式,在關系型資料庫中,要提前定義欄位才能使用,在Elasticsearch中,對于欄位是非常靈活的,有時候,我們可以忽略該欄位,或者動態的添加一個新的欄位,
盡管我們可以隨意的新增或者忽略某個欄位,但是,每個欄位的型別非常重要,比如一個年齡欄位型別,可以是字 串也可以是整形,因為Elasticsearch會保存欄位和型別之間的映射及其他的設定,這種映射具體到每個映射的每種型別,這也是為什么在Elasticsearch中,型別有時候也稱為映射型別,
型別
型別是檔案的邏輯容器,類似于表格是行的容器,在不同的型別中,最好放入不同結構的檔案,(有點類似于關系型資料庫中的表的概念),
每個型別中對于欄位的定義稱為映射,比如name欄位映射為string型別, 我們說檔案是無模式的,它們不需要擁有映射中所定義的所有欄位,例如我們可能會新增一個映射中不存在的欄位,那么Elasticsearch是怎么做的呢?
Elasticsearch會自動的將新欄位加入映射,由于不確定這個欄位是什么型別,Elasticsearch就會根據欄位的值來推導它的型別,如果這個值是10,那么Elasticsearch會認為它是整形, 但是這種推導也可能會存在問題,如果這里的10實際上是字串“10”,如果后續在索引字串“hello world”,就會因為型別不一致而導致索引失敗, 所以最安全的方式就是在索引資料之前,就定義好所需要的映射,這點跟關系型資料庫殊途同歸了,先定義好欄位,然后再使用,
映射型別只是將檔案進行邏輯劃分,從物理角度來看,同一索引的檔案都是寫入磁盤,而不考慮它們所屬的映射型別,
注意??:為什么ElasticSearch要在7.X版本去掉type?
在Elasticsearch設計初期,是直接查考了關系型資料庫的設計模式,存在了型別(表)的概念, 但是,其搜索引擎是基于Lucene的,這種基因決定了型別是多余的,Lucene的全文檢索功能之所以快,是因為倒序索引的存在, 而這種倒序索引的生成是基于索引的,而并非 型別,多個型別反而會減慢搜索的速度——兩個不同type下的兩個user_name,在ES同一個索引下其實被認為是同一個filed,你必須在兩個不同的type中定義相同的filed映射,否則,不同type中的相同欄位名稱就會在處理中出現沖突的情況,導致Lucene處理效率下降,
索引
在Elasticsearch中,索引有兩個含義:
- 名詞
- 索引是映射型別的容器,Elasticsearch中的索引是一個非常大的檔案集合,非常類似關系型資料庫中庫的概念,索引存盤了所有映射型別的欄位,
- 動詞
- 索引一個檔案就是存盤一個檔案到一個索引 (名詞)中以便被檢索和查詢,這非常類似于SQL中的
INSERT關鍵詞,不同的是檔案已存在時,新檔案會替換舊檔案(UPSERT),
- 索引一個檔案就是存盤一個檔案到一個索引 (名詞)中以便被檢索和查詢,這非常類似于SQL中的
在Elasticsearch中,索引使用了一種稱為倒排索引(即通過查詢詞索引到檔案)的結構,它適用于快速的全文搜索,一個倒排索引由檔案中所有不重復詞的串列構成,對于其中每個詞,有一個包含它的檔案串列,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/292664.html
標籤:其他
上一篇:大資料面試(一):Hive面試題
下一篇:Spark RDD