文章目錄
- 一、#Spark RDD概述
- 二、 RDD編程
- 1、編程模型
- 2、RDD的創建
- 3.RDD的轉換(Transformations)算子
- Value型別
- map(func)案例
- mapPartitions(func)案例
- map和mapPartition的區別
- mapPartitionsWithIndex(func)案例
- flatMap(func)案例
- glom案例
- groupBy(func)案例
- filter(func)案例
- distinct案例
- distinct案例 [重要]
- repartition(numPartitions) 案例
- coalesce(numPartitions)案例
- sortBy(func,[ascending],[numTasks]) 案例
- union(otherDataset)案例
- subtract (otherDataset) 案例
- intersection(otherDataset)案例
- Key-Value pair型別
- groupByKey案例
- reduceByKey(func, [numTasks])案例
- aggregateByKey案例
- sortByKey([ascending],[numTasks]) 案例
- mapValues案例
- join(otherDataset,[numTasks]) 案例
- 4.RDD的行動(Action)算子
- reduce(func)案例
- collect()案例
- count()案例
- first()案例
- take(n)案例
- takeOrdered(n)案例
- aggregate案例
- fold(num)(func)案例
- saveAsTextFile(path)
- saveAsSequenceFile(path)
- saveAsObjectFile(path)
- countByKey()案例
- foreach(func)案例
- 三、RDD相關概念
- RDD的依賴關系
- DAG
- RDD的快取
- RDD的checkpoint
- 四、Spark對外部資料庫的寫入
- MySQL資料庫
- HBase資料庫
- 五、RDD編程進階
- 1.累加器 accumulators
- 2.廣播變數
一、#Spark RDD概述
Resilient Distributed Dataset
http://spark.apache.org/docs/latest/rdd-programming-guide.html

二、 RDD編程
1、編程模型
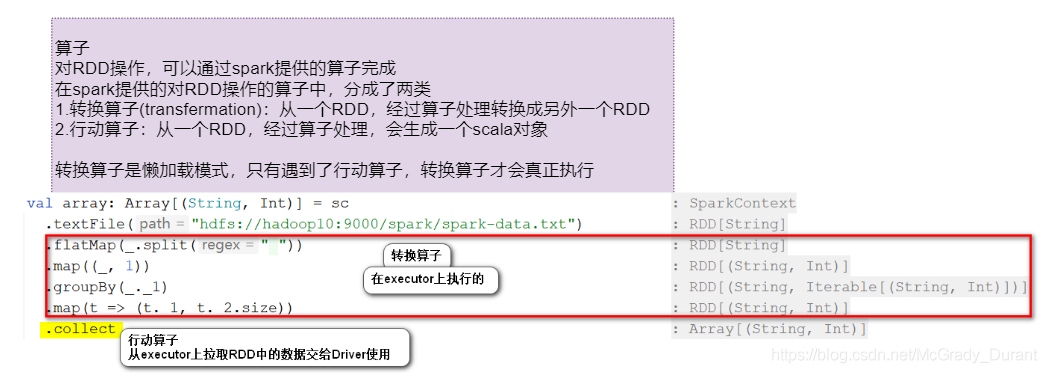
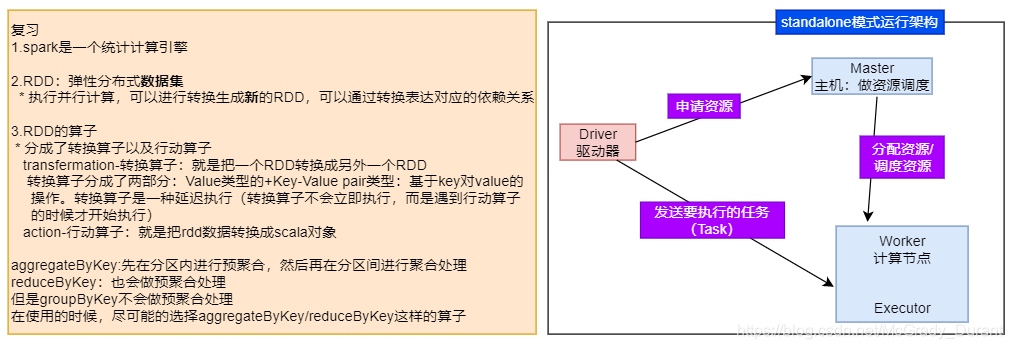
在Spark中,RDD被表示為物件,通過物件上的方法呼叫來對RDD進行轉換,經過一系列的transformations定義RDD之后,就可以呼叫actions觸發RDD的計算,action可以是向應用程式回傳結果(count, collect等),或者是向存盤系統保存資料(saveAsTextFile等),在Spark中,只有遇到action,才會執行RDD的計算(即延遲計算),這樣在運行時可以通過管道的方式傳輸多個轉換,
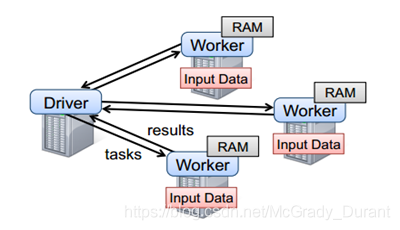
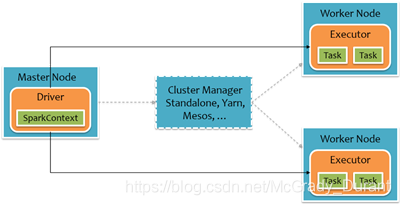
要使用Spark,開發者需要撰寫一個Driver程式,它被提交到集群以調度運行Worker,如下圖所示,Driver中定義了一個或多個RDD,并呼叫RDD上的action,Worker則執行RDD磁區計算任務,
2、RDD的創建
1)集合中創建;
2)從外部存盤創建RDD;
3)從其他RDD創建,

①從集合中創建RDD:parallelize和makeRDD
1)使用parallelize()從集合創建
scala> val rdd = sc.parallelize(Array(1,2,3,4,5,6,7,8))
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:24
2)使用makeRDD()從集合創建 (底層依舊呼叫parallelize)
scala> val rdd1 = sc.makeRDD(Array(1,2,3,4,5,6,7,8))
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[1] at makeRDD at <console>:24
② 由外部存盤系統的資料集創建
scala> val rdd2= sc.textFile("hdfs://spark1:9000/a.txt")
rdd2: org.apache.spark.rdd.RDD[String] = hdfs://spark1:9000/a.txt MapPartitionsRDD[1] at textFile at <console>:24
③ 從其他RDD創建
見轉換算子章節
3.RDD的轉換(Transformations)算子
RDD整體上分為Value型別和Key-Value型別
Value型別

map(func)案例
作用:回傳一個新的RDD,該RDD由每一個輸入元素經過func函式轉換后組成
需求:創建一個1-10陣列的RDD,將所有元素*2形成新的RDD
//1.創建一個RDD
val rdd1: RDD[Int] = sc.makeRDD(1 to 10)
//2.將所有元素*2
val rdd2: RDD[Int] = rdd1.map(_*2)
//3.在驅動程式中,以陣列的形式回傳資料集的所有元素
val arr: Array[Int] = rdd2.collect()
//4.輸出陣列中的元素
arr.foreach(println)
mapPartitions(func)案例
作用:類似于map,但獨立地在RDD的每一個磁區上運行,因此在型別為T的RDD上運行時,func的函式型別必須是Iterator[T] => Iterator[U],假設有N個元素,有M個磁區,那么map的函式的將被呼叫N次,而mapPartitions被呼叫M次,一個函式一次處理該磁區,
需求:創建一個RDD,使每個元素*2組成新的RDD
//1.創建一個RDD
val rdd1: RDD[Int] = sc.makeRDD(1 to 10)
//2.將所有元素*2
val rdd2: RDD[Int] = rdd1.mapPartitions(iter => {
iter.map(_ * 2)
})
//3.列印結果
rdd2.collect().foreach(println)
map和mapPartition的區別
map():每次處理一條資料,
mapPartition():每次處理一個磁區的資料
mapPartitionsWithIndex(func)案例
作用:類似于mapPartitions,但func帶有一個整數引數表示磁區的索引值,因此在型別為T的RDD上運 行時,func的函式型別必須是(Int, Interator[T]) => Iterator[U];
需求:創建一個RDD,使每個元素跟所在磁區形成一個元組組成一個新的RDD
//1.創建一個RDD
val rdd1: RDD[Int] = sc.makeRDD(1 to 10)
//2.使每個元素跟所在磁區形成一個元組組成一個新的RDD
val rdd2: RDD[(Int, Int)] = rdd1.mapPartitionsWithIndex((index, iter) => {
iter.map((index, _))
})
//3.列印新的RDD
rdd2.collect().foreach(println)
flatMap(func)案例
作用:類似于map,但是每一個輸入元素可以被映射為0或多個輸出元素(所以func應該回傳一個序 列,而不是單一元素)
需求:創建一個元素為1-5的RDD,運用flatMap創建一個新的RDD,新的RDD為(1,1, 2, 1, 2, 3, 1, 2, 3, 4, 1, 2, 3, 4, 5)
//1.創建一個RDD
val rdd1: RDD[Int] = sc.makeRDD(1 to 5)
//2.根據原RDD創建新RDD
val rdd2 = rdd1.flatMap(v => 1 to v)
//3.列印新的RDD
rdd2.collect().foreach(v=>{
print(v + " ")
})
glom案例
作用:將每一個磁區形成一個陣列,形成新的RDD型別是RDD[Array[T]]
需求:創建一個4個磁區的RDD,并將每個磁區的資料放到一個陣列
應用場景:計算RDD中的最大值
//1.創建一個RDD
val rdd1: RDD[Int] = sc.makeRDD(1 to 16,4)
//2.根據原RDD創建新RDD
val rdd2: RDD[Array[Int]] = rdd1.glom()
//3.列印
rdd2.collect().foreach(v=>{
println(v.mkString(","))
})
groupBy(func)案例
作用:分組,按照傳入函式的回傳值進行分組,將相同的key對應的值放入一個迭代器,
需求:創建一個RDD,按照元素模以2的值進行分組,
//1.創建一個RDD
val rdd1: RDD[Int] = sc.makeRDD(1 to 10)
//2.根據原RDD創建新RDD
val rdd2: RDD[(Int, Iterable[Int])] = rdd1.groupBy( v=> v%2)
//3.列印
rdd2.collect().foreach(println)
filter(func)案例
作用:過濾,回傳一個新的RDD,該RDD由經過func函式計算后回傳值為true的輸入元素組成,
需求:創建一個RDD(由字串組成),過濾出一個新RDD(包含”xiao”子串)
//1.創建一個RDD
val rdd1: RDD[String] = sc.makeRDD(List("xiaoming","zhangsan","xiaohong","lisi","wangxiao"))
//2.根據原RDD創建新RDD
val rdd2: RDD[String] = rdd1.filter(v=>v.contains("xiao"))
//3.列印
rdd2.collect().foreach(println)
distinct案例
作用:過濾,回傳一個新的RDD,該RDD由經過func函式計算后回傳值為true的輸入元素組成,
需求:創建一個RDD(由字串組成),過濾出一個新RDD(包含”xiao”子串)
//1.創建一個RDD
val rdd1: RDD[String] = sc.makeRDD(List("xiaoming","zhangsan","xiaohong","lisi","wangxiao"))
//2.根據原RDD創建新RDD
val rdd2: RDD[String] = rdd1.filter(v=>v.contains("xiao"))
//3.列印
rdd2.collect().foreach(println)
distinct案例 [重要]
作用:對源RDD進行去重后回傳一個新的RDD
需求:創建一個RDD,使用distinct()對其去重,
//1.創建一個RDD
val rdd1: RDD[Int] = sc.makeRDD(List(1,2,3,3,5,6,7,1,2,3))
//2.根據原有RDD去重,產生新的RDD
val rdd2: RDD[Int] = rdd1.distinct()
//3.列印
rdd2.collect().foreach(println)
repartition(numPartitions) 案例
作用:根據磁區數,重新通過網路隨機洗牌(shuffle)所有資料,
需求:創建一個4個磁區的RDD,對其重新磁區
//1.創建一個RDD
val rdd1: RDD[Int] = sc.makeRDD(1 to 10,4)
//2.重新磁區
val rdd2: RDD[Int] = rdd1.repartition(6)
//3.列印
println("磁區數:"+rdd2.getNumPartitions)
rdd2.collect()
coalesce(numPartitions)案例

作用:縮減磁區數,用于大資料集過濾后,提高小資料集的執行效率,
需求:創建一個4個磁區的RDD,對其縮減磁區
//1.創建一個RDD
val rdd1: RDD[Int] = sc.makeRDD(1 to 10,4)
//2.對RDD重新磁區
val rdd2: RDD[Int] = rdd1.coalesce(2)
//3.列印
println("磁區數:"+rdd2.getNumPartitions)
rdd2.collect()
sortBy(func,[ascending],[numTasks]) 案例
作用;使用func先對資料進行處理,按照處理后的資料比較結果排序,默認為正序,
需求:創建一個RDD,按照不同的規則進行排序
//1.創建一個RDD
val rdd1: RDD[Int] = sc.makeRDD(List(1,12,4,5,2))
//按照自身大小排序
val rdd2: RDD[Int] = rdd1.sortBy(v=>v)
rdd2.collect().foreach(println)
//按照與3余數的大小排序
val rdd3: RDD[Int] = rdd1.sortBy(v=>v%3)
rdd3.collect().foreach(println)
union(otherDataset)案例
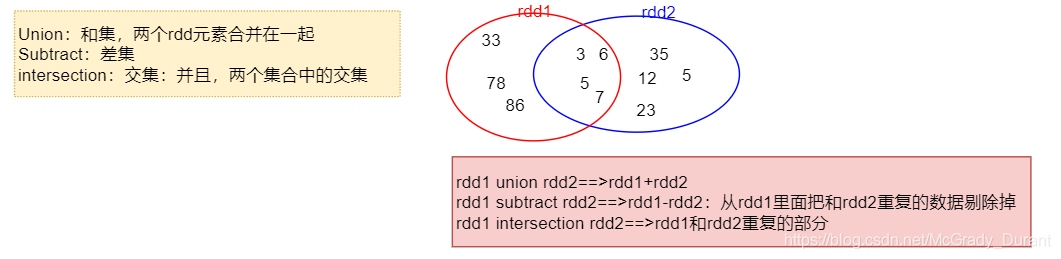
作用:對源RDD和引數RDD求并集后回傳一個新的RDD
需求:創建兩個RDD,求并集
//1.創建一個RDD
val rdd1: RDD[Int] = sc.makeRDD(1 to 5)
val rdd2: RDD[Int] = sc.makeRDD(4 to 8)
//2.計算兩個RDD的并集
val rdd3: RDD[Int] = rdd1.union(rdd2)
//3.列印
rdd3.collect().foreach(println)
subtract (otherDataset) 案例
作用:計算差的一種函式,從第一個RDD減去第二個RDD的交集部分
需求:創建兩個RDD,求第一個RDD與第二個RDD的差集
//1.創建一個RDD
val rdd1: RDD[Int] = sc.makeRDD(1 to 5)
val rdd2: RDD[Int] = sc.makeRDD(4 to 8)
//2.計算兩個RDD的差集
val rdd3: RDD[Int] = rdd1.subtract(rdd2)
//3.列印
rdd3.collect().foreach(println)
//結果:1 2 3
intersection(otherDataset)案例
作用:對源RDD和引數RDD求交集后回傳一個新的RDD
需求:創建兩個RDD,求兩個RDD的交集
//1.創建一個RDD
val rdd1: RDD[Int] = sc.makeRDD(1 to 5)
val rdd2: RDD[Int] = sc.makeRDD(4 to 8)
//2.計算兩個RDD的交集
val rdd3: RDD[Int] = rdd1.intersection(rdd2)
//3.列印
rdd3.collect().foreach(println)
//結果:4 5
Key-Value pair型別

groupByKey案例
作用:groupByKey也是對每個key進行操作,但只生成一個sequence,
需求:創建一個pairRDD,將相同key對應值聚合到一個sequence中, 并計算相同key對應值的相加結果,
//1.創建一個RDD
val rdd1: RDD[String] = sc.makeRDD(List("one", "two", "two", "three", "three", "three"))
//2.相同key對應值的相加結果
val rdd2: RDD[(String, Int)] = rdd1.map((_,1)).groupByKey().map(v=>(v._1,v._2.size))
//3.列印
rdd2.collect().foreach(println)
結果(three,3) (two,2) (one,1)
reduceByKey(func, [numTasks])案例
在一個(K,V)的RDD上呼叫,回傳一個(K,V)的RDD,使用指定的reduce函式,將相同key的值聚合到一起,reduce任務的個數可以通過第二個可選的引數來設定,
需求:創建一個pairRDD,計算相同key對應值的相加結果
//1.創建一個RDD
val rdd1: RDD[(String,Int)] = sc.makeRDD(List(("female",1),("male",5),("female",5),("male",2)))
//2.相同key對應值的相加結果
val rdd2: RDD[(String, Int)] = rdd1.reduceByKey(_+_)
//3.列印
rdd2.collect().foreach(println)
結果:(male,7) (female,6)
reduceByKey和groupByKey的區別
reduceByKey:按照key進行聚合,在shuffle之前有combine(預聚合)操作,回傳結果是RDD[k,v].
groupByKey:按照key進行分組,直接進行shuffle,
開發指導:reduceByKey比groupByKey,建議使用,但是需要注意是否會影響業務邏輯,
aggregateByKey案例
引數:(zeroValue:U,[partitioner: Partitioner]) (seqOp: (U, V) => U,combOp: (U, U) => U)
作用:在kv對的RDD中,,按key將value進行分組合并,合并時,將每個value和初始值作為seq函式的引數,進行計算,回傳的結果作為一個新的kv對,然后再將結果按照key進行合并,最后將每個分組的value傳遞給combine函式進行計算(先將前兩個value進行計算,將回傳結果和下一個value傳給combine函式,以此類推),將key與計算結果作為一個新的kv對輸出,
引數描述:
(1)zeroValue:給每一個磁區中的每一個key一個初始值;
(2)seqOp:函式用于在每一個磁區中用初始值逐步迭代value;
(3)combOp:函式用于合并每個磁區中的結果,
需求:創建一個pairRDD,取出每個磁區相同key對應值的最大值,然后相加
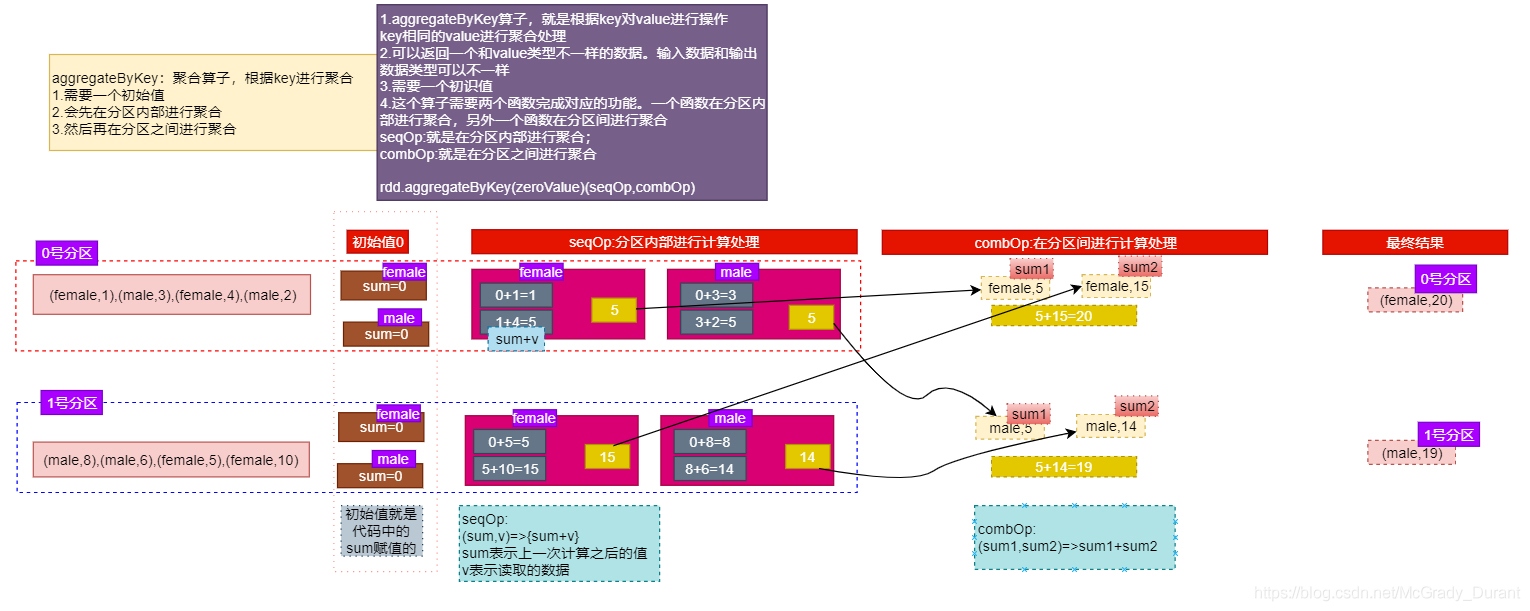
//1.創建一個RDD
val rdd1: RDD[(String,Int)] = sc.makeRDD(List(("a",3),("a",2),("c",4),("b",3),("c",6),("c",8)),2)
//2.取出每個磁區相同key對應值的最大值
val rdd2: RDD[(String, Int)] = rdd1.aggregateByKey(0)((v1,v2)=> if(v1 > v2) v1 else v2 ,_+_)
//3.列印
rdd2.collect().foreach(println)
結果:(b,3) (a,3) (c,12)
sortByKey([ascending],[numTasks]) 案例
作用:在一個(K,V)的RDD上呼叫,K必須實作Ordered介面,回傳一個按照key進行排序的(K,V)的RDD
需求:創建一個pairRDD,按照key的正序和倒序進行排序
//1.創建一個RDD
val rdd1: RDD[(Int,String)] = sc.makeRDD(List((3,"aa"),(6,"cc"),(2,"bb"),(1,"dd")))
//2.按照key的正序
rdd1.sortByKey(true).collect().foreach(print) //(1,dd)(2,bb)(3,aa)(6,cc)
//3.按照key的降序
rdd1.sortByKey(false).collect().foreach(print) //(6,cc)(3,aa)(2,bb)(1,dd)
mapValues案例
針對于(K,V)形式的型別只對V進行操作
需求:創建一個pairRDD,并將value添加字串"_x"
//1.創建一個RDD
val rdd1: RDD[(Int,String)] = sc.makeRDD(List((1,"a"),(1,"d"),(2,"b"),(3,"c")))
//2.給value增加一個_x
val rdd2: RDD[(Int, String)] = rdd1.mapValues(v=>v+"_x")
//3.列印
rdd2.collect().foreach(print)
結果 (1,a_x)(1,d_x)(2,b_x)(3,c_x)
join(otherDataset,[numTasks]) 案例
作用:在型別為(K,V)和(K,W)的RDD上呼叫,回傳一個相同key對應的所有元素對在一起的(K,(V,W))的RDD
需求:創建兩個pairRDD,并將key相同的資料聚合到一個元組,
//1.創建一個RDD
val rdd1: RDD[(Int,String)] = sc.makeRDD(List((1,"a"),(2,"b"),(3,"c")))
val rdd2: RDD[(Int,Int)] = sc.makeRDD(List((1,4),(2,5),(3,6)))
//2.join操作
val rdd3: RDD[(Int, (String, Int))] = rdd1.join(rdd2)
//3.列印
rdd3.collect().foreach(println)
結果:(1,(a,4))
(2,(b,5))
(3,(c,6))
4.RDD的行動(Action)算子
spark呼叫rdd的轉換算子,默認都是延遲執行的,只有呼叫行動算子才會觸發之前的轉換算子的呼叫
rdd呼叫轉換算子回傳的還是rdd物件,如果呼叫行動算子回傳的是scala物件
只有rdd才可以呼叫spark中的轉換或者行動算子
reduce(func)案例
作用:通過func函式聚集RDD中的所有元素,先聚合磁區內資料,再聚合磁區間資料,
需求:創建一個RDD,將所有元素聚合得到結果,
val rdd1 = sc.makeRDD(1 to 10)
println(rdd1.reduce(_ + _)) //輸出 55
val rdd2 = sc.makeRDD(Array(("a",1),("a",3),("c",3),("d",5)))
println(rdd2.reduce((v1, v2) => (v1._1 + v2._1, v1._2 + v2._2))) //輸出 (aacd,12)
collect()案例
作用:在驅動程式中,以陣列的形式回傳資料集的所有元素,
需求:創建一個RDD,并將RDD內容收集到Driver端列印
count()案例
作用:回傳RDD中元素的個數
需求:創建一個RDD,統計該RDD的條數
val rdd1 = sc.makeRDD(1 to 10)
println(rdd1.count()) //輸出 10
first()案例
作用:回傳RDD中的第一個元素
需求:創建一個RDD,回傳該RDD中的第一個元素
val rdd1 = sc.makeRDD(1 to 10)
println(rdd1.first())
take(n)案例
作用:回傳一個由RDD的前n個元素組成的陣列
需求:創建一個RDD,統計該RDD的條數
val rdd1 = sc.makeRDD(1 to 10)
println(rdd1.take(5).mkString(",")) //輸出:1,2,3,4,5
takeOrdered(n)案例
作用:回傳該RDD排序后的前n個元素組成的陣列
需求:創建一個RDD,統計該RDD的條數
val rdd = sc.parallelize(Array(2,5,4,6,8,3))
println(rdd.takeOrdered(3).mkString(",")) //輸出:2,3,4
aggregate案例
引數:(zeroValue: U)(seqOp: (U, T) ? U, combOp: (U, U) ? U)
作用:aggregate函式將每個磁區里面的元素通過seqOp和初始值進行聚合,然后用combine函式將每個磁區的結果和初始值(zeroValue)進行combine操作,這個函式最侄訓傳的型別不需要和RDD中元素型別一致,
fold(num)(func)案例
作用:折疊操作,aggregate的簡化操作,seqop和combop一樣,
需求:創建一個RDD,將所有元素相加得到結果
saveAsTextFile(path)
作用:將資料集的元素以textfile的形式保存到HDFS檔案系統或者其他支持的檔案系統,對于每個元素,Spark將會呼叫toString方法,將它裝換為檔案中的文本
對應讀取檔案的方法:sc.textFile("")
saveAsSequenceFile(path)
作用:將資料集中的元素以Hadoop sequencefile的格式保存到指定的目錄下,可以使HDFS或者其他Hadoop支持的檔案系統,
針對rdd中的元素是(k,v)格式的資料進行保存
sc.sequenceFile()可以讀取rdd.saveAsSequenceFile()保存的資料
saveAsObjectFile(path)
作用:用于將RDD中的元素序列化成物件,存盤到檔案中,
對保存的資料進行序列化
sc.objectFile("")
countByKey()案例
作用:針對(K,V)型別的RDD,回傳一個(K,Int)的map,表示每一個key對應的元素個數,
需求:創建一個PairRDD,統計每種key的個數
val rdd = sc.parallelize(List((1,3),(1,2),(1,4),(2,3),(3,6),(3,8)))
val map: collection.Map[Int, Long] = rdd.countByKey()
println(map)
輸出:Map(1 -> 3, 2 -> 1, 3 -> 2)
foreach(func)案例
作用:在資料集的每一個元素上,運行函式func進行更新,
需求:創建一個RDD,對每個元素進行列印
三、RDD相關概念
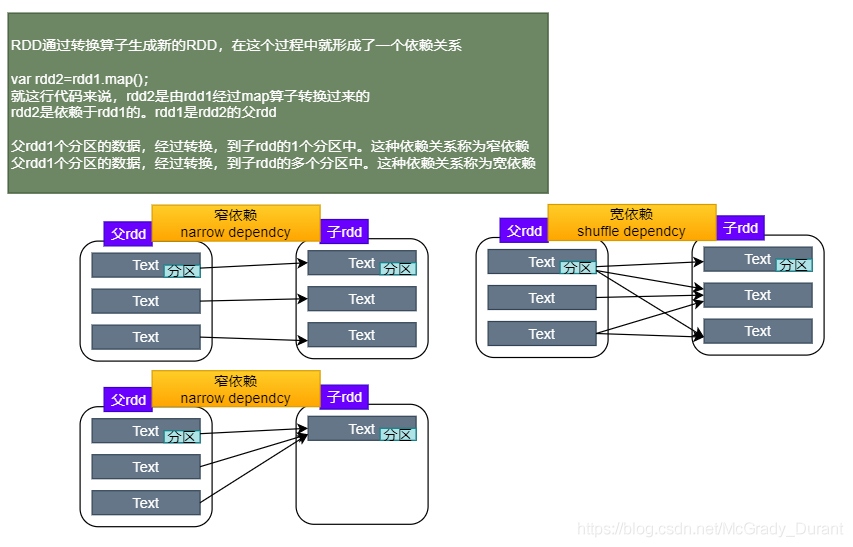
RDD的依賴關系
RDD依賴關系也稱為RDD的血統,描述了RDD間的轉換關系 ,Spark將RDD間依賴關系分為了寬依賴|ShuffleDependency、窄依賴|NarrowDependency,Spark在提交任務的時候會根據轉換算子逆向推匯出所有的Stage,然后計算推導的stage的磁區用于表示該Stage執行的并行度,
窄依賴:
-
父RDD和子RDD partition之間的關系是一對一的,或者父RDD一個partition只對應一個子RDD的partition情況下的父RDD和子RDD partition關系是多對一的,不會有shuffle的產生,父RDD的一個磁區去到子RDD的一個磁區,
-
可以理解為獨生子女
寬依賴:
-
父RDD與子RDD partition之間的關系是一對多,會有shuffle的產生,父RDD的一個磁區的資料去到子RDD的不同磁區里面,
-
可以理解為超生
DAG
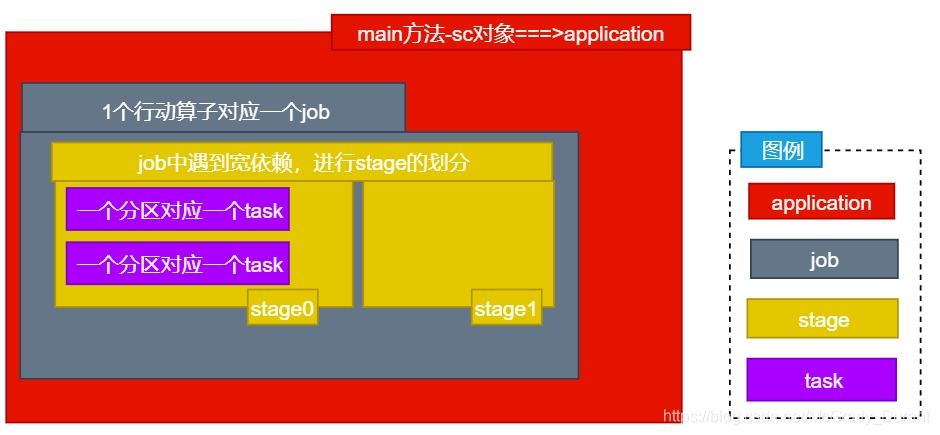
DAG(Directed Acyclic Graph)叫做有向無環圖,原始的RDD通過一系列的轉換就就形成了DAG,根據RDD之間的依賴關系的不同將DAG劃分成不同的Stage,對于窄依賴,partition的轉換處理在Stage中完成計算,對于寬依賴,由于有Shuffle的存在,只能在parent RDD處理完成后,才能開始接下來的計算,因此寬依賴是劃分stage的依據,
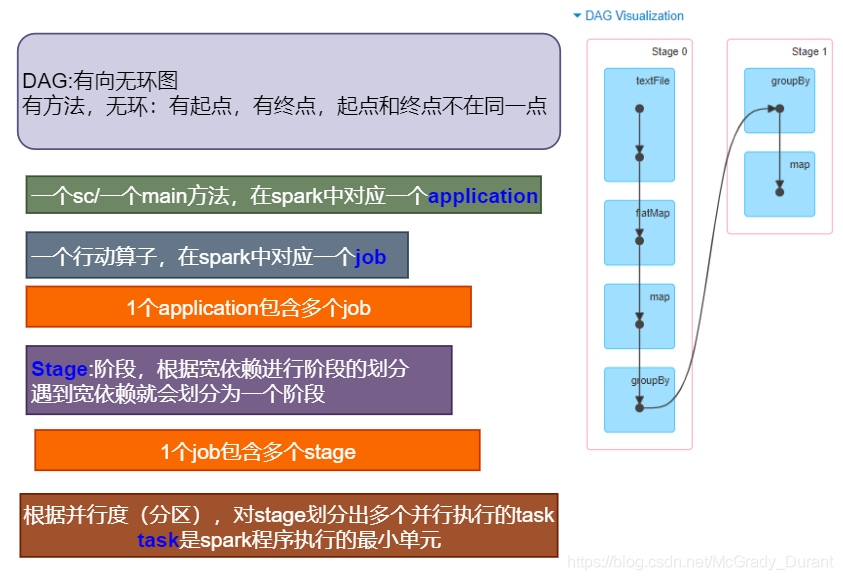
任務劃分
RDD任務切分中間分為:Application、Job、Stage和Task
1)Application:初始化一個SparkContext即生成一個Application
2)Job:一個Action算子就會生成一個Job
3)Stage:根據RDD之間的依賴關系的不同將Job劃分成不同的Stage,遇到一個寬依賴則劃分一個Stage,
4)Task:Stage是一個TaskSet,將Stage劃分的結果發送到不同的Executor執行即為一個Task,
注意:Application->Job->Stage-> Task每一層都是1對n的關系,
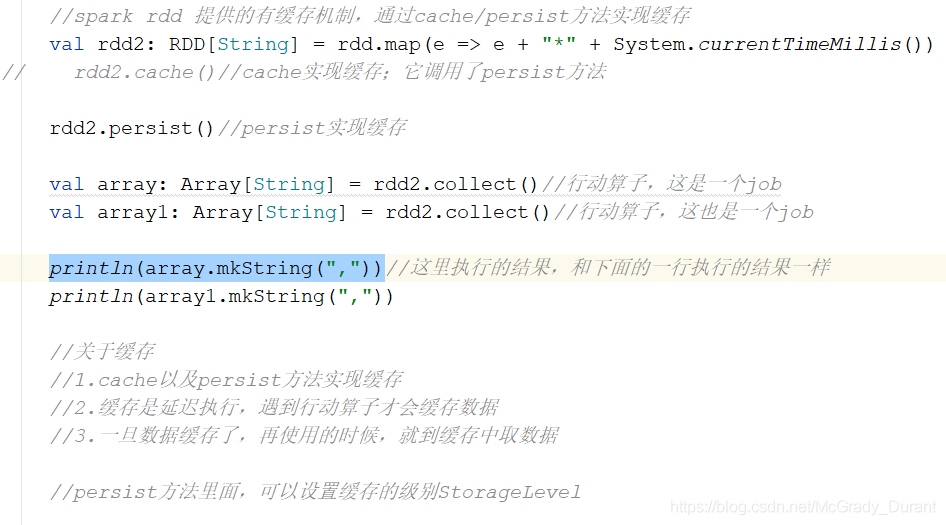
RDD的快取
RDD通過persist方法或cache方法可以將前面的計算結果快取,默認情況下 persist() 會把資料快取在 JVM 的堆空間中,
但是并不是這兩個方法被呼叫時立即快取,而是觸發后面的action時,該RDD將會被快取在計算節點的記憶體中,并供后面重用,
val rdd1: RDD[String] = sc.makeRDD(List("zhangsan"))
val rdd2: RDD[String] = rdd1.map(_ + System.currentTimeMillis()).cache()
rdd2.foreach(println)
rdd2.foreach(println) //兩次列印結果相同
RDD的checkpoint
Spark中對于資料的保存除了持久化操作之外,還提供了一種檢查點的機制,檢查點(本質是通過將RDD寫入Disk做檢查點)是為了通過lineage做容錯的輔助,lineage過長會造成容錯成本過高,這樣就不如在中間階段做檢查點容錯,如果之后有節點出現問題而丟失磁區,從做檢查點的RDD開始重做Lineage,就會減少開銷,檢查點通過將資料寫入到HDFS檔案系統實作了RDD的檢查點功能,
為當前RDD設定檢查點,該函式將會創建一個二進制的檔案,并存盤到checkpoint目錄中,該目錄是用SparkContext.setCheckpointDir()設定的,在checkpoint的程序中,該RDD的所有依賴于父RDD中的資訊將全部被移除,對RDD進行checkpoint操作并不會馬上被執行,必須執行Action操作才能觸發,
sc.setCheckpointDir("hdfs://spark1:9000/rdd-checkpoint")
val rdd1: RDD[String] = sc.makeRDD(List("zhangsan"))
val rdd2: RDD[String] = rdd1.map(_ + System.currentTimeMillis())
rdd2.checkpoint() //此處可以通過查看checkpoint方法的注釋了解它的運行機制
rdd2.collect().foreach(println) //zhangsan1588656910532
rdd2.collect().foreach(println) //zhangsan1588656910641
rdd2.collect().foreach(println) //zhangsan1588656910641

四、Spark對外部資料庫的寫入
MySQL資料庫
① 添加依賴
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.38</version>
</dependency>
② 將spark計算的資料寫入mysql
val data = sc.parallelize(List("zhangsan", "lisi","wangwu"),2)
data.foreachPartition(iter=>{
val conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/test1","root","123456")
iter.foreach(data=>{
val ps = conn.prepareStatement("insert into spark_user(name) values (?)")
ps.setString(1, data)
ps.executeUpdate()
})
conn.close()
})
sql陳述句:
create table spark_user(
id int primary key auto_increment,
name varchar(50)
)
HBase資料庫
①. 添加依賴
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.9.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-auth</artifactId>
<version>2.9.0</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>1.5.0</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>1.5.0</version>
</dependency>
②. 將spark計算結果添加到hbase中
create_namespace “baizhi” 在hbase中提前創建namespace
create “baizhi:spark_fruit”,“info” 在namespace下創建表
val rdd = sc.parallelize(List((1,"蘋果",11), (2,"香蕉",12), (3,"梨",13)))
// 批量插入
rdd.foreachPartition(x => {
val conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum","spark1");
val conn = ConnectionFactory.createConnection(conf);
val table = conn.getTable(TableName.valueOf("baizhi:spark_fruit"))
val puts = new java.util.ArrayList[Put]()
x.foreach(y => {
// 將陣列插入hbase
val wordPut = new Put(Bytes.toBytes(y._1))
wordPut.addColumn(Bytes.toBytes("info"), Bytes.toBytes("name"), Bytes.toBytes(y._2))
wordPut.addColumn(Bytes.toBytes("info"), Bytes.toBytes("price"), Bytes.toBytes(y._3))
puts.add(wordPut)
})
table.put(puts)
})
③. 讀取hbase中的資料
val hadoopConfig = new Configuration()
hadoopConfig.set(HConstants.ZOOKEEPER_QUORUM,"spark1")//配置Hbase連接引數
hadoopConfig.set(TableInputFormat.INPUT_TABLE,"baizhi:spark_fruit") //配置掃描的表
sc.newAPIHadoopRDD(hadoopConfig,classOf[TableInputFormat],classOf[ImmutableBytesWritable],classOf[Result])
.map(t=>{
var rowKey=Bytes.toInt(t._1.get())
var name=Bytes.toString(t._2.getValue("info".getBytes(),"name".getBytes()))
var price=Bytes.toInt(t._2.getValue("info".getBytes(),"price".getBytes()))
(rowKey,name,price)
}).collect()
.foreach(t=>{
println(t)
})
五、RDD編程進階

1.累加器 accumulators
如果在Driver定義了變數,下游的算子在使用Driver變數的時候會通過網路下載Driver的變數,因此定義在Driver的變數一般的是只讀的,并且支持序列化,

//1.創建SparkContext
val sparkConf = new SparkConf()
.setMaster("local[*]")
.setAppName("wordcount")
val sc=new SparkContext(sparkConf)
var count=0
sc.makeRDD(List(1,2,3,4,5))
.foreach(item=> count += item)//并行執行 遠程復制count變數,只是修改遠程變數
println(s"count:${count}") //0
//4.關閉SparkContext
sc.stop();
以上因為count變數定義在Driver中,foreach算子是并行執行的算子,遠程的Task會向Driver下載變數count,所有下游的Task都存盤了count變數的副本,因此拿到都是0.當Task結束后遠程count變數的值并不會傳遞給Driver,因此count最后依然是0.如果定義如下:
var count=0
sc.makeRDD(List(1,2,3,4,5))
.collect()//把RDD拿到Driver端,后續的foreach并不是并行執行
.foreach(item=> count += item) //count = 15
Spark提供了**accumulators(累加器)**專門用于Driver端和Task端傳遞計數變數,
var count=sc.longAccumulator("a1")//long 型別的累加器
sc.makeRDD(List(1,2,3,4,5)).foreach(item=> count.add(item))
println(count.value) //15
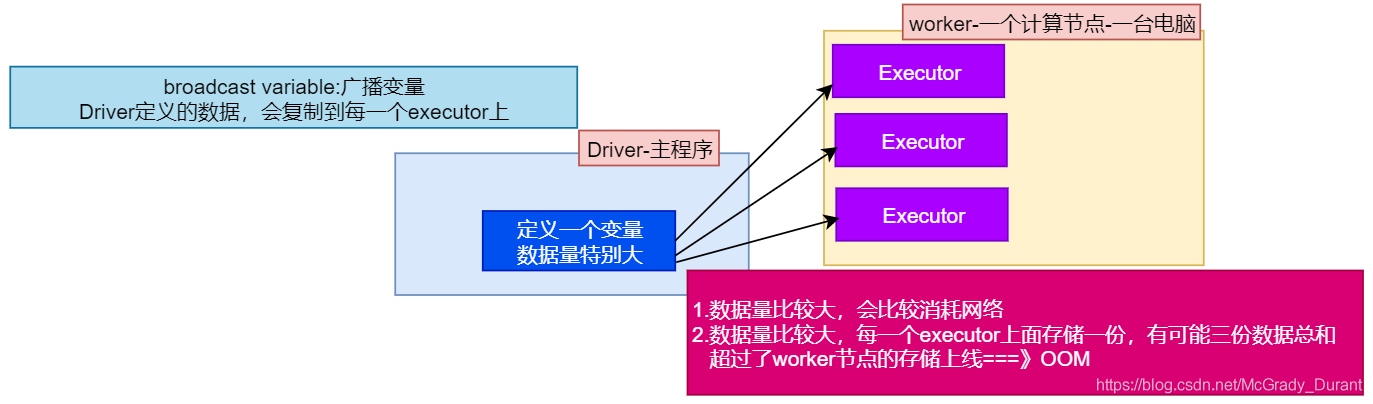
2.廣播變數
如果你的算子函式中,使用到了特別大的資料,那么,這個時候,推薦將該資料進行廣播,這樣的話,就不至于將一個大資料拷貝到每一個task上去,而是給每個節點拷貝一份,然后節點上的task共享該資料,這樣的話,就可以減少大資料在節點上的記憶體消耗,并且可以減少資料到節點的網路傳輸消耗,
需求:讀取檔案中的單詞,然后進行篩選,最終保留的資料為Set集合中規范的,
//定義一個set集合
val set = Set("hello","hehe")//資料量比較大
//從hfds讀取檔案,創建RDD
val rdd1: RDD[String] = sc.textFile("hdfs://spark1:9000/a.txt")
//對讀取的單詞執行flatMap操作,并且進一步篩選,最終保留set集合中規范的資料
rdd1.flatMap(_.split(" ")).filter(v=>{
set.contains(v)
}).collect().foreach(println)
使用broadcast改造上述代碼
//定義一個set集合
val set = Set("hello","hehe")
//通過set集合 創建廣播變數
val broadCast: Broadcast[Set[String]] = sc.broadcast(set)
//從hfds讀取檔案,創建RDD
val rdd1: RDD[String] = sc.textFile("hdfs://spark1:9000/a.txt")
//對讀取的單詞執行flatMap操作,并且進一步篩選,最終保留set集合中規范的資料
rdd1.flatMap(_.split(" ")).filter(v=>{
//通過廣播變數獲取set集合
broadCast.value.contains(v)
}).collect().foreach(println)

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/292665.html
標籤:其他