ElasticSearch
- ElasticSearch
- ElasticSearch與Lucene
- Lucene缺點
- ES vs Solr
- ES與關系型資料庫
- 全文檢索
- 什么是全文檢索
- 倒排索引
- Elasticsearch中的核心概念
- 索引 index
- 映射Mapping
- 欄位Field
- 欄位型別 Type
- 檔案 document
- 集群 cluster
- 節點 node
- 分片
- 副本
- windows安裝ElasticSearch
- window下載kibana客戶端
- ES命令
- 查看分詞效果_analyze
- 索引操作
- 檔案操作
ElasticSearch
- ElasticSearch使用Java開發并且是當前最流行的ElasticSearch企業級搜索引擎;
- 能夠達到實時搜索,穩定,可靠,快速,安裝使用方便,
- 客戶端支持Java、.NET(C#)、PHP、Python、Ruby等多種語言,
- 官網:: https://www.elastic.co/
- 下載地址::https://www.elastic.co/cn/start
ElasticSearch與Lucene
Lucene是性能最好,最先進,功能最全的搜索引擎框架,但是想要使用Lucene,必須使用Java作為開發語言并將其集成到你的應用中,且其配置與使用復雜,需要深入了解其是如何作業的,
Lucene缺點
- 只能在Java專案中使用,要以jar包集成到專案中,
- 不支持集群環境-索引資料不同步
- 使用復雜
- 索引資料如果太多就不行,索引庫和應用所在同一個服務器,共同占用硬碟.共用空間少.
這些缺點ES都能解決,ES底層對Lucene進行封裝與改進,達到更好的效果,
ES vs Solr
當單純的對已有資料進行搜索時,Solr更快,
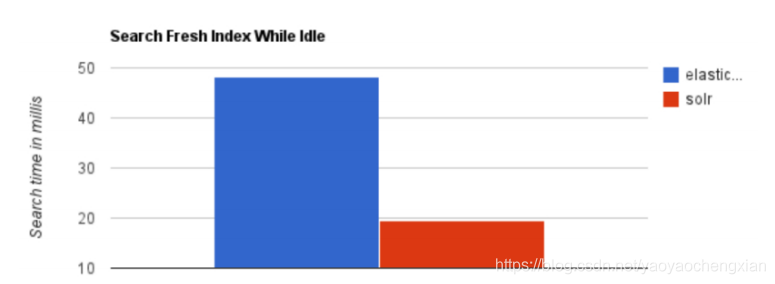
當實時建立索引時, Solr會產生io阻塞,查詢性能較差, Elasticsearch具有明顯的優勢,
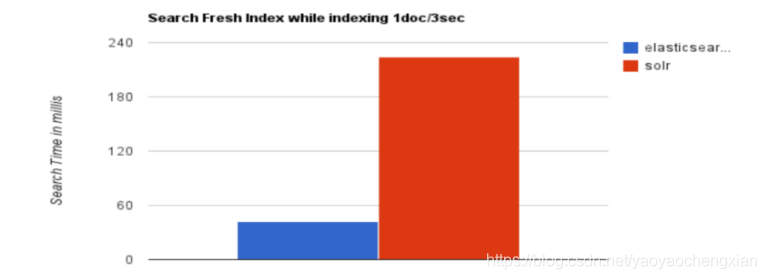
- Solr使用Zookeeper進行分布式管理,而ElasticSearch本事帶有分布式協調管理功能
- Solr 支持更多格式的資料,比如JSON、XML、CSV,而 Elasticsearch 僅支持json檔案格式,
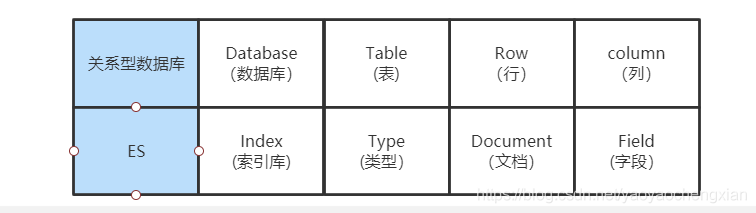
ES與關系型資料庫
全文檢索
什么是全文檢索
- 通過一個程式掃描文本的每一個單詞,針對單詞建立索引,并保存該單詞在文本中的位置,以及出現的次數,
- 用戶查詢時,通過之前建立好的索引來查詢,將索引中單詞對應的文本位置,出現的次數回傳給用戶,因為有了具體文本的位置,就可以將具體的內容讀取出來了,
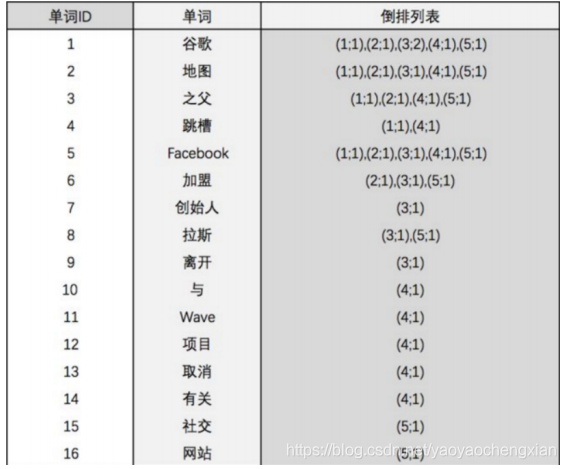
倒排索引
針對一組資料,首先會進行分詞、再進行去重,最后進行排序,這樣,一張由資料到索引的映射關系表就形成了,
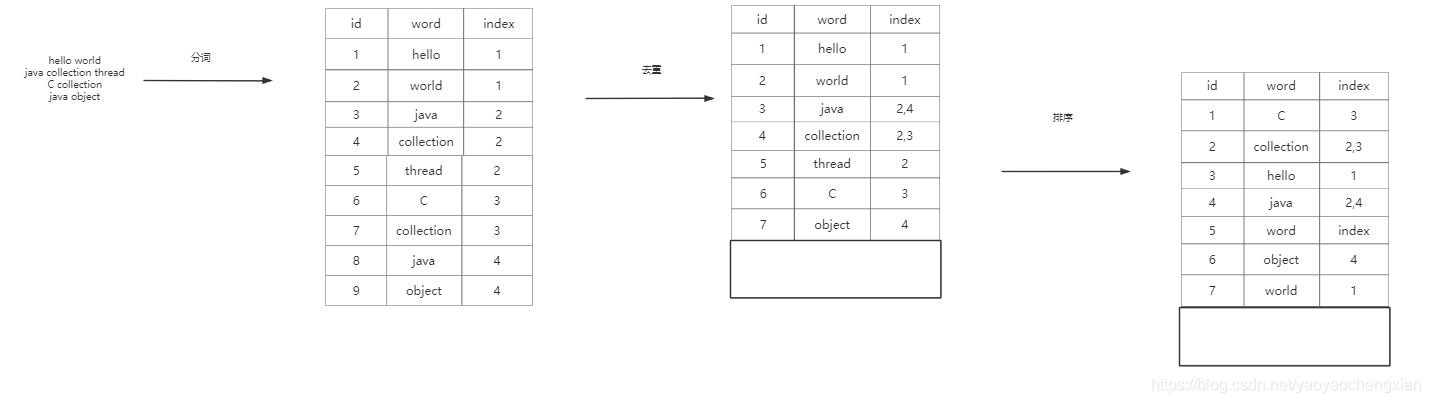
再看一個實體

以下的倒排串列中不僅包含了資料出現的位置,還包含了包含資料的次數,
Elasticsearch中的核心概念
索引 index
- 一個索引就是一個擁有幾份相似特征的檔案的集合,
- 比如說,可以有一個客戶資料的索引,另一個產品目錄的索引,還有一個訂單資料的索引,
- 一個索引由一個名字來標識(必須全是小寫字母),并且當我們要對索引中的檔案進行操作時,都需要用到索引名,
映射Mapping
- 用來定義一個檔案
- mapping是處理資料的方式和規則方面做一些限制,如某個欄位的資料型別、默認值、分詞器、是否被索引等等,這些都是映射里面可以設定的
欄位Field
相當于是資料表的欄位/列
欄位型別 Type
每一個欄位都應該有一個對應的型別,例如:Text、Keyword、Byte等
檔案 document
一個檔案是一個可被索引的基礎資訊單元、類似一條記錄,檔案以JSON格式來標識,
集群 cluster
一個集群就是由一個或多個節點組織在一起,它們共同持有整個的資料,并一起提供索引和搜索功能
節點 node
- 一個節點是集群中的一個服務器,作為集群的一部分,它存盤資料,參與集群的索引和搜索功能
- 一個節點可以通過配置集群名稱的方式來加入一個指定的集群,默認情況下,每個節點都會被安排加入到一個叫做“elasticsearch”的集群中,
- 這意味著,如果在網路中啟動了若干個節點,并假定它們能夠相互發現彼此,它們將會自動地形成并加入到一個叫做“elasticsearch”的集群中
- 在一個集群里,可以擁有任意多個節點,而且,如果當前網路中沒有運行任何Elasticsearch節點,這時啟動一個節點,會默認創建并加入一個叫做“elasticsearch”的集群,
分片
- 一個索引可以存盤超出單個結點硬體限制的大量資料,比如,一個具有10億檔案的索引占據1TB的磁盤空間,而任一節點都沒有這樣大的磁盤空間;或者單個節點處理搜索請求,回應太慢
- 為了解決這個問題,Elasticsearch提供了將索引劃分成多份的能力,這些份就叫做分片
- 當創建一個索引的時候,可以指定你想要的分片的數量
- 每個分片本身也是一個功能完善并且獨立的“索引”,這個“索引”可以被放置到集群中的任何節點上
- 分片很重要,主要有兩方面的原因:允許水平分割/擴展你的內容容量;允許在分片之上進行分布式的、并行的操作,進而提高性能/吞吐量
- 至于一個分片怎樣分布,它的檔案怎樣聚合回搜索請求,是完全由Elasticsearch管理的,對于作為用戶來說,這些都是透明的
副本
- 在一個網路/云的環境里,失敗隨時都可能發生,在某個分片/節點不知怎么的就處于離線狀態,或者由于任何原因消失了,這種情況下,有一個故障轉移機制是非常有用并且是強烈推薦的,
- 為此目的,Elasticsearch允許你創建分片的一份或多份拷貝,這些拷貝叫做副本分片,或者直接叫副本
- 副本之所以重要,有兩個主要原因
- 在分片/節點失敗的情況下,提供了高可用性,
注意到復制分片從不與原/主要(original/primary)分片置于同一節點上是非常重要的 - 擴展搜索量/吞吐量,因為搜索可以在所有的副本上并行運行,
每個索引可以被分成多個分片,一個索引有0個或者多個副本
一旦設定了副本,每個索引就有了主分片和副本分片,分片和副本的數量可以在索引創建的時候指定,
在索引創建之后,可以在任何時候動態地改變副本的數量,但是不能改變分片,的數量
windows安裝ElasticSearch
網站:https://www.elastic.co/cn/downloads/elasticsearch;
- 安裝Window版本、下載完解壓到本地即可,
- 進入bin目錄、點擊elasticsearch.bat檔案運行
- 打開瀏覽器輸入網站:localhost:9200;
- 出現下面結果、則成功

window下載kibana客戶端
-
. 進入官網https://www.elastic.co/cn/downloads/kibana,下載Window版本
-
解壓到本地,
-
進入bin目錄、運行kibana.bat檔案,
-
瀏覽器中輸入localhost:5601
-
出現下面結果則運行成功:
-
目錄下找到devtools,在這里練習使用es操作,
有需要的可以去下載IK分詞器,只需要下載解壓到ES的plugins目錄下即可,但是最好保持版本一直,不然容易閃退,
ES命令
通過使用kibana的網頁DevTools功能來測驗命令,
查看分詞效果_analyze
POST _analyze
{
"analyzer" : "standard",
"text" : "我愛你Chinese"
}
結果

如果你下載了IK分詞器、可使用其兩種分詞效果
POST _analyze
{
"analyzer" : "ik_smart",
"text" : "我愛你Chinese"
}
POST _analyze
{
"analyzer" : "ik_max_word",
"text" : "我愛你Chinese"
}
- ES的默認分詞器為Standard.
這個在中文分詞時就比較尷尬了,會單字拆分,比如我搜索關鍵詞“清華大學”,這時候會按“清”,“華”,“大”,“學”去分詞,然后搜出來的都是些“清清的河水”,“中華兒女”,“地大物博”,“學而不思則罔”之類的莫名其妙的結果. - 可以使用IK分詞器進行分詞
兩種ik_smart和ik_max_word;
ik_smart會將“清華大學”整個分為一個詞、最粗粒度,
ik_max_word會將“清華大學”分為“清華大學”,“清華”和“大學”,按需選其中之一就可以了,
修改默認分詞方法(這里修改school_index索引的默認分詞為:ik_max_word)
PUT /schoole_index
{
"settings": {
"index":{
"analysis.analyzer.default.type": "ik_max_word"
}
}
}
MySQL檔案格式是JSON型別
{
"email":"123",
"name":"123",
"age":10
}
索引操作
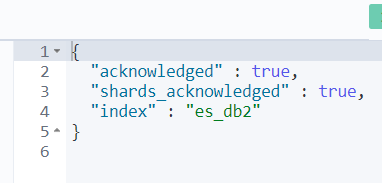
- 創建索引
格式:PUT /索引名稱
PUT /es_db
- 查詢索引
格式:GET /索引名稱
GET /es_db

- 洗掉索引
格式:DELETE /索引名稱
DELETE /es_db
檔案操作
- 添加
格式: PUT /索引名稱/型別/id
PUT /es_db/_doc/1
{
"name": "yaoyang",
"age": 20,
"sex": 1
}
PUT /es_db/_doc/2
{
"name": "yaoyao",
"age": 15,
"sex": 2
}
PUT /es_db/_doc/3
{
"name": "yangguo",
"age": 25,
"sex": 1,
"address": "donghu"
}
PUT /es_db/_doc/4
{
"name": "yaoguai",
"age": 1000,
"sex": 1
}
PUT /es_db/_doc/5
{
"name": "yaoxian",
"age": 19,
"sex": 1
}
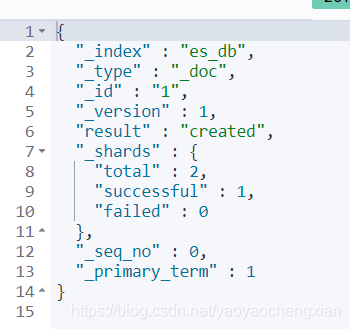
- 修改檔案
格式:PUT /索引名稱/型別/id
put /es_db/_doc/1
{
"name":"白起",
"age":30,
"sex":0
}
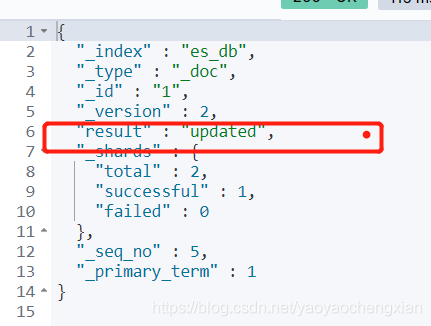
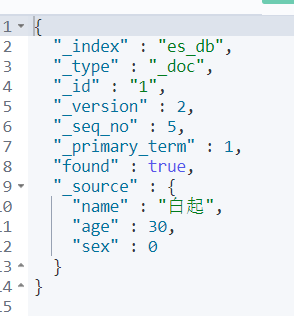
- 查詢檔案
GET /索引名稱/型別/id
GET /es_db/_doc/1
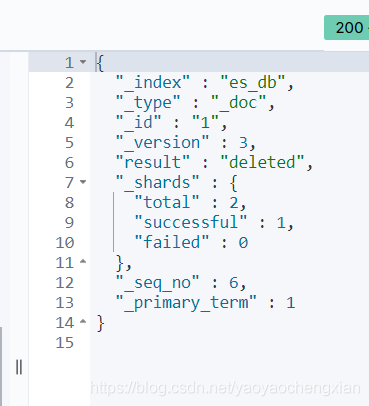
- 洗掉檔案
格式: DELETE /索引名稱/型別/id
Delete /es_db/_doc/1
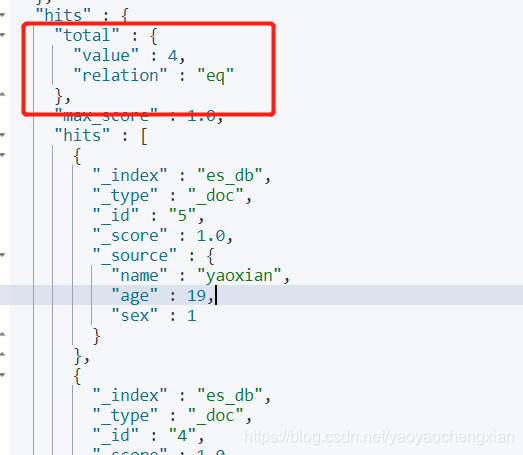
- 查詢索引庫下的某型別中的所有檔案
格式: get /索引名/_search
get /es_db/_search
- 條件等值查詢
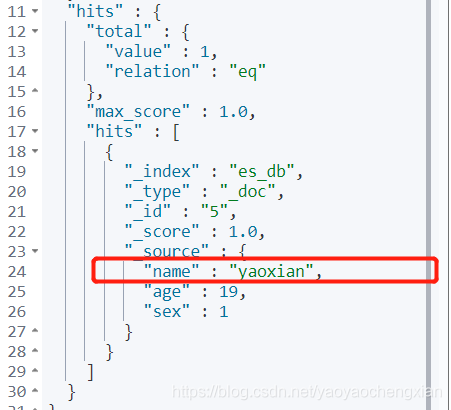
格式: GET /索引名稱/型別/_search?q=:**
GET /es_db/_doc/_search?q=age:19
- 范圍查詢1
格式: GET /索引名稱/型別/_search?q=***[ start TO end ]
GET /es_db/_doc/_search?q=age[20 TO 27]

- 范圍查詢2: >= ,<=
查詢年齡小于等于20歲的 :<=
GET /es_db/_doc/_search?q=age:<=20

- 多個ID批量查詢_mget
格式: GET /索引名稱/型別/_mget
GET /es_db/_doc/_mget
{
"ids" : [2,3]
}
//SQL: select * from student where id in (1,2)

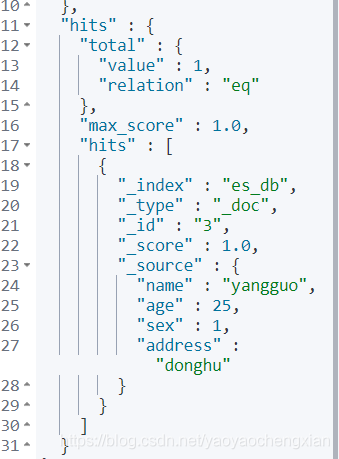
- 分頁查詢 from=&size=
格式: GET /索引名稱/型別/_search?q=age[25 TO 26]&from=0&size=1
GET /es_db/_doc/_search?q=age[25 TO 26]&from=0&size=1
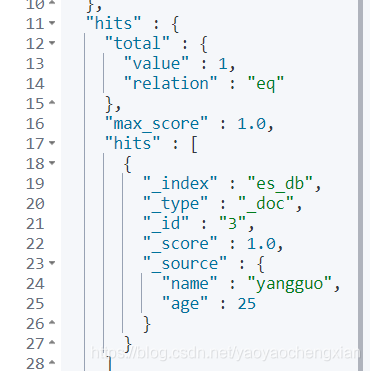
- 只查詢某些欄位 _source
格式: GET /索引名稱/型別/_search?_source=欄位,欄位
GET /es_db/_doc/_search?_source=name,age&&q=age[25 TO 26]&from=0&size=1
- 查詢結果排序 sort=欄位:desc/asc
格式: GET /索引名稱/型別/_search?sort=欄位 desc
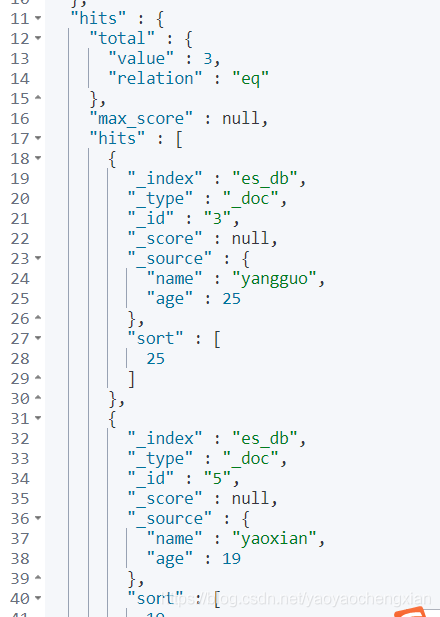
GET /es_db/_doc/_search?_source=name,age&&q=age[10 TO 50]&from=0&size=10&&sort=age:desc
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/292670.html
標籤:其他
下一篇:分布式搜索引擎ElasticSearch(三)---ElasticSearch進階使用、深入理解搜索技術、集群架構原理