ElasticSearch
- ElasticSearch
- term查詢
- match查詢
- Elasticsearch架構原理
- Master節點
- DataNode節點
- 分片(Shard)
- 副本
- 指定分片、副本數量
- Elasticsearch重要作業流程
- Elasticsearch檔案寫入原理
- Elasticsearch檢索原理
- Elasticsearch準實時索引實作
- 手工控制搜索結果精準度
- match 的底層轉換
- boost權重控制
- 基于dis_max實作best fields策略進行多欄位搜索
- 基于tie_breaker引數優化dis_max搜索效果
- 使用multi_match簡化dis_max+tie_breaker
- cross fields搜索
- copy_to組合fields
- 近似匹配
- match phrase
- match phrase原理 -- term position
- 前綴搜索 prefix search
- 正則搜索
- fuzzy模糊搜索技術
- 通配符搜索
- 總結
ElasticSearch
term查詢
- term查詢keyword欄位,
term不會分詞,而keyword欄位也不分詞,需要完全匹配才可, - term查詢text欄位,
因為text欄位會分詞,而term不分詞,所以term查詢的條件必須是text欄位分詞后的某一個,
match查詢
- match查詢keyword欄位
match會被分詞,而keyword不會被分詞,match的需要跟keyword的完全匹配可以, - match查詢text欄位
match分詞,text也分詞,只要match的分詞結果和text的分詞結果有相同的就匹配,
Elasticsearch架構原理
Elasticsearch的節點型別分為兩種節點:一類是Master,一類是DataNode;
Master節點
在ElasticSearch集群啟動時,會選舉出來一個Master節點,當某個節點啟動后,然后使用Zen Discovery機制找到集群中的其他節點,并建立連接,
discovery.seed_hosts: [“192.168.21.130”, “192.168.21.131”, “192.168.21.132”]
并從候選主節點中選舉出一個主節點,
cluster.initial_master_nodes: [“node1”, “node2”,“node3”]
Master節點的主要負責:
- 管理索引(創建索引,洗掉索引),分配分片
- 維護元資料(映射資訊);
- 管理集群節點狀態
- 不負責資料的寫入和查詢
一個ElasticSearch集群中,只有一個Master節點,在生產環境中,記憶體可以相對
小一點,但機器要穩定,
DataNode節點
在ElasticSearch集群中,會有N個DataNode節點,
主要負責 資料的寫入,資料檢索,大部分壓力都在DataNode節點上,
因此,在生產環境中,記憶體最好配置大一些,
分片(Shard)
ES索引的資料也是分成若干部分,分布在不同的服務器節點中,
分布在不同服務器中的索引資料,就是分片;
ES會自動管理分片,如果發現分片分布不均勻,就會自動遷移;
一個索引由多個shard組成,而分片分布在不同服務器上,
副本
為了對ES的分片進行容錯,假設某個節點不可用,會導致整個索引庫都不可用,
所以,需要對分片進行副本容錯,每一個分片都會有對應的副本,
在ES中,默認創建的所有為一個分片,每個分片有1個主分片,一個副本分片,
Primary Shard和Replica Shard不在同一個節點上
指定分片、副本數量
PUT /job_shard
{
"mappings": {
"properties": {
"id":{
"type":"long","store": true
},
"area":{
"type": "keyword","store": true
},
"exp":{
"type": "keyword","store": true
},
"edu":{
"type": "keyword","store": true
},
"salary":{
"type": "keyword","store": true
},
"job_type":{
"type": "keyword","store": true
},
"cmp":{
"type": "keyword","store": true
},
"pv":{
"type": "keyword","store": true
},
"title":{
"type": "text","store": true
},
"jb":{
"type": "text","store": true
}
}
},
"settings": {
"number_of_shards": 3,
"number_of_replicas": 2
}
}
//查看分片、副本資訊
GET /_cat/indices?v
Elasticsearch重要作業流程
Elasticsearch檔案寫入原理
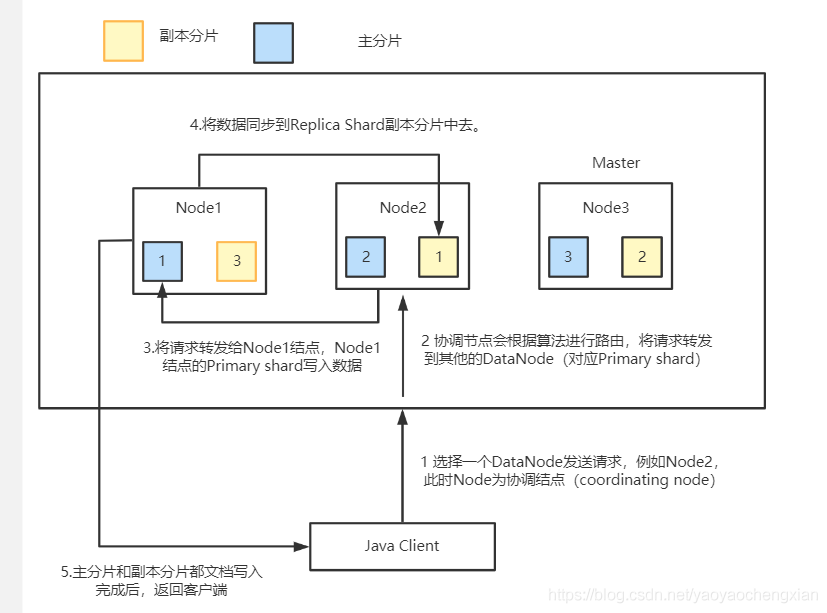
- 選擇任意一個DataNode發送請求,例如:node2,此時,node2就成為一個
coordinating node(協調節點) - 計算得到檔案要寫入的分片
shard = hash(routing) % number_of_primary_shards
routing 是一個可變值,默認是檔案的 _id - coordinating node會進行路由,將請求轉發給對應的primary shard所在的
DataNode(假設primary shard在node1、replica shard在node2) - node1節點上的Primary Shard處理請求,寫入資料到索引庫中,并將資料同步到
Replica shard - Primary Shard和Replica Shard都保存好了檔案,回傳client
Elasticsearch檢索原理
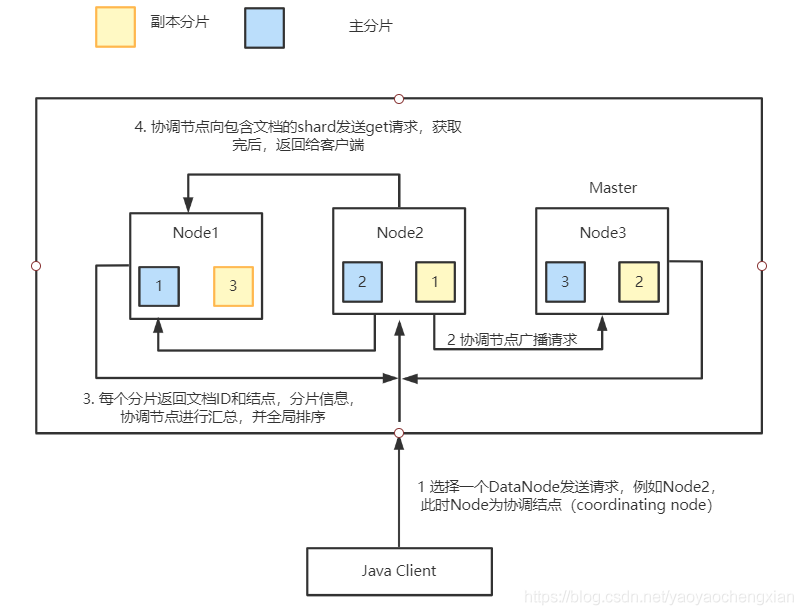
- client發起查詢請求,某個DataNode接收到請求,該DataNode就會成為協調節點
(Coordinating Node) - 協調節點(Coordinating Node)將查詢請求廣播到每一個資料節點,這些資料節
點的分片會處理該查詢請求 - 每個分片進行資料查詢,將符合條件的資料放在一個優先佇列中,并將這些資料
的檔案ID、節點資訊、分片資訊回傳給協調節點, - 協調節點將所有的結果進行匯總,并進行全域排序
- 協調節點向包含這些檔案ID的分片發送get請求,對應的分片將檔案資料回傳給協
調節點,最后協調節點將資料回傳給客戶端
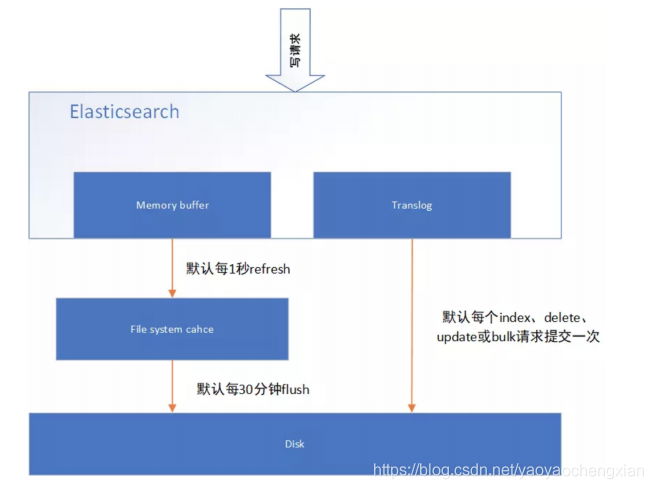
Elasticsearch準實時索引實作
- 溢寫到檔案系統快取
當資料寫入到ES分片時,會首先寫入到記憶體中,然后通過記憶體的buffer生成一個
segment,并刷到檔案系統快取中,資料可以被檢索(注意不是直接刷到磁盤)
ES中默認1秒,refresh一次 - 寫translog保障容錯
在寫入到記憶體中的同時,也會記錄translog日志,
在refresh期間出現例外,會根據translog進行資料恢復,等到檔案系統快取中的segment資料刷磁盤中,清空translog檔案, - flush刷盤
ES默認每隔30分鐘會將檔案系統快取的資料刷入到磁盤 - segment合并
Segment太多時,ES定期會將多個segment合并成為大的segment,減少索引查詢時
IO開銷,此階段ES會真正的物理洗掉(之前執行過的delete的資料)
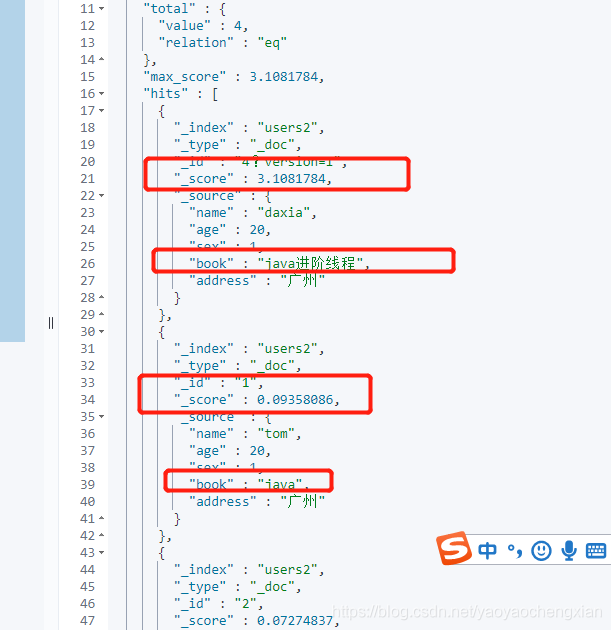
手工控制搜索結果精準度
下述搜索中,如果document中的book欄位包含java或泛型詞組,都符合搜索條件,
GET /users2/_search
{
"query": {
"match": {
"book": "java 泛型"
}
}
}

如果需要搜索的document中的book欄位,包含java和泛型詞組,則需要使
用下述語法
GET /users2/_search
{
"query": {
"match": {
"book":{
"query":"java 泛型",
"operator": "and"
}
}
}
}

上述語法中,如果將operator的值改為or,則與第一個案例搜索語法效果一致,默
認的ES執行搜索的時候,operator就是or,
如果在搜索結果的document中,需要remark欄位中包含一定比例的搜索詞,則可以使用minimum_should_match,其可以使用百分比或固定數字,百分比代表query搜索條件中詞條百分比,如果無法整除,向下匹配(如,query條件有3個單詞,如果使用百分比提供精準度計算,那么是無法除盡的,如果需要至少匹配兩個單詞,則需要用67%來進行描述,如果使用66%描述,ES
則認為匹配一個單詞即可,),固定數字代表query搜索條件中的詞條,至少需要匹配多少個,
POST /users2/_search
{
"query": {
"match": {
"book":{
"query":"java 執行緒 泛型",
"minimum_should_match": "68%"
}
}
}
}

如果使用should+bool搜索的話,也可以控制搜索條件的匹配度,具體如下:下述
案例代表搜索的document中的remark欄位中,必須匹配java、developer、
assistant三個詞條中的至少2個,
POST /users2/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"book": "java"
}
},
{
"match": {
"book": "執行緒"
}
},
{
"match": {
"book": "泛型"
}
}
],
"minimum_should_match": 2
}
}
}

match 的底層轉換
其實在ES中,執行match搜索的時候,ES底層通常都會對搜索條件進行底層轉換,
來實作最終的搜索結果,如:
POST /users2/_search
{
"query": {
"match": {
"book":{
"query":"java 執行緒"
}
}
}
}
//轉化
POST /users2/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"book": {
"value": "java"
}
}
},
{
"term": {
"book": {
"value": "執行緒"
}
}
}
]
}
}
}
POST /users2/_search
{
"query": {
"match": {
"book":{
"query":"java 進階",
"operator": "and"
}
}
}
}
GET /users2/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"book": {
"value": "java"
}
}
},
{
"term": {
"book": {
"value": "進階"
}
}
}
]
}
}
}
建議,如果不怕麻煩,盡量使用轉換后的語法執行搜索,效率更高,
如果開發周期短,作業量大,使用簡化的寫法,
boost權重控制
搜索document中remark欄位中包含java的資料,如果remark中包含developer
或architect,則包含architect的document優先顯示,(就是將architect資料匹
配時的相關度分數增加),
一般用于搜索時相關度排序使用,如:電商中的綜合排序,將一個商品的銷
量,廣告投放,評價值,庫存,單價比較綜合排序,在上述的排序元素中,廣告投
放權重最高,庫存權重最低,
GET /users2/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"book": "java"
}
}
],
"should": [
{
"match": {
"book": {
"query": "執行緒",
"boost": 2
}
}
},
{
"match": {
"book": {
"query": "集合",
"boost": 1
}
}
}
]
}
}
}
基于dis_max實作best fields策略進行多欄位搜索
-
best fields策略: 搜索的document中的某一個field,盡可能多的匹配搜索
條件, -
與之相反的是,盡可能多的欄位匹配到搜索條件(most fields策略),如
百度搜索使用這種策略, -
優點:精確匹配的資料可以盡可能的排列在最前端,且可以通過
minimum_should_match來去除長尾資料,避免長尾資料欄位對排序結果的影響, -
長尾資料比如說我們搜索4個關鍵詞,但很多檔案只匹配1個,也顯示出來了,這些文
檔其實不是我們想要的
缺點:相對排序不均勻, -
dis_max語法: 直接獲取搜索的多條件中的,單條件query相關度分數最
高的資料,以這個資料做相關度排序,
下述的案例中,就是找name欄位中rod匹配相關度分數或remark欄位中java
developer匹配相關度分數,哪個高,就使用哪一個相關度分數進行結果排序,
GET /users2/_search
{
"query": {
"dis_max": {
"queries": [{
"match": {
"address": "深"
}
},{
"match": {
"book": "java 進階"
}
}]
}
}
}

基于tie_breaker引數優化dis_max搜索效果
dis_max是將多個搜索query條件中相關度分數最高的用于結果排序,忽略其他
query分數,在某些情況下,可能還需要其他query條件中的相關度介入最終的結果
排序,這個時候可以使用tie_breaker引數來優化dis_max搜索,tie_breaker引數
代表的含義是:將其他query搜索條件的相關度分數乘以引數值,再參與到結果排
序中,如果不定義此引數,相當于引數值為0,所以其他query條件的相關度分數被
忽略,
GET /users2/_search
{
"query": {
"dis_max": {
"tie_breaker": 0.7,
"queries": [{
"match": {
"address": "廣州"
}
},{
"match": {
"book": "java 進階"
}
}]
}
}
}
使用multi_match簡化dis_max+tie_breaker
ES中相同結果的搜索也可以使用不同的語法陳述句來實作,不需要特別關注,只
要能夠實作搜索,就是完成任務!
POST /users2/_search
{
"query": {
"multi_match": {
"query": "Java 進階 執行緒 廣州",
"fields": ["address","book"],
"type": "best_fields",
"tie_breaker": 0.7,
"minimum_should_match": 4
}
}
}
cross fields搜索
cross fields : 一個唯一的標識,分部在多個fields中,使用這種唯一標識
搜索資料就稱為cross fields搜索 (類似聯合索引),
如:人名可以分為姓和名,地址可以分為省、市、區縣、街道等,那么使用人名或地址來搜索document,就稱為cross fields搜索,
實作這種搜索,一般都是使用most fields搜索策略,因為這就不是一個field
的問題,
**Cross fields搜索策略,是從多個欄位中搜索條件資料,默認情況下,和most
fields搜索的邏輯是一致的,計算相關度分數是和best fields策略一致的,**一般
來說,如果使用cross fields搜索策略,那么都會攜帶一個額外的引數operator,
用來標記搜索條件如何在多個欄位中匹配,
當然,在ES中也有cross fields搜索策略,具體語法如下:
POST /users2/_search
{
"query": {
"multi_match": {
"query": "Java 進階 執行緒 廣州",
"fields": ["address","book"],
"type": "cross_fields",
"operator": "and"
}
}
}

上述語法代表的是,搜索條件中的java必須在book或address欄位中匹配,
“進階”也必須在book或book欄位中匹配,“執行緒”也必須在book或book欄位中匹配,
“廣州”也必須在book或book欄位中匹配,
most field策略問題:most fields策略是盡可能匹配更多的欄位,所以會導致
精確搜索結果排序問題,又因為cross fields搜索,不能使用
minimum_should_match來去除長尾資料,
所以在使用most fields和cross fields策略搜索資料的時候,都有不同的缺
陷,所以商業專案開發中,都推薦使用best fields策略實作搜索,
copy_to組合fields
京東中,如果在搜索框中輸入“手機”,點擊搜索,那么是在商品的型別名
稱、商品的名稱、商品的賣點、商品的描述等欄位中,哪一個欄位內進行資料的匹
配?如果使用某一個欄位做搜索不合適,那么使用_all做搜索是否合適?也不合
適,因為_all欄位中可能包含圖片,價格等欄位,
假設,有一個欄位,其中的內容包括(但不限于):商品型別名稱、商品名稱、
商品賣點等欄位的資料內容,是否可以在這個特殊的欄位上進行資料搜索匹配?
在這里插入代碼片
copy_to : 就是將多個欄位,復制到一個欄位中,實作一個多欄位組合,copy_to
可以解決cross fields搜索問題,在商業專案中,也用于解決搜索條件默認欄位問
題,
如果需要使用copy_to語法,則需要在定義index的時候,手工指定mapping映射策
略,
copy_to語法:
PUT /escopy
{
"mappings": {
"properties": {
"province":{
"type":"text","store": true,"analyzer": "standard","copy_to": "address"
},
"city":{
"type": "text","store": true,"analyzer": "standard","copy_to": "address"
},
"street":{
"type": "text","store": true,"analyzer": "standard","copy_to": "address"
}, "address":{
"type": "text","store": true,"analyzer": "standard"
}
}
}
}
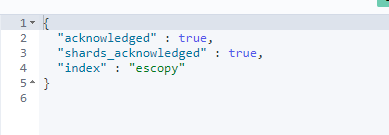
上述的escopy定義中,是新增了4個欄位,分別是provice、city、street、
address,其中provice、city、street三個欄位的值,會自動復制到address欄位
中,實作一個欄位的組合,那么在搜索地址的時候,就可以在address欄位中做條
件匹配,從而避免most fields策略導致的問題,在維護資料的時候,不需對
address欄位特殊的維護,因為address欄位是一個組合欄位,是由ES自動維護的,
類似java代碼中的推導屬性,在存盤的時候,未必存在,但是在邏輯上是一定存在
的,因為address是由3個物理存在的屬性province、city、street組成的,
近似匹配
前文都是精確匹配,如doc中有資料java assistant,那么搜索jave是搜索不到
資料的,因為jave單詞在doc中是不存在的,
如果搜索的語法是:
GET _search
{
"query": {
"match": {
"name": "jave"
}
}
}
如果需要的結果是有特殊要求,如:hello world必須是一個完整的短語,不
可分割;或document中的field內,包含的hello和world單詞,且兩個單詞之間離
的越近,相關度分數越高,那么這種特殊要求的搜索就是近似搜索,包括hell搜索
條件在hello world資料中搜索,包括h搜索提示等都資料近似搜索的一部分,
如何上述特殊要求的搜索,使用match搜索語法就無法實作了,
match phrase
短語搜索,就是搜索條件不分詞,代表搜索條件不可分割,
如果hello world是一個不可分割的短語,我們可以使用前文學過的短語搜索
match phrase來實作,語法如下:
POST /users2/_search
{
"query":{
"match_phrase": {
"book": "java進階"
}
}
}
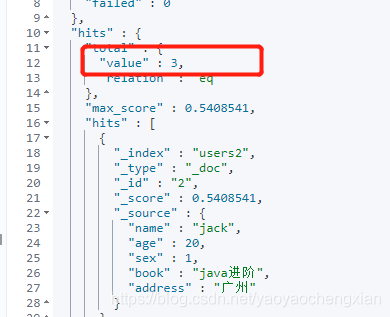
POST /users2/_search
{
"query":{
"match_phrase": {
"book": "java進階執行緒"
}
}
}

match phrase原理 – term position
ES是如何實作match phrase短語搜索的?其實在ES中,使用match phrase做搜
索的時候,也是和match類似,首先對搜索條件進行分詞-analyze,將搜索條件拆
分成hello和world,既然是分詞后再搜索,ES是如何實作短語搜索的?
這里涉及到了倒排索引的建立程序,在倒排索引建立的時候,ES會先對
document資料進行分詞,如:
GET _analyze
{
"text": "hello world , java thread",
"analyzer": "standard"
}

從上述結果中,可以看到,ES在做分詞的時候,除了將資料切分外,還會保留
一個position,position代表的是這個詞在整個資料中的下標,當ES執行match
phrase搜索的時候,首先將搜索條件hello world分詞為hello和world,然后在倒
排索引中檢索資料,如果hello和world都在某個document的某個field出現時,那
么檢查這兩個匹配到的單詞的position是否是連續的,如果是連續的,代表匹配成
功,如果是不連續的,則匹配失敗,
前綴搜索 prefix search
使用前綴匹配實作搜索能力,通常針對keyword型別欄位,也就是不分詞的字
段,
GET /users2/_search
{
"query": {
"prefix": {
"name": {
"value": "d"
}
}
}
}

注意:針對前綴搜索,是對keyword型別欄位而言,而keyword型別欄位資料大小
寫敏感,
前綴搜索效率比較低,前綴搜索不會計算相關度分數,前綴越短,效率越低,
如果使用前綴搜索,建議使用長前綴,因為前綴搜索需要掃描完整的索引內容,所
以前綴越長,相對效率越高,
正則搜索
ES支持正則運算式,可以在倒排索引或keyword型別欄位中使用,
常用符號:
[] - 范圍,如: [0-9]是0~9的范圍數字
. - 一個字符
-
- 前面的運算式可以出現多次,
GET /users2/_search
{
"query": {
"regexp": {
"name":"[A‐z].+"
}
}
}
fuzzy模糊搜索技術
搜索的時候,可能搜索條件文本輸入錯誤,如:hello world -> hello
word,這種拼寫錯誤還是很常見的,fuzzy技術就是用于解決錯誤拼寫的(在英文
中很有效,在中文中幾乎無效,),其中fuzziness代表value的值word可以修改多
少個字母來進行拼寫錯誤的糾正(修改字母的數量包含字母變更,增加或減少字
母),f代表要搜索的欄位名稱,
GET /users2/_search
{
"query": {
"fuzzy": {
"name": {
"value": "toa",
"fuzziness": 2
}
}
}
}

通配符搜索
ES中也有通配符,但是和java還有資料庫不太一樣,通配符可以在倒排索引中
使用,也可以在keyword型別欄位中使用,
常用通配符:
? - 一個任意字符
* - 0~n個任意字符
GET /users2/_search
{
"query": {
"wildcard": {
"name": {
"value": "*o*"
}
}
}
}

總結
個人感覺ES是實戰性較強的技術,沒有動手實踐,很難記得住,記住一些常用的即可,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/292671.html
標籤:其他
上一篇:保姆級教程ElasticSsearch分布式搜索引擎(一)---ElasticSsearch新手快速入門實戰
下一篇:HTML(一):開發工具