前言
本文隸屬于專欄《1000個問題搞定大資料技術體系》,該專欄為筆者原創,參考請注明來源,不足和錯誤之處請在評論區幫忙指出,謝謝!
本專欄目錄結構和參考文獻請見1000個問題搞定大資料技術體系
正文
HBase 是構建在 HDFS 之上的,它利用 HDFS 可靠地存盤資料檔案,其內部則包含 Region 定位、讀寫流程管理和檔案管理等實作,本文從以下幾個方面剖析 HBase 內部原理,
1 . Region 定位
HBase 支持 put , get , delete 和 scan 等基礎操作,所有這些操作的基礎是 region 定位,
給定一個 rowkey 或 rowkey 區間,如何獲取 rowkey 所在的 RegionServer 地址?
region 定位基本步驟如下:
- 客戶端與 ZooKeeper 互動,查找
hbase:meta系統表所在的 Regionserver ,hbase:meta表維護了每個用戶表中 rowkey 區間與 Region 存放位置的映射關系,具體如下:
rowkey : table name , start key , region id
value : RegionServer 物件(保存了 RegionServer 位置資訊等) - 客戶端與
hbase:meta系統表所在 RegionServer 互動,獲取 rowley 所在的 RegionServer - 客戶端與 rowkey 所在的 RegionServer 互動,執行該 rowkey 相關操作,
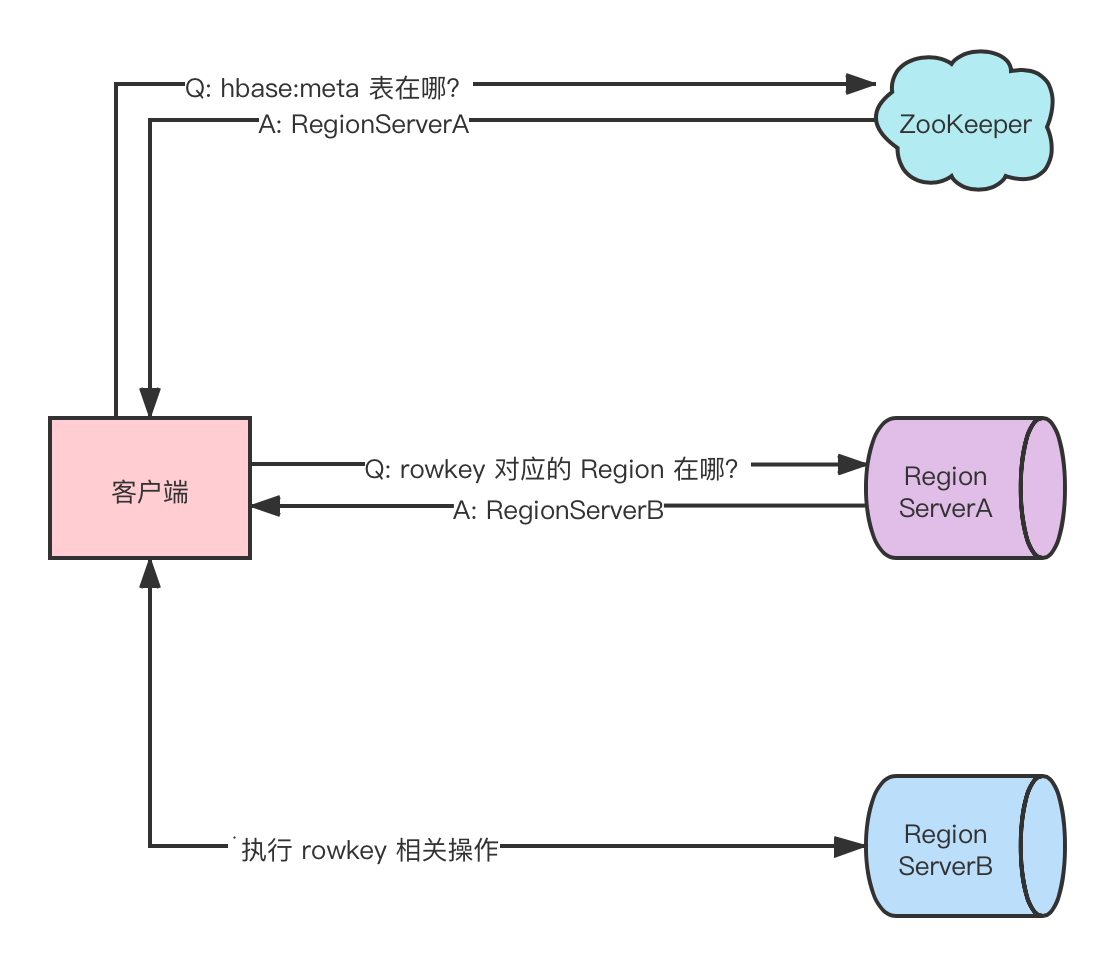
需要注意的是,客戶端首次執行讀寫操作時才需要定位 hbase:meta 表的位置,之后會
將其快取到本地,除非因 region 移動導致快取失效,客戶端才會重新讀取 hbase:meta 表位置,并更新快取,
2. RegionServer 內部關鍵組件
| 關鍵組件 | 名稱解釋 | 主要功能 |
|---|---|---|
| BlockCache | 讀快取 | 負責快取頻繁讀取的資料,采用了 LRU 置換策略, |
| MemStore | 寫快取 | 負責暫時快取未寫入磁盤的資料,并在寫入磁盤前對資料排序,每個 region 內的每個 columnfamily 擁有一個 MemStore , |
| HFile | 一種支持多級索引的資料存盤格式 | 用于保存 HBase 表中實際的資料,所有 HFile 均保存在 HDFS 中, |
| WAL | WriteAheadLog ,保存在 HDFS 上的日志檔案 | 用于保存那些未持久化到 HDFS 中的 HBase 資料,以便 RegionServer 宕機后恢復這些資料, |
3. RegionServer 讀寫操作
HBase中最重要的兩個操作是寫操作和讀操作,
寫流程
為了提到 HBase 寫效率,避免隨機寫性能低下, RegionServer 將所有收到的寫請求暫時寫入記憶體,之后再順序重繪到磁盤上,進而將隨機寫轉化成順序寫以提升性能,具體流程如下:
- RegionServer 收到寫請求后,將寫入的資料以追加的方式寫入 HDFS 上的日志檔案,該日志被稱為 WriteAheadLog ( WAL ),WAL 主要作用是當 RegionServer 突然宕機后重新恢復丟失的資料,
- RegionServer 將資料寫入記憶體資料結構 MemStore 中,之后通知客戶端資料寫入成功,
- 當 MemStore 所占記憶體達到一定閾值后, RegionServer 會將資料順序重繪到 HDFS 中,保存成 HFile (一種帶多級索引的檔案格式)格式的檔案,
讀流程
由于寫流程可能使得資料位于記憶體中或者磁盤上,因此讀取資料時,需要從多個資料存放位置中尋找資料,包括讀快取 BlockCache 、寫快取 MemStore ,以及磁盤上的 HFile 檔案(可能有多個),并將讀到的資料合并在一起回傳給用戶,具體流程如下:
- 掃描器查找讀快取 BlockCache ,它內部快取了最近讀取過的資料
- 掃描器査找寫快取 MemCache ,它內部快取了最近寫入的資料,
- 如果在 BlockCache 和 MemCache 中未找到目標資料, HBase 將讀取 HFile 中的資料,以獲取需要的資料,
4 . MemStore 與 HFile
MemStore
MemStore 負責將最近寫入的資料快取到記憶體中,它是一個有序 Key / Value 記憶體存盤格式,每個 colum family 擁有一個 MemStore,
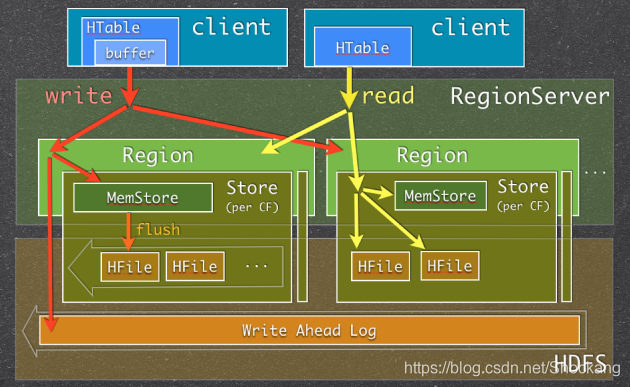
當 RegionServer 收到寫請求的時候(write request),RegionServer會將請求轉至相應的Region,
每一個Region都存盤著一些列(a set of rows),
根據其列族的不同,將這些列資料存盤在相應的列族中(Column Family),
不同的Column Family中的資料存盤在各自的HStore中,HStore由一個MemStore及一系列HFile組成,
MemStore位于RegionServer的主記憶體中,而HFiles 被寫入到HDFS中,
當RegionServer處理寫請求的時候,資料首先寫入到MemStore,然后當到達一定的閥值的時候,MemStore中的資料會被刷到HFile中,
用到 MemStore 最主要的原因是:
存盤在HDFS上的資料需要按照row key 排序,
而HDFS本身被設計為順序讀寫(sequential reads/writes),不允許修改,
這樣的話,HBase就不能夠高效的寫資料,因為要寫入到HBase的資料不會被排序,這也就意味著沒有為將來的檢索優化,
為了解決這個問題,HBase將最近接收到的資料快取在記憶體中(in MemStore),在持久化到HDFS之前完成排序,然后再快速的順序寫入HDFS,
需要注意的一點是實際的HFile中,不僅僅只是簡單地排序的列資料的串列
除了解決“無序”問題外,Memstore還有一些其他的好處,例如:
- 作為一個記憶體級快取,快取最近增加資料,一種顯而易見的場合是,新插入資料總是比老資料頻繁使用,
- 在持久化寫入之前,在記憶體中對Rows/Cells可以做某些優化,比如,當資料的version被設為1的時候,對于某些Column Family的一些資料,Memstore快取了數個對該Cell的更新,在寫入HFile的時候,僅需要保存一個最新的版本就好了,其他的都可以直接拋棄,
有一點需要特別注意:每一次Memstore的flush,會為每一個Column Family創建一個新的HFile, 在讀方面相對來說就會簡單一些:HBase首先檢查請求的資料是否在Memstore,不在的話就到HFile中查找,最侄訓傳merged的一個結果給用戶,
HBase MemStore關注要點:
迫于以下幾個原因,HBase用戶或者管理員需要關注Memstore并且要熟悉它是如何被使用的:
- Memstore有許多配置可以調整以取得好的性能和避免一些問題,HBase不會根據用戶自己的使用模式來調整這些配置,你需要自己來調整,
- 頻繁的Memstore flush會嚴重影響HBase集群讀性能,并有可能帶來一些額外的負載,
- Memstore flush的方式有可能影響你的HBase schema設計
HFile
MemStore 中的資料量達到一定閾值后,會被重繪到 HDFS 檔案中,保存成 HFile 格式,
HFile 是 GoogleSSTable ( Sorted String Table , Google BigTable 中用到的存盤格式)的開源實作,它是一種有序 Key / Value 磁盤存盤格式,帶有多級索引,以方便定位資料, HFile 中的多級索引類似于 B +樹,
HFile 格式如圖所示,
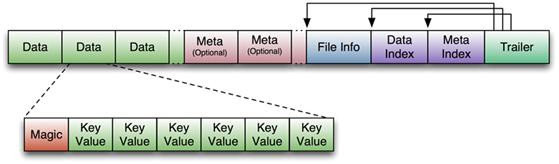
| Block 段 | 說明 | 是否可選 |
|---|---|---|
| Data Block 段 | 用來保存表中的資料,這部分可以被壓縮, | 否 |
| Meta Block 段 | 用來保存用戶自定義的kv段,可以被壓縮, | 是 |
| File Info 段 | 用來保存HFile的元資訊,本能被壓縮,用戶也可以在這一部分添加自己的元資訊, | 否 |
| Data Block Index段 | 用來保存Meta Blcok的索引,Data Block Index采用LRU機制淘汰, | 是 |
| Trailer | 這一段是定長的,保存了每一段的偏移量,讀取一個HFile時,會首先讀取Trailer,Trailer保存了每個段的起始位置(段的Magic Number用來做安全check),然后,DataBlock Index會被讀取到記憶體中,這樣,當檢索某個key時,不需要掃描整個HFile,而只需從記憶體中找到key所在的block,通過一次磁盤io將整個 block讀取到記憶體中,再找到需要的key, | 否 |
HFile的Data Block,Meta Block通常采用壓縮方式存盤,壓縮之后可以大大減少網路IO和磁盤IO,隨之而來的開銷當然是需要花費cpu進行壓縮和解壓縮,目標HFile的壓縮支持兩種方式:gzip、lzo,
參考文獻
《大資料技術體系詳解:原理、架構與實戰》董西成著
hbase存盤結構介紹及hbase各種概念
深入理解HBase Memstore
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/292900.html
標籤:其他
上一篇:Zookeeper概念