零、準備作業
準備三臺Linux服務器,本文是在自己的臺式機上安裝了虛擬機工具(vmware和virtualbox都行),裝3臺CentOS7虛擬機,
集群規劃:
| hadoop001 192.168.164.10 | hadoop002 192.168.164.20 | hadoop003 192.168.164.30 | |
| HDFS集群 | NameNode | SecondaryNameNode | |
| DataNode | DataNode | DataNode | |
| Yarn集群 | NodeManager | NodeManager | ResourceManager |
一、 配置網路
1. 修改網路配置
vi /etc/sysconfig/network-scripts/ifcfg-ens33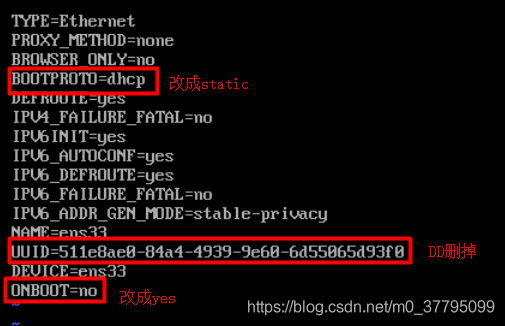
加入以下幾項:
IPADDR=192.168.164.10(自己設定的IP)
NETMASK=255.255.255.0
GATEWAY=192.168.164.2
DNS1=192.168.164.2
DNS2=114.114.114.114重啟網路服務
service network restart測驗ping一下百度看通不通
ping www.baidu.com2. 安裝ifconfig
yum search ifconfig #查找對應的net-tools包
yum install net-tools.x86_64 -y安裝后查看一下IP地址
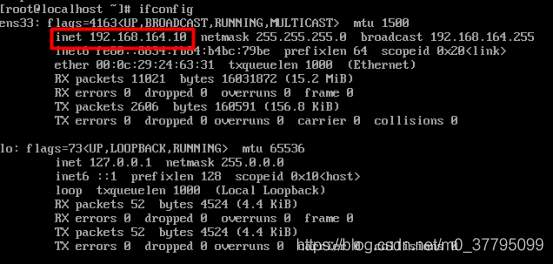
3. 關閉防火墻
systemctl stop firewalld
iptables -F4. 修改selinux配置為disabled
vi /etc/selinux/config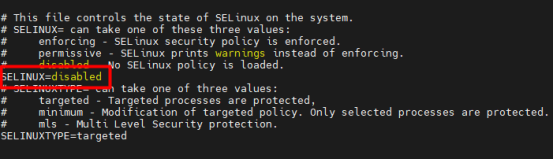
5. 修改主機名
hostnamectl set-hostname hadoop0016. 配置hosts
vi /etc/hosts加入以下內容
192.168.164.10 hadoop001
192.168.164.20 hadoop002
192.168.164.30 hadoop0037. 配置免密登錄
ssh-keygen -t rsa
ssh-copy-id -i ~/.ssh/id_rsa.pub 192.168.164.10
ssh-copy-id -i ~/.ssh/id_rsa.pub 192.168.164.20
ssh-copy-id -i ~/.ssh/id_rsa.pub 192.168.164.308. 裝rsync,用于分發腳本
yum install -y rsync9. 重復1-8
在另外兩臺服務器重復步驟1-8(對應的IP和主機名記得修改)
10. 配置集群時間同步
yum -y install ntp #安裝ntp
systemctl enable ntpd #設定開機啟動
systemctl start ntpd.service #啟動ntp
systemctl is-enabled ntpd #檢查是否啟動成功配置主從服務器(本文選擇hadoop003,即192.168.164.30作為server)
#時間主服務器(hadoop003)
vi /etc/ntp.conf
#加上
restrict 192.168.164.0 mask 255.255.255.0 nomodify notrap
#加上
server 127.127.1.0
fudge 127.127.1.0 stratum 10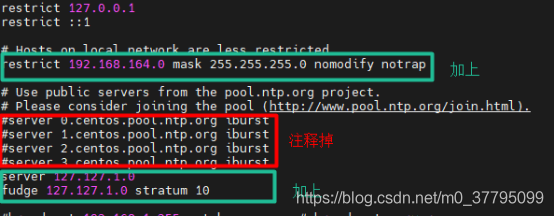
#從服務器(hadoop001和hadoop002)
vi /etc/ntp.conf
#加上
server 192.168.164.30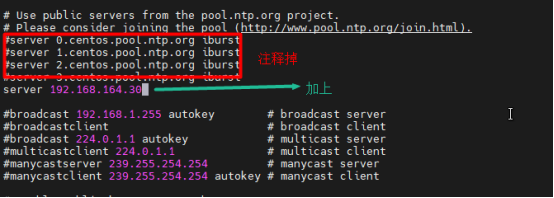
二、三臺機器安裝jdk
Jdk下載地址:https://www.oracle.com/java/technologies/javase-downloads.html
下載完之后上傳到服務器上,路徑:/usr/local/apps/,解壓
tar -zxvf jdk-8u291-linux-x64.tar.gz設定環境變數
vi /etc/profile添加以下配置
export JAVA_HOME=/usr/local/apps/jdk1.8.0_291
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH執行source指令使配置生效
source /etc/profile檢查是否安裝成功
java -version這樣就表示安裝成功了

三、三臺機器安裝Hadoop
Hadoop下載地址:https://archive.apache.org/dist/hadoop/common
下載后上傳到其中一臺服務器,路徑/usr/local/apps/,解壓
tar -zxvf hadoop-2.9.2.tar.gz配置環境變數
vi /etc/profile添加以下配置
export HADOOP_HOME=/usr/local/apps/hadoop-2.9.2
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin執行source指令使之生效
source /etc/profile檢查是否安裝成功
hadoop version這樣就表示安裝成功了

進入安裝好的hadoop目錄里面
cd hadoop-2.9.2/etc/hadoop/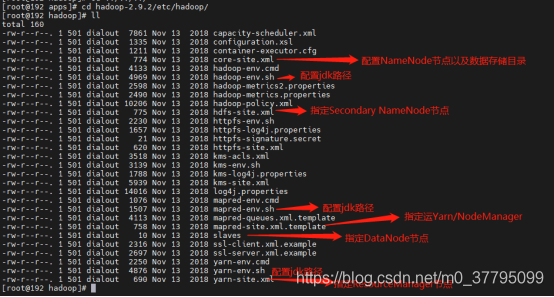
四、集群配置
在hadoop001進行以下配置,所有的可配置項可以參考官網下的Configuration
HDFS集群
1. hadoop-env.sh:配置JDK路徑
# JDK安裝路徑
export JAVA_HOME=/usr/local/apps/jdk1.8.0_2912. core-site.xml:指定NameNode節點以及資料存盤目錄
<configuration>
<property>
<!--指定 namenode 的 hdfs 協議檔案系統的通信地址-->
<name>fs.defaultFS</name>
<value>hdfs://hadoop001:8070</value>
</property>
<property>
<!--指定 hadoop 存盤臨時檔案的目錄-->
<name>hadoop.tmp.dir</name>
<value>/usr/local/apps/hadoop-2.9.2/tmp</value>
</property>
</configuration>3. hdfs-site.xml:指定SecondaryNameNode節點
<configuration>
<property>
<!--指定SecondaryNameNode節點配置-->
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop003:50090</value>
</property>
<property>
<!--指定 dfs 的副本系數為 3-->
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>4. slave:指定DataNode從節點
#先把localhost刪掉
hadoop001
hadoop002
hadoop003MpReduce集群
1. mapred-env.sh:配置JDK路徑
# JDK安裝路徑
export JAVA_HOME=/usr/local/apps/jdk1.8.0_2912. mapred-site.xml:指定MapReduce計算框架運行Yarn資源調度框架
<configuration>
<property>
<!--指定 mapreduce 作業運行在 yarn 上-->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<!--歷史服務器端地址-->
<name>mapreduce.jobhistory.address</name>
<value>hadoop001:10020</value>
</property>
<property>
<!--歷史服務器web端地址-->
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop001:19888</value>
</property>
</configuration>Yarn集群
1. yarn-env.sh:配置JDK路徑
# JDK安裝路徑
export JAVA_HOME=/usr/local/apps/jdk1.8.0_2912. yarn-site.xml:指定ResourceManager所在計算機節點
<configuration>
<property>
<!--配置 NodeManager 上運行的附屬服務,需要配置成 mapreduce_shuffle 后才可以在 Yarn 上運行 MapReduce 程式,-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<!--resourcemanager 的主機名-->
<name>yarn.resourcemanager.hostname</name>
<value>hadoop003</value>
</property>
<property>
<!--開啟日志聚集功能-->
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<!--日志保存時間設定7天-->
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>3. slave:指定NodeManager節點(這步無需操作,前面其實已經配置過了)
#先把localhost刪掉
hadoop001
hadoop002
hadoop0034. 回到hadoop安裝目錄的上一層,修改用戶組
chown -R root:root hadoop-2.9.2/修改前:
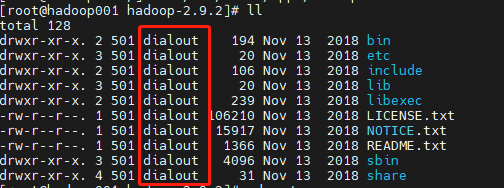
修改后:
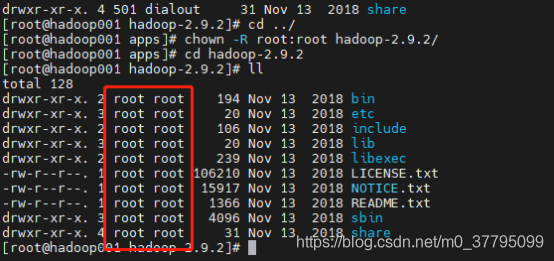
分發腳本
前面的配置都是在hadoop001操作的,需要用rsync將上面所有的配置腳本分發給另外兩臺機器,
rsync -rvl /usr/local/apps/ root@192.168.164.20:/usr/local/apps/
rsync -rvl /usr/local/apps/ root@192.168.164.30:/usr/local/apps/五、啟動Hadoop集群
0. 如果是第一次啟動Hadoop集群,需要在NameNode節點格式化NameNode,非第一次不需要執行格式化!!
hadoop namenode -format
啟動方式1、一臺臺啟動
1. 在Hadoop001上啟動NameNode
hadoop-daemon.sh start namenode2. 在Hadoop001/Hadoop002/Hadoop003上啟動DataNode
hadoop-daemon.sh start datanode3. 在hadoop003上啟動ResourceManager
yarn-daemon.sh start resourcemanager4. 在hadoop001/hadoop002上啟動NodeManager
yarn-daemon.sh start nodemanager啟動方式2、群起
1. 在hadoop001上啟動dfs
start-dfs.sh2. 在hadoop003上啟動yarn
start-yarn.sh驗證
啟動成功后訪問NameNode節點的50070埠
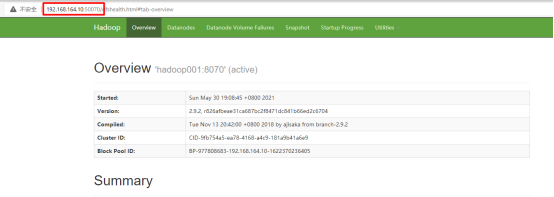
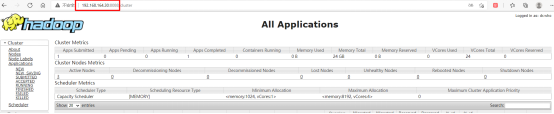
訪問Yarn集群ResourceManager的8088埠
六、 測驗
測驗hdfs
在本地root目錄下創建一個test.txt檔案,隨便輸入點什么內容,
在hadoop上創建一個目錄
hdfs dfs -mkdir -p /test/input將test.txt上傳到hadoop,在圖形界面查看上傳情況
hdfs dfs -put /root/test.txt /test/input將本地root下的test.txt洗掉
rm -rf test.txt從hdfs上下載test.txt,測驗是否可以下載成功
hdfs dfs -get /test/input/test.txt測驗MapReduce
創建目錄,上傳檔案
hdfs dfs -mkdir -p /wcinput
hdfs dfs -put /root/wc.txt /wcinput使用hadoop提供的一個示例jar進行wordcount
hadoop jar /usr/local/apps/hadoop-2.9.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar wordcount /wcinput /wcoutput列印結果
hdfs dfs -cat /wcoutput/part-r-00000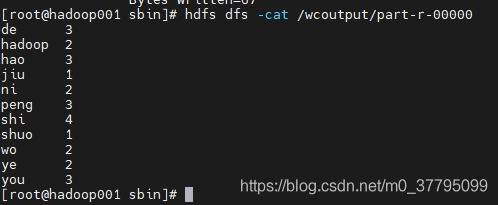
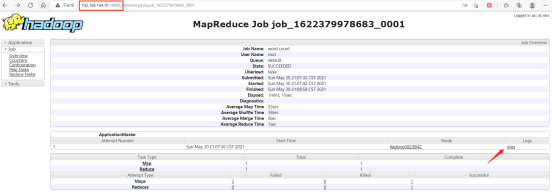
測驗日志收集
在瀏覽器輸入192.168.164.10:19888,查看日志收集是否正常
完畢!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/292901.html
標籤:其他