卷積神經網路
1. 卷積層
全連接神經網路:網路全部由線性層串聯(在線性層中,任意兩個輸入與輸出之間都存在權重,即每一個輸入節點都參與到下一層任何一個輸出節點的計算上,因此線性層也叫做全連接層)
二維卷積的神經網路,卷積層:特征提取器
卷積程序:
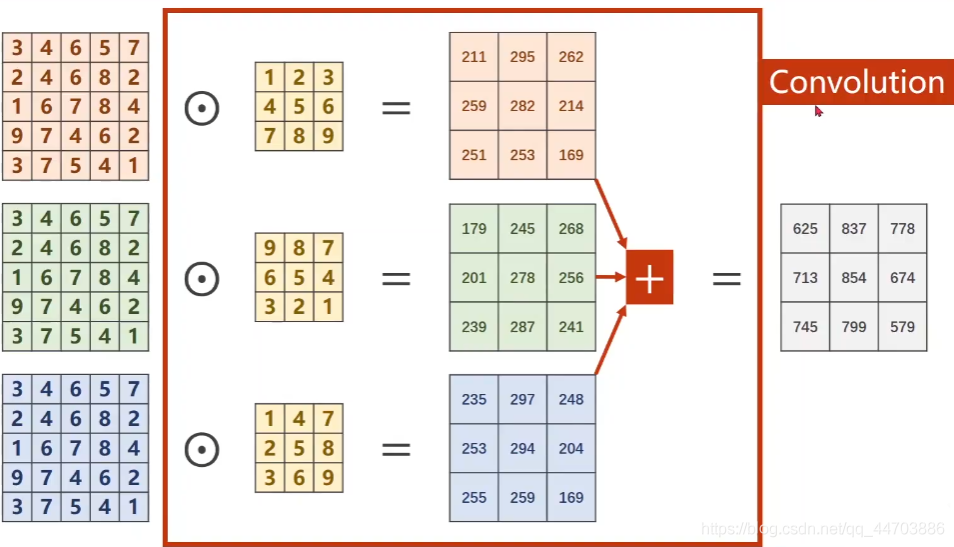
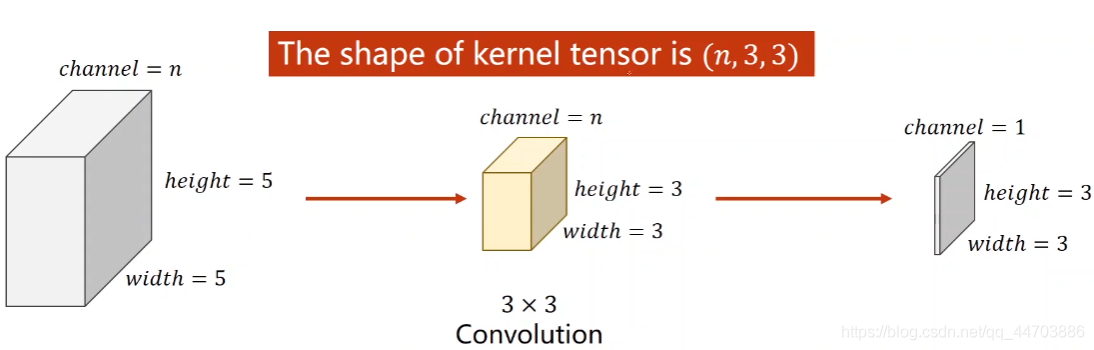
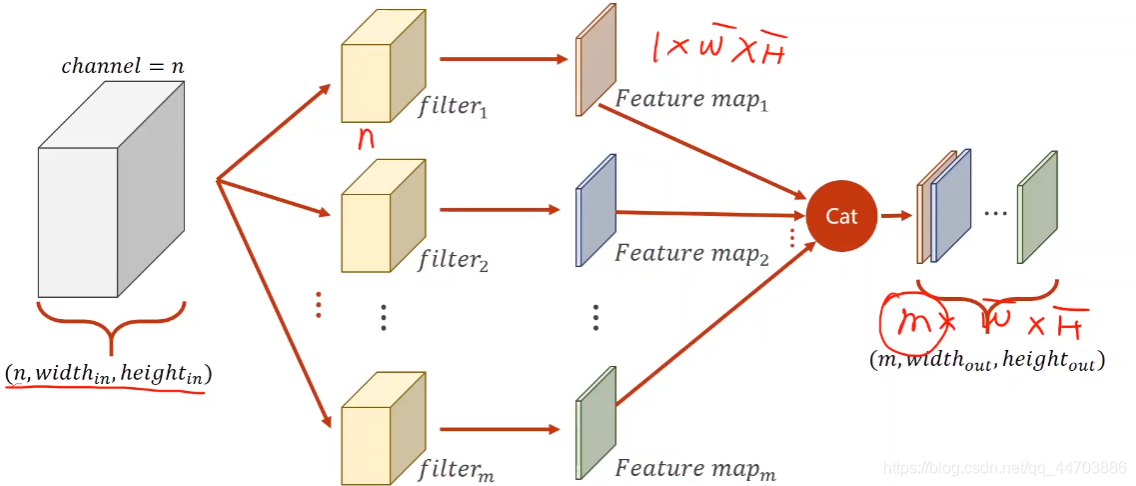
幾個要點:
- 每個卷積核的通道數與輸入影像的通道數必須一致
- 卷積核的個數決定輸出影像的通道數

import torch
in_channels,out_channels = 5,10
width,height = 100,100
kernel_size = 3
batch_size = 1
input = torch.randn(batch_size,
in_channels,
width,
height)
# 卷積層的關鍵引數:輸入通道,輸出通道,以及卷積核的尺寸大小
conv_layer = torch.nn.Conv2d(in_channels,
out_channels,
kernel_size=kernel_size)
output = conv_layer(input)
print(input.shape)
print(output.shape)
print(conv_layer.weight.shape)
結果:
torch.Size([1, 5, 100, 100])
torch.Size([1, 10, 98, 98])
torch.Size([10, 5, 3, 3])
卷積層不在乎輸入影像的尺寸大小,但嚴格要求輸入影像的通道數必須與卷積核一致
2. 卷積層的填充(padding)

代碼:
import torch
input=[3,4,6,5,7,
2,4,6,8,2,
1,6,7,8,4,
9,7,4,6,2,
3,7,5,4,1]
input = torch.Tensor(input).view(1,1,5,5)
# 卷積層
conv_layer = torch.nn.Conv2d(1,1,kernel_size=3,stride=1,bias=False)
# max polling
maxpolling_layer = torch.nn.MaxPool2d(kernel_size=2)
kernel = torch.Tensor([1,2,3,4,5,6,7,8,9]).view(1,1,3,3)
conv_layer.weight.data = kernel.data # 卷積核初始化
output = conv_layer(input)
print(output)
3. 最大池化層(Max Pooling)
卷積核尺寸為2*2,stride=2,池化后,影像縮小為原來的一半
import torch
input = [3,4,6,5,
2,4,6,8,
1,6,7,8,
9,7,4,6]
input = torch.Tensor(input).view(1,1,4,4)
maxpolling_layer = torch.nn.MaxPool2d(kernel_size=2)
output = maxpolling_layer(input)
print(output)
4. 卷積神經網路實作
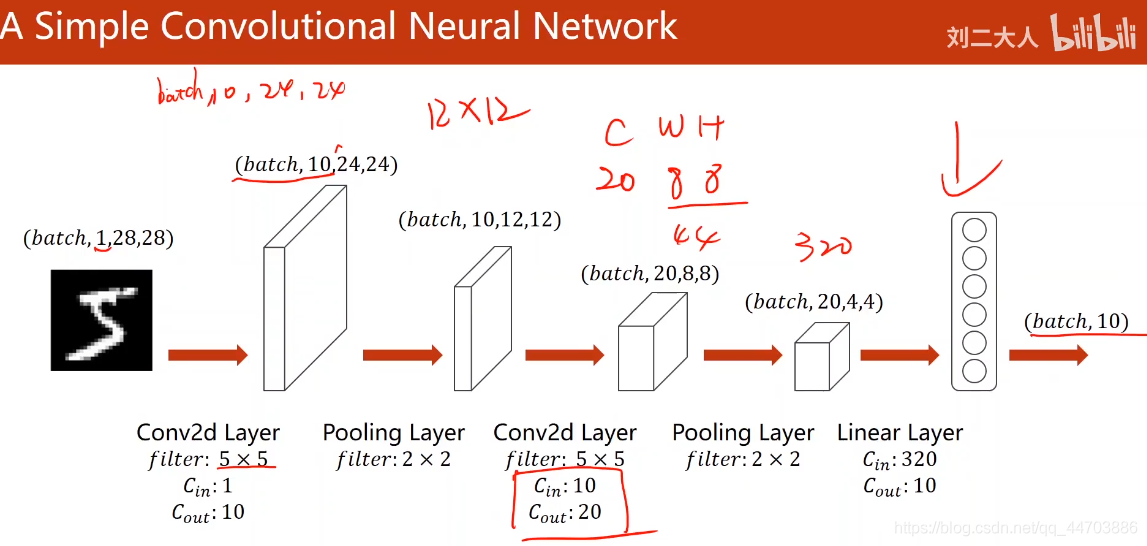

# 2. 設計模型
class Net(torch.nn.Module):
def __init__(self):
super(Net,self).__init__()
self.conv1 = torch.nn.Conv2d(1,10,kernel_size=5)
self.conv2 = torch.nn.Conv2d(10,20,kernel_size=5)
self.pooling = torch.nn.MaxPool2d(2)
self.fc = torch.nn.Linear(320,10)
def forward(self,x):
# Flatten data from(n,1,28,28) to (n,784)
batch_size = x.size(0)
x = F.relu(self.pooling(self.conv1(x)))
x = F.relu(self.pooling(self.conv2(x)))
x = x.view(batch_size,-1)
x = self.fc(x)
return x
model = Net()
5. 怎么使用GPU計算
資料加載和模型訓練必須遷移到同一塊GPU上,否則將報錯
(1)模型使用GPU
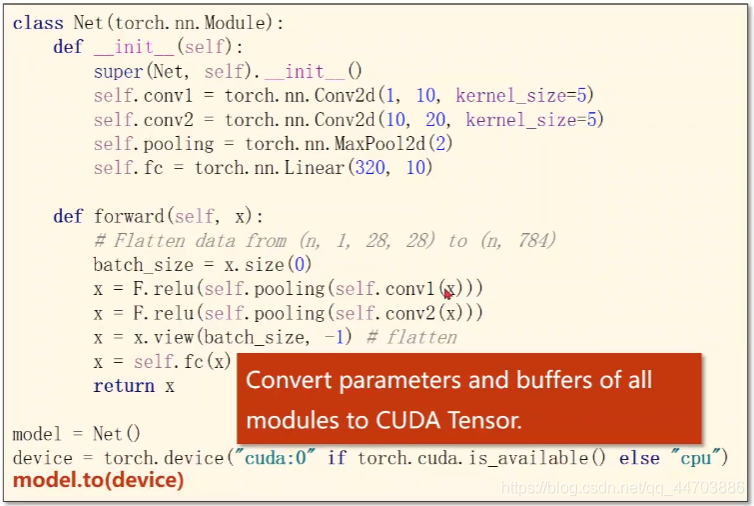
(2)訓練程序使用GPU
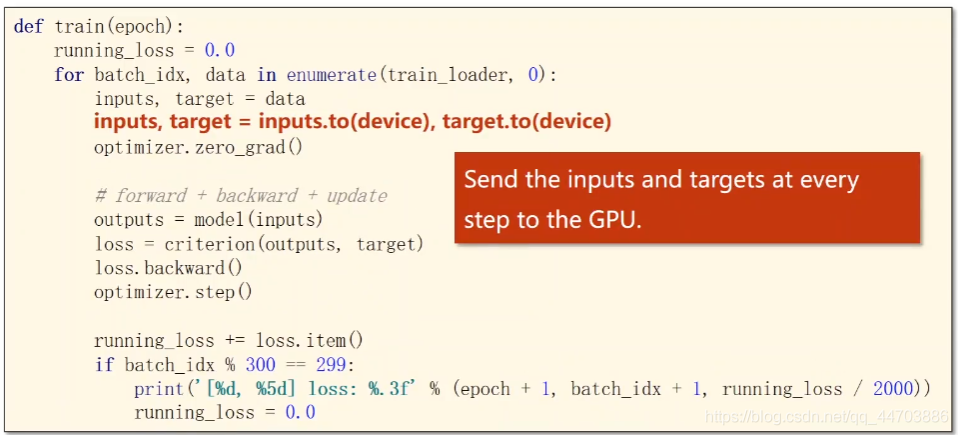
(3)測驗代碼使用GPU

6. 完整代碼
"""
2021.08.09
author:alian
10 卷積神經網路
"""
import torch
from torchvision import transforms,datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
# 1. 資料集準備
batch_size = 64
# transforms:
# (1)將影像像素值(影像張量)映射到0-1之間
# (2)H*W*C 轉化成 C*H*W
# (3)Normalize,歸一化(均值,標準差),使其滿足0-1分布
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,),(0.3081,))
])
train_dataset = datasets.MNIST(root='../dataset/mnist',
train=True,
transform=transforms.ToTensor(), # 影像轉換為張量
download=True)
test_dataset = datasets.MNIST(root='../dataset/mnist',
train=False,
transform=transforms.ToTensor(), # 影像轉換為張量
download=True)
train_loder = DataLoader(dataset=train_dataset,
batch_size=32,
shuffle=True)
test_loder = DataLoader(dataset=train_dataset,
batch_size=32,
shuffle=False)
# 2. 設計模型
class Net(torch.nn.Module):
def __init__(self):
super(Net,self).__init__()
self.conv1 = torch.nn.Conv2d(1,10,kernel_size=5)
self.conv2 = torch.nn.Conv2d(10,20,kernel_size=5)
self.pooling = torch.nn.MaxPool2d(2)
self.fc = torch.nn.Linear(320,10)
def forward(self,x):
# Flatten data from(n,1,28,28) to (n,784)
batch_size = x.s(0)
x = F.relu(self.pooling(self.conv1(x)))
x = F.relu(self.pooling(self.conv2(x)))
x = x.view(batch_size,-1)
x = self.fc(x)
return x
model = Net()
device = torch.device("cuda:0" if torch.cuda.is_available() else "cup")
model.to(device) # 把整個模型的引數(權重)和快取全部放到cuda里計算,即將CPU涉及的權重全部遷移到GPU上
# 3. 構造損失函式和優化器
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(),lr=0.01,momentum=0.5)
# 4. 訓練回圈
def train(epoch):
running_loss = 0.0
for batch_idx,data in enumerate(train_loder,0):
inputs,target = data
inputs,target = inputs.to(device),target.to(device) # 使用GPU
optimizer.zero_grad()
# forward+backward+updata
output = model(inputs)
loss = criterion(output,target)
loss.backward()
optimizer.step()
running_loss+=loss.item()
if batch_idx % 300 == 299:
print('[%d,%5d] loss: %.3f' % (epoch+1, batch_idx+1,running_loss/2000))
running_loss = 0.0
# 測驗代碼
def test():
correct = 0
total = 0
with torch.no_grad(): # 不需要計算梯度
for data in test_loder:
images,labels = data
inputs,target = inputs.to(device),target.to(device) # 使用GPU
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1)
total +=labels.size(0)
correct += (predicted == labels).sum().item()
print('Accurary on test set: %d %%' % (100 * correct/total))
if __name__ == '__mian__':
for epoch in range(10):
train(epoch)
test()
練習

下面是筆者做的練習(不確定是不是正確的,有錯誤的地方歡迎指出)
# 練習:模型設計
class Net1(torch.nn.Module):
def __init__(self):
super(Net1, self).__init__()
self.conv1 = torch.nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = torch.nn.Conv2d(10, 20, kernel_size=5)
self.conv3 = torch.nn.Conv2d(20, 40, kernel_size=3)
self.pooling = torch.nn.MaxPool2d(2)
self.fc1 = torch.nn.Linear(40, 20)
self.fc2 = torch.nn.Linear(20, 10)
def forward(self, x):
# Flatten data from(n,1,28,28) to (n,784)
batch_size = x.size(0)
x = F.relu(self.pooling(self.conv1(x)))
x = F.relu(self.pooling(self.conv2(x)))
x = F.relu(self.pooling(self.conv3(x)))
x = x.view(batch_size, -1)
x = self.fc1(x)
x = self.fc2(x)
return x
后記
def func(*args, **kwargs) # *args輸入任意數量的變數,**kwargs,回傳以字典的格式
print(args)
print(kwargs)
func(1,2,3,4,x=6,y=7)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/293090.html
標籤:AI