如今在人臉識別領域中,開始逐步加強對深度學習技術的運用,這促使人臉識別的相關技術的發展速度得到顯著提升,在此背景下,人臉識別技術在未來必然會擁有更為廣闊的發展前景,
本文主要以卷積神經網路為基礎對人臉識別模型進行設計,使用深度學習框架,通過Keras完成對卷積神經網路模型進行構建,使用OpenCV介面識別人臉并處理人臉資料建立資料集,然后對設立的模型開展訓練,在完成訓練后,運用該模型來實作人臉識別打卡,系統主要分為人臉采集、人臉影像處理、訓練人臉模型訓練和人臉識別打卡小程式四個模塊,四個模塊均能按照預定方式實作相應功能,整體來看,系統所具備的性能能夠達到預期水平,
關鍵詞 人臉識別 卷積神經網路 OpenCV Keras
5 系統實作
經過前期的需求分析與系統設計,本章將按照人臉檢測收集、人臉處理、模型訓練和人臉識別GUI打卡小程式模塊,分別介紹基于深度學習的人臉識別系統的開發的具體程序及實作代碼,
5.1 人臉檢測收集
設定獲取圖片后的保存路徑save_path,然后執行get_face.py中的__name__ == '__main__方法,首先使用OpenCV中的VideoCapture函式呼叫并啟用攝像頭,然后使用OpenCV中的級聯分類器(CascadeClassifier)加載人臉識別分類器haarcascade_frontalface_default.xml,針對所收集每幀影像中包含的人臉相關資訊進行檢測,且把得到的資訊保存至特定位置,同時在視頻中標記出人臉框與當前以保存圖片張數,實作效果如圖5.1所示,
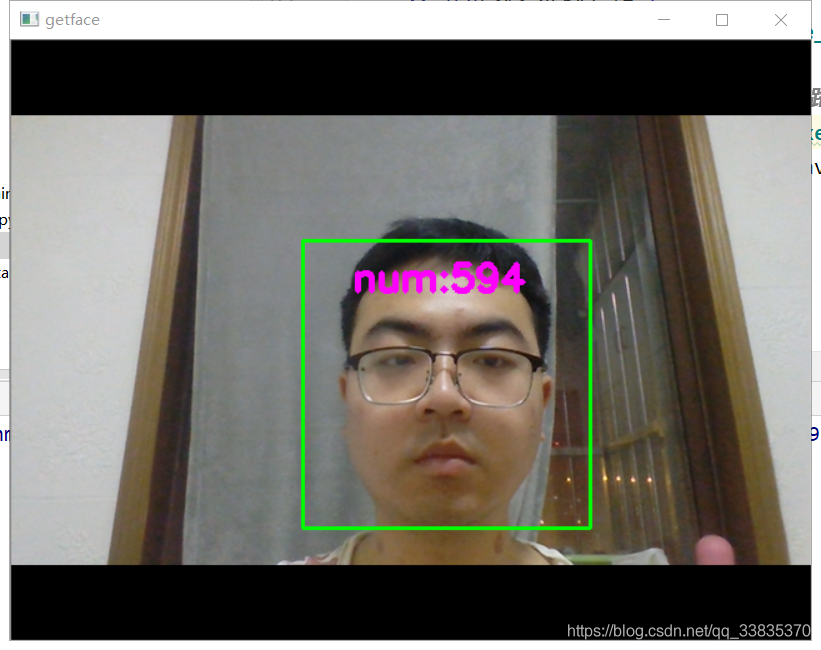
圖5.1 人臉檢測收集實作
實作代碼如下:
def getface(name, cameraid, max_num, path_name):
cv2.namedWindow(name)
videocap = cv2.VideoCapture(cameraid)
data_path = "haarcascade_frontalface_default.xml"
classfier = cv2.CascadeClassifier(data_path)#加載OpenCV人臉識別器
color = (0, 255, 0)
num = 0
while videocap.isOpened):
ok, frame = videocap.read()
if not ok:
break
grey = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
faceRects = classfier.detectMultiScale(grey, scaleFactor=1.2, minNeighbors=3, minSize=(32, 32)
if len(faceRects) > 0: #檢測到人臉,對人臉進行加框
for faceRect in faceRects:
x, y, w, h = faceRect
img_name = '%s/%d.jpg ' %(path_name, num)#保存人臉到目錄
if num > max_num: #如果下載數量完成,退出
break
cv2.rectangle(frame,
if num > max_num:
break
cv2.imshow(name, frame)
c = cv2.waitKey(10)
if c & 0xFF == ord('q'):
break
videocap.release()
cv2.destroyAllWindows()
5.2 人臉處理
首先設定影像大小引數IMAGE_SIZE,對影像尺寸進行調整,若圖片初始長寬存在差異,先確定哪一個邊的長度是最長的,之后對其跟短邊的差距進行計算,以明確短邊對應的像素寬度需增加的具體數值,給影像增加邊界,然后使用OpenCV中的cv2.copyMakeBorder函式進行邊緣填充,最后使用OpenCV中的cv2.resize函式調整影像大小并回傳,當訓練模型時,會呼叫load_dataseth函式,從指定路徑讀取訓練資料對圖片進行轉換并得到相應的四維陣列,
尺寸為最后標注資料,chenkepu檔案夾下都是需要被識別的臉部影像,全部指定為0,其他檔案夾下是其他人臉,全部指定為1,最后回傳資料集,實作代碼如下:
IMAGE_SIZE = 64 #影像大小引數IMAGE_SIZE
def resize_image(image,value=BLACK)
return cv2.resize(constant,(height, width))
images = [] #保存圖片
labels = []#保存標簽
# 讀取圖片
def read_path(path_name):
for dir_item in os.listdir(path_name):
full_path = os.path.abspath(os.path.join(path_name, dir_item)
if os.path.isdir(full_path): #讀取路徑
read_path(full_path)
else:
if dir_item.endswith('.jpg'):
image = cv2.imread(full_path)
image = resize_image(image, IMAGE_SIZE, IMAGE_SIZE)
images.append(image)
labels.append(path_name)
return images, labels
def load_dataset(path_name): #加載資料時呼叫此函式
images, labels = read_path(path_name)
images = np.array(images)
labels = np.array([0 if label.endswith('chenkepu') else 1 for label in labels])#打上標簽
return images, labels #回傳圖片與標簽
5.3 模型訓練
5.3.1 資料集處理
收集人臉資料完成后,開始訓練模型,完成對所需資料的全面加載后,基于函式對資料集進行合理劃分,以得到分別用于訓練、測驗不同方面的集,本次運用比例為7:3的,劃分前,先會將資料全部都打亂,使得訓練集和測驗集的資料分布均勻,劃分好資料集以后,若Keras中運用的后端引擎為,則具備的屬性為,若為Theano,則具備的屬性為,為保證程式具有更高的穩健性,需先對具備的實際屬性進行判定,且以此為依據來調整維度順序,最后要開展歸一化處理,保證各特征值所對應的尺度能夠相對一致,若不開展該處理,所具備尺度不同的特征值對應的梯度會存在顯著差異,但對梯度進行更新的程序中,對應的學習率卻具備較高統一性,若其對應數值較小,則較小的梯度難以實作快速的更新,若其對應的數值較大,則較大的梯度在方向上面會缺乏穩定性,不易收斂,一般會將學習率對應的數值調低,以實作跟所具備尺度較大的維度實作匹配,進而保證損失函式能夠處于較低范圍內,因此,通過歸一化,把不同維度的特征值范圍調整到相近的范圍內,就能統一使用較大的學習率加速學習,因為圖片像素值的范圍都在0~255,圖片資料的歸一化可以簡單地除以255,實作代碼如下:
class Dataset:
def __init__(self, path_name):
# 訓練集
self.train_images = None
self.train_labels = None
# 驗證集
self.valid_images = None
self.valid_labels = None
# 測驗集
self.test_images = None
self.test_labels = None
# 資料集加載路徑
self.path_name = path_name
#def load(self, img_rows=IMAGE_SIZE, img_cols=IMAGE_SIZE,
img_channels=3, nb_classes=2):
# 加載資料集到記憶體
images, labels = load_dataset(self.path_name)
#訓練 驗證 訓練標簽 驗證標簽
train_images, valid_images, train_labels, valid_labels = train_test_split(images, labels, test_size=0.3, random_state=random.randint(0, 100))
_, test_images, _, test_labels = train_test_split(images, labels, test_size=0.5,
random_state=random.randint(0, 100))
if K.image_data_format() == 'channels_first':
train_images = train_images.reshape(train_images.shape[0], img_channels, img_rows, img_cols)
valid_images = valid_images.reshape(valid_images.shape[0], img_channels, img_rows, img_cols)
test_images = test_images.reshape(test_images.shape[0], img_channels, img_rows, img_cols)
self.input_shape = (img_channels, img_rows, img_cols)
else:
train_images = train_images.reshape(train_images.shape[0], img_rows, img_cols, img_channels)
valid_images = valid_images.reshape(valid_images.shape[0], img_rows, img_cols, img_channels)
test_images = test_images.reshape(test_images.shape[0], img_rows, img_cols, img_channels)
self.input_shape = (img_rows, img_cols, img_channels)
valid_labels = np_utils.to_categorical(valid_labels, nb_classes)
test_labels = np_utils.to_categorical(test_labels, nb_classes)
# 像素資料浮點化以便歸一化
train_images = train_images.astype('float32')
valid_images = valid_images.astype('float32')
test_images = test_images.astype('float32')
# 將其歸一化,影像的各像素值歸一化到0~1區間
train_images /= 255
valid_images /= 255
test_images /= 255
self.train_images = train_images #加載訓練資料
self.valid_images = valid_images #加載驗證資料
self.test_images = test_images #加載測驗資料
self.train_labels = train_labels #加載訓練標簽
self.valid_labels = valid_labels #加載驗證標簽
self.test_labels = test_labels #加載測驗標簽
5.3.2 搭建神經網路
該網路具備的整體結構列示在表5.1中,Layer指各層對應的具體型別,Filters指輸出濾波器的具體數量,Size為卷積核體積,為輸出資料資訊,
表5.1 網路結構概況
| Layer (type) | Filters | Size | Output Shape |
| conv2d (Conv2D) | 32 | (3,3) | (22, 22, 32) |
| activation (Activation) | (22, 22, 32) | ||
| conv2d_1 (Conv2D) | 32 | (3,3) | (20, 20, 32) |
| activation_1 (Activation) | (20, 20, 32) | ||
| max_pooling2d (MaxPooling2D) | (2,2) | (10, 10, 32) | |
| dropout (Dropout) | (10, 10, 32) | ||
| conv2d_2 (Conv2D) | 64 | (3,3) | (10, 10, 64) |
| activation_2 (Activation) | (10, 10, 64) | ||
| conv2d_3 (Conv2D) | 64 | (3,3) | (8, 8, 64) |
| activation_3 (Activation) | (8, 8, 64) | ||
| max_pooling2d_1 (MaxPooling2) | (2,2) | (4, 4, 64) | |
| dropout_1 (Dropout) | (4, 4, 64) | ||
| flatten (Flatten) | (1024) | ||
| dense (Dense) | (512) | ||
| activation_4 (Activation) | (512) | ||
| dropout_2 (Dropout) | (512) | ||
| dense_1 (Dense) | (2) | ||
| activation_5 (Activation) | (2) |
上表描述了搭建神經網路的詳細資訊,如下圖5.2是基于CNN的人臉識別神經網路結構圖,包含4個卷積層、池化及全連接層各2各、Flatten及分類層各1個,其中每一層的作用如下:

圖5.2 基于CNN的人臉識別神經網路結構圖
(1)卷積層(convolution layer):運用keras內包含的函式基于二維層面開展相關的卷積計算,輸入影像純為64*64,對其開展滑窗計算,如下圖5.2所示:
圖5.3 卷積計算
(2)激活函式層:激活函式將簡單的線性分類變成復雜的非線性分類以獲得更好的分類效果,該網路主要運用了relu函式,輸入的具體數值若小于0,則輸出的所有數值均為0,若輸入部分超過0,那么最終輸出的數值會與之相等,其優點為能夠在較短時間內實作收斂,其數學形式如下:
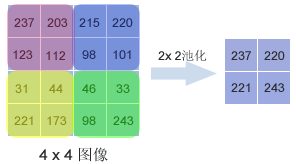
圖5.4 池化
(4)Dropout層:隨機對一定數量的輸入神經元間存在的鏈接進行斷開,避免出現過擬合情況,
(5)Flatten層:完成上面提及的各個程序后,資料仍舊以二維方式呈現,而基于該層能夠將其壓縮為一維,
(6)全連接層:負責將資料劃分成不同型別且開展回歸處理,該層會對512個特征進行保留并傳給下層,函式為基礎完成整個分類程序,基于分類層面,若神經元所輸出的具體數值較大,則更可能被歸為真實類別,所以通過該函式進行處理后,從上層得到的N個輸入會以映射方式形成與之對應的概率分布,且所有概率相加后為1,所對應概率最高的便是預估的具備類別,其函式式如下:
實作代碼如下:
# 建立模型
def build_model(self, dataset, nb_classes=2):
# 構建一個空的線性堆疊網路模型
self.model = Sequential()
self.model.add(Convolution2D(32, 3, 3, padding='same',
input_shape=dataset.input_shape)) # 2維卷積層
self.model.add(Activation('relu')) # self.model.
self.model.add(MaxPooling2D(pool_size=(2, 2))) # 池化層
self.model.add(Dropout(0.25)) # self.model.add(Dropout(0.5)) # Dropout層
self.model.add(Dense(nb_classes)) # Dense層
self.model.add(Activation('softmax')) #分類層,輸出最終結果
# 輸出模型概況
self.model.summary()
5.3.3 模型訓練
搭建神經網路后,開始訓練模型, 在開始訓練前,先對優化器對應的函式進行設定,優化器在訓練程序主要對相關引數進行調節,保證處于最優水平,本次基為主要依據來判定是不是要運用相應的動量方法,相對于傳統動量法,其效率更高,實作代碼如下:
# 訓練模型
def train(self, dataset, batch_size = 32, nb_epoch = 5, data_augmentation=True):
sgd = SGD(lr=0.01, decay=1e-6,
momentum=0.9, nesterov=True) # 采用SGD+momentum的優化器進行訓練,首先生成一個優化器物件
self.model.compile(loss='categorical_crossentropy',
optimizer=sgd,
if not data_augmentation:
self.model.fit(dataset.train_images,
dataset.train_labels,
batch_size=batch_size,
nb_epoch=nb_epoch,
validation_data=(dataset.valid_images, dataset.valid_labels),
shuffle=True)
featurewise_std_normalization=False, # 是否資料標準化(輸入資料除以資料集的標準差) datagen.fit(dataset.train_images)
# 利用生成器開始訓練模型
self.model.fit(datagen.flow(dataset.train_images, dataset.train_labels,
batch_size=batch_size),
steps_per_epoch = int(2100/batch_size),
epochs=nb_epoch,
validation_data=(dataset.valid_images, dataset.valid_labels),verbose=1)
5.4 人臉識別GUI打卡小程式
人臉識別GUI打卡小程式使用Python GUI庫 Tkinter,實作了簽到打卡,模式選擇,錄入新人,查看簽到資訊等功能,使用Frame初始化頁面,組件使用grid布局排列,資料庫使用SqlLite3,在頁面創建時初始化,
- 初始資料庫
在啟動小程式時,首先使用sqlite3.connect函式創建或打開一個資料庫,然后在初始化資料庫時,創建打卡記錄表、管理員表、人臉標簽表表,在需要呼叫資料庫時,使用資料庫類中封裝的方法,主要實作代碼如下:
self.conn.execute('create table if not exists record_table('
'id integer primary key autoincrement,'
'name varchar(30) ,'
'record_time timestamp)')
self.conn.execute('create table if not exists name_table('
'id integer primary key autoincrement,'
'name varchar(30))')
self.conn.execute('create table if not exists admin_table('
'id integer primary key autoincrement,'
'username varchar(30),'
'password varchar(32))')
- 主頁頁面
啟動小程式后,通過Frame類創建一個視窗,使用grid布局,在網格布局上添加Label標簽,設定字體font為粗體,在網格布局上添加簽到打卡、錄入新人按鈕,給按鈕command屬性上系結點擊事件,分別跳轉到簽到打卡頁面與錄入新人界面,通過給按鈕bg屬性添加16進制顏色,改變按鈕的顏色,實作效果如圖5.1所示,
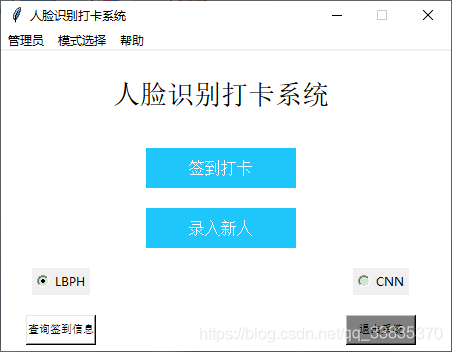
圖5.5 主頁頁面
- 簽到打卡
在主頁上點擊簽到打卡后,小程式將呼叫電腦攝像頭,對攝像頭外的人臉進行識別,在CNN模式下,加載訓練的H5模式模型檔案,對獲取的人臉進行識別,識別成功將在打卡記錄表中插入一條資料,在LBPH模式下,將加載訓練后的yml檔案,對人臉進行識別打卡,實作代碼如下:
def check(names,mode_id):
cam = cv2.VideoCapture(0)
if mode_id==1:
recognizer = cv2.face.LBPHFaceRecognizer_create()
recognizer.read('face_trainer/trainer.yml') #加載模型
cascadePath = "haarcascade_frontalface_default.xml"
faceCascade = cv2.CascadeClassifier(cascadePath)#加載人臉識別器
font = cv2.FONT_HERSHEY_SIMPLEX
(gray[y:y + h, x:x + w])
if confidence < 100:
username = names[idnum-1]
confidence = "{0}%".format(round(100 - confidence))
cv2.putText(img, str(username
cv2.imshow('camera', img)
time.sleep(2)
db.record().insert_record(username) # 簽到資訊插入數
cam.release()
cv2.destroyAllWindows()
return
else:
idnum = "unknown"
confidence = "{0}%".format(round(100 - confidence))
cv2.putText(img, str(idnum), (x + 5, y - 5), font, 1, (0, 0, 255), 1)
cv2.putText(img, str(confidence),
break
elif mode_id==2:
face_recognition(names,True) #進行加載H5人臉識別模型
print(2)
else:
print("請選著模式")
cam.release()
cv2.destroyAllWindows()
- 登錄界面
點擊選單欄中登錄按鈕,創建Frame視窗,并銷毀主頁頁面,用戶名和密碼使用Entry控制元件實作獲取輸入的資料,獲取資料后,點擊按鈕觸發點擊事件中函式,把輸入的用戶名與密碼跟資料庫中保存的資料開展全面對比,若發現彼此能夠匹配,跳轉到主頁,同時將用戶狀態self.authority的值改為1,
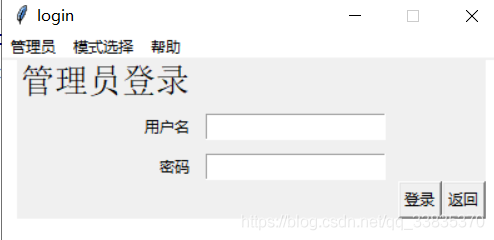
圖5.6 登錄界面
- 注冊界面
點擊選單欄中注冊按鈕,創建Frame視窗,并銷毀主頁頁面,用戶名和密碼使用Entry控制元件實作獲取輸入的資料,獲取資料后,點擊按鈕觸發點擊事件中函式,將獲取到的用戶名與密碼向資料中插入資料,實作效果如圖5.3所示,
圖5.7 注冊界面
向資料庫中插入資料代碼如下:
usr_name = self.var_usr_name.get()
usr_pwd = self.var_usr_pwd.get()
if usr_name == "" or usr_pwd == "":
tkinter.messagebox.askokcancel(title='提示', message='請輸入用戶名或密碼!')
return
tkinter.messagebox.askokcancel(title='提示', message='注冊成功!')
self.mydb.add_admin(usr_name,usr_pwd)
#向資料庫插入一條資料
def add_admin(self,username,password):
sql = "INSERT INTO admin_table VALUES (null,?,?);"
self.conn.execute(sql,[username,password])
self.conn.commit()
- 增加人臉界面
在主頁上點擊增加新人按鈕,創建Frame視窗,并銷毀主頁頁面,在LBPH模式下,提示輸入姓名,輸入姓名后,點擊確定后呼叫OpenCV的VideoCapture函式打開電腦的攝像頭,獲取人臉并訓練資料,實作效果如圖5.3所示,

圖5.8 增加人臉界面
- 簽到資訊
管理員點擊簽到資訊按鈕,從資料庫讀取打卡記錄表,將所有資料都系結在Treeview上,實作效果如圖5.5所示,查詢資料庫實作代碼如下:
def query_record(self):
self.cursor.execute('select * from record_table') #執行一條查找的SQL資料
results = self.cursor.fetchall()
return results
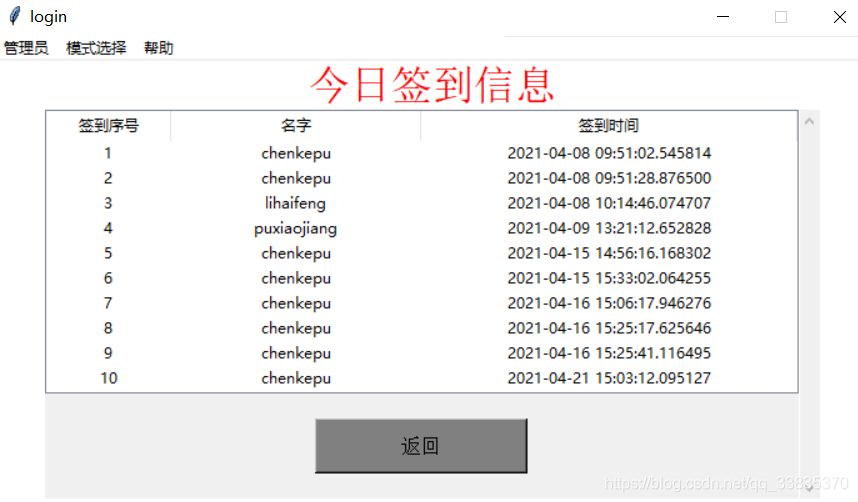
圖5.9 簽到資訊
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/293091.html
標籤:AI
上一篇:【Pytorch】學習筆記(四)
下一篇:人工智能正在學習如何創造自己