睿智的目標檢測51——Tensorflow2搭建yolo3目標檢測平臺
- 學習前言
- 原始碼下載
- YoloV3實作思路
- 一、整體結構決議
- 二、網路結構決議
- 1、主干網路Darknet53介紹
- 2、構建FPN特征金字塔進行加強特征提取
- 3、利用Yolo Head獲得預測結果
- 三、預測結果的解碼
- 1、什么是先驗框
- 2、獲得先驗框后做什么
- 5、得分篩選與非極大抑制
- 四、訓練部分
- 1、計算loss所需引數
- 2、y_pre是什么
- 3、y_true是什么,
- 4、loss的計算程序
- 訓練自己的YoloV3模型
- 一、資料集的準備
- 二、資料集的處理
- 三、開始網路訓練
- 四、訓練結果預測
學習前言
對YoloV3進行了重構,用tensorflow2進行了復現,

原始碼下載
https://github.com/bubbliiiing/yolo3-tf2
喜歡的可以點個star噢,
YoloV3實作思路
一、整體結構決議
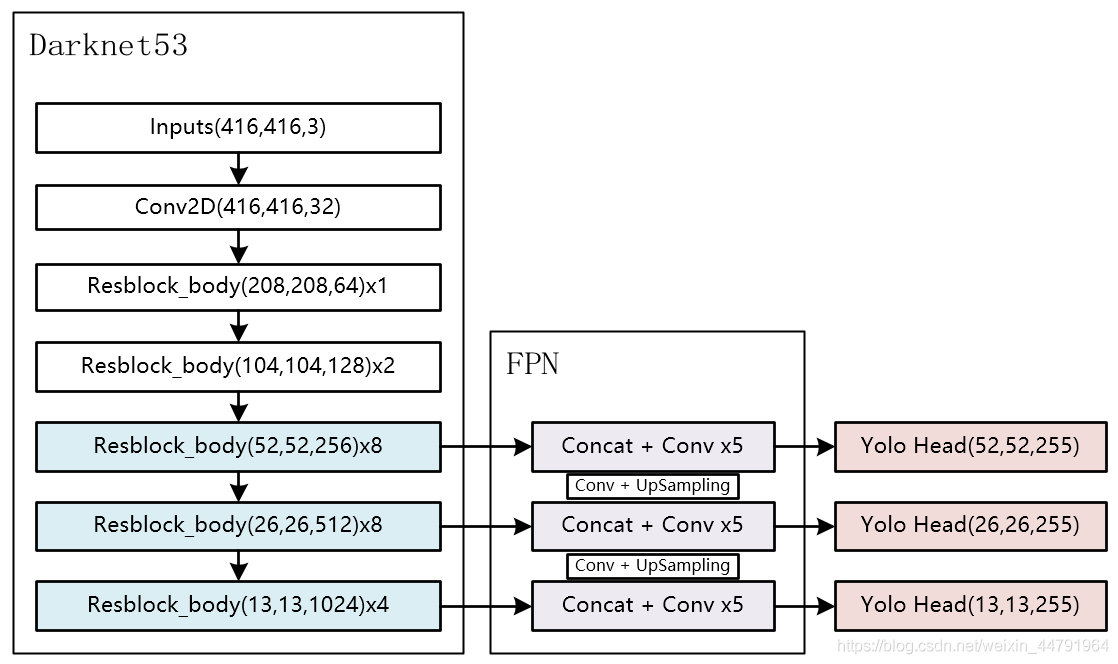
在學習YoloV3之前,我們需要對YoloV3所作的作業有一定的了解,這有助于我們后面去了解網路的細節,
整個YoloV3可以分為三個部分,分別是Darknet53,FPN以及Yolo Head,
Darknet53可以被稱作YoloV3的主干特征提取網路,輸入的圖片首先會在Darknet53里面進行特征提取,提取到的特征可以被稱作特征層,是輸入圖片的特征集合,在主干部分,我們獲取了三個特征層進行下一步網路的構建,這三個特征層我稱它為有效特征層,
FPN可以被稱作YoloV3的加強特征提取網路,在主干部分獲得的三個有效特征層會在這一部分進行特征融合,特征融合的目的是結合不同尺度的特征資訊,在FPN部分,已經獲得的有效特征層被用于繼續提取特征,
Yolo Head是YoloV3的分類器與回歸器,通過Darknet53和FPN,我們已經可以獲得三個加強過的有效特征層,他們的shape分別為(52,52,128),(26,26,256),(13,13,512),每一個特征層都有寬、高和通道數,此時我們可以將特征圖看作一個又一個特征點的集合,每一個特征點都有通道數個特征,Yolo Head實際上所做的作業就是對特征點進行判斷,判斷特征點是否有物體與其對應,
因此,整個YoloV3網路所作的作業就是 特征提取-特征加強-預測特征點對應的物體情況,
二、網路結構決議
1、主干網路Darknet53介紹
YoloV3所使用的主干特征提取網路為Darknet53,它具有兩個重要特點:
1、使用了殘差網路Residual,Darknet53中的殘差卷積可以分為兩個部分,主干部分是一次1X1的卷積和一次3X3的卷積;殘差邊部分不做任何處理,直接將主干的輸入與輸出結合,整個YoloV3的主干部分都由殘差卷積構成,上述所示的YoloV3整體結構里,Resblock_body后面的x幾就代表在這個特征層部分,殘差結構重復了幾次,Resblock_body的代碼如下,for訓練里的就是殘差結構:
#---------------------------------------------------#
# 卷積塊
# DarknetConv2D + BatchNormalization + LeakyReLU
#---------------------------------------------------#
def resblock_body(x, num_filters, num_blocks):
x = ZeroPadding2D(((1,0),(1,0)))(x)
x = DarknetConv2D_BN_Leaky(num_filters, (3,3), strides=(2,2))(x)
for i in range(num_blocks):
y = DarknetConv2D_BN_Leaky(num_filters//2, (1,1))(x)
y = DarknetConv2D_BN_Leaky(num_filters, (3,3))(y)
x = Add()([x,y])
return x

殘差網路的特點是容易優化,并且能夠通過增加相當的深度來提高準確率,其內部的殘差塊使用了跳躍連接,緩解了在深度神經網路中增加深度帶來的梯度消失問題,
2、Darknet53的每一個DarknetConv2D后面都緊跟了BatchNormalization標準化與LeakyReLU部分,普通的ReLU是將所有的負值都設為零,Leaky ReLU則是給所有負值賦予一個非零斜率,以數學的方式我們可以表示為**:
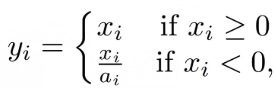
DarknetConv2D_BN_Leaky的實作代碼如下
#---------------------------------------------------#
# 卷積塊 -> 卷積 + 標準化 + 激活函式
# DarknetConv2D + BatchNormalization + LeakyReLU
#---------------------------------------------------#
def DarknetConv2D_BN_Leaky(*args, **kwargs):
no_bias_kwargs = {'use_bias': False}
no_bias_kwargs.update(kwargs)
return compose(
DarknetConv2D(*args, **no_bias_kwargs),
BatchNormalization(),
LeakyReLU(alpha=0.1))
整個主干實作代碼為:
from functools import wraps
from tensorflow.keras.initializers import RandomNormal
from tensorflow.keras.layers import (Add, BatchNormalization, Conv2D, LeakyReLU,
ZeroPadding2D)
from tensorflow.keras.regularizers import l2
from utils.utils import compose
#------------------------------------------------------#
# 單次卷積DarknetConv2D
# 如果步長為2則自己設定padding方式,
# 測驗中發現沒有l2正則化效果更好,所以去掉了l2正則化
#------------------------------------------------------#
@wraps(Conv2D)
def DarknetConv2D(*args, **kwargs):
darknet_conv_kwargs = {'kernel_initializer' : RandomNormal(stddev=0.02), 'kernel_regularizer': l2(5e-4)}
darknet_conv_kwargs['padding'] = 'valid' if kwargs.get('strides')==(2,2) else 'same'
darknet_conv_kwargs.update(kwargs)
return Conv2D(*args, **darknet_conv_kwargs)
#---------------------------------------------------#
# 卷積塊 -> 卷積 + 標準化 + 激活函式
# DarknetConv2D + BatchNormalization + LeakyReLU
#---------------------------------------------------#
def DarknetConv2D_BN_Leaky(*args, **kwargs):
no_bias_kwargs = {'use_bias': False}
no_bias_kwargs.update(kwargs)
return compose(
DarknetConv2D(*args, **no_bias_kwargs),
BatchNormalization(),
LeakyReLU(alpha=0.1))
#---------------------------------------------------------------------#
# 殘差結構
# 首先利用ZeroPadding2D和一個步長為2x2的卷積塊進行高和寬的壓縮
# 然后對num_blocks進行回圈,回圈內部是殘差結構,
#---------------------------------------------------------------------#
def resblock_body(x, num_filters, num_blocks):
x = ZeroPadding2D(((1,0),(1,0)))(x)
x = DarknetConv2D_BN_Leaky(num_filters, (3,3), strides=(2,2))(x)
for i in range(num_blocks):
y = DarknetConv2D_BN_Leaky(num_filters//2, (1,1))(x)
y = DarknetConv2D_BN_Leaky(num_filters, (3,3))(y)
x = Add()([x,y])
return x
#---------------------------------------------------#
# darknet53 的主體部分
# 輸入為一張416x416x3的圖片
# 輸出為三個有效特征層
#---------------------------------------------------#
def darknet_body(x):
# 416,416,3 -> 416,416,32
x = DarknetConv2D_BN_Leaky(32, (3,3))(x)
# 416,416,32 -> 208,208,64
x = resblock_body(x, 64, 1)
# 208,208,64 -> 104,104,128
x = resblock_body(x, 128, 2)
# 104,104,128 -> 52,52,256
x = resblock_body(x, 256, 8)
feat1 = x
# 52,52,256 -> 26,26,512
x = resblock_body(x, 512, 8)
feat2 = x
# 26,26,512 -> 13,13,1024
x = resblock_body(x, 1024, 4)
feat3 = x
return feat1, feat2, feat3
2、構建FPN特征金字塔進行加強特征提取
在特征利用部分,YoloV3提取多特征層進行目標檢測,一共提取三個特征層,
三個特征層位于主干部分Darknet53的不同位置,分別位于中間層,中下層,底層,三個特征層的shape分別為(52,52,256)、(26,26,512)、(13,13,1024),
在獲得三個有效特征層后,我們利用這三個有效特征層進行FPN層的構建,構建方式為:
- 13x13x1024的特征層進行5次卷積處理,處理完后利用YoloHead獲得預測結果,一部分用于進行上采樣UmSampling2d后與26x26x512特征層進行結合,結合特征層的shape為(26,26,768),
- 結合特征層再次進行5次卷積處理,處理完后利用YoloHead獲得預測結果,一部分用于進行上采樣UmSampling2d后與52x52x256特征層進行結合,結合特征層的shape為(52,52,384),
- 結合特征層再次進行5次卷積處理,處理完后利用YoloHead獲得預測結果,
特征金字塔可以將不同shape的特征層進行特征融合,有利于提取出更好的特征,
from tensorflow.keras.layers import Concatenate, Input, Lambda, UpSampling2D
from tensorflow.keras.models import Model
from utils.utils import compose
from nets.darknet import DarknetConv2D, DarknetConv2D_BN_Leaky, darknet_body
from nets.yolo_training import yolo_loss
#---------------------------------------------------#
# 特征層->最后的輸出
#---------------------------------------------------#
def make_five_conv(x, num_filters):
x = DarknetConv2D_BN_Leaky(num_filters, (1,1))(x)
x = DarknetConv2D_BN_Leaky(num_filters*2, (3,3))(x)
x = DarknetConv2D_BN_Leaky(num_filters, (1,1))(x)
x = DarknetConv2D_BN_Leaky(num_filters*2, (3,3))(x)
x = DarknetConv2D_BN_Leaky(num_filters, (1,1))(x)
return x
def make_yolo_head(x, num_filters, out_filters):
y = DarknetConv2D_BN_Leaky(num_filters*2, (3,3))(x)
y = DarknetConv2D(out_filters, (1,1))(y)
return y
#---------------------------------------------------#
# FPN網路的構建,并且獲得預測結果
#---------------------------------------------------#
def yolo_body(input_shape, anchors_mask, num_classes):
inputs = Input(input_shape)
#---------------------------------------------------#
# 生成darknet53的主干模型
# 獲得三個有效特征層,他們的shape分別是:
# C3 為 52,52,256
# C4 為 26,26,512
# C5 為 13,13,1024
#---------------------------------------------------#
C3, C4, C5 = darknet_body(inputs)
#---------------------------------------------------#
# 第一個特征層
# y1=(batch_size,13,13,3,85)
#---------------------------------------------------#
# 13,13,1024 -> 13,13,512 -> 13,13,1024 -> 13,13,512 -> 13,13,1024 -> 13,13,512
x = make_five_conv(C5, 512)
P5 = make_yolo_head(x, 512, len(anchors_mask[0]) * (num_classes+5))
# 13,13,512 -> 13,13,256 -> 26,26,256
x = compose(DarknetConv2D_BN_Leaky(256, (1,1)), UpSampling2D(2))(x)
# 26,26,256 + 26,26,512 -> 26,26,768
x = Concatenate()([x, C4])
#---------------------------------------------------#
# 第二個特征層
# y2=(batch_size,26,26,3,85)
#---------------------------------------------------#
# 26,26,768 -> 26,26,256 -> 26,26,512 -> 26,26,256 -> 26,26,512 -> 26,26,256
x = make_five_conv(x, 256)
P4 = make_yolo_head(x, 256, len(anchors_mask[1]) * (num_classes+5))
# 26,26,256 -> 26,26,128 -> 52,52,128
x = compose(DarknetConv2D_BN_Leaky(128, (1,1)), UpSampling2D(2))(x)
# 52,52,128 + 52,52,256 -> 52,52,384
x = Concatenate()([x, C3])
#---------------------------------------------------#
# 第三個特征層
# y3=(batch_size,52,52,3,85)
#---------------------------------------------------#
# 52,52,384 -> 52,52,128 -> 52,52,256 -> 52,52,128 -> 52,52,256 -> 52,52,128
x = make_five_conv(x, 128)
P3 = make_yolo_head(x, 128, len(anchors_mask[2]) * (num_classes+5))
return Model(inputs, [P5, P4, P3])
3、利用Yolo Head獲得預測結果
利用FPN特征金字塔,我們可以獲得三個加強特征,這三個加強特征的shape分別為(13,13,512)、(26,26,256)、(52,52,128),然后我們利用這三個shape的特征層傳入Yolo Head獲得預測結果,
Yolo Head本質上是一次3x3卷積加上一次1x1卷積,3x3卷積的作用是特征整合,1x1卷積的作用是調整通道數,
對三個特征層分別進行處理,假設我們預測是的VOC資料集,我們的輸出層的shape分別為(13,13,75),(26,26,75),(52,52,75),最后一個維度為75是因為該圖是基于voc資料集的,它的類為20種,YoloV3針對每一個特征層的每一個特征點存在3個先驗框,所以預測結果的通道數為3x25;
如果使用的是coco訓練集,類則為80種,最后的維度應該為255 = 3x85,三個特征層的shape為(13,13,255),(26,26,255),(52,52,255)
其實際情況就是,輸入N張416x416的圖片,在經過多層的運算后,會輸出三個shape分別為(N,13,13,255),(N,26,26,255),(N,52,52,255)的資料,對應每個圖分為13x13、26x26、52x52的網格上3個先驗框的位置,
實作代碼如下:
from tensorflow.keras.layers import Concatenate, Input, Lambda, UpSampling2D
from tensorflow.keras.models import Model
from utils.utils import compose
from nets.darknet import DarknetConv2D, DarknetConv2D_BN_Leaky, darknet_body
from nets.yolo_training import yolo_loss
#---------------------------------------------------#
# 特征層->最后的輸出
#---------------------------------------------------#
def make_five_conv(x, num_filters):
x = DarknetConv2D_BN_Leaky(num_filters, (1,1))(x)
x = DarknetConv2D_BN_Leaky(num_filters*2, (3,3))(x)
x = DarknetConv2D_BN_Leaky(num_filters, (1,1))(x)
x = DarknetConv2D_BN_Leaky(num_filters*2, (3,3))(x)
x = DarknetConv2D_BN_Leaky(num_filters, (1,1))(x)
return x
def make_yolo_head(x, num_filters, out_filters):
y = DarknetConv2D_BN_Leaky(num_filters*2, (3,3))(x)
y = DarknetConv2D(out_filters, (1,1))(y)
return y
#---------------------------------------------------#
# FPN網路的構建,并且獲得預測結果
#---------------------------------------------------#
def yolo_body(input_shape, anchors_mask, num_classes):
inputs = Input(input_shape)
#---------------------------------------------------#
# 生成darknet53的主干模型
# 獲得三個有效特征層,他們的shape分別是:
# C3 為 52,52,256
# C4 為 26,26,512
# C5 為 13,13,1024
#---------------------------------------------------#
C3, C4, C5 = darknet_body(inputs)
#---------------------------------------------------#
# 第一個特征層
# y1=(batch_size,13,13,3,85)
#---------------------------------------------------#
# 13,13,1024 -> 13,13,512 -> 13,13,1024 -> 13,13,512 -> 13,13,1024 -> 13,13,512
x = make_five_conv(C5, 512)
P5 = make_yolo_head(x, 512, len(anchors_mask[0]) * (num_classes+5))
# 13,13,512 -> 13,13,256 -> 26,26,256
x = compose(DarknetConv2D_BN_Leaky(256, (1,1)), UpSampling2D(2))(x)
# 26,26,256 + 26,26,512 -> 26,26,768
x = Concatenate()([x, C4])
#---------------------------------------------------#
# 第二個特征層
# y2=(batch_size,26,26,3,85)
#---------------------------------------------------#
# 26,26,768 -> 26,26,256 -> 26,26,512 -> 26,26,256 -> 26,26,512 -> 26,26,256
x = make_five_conv(x, 256)
P4 = make_yolo_head(x, 256, len(anchors_mask[1]) * (num_classes+5))
# 26,26,256 -> 26,26,128 -> 52,52,128
x = compose(DarknetConv2D_BN_Leaky(128, (1,1)), UpSampling2D(2))(x)
# 52,52,128 + 52,52,256 -> 52,52,384
x = Concatenate()([x, C3])
#---------------------------------------------------#
# 第三個特征層
# y3=(batch_size,52,52,3,85)
#---------------------------------------------------#
# 52,52,384 -> 52,52,128 -> 52,52,256 -> 52,52,128 -> 52,52,256 -> 52,52,128
x = make_five_conv(x, 128)
P3 = make_yolo_head(x, 128, len(anchors_mask[2]) * (num_classes+5))
return Model(inputs, [P5, P4, P3])
三、預測結果的解碼
1、什么是先驗框
由網路我們可以獲得三個特征層的預測結果,shape分別為:
- (N,13,13,255)
- (N,26,26,255)
- (N,52,52,255)
N代表的是batch_size,就是輸入圖片的數量,我們可以忽略,但是后面的(52,52,255)、(26,26,255)、(13,13,255),就不可以忽略了,
每一個預測結果都有寬、高和通道數,寬、高里面是一個又一個特征點,那此時我們便可以想辦法利用這些特征點,和原圖進行結合,
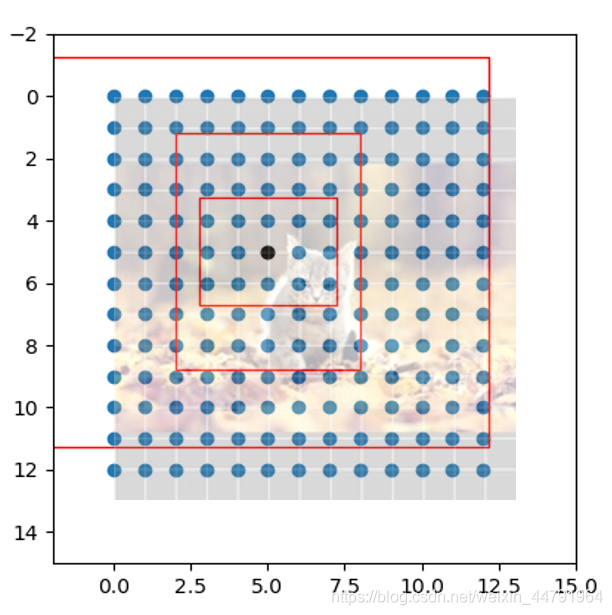
我們再看看預測結果的特點,13X13,26X26,52X52,它是不是非常像三個等分的網格?如果我們將原圖劃分成對應13X13,26X26,52X52的部分,是不是整個特征層就以某種形式映射在原圖上了,
事實上yolo系列就是這么做的,每一個有效特征層將整個圖片分成與其長寬對應的網格,仔細看看這幅圖,原圖被劃分成13x13的網格;然后從每個網格中心建立多個先驗框,典型值是一個特征點三個先驗框,這些框是網路預先設定好的框,網路的預測結果會判斷這些框內是否包含物體,以及這個物體的種類,
2、獲得先驗框后做什么
由網路我們可以獲得三個特征層的預測結果,shape分別為:
- (N,13,13,255)
- (N,26,26,255)
- (N,52,52,255)
由于每一個網格點都具有三個先驗框,所以上述的預測結果可以reshape為: - (N,13,13,3,85)
- (N,26,26,3,85)
- (N,52,52,3,85)
其中的85可以拆分為4+1+80,其中的4代表先驗框的調整引數,1代表先驗框內是否包含物體,80代表的是這個先驗框的種類,由于coco分了80類,所以這里是80,如果YoloV3只檢測兩類物體,那么這個85就變為了4+1+2 = 7,
即85包含了4+1+80,分別代表x_offset、y_offset、h和w、置信度、分類結果,
但是這個預測結果并不對應著最終的預測框在圖片上的位置,還需要解碼才可以完成,
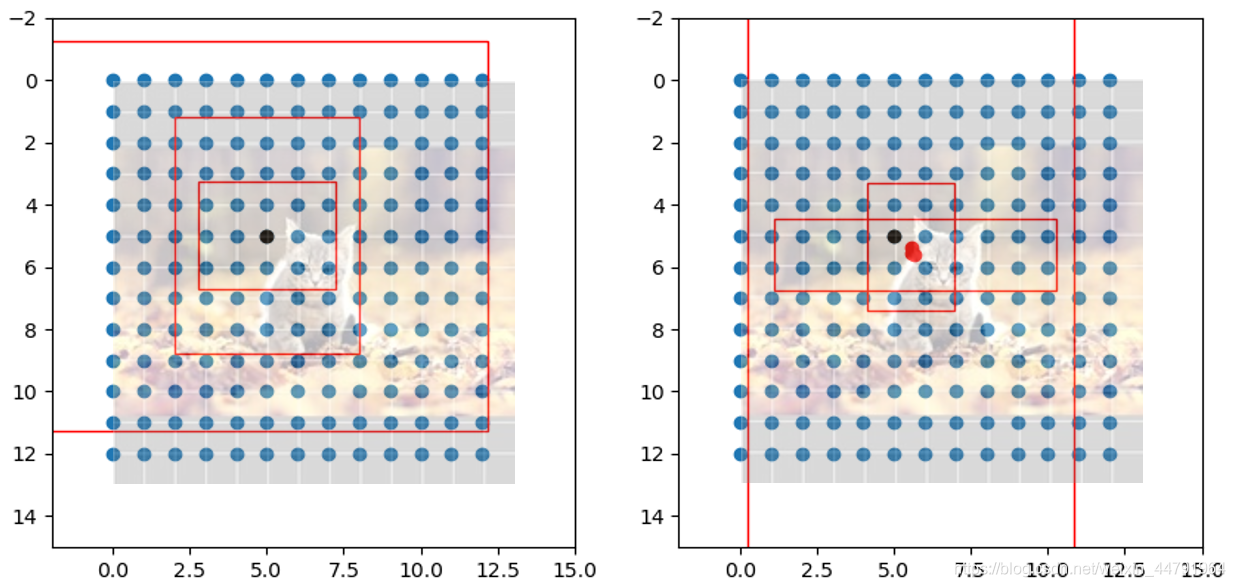
YoloV3的解碼程序分為兩步:
- 先將每個網格點加上它對應的x_offset和y_offset,加完后的結果就是預測框的中心,
- 然后再利用 先驗框和h、w結合 計算出預測框的寬高,這樣就能得到整個預測框的位置了,
下圖展示了YoloV3解碼的程序:
實作代碼如下,當呼叫DecodeBox時,就會進行解碼:
#---------------------------------------------------#
# 對box進行調整,使其符合真實圖片的樣子
#---------------------------------------------------#
def yolo_correct_boxes(box_xy, box_wh, input_shape, image_shape, letterbox_image):
#-----------------------------------------------------------------#
# 把y軸放前面是因為方便預測框和影像的寬高進行相乘
#-----------------------------------------------------------------#
box_yx = box_xy[..., ::-1]
box_hw = box_wh[..., ::-1]
input_shape = K.cast(input_shape, K.dtype(box_yx))
image_shape = K.cast(image_shape, K.dtype(box_yx))
if letterbox_image:
#-----------------------------------------------------------------#
# 這里求出來的offset是影像有效區域相對于影像左上角的偏移情況
# new_shape指的是寬高縮放情況
#-----------------------------------------------------------------#
new_shape = K.round(image_shape * K.min(input_shape/image_shape))
offset = (input_shape - new_shape)/2./input_shape
scale = input_shape/new_shape
box_yx = (box_yx - offset) * scale
box_hw *= scale
box_mins = box_yx - (box_hw / 2.)
box_maxes = box_yx + (box_hw / 2.)
boxes = K.concatenate([box_mins[..., 0:1], box_mins[..., 1:2], box_maxes[..., 0:1], box_maxes[..., 1:2]])
boxes *= K.concatenate([image_shape, image_shape])
return boxes
#---------------------------------------------------#
# 將預測值的每個特征層調成真實值
#---------------------------------------------------#
def get_grid_anchors(feats, anchors):
num_anchors = len(anchors)
#------------------------------------------#
# grid_shape指的是特征層的高和寬
#------------------------------------------#
grid_shape = K.shape(feats)[1:3]
#---------------------------------------------------------------#
# 將先驗框進行拓展,生成的shape為(13, 13, num_anchors, 2)
#---------------------------------------------------------------#
anchors_tensor = K.reshape(tf.constant(anchors), [1, 1, num_anchors, 2])
anchors_tensor = K.tile(anchors_tensor, [grid_shape[0], grid_shape[1], 1, 1])
#------------------------------------------#
# 獲得各個特征點的坐標資訊,
#------------------------------------------#
grid_x = K.tile(K.reshape(K.arange(0, stop=grid_shape[1]), [1, -1, 1, 1]), [grid_shape[0], 1, num_anchors, 1])
grid_y = K.tile(K.reshape(K.arange(0, stop=grid_shape[0]), [-1, 1, 1, 1]), [1, grid_shape[1], num_anchors, 1])
#------------------------------------------#
# 將各個特征點和先驗框進行堆疊
#------------------------------------------#
grid_anchors = K.concatenate([K.cast(grid_x, K.dtype(feats)), K.cast(grid_y, K.dtype(feats)), K.cast(anchors_tensor, K.dtype(feats))])
grid_anchors = K.reshape(grid_anchors, [-1, 4])
#------------------------------------------#
# 獲得特征層的高寬
#------------------------------------------#
grid_w = K.ones_like(grid_x) * grid_shape[1]
grid_h = K.ones_like(grid_y) * grid_shape[0]
grid_wh = K.concatenate([K.cast(grid_h, K.dtype(feats)), K.cast(grid_w, K.dtype(feats))])
grid_wh = K.reshape(grid_wh, [-1, 2])
return grid_anchors, grid_wh
def decode_anchors(reshape_outputs, grid_anchors, grid_wh, input_shape):
#------------------------------------------#
# 對先驗框進行解碼,并進行歸一化
#------------------------------------------#
box_xy = (K.sigmoid(reshape_outputs[..., :2]) + grid_anchors[:, :2])/grid_wh
box_wh = K.exp(reshape_outputs[..., 2:4]) * grid_anchors[:, 2:] / K.cast(input_shape[::-1], K.dtype(reshape_outputs))
#------------------------------------------#
# 獲得預測框的置信度
#------------------------------------------#
box_confidence = K.sigmoid(reshape_outputs[..., 4:5])
box_class_probs = K.sigmoid(reshape_outputs[..., 5:])
return box_xy, box_wh, box_confidence, box_class_probs
#---------------------------------------------------#
# 圖片預測
#---------------------------------------------------#
def DecodeBox(outputs,
anchors,
num_classes,
input_shape,
#-----------------------------------------------------------#
# 13x13的特征層對應的anchor是[116,90],[156,198],[373,326]
# 26x26的特征層對應的anchor是[30,61],[62,45],[59,119]
# 52x52的特征層對應的anchor是[10,13],[16,30],[33,23]
#-----------------------------------------------------------#
anchor_mask = [[6, 7, 8], [3, 4, 5], [0, 1, 2]],
max_boxes = 100,
confidence = 0.5,
nms_iou = 0.3,
letterbox_image = True):
image_shape = K.reshape(outputs[-1],[-1])
#-----------------------------------------------------------#
# 對特征層進行回圈
# grid_anchors 代表每一個特征層所對應的先驗框
# grid_whs 代表每一個特征層所對應的寬高
# reshape_outputs 代表YOLO網路的輸出
#-----------------------------------------------------------#
grid_anchors = []
grid_whs = []
reshape_outputs = []
for l in range(len(outputs) - 1):
grid_anchor, grid_wh = get_grid_anchors(outputs[l], anchors[anchor_mask[l]])
grid_anchors.append(grid_anchor)
grid_whs.append(grid_wh)
reshape_outputs.append(K.reshape(outputs[l], [-1, num_classes + 5]))
grid_anchors = K.concatenate(grid_anchors, axis = 0)
reshape_outputs = K.concatenate(reshape_outputs, axis = 0)
grid_whs = K.concatenate(grid_whs, axis = 0)
box_xy, box_wh, box_confidence, box_class_probs = decode_anchors(reshape_outputs, grid_anchors, grid_whs, input_shape)
#------------------------------------------------------------------------------------------------------------#
# 在影像傳入網路預測前會進行letterbox_image給影像周圍添加灰條,因此生成的box_xy, box_wh是相對于有灰條的影像的
# 我們需要對其進行修改,去除灰條的部分, 將box_xy、和box_wh調節成y_min,y_max,xmin,xmax
# 如果沒有使用letterbox_image也需要將歸一化后的box_xy, box_wh調整成相對于原圖大小的
#------------------------------------------------------------------------------------------------------------#
boxes = yolo_correct_boxes(box_xy, box_wh, input_shape, image_shape, letterbox_image)
5、得分篩選與非極大抑制
得到最終的預測結果后還要進行得分排序與非極大抑制篩選,
得分篩選就是篩選出得分滿足confidence置信度的預測框,
非極大抑制就是篩選出一定區域內屬于同一種類得分最大的框,
得分篩選與非極大抑制的程序可以概括如下:
1、找出該圖片中得分大于門限函式的框,在進行重合框篩選前就進行得分的篩選可以大幅度減少框的數量,
2、對種類進行回圈,非極大抑制的作用是篩選出一定區域內屬于同一種類得分最大的框,對種類進行回圈可以幫助我們對每一個類分別進行非極大抑制,
3、根據得分對該種類進行從大到小排序,
4、每次取出得分最大的框,計算其與其它所有預測框的重合程度,重合程度過大的則剔除,
得分篩選與非極大抑制后的結果就可以用于繪制預測框了,
下圖是經過非極大抑制的,

下圖是未經過非極大抑制的,
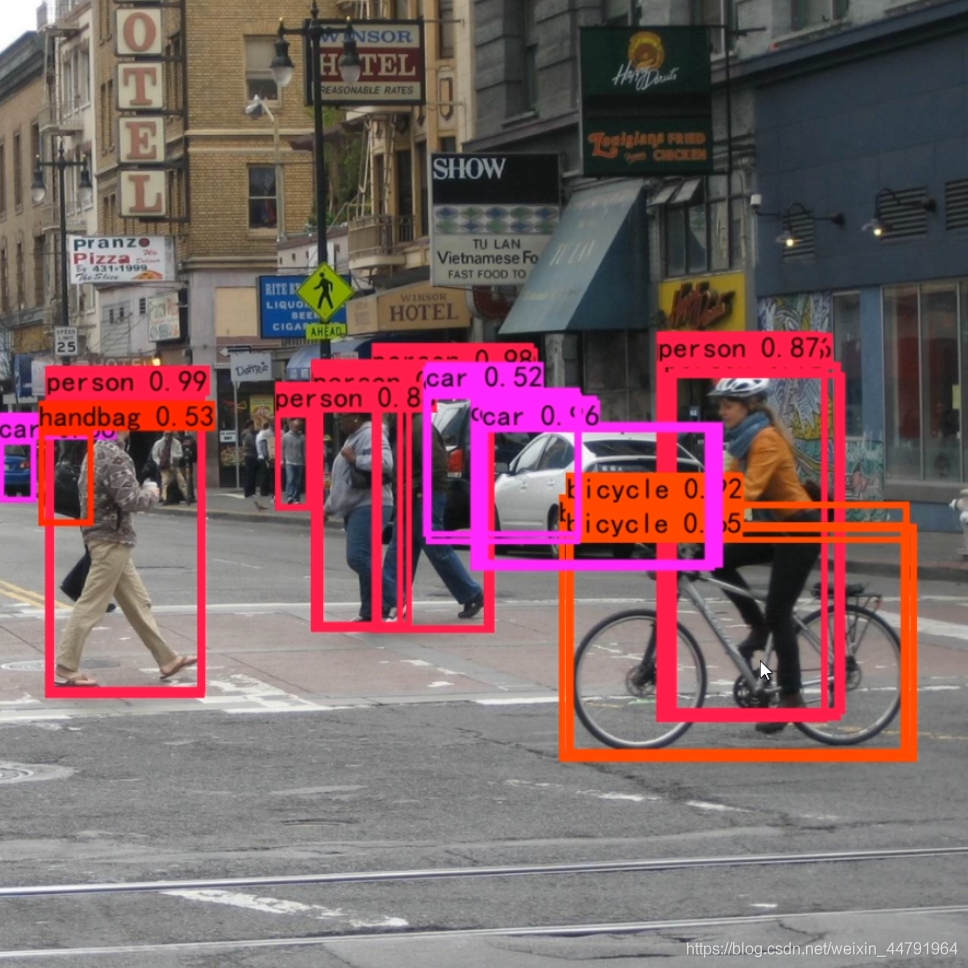
實作代碼為:
box_scores = box_confidence * box_class_probs
#-----------------------------------------------------------#
# 判斷得分是否大于score_threshold
#-----------------------------------------------------------#
mask = box_scores >= confidence
max_boxes_tensor = K.constant(max_boxes, dtype='int32')
boxes_out = []
scores_out = []
classes_out = []
for c in range(num_classes):
#-----------------------------------------------------------#
# 取出所有box_scores >= score_threshold的框,和成績
#-----------------------------------------------------------#
class_boxes = tf.boolean_mask(boxes, mask[:, c])
class_box_scores = tf.boolean_mask(box_scores[:, c], mask[:, c])
#-----------------------------------------------------------#
# 非極大抑制
# 保留一定區域內得分最大的框
#-----------------------------------------------------------#
nms_index = tf.image.non_max_suppression(class_boxes, class_box_scores, max_boxes_tensor, iou_threshold=nms_iou)
#-----------------------------------------------------------#
# 獲取非極大抑制后的結果
# 下列三個分別是:框的位置,得分與種類
#-----------------------------------------------------------#
class_boxes = K.gather(class_boxes, nms_index)
class_box_scores = K.gather(class_box_scores, nms_index)
classes = K.ones_like(class_box_scores, 'int32') * c
boxes_out.append(class_boxes)
scores_out.append(class_box_scores)
classes_out.append(classes)
boxes_out = K.concatenate(boxes_out, axis=0)
scores_out = K.concatenate(scores_out, axis=0)
classes_out = K.concatenate(classes_out, axis=0)
四、訓練部分
1、計算loss所需引數
在計算loss的時候,實際上是y_pre和y_true之間的對比:
y_pre就是一幅影像經過網路之后的輸出,內部含有三個特征層的內容;其需要解碼才能夠在圖上作畫
y_true就是一個真實影像中,它的每個真實框對應的(13,13)、(26,26)、(52,52)網格上的偏移位置、長寬與種類,其仍需要編碼才能與y_pred的結構一致
實際上y_pre和y_true內容的shape都是
(batch_size,13,13,3,85)
(batch_size,26,26,3,85)
(batch_size,52,52,3,85)
2、y_pre是什么
對于YoloV3的模型來說,網路最后輸出的內容就是三個特征層每個網格點對應的預測框及其種類,即三個特征層分別對應著圖片被分為不同size的網格后,每個網格點上三個先驗框對應的位置、置信度及其種類,
對于輸出的y1、y2、y3而言,[…, : 2]指的是相對于每個網格點的偏移量,[…, 2: 4]指的是寬和高,[…, 4: 5]指的是該框的置信度,[…, 5: ]指的是每個種類的預測概率,
現在的y_pre還是沒有解碼的,解碼了之后才是真實影像上的情況,
3、y_true是什么,
y_true就是一個真實影像中,它的每個真實框對應的(13,13)、(26,26)、(52,52)網格上的偏移位置、長寬與種類,其仍需要編碼才能與y_pred的結構一致
在YoloV3中,其使用了一個專門的函式用于處理讀取進來的圖片的框的真實情況,
def preprocess_true_boxes(true_boxes, input_shape, anchors, num_classes):
其輸入為:
true_boxes:shape為(m, T, 5)代表m張圖T個框的x_min、y_min、x_max、y_max、class_id,
input_shape:輸入的形狀,此處為416、416
anchors:代表9個先驗框的大小
num_classes:種類的數量,
其實對真實框的處理是將真實框轉化成圖片中相對網格的xyhw,步驟如下:
1、取框的真實值,獲取其框的中心及其寬高,除去input_shape變成比例的模式,
2、建立全為0的y_true,y_true是一個串列,包含三個特征層,shape分別為(m,13,13,3,85),(m,26,26,3,85),(m,52,52,3,85),
3、對每一張圖片處理,將每一張圖片中的真實框的wh和先驗框的wh對比,計算IOU值,選取其中IOU最高的一個,得到其所屬特征層及其網格點的位置,在對應的y_true中將內容進行保存,
for t, n in enumerate(best_anchor):
for l in range(num_layers):
if n in anchor_mask[l]:
# 計算該目標在第l個特征層所處網格的位置
i = np.floor(true_boxes[b,t,0]*grid_shapes[l][1]).astype('int32')
j = np.floor(true_boxes[b,t,1]*grid_shapes[l][0]).astype('int32')
# 找到best_anchor索引的索引
k = anchor_mask[l].index(n)
c = true_boxes[b,t, 4].astype('int32')
# 保存到y_true中
y_true[l][b, j, i, k, 0:4] = true_boxes[b,t, 0:4]
y_true[l][b, j, i, k, 4] = 1
y_true[l][b, j, i, k, 5+c] = 1
對于最后輸出的y_true而言,只有每個圖里每個框最對應的位置有資料,其它的地方都為0,
preprocess_true_boxes全部的代碼如下:
def preprocess_true_boxes(self, true_boxes, input_shape, anchors, num_classes):
assert (true_boxes[..., 4]<num_classes).all(), 'class id must be less than num_classes'
#-----------------------------------------------------------#
# 獲得框的坐標和圖片的大小
#-----------------------------------------------------------#
true_boxes = np.array(true_boxes, dtype='float32')
input_shape = np.array(input_shape, dtype='int32')
#-----------------------------------------------------------#
# 一共有三個特征層數
#-----------------------------------------------------------#
num_layers = len(self.anchors_mask)
#-----------------------------------------------------------#
# m為圖片數量,grid_shapes為網格的shape
#-----------------------------------------------------------#
m = true_boxes.shape[0]
grid_shapes = [input_shape // {0:32, 1:16, 2:8}[l] for l in range(num_layers)]
#-----------------------------------------------------------#
# y_true的格式為(m,13,13,3,85)(m,26,26,3,85)(m,52,52,3,85)
#-----------------------------------------------------------#
y_true = [np.zeros((m, grid_shapes[l][0], grid_shapes[l][1], len(self.anchors_mask[l]), 5 + num_classes),
dtype='float32') for l in range(num_layers)]
#-----------------------------------------------------------#
# 通過計算獲得真實框的中心和寬高
# 中心點(m,n,2) 寬高(m,n,2)
#-----------------------------------------------------------#
boxes_xy = (true_boxes[..., 0:2] + true_boxes[..., 2:4]) // 2
boxes_wh = true_boxes[..., 2:4] - true_boxes[..., 0:2]
#-----------------------------------------------------------#
# 將真實框歸一化到小數形式
#-----------------------------------------------------------#
true_boxes[..., 0:2] = boxes_xy / input_shape[::-1]
true_boxes[..., 2:4] = boxes_wh / input_shape[::-1]
#-----------------------------------------------------------#
# [9,2] -> [1,9,2]
#-----------------------------------------------------------#
anchors = np.expand_dims(anchors, 0)
anchor_maxes = anchors / 2.
anchor_mins = -anchor_maxes
#-----------------------------------------------------------#
# 長寬要大于0才有效
#-----------------------------------------------------------#
valid_mask = boxes_wh[..., 0]>0
for b in range(m):
#-----------------------------------------------------------#
# 對每一張圖進行處理
#-----------------------------------------------------------#
wh = boxes_wh[b, valid_mask[b]]
if len(wh) == 0: continue
#-----------------------------------------------------------#
# [n,2] -> [n,1,2]
#-----------------------------------------------------------#
wh = np.expand_dims(wh, -2)
box_maxes = wh / 2.
box_mins = - box_maxes
#-----------------------------------------------------------#
# 計算所有真實框和先驗框的交并比
# intersect_area [n,9]
# box_area [n,1]
# anchor_area [1,9]
# iou [n,9]
#-----------------------------------------------------------#
intersect_mins = np.maximum(box_mins, anchor_mins)
intersect_maxes = np.minimum(box_maxes, anchor_maxes)
intersect_wh = np.maximum(intersect_maxes - intersect_mins, 0.)
intersect_area = intersect_wh[..., 0] * intersect_wh[..., 1]
box_area = wh[..., 0] * wh[..., 1]
anchor_area = anchors[..., 0] * anchors[..., 1]
iou = intersect_area / (box_area + anchor_area - intersect_area)
#-----------------------------------------------------------#
# 維度是[n,] 感謝 消盡不死鳥 的提醒
#-----------------------------------------------------------#
best_anchor = np.argmax(iou, axis=-1)
for t, n in enumerate(best_anchor):
#-----------------------------------------------------------#
# 找到每個真實框所屬的特征層
#-----------------------------------------------------------#
for l in range(num_layers):
if n in self.anchors_mask[l]:
#-----------------------------------------------------------#
# floor用于向下取整,找到真實框所屬的特征層對應的x、y軸坐標
#-----------------------------------------------------------#
i = np.floor(true_boxes[b,t,0] * grid_shapes[l][1]).astype('int32')
j = np.floor(true_boxes[b,t,1] * grid_shapes[l][0]).astype('int32')
#-----------------------------------------------------------#
# k指的的當前這個特征點的第k個先驗框
#-----------------------------------------------------------#
k = self.anchors_mask[l].index(n)
#-----------------------------------------------------------#
# c指的是當前這個真實框的種類
#-----------------------------------------------------------#
c = true_boxes[b, t, 4].astype('int32')
#-----------------------------------------------------------#
# y_true的shape為(m,13,13,3,85)(m,26,26,3,85)(m,52,52,3,85)
# 最后的85可以拆分成4+1+80,4代表的是框的中心與寬高、
# 1代表的是置信度、80代表的是種類
#-----------------------------------------------------------#
y_true[l][b, j, i, k, 0:4] = true_boxes[b, t, 0:4]
y_true[l][b, j, i, k, 4] = 1
y_true[l][b, j, i, k, 5+c] = 1
return y_true
4、loss的計算程序
在得到了y_pre和y_true后怎么對比呢?不是簡單的減一下就可以的呢,
loss值需要對三個特征層進行處理,這里以最小的特征層為例,
1、利用y_true取出該特征層中真實存在目標的點的位置(m,13,13,3,1)及其對應的種類(m,13,13,3,80),
2、將yolo_outputs的預測值輸出進行處理,得到reshape后的預測值y_pre,shape分別為(m,13,13,3,85),(m,26,26,3,85),(m,52,52,3,85),還有解碼后的xy,wh,
3、獲取真實框編碼后的值,后面用于計算loss,編碼后的值其含義與y_pre相同,可用于計算loss,
4、對于每一幅圖,計算其中所有真實框與預測框的IOU,取出每個網路點中IOU最大的先驗框,如果這個最大的IOU都小于ignore_thresh,則保留,一般來說ignore_thresh取0.5,該步的目的是為了平衡負樣本,
5、計算xy和wh上的loss,其計算的是實際上存在目標的,利用第三步真實框編碼后的的結果和未處理的預測結果進行對比得到loss,
6、計算置信度的loss,其有兩部分構成,第一部分是實際上存在目標的,預測結果中置信度的值與1對比;第二部分是實際上不存在目標的,在第四步中得到其最大IOU的值與0對比,
7、計算預測種類的loss,其計算的是實際上存在目標的,預測類與真實類的差距,
其實際上計算的總的loss是三個loss的和,這三個loss分別是:
- 實際存在的框,編碼后的長寬與xy軸偏移量與預測值的差距,
- 實際存在的框,預測結果中置信度的值與1對比;實際不存在的框,在上述步驟中,在第四步中得到其最大IOU的值與0對比,
- 實際存在的框,種類預測結果與實際結果的對比,
其實際代碼如下,使用yolo_loss就可以獲得loss值:
import tensorflow as tf
from tensorflow.keras import backend as K
from utils.utils_bbox import decode_anchors, get_grid_anchors
#---------------------------------------------------#
# 用于計算每個預測框與真實框的iou
#---------------------------------------------------#
def box_iou(b1, b2):
#---------------------------------------------------#
# num_anchor,1,4
# 計算左上角的坐標和右下角的坐標
#---------------------------------------------------#
b1 = K.expand_dims(b1, -2)
b1_xy = b1[..., :2]
b1_wh = b1[..., 2:4]
b1_wh_half = b1_wh/2.
b1_mins = b1_xy - b1_wh_half
b1_maxes = b1_xy + b1_wh_half
#---------------------------------------------------#
# 1,n,4
# 計算左上角和右下角的坐標
#---------------------------------------------------#
b2 = K.expand_dims(b2, 0)
b2_xy = b2[..., :2]
b2_wh = b2[..., 2:4]
b2_wh_half = b2_wh/2.
b2_mins = b2_xy - b2_wh_half
b2_maxes = b2_xy + b2_wh_half
#---------------------------------------------------#
# 計算重合面積
#---------------------------------------------------#
intersect_mins = K.maximum(b1_mins, b2_mins)
intersect_maxes = K.minimum(b1_maxes, b2_maxes)
intersect_wh = K.maximum(intersect_maxes - intersect_mins, 0.)
intersect_area = intersect_wh[..., 0] * intersect_wh[..., 1]
b1_area = b1_wh[..., 0] * b1_wh[..., 1]
b2_area = b2_wh[..., 0] * b2_wh[..., 1]
iou = intersect_area / (b1_area + b2_area - intersect_area)
return iou
#---------------------------------------------------#
# loss值計算
#---------------------------------------------------#
def yolo_loss(args, input_shape, anchors, anchors_mask, num_classes, ignore_thresh=.5, print_loss=False):
num_layers = len(anchors_mask)
#---------------------------------------------------------------------------------------------------#
# 將預測結果和實際ground truth分開,args是[*model_body.output, *y_true]
# y_true是一個串列,包含三個特征層,shape分別為:
# (m,13,13,3,85)
# (m,26,26,3,85)
# (m,52,52,3,85)
# yolo_outputs是一個串列,包含三個特征層,shape分別為:
# (m,13,13,3,85)
# (m,26,26,3,85)
# (m,52,52,3,85)
#---------------------------------------------------------------------------------------------------#
y_true = args[num_layers:]
yolo_outputs = args[:num_layers]
#-----------------------------------------------------------#
# 得到input_shpae為416,416
#-----------------------------------------------------------#
input_shape = K.cast(input_shape, K.dtype(y_true[0]))
batch_size = K.cast(K.shape(yolo_outputs[0])[0], K.dtype(y_true[0]))
#-----------------------------------------------------------#
# 取出每一張圖片
# m的值就是batch_size
#-----------------------------------------------------------#
m = K.shape(yolo_outputs[0])[0]
#-----------------------------------------------------------#
# 對特征層進行回圈
# grid_anchors 代表每一個特征層所對應的先驗框
# grid_whs 代表每一個特征層所對應的寬高
# reshape_outputs 代表YOLO網路的輸出
# reshape_y_true 代表真實框的情況
#-----------------------------------------------------------#
grid_anchors = []
grid_whs = []
reshape_outputs = []
reshape_y_true = []
for l in range(len(anchors_mask)):
grid_anchor, grid_wh = get_grid_anchors(yolo_outputs[l], anchors[anchors_mask[l]])
grid_anchors.append(grid_anchor)
grid_whs.append(grid_wh)
reshape_outputs.append(K.reshape(yolo_outputs[l], [batch_size, -1, num_classes + 5]))
reshape_y_true.append(K.reshape(y_true[l], [batch_size, -1, num_classes + 5]))
grid_anchors = K.concatenate(grid_anchors, axis = 0)
grid_whs = K.concatenate(grid_whs, axis = 0)
reshape_outputs = K.concatenate(reshape_outputs, axis = 1)
reshape_y_true = K.concatenate(reshape_y_true, axis = 1)
#----------------------------------------------------------#
# 取出該特征層中存在目標的點的位置,(m,num_anchor,1)
#-----------------------------------------------------------#
object_mask = reshape_y_true[..., 4:5]
#-----------------------------------------------------------#
# 取出其對應的種類(m,num_anchor,80)
#-----------------------------------------------------------#
true_class_probs = reshape_y_true[..., 5:]
#-----------------------------------------------------------#
# 將yolo_outputs的特征層輸出進行處理,對先驗框進行解碼!
# pred_xy (m,num_anchor,2) 解碼后的中心坐標
# pred_wh (m,num_anchor,2) 解碼后的寬高坐標
#-----------------------------------------------------------#
box_xy, box_wh, _, _ = decode_anchors(reshape_outputs, grid_anchors, grid_whs, input_shape)
#-----------------------------------------------------------#
# pred_box是解碼后的預測的box的位置 (m,num_anchor,4)
#-----------------------------------------------------------#
pred_box = K.concatenate([box_xy, box_wh])
#-----------------------------------------------------------#
# 找到負樣本群組,第一步是創建一個陣列,[]
#-----------------------------------------------------------#
ignore_mask = tf.TensorArray(K.dtype(y_true[0]), size = 1, dynamic_size = True)
object_mask_bool = K.cast(object_mask, 'bool')
#-----------------------------------------------------------#
# 對每一張圖片計算ignore_mask
#-----------------------------------------------------------#
def loop_body(b, ignore_mask):
#-----------------------------------------------------------#
# 取出n個真實框:n,4
#-----------------------------------------------------------#
true_box = tf.boolean_mask(reshape_y_true[b, ..., 0:4], object_mask_bool[b, ..., 0])
#-----------------------------------------------------------#
# 計算預測框與真實框的iou
# pred_box (num_anchor,4) 預測框的坐標
# true_box (n,4) 真實框的坐標
# iou (num_anchor,n) 預測框和真實框的iou
#-----------------------------------------------------------#
iou = box_iou(pred_box[b], true_box)
#-----------------------------------------------------------#
# best_iou (num_anchor,) 每個特征點與真實框的最大重合程度
#-----------------------------------------------------------#
best_iou = K.max(iou, axis=-1)
#-----------------------------------------------------------#
# 將與真實框重合度小于0.5以下的預測框對應的先驗框作為負樣本
# 當預測框和真實框重合度較大時,不宜作為負樣本,
# 因為這些框已經預測的比較準確了
#-----------------------------------------------------------#
ignore_mask = ignore_mask.write(b, K.cast(best_iou < ignore_thresh, K.dtype(true_box)))
return b + 1, ignore_mask
#-----------------------------------------------------------#
# 在這個地方進行一個回圈、回圈是對每一張圖片進行的
#-----------------------------------------------------------#
_, ignore_mask = tf.while_loop(lambda b,*args: b<m, loop_body, [0, ignore_mask])
#-----------------------------------------------------------#
# ignore_mask用于提取出作為負樣本的特征點
# (m,num_anchor)
#-----------------------------------------------------------#
ignore_mask = ignore_mask.stack()
# (m,num_anchor,1)
ignore_mask = K.expand_dims(ignore_mask, -1)
#-----------------------------------------------------------#
# 將真實框進行編碼,使其格式與預測的相同,后面用于計算loss
#-----------------------------------------------------------#
raw_true_xy = reshape_y_true[..., :2] * grid_whs - grid_anchors[..., :2]
raw_true_wh = K.log(reshape_y_true[..., 2:4] / grid_anchors[..., 2:] * input_shape[::-1])
#-----------------------------------------------------------#
# object_mask如果真實存在目標則保存其wh值
# switch介面,就是一個if/else條件判斷陳述句
#-----------------------------------------------------------#
raw_true_wh = K.switch(object_mask, raw_true_wh, K.zeros_like(raw_true_wh))
#-----------------------------------------------------------#
# reshape_y_true[...,2:3]和reshape_y_true[...,3:4]
# 表示真實框的寬高,二者均在0-1之間
# 真實框越大,比重越小,小框的比重更大,
#-----------------------------------------------------------#
box_loss_scale = 2 - reshape_y_true[...,2:3] * reshape_y_true[...,3:4]
#-----------------------------------------------------------#
# 利用binary_crossentropy計算中心點偏移情況,效果更好
#-----------------------------------------------------------#
xy_loss = object_mask * box_loss_scale * K.binary_crossentropy(raw_true_xy, reshape_outputs[...,0:2], from_logits=True)
#-----------------------------------------------------------#
# wh_loss用于計算寬高損失
#-----------------------------------------------------------#
wh_loss = object_mask * box_loss_scale * 0.5 * K.square(raw_true_wh - reshape_outputs[...,2:4])
#------------------------------------------------------------------------------#
# 如果該位置本來有框,那么計算1與置信度的交叉熵
# 如果該位置本來沒有框,那么計算0與置信度的交叉熵
# 在這其中會忽略一部分樣本,這些被忽略的樣本滿足條件best_iou<ignore_thresh
# 該操作的目的是:
# 忽略預測結果與真實框非常對應特征點,因為這些框已經比較準了
# 不適合當作負樣本,所以忽略掉,
#------------------------------------------------------------------------------#
confidence_loss = object_mask * K.binary_crossentropy(object_mask, reshape_outputs[...,4:5], from_logits=True) + \
(1 - object_mask) * K.binary_crossentropy(object_mask, reshape_outputs[...,4:5], from_logits=True) * ignore_mask
class_loss = object_mask * K.binary_crossentropy(true_class_probs, reshape_outputs[...,5:], from_logits=True)
#-----------------------------------------------------------#
# 將所有損失求和
#-----------------------------------------------------------#
xy_loss = K.sum(xy_loss)
wh_loss = K.sum(wh_loss)
confidence_loss = K.sum(confidence_loss)
class_loss = K.sum(class_loss)
#-----------------------------------------------------------#
# 計算正樣本數量
#-----------------------------------------------------------#
num_pos = tf.maximum(K.sum(K.cast(object_mask, tf.float32)), 1)
loss = xy_loss + wh_loss + confidence_loss + class_loss
if print_loss:
loss = tf.Print(loss, [loss, xy_loss, wh_loss, confidence_loss, class_loss, tf.shape(ignore_mask)], summarize=100, message='loss: ')
loss = loss / num_pos
return loss
訓練自己的YoloV3模型
首先前往Github下載對應的倉庫,下載完后利用解壓軟體解壓,之后用編程軟體打開檔案夾,
注意打開的根目錄必須正確,否則相對目錄不正確的情況下,代碼將無法運行,
一定要注意打開后的根目錄是檔案存放的目錄,
一、資料集的準備
本文使用VOC格式進行訓練,訓練前需要自己制作好資料集,如果沒有自己的資料集,可以通過Github連接下載VOC12+07的資料集嘗試下,
訓練前將標簽檔案放在VOCdevkit檔案夾下的VOC2007檔案夾下的Annotation中,
訓練前將圖片檔案放在VOCdevkit檔案夾下的VOC2007檔案夾下的JPEGImages中,
此時資料集的擺放已經結束,
二、資料集的處理
在完成資料集的擺放之后,我們需要對資料集進行下一步的處理,目的是獲得訓練用的2007_train.txt以及2007_val.txt,需要用到根目錄下的voc_annotation.py,
voc_annotation.py里面有一些引數需要設定,
分別是annotation_mode、classes_path、trainval_percent、train_percent、VOCdevkit_path,第一次訓練可以僅修改classes_path
'''
annotation_mode用于指定該檔案運行時計算的內容
annotation_mode為0代表整個標簽處理程序,包括獲得VOCdevkit/VOC2007/ImageSets里面的txt以及訓練用的2007_train.txt、2007_val.txt
annotation_mode為1代表獲得VOCdevkit/VOC2007/ImageSets里面的txt
annotation_mode為2代表獲得訓練用的2007_train.txt、2007_val.txt
'''
annotation_mode = 0
'''
必須要修改,用于生成2007_train.txt、2007_val.txt的目標資訊
與訓練和預測所用的classes_path一致即可
如果生成的2007_train.txt里面沒有目標資訊
那么就是因為classes沒有設定正確
僅在annotation_mode為0和2的時候有效
'''
classes_path = 'model_data/voc_classes.txt'
'''
trainval_percent用于指定(訓練集+驗證集)與測驗集的比例,默認情況下 (訓練集+驗證集):測驗集 = 9:1
train_percent用于指定(訓練集+驗證集)中訓練集與驗證集的比例,默認情況下 訓練集:驗證集 = 9:1
僅在annotation_mode為0和1的時候有效
'''
trainval_percent = 0.9
train_percent = 0.9
'''
指向VOC資料集所在的檔案夾
默認指向根目錄下的VOC資料集
'''
VOCdevkit_path = 'VOCdevkit'
classes_path用于指向檢測類別所對應的txt,以voc資料集為例,我們用的txt為:
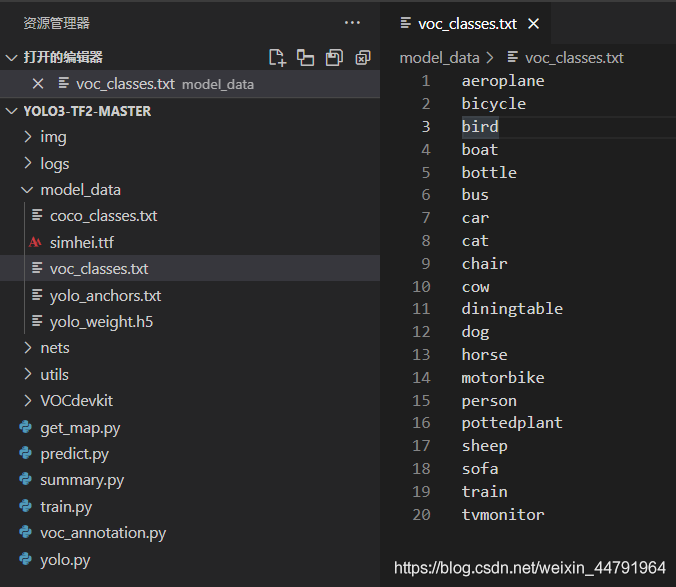
訓練自己的資料集時,可以自己建立一個cls_classes.txt,里面寫自己所需要區分的類別,
三、開始網路訓練
通過voc_annotation.py我們已經生成了2007_train.txt以及2007_val.txt,此時我們可以開始訓練了,
訓練的引數較多,大家可以在下載庫后仔細看注釋,其中最重要的部分依然是train.py里的classes_path,
classes_path用于指向檢測類別所對應的txt,這個txt和voc_annotation.py里面的txt一樣!訓練自己的資料集必須要修改!
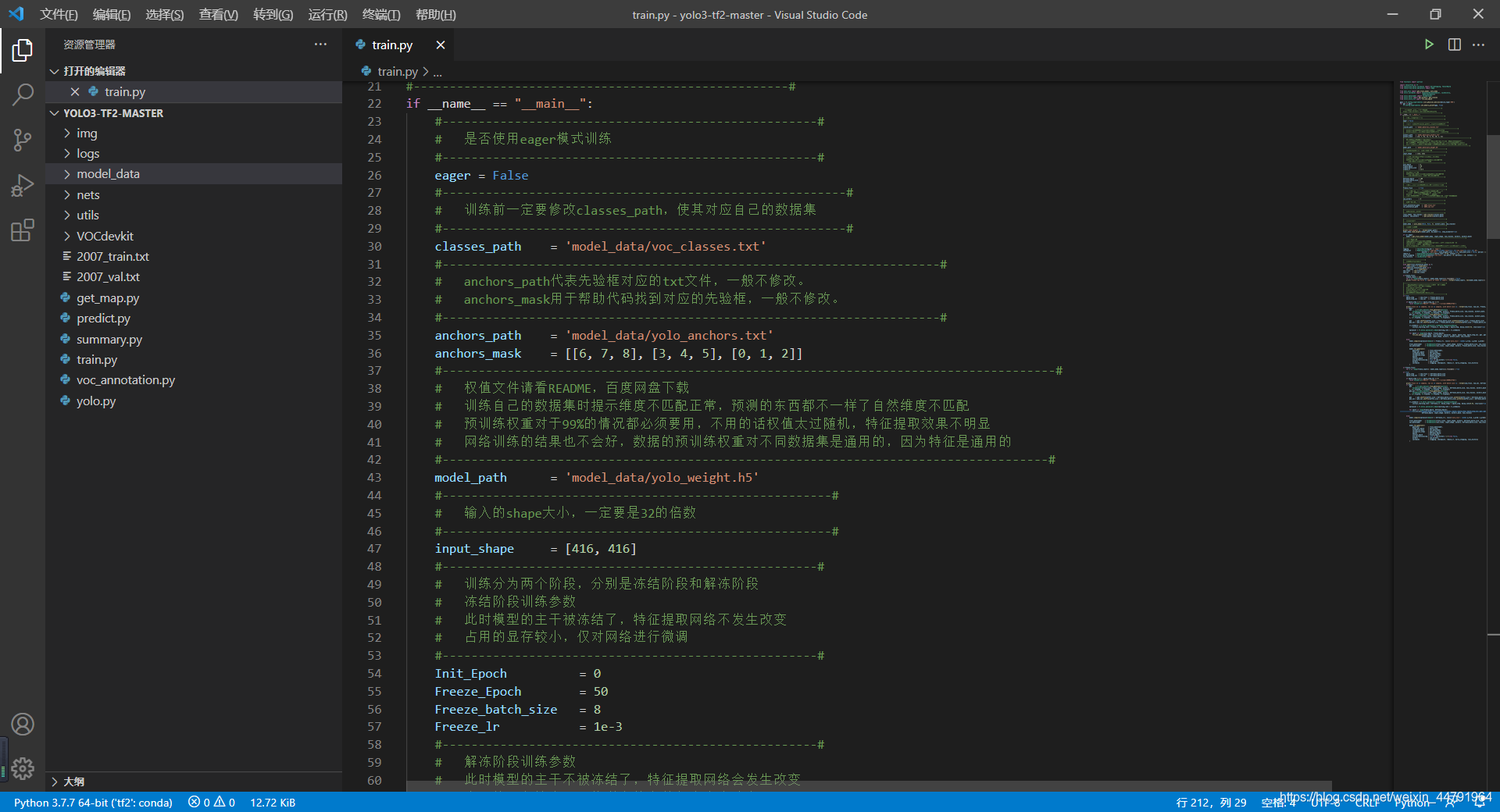
修改完classes_path后就可以運行train.py開始訓練了,在訓練多個epoch后,權值會生成在logs檔案夾中,
其它引數的作用如下:
'''
是否使用eager模式訓練
'''
eager = False
'''
訓練前一定要修改classes_path,使其對應自己的資料集
'''
classes_path = 'model_data/voc_classes.txt'
'''
anchors_path代表先驗框對應的txt檔案,一般不修改,
anchors_mask用于幫助代碼找到對應的先驗框,一般不修改,
'''
anchors_path = 'model_data/yolo_anchors.txt'
anchors_mask = [[6, 7, 8], [3, 4, 5], [0, 1, 2]]
'''
權值檔案請看README,百度網盤下載
訓練自己的資料集時提示維度不匹配正常,預測的東西都不一樣了自然維度不匹配
預訓練權重對于99%的情況都必須要用,不用的話權值太過隨機,特征提取效果不明顯
網路訓練的結果也不會好,資料的預訓練權重對不同資料集是通用的,因為特征是通用的
'''
model_path = 'model_data/yolo_weight.h5'
'''
輸入的shape大小,一定要是32的倍數
'''
input_shape = [416, 416]
'''
訓練分為兩個階段,分別是凍結階段和解凍階段
凍結階段訓練引數
此時模型的主干被凍結了,特征提取網路不發生改變
占用的顯存較小,僅對網路進行微調
'''
Init_Epoch = 0
Freeze_Epoch = 50
Freeze_batch_size = 8
Freeze_lr = 1e-3
'''
解凍階段訓練引數
此時模型的主干不被凍結了,特征提取網路會發生改變
占用的顯存較大,網路所有的引數都會發生改變
'''
UnFreeze_Epoch = 100
Unfreeze_batch_size = 4
Unfreeze_lr = 1e-4
'''
是否進行凍結訓練,默認先凍結主干訓練后解凍訓練,
'''
Freeze_Train = True
'''
用于設定是否使用多執行緒讀取資料,0代表關閉多執行緒
開啟后會加快資料讀取速度,但是會占用更多記憶體
keras里開啟多執行緒有些時候速度反而慢了許多
在IO為瓶頸的時候再開啟多執行緒,即GPU運算速度遠大于讀取圖片的速度,
'''
num_workers = 0
'''
獲得圖片路徑和標簽
'''
train_annotation_path = '2007_train.txt'
val_annotation_path = '2007_val.txt'
四、訓練結果預測
訓練結果預測需要用到兩個檔案,分別是yolo.py和predict.py,
我們首先需要去yolo.py里面修改model_path以及classes_path,這兩個引數必須要修改,
model_path指向訓練好的權值檔案,在logs檔案夾里,
classes_path指向檢測類別所對應的txt,
完成修改后就可以運行predict.py進行檢測了,運行后輸入圖片路徑即可檢測,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/293295.html
標籤:AI