Pytorch Note43 自動編碼器(Autoencoder)
文章目錄
- Pytorch Note43 自動編碼器(Autoencoder)
- 自動編碼器
- 資料預處理
- 定義網路
- 開始訓練
- 可視化
- 卷積神經網路 Autoencoder
全部筆記的匯總貼: Pytorch Note 快樂星球
自動編碼器
自動編碼器最開始是作為一種資料壓縮方法,同時還可以在卷積網路中進行逐層預訓練,但是隨后更多結構復雜的網路,比如 resnet 的出現使得我們能夠訓練任意深度的網路,自動編碼器就不再使用在這個方面,下面我們講一講自動編碼器的一個新的應用,這是隨著生成對抗模型而出現的,就是使用自動編碼器生成資料,
其特點有:
(1)跟資料相關程度很高,這意味著自動編碼器只能壓縮與訓練資料相似的資料.因為使用神經網路提取的特征一般是高度相關于原始的訓練集,使用人臉訓練出來的自動編碼器在壓縮自然界動物的圖片時表現就會比較差,因為它只學習到了人臉的特征,而沒有學習到自然界圖片的特征,
(2)壓縮后資料是有損的,這是因為在降維的程序中不可避免地要丟失資訊,到了2012年,人們發現在卷積神經網路中使用自動編碼器做逐層預訓練可以訓練更深層的網路,但是人們很快發現,良好的初始化策略要比復雜的逐層預訓練有效得多,2014年出現的 Batch Normalization技術也使得更深的網路能夠被有效訓練,到了2015年年底,通過殘差(ResNet)基本可以訓練任意深度的神經網路,
所以現在自動編碼器主要應用在兩個方面:第一是資料去噪,第二是進行可視化降維,自動編碼器還有一個功能,即生成資料,
自動編碼器的一般結構如下
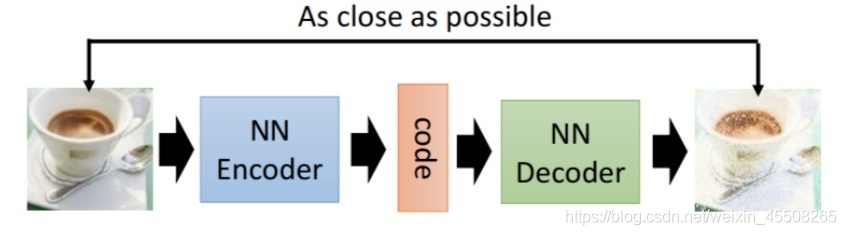
由上面的圖片,我們能夠看到,第一部分是編碼器(encoder),第二部分是解碼器(decoder),編碼器和解碼器都可以是任意的模型,通常我們可以使用神經網路作為我們的編碼器和解碼器,輸入的資料經過神經網路降維到一個編碼,然后又通過另外一個神經網路解碼得到一個與原始資料一模一樣的生成資料,通過比較原始資料和生成資料,希望他們盡可能接近,所以最小化他們之間的差異來訓練網路中編碼器和解碼器的引數,
當訓練完成之后,我們如何生成資料呢?非常簡單,我們只需要拿出解碼器的部分,然后隨機傳入 code,就可以通過解碼器生成各種各樣的資料
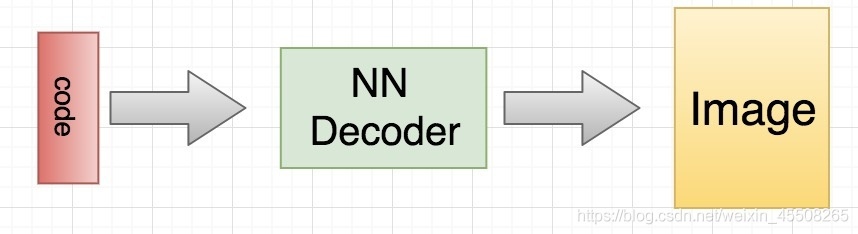
下面我們使用 mnist 資料集來說明一個如何構建一個簡單的自動編碼器
資料預處理
首先進行資料預處理和迭代器的構建
im_tfs = tfs.Compose([
tfs.ToTensor(),
tfs.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]) # 標準化
])
train_set = MNIST('./mnist', transform=im_tfs, download = True)
train_data = DataLoader(train_set, batch_size=128, shuffle=True)
定義網路
# 定義網路
class autoencoder(nn.Module):
def __init__(self):
super(autoencoder, self).__init__()
self.encoder = nn.Sequential(
nn.Linear(28*28, 128),
nn.ReLU(True),
nn.Linear(128, 64),
nn.ReLU(True),
nn.Linear(64, 12),
nn.ReLU(True),
nn.Linear(12, 3) # 輸出的 code 是 3 維,便于可視化
)
self.decoder = nn.Sequential(
nn.Linear(3, 12),
nn.ReLU(True),
nn.Linear(12, 64),
nn.ReLU(True),
nn.Linear(64, 128),
nn.ReLU(True),
nn.Linear(128, 28*28),
nn.Tanh()
)
def forward(self, x):
encode = self.encoder(x)
decode = self.decoder(encode)
return encode, decode
這里定義的編碼器和解碼器都是 4 層神經網路作為模型,中間使用 relu 激活函式,最后輸出的 code 是三維,注意解碼器最后我們使用 tanh 作為激活函式,因為輸入圖片標準化在 -1 ~ 1 之間,所以輸出也要在 -1 ~ 1 這個范圍內,最后我們可以驗證一下
net = autoencoder()
x = torch.randn(1, 28*28) # batch size 是 1
code, _ = net(x)
print(code.shape)
torch.Size([1, 3])
可以看到最后得到的 code 就是三維的
criterion = nn.MSELoss(size_average=False)
optimizer = torch.optim.Adam(net.parameters(), lr=1e-3)
def to_img(x):
'''
定義一個函式將最后的結果轉換回圖片
'''
x = 0.5 * (x + 1.)
x = x.clamp(0, 1)
x = x.view(x.shape[0], 1, 28, 28)
return x
開始訓練
# 開始訓練自動編碼器
for e in range(100):
for im, _ in train_data:
im = im.view(im.shape[0], -1)
im = Variable(im)
# 前向傳播
_, output = net(im)
loss = criterion(output, im) / im.shape[0] # 平均
# 反向傳播
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (e+1) % 20 == 0: # 每 20 次,將生成的圖片保存一下
print('epoch: {}, Loss: {:.4f}'.format(e + 1, loss.data[0]))
pic = to_img(output.cpu().data)
if not os.path.exists('./simple_autoencoder'):
os.mkdir('./simple_autoencoder')
save_image(pic, './simple_autoencoder/image_{}.png'.format(e + 1))
訓練完成之后我們可以看看生成的圖片效果

可以看出,圖片還是具有較好的清晰度
可視化
我們可以將編碼的分布可視化出來,具體看看隨機給一個三維的編碼,能夠生成圖片的分布
import matplotlib.pyplot as plt
from matplotlib import cm
from mpl_toolkits.mplot3d import Axes3D
%matplotlib inline
# 可視化結果
view_data = (train_set.train_data[:200].type(torch.FloatTensor).view(-1, 28*28) / 255. - 0.5) / 0.5
view_data = view_data.to(device)
encode, _ = net(view_data) # 提取壓縮的特征值
fig = plt.figure(2)
ax = Axes3D(fig) # 3D 圖
# x, y, z 的資料值
X = encode.data[:, 0].cpu().numpy()
Y = encode.data[:, 1].cpu().numpy()
Z = encode.data[:, 2].cpu().numpy()
values = train_set.train_labels[:200].numpy() # 標簽值
for x, y, z, s in zip(X, Y, Z, values):
c = cm.rainbow(int(255*s/9)) # 上色
ax.text(x, y, z, s, backgroundcolor=c) # 標位子
ax.set_xlim(X.min(), X.max())
ax.set_ylim(Y.min(), Y.max())
ax.set_zlim(Z.min(), Z.max())
plt.show()
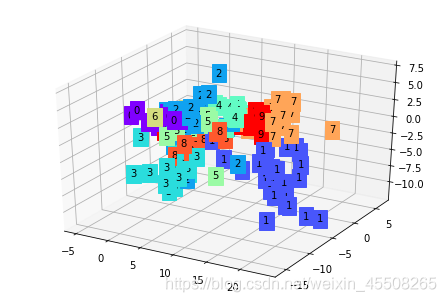
可以看到,不同種類的圖片進入自動編碼器之后會被編碼得不同,而相同型別的圖片經過自動編碼之后的編碼在幾何示意圖上距離較近,在訓練好自動編碼器之后,我們可以給一個隨機的 code,通過 decoder 生成圖片
code = torch.FloatTensor([[1.19, -3.36, 2.06]]) # 給一個 code 是 (1.19, -3.36, 2.06)
decode = net.decoder(code.to(device))
decode_img = to_img(decode).squeeze()
decode_img = decode_img.data.cpu().numpy() * 255
plt.imshow(decode_img.astype('uint8'), cmap='gray') # 生成圖片 3
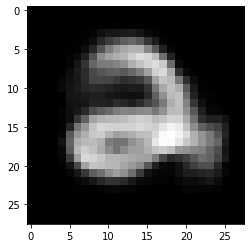
這里我們僅僅使用多層神經網路定義了一個自動編碼器,當然你會想到,為什么不使用效果更好的卷積神經網路呢?我們當然可以使用卷積神經網路來定義,下面我們就重新定義一個卷積神經網路來進行 autoencoder
卷積神經網路 Autoencoder
class conv_autoencoder(nn.Module):
def __init__(self):
super(conv_autoencoder, self).__init__()
self.encoder = nn.Sequential(
nn.Conv2d(1, 16, 3, stride=3, padding=1), # (b, 16, 10, 10)
nn.ReLU(True),
nn.MaxPool2d(2, stride=2), # (b, 16, 5, 5)
nn.Conv2d(16, 8, 3, stride=2, padding=1), # (b, 8, 3, 3)
nn.ReLU(True),
nn.MaxPool2d(2, stride=1) # (b, 8, 2, 2)
)
self.decoder = nn.Sequential(
nn.ConvTranspose2d(8, 16, 3, stride=2), # (b, 16, 5, 5)
nn.ReLU(True),
nn.ConvTranspose2d(16, 8, 5, stride=3, padding=1), # (b, 8, 15, 15)
nn.ReLU(True),
nn.ConvTranspose2d(8, 1, 2, stride=2, padding=1), # (b, 1, 28, 28)
nn.Tanh()
)
def forward(self, x):
encode = self.encoder(x)
decode = self.decoder(encode)
return encode, decode
conv_net = conv_autoencoder()
if torch.cuda.is_available():
conv_net = conv_net.cuda()
optimizer = torch.optim.Adam(conv_net.parameters(), lr=1e-3, weight_decay=1e-5)
對于卷積網路中,我們可以對輸入進行上采樣,那么對于卷積神經網路,我們可以使用轉置卷積進行這個操作,在 pytorch 中使用轉置卷積就是上面的操作,torch.nn.ConvTranspose2d() 就可以了,可以在某種意義上看成是反卷積,
# 開始訓練自動編碼器
for e in range(40):
for im, _ in train_data:
if torch.cuda.is_available():
im = im.cuda()
# 前向傳播
_, output = conv_net(im)
loss = criterion(output, im) / im.shape[0] # 平均
# 反向傳播
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (e+1) % 20 == 0: # 每 20 次,將生成的圖片保存一下
print('epoch: {}, Loss: {:.4f}'.format(e+1, loss.data))
pic = to_img(output.cpu().data)
if not os.path.exists('./conv_autoencoder'):
os.mkdir('./conv_autoencoder')
save_image(pic, './conv_autoencoder/image_{}.png'.format(e+1))
epoch: 20, Loss: 70.8879 epoch: 40, Loss: 74.8522
最后我們看看結果

跟前面的相比,兩者的區別其實并不大,只不過多層感知機的結果會稍微模糊一些
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/293299.html
標籤:AI