??大家好,我是不溫卜火,是一名計算機學院大資料專業大三的學生,昵稱來源于成語—
不溫不火,本意是希望自己性情溫和,作為一名互聯網行業的小白,博主寫博客一方面是為了記錄自己的學習程序,另一方面是總結自己所犯的錯誤希望能夠幫助到很多和自己一樣處于起步階段的萌新,但由于水平有限,博客中難免會有一些錯誤出現,有紕漏之處懇請各位大佬不吝賜教!博客主頁:https://buwenbuhuo.blog.csdn.net/
目錄
- 推薦
- 一、前言
- 1.產品和解決方案
- 2.產品理念
- 二、機器學習在神策資料的應用
- 1.智能推薦
- 個性化推薦:"為你推薦" “猜你喜歡”
- 相關推薦:“相關商品” “買了又買”
- 熱門推薦:"今日熱榜 " "今日爆款 "
- 智能推薦的基本步驟
- 智能推薦概念 — Embedding(最重要)
- 智能推薦模型—基于用戶行為的召回模型(最常見)
- 2.智能預警
- 智能判斷指標是否例外
- 自動分析出例外原因
- 時空預測`Prophet`
- 判斷例外:預測指標的正常區間
- 預測值 = 趨勢 + 周期性 + 特殊事件
- 3.用戶預測
- 用戶預測的產品形態
- 機器學習在神策資料的落地挑戰
- 自適應性
- 可解釋性
推薦

???各位如果想要交流的話,可以加下QQ交流群:974178910,里面有各種你想要的學習資料,?
一、前言

很抱歉,好久沒有更新博文了,最近抽出點時間整理了這篇關于《機器學習在神策資料的應用和挑戰》報告的文章,為什么說是抽出時間,總不能說最近總是打游戲不想更新博文吧,hh~
本次報告是在8月6號進行的,很抱歉快一個星期才進行整理,主講人胡士文先生是神策算資料機器學習演算法團隊專家,如果需要視頻的話可以私信博主,或者加交流群@群主,
在講解之前,我們需要先簡單介紹下神策資料
對于這個公司我們只需知道他是大資料分析及數字化運營解決方案的服務商,是To B型公司即可,除此之外,我們還需要了解產品和解決方案以及產品理念,
1.產品和解決方案

先從下往上簡單介紹:
資料根基部分:
- 資料治理平臺:進行資料采集以及簡單的資料治理,
- 資料倉庫:匯入、查詢、存盤資料,
- 資料智能:資料利用的資料智能引擎(此部分為重點介紹部分)
依托資料根基部分的兩個大的應用場景:分析云和營銷云
-
分析云:
分析云顧名思義就是基于材料資料進行分析的功能或作業,例如用戶行為分析,廣告投放分析等,
-
營銷云:
主要針對客戶針他們的用戶進行營銷的動作,做一些工具能夠更好的幫助客戶進行營銷,例如智能推薦、規則推薦等,
2.產品理念
其產品理念是基于資料流的SDAF運營框架
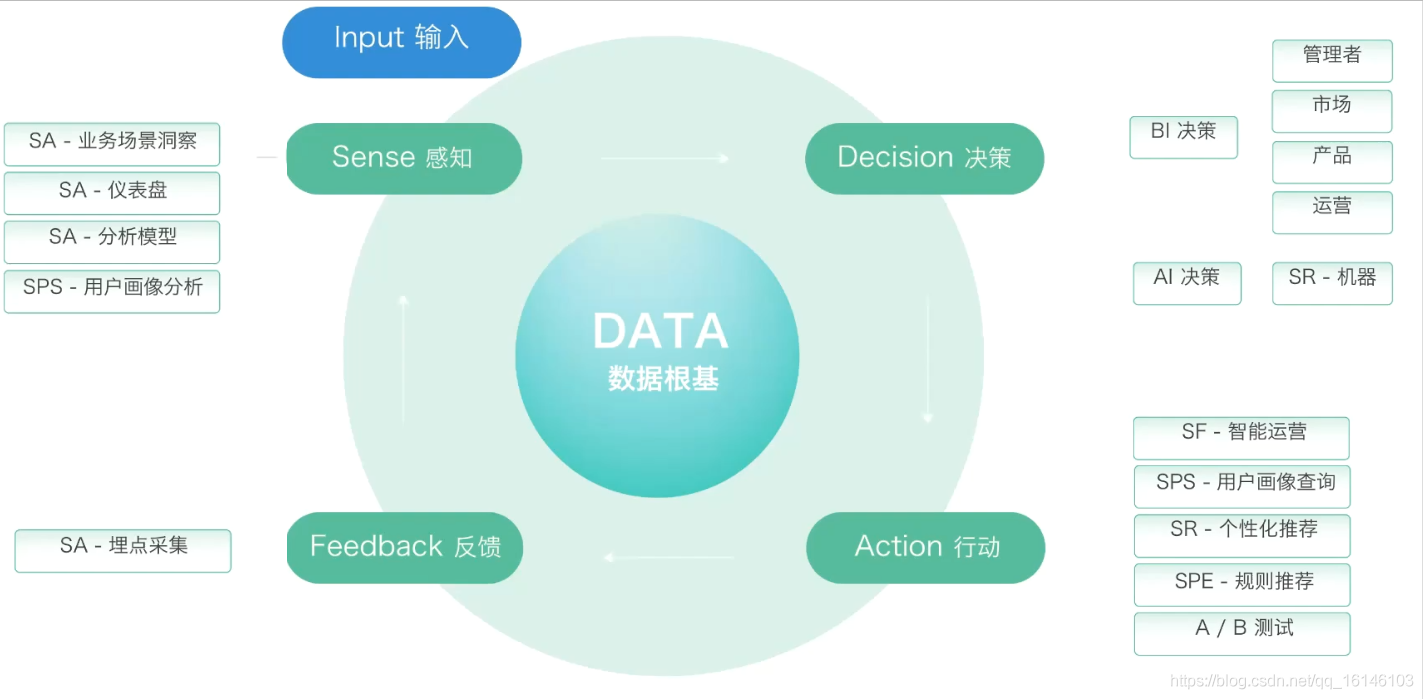
資料運營拆分成四個步驟,分別是:Sense(感知)、Decision(決策)、Action(行動)、Feedback(反饋),
在此我們以客戶準備對用戶做流失用戶的召回或者留存率的提升作為切入點,
-
首先需要感知資料:
看一下產品里面用戶的留存率是多少,用戶流失的原因嚴不嚴重,
-
其次進行決策:
決策可以基于BI決策,也可以基于AI的機器學習的決策,借助一些機器學習的模型去預測接下來哪些用戶會流失掉,可以知道高概率流失的用戶就是我接下來需要重點關照的用戶,
-
決策完成后開始行動:
對高概率流失的用戶進行一些處理動作,比如說發送短信、優惠券或者紅包吸引他們讓他們重新回到我們的產品里面,
-
最后進行基于資料的分析與反饋:
最終需要看運行情況的最終結果,
此流程是一個不斷迭代的流程(倍訓)
二、機器學習在神策資料的應用
好了,終于開始了正式環節,

1.智能推薦
智能推薦的三個基本場景有:個性化推薦、相關推薦、熱門推薦
個性化推薦:“為你推薦” “猜你喜歡”
個性化推薦一般是以用戶為維度,比如說你在京東上查看筆記本電腦,下拉會發現有為你推薦的相關筆記本電腦,

相關推薦:“相關商品” “買了又買”
相關推薦以具體的物品為維度,推薦與物品相關的物品,比如說你查看藍牙耳機,它會給你推薦其他相關的耳機商品資訊,

熱門推薦:"今日熱榜 " "今日爆款 "
熱門推薦基本上無個性化需求,主要呈現的是熱度較高的話題,比如說知乎熱榜,微博熱搜等,
智能推薦的基本步驟
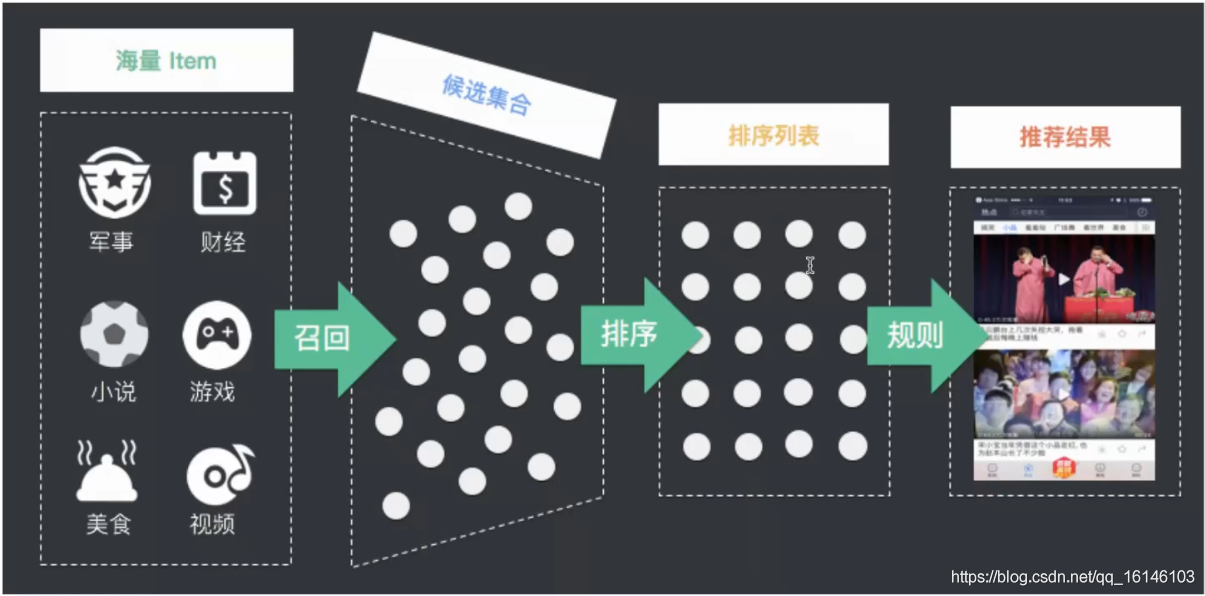
智能推薦在演算法的角度分解成三個步驟:召回、排序、規則
-
召回:
在一個場景內有很多可以給用戶呈現的內容,以今日頭條為例,今日頭條有千萬量級的文章,但是每一個用戶能夠一次性去瀏覽的資訊是及其有限的,所以推薦的第一步需要經過召回這個步驟,通過召回進行初步粗略的篩選用戶可能感興趣的內容,比如說本人喜歡歷史和地理,那么就會把與歷史和地理相關的內容回傳到候選集合當中, -
排序:
對召回階段存入到候選集合的內容進行打分,打分的依據是通過模型去預測用戶對每一個內容的可能感興趣的程度,本質是做預測, -
規則:
通過業務規則進行排序,比如說置頂的內容就是根據置頂規則實作的,
智能推薦概念 — Embedding(最重要)
個人理解在智能推薦里面最重要的概念是Embedding,Embedding有些地方叫詞向量,有的地方叫詞嵌入,叫法不同,但是本質上是一樣的,本質上是做一個向量化的事情,
Embedding并不是起源于推薦,而是起源于2013年谷歌發表的一篇論文《word2vec》,思想是把一篇文章里面的每一個詞映射到向量空間里面去,這樣詞就可以在向量空間里做一些相似計算,這篇文章奠定了2013年以后的所有的三元處理技術的一個發展和研究的方向,
2016年Youtube發表一篇借鑒《word2vec》的思路,只不過把向量化的思路搬到了智能推薦的場景下,文章的主要內容是用一個向量來描述一個用戶/物品/文章,這樣做的好處就是把一個推薦的問題轉化為一個向量計算的問題,如果能夠將一個用戶編碼成一個向量,將一個視頻或者一篇文章也能編碼成一個向量,那么這時再想做推薦就很簡單了,推薦無非就是說從數學上計算一下跟用戶向量最相近的物品向量是什么,把跟用戶向量最相近的物品推薦給用戶,
從16年以后推薦系統的嘗試也都是基于Embedding來進行的,深度學習在推薦系統中的應用,本質上是在將用戶和物品做更精準的向量化表示,
智能推薦模型—基于用戶行為的召回模型(最常見)
基于Embedding的推薦演算法也有很多,現在機器學習的推薦演算法都是基于Embedding的概念進行各種改進而成的,
- 基于用戶行為的召回模型(雙塔)
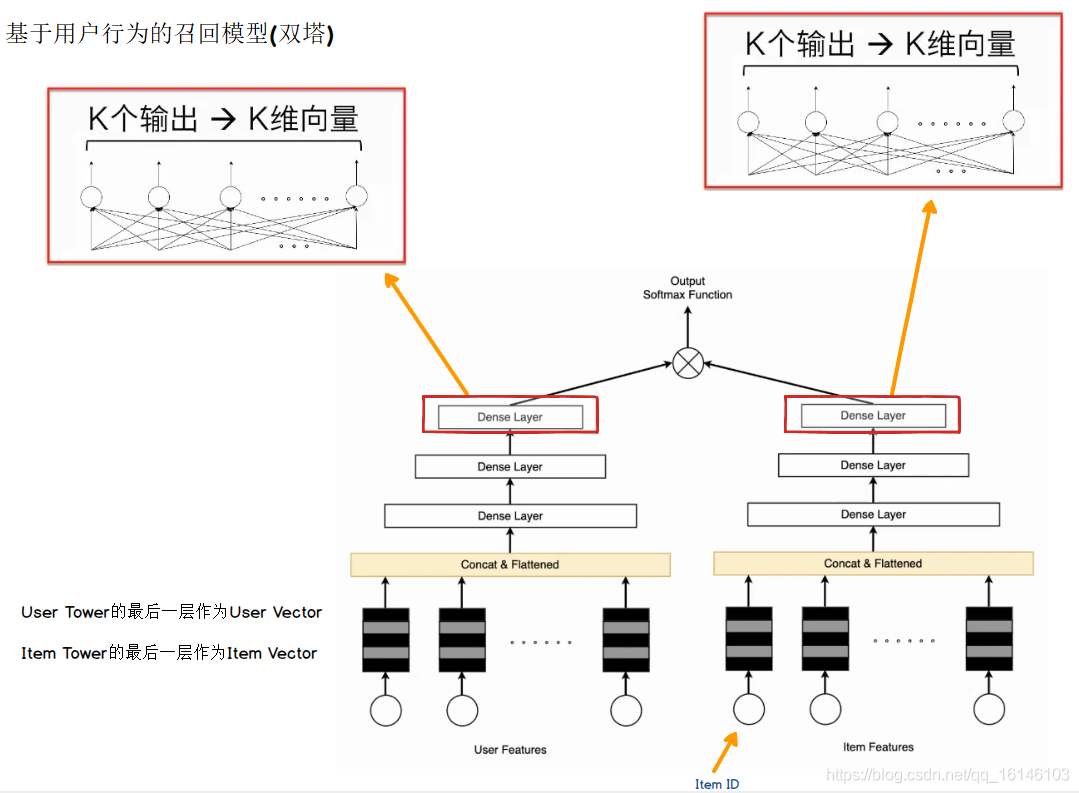
從深度學習的本身來說,這個模型并不是一個太復雜的模型,他其實就是一個簡單的前饋神經網路,前饋神經網路有幾個比較重要的方面,
第一個方面是它分成了兩路,我們叫其為雙塔,左邊的塔輸出的是用戶的特征,用戶的特征在推薦系統中最重要的是這個用戶以往有過什么樣的行為,比如說這個用戶以前點擊過或者觀看過什么樣的文章或者視頻或者商品,左邊的塔在建模用戶的特征,目的是希望左邊前饋神經網路最后這一層的輸出用來表示用戶的Embedding,左邊最后輸出的是一個k-v的向量,作為用戶的vector的表示,
右側這個塔也是典型的前饋神經網路,它的輸入是一些物品類的特征,以一個文章為例,輸入的就是這個文章的主題、文章的作者,以及文章的正文,可能還有文章的其他的一些屬性,作為特征輸入進去,右邊的這個塔也被稱為Item的塔,最終的目的是給物品做一個向量化的標識,最后輸出的是一個k-v的向量,向量標識物品本身,
最后通過用戶的向量和物品的向量做一個計算,如果說用戶點擊了這篇文章,希望模型能夠訓練到用戶和文章的相似度是比較高的程度,如果用戶沒有點擊過這篇文章,希望模型能夠訓練到用戶和文章的相似度是不高的程度,
通過這么一個簡單的神經網路的結構,就能夠訓練到用戶的向量和內容的向量,
-
為什么使用雙塔而不使用一個統一的神經網路呢?
這是基于工程實踐上的考慮,以今日頭潭訓者抖音為例,比如我做一次下滑的操作,產品上會很快的把推薦結果給回傳出來,也就是說整個推薦系統,在工業界其實是對時效性要求是很高的,通常的一次操作在100-200ms內把結果回傳出來,但是在像今日頭條這種場景下,整個的內容量是很大的,資料量有千萬級別是可被推薦的,在工程上怎么能夠在100ms以內或200ms以內完成所有
Item和User的符合興趣度的計算呢?雙塔模型提供了一個能夠近似的解決問題的方法,也就說通過兩個不同的塔建模用戶和內容,如果能夠提前把模型給訓練好,那么就可以單獨的把用戶的向量和內容的向量都提前給計算出來,計算這一步就不需要在用戶請求的時候去計算,可以提前把用戶的向量和內容的向量去計算好,當用戶發送請求過來的時候,只需要去查找跟用戶向量最相似的幾千個物品向量即可,在線上只需要做查找的作業,不需要做計算的作業,在整個工程性能上,在幾百毫秒的量級上能夠實時的回傳用戶感興趣的推薦的結果,所以進行這個設計,
2.智能預警
核心功能共有兩個,分別為:智能判斷指標是否例外和自動分析出例外原因,下面專門針對這兩個方面做講解,
智能判斷指標是否例外
- 智能預警的應用背景:
在分析產品里面,幫用戶采集許多基礎資料,以很多的互聯網客戶為例,把分析產品當成一個基礎的資料平臺來使用,平臺基本上會幫客戶采集他們產品的所有的用戶行為資料,客戶會在分析平臺看DAU(Daily Active User)、客戶的留存率、下單次數等等比較核心的業務指標,
在看指標的場景下,會有一個非常核心的需求,我們需要及時的幫助客戶去發現指標是否例外,舉個很簡單的例子,比如說以外賣客戶為例,他可能需要實時的監控訂單數,如果訂單數在某個時間點發生了很例外的變化的話,很有可能是他的產品某個方面出問題了,指標的例外是非常需要客戶區關注和關心的點,這里核心的需求:需要幫助客戶去做指標的監控和預警,傳統的預警方式就是配一些規則,比如說今天的指標低于昨天的20%就進行報警,又或者訂單比上個月低15%就進行報警等,
以往的預警都是通過一些規則去進行的,這樣做會出現什么樣的問題呢?這樣是不靈活的,第一我們不知道要怎樣區配置怎樣的規則是合理的,第二是資料呈現出周期性和趨勢的時候很難用一個規則去描述這個指標是否例外,針對于此,使用機器學習的方式去預測這個資料是例外還是正常的,讓其變成一個機器學習的問題,
自動分析出例外原因
此部分的第二個核心需求是當指標發生例外的時候,怎樣能夠迅速的自動的定位到例外的原因是什么,還以訂單資料例外為例,
假設平臺上的訂單量,14點的訂單量突然發生明顯的下降,老板這是肯定關心的是指標下降的原因是什么,如果能夠自動分析出ios的訂單量是正常的,但是安卓的訂單量是例外的,可能有理由去懷疑安卓端產品發生的BUG導致了訂單的例外,
在這個場景下第二個比較重要的需求是如何能夠自動的在已經能夠判斷出指標已經發生例外的情況下,能夠自動的找到例外發生的原因,
時空預測Prophet
在智能預警這一塊比較核心的需求:如何能夠智能的判斷出當前的指標是否正常,將其轉化成預測問題,通過預測這個指標當前的正常區間應該是什么,
判斷例外:預測指標的正常區間
指標預測的問題其實就是時序預測的問題,時序預測的問題其實有很多種解決的方法,它可以是一個分類的問題,用分類的方法去做,假設如果在某個業務場景下,能夠拿到許多標注資料,能夠知道哪些資料點是正常的,哪些資料點是例外的,可以用分類的模型去解決這些問題,
但是在我們這個場景下,因為其是一個比較標準化的解決方案,沒辦法去假設有很多標準資料,所以此部分的解決方案選擇的是一個時序預測的方式去預測指標的正常區間,當真實發生的指標不在預測區間里面,我們就認為指標發生了一次預警,
預測值 = 趨勢 + 周期性 + 特殊事件
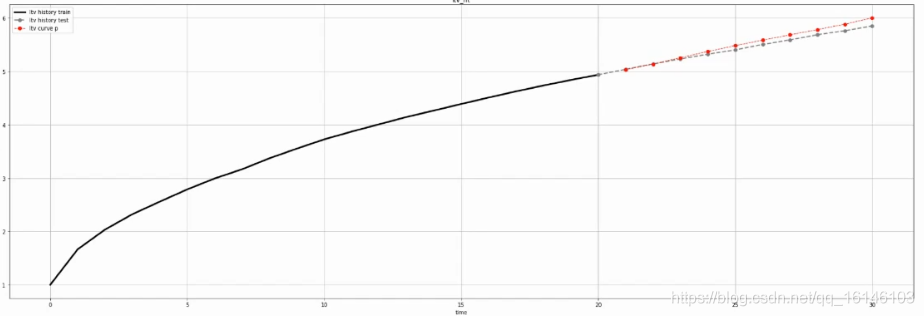
在時序預測目前用到的是開源的工具Prophet,Prophet是facebook開源的一個時間序列預測演算法,在此僅簡單介紹最核心的思想:把時序預測的一個值拆解成三個維度,分別是趨勢、周期性和特殊事件,然后用三個獨立的預測方法來分別預測指標的趨勢,指標的周期性以及去預測指標的特殊事件對預測值的影響,特殊事件比如"雙十一"和"618",這樣的一些比較大的特殊事件通常會對指標產生比較大的影響,
整個Prophet的一個比較大的思路就是把整個預測拆解成趨勢、周期性和特殊事件三個維度去分別做出預測和擬合,
在趨勢下和周期性這塊具體怎么做的,感興趣的可以去看prophet是怎么樣做的,facebook是有開源的paper和代碼的,
在此給出gitee地址以及主頁地址:
gitee地址:https://gitee.com/mirrors/prophet?utm_source=alading&utm_campaign=repo
主頁地址:https://facebook.github.io/prophet/
3.用戶預測
用戶預測的核心需求就是如何從海量的用戶中找到目標用戶,
舉幾個常見的例子:
比如說客戶他的哪些用戶更有可能流失,流失是客戶比較關心的一個指標和業務場景,他的需求可能是哪些用戶有比較高的流失風險,還有一種場景是哪些用戶是高轉化概率的用戶,如果我們能幫夠他找到哪些用戶是高流失的用戶,那么客戶接下來就可以有針對性的對用戶進行一些針對的運營和活動,好讓這些客戶可以留存下來,如果能夠幫客戶找到哪些用戶是可以轉化的用戶的話,客戶可以針對用戶進行一些營銷的動作,能夠完成用戶轉換,進而提升整個產品的收入,
在用戶預測這個場景下,To C的思路和To B的思路會很不一樣,如果說僅僅是一個C端的產品,要做一個用戶預測的產品,會先做一些用戶的樣本,構建特征工程,然后做模型的訓練和調參,最后得到預測結果,常用的模型有GBDT和LR這樣的模型來進行用戶預測,實際上在很多具體的C端產品下都是這樣做的,比如說像世紀佳緣、珍愛網等相親網站,他們要去預測哪一些用戶會更有可能購買他們的高端的或者比較貴的相親服務的可能,
但是在神策這種To B的產品下,面臨的問題是很不一樣的,下面主要講解機器學習落地遇到一些問題和挑戰以及解決方案,
可能有些讀者對To B和To C不了解,個人看到知乎的一篇帖子講解的很清晰,鏈接如下:
To B和To C,你真的知道它們之間的區別么?
用戶預測的產品形態
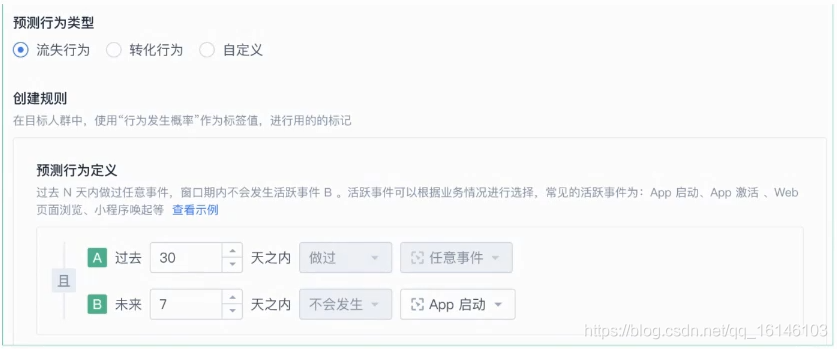
在此以流失為例,針對流失的定義在過去30天來過產品,并且未來七天之內沒有做過任何行為的用戶,我們認為他就是流失的用戶,只要客戶能夠把流失定義清楚,這個功能就能夠自動的幫客戶計算出每一個用戶流失的概率,但是由于神策是一個To B 產品的一種思路,是做的用戶預測的產品,所以這個思路和普通的C端公司做用戶的思路是不一樣的,
機器學習在神策資料的落地挑戰
以用戶預測的場景為例,去介紹機器學習在神策資料的落地的挑戰,
自適應性
自適應性這個詞可能有點模糊,不好理解,傳統的構建一個有效的模型的時候,我們通常需要進行以下幾個步驟:
- 資料采集
- 特征工程
- 模型選擇和訓練
- 調參
去做這樣一個預測模型,其實是需要投入比較多的人力的,并且周期也比較長,
假設我們去做一個用戶預測模型,只做一次預測需要多久? 比如說預測珍愛網或者世紀佳緣哪些用戶有可能購買高級相親服務,從目前了解到的情況而言,就僅做一個預測來說,在一些資料基礎和組織架構比較完善的公司最短大概兩到三周能夠去做一次預測,
回到神策的應用場景,我們要做的是一個產品化的功能,什么是產品化的功能,所謂產品化的功能就是我們提供給客戶一個產品,這個產品能夠幫助客戶把用戶預測這件事情給做出來,
按照傳統的思路做下來的話他會有幾個大的問題:
第一個就是整個周期很長,兩到三周,并且很多公司沒有能力做這件事情,
第二個更大的問題在To B的場景下,傳統的方法無法形成產品化的解決方案,
針對于此探索出來的解決方案:自動機器學習(AutoML)
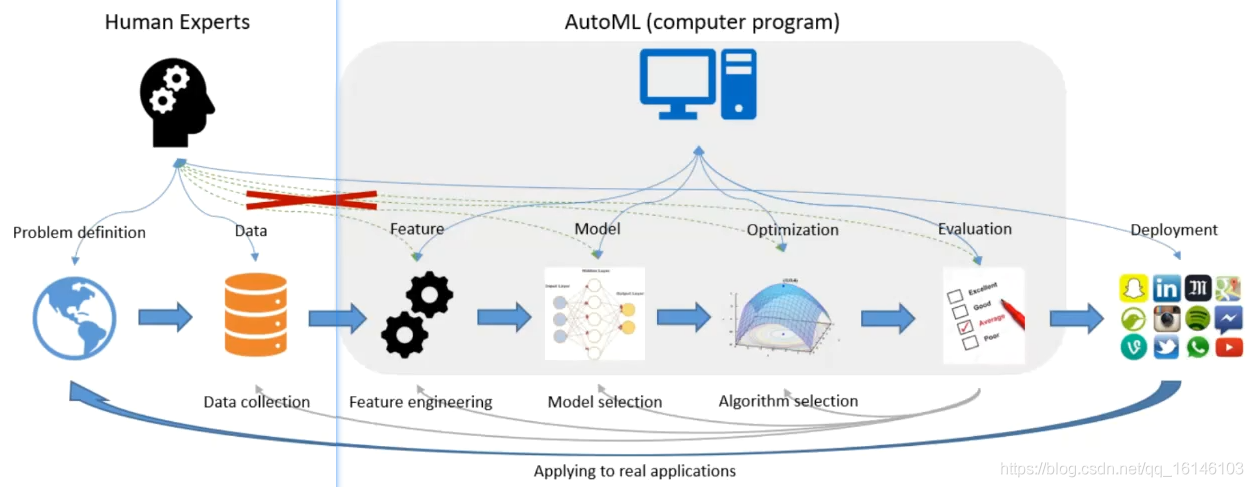
通過上圖我們可以看到兩個視角,第一個視角是傳統的機器學習方案,從問題定義—>資料—>特征—>模型—>優化—>評估,傳統的機器學習每一步都是人來做的,在自動機器學習的角度來看,只有問題的定義是人來做的,從特征—>模型—>優化—>評估都是自動去做的, 回歸到用戶行為預測,我們只需要用戶定義問題,產品就可以根據用戶的定義把結果計算出來,這一程序中,不需要用戶做特征工程,也不需要客戶進行調參等等,自動把結果計算出來,
-
什么是自動機器學習?
1.盡可能少的人力投入
2.在有限的計算模型做出最優的模型效果 -
在神策中自動機器學習要做的事情?
1.自動特征工程
2.自動模型選擇和訓練
自動特征工程是神策從20年以來探索機器學習怎么在To B的場景下怎么去做產品化的一個自己想到的一個點,因為手動特征工程對于客戶來說是行不通的,一定要自動的幫客戶做特征工程這件事情,哪怕自動特征工程會損失一些模型的準確性和精度,至少客戶是能用的起來的,
-
自動特征工程:
1、自動統計用戶在過去一段時間每個行為的次數
2、如果是在流失正常的情況下,自動統計用戶在過去一段時間每個行為的衰減情況,比如說預測這個用戶是否流失,可能會去構造特征,比如說他過去一個月登錄次數多少次,最近七天登錄多少次,如果最近七天比過去一個月登錄次數衰減很多,這就可能是一個比較關鍵的用戶的可能將要流失的特征,
3、onehot / 分箱特征處理,
4、在做自動特征工程這一塊,需要警惕特征穿越,特征穿越的意思是在模型訓練的時候,能夠拿到一些在實際預測中拿不到的特征,造成的結果就是模型訓練的結果很好,但是在實際的預測中的結果很差, -
自動模型選擇和訓練
1、GBDT vs RF vs LR
2、超參自動遍歷:grid search
3、優化方法自動遍歷:SGD vs FTRL vs L-BFGS
4、由于資料量大,所以會做資料采樣,能夠加速這一塊整個的計算
可解釋性
如何讓用戶理解和信任模型結果
神策的產品是給客戶去使用的,但是客戶可能是對機器學習基本沒有了解的人,他可能對機器學習跑出來的結果是不信任的,比如說用模型跑出來一部分用戶的流失,告訴客戶這是一批流失概率比較高的用戶,他可能不理解為什么我們認為這批用戶是流失概率比較高的,也有可能會不愿意使用神策產品的結果,
解決方案:
1、為什么這個用戶會流失
①使用者并不期望全面的解釋,使用者期望的是造成這個結果的最重要的1-2個原因
②造成這個用戶會流失的最重要的1-2個特征是什么
2、為什么這個用戶會轉化
簡單介紹下怎樣計算特征重要性
使用的方法是SHAP value
此演算法模型源自于博弈論:shapley value中的一個方法,
假設有模型m,特征(a,b,c),a’代表特征缺失
下面為舉例
m(a,b',c') - (a',b',c') // 只用a特征對比什么特征都不用能夠帶來的收益是什么
1/2 * ((m(a,b,c') - m(a',b,c')) + (m(a,b',c) - m(a',b',c))) // 用a和不用a所帶來的收益是什么
mm(a,b,c) - m(a',b,c) // 用三個特征和只用b.c 兩個特征的帶來的收益是什么
把上面三個分別計算出來在除以3 計算出來的結果就是整個a這個特征對于整個模型預測的結果是什么
- 思路就是利用SHAP value值最大的特征,做出預測結果的的解釋原因
用戶A會流失,因為最近30天未充值
用戶B會流失,因為最近10次PK都輸了
用戶C會流失,因為他的2個好友最近都未登錄
…
通過找到這樣一些結果,能夠讓客戶更好的理解模型,如果可解釋性的原因是準確的話,也能夠給客戶一些知道和建議,
關于合作博弈論:Shapley value,筆者看到知乎上有一篇比較通俗的講解,同時給出前人實作的代碼地址,鏈接下如下:
合作博弈論:Shapley value
GitHub地址:shap
文章內容到這里就結束了,如有不足敬請指出~

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/293512.html
標籤:AI