文章目錄
- 系列文章
- K-近鄰演算法
- 1 什么是K-近鄰演算法
- 1.1 K-近鄰演算法(KNN)概念
- 1.2 舉例說明K-近鄰演算法
- 1.3 K-近鄰演算法流程總結
- 2 K-近鄰演算法API初步使用
- 2.1 Scikit-learn工具介紹
- 2.2 K-近鄰演算法API
- 3 距離公式
- 3.1 距離公式基本性質
- 3.2 常見的舉例公式
- 歐式距離(Euclidean Distance)
- 曼哈頓距離(Manhattan Distance)
- 切?雪夫距離 (Chebyshev Distance)
- 閔可夫斯基距離(Minkowski Distance)
- 3.3 “連續屬性”和“離散屬性”的距離計算
- 4 K值的選取
- 5 KD樹
- 5.1 KD樹介紹
- 5.2 KD樹案例
- 樹的建立
- 最近鄰域搜索
- 6 鳶尾花種類預測案例
- 6.1 資料集介紹
- 加載資料集
- 資料集可視化
- 資料集劃分
- 6.2 特征預處理
- 什么是特征預處理
- 為什么要特征預處理
- 歸一化
- 標準化
- 預處理的API—fit、fit_transform和transform的區別
- 6.3 流程實作
- 7 K-近鄰演算法優缺點
- 8 模型調優—交叉驗證與網格搜索
- 9 實戰案例:預測FaceBook簽到位置
系列文章
機器學習演算法 01 —— K-近鄰演算法(資料集劃分、歸一化、標準化)
機器學習演算法 02 —— 線性回歸演算法(梯度下降、模型保存)
K-近鄰演算法
學習目標:
- 掌握K-近鄰演算法實作程序
- 知道K-近鄰演算法的距離公式
- 知道K-近鄰演算法的超引數K值以及取值問題
- 知道kd樹實作搜索的程序
- 應?KNeighborsClassifier實作分類
- 知道K-近鄰演算法的優缺點
- 知道交叉驗證實作程序
- 知道超引數搜索程序
- 應?GridSearchCV實作演算法引數的調優
1 什么是K-近鄰演算法
用下面這個圖來簡單說明就是,你所處的位置距離小明最近,那么你就被認為也處于地區A,即根據你最近的“鄰居”來推斷你所屬的類別,

1.1 K-近鄰演算法(KNN)概念
K Nearest Neighbor演算法?叫KNN演算法,這個演算法是機器學習???個?較經典的演算法, 總體來說KNN演算法是相對?較容易理解的演算法,
-
定義:如果?個樣本在特征空間中的k個最相似**(即特征空間中最鄰近)**的樣本中的?多數屬于某?個類別,則該樣本也屬于這個類別,上面的例子里K取的是1,如果k取3,那么在最近的3個地區中取眾數,距離最近的3個鄰居是小明、小呆、小綠,而小呆和小綠都是地區B,所以你屬于地區B,
-
距離公式:兩個樣本的距離可以通過如下公式計算(又叫歐式距離),關于距離公式會在后面說明,
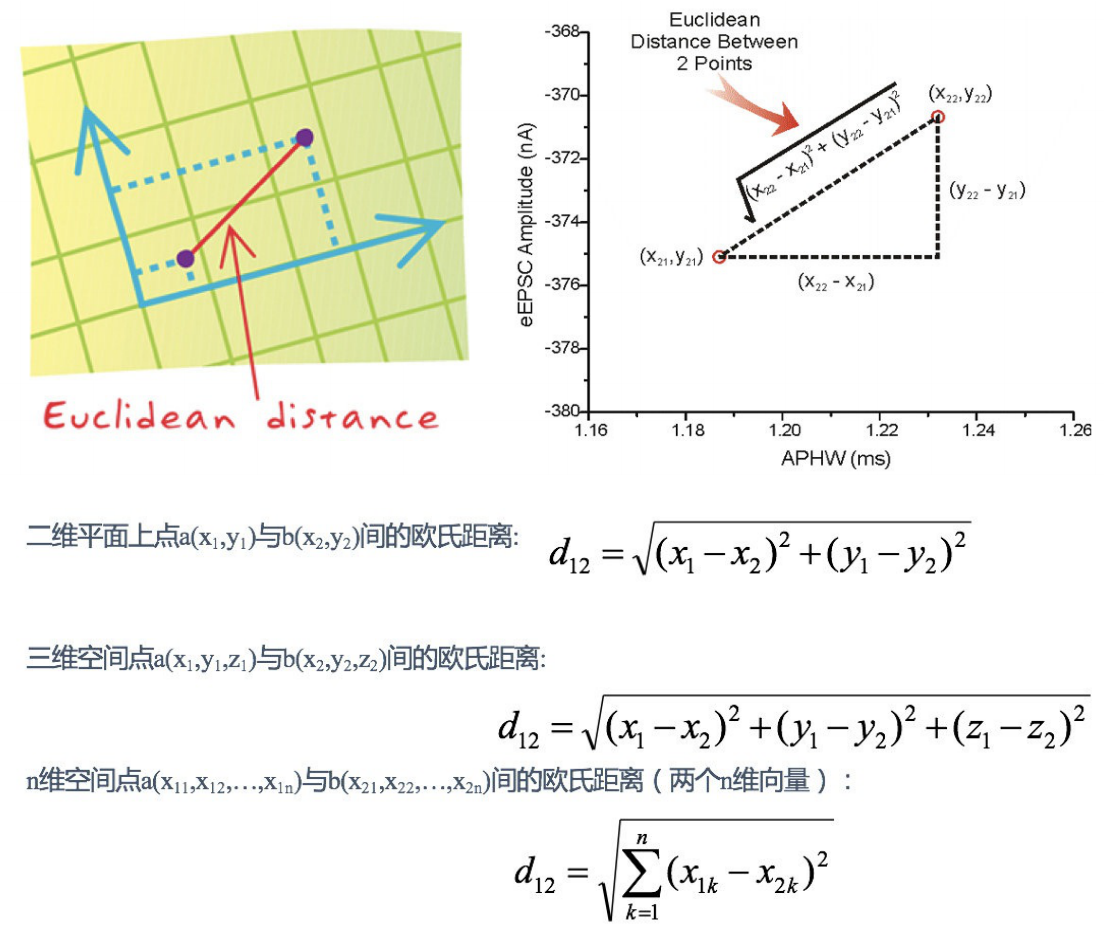
1.2 舉例說明K-近鄰演算法
下面通過一個例子來說明:通過K-近鄰演算法預測一部電影的型別,
現在已知前8部電影的型別,根據它們的各種鏡頭來判斷第9部電影是什么型別,根據圖表我們知道,喜劇片搞笑鏡頭較多,動作片打斗鏡頭較多,愛情片擁抱鏡頭較多,
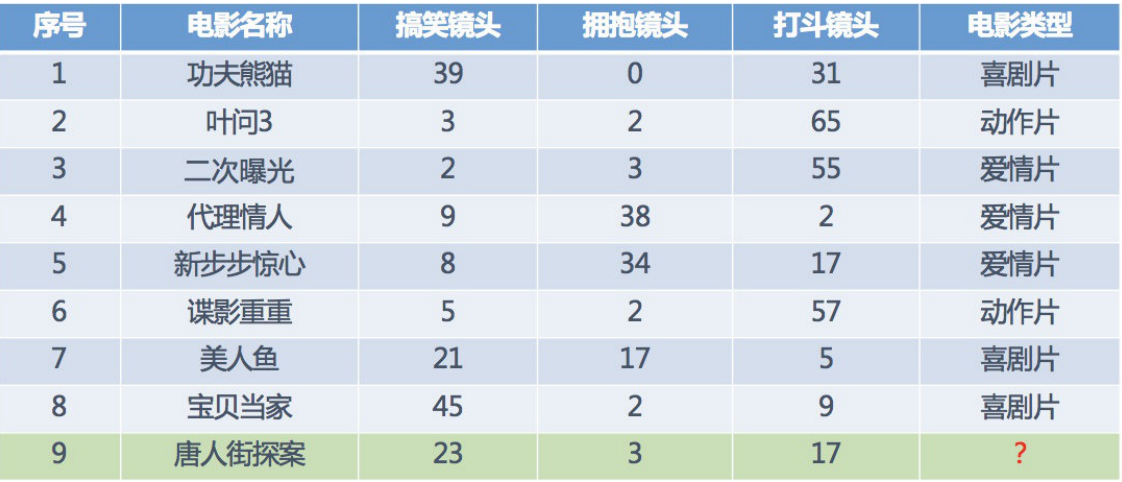
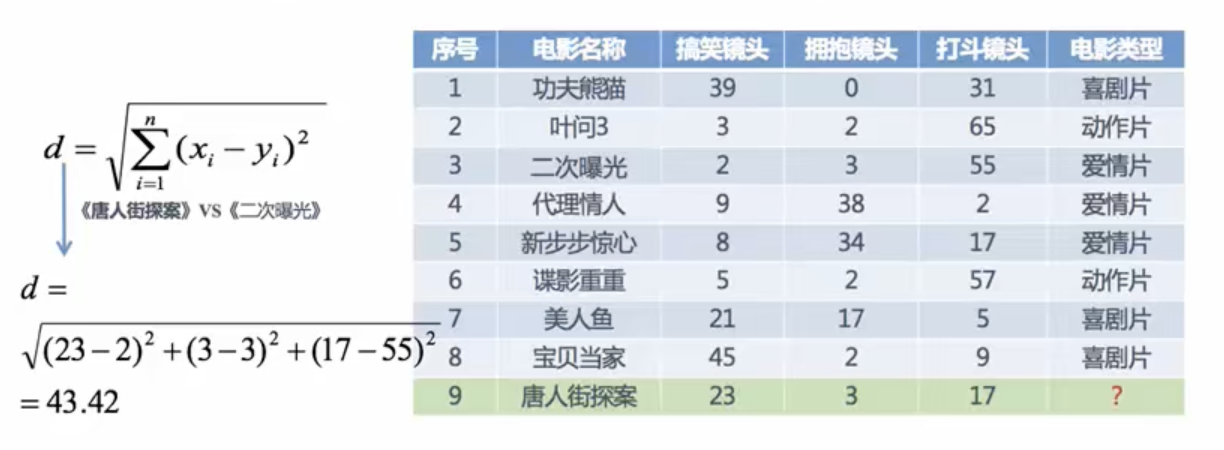
現在對《唐人街探案》的三種鏡頭和其他電影的三種鏡頭運用距離公式
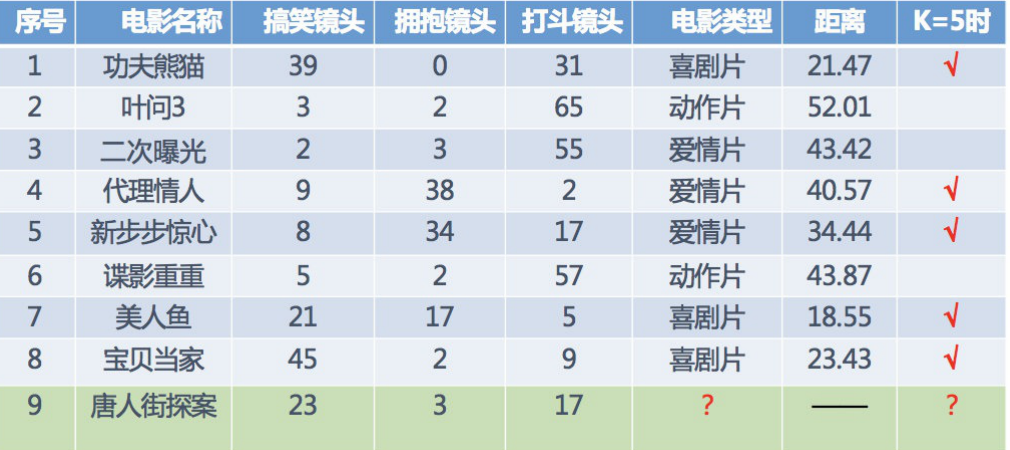
假設我們K取5(即最近的5部電影),根據眾數,這五部電影中有3部喜劇,1部愛情,所以得出結果《唐人街探案》是喜劇片,
1.3 K-近鄰演算法流程總結
- 計算已知類別資料集中的點與當前點之間的距離
- 按距離遞增次序排序
- 選取與當前點距離最?的k個點
- 統計前k個點所在的類別出現的頻率
- 回傳前k個點出現頻率最?的類別作為當前點的預測分類
2 K-近鄰演算法API初步使用
2.1 Scikit-learn工具介紹
Science Kit Learn,包含了許多知名機器學習演算法的實作,內置了很多資料集,scikit-learn檔案比較完善且容易上手,因此對于初學者比較友好,要安裝使用scikit-learn,需要先安裝numpy、scipy等庫,所以推薦直接安裝Anaconda,它專門管理Python庫,內置了許多科學庫,可以參考我另外的博客 Python包/庫/環境管理 —— Anaconda、PyCharm匯入Anaconda的包,
2.2 K-近鄰演算法API
sklearn.neighbors.KNeighborsClassifier(n_neighbors=5),n_neighbors就是K值,默認是5,
下面簡單舉例使用,這里推薦用PyCharm,jupyter主要是一些探索性作業,PyCharm更適合一個專案開發,同時,由于只是簡單使用,所以機器學習開發流程中的一些布置就省略了,
-
獲取資料集
-
資料基本處理(該案例中省略)
-
特征?程(該案例中省略)
-
機器學習
-
模型評估(該案例中省略)
from sklearn.neighbors import KNeighborsClassifier
# 1. 獲取資料集(這里是我們自己構造一個簡單的)
x = [[0], [1], [3], [5]] # 特征值
y = [0, 0, 1, 1] # 目標值
# 4. 機器學習
# 4.1 實體化一個估計器
estimator = KNeighborsClassifier(1) # K 取1
# 4.2 模型訓練
estimator.fit(x, y) # 簡單來說,fit就是求得訓練集X的均值,方差,最大值,最小值,這些訓練集X固有的屬性,
# 資料預測
result = estimator.predict([[6]])
print(result) # 結果 1,因為6距離【5】最近,而【5】的結果是1,所以6歸類為1
看到這里,你肯定會有一些疑惑:
- 距離公式除了歐氏距離外,還有哪些公式可以使用?
- K值應該如何選擇?
- API中的其他引數有什么含義?
這里后面將會一一進行解答,
3 距離公式
3.1 距離公式基本性質
在機器學習程序中,對于函式 dist(., .),若它是"距離度量" (distance measure),則需滿??些基本性質:
-
?負性: dist(X , X ) >= 0 ;
-
同?性:dist(x , x ) = 0,當且僅當 X = X ;
-
對稱性: dist(x , x ) = dist(x , x );
-
直遞性: dist(x , x ) <= dist(x , x ) + dist(x , x )
直遞性常被直接稱為“三?不等式”,
3.2 常見的舉例公式
歐式距離(Euclidean Distance)
歐?距離是最容易直觀理解的距離度量?法,我們?學、初中和?中接觸到的兩個點在空間中的距離?般都是指歐?距離,

# 點A、B、C、D
X=[[1,1],[2,2],[3,3],[4,4]];
經計算得: AB距離-1.4142、AC距離-2.8284、AD距離-4.2426、BC距離-1.4142、BD距離-2.8284、CD距離-1.4142
曼哈頓距離(Manhattan Distance)
在曼哈頓街區要從?個?字路?開?到另?個?字路?,駕駛距離顯然不是兩點間的直線距離,這個實際駕駛距離就是“曼哈頓距離”,曼哈頓距離也稱為“城市街區距離”(City Block distance), 下圖中,從A到B的三條線路距離是相同的,
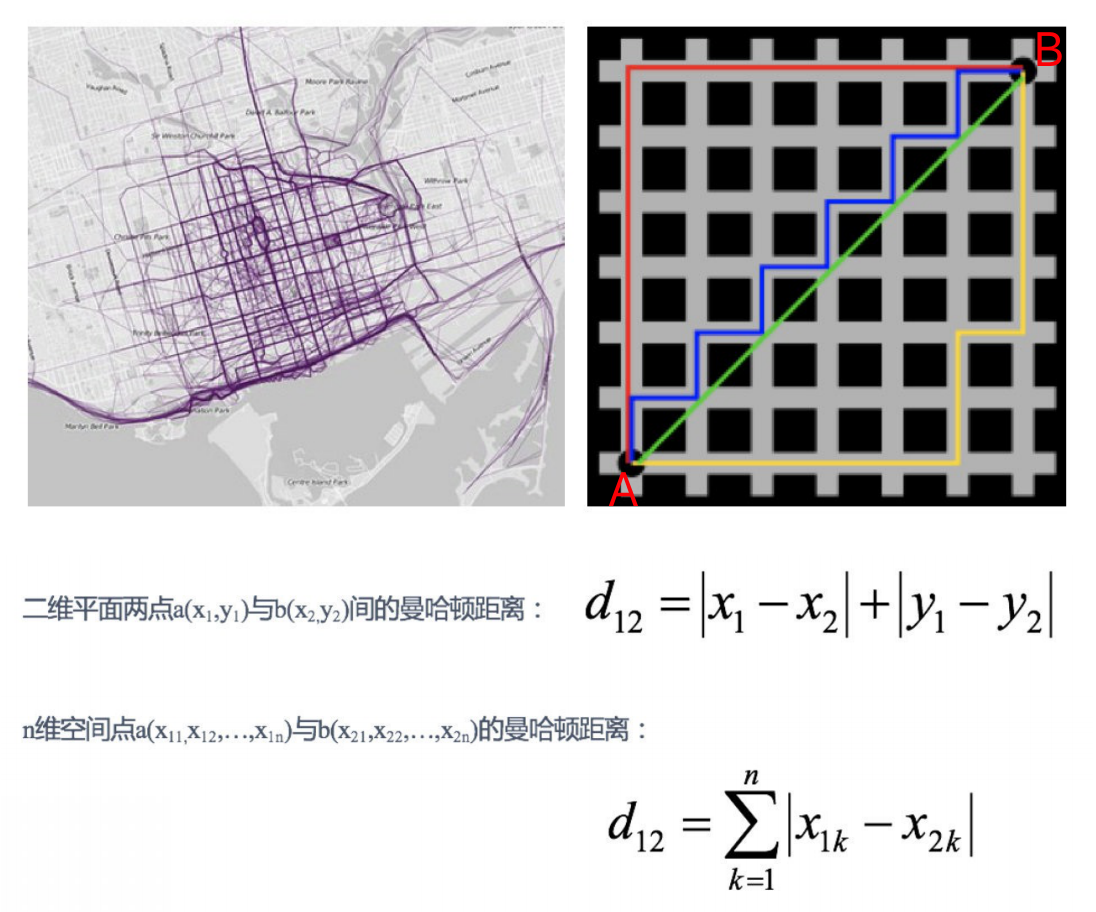
# A、B、C、D
X=[[1,1],[2,2],[3,3],[4,4]];
經計算得: AB=2、AC=4、AD=6、BC=2、BD=4、CD=2
切?雪夫距離 (Chebyshev Distance)
國際象棋中,國王可以直?、橫?、斜?,所以國王??步可以移動到相鄰8個?格中的任意?個,國王從格?(x1,y1)?到格?(x2,y2)最少需要多少步?這個距離就叫切?雪夫距離,
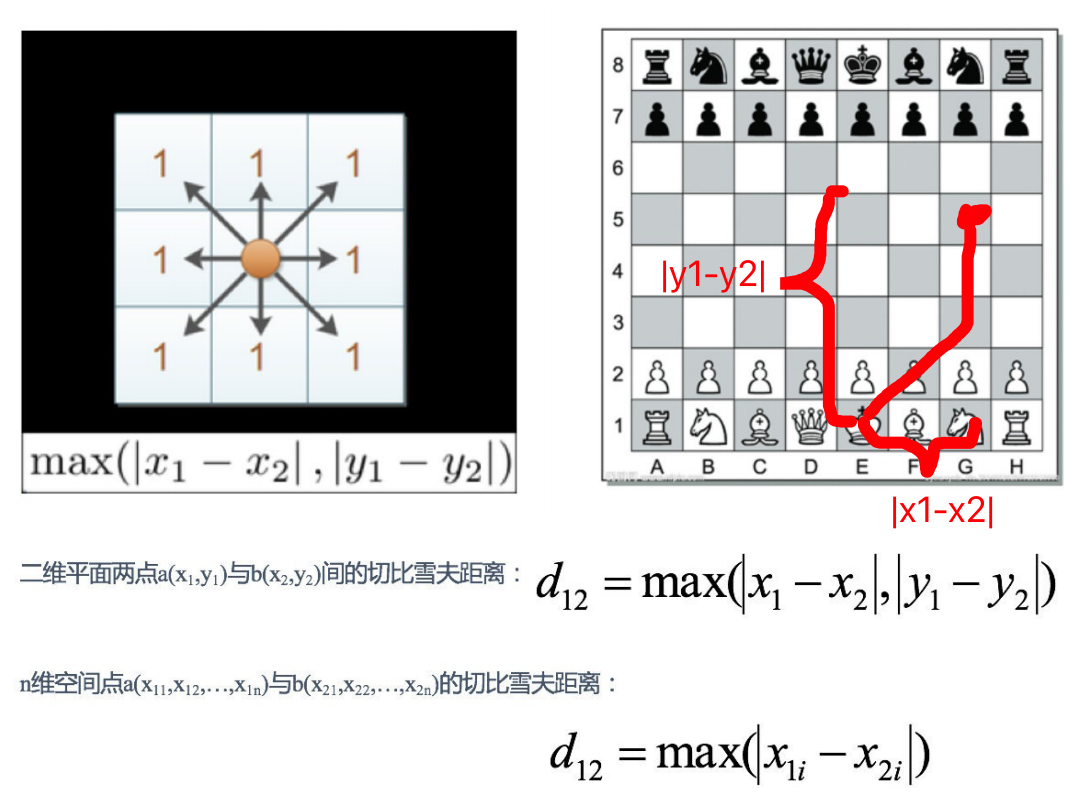
X=[[1,1],[2,2],[3,3],[4,4]];
經計算得: d = 1 2 3 1 2 1
閔可夫斯基距離(Minkowski Distance)
閔?距離不是?種距離,?是?組距離的定義,是對多個距離度量公式的概括性的表述,
兩個n維變數a(x11,x12,…,x1n)與b(x21,x22,…,x2n)間的閔可夫斯基距離定義為:
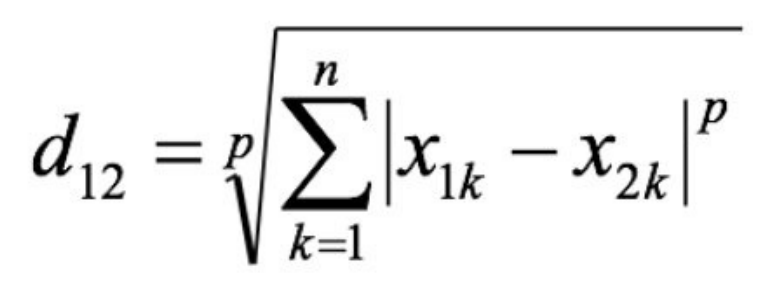
其中p是?個變引數:
-
當p=1時,就是曼哈頓距離;
-
當p=2時,就是歐?距離;
-
當p→∞時,就是切?雪夫距離,
根據p的不同,閔?距離可以表示某?類/種的距離,
?結:
- 閔?距離,包括曼哈頓距離、歐?距離和切?雪夫距離,都存在明顯的缺點:
? 例如:?維樣本(身?[單位:cm],體重[單位: ]),現有三個樣本:a(180,50),b(190,50),c(180,60),a與b的閔?距離(?論是曼哈頓距離、歐?距離或切?雪夫距離)等于a與c的閔?距離,但實際上身?的10cm并不能和體重的10kg劃等號,
- 閔?距離的缺點:
- 將各個分量的“單位”同等看待了;
- 沒有考慮到各個分量的分布(期望,?差等)可能是不同的,
3.3 “連續屬性”和“離散屬性”的距離計算
我們常將屬性劃分為"連續屬性和"離散屬性",前者在定義域上有?窮多個可能的取值,后者在定義域上是有限個取值,
-
若屬性值之間存在序關系,則可以將其轉化為連續值,例如:身?屬性“?”“中等”“矮”,可轉化為{1, 0.5, 0},
- 閔可夫斯基距離可以?于有序屬性,
-
若屬性值之間不存在序關系,則通常將其轉化為向量的形式,例如:性別屬性“男” “?”,可轉化為{(1,0),(0,1)},
4 K值的選取
假如我們之前電影型別預測案例中的K值取1或者取6會發生什么問題呢?
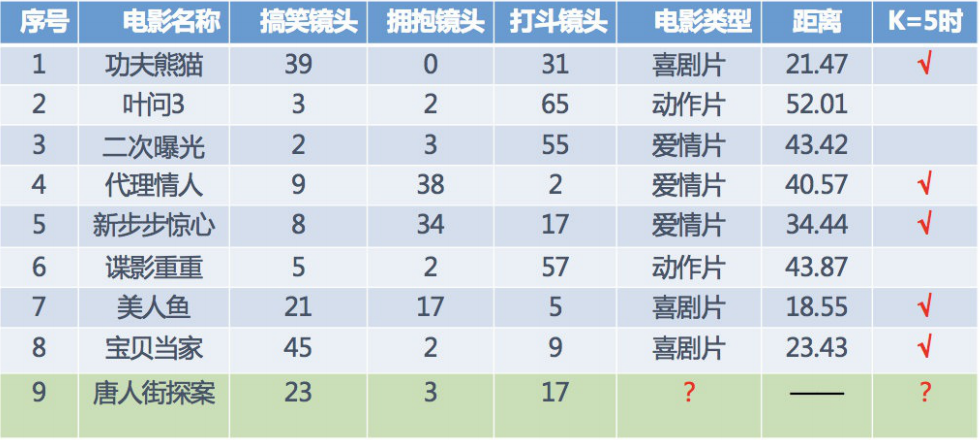
- K值過小:
- 容易受到例外點的影響
- 例如K=1,最近的是《美人魚》喜劇片,但如果《美人魚》在統計時不小心記錄為愛情片,那么預測結果也會跟著出錯,
- K值過大:
- 容易出現樣本均衡的問題
- 例如K=6,就會出現3部喜劇片和3部愛情片,此時預測結果無法得知,
K值選擇問題,李航博?的?書「統計學習?法」上說:
- 選擇較?的K值,就相當于?較?的領域中的訓練實體進?預測,
- “學習”近似誤差會減?,只有與輸?實體較近或相似的訓練實體才會對預測結果起作?,與此同時帶來的問題是“學習”的估計誤差會增?,
- 換句話說,K值的減?就意味著整體模型變得復雜,容易發?過擬合;
- 選擇較?的K值,就相當于?較?領域中的訓練實體進?預測,
- 其優點是可以減少學習的估計誤差,但缺點是學習的近似誤差會增?,這時候,與輸?實體較遠(不相似的)訓練實體也會對預測器作?,使預測發?錯誤,
- 且K值的增?就意味著整體的模型變得簡單,
- K=N(N為訓練樣本個數),則完全不?取,因為此時?論輸?實體是什么,都只是簡單的預測它屬于在訓練實體中最多的類,模型過于簡單,忽略了訓練實體中?量有?資訊,
概念解釋
- 近似誤差:
- 對現有訓練集的訓練誤差,關注訓練集,
- 如果近似誤差過?可能會出現過擬合的現象,對現有的訓練集能有很好的預測,但是對未知的測驗樣本將會出現較?偏差的預測,
- 模型本身不是最接近最佳模型,
- 估計誤差:
- 可以理解為對測驗集的測驗誤差,關注測驗集,
- 估計誤差?說明對未知資料的預測能?好,
- 模型本身最接近最佳模型,
- 過擬合:所建的機器學習模型或者是深度學習模型在訓練樣本中表現得過于優越,導致在測驗資料集中表現不佳,
- 欠擬合:模型學習的太過粗糙,連訓練集中的樣本資料特征關系都沒有學出來,
5 KD樹
問題匯入:在實作K-鄰近演算法時,主要考慮的問題是如何對訓練資料快速進行K-鄰近搜索(即找出最近的“鄰居”),最簡單的方法當然是線性掃描,將輸入值與每一個訓練資料進行距離計算,但這在訓練資料量大時會非常耗時,
因此,為了提高KNN搜索效率,使用的是特殊存盤結構,以減少計算距離的次數,
5.1 KD樹介紹
KNN每次要預測一個點時,都需要計算這個點到訓練資料集里每個點的距離,針對N個樣本,每個樣本有D個特征的資料集,這樣的時間復雜度是O(DN2),
KD樹的原理:假如點A和點B距離很遠,點B和點C距離很近,那么可以得出點A和點C距離也很遠,在計算距離時就可以跳過點C,這樣演算法復雜度可以降低到O(DNlogN),
KD樹類似于二叉排序樹,先對所有點進行大小排序,將中間的點作為根節點(事例里是黃點),將黃點上面的歸為左子樹,下面的歸為右子樹,然后再對這兩個區域繼續劃分直到區域里沒有點,分割的那條線叫超平面,(在一維里是點,二維里是線,三維里是面)
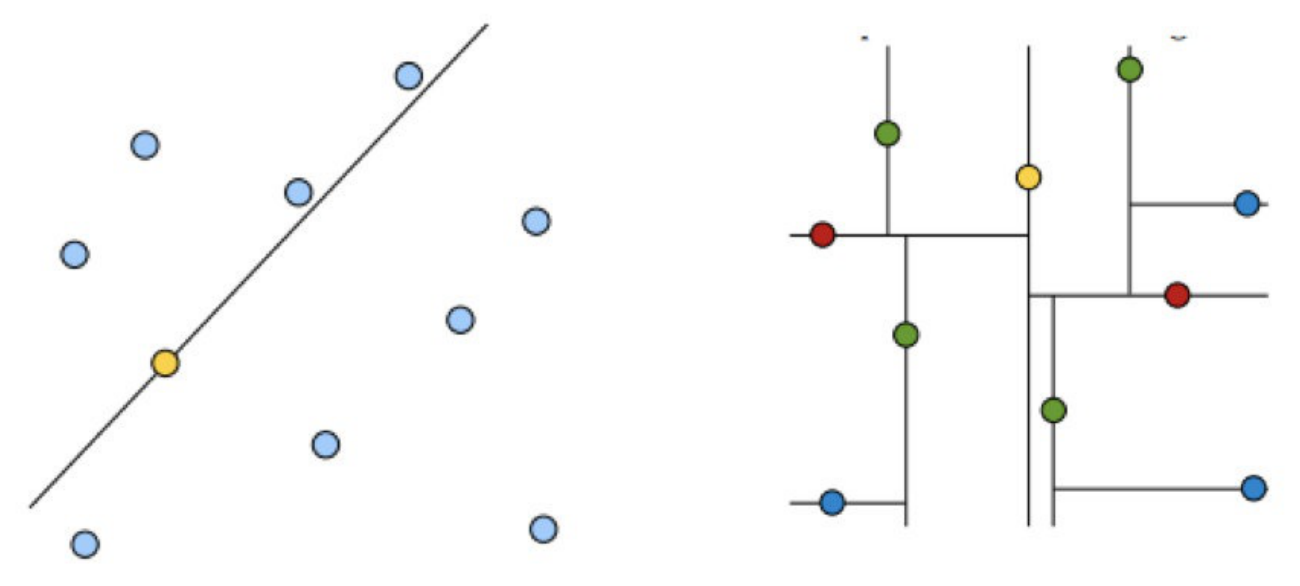
第一層是黃色根節點,第二層是紅色,第三層是綠色,第四層是藍色,
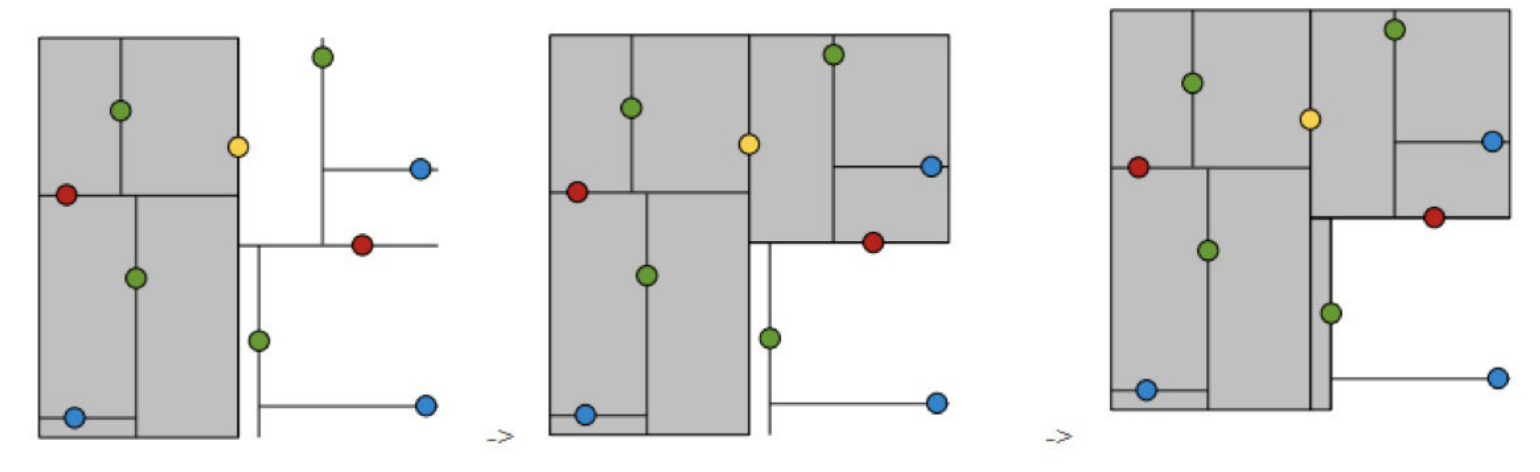
構造好樹后,距離計算就類?“?分查找”:
? 給出?組資料:[9 1 4 7 2 5 0 3 8],要查找8,如果挨個查找(線性掃描),那么將會把資料集都遍歷?遍,?如果排?下序那資料集就變成了:[0 1 2 3 4 5 6 7 8 9],按前?種?式我們進?了很多沒有必要的查找,現在如果我們以5為分界點,那么資料集就被劃分為了左右兩個“簇” [0 1 2 3 4]和[6 7 8 9],因此,根本就沒有必要進?第?個簇,可以直接進?第?個簇進?查找,
5.2 KD樹案例
下面通過一個例子來說明KD樹的如何構造的,
樹的建立
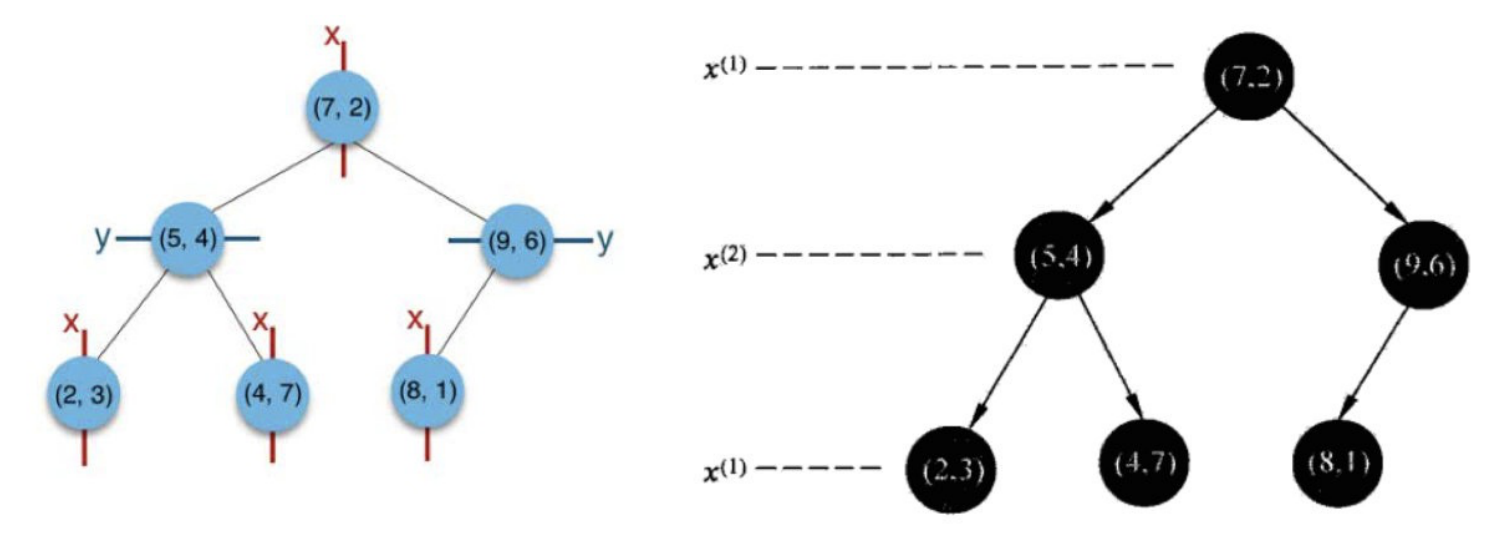
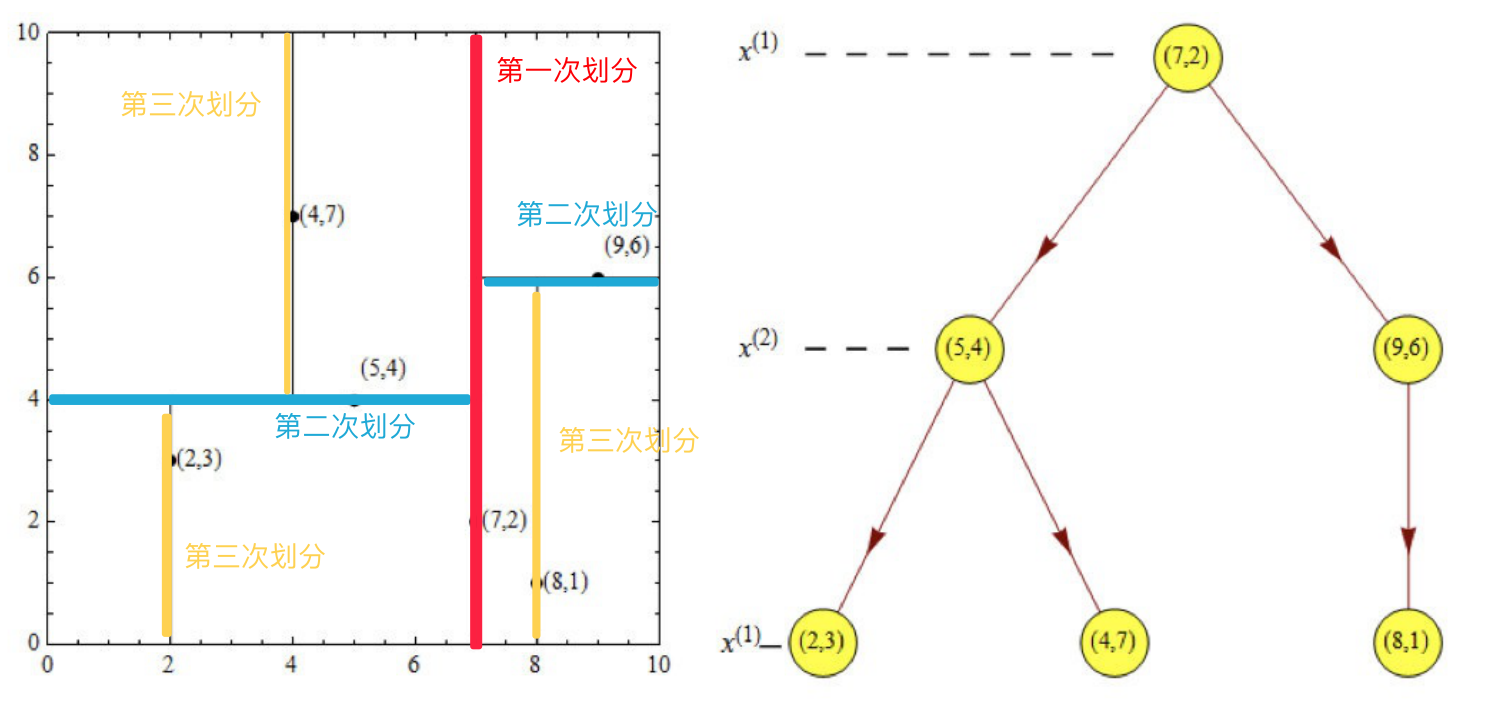
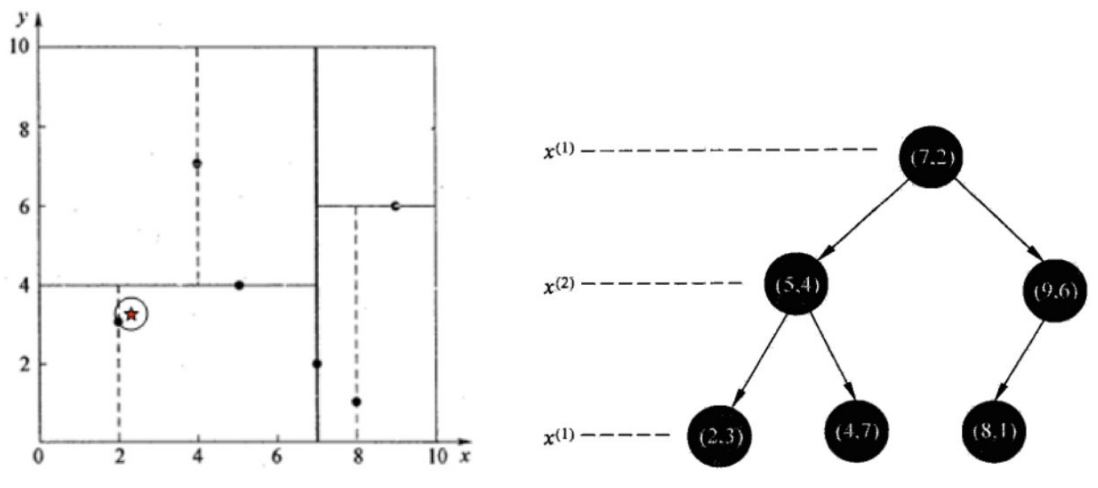
給定一個二維資料集:T={(2, 3), (5, 4), (9, 6), (4, 7), (8, 1), (7, 2)},將其構造成一個平衡KD樹,其結果如下:
-
首先將x和y分開成兩個維度,然后選擇方差更大的那個維度找出中位數
第一維度 x:2、5、9、4、8、7 第二維度 y:3、4、6、7、1、2 由于第一維度 x的方差更大(肉眼觀察,x的分散程度更高,方差就更大),所以選x來排序, 排序后 第一維度 x:2、4、5、7、8、9 中位數是5和7的平均值:6 -
由于中位數是6,接下來選擇最接近中位數的點來作為根節點時,這里既可以選(5, 4)又可以選(7, 2),它們x距離相同,這里選的是(7, 2),
選擇(7,2),所以樹的第一層是(7,2) 此時,根據排序,在7左邊的有 2、4、5,在7右邊的有8、9, 對應的點是 (2, 3)、(4, 7)、(5, 4),(8, 1)、(9, 6) -
接下來再對剩余的點進行劃分,但這次是要根據第二維度y來找中位數,
左邊的點的y排序:3、4、7,即點(2, 3)、(5, 4)、(4, 7),此時中位數是4,所以第二層左子樹根節點是(5, 4) 右邊的點的y排序:1、6,即點(8, 1)、(9, 6),此時中位數是5,隨便選一個點(9, 6)作為根節點,
所以特征空間劃分(圖里面的線就是超平面)和KD樹就是下面這樣的:
最近鄰域搜索
假設標記為星星的點是待測驗點, 綠?的點是初次找到的近似點,在回溯程序中,需要?到?個堆疊,用來存盤需要回溯的點,每次回溯判斷其他?節點是否有可能有距離查詢點更近的資料點時,具體做法是以查詢點為圓?,以當前的最近距離為半徑畫圓,這個圓稱為候選超球,如果圓與回溯點的軸相交,則需要將軸另?邊的節點都放到回溯堆疊中,之后繼續彈堆疊并重復,直到堆疊空,
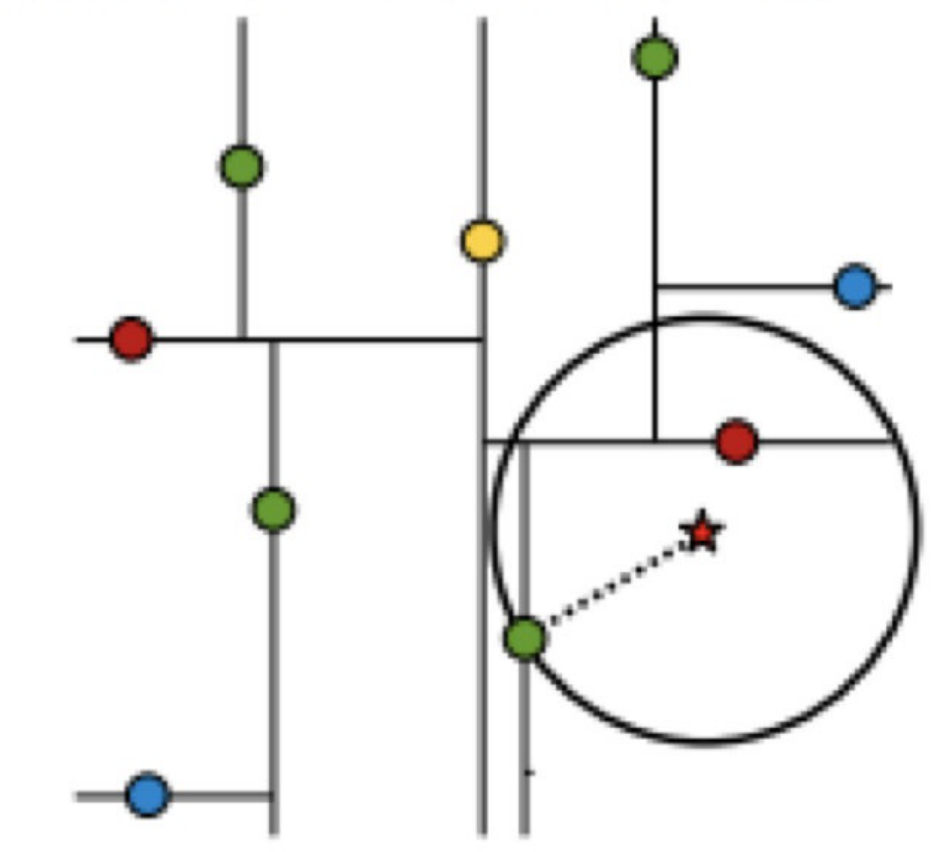
下面舉兩個例子,
查找點(2.1, 3.1)
- 構造回溯堆疊:根據KD樹,所以先比較第一維度x,查找點(2.1, 3.1)的x為2.1,小于根節點的7,點(7, 2)入堆疊,然后繼續比較左子樹,根據KD樹,第二層要比較第二維度,查找點(2.1, 3.1)的y為3.1,小于左子樹根節點4,點(5, 4)入堆疊,然后繼續比較左子樹,根據KD樹,第三層要比較第一維度,查找點(2.1, 3.1)的x為2.1,大于2,點(2, 3)入堆疊,后面沒有點了,構造完畢,回溯堆疊為 <(7, 2), (5, 4), (2, 3)>
- 開始回溯并進行比較:持續彈堆疊,(2.1, 3.1)與(2, 3)的距離為0.141,以此距離為半徑,點(2.1, 3.1)為圓心,構造候選超球,如上圖五角星周圍的圓圈,該候選超球的半徑內沒有其他點,因此最近鄰點就是(2, 3),距離為0.141,
查找點(2, 4.5)

- 構造回溯堆疊:同理,根據KD樹構造出來的堆疊是<(7, 2), (5, 4), (4, 7)>
- 回溯彈堆疊:點(2, 4.5)與點(4, 7)距離為3.202,以此距離為半徑,點(2, 4.5)為圓心,構造候選超球,此時點(2, 3)在范圍內,所以需要加入到回溯堆疊中,此時回溯堆疊為<(7, 2), (5, 4), (2, 3)>,接著繼續彈堆疊,點(2, 4.5)與點(2, 3)距離為1.5,比3.202小,因此最近鄰點更新為(2, 3),構造新的超球,這次沒有新點加入,然后繼續回溯直到堆疊空,最終,(2, 3)是最近鄰點,距離為1.5,
6 鳶尾花種類預測案例
6.1 資料集介紹
Iris資料集是常?的分類實驗資料集,由Fisher, 1936收集整理,Iris也稱鳶尾花卉資料集,是?類多重變數分析的資料集,關于資料集的具體介紹:

通常一個領域的資料集選擇是由該領域的行業專家來判斷,不需要機器學習開發者來做,
加載資料集
sklearn.datasets加載資料集,它有兩種方式:
sklearn.datasets.load_xx():獲取小規模資料集,sklearn本身就有,無需下載,- 例如,這次使用的鳶尾花資料集
sklearn.datasets.load_iris()
- 例如,這次使用的鳶尾花資料集
sklearn.datasets.fetch_xx(datahome=None):獲取大規模資料集,需要聯網下載,引數datahome是下載到本地的位置,默認是~/scikit_learn_data/- 例如
sklearn.datasets.fetch_20newsgroups(data_home=None,subset=‘train’),其中subset可取訓練集’train’、測驗集’test’、全部’all’
- 例如
- load和fetch回傳的資料型別都是datasets.base.Bunch(字典格式)
- data:特征資料陣列,是?維 numpy.ndarray 陣列
- target:標簽陣列,是?維 numpy.ndarray 陣列
- DESCR:資料描述
- feature_names:特征名,新聞資料,?寫數字、回歸資料集沒有
- target_names:標簽名
from sklearn.datasets import load_iris
# 獲取鳶尾花資料集
iris = load_iris()
print("鳶尾花資料集的回傳值:\n", iris)
# 回傳值是?個繼承?字典的Bench
print("鳶尾花的特征值:\n", iris["data"])
print("鳶尾花的?標值:\n", iris.target)
print("鳶尾花特征的名字:\n", iris.feature_names)
print("鳶尾花?標值的名字:\n", iris.target_names)
print("鳶尾花的描述:\n", iris.DESCR)
資料集可視化
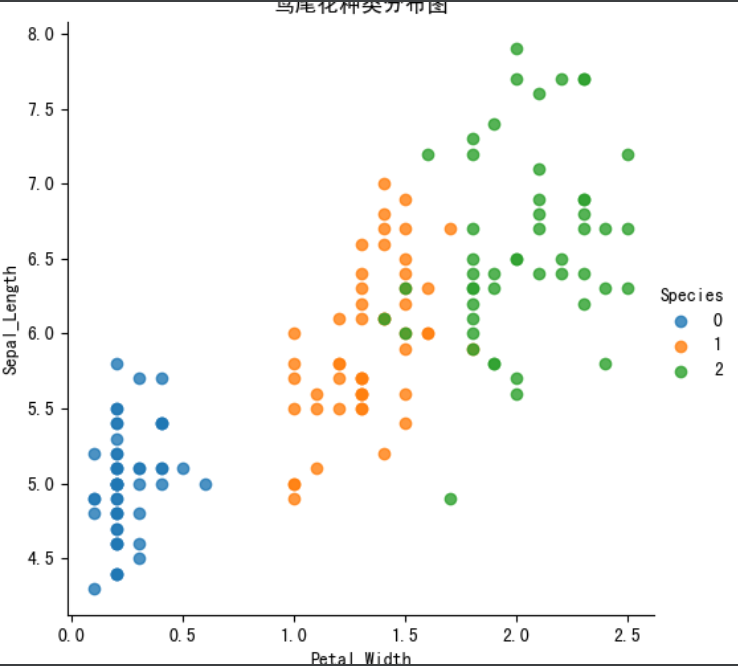
下面通過seaborn來查看鳶尾花的資料分布情況,我另一篇博客有說明seaborn使用:機器學習入門 06 —— Seaborn使用
- seaborn.lmplot() 用于繪制回歸圖,它會在繪制?維散點圖時,?動完成回歸擬合,
- sns.lmplot() ?的 x, y 分別代表橫縱坐標的列名,
- data:資料集,
- hue:表示按斬訓的類別分類顯示,
- fit_reg:是否進?線性擬合,
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.datasets import load_iris, fetch_20newsgroups
# 獲取資料
iris = load_iris()
# 把資料轉換成DataFrame的格式
iris_d = pd.DataFrame(iris['data'],
columns=['Sepal_Length', 'Sepal_Width', 'Petal_Length', 'Petal_Width'])
# 新增一列 種類(目標值target就是種類)
iris_d['Species'] = iris.target
def plot_iris(iris, col1, col2):
sns.lmplot(x=col1, y=col2, data=iris, hue="Species", fit_reg=False)
plt.xlabel(col1)
plt.ylabel(col2)
plt.title('鳶尾花種類分布圖')
plt.show()
plot_iris(iris_d, 'Petal_Width', 'Sepal_Length')
資料集劃分
通常機器學習的資料集會被劃分為兩個部分:
-
訓練資料:?于訓練、構建模型
-
測驗資料:在模型檢驗時使?,?于評估模型是否有效
劃分比例大致分為:
-
訓練集:70%、80%、75%
-
測驗集:30%、20%、25%
sklearn.model_selection.train_test_split(arrays, *options)
- 引數:
- arrays:資料集,或者傳入x特征值、y目標值,(這里由于鳶尾花資料集是自帶的,就不需要區分特征值和目標值)
- test_size:測驗集的??,例如 0.7,那么測驗集就占總資料的70%
- random_state:亂數種?,不同的種?會造成不同的隨機采樣結果,相同的種?回傳結果也相同,
- 回傳值:訓練集的特征值x_train, 測驗集的特征值x_test, 訓練集的目標值y_train, 測驗集的目標值y_test
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# 1、獲取鳶尾花資料集
iris = load_iris()
# 對鳶尾花資料集進?分割
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=22)
print("x_train:\n", x_train.shape)
# 亂數種?
x_train1, x_test1, y_train1, y_test1 = train_test_split(iris.data, iris.target, random_state=6)
x_train2, x_test2, y_train2, y_test2 = train_test_split(iris.data, iris.target, random_state=6)
print("如果亂數種?不?致:\n", y_test == y_test1) # 陣列中,有False,也有True,因為可能隨機到相同的
print("如果亂數種??致:\n", y_test1 == y_test2) # 全為True
6.2 特征預處理
什么是特征預處理
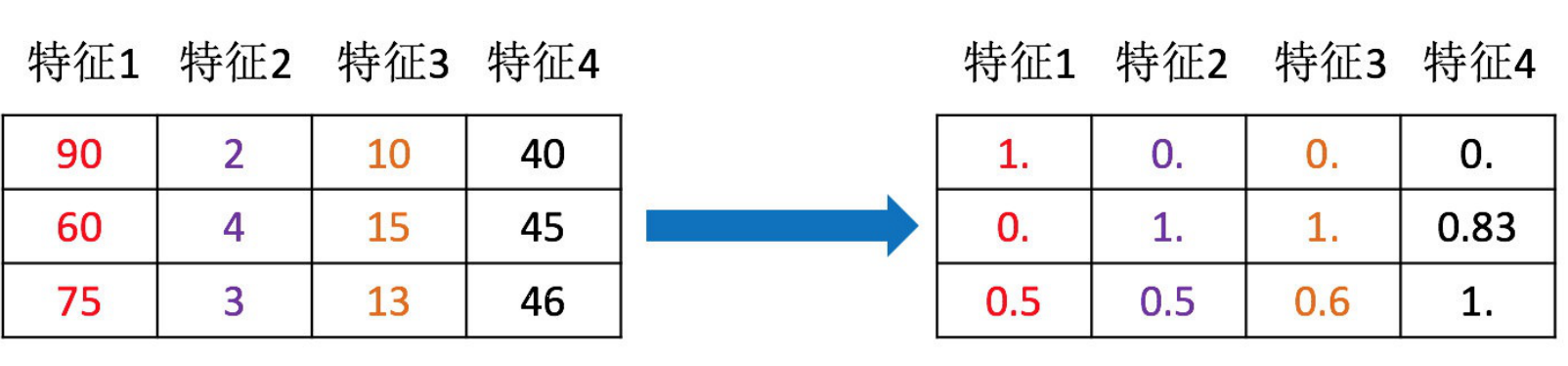
定義:通過一些轉換函式將特征資料轉換成更適合演算法模型的特征資料的程序(主要是歸一化和標準化),例如下圖,將特征1234都轉換到一個范圍里,(這就是歸一化)
為什么要特征預處理
特征的單位或者??相差較?,或者某特征的?差相?其他的特征要?出?個數量級,容易影響(?配)?標結果,使得?些演算法?法學習到其它的特征,所以,我們需要?到?些?法進??量綱化,使不同規格的資料轉換到同?規格,
歸一化
定義:通過對原始資料進行變化,把資料映射到某個區間,(默認是[0, 1],所以叫歸一)
公式如下:
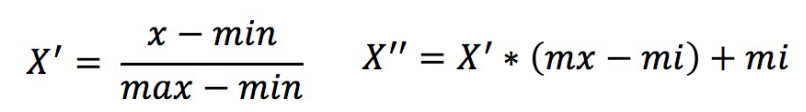
作?于每?列,max為?列的最?值,min為?列的最?值,那么X’’為最終結果,mx,mi分別為指定區間值默認mx為1,mi為0
前面那張圖就是歸一化,其中每個特征都套用了這個公式,90轉換到1,就是 x ′ = 90 ? 60 90 ? 60 x'=\frac{90-60}{90-60} x′=90?6090?60??????、 x ′ ′ = x ′ ( 1 ? 0 ) + 0 = 1 x''=x'(1-0)+0=1 x′′=x′(1?0)+0=1???,
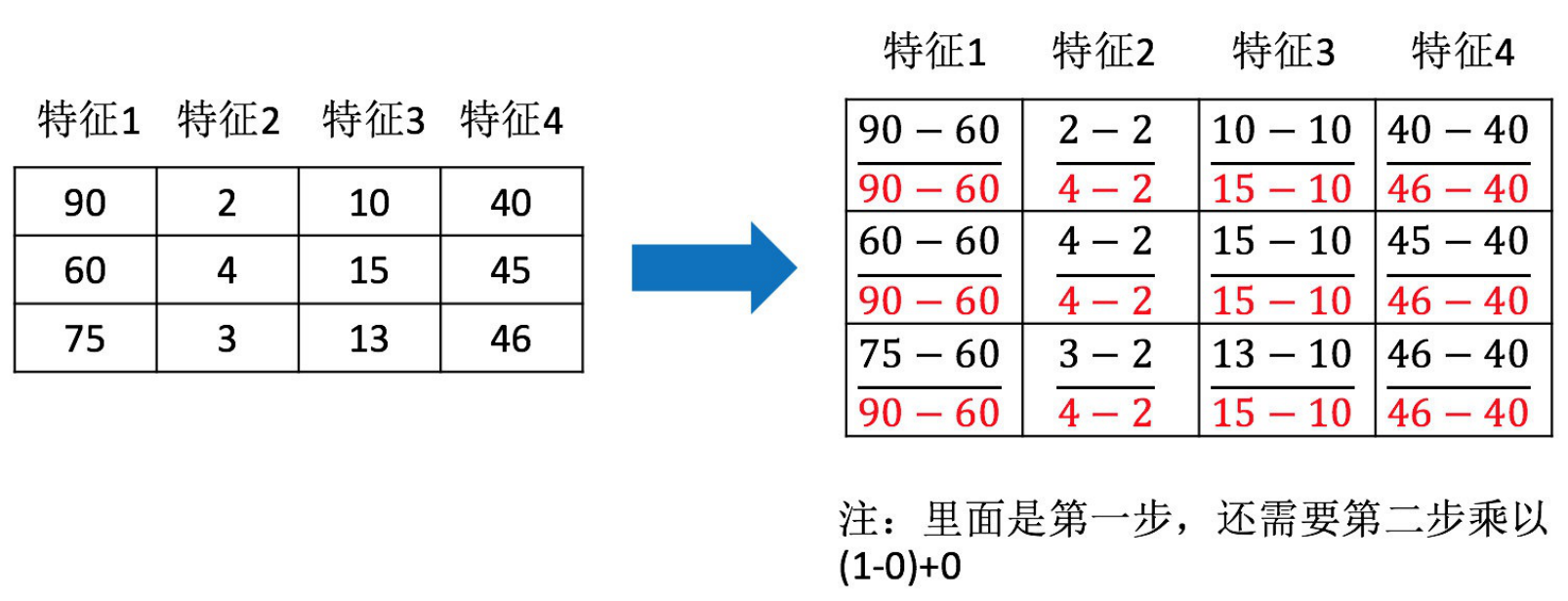
代碼實作歸一化:
先實體化轉換器物件MinMaxScaler(feature_range=(0, 1)),再呼叫轉換器的fit_transform(X)方法進行轉換,
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
def minmax_demo():
"""
歸一化演示
:return:None
"""
data = pd.DataFrame({"特征1": [90, 60, 75],
"特征2": [2, 4, 3],
"特征3": [10, 15, 13],
"特征4": [40, 45, 46]})
print(data)
# 1. 實體化一個轉換器物件;feature_range指定區間
transfer = MinMaxScaler(feature_range=(0, 1))
# 2. 呼叫轉換器的fit_transform,開始轉換
data = transfer.fit_transform(data[["特征1", "特征2", "特征3", "特征4"]])
print("歸一化:\n", data)
minmax_demo()
標準化
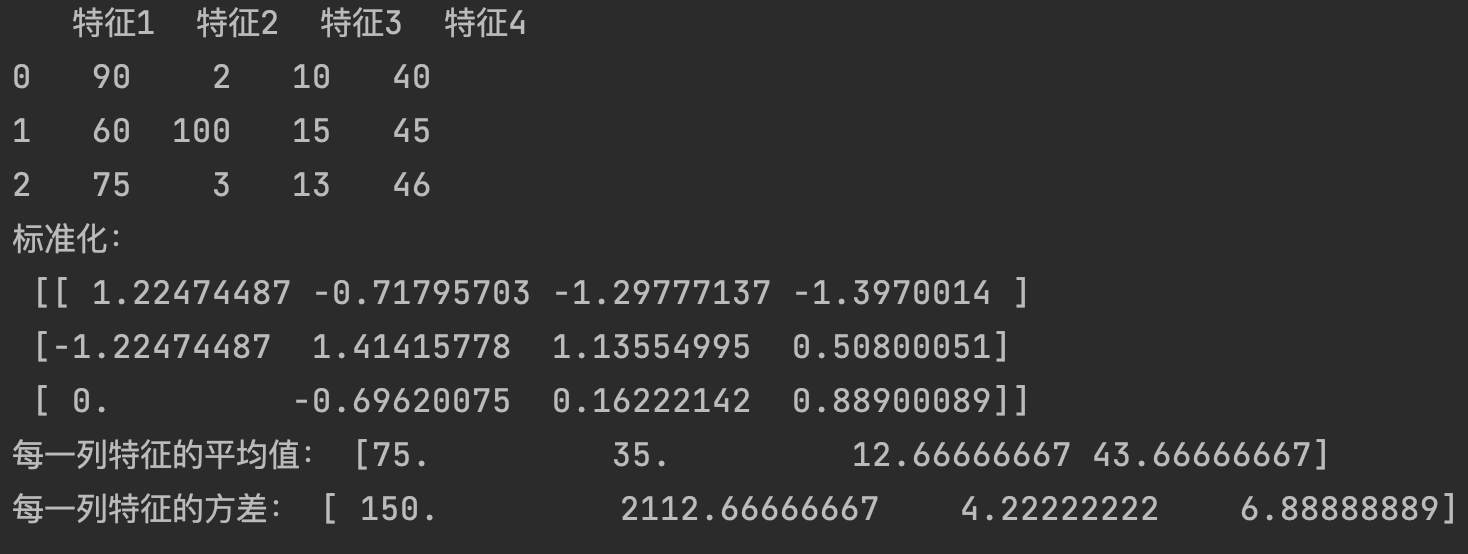
如果資料中的例外點比較多,例如特征2中突然有個資料是100,這明顯比其他資料大很多,那么歸一化時就會對結果產生很大影響,因為歸一化會受到最大和最小值影響,因此歸一化的魯棒性(穩定性)比較差,只適合傳統精確的小資料場景,
標準化定義:通過對原始資料進?變換把資料變換到平均值為0,標準差為1范圍內,對于標準化來說,如果出現例外點,由于具有?定資料量,少量的例外點對于平均值的影響并不?,從??差改變較?, 更適合現代嘈雜大資料場景,因此常用的是標準化,
公式如下:
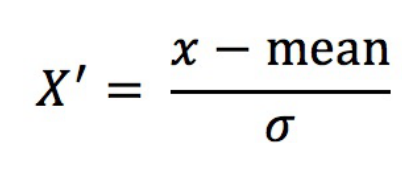
作?于每?列,mean為平均值,σ為標準差
這次我們把上面的特征2里的4改成100,
代碼實作標準化:
先實體化轉換器物件StandardScaler(),再呼叫轉換器的fit_transform(X)方法進行轉換,
import pandas as pd
from sklearn.preprocessing import StandardScaler
def stand_demo():
"""
標準化演示
:return:None
"""
data = pd.DataFrame({"特征1": [90, 60, 75],
"特征2": [2, 100, 3],
"特征3": [10, 15, 13],
"特征4": [40, 45, 46]})
print(data)
# 1. 實體化一個轉換器物件;
transfer = StandardScaler()
# 2. 呼叫轉換器的fit_transform,開始轉換
data = transfer.fit_transform(data[["特征1", "特征2", "特征3", "特征4"]])
print("標準化:\n", pd.DataFrame(data))
print("每一列未轉化特征值的平均值:", transfer.mean_)
print("每一列未轉化特征的方差:", transfer.var_)
stand_demo()
預處理的API—fit、fit_transform和transform的區別
fit():該函式是求得訓練集X的均值,方差,最大值,最小值等這些訓練集X固有的屬性,transform():在fit的基礎上,進行標準化,降維,歸一化等操作(看具體用的是哪個工具,StandardScaler就是標準化)fit_transform():fit_transform是fit和transform的組合,既包括了訓練又包含了轉換,- transform()和fit_transform()二者的功能都是對資料進行某種統一處理(比如標準化~N(0,1),將資料縮放(映射)到某個固定區間,歸一化,正則化等)
- fit_transform(trainData)對部分資料先擬合fit,找到這部分資料的整體指標,如均值、方差、最大值最小值等等(根據具體轉換的目的),然后對trainData進行轉換,從而實作資料的標準化、歸一化等等,
根據對之前部分trainData進行fit的整體指標,對剩余的資料(testData)使用同樣的均值、方差、最大最小值等指標進行轉換transform(testData),從而保證train、test處理方式相同,所以,在預處理階段一般都是這么用:
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
sc.fit_tranform(X_train)
sc.tranform(X_test)
- 必須先用fit_transform(trainData),之后再transform(testData)
- 如果直接transform(testData),程式會報錯
- 如果fit_transfrom(trainData)后,使用fit_transform(testData)而不transform(testData),雖然也能歸一化,但是兩個結果不是在同一個“標準”下的,具有明顯差異,(一定要避免這種情況)
6.3 流程實作
sklearn.neighbors.KNeighborsClassifier(n_neighbors=5,algorithm='auto')
- n_neighbors:鄰居數目,也就是K值
- algorithm:指定使用什么演算法
- auto:自動選擇合適的
- brute:暴力搜索,也就是線性掃描,當訓練集很?時,計算?常耗時,
- kd_tree:構造kd樹存盤資料以便對其進?快速檢索的樹形資料結構,在維數?于20時效率?,
- ball_tree:克服kd樹?維失效?發明的,資料集的維度超過20時使用,
下面完整展示對鳶尾花種類預測的流程
# -*- coding = utf-8 -*-
# @Time : 2021/8/5 10:17 上午
# @Author : zcy
# @File : 4.iris_example.py
# @Software : PyCharm
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
# K-近鄰演算法 —— 鳶尾花種類預測
# 實體數量:150(3個種類,0山鳶花、1變色鳶尾、2維吉尼亞鳶尾,每種各50個)
# 屬性數量:4(數值型,萼片長度、萼片寬度、花瓣長度、花瓣寬度)
# 1. 獲取資料集
iris = load_iris()
# 2. 資料基本處理 - 這里是只是把資料集劃分為訓練集和測驗集
x_train, x_test, y_train, y_test = train_test_split(
iris.data, iris.target, test_size=0.2, random_state=10)
# 3. 特征工程 - 特征預處理 標準化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test) # 這里看前面特征預處理部分,有解釋
# 4. 機器學習 - KNN
# 4.1 實體化一個估計器
estimator = KNeighborsClassifier(n_neighbors=5)
# 4.2 估計器訓練
estimator.fit(x_train, y_train)
# 5. 模型評估
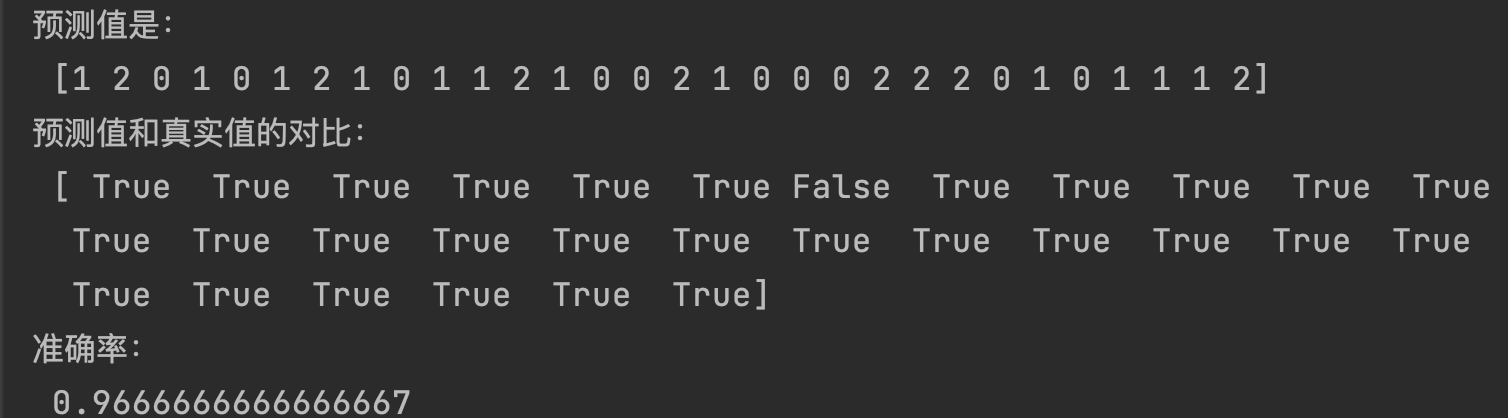
# 5.1 預測值結果輸出
y_pre = estimator.predict(x_test)
print("預測值是:\n", y_pre)
print("預測值和真實值的對比:\n", y_pre == y_test)
# 5.2 準確率
score = estimator.score(x_test, y_test)
print("準確率:\n", score)
結果每次運行都是下面這樣,因為在劃分資料時指定了random_state=10,如果去掉該屬性,那么每次結果都隨機,
7 K-近鄰演算法優缺點
優點:
-
是一種非常典型的分類監督學習演算法,可以解決多分類的問題,
-
適合類域交叉樣本,適合大樣本的自動分類
-
整體思想簡單
-
重新訓練的代價低
- 不會像其他演算法一樣需要有模型保存之類的操作,直接訓練就完事兒了
-
精度高、對例外值不敏感、無資料輸入假定,
缺點:
-
效率低,時間復雜度高、空間復雜度高
-
惰性學習,正是因為沒有模型學習,所以效率更低
-
對不均衡的樣本不擅長
- 例如一個班里大部分都是男生,極少數女生,那么預測一個插班生進來,一找鄰居發現都是男生,就會預測成男生,
- 改進方法是對K臨近點進行加權,也就是距離近的點的權值大,距離遠的點權值小,
-
解釋性不強,類別評分不是規格化
- 預測結果只是來自于對于測驗資料最近的點的屬性,整體上很難解釋,也導致了很難進行后續的改進和發展;
- 其他演算法的預測可能給出你一個百分比,讓你很清晰的知道是什么情況,而KNN是直接給你結果,
-
計算量較大
- 每個待分類的樣本都要計算它到全部點的距離,根據距離排序才能求得K個臨近點,
- 改進方法是先對已知樣本點進行剪輯,事先去除對分類作用不大的樣本
8 模型調優—交叉驗證與網格搜索
交叉驗證:資料處理中把資料集劃分為訓練資料和測驗資料,而交叉驗證則再把訓練資料劃分為訓練集和驗證集,如下圖,將訓練資料分為4分,一份作為驗證集,另外三分作為訓練集,然后進行N次測驗,每次都更換不同的驗證集(下圖是進行4次驗證),最后把所有驗證結果取平均值,作為最終結果,這就是N折交叉驗證,(下圖是4折交叉驗證)

注意:交叉驗證只是讓被評估的模型更加可信,并不能提高最后的準確率,
超引數:在sklearn中需要我們手動指定的引數,例如K-近鄰里的K值,
網格搜索:一個模型通常都會有超引數,例如K-近鄰的K,我們可能預設不同的K值,然后根據結果確定最好的K值,但這個程序比較麻煩,要反復呼叫函式,而網格搜索就是預先設定好超引數,每組超引數都采取交叉驗證進行評估,最后選出最優引數建立模型,
sklearn.model_selection.GridSearchCV(estimator, param_grid=None,cv=None)
- estimator:估計器
- param_grid:我們預設的超引數
- cv:指定?折交叉驗證
- 回傳的結果物件特有屬性:
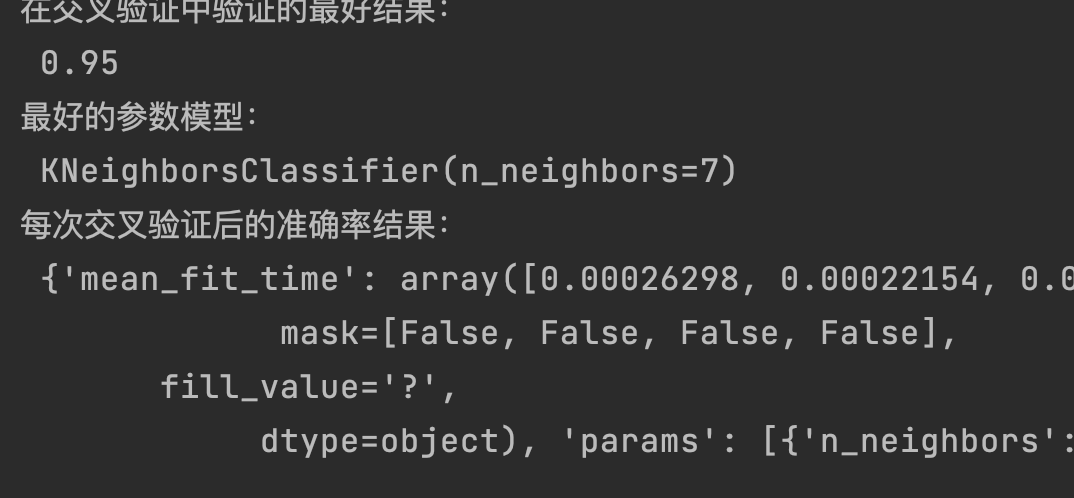
- best_score__:在交叉驗證中驗證的最好結果
- best_estimator__:最好的引數模型
- cv_results_:每次交叉驗證后的驗證集準確率結果和訓練集準確率結果
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
# K-近鄰演算法 —— 鳶尾花種類預測
# 實體數量:150(3個種類,山鳶花、變色鳶尾、維吉尼亞鳶尾,每種各50個)
# 屬性數量:4(數值型,萼片長度、萼片寬度、花瓣長度、花瓣寬度)
# 1. 獲取資料集
iris = load_iris()
# 2. 資料基本處理 - 這里是只是把資料集劃分為訓練集和測驗集
x_train, x_test, y_train, y_test = train_test_split(
iris.data, iris.target, test_size=0.2, random_state=10)
# 3. 特征工程 - 特征預處理 標準化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test) # fit_transform和transform的區別是 前者
# 4. 機器學習 - KNN
# 4.1 實體化一個估計器
estimator = KNeighborsClassifier() # 不指定K值了
# 4.2 模型選擇與調優——?格搜索和交叉驗證
# 準備要調的超引數
param_dict = {"n_neighbors": [1, 3, 5, 7]} # 預設K為 1、3、5、7,最后會選擇一個最好的引數
estimator = GridSearchCV(estimator, param_grid=param_dict, cv=5) # 4折交叉驗證
# 4.3 估計器訓練
estimator.fit(x_train, y_train)
# 5. 模型評估
# 5.1 預測值結果輸出
y_pre = estimator.predict(x_test)
print("預測值是:\n", y_pre)
print("預測值和真實值的對比:\n", y_pre == y_test)
# 5.2 準確率
score = estimator.score(x_test, y_test)
print("準確率:\n", score)
# 5.3 交叉驗證和網格搜索的特有屬性
print("在交叉驗證中驗證的最好結果:\n", estimator.best_score_)
print("最好的引數模型:\n", estimator.best_estimator_)
print("每次交叉驗證后的準確率結果:\n", estimator.cv_results_)
9 實戰案例:預測FaceBook簽到位置
專案資料集來自Kaggle:https://www.kaggle.com/c/facebook-v-predicting-check-ins
為了方便下載,我也上傳到CSDN里了(免積分):https://download.csdn.net/download/qq_39763246/21002651

本次?賽的?的是預測?個?將要簽到的地?, 為了本次?賽,Facebook創建了?個虛擬世界,其中包括10公?10 公?共100平?公?的約10*萬個地?, 對于給定的坐標集,您的任務將根據?戶的位置,準確性和時間戳等預測?戶下?次的簽到位置, 資料被制作成類似于來?移動設備的位置資料, 請注意:您只能使?提供的資料進?預測,
資料集情況:
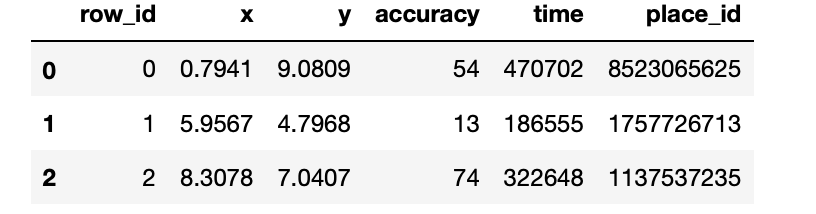
id:簽?事件的id
x y:坐標
accuracy: 準確度,定位精度
time: 時間戳
place_id: 簽到的位置,這也是你需要預測的內容
步驟分析:
-
對于資料做?些基本處理
- 1 縮?資料集范圍 DataFrame.query() ,因為資料量很大,為了節省時間,就減少一些資料,
- 2 選取有?的時間特征,特征time是時間戳,不是常見的日期格式,將其轉換下,
- 3 將簽到位置少于n個的?戶洗掉,每一行都是一個用戶簽到記錄,每行的place_id是該用戶簽到的地區編號,有些地區編號可能只有一兩個人,這種地區就可以去除,
-
分割資料集
-
標準化處理
-
k-近鄰預測
具體步驟:
# 1.獲取資料集
# 2.基本資料處理
# 2.1 縮?資料范圍
# 2.2 選擇時間特征
# 2.3 去掉簽到較少的地?
# 2.4 確定特征值和?標值
# 2.5 分割資料集
# 3.特征?程 -- 特征預處理(標準化)
# 4.機器學習 -- knn+cv
# 5.模型評估
具體代碼如下(建議用jupyter編程,里面每個步驟單獨運行查看):
- 導包
import pandas as pd
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
- 獲取資料
# 1.獲取資料集
facebook = pd.read_csv("FaceBook_train.csv")
facebook.head(3)
- 資料基本處理
# 2. 資料基本處理
# 2.1 縮小資料范圍以減少訓練時間()
facebook_data = facebook.query("x > 2.0 & x < 3.0 & y > 2.0 & y < 3.0")
# 2.2 對time進行轉換處理(time是時間戳,將其轉為日期格式)
time = pd.to_datetime(facebook_data["time"], unit="s") # 時間戳的單位是秒,所以用unit設定下
time = pd.DatetimeIndex(time)
facebook_data["day"] = time.day # 在源資料里新增day列
facebook_data["week"] = time.week # 在源資料里新增week列
facebook_data["hour"] = time.hour # 在源資料里新增hour列
# 2.3 去除 簽到 比較少的地方(place_id是地區編號,每一行簽到都會屬于一個地區)
place_count = facebook_data.groupby("place_id").count() # 根據地區編號進行分組聚合,統計每個地區有多少簽到處
place_count = place_count[place_count["row_id"]>3] #根據統計結果,篩選出簽到處大于3的地區
# place_count此時只包含簽到處大于3的地區,但不是一個完整的表,根據place_count的索引(索引就是place_id)來獲取完整資料
facebook_data = facebook_data[facebook_data["place_id"].isin(place_count.index)]
# 2.4 確定特征值和目標值
x = facebook_data[["x", "y", "accuracy", "day", "week", "hour"]] # 特征值
y = facebook_data["place_id"] # 目標值
# 2.5 分割資料
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=10)
- 特征工程
# 3. 特征工程 —— 特征預處理 標準化
# 3.1 實體化一個轉換器
transfer = StandardScaler()
# 3.2 開始轉換
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
- 機器學習
# 4. 機器學習 KNN
# 4.1 實體化一個估計器
estimator = KNeighborsClassifier()
# 4.2 交叉驗證、網格搜索
param_grid = {"n_neighbors":[3, 5, 7, 9]}
# n_jobs表示用幾核CPU來跑這個程式,我的電腦是8核,-1表示整個CPU都來跑,花了12秒,
estimator = GridSearchCV(estimator=estimator, param_grid=param_grid, cv=3, n_jobs=6)
# 4.3 模型訓練
estimator.fit(x_train, y_train)
- 模型評估
# 5. 模型評估
# 5.1 基本評估方式
score = estimator.score(x_test, y_test)
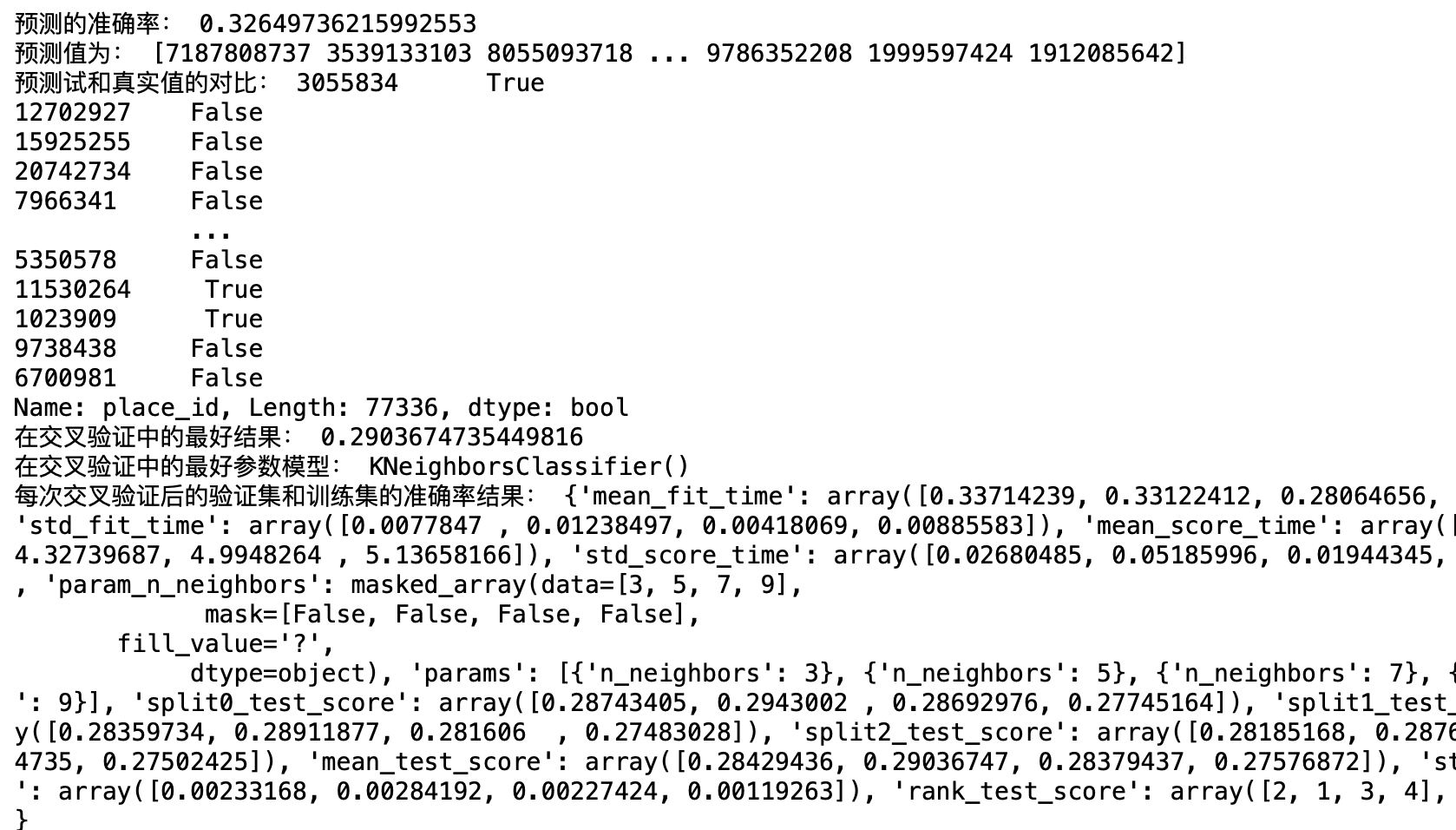
print("預測的準確率:", score)
y_predic = estimator.predict(x_test)
print("預測值為:", y_predic)
print("預測驗和真實值的對比:", y_predic == y_test)
# 5.2 交叉驗證的評估
print("在交叉驗證中的最好結果:", estimator.best_score_)
print("在交叉驗證中的最好引數模型:", estimator.best_estimator_)
print("每次交叉驗證后的驗證集和訓練集的準確率結果:", estimator.cv_results_)
效果:準確度這么低是因為資料只使用了一部分
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/293511.html
標籤:AI
上一篇:Value-Based Reinforcement Learning-DQN
下一篇:機器學習在神策資料的應用