強化學習
這一章會講DQN演算法,并且用TD演算法來訓練DQN,Value-Based Reinforcement Learning-DQN
- 強化學習
- 前言
- 一、Action-Value Functions
- 二、DQN
- 2.1 游戲中agent的目標是什么?
- 2.2 agent如何做決策?
- 2.3 如何理解Q* 函式呢?
- 2.5 DQN打游戲?
- 三、如何訓練DQN?
- 3.1 TD演算法
- 3.2 TD演算法訓練DQN
- 四、訓練步驟
- 六、總結
前言
說明一下:這是我的一個學習筆記,課程鏈接如下:最易懂的強化學習課程
公眾號:AI那些事

一、Action-Value Functions
我們回顧一下Action-Value Functions:

??這些R都是環境給的Reward獎勵,每當agent做出一個動作,環境就會更新一個狀態,并且給一個獎勵R,每一個獎勵R都依賴前一個狀態和動作,所以Return依賴t時刻開始所有的動作和所有的狀態,未來的狀態A和S都是隨機變數,動作A的隨機性來自policy函式π,動作是agent根據函式π隨機抽樣得到的,狀態S的隨機性來自于狀態轉移函式p,新的狀態是根據函式p隨機抽樣得到的,未來所有的動作和狀態都是隨機的,Ut依賴于這些動作和狀態,因此Ut也是隨機的,Ut的值可以反映出來未來獎勵的總和,所以我們想了解Ut的大小,由于Ut是一個隨機變數,在t時刻我們并不知道Ut的值,我們可以對Ut求期望,這樣就可以排除掉Ut中的隨機性,這個期望是關于未來所有的動作A和狀態S求的,期望消除了S和A的隨機變數,只留下了At和St兩個變數,通過求期望我們得到了Qπ函式,它被稱為Action-Value function 動作價值函式,Qπ和策略函式π有關,和St和At也有關,未來的隨機性都被期望所消除了,Qπ只依賴當前的動作At和狀態St,Qπ可以反映出當前狀態St下做動作At的好壞程度,我們想要進行一般消除策略函式π,我們可以根據Qπ對π求最大化得到最優動作價值函式Q*(最優動作價值函式)
??Q* 告訴我們不管用什么樣的策略π要使agent在當前狀態st下做動作at,那么回報Ut的期望頂多就是Q*(st,at),不會更好,Q* 函式與policy函式π無關,只要agent做的動作a那么Q*(st,at)就是最好的結果了,哪怕之后你把策略函式π改進的更好,你獲得的回報也不會比Q*(st,at)更好,
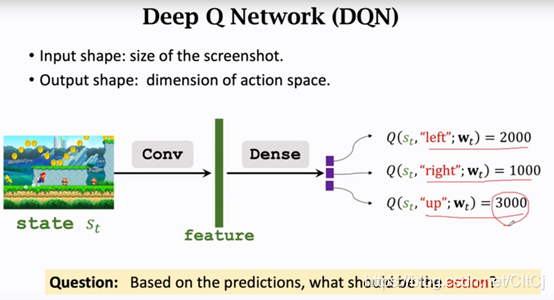
??說的更簡單一點Q* 函式告訴我們,基于當前狀態st做出動作at的好壞程度,所以Q* 函式可以指導agent做決策,agent觀測到當前的狀態st,Q* 函式可以給當前狀態進行打分,比如向上跳是3000分,向左是2000分,向右是1000分,agent可以根據分數來做決策,既然向上跳的分數最高是3000分agent就應該向上跳,這樣期望回報才會最大化,
二、DQN

2.1 游戲中agent的目標是什么?
??主要目標是打贏游戲,既然目標定下來了,那么agent就要努力的實作目標,假設Q* 函式是知道的,那么agent該怎么做決策呢?
2.2 agent如何做決策?
??決策就是選出最優動作,那什么才是最優動作呢,我們剛才說Q* 函式可以給所有的動作打分,每個動作a都有一個分數,最好的動作a就是分數最高的那個動作,我做一個更加通俗的解釋:Q* 函式就像一個先知一樣,它能預見未來的結果,比如你問先知,現在有a,b,c三支股票,我該把我的錢用來買哪一支股票呢?未來是充滿隨機性的,什么都可能發生,如蝴蝶效應,所以先知沒有辦法給你一個確定的答案,只能告訴你平均值,先知告訴你,從平均值來看,A股票漲了10倍,B股票漲了2倍,C股票跌了一半,先知還告訴你實際發生的情況和平均值并不一樣,那么你該買哪一支股票呢?我們很定會選擇A股票,因為它能漲10倍,
2.3 如何理解Q* 函式呢?
??我們可以把Q* 當做一個先知,它能夠告訴你每一個動作帶來的平均回報,你該聽先知的話,選平均回報最高的那個動作,我們希望有Q* 這樣一個先知,agent可以靠Q* 的指點來做決策,這樣agent就像開了掛一樣,但實際上我們沒有Q* 函式,價值學習的基本想法就是學習一個函式來近似Q* ,我們不可能近似出一個萬能的先知,但是對于超級瑪麗這種游戲學習出來一個先知并不難,要是我玩了10w次超級瑪麗,我就跟先知一樣了,看一眼螢屏就告訴你這一步是什么操作才是最好的,
2.5 DQN打游戲?
??DQN是一種價值學習的方法,用一個神經網路去近似Q* 函式,我們將這個神經網路記為Q(s,a;w),神經網路的引數是w,輸入是狀態s,輸出是很多數值,這些數值是對所有很能的動作的打分,每一個動作對應一個分數,我們通過獎勵來學習神經網路,這個神經網路給動作的打分就會逐漸改進,打分會越來越準,如果讓神經網路玩幾百萬次超級瑪麗,這個神經網路就跟先知一樣了,

??DQN就是一個這樣的神經網路,對于不同的問題DQN的結構可能會不一樣,我這里舉個例子,如果是玩超級瑪麗,可以把螢屏上的畫面進行輸入,用一個卷積層將圖片變為特征向量,最后用幾個全連接層把特征映射到一個輸出的向量,這個輸出的向量就是對動作的打分,向量每一個元素對應一個動作,在超級瑪麗的例子里面有左右上三個動作,所以輸出的向量是三維的,agent會做得分最高的動作,所以我們只要把DQN訓練好,就可以用DQN自動控制超級瑪麗打游戲,
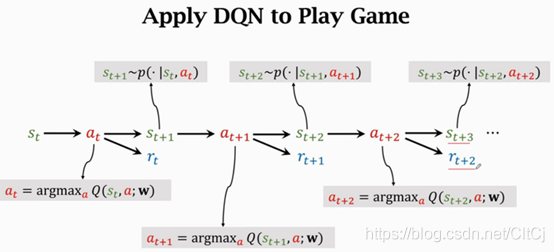
??用DQN控制agent打游戲,當前觀測到狀態st,用DQN把st作為輸入,給所有的動作打分,選出分數最高的動作作為at,agent執行at這個動作后,環境會改變狀態,用狀態轉移函式p來隨機抽一個狀態st+1,環境告訴我們這一步的獎勵rt,獎勵可以是正的可以是負的也可以是0,獎勵就是強化學習中的監督信號,DQN要靠獎勵進行訓練,有了新的狀態st+1,DQN再對所有的動作打分,agent選擇分數最高的動作,作為at+1,agent執行at+1后,環境會再更新狀態st+2,還會再給一個獎勵rt+1,然后還是重復這一程序,讓DQN給動作打分,讓agent選擇分數最高的動作來執行,然后環境再更新狀態s再給獎勵rt+2,不斷重復這一程序直到游戲結束,
三、如何訓練DQN?
??我們這里采用TD演算法
3.1 TD演算法

??TD演算法不是那么容易理解,所以我用一個例子來闡述:
??假設:我要從紐約開車到亞特蘭大,我有一個模型Q,引數是W,他可以預測出開車出行的時間開銷,我現在要從紐約出發了,這是Q告訴我,要開車1000min,才能到亞特蘭大,這個模型一開始不是很準確,或者是純隨機的,但是隨著用這個模型的人越來越多,得到越來越來資料跟多訓練,這個模型就會越來越準,會像谷歌地圖一樣準確,
??問題是這樣的,我需要什么資料呢,得到這些資料我該怎么更新模型引數呢?
??最簡單的辦法是,首先,出發之前,讓模型做一個預測記作q,模型告訴我,從紐約到亞特蘭大要花1000min,所以q=1000,預測過后我就出發了,但當我到亞特蘭大的時候我只用了860min,這里的q是模型的預測,而y是我真實的開銷,于是我把y作為target,q和y不一樣,q比y大了140min,這就說明我的模型預測有了偏差,比我實際的y要多,這就造成了loss損失,損失定義為q和y的平方差,記作l,我們對損失l關于模型引數W求導,然后把倒數關于鏈式法則展開l是q的函式,q是W的函式,所以這之間可以用鏈式法則求導,結果就是(q-y) * q函式對W的倒數,梯度求出來了,我們就能根據梯度下降來更新模型引數W,新的引數Wt+1為:
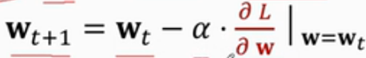
??假如我們用Wt+1代替Wt那么預測值將會更加接近真實值y=860,這是因為梯度下降減小了loss讓預測值離真實值更近了,這種演算法我必須完成整個旅途才能對模型進行一次更新,

??我問個問題,假如我走到半路我就不走了,那我還有辦法對模型進行更新嗎?
??我從紐約開車去亞特蘭大會經過華盛頓DC,假如我到DC的時候,車子出故障了,我就去不了亞特蘭大了,那我有沒有可能使用這一段旅途去改進模型呢?
??其實是可以的,我從出發的時刻做了預測,模型說從紐約開車到亞特蘭大要花1000分鐘,這個1000就是模型的估計,當我開車到DC的時候我一看花了300分鐘(真實觀測),然后模型又預測我還需要花600min才能到達亞特蘭大,
??回顧一下,一開始模型告訴我,從紐約到亞特蘭大需要花1000min,而現在我到DC花了300min,模型又告訴我,我還需要花600min才能到達亞特蘭大,根據模型新的預測我知道我到達亞特蘭大的總時間900min,比原來快了100min,在TD演算法里面我們將這個新的估計900min叫做TD target
??TD target雖然也是一個雖然也是個估計,但未必是實際情況,但是它要比最初的1000min要更可靠,最初的估計純粹是一個估計,無事實成分,雖然TD target也是一個估計但是它有事實成分,當我越接近亞特蘭大,TD target就越接近真實值,
??用TD target的話我不需要跑完整個路程去知道真實的時間開銷,我到了DC我得到TD target=900,我就可以更新模型引數了,我假如y=900就是真實觀測,我把y作為target,損失函式就是:最開始預測的模型引數 1000和TD target差的平方,這里Q(W)和y的差我們稱為TD error,
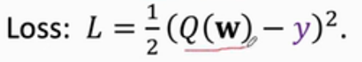
??整個模型更新如下:


??剛才我們學了TD演算法,有了TD演算法即使不完成旅途也能更新模型引數,把TD演算法用來學習DQN是相同的道理,我不需要打完游戲就能更新游戲的引數,
3.2 TD演算法訓練DQN

??怎樣才能使用TD演算法來學習DQN呢?
??剛才的例子里面要用到這樣一個公式:

&ems p;?公式的意思是紐約到亞特蘭大的時間(估計)約等于紐約到DC(真實時間)+ DC到亞特蘭大的時間(估計),有上述公式才能實作TD演算法:
在深度強化學習中也有這樣一個公式:
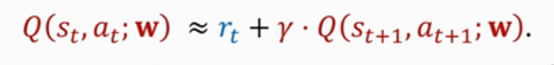
??等式左邊是T時刻的估計,這是未來總和的期望相當于紐約到亞特蘭大的總時間,等式右邊有一項rt是真實的獎勵,第二項是DQN在t+1時刻做的估計,相當于DC到亞特蘭大的估計時間,接下來,我總結一下為什么強化學習有這個公式:
??回顧一下折扣回報:
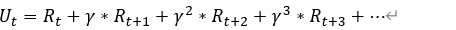
??這里的R是獎勵,γ是一個介于0-1之間的折扣率,我們對這個公式進行處理,將有γ的項提取一個γ得到:
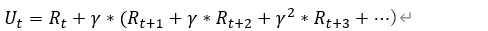
??括號里的內容是什么呢?我們再用一下折扣回報U的定義,不難發現括號里面就是Ut+1因此我們得到一個等式:
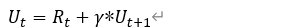
??這個等式反應了相鄰兩個折扣之間的關系,
??現在我們要把TD演算法用到DQN上,在t時刻DQN輸出的值Q(st,at;w)是對Ut做出的估計,這就像我從紐約出發前,模型做的預測,告訴我,紐約到亞特蘭大的總時間,
??在下一時刻DQN輸出的值Q(st+1,at+1;w)是對Ut+1做出的估計,這就我開車到DC,模型預測DC到亞特蘭大的時間,
??我們知道Ut=Rt+γ * Ut+1,所以Ut的期望約等于Rt加上Ut+1的期望,所以我們能夠得到這樣一個關系,DQN在t時刻做出的預測:
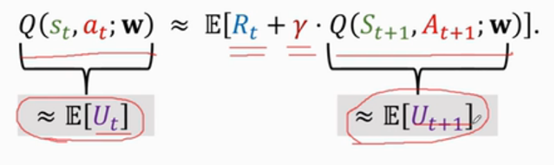
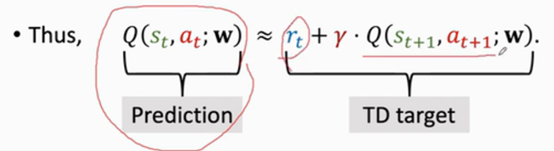
四、訓練步驟
??有了prediction和TD target我們就能更新DQN的模型引數了:
在t時刻,模型做出了預測Q(st,at;w),這里的st是當前的狀態,at是已經做出的動作,wt是當時的模型引數,
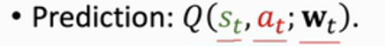
??到了t+1時刻,我們觀測到真實的獎勵rt,還觀測到新的狀態st+1,有了st+1,我們就能用DQN算出下一個動作at+1了,在t+1時刻我們知道了rt,st+1,at+1的值,這時候我們就能計算TD target記作yt,t+1時刻的動作at+1是怎么算出來的呢,DQN對每一個動作打分,分數最高的那個動作就被選出來作為at+1,所以呢,Q(st+1,at+1;wt)就是對Q函式關于a求最大化,
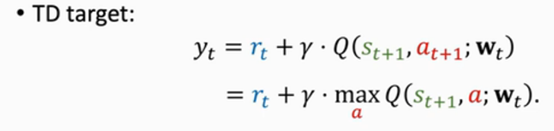
??我們將兩者差的平方l做為loss:
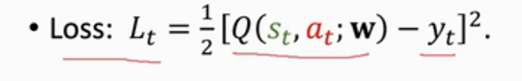
??然后算lt關于模型引數w的導數,作梯度下降來更新模型引數,做梯度下降是為了使loss減小
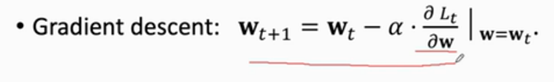
??總的來說所有步驟就是這樣的:

六、總結
期待大家和我交流,留言或者私信,一起學習,一起進步!麻煩大家可用關注公眾號:AI那些事,感謝!!!

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/293510.html
標籤:AI