🐱今天出一期spark系列的硬貨,即RDD算子,所謂算子,就是對某些事物的操作,或者說是方法,本期主要介紹幾十個RDD算子,根據他們的特點,逐一進行介紹,有關spark的往期內容大家可以查看下面的內容👇:
- 鏈接: Spark之處理布爾、數值和字串型別的資料.
- 鏈接: Spark之Dataframe基本操作.
- 鏈接: Spark之處理布爾、數值和字串型別的資料.
- 鏈接: Spark之核心架構.
??記得我們前面說過,saprk存在著惰性評估的機制,所謂惰性評估,就是等到絕對需要時才執行計算,當用戶表達一些對資料的操作時,不是立即修改資料,而是建立一個作用到原始資料的轉換計劃,直到最后才開始執行代碼,這里我們將RDD分為2種,一種是轉換算子,一種是行動算子,
目錄
- 1. RDD 轉換算子
- 1.1 Value 型別
- 1.2 雙Value 型別
- 1.3 Key - Value 型別
- 2. RDD 行動算子
- 3. 參考文獻
1. RDD 轉換算子
轉換算子,故名思義,就是對資料進行轉換的算子,并不不能立馬執行,而是定義邏輯,根據資料處理方式的不同將算子整體上分為Value 型別、雙 Value 型別和 Key-Value型別,
1.1 Value 型別
- map
將處理的資料逐條進行映射轉換,這里的轉換可以是型別的轉換,也可以是值的轉換,(一個一個執行,效率不高)
- mapPartitions
將待處理的資料以磁區為單位發送到計算節點進行處理,這里的處理是指可以進行任意的處理,哪怕是過濾資料,(效率較高,得到一個磁區后的資料才開始計算,但是對記憶體需求較高)
map 和 mapPartitions 的區別?
- Map 算子是磁區內一個資料一個資料的執行,類似于串行操作,而 mapPartitions 算子是以磁區為單位進行批處理操作,
- Map 算子主要目的將資料源中的資料進行轉換和改變,但是不會減少或增多資料,MapPartitions 算子需要傳遞一個迭代器,回傳一個迭代器,沒有要求的元素的個數保持不變,所以可以增加或減少資料
- Map 算子因為類似于串行操作,所以性能比較低,而是mapPartitions 算子類似于批處理,所以性能較高,但是mapPartitions 算子會長時間占用記憶體,那么這樣會導致記憶體可能不夠用,出現記憶體溢位的錯誤,所以在記憶體有限的情況下,不推薦使用,使用 map 操作,
- mapPartitionsWithIndex
將待處理的資料以磁區為單位發送到計算節點進行處理,這里的處理是指可以進行任意的處理,哪怕是過濾資料,在處理時同時可以獲取當前磁區索引,
- flatMap
將處理的資料進行扁平化后再進行映射處理,所以算子也稱之為扁平映射,(將整體映射成一個一個個體,如: List(List(1,2),3,List(4,5))轉換為 List(List(1),List(2),List(3),List(4),List(5))
- glom
將同一個磁區的資料直接轉換為相同型別的記憶體陣列進行處理,磁區不變,(比如將int型別的【1,2】【3,4】這兩個磁區內的資料轉化為array型別的【1,2】【3,4】每個磁區內的資料轉化為了陣列型別)
- groupby
將資料根據指定的規則進行分組, 磁區默認不變,但是資料會被打亂重新組合,我們將這樣的操作稱之為shuffle,極限情況下,資料可能被分在同一個磁區中,(分組和磁區沒有本質的關系!)
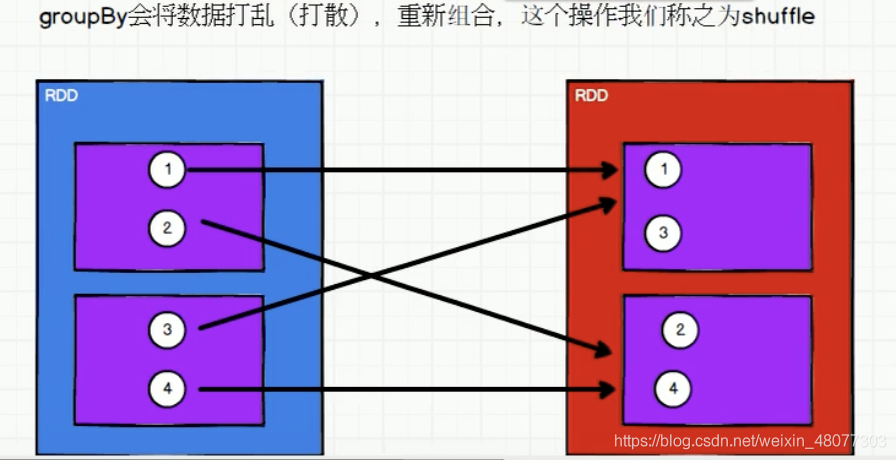
解釋一下:(1,2)一個磁區,(3,4)一個磁區,但是經過groupby之后,我們發現(1,3)一個磁區,(2,4)一個磁區,但總體上還是兩個磁區,
- filter
將資料根據指定的規則進行篩選過濾,符合規則的資料保留,不符合規則的資料丟棄,當資料進行篩選過濾后,磁區不變,但是磁區內的資料可能不均衡,生產環境下,可能會出現資料傾斜,
- sample
根據指定的規則從資料集中抽取資料,
//sample的三個引數
withReplacement: Boolean,#是否又放回抽樣
fraction: Double,#抽取的幾率
seed: Long = Utils.random.nextLong#亂數種子
- distinct
將資料集中重復的資料去重,去重的方式是通過將數值map成鍵值對的形式然后通過reducebykey聚合,最后選出聚合結果,
- coalesce
根據資料量縮減磁區,用于大資料集過濾后,提高小資料集的執行效率,當 spark 程式中,存在過多的小任務的時候,可以通過coalesce 方法,收縮合并磁區,減少磁區的個數,減小任務調度成本,(該方法不會打亂資料,可能會導致資料傾斜,也可以設定成shuffle,也可以擴大磁區,但是需要shuffle,擴大磁區時等于repartition)
- repartition
該操作內部其實執行的是 coalesce 操作,引數 shuffle 的默認值為 true,無論是將磁區數多的RDD 轉換為磁區數少的 RDD,還是將磁區數少的 RDD 轉換為磁區數多的 RDD,repartition操作都可以完成,因為無論如何都會經 shuffle 程序,(將磁區數由少變多)
- sortBy
該操作用于排序資料,在排序之前,可以將資料通過 f 函式進行處理,之后按照 f 函式處理的結果進行排序,默認為升序排列,排序后新產生的 RDD 的磁區數與原 RDD 的磁區數一致,中間存在 shuffle 的程序,
(例如:有一組資料1,2,3,4,1,2 其中123時一個磁區,412是一個磁區,排序后的結果是112,234這兩個磁區,)
1.2 雙Value 型別
雙Value 型別故名思義,就是傳遞兩個資料源的算子,這里就會涉及到交集并集差集的概念,(交,并,差集都需要兩個rdd資料型別一樣)
- intersection
對源 RDD 和引數 RDD 求交集后回傳一個新的 RDD
- union
對源 RDD 和引數 RDD 求并集后回傳一個新的 RDD
- subtract
以一個 RDD 元素為主,去除兩個 RDD 中重復元素,將其他元素保留下來,求差集
- zip
將兩個 RDD 中的元素,以鍵值對的形式進行合并,其中,鍵值對中的 Key 為第 1 個 RDD中的元素,Value 為第 2 個 RDD 中的相同位置的元素,(要求磁區數量一樣,每個磁區中的資料也一樣)
val dataRDD1 = sparkContext.makeRDD(List(1,2,3,4))
val dataRDD2 = sparkContext.makeRDD(List(3,4,5,6))
val dataRDD = dataRDD1.zip(dataRDD2)
結果為(1,3)(2,4)(3,5)(4,6)
1.3 Key - Value 型別
- partitionBy
將資料按照指定 Partitioner 重新進行磁區,Spark 默認的磁區器是HashPartitioner(資料型別一定需要是Key - Value型別的資料,是將資料進行重新的磁區,磁區數量不變,)
- reduceByKey
可以將資料按照相同的 Key 對 Value 進行聚合(相同的key分在一個組里面進行聚合,原理是兩兩聚合,如果key的值只有一個,那就不會進行聚合)
- groupByKey
將資料源的資料根據 key 對 value 進行分組,將相同的key放在一個組中,形成一個對偶元組(什么是對偶元組,即元組的第一個值是key值,元組的第二個值是相同key的value集合,)
reduceByKey 和 groupByKey 的區別?
我們今天就來從深層次來講講groupByKey和reduceByKey的相同與不同點,
先說一下groupByKey的原理:
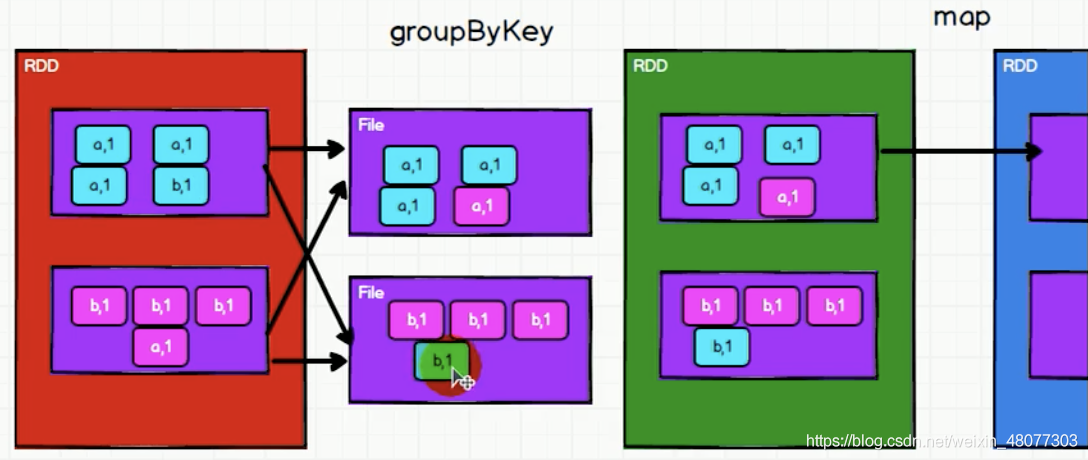
解釋:在groupByKey會將磁區內的資料打亂,因此存在著shuffle操作,spark中的shuffle操作必須落盤處理,也就是寫進磁盤中進行存盤,否則很容易造成記憶體溢位,shuffle性能不夠高,如果后續需要實作reducebykey一樣的聚合操作,可以使用map函式來實作,
reduceByKey的原理:
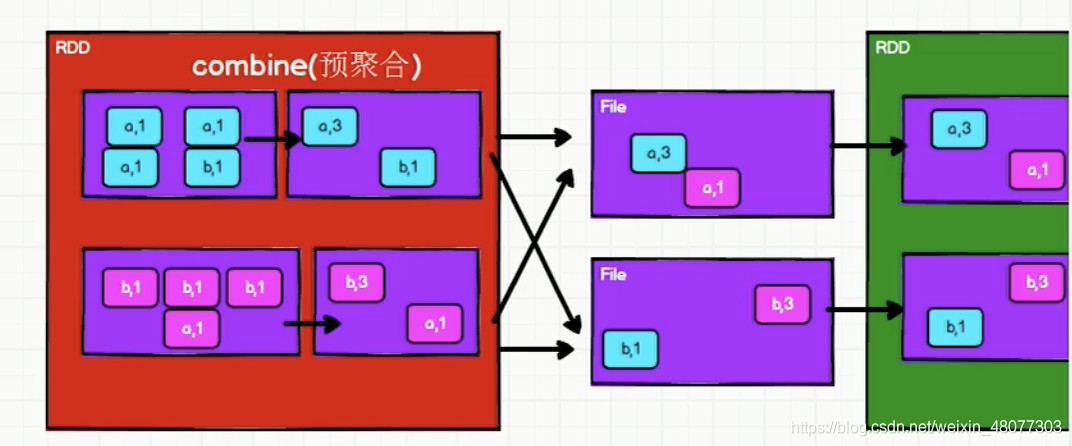
解釋:reducebykey可以將資料在磁區內就進行聚合操作,使得shuffle落盤的資料大大減少,增強shuffle效率,
總結:
- shuffle角度:reduceByKey 和 groupByKey 都存在 shuffle 的操作,但是 reduceByKey 可以在 shuffle 前對磁區內相同 key 的資料進行預聚合(combine)功能,這樣會減少落盤的 資料量,而 groupByKey 只是進行分組,不存在資料量減少的問題,reduceByKey 性能比較高,
- 從功能的角度:reduceByKey 其實包含分組和聚合的功能,GroupByKey只能分組,不能聚合,所以在分組聚合的場合下,推薦使用 reduceByKey,如果僅僅是分組而不需要聚合,那么還是只能使用 groupByKey,
- aggregateByKey
將資料根據不同的規則進行磁區內計算和磁區間計算,啥叫磁區內和磁區間呢?我給大家解釋一下:其實在前面的reducebykey中,磁區內指的就是一個磁區內部的資料可以進行聚合操作(不僅僅限于聚合),磁區外,指的是不同磁區之間的資料也可以進行聚合操作(不僅僅限于聚合),
aggregateByKey就是這樣一個函式,可以將磁區內和磁區外的邏輯操作分開來計算,例如磁區內進行取最大值,磁區外求和,這時就可以使用該函式,
- foldByKey
當磁區內計算規則和磁區間計算規則相同時,aggregateByKey 就可以簡化為 foldByKey(計算規則相同時,簡化aggregateByKey操作)
- combineByKey
最通用的對 key-value 型 rdd 進行聚集操作的聚集函式(aggregation function),類似于 aggregate(),combineByKey()允許用戶回傳值的型別與輸入不一致,
- join
在兩個資料源上在型別為(K,V)和(K,W)的 RDD 上呼叫,回傳一個相同 key 對應的所有元素連接在一起的 (K,(V,W))的 RDD,如果兩個資料源中沒有相同的K,則結果中不會出現該(K,W),
- leftOuterJoin
類似于 SQL 陳述句的左外連接
- cogroup
在型別為(K,V)和(K,W)的 RDD 上呼叫,回傳一個(K,(Iterable,Iterable))型別的 RDD (可以理解為先連接后分組)
2. RDD 行動算子
前面終于把轉換算子講完了,識訓就是對shuffle程序有了更深層次的認識,這一部分我們來講行動算子,所謂行動算子,就是使用了該算子后,將會觸發整個流程的執行,
- reduce
聚集 RDD 中的所有元素,先聚合磁區內資料,再聚合磁區間資料
- collect
在驅動程式中,以陣列 Array 的形式回傳資料集的所有元素(會將不同磁區內的資料按照磁區順序采集到driver端的記憶體中形成陣列,)
- count
回傳 RDD(資料源) 中元素的個數
- first
回傳 RDD(資料源) 中的第一個元素
- take
回傳一個由 RDD 的前 n 個元素組成的陣列
- takeOrdered
回傳該 RDD 排序后的前 n 個元素組成的陣列(先排序,再取數)
- aggregate
磁區的資料通過初始值和磁區內的資料進行聚合,然后再和初始值進行磁區間的資料聚合(例如;【1,2】,【3,4】兩個磁區,初始值為10,那么該函式就會 (1+2+10)+(3+4+10)+10計算)
- fold
折疊操作,aggregate 的簡化版操作(aggregate當磁區內和磁區間的計算規則相同時可以簡化,)
- countByKey
統計每種 key 的個數
- save 相關算子
將資料保存到不同格式的檔案中
// 保存成 Text 檔案
rdd.saveAsTextFile("output")
// 序列化成物件保存到檔案
rdd.saveAsObjectFile("output1")
// 保存成 Sequencefile 檔案
rdd.map((_,1)).saveAsSequenceFile("output2")
- foreach
分布式遍歷 RDD 中的每一個元素,呼叫指定函式
// 收集后列印
rdd.map(num=>num).collect().foreach(println)
// 分布式列印
rdd.foreach(println)
3. 參考文獻
這些spark函式真的是一個一個學習的,因為不太會Scala,所以只能從分布式的角度來理解他,這些函式對學會分布式的原理太有幫助了,
- 《Spark權威指南》
- 《Hadoop權威指南》
- 《尚硅谷spark教材》
- 《大資料hadoop3.X分布式處理實戰》
- 《Pyspark實戰》
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/293550.html
標籤:其他
上一篇:Spark面試總結(1)