sk-learn Facebook資料集預測簽到位置
本次比賽的目的是預測一個人將要簽到的地方, 為了本次比賽,Facebook創建了一個虛擬世界,其中包括10公里*10公里共100平方公里的約10萬個地方,
對于給定的坐標集,我們的任務將根據用戶的位置,準確性和時間戳等預測用戶下一次的簽到位置, 資料被制作成類似于來自移動設備的位置資料,
特征值:“x”, “y”, “accuracy”, “day”, “hour”, “weekday”
目標值: place_id
本實體使用Facebook上統計的資料,根據地點坐標和簽到時間等特征來訓練模型,最終得到目標地點的ID,訓練集與測驗集比例為8:2,
在進行資料模型訓練時,首先要進行資料預處理
縮小資料范圍:因為資料集有2000W+條資料,程式跑起來會非常慢,因此適當縮小資料范圍,如果電腦配置夠或者租了服務器請隨意~
選擇時間特征:資料中的時間分離出day,hour,weekend
去掉簽到較少的地方:剔除意義不大的特殊地點,減少過擬合
確定特征值和目標值
分割資料集
交叉驗證:將拿到的訓練資料,分為訓練和驗證集,以下圖為例:將資料分成4份,其中一份作為驗證集,然后經過4次(組)的測驗,每次都更換不同的驗證集,即得到4組模型的結果,取平均值作為最終結果,又稱4折交叉驗證,本實體cv=5,則為5折交叉驗證,
def facebook_demo():
"""
sk-learn Facebook資料集預測簽到位置
:return:
"""
# 1、獲取資料集
facebook = pd.read_csv('/Users/maxinze/Downloads/機器學xiday2資料/02-代碼/FBlocation/train.csv')
# 2.基本資料處理
# 2.1 縮小資料范圍
# 選擇(2,2.5)這一范圍的資料,使用 query
facebook_data = facebook.query("x>5.0 & x<6 & y>5.0 & y<6.0")
# 2.2 選擇時間特征
# 提取時間
time = pd.to_datetime(facebook_data["time"], unit="s")
time = pd.DatetimeIndex(time)
# 加一列day
facebook_data["day"] = time.day
# 加一列hour
facebook_data["hour"] = time.hour
# 加一列weekday
facebook_data["weekday"] = time.weekday
# 2.3 去掉簽到較少的地方
# 分組聚類,按數目聚類
place_count = facebook_data.groupby("place_id").count()
# 選擇簽到大于3的
place_count = place_count[place_count["row_id"] > 3]
# 傳遞資料
facebook_data = facebook_data[facebook_data["place_id"].isin(place_count.index)]
# facebook_data.shape()
# 2.4 篩選特征值和目標值
# 特征值
x = facebook_data[["x", "y", "accuracy", "day", "hour", "weekday"]]
# 目標值
y = facebook_data["place_id"]
# 2.5 分割資料集(資料集劃分) 引數特征值, 目標值
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=22)
# 3.特征工程--特征預處理(標準化)
# 3.1 實體化一個轉換器
transfer = StandardScaler()
# 3.2 呼叫fit_transform
# 特征訓練集
x_train = transfer.fit_transform(x_train)
# 特征測驗集
x_test = transfer.fit_transform(x_test)
# 4.機器學習--knn+cv
# 4.1 實體化一個估計器
estimator = KNeighborsClassifier()
# 4.2 呼叫gridsearchCV
# param_grid = {"n_neighbors": [1, 3, 5, 7, 9]}
param_grid = {"n_neighbors": [5, 7, 9]}
estimator = GridSearchCV(estimator, param_grid=param_grid, cv=3 )
# 4.3 模型訓練
estimator.fit(x_train, y_train)
# 5.模型評估
# 5.1 基本評估方式
score = estimator.score(x_test, y_test)
print("最后預測的準確率為:\n", score)
y_predict = estimator.predict(x_test)
print("最后的預測值為:\n", y_predict)
print("預測值和真實值的對比情況:\n", y_predict == y_test)
# 5.2 使用交叉驗證后的評估方式
print("在交叉驗證中驗證的最好結果:\n", estimator.best_score_)
print("最好的引數模型:\n", estimator.best_estimator_)
print("每次交叉驗證后的驗證集準確率結果和訓練集準確率結果:\n", estimator.cv_results_)
return None
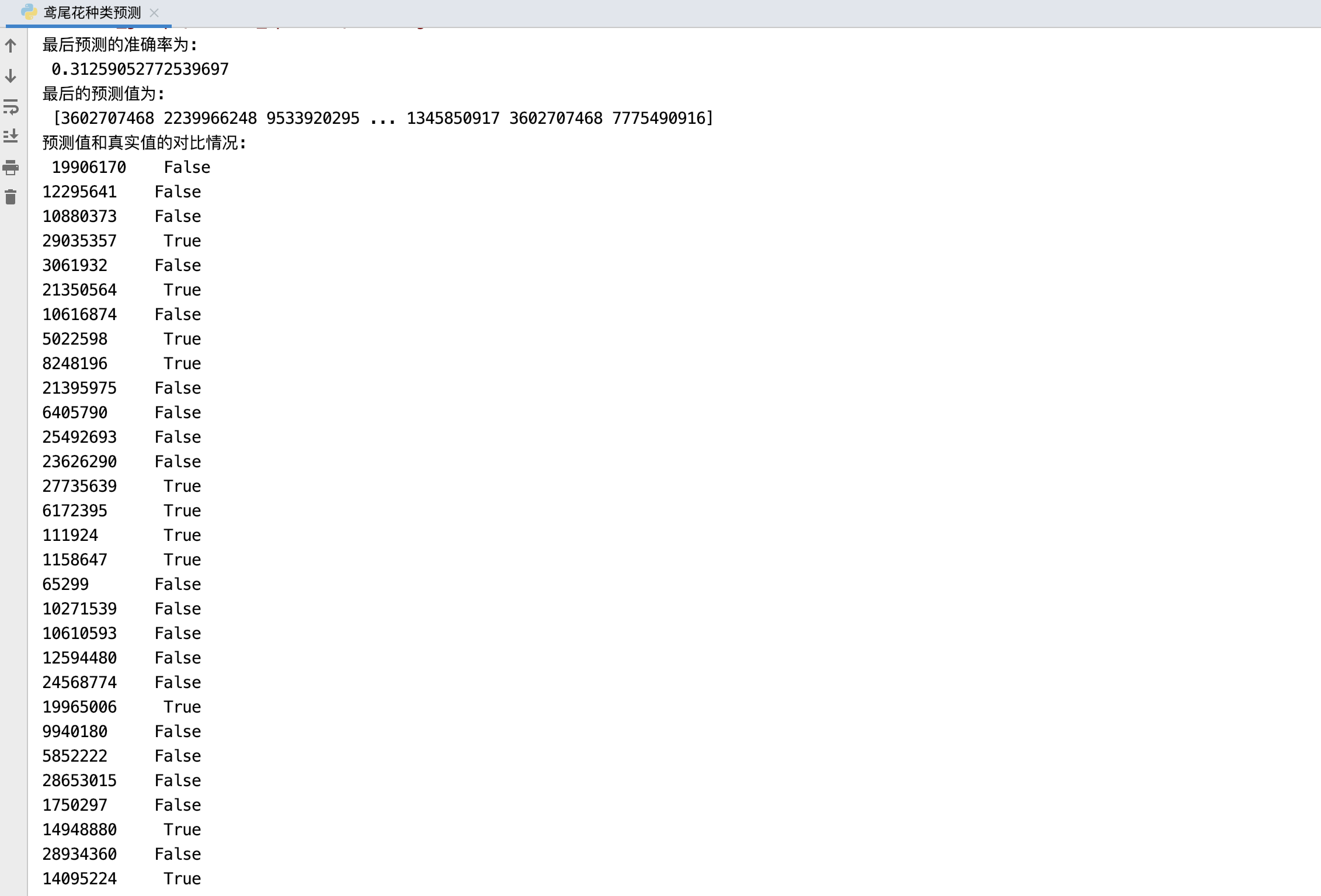
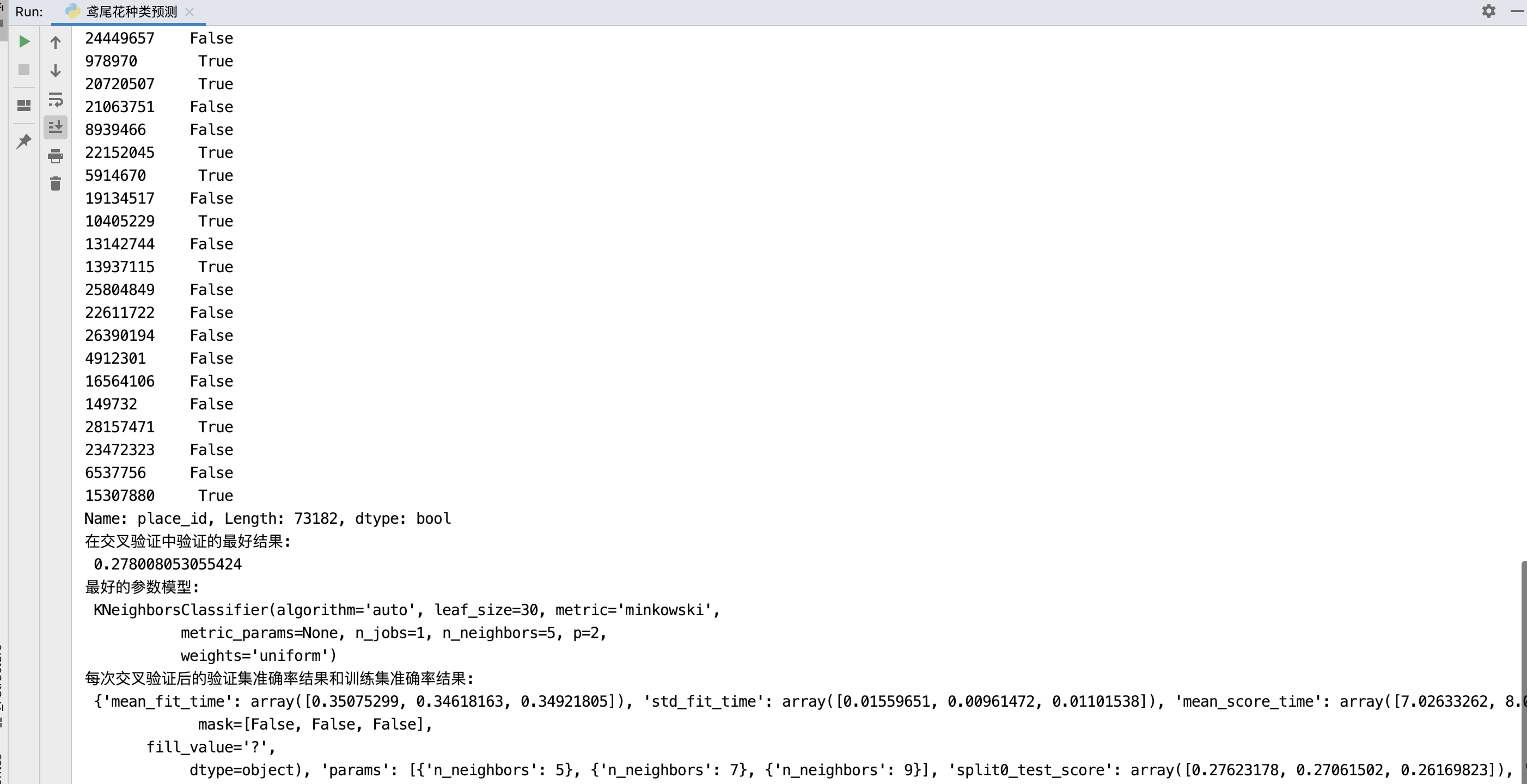
因為只選用了部分資料跑代碼,所以模型訓練后測驗的準確率不太高,如果可以選用全部資料跑,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/293697.html
標籤:AI