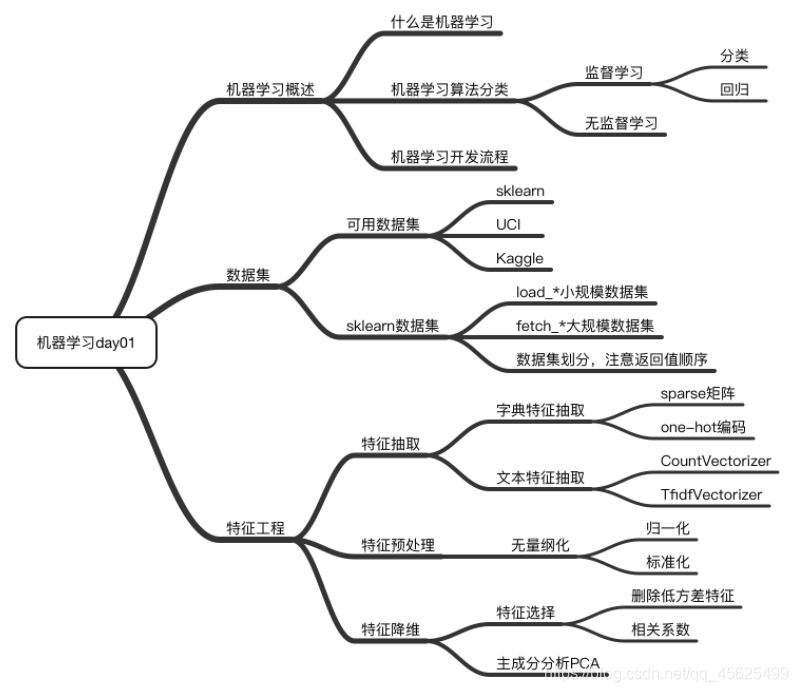
文章目錄
- 1、資料集
- 1.1 可用資料集
- 1.2 scikit-learn資料集
- sklearn小資料集
- sklearn大資料集
- 1.3 資料集的劃分
- 資料集劃分API
- 2.特征工程
- 2.1特征工程包含內容
- 3.特征提取
- 3.1字典特征提取
- 3.2 文本特征提取
- 3.3中文文本特征提取
- 3.4 Tf-idf文本特征提取
- 公式
- 4.特征預處理
- 4.1 歸一化
- 4.2 標準化
- 5. 特征降維
- 5.1 特征選擇
- 5.1.1 低方差特征過濾
- 5.1.2 相關系數
- 6. 主成分分析
- 總結
1、資料集
1.1 可用資料集
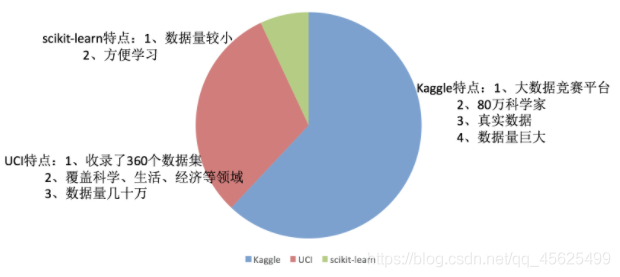
Kaggle網址:https://www.kaggle.com/datasets
UCI資料集網址: http://archive.ics.uci.edu/ml/
scikit-learn網址:https://scikit-learn.org/stable/
1.2 scikit-learn資料集
- load_* 獲取小規模資料集,資料包含在datasets里
- fetch_* 獲取大規模資料集,需要從網路上下載,函式的第一個引數是data_home,表示資料集下載的目錄,默認是 ~/scikit_learn_data/
sklearn小資料集
def datasets_demo():
"""
sklearn資料集使用
:return:
"""
# 獲取資料集
iris = load_iris()
print("鳶尾花資料集:\n", iris)
print("查看資料集描述:\n", iris["DESCR"])
print('鳶尾花的目標值:\n', iris.target)
print("查看特征值的名字:\n", iris.feature_names)
print("鳶尾花目標值的名字:\n", iris.target_names)
print("查看特征值:\n", iris.data, iris.data.shape)
# 資料集劃分
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=22)
print("訓練集的特征值:\n", x_train, x_train.shape)
return None
sklearn大資料集
sklearn.datasets.fetch_20newsgroups(data_home=None,subset=‘train’)
- subset:‘train’或者’test’,‘all’,可選,選擇要加載的資料集,
- 訓練集的“訓練”,測驗集的“測驗”,兩者的“全部”
1.3 資料集的劃分
- 訓練資料:用于訓練,構建模型
- 測驗資料:在模型檢驗時使用,用于評估模型是否有效,測驗集一般在20%~30%
資料集劃分API
sklearn.model_selection.train_test_split(arrays, *options)
- x 資料集的特征值
- y 資料集的標簽值
- test_size 測驗集的大小,一般為float
- random_state 亂數種子,不同的種子會造成不同的隨機采樣結果,相同的種子采樣結果相同,
- return 測驗集特征訓練集特征值值,訓練標簽,測驗標簽(默認隨機取)
# 資料集劃分
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=22)
print("訓練集的特征值:\n", x_train, x_train.shape)
2.特征工程
特征工程是使用專業背景知識和技巧處理資料,使得特征能在機器學習演算法上發揮更好的作用的過程,
- 意義:會直接影響機器學習的效果
2.1特征工程包含內容
- 特征抽取
- 特征預處理
- 特征降維
3.特征提取
特征提取是將任意資料(如文本或影像)轉換為可用于機器學習的數字特征
- 字典特征提取(特征離散化)
- 文本特征提取
- 影像特征提取(深度學習將介紹)
特征提取API:sklearn.feature_extraction
3.1字典特征提取
def dict_demo():
"""
字典特征提取
:return:
"""
data = [{'city': '北京', 'temperature': 100},
{'city': '上海', 'temperature': 60},
{'city': '深圳', 'temperature': 30}]
# 1.實體化一個轉換器類
transfer = DictVectorizer(sparse=False)
# 2.呼叫fit_transform()
data_new = transfer.fit_transform(data)
print('data_new\n', data_new)
print("特征名字: \n", transfer.get_feature_names())
return None
3.2 文本特征提取
def count_demo():
"""
文本特征抽取:CountVecotrizer
:return:
"""
data = ["Life is short, i like like python", "life is too long, i dislike python"]
# 1.一個轉換器類
transfer = CountVectorizer(stop_words=['is', 'too']) # 停用詞不統計
# 2.呼叫fit_transform
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new.toarray())
print("特征名字:\n", transfer.get_feature_names())
return None
3.3中文文本特征提取
def cut_word(text):
"""
進行中文分詞:“我愛北京天安門” --->"我 愛 北京 天安門"
:param text:
:return:
"""
text = " ".join(list(jieba.cut(text)))
return text
def count_chinese_demo2():
"""
中文文本特征抽取,自動分詞
:return:
"""
# 1.將中文文本進行分詞
data = ["一種還是一種今天很殘酷,明天更殘酷,后天很美好,但絕對大部分是死在明天晚上,所以每個人不要放棄今天,",
"我們看到的從很遠星系來的光是在幾百萬年之前發出的,這樣當我們看到宇宙時,我們是在看它的過去,",
"如果只用一種方式了解某樣事物,你就不會真正了解它,了解事物真正含義的秘密取決于如何將其與我們所了解的事物相聯系,"]
data_new = []
for sent in data:
data_new.append(cut_word(sent))
# print(data_new)
# 2.實體化一個轉換器類
transfer = CountVectorizer(stop_words=['一種', '因為'])
# 3.呼叫fit_transform
data_final = transfer.fit_transform(data_new)
print("data_new:\n", data_final.toarray())
print("特征名字:\n", transfer.get_feature_names())
return None
3.4 Tf-idf文本特征提取
- TF-IDF的主要思想是:如果某個詞或短語在一篇文章中出現的概率高,并且在其他文章中很少出現,則認為此詞或者短語具有很好的類別區分能力,適合用來分類,
- TF-IDF作用:用以評估一字詞對于一個檔案集或一個語料庫中的其中一份檔案的重要程度,
公式
- 詞頻(term frequency,tf)指的是某一個給定的詞語在該檔案中出現的頻率
- 逆向檔案頻率(inverse document frequency,idf)是一個詞語普遍重要性的度量,某一特定詞語的idf,可以由總檔案數目除以包含該詞語之檔案的數目,再將得到的商取以10為底的對數得到
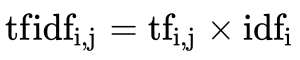
def tfidf_demo():
"""
用tfidf的方法進行文本特征提取
:return:
"""
# 1.將中文文本進行分詞
data = ["一種還是一種今天很殘酷,明天更殘酷,后天很美好,但絕對大部分是死在明天晚上,所以每個人不要放棄今天,",
"我們看到的從很遠星系來的光是在幾百萬年之前發出的,這樣當我們看到宇宙時,我們是在看它的過去,",
"如果只用一種方式了解某樣事物,你就不會真正了解它,了解事物真正含義的秘密取決于如何將其與我們所了解的事物相聯系,"]
data_new = []
for sent in data:
data_new.append(cut_word(sent))
# print(data_new)
# 2.實體化一個轉換器類
transfer = TfidfVectorizer(stop_words=["一種", '因為'])
# 3.呼叫fit_transform
data_final = transfer.fit_transform(data_new)
print("data_new:\n", data_final.toarray())
print("特征名字:\n", transfer.get_feature_names())
return None
4.特征預處理
通過一些轉換函式將特征資料轉換成更加適合演算法模型的特征資料程序
原因:特征的單位或者大小相差較大,或者某特征的方差相比其他的特征要大出幾個數量級,容易影響(支配)目標結果,使得一些演算法無法學習到其它的特征
數值型資料的無量綱化:
- 歸一化
- 標準化
API:sklearn.preprocessing
4.1 歸一化
通過對原始資料進行變換把資料映射到(默認為[0,1])之間
def minmax_demo():
"""
歸一化
:return:
"""
# 1.獲取資料
data = pd.read_csv('dating.txt')
data = data.iloc[:, :3]
# print("data:\n", data)
# 2.實體化一個轉換器類
transfer = MinMaxScaler()
# 3.呼叫fit_transform
data_new = transfer.fit_transform(data)
print("data_new:\n", data_new)
return None
注意:最大值最小值是變化的,另外,最大值與最小值非常容易受例外點影響,所以這種方法魯棒性(健壯性)較差,只適合傳統精確小資料場景,
4.2 標準化
通過對原始資料進行變換把資料變換到均值為0,標準差為1范圍內
- 對于歸一化來說:如果出現例外點,影響了最大值和最小值,那么結果顯然會發生改變
- 對于標準化來說:如果出現例外點,由于具有一定資料量,少量的例外點對于平均值的影響并不大,從而方差改變較小,
def stand_demo():
"""
標準化
:return:
"""
# 1. 獲取資料
data = pd.read_csv('dating.txt')
data = data.iloc[:, :3]
print('data:\n', data)
# 2.實體化一個轉換器類
transfer = StandardScaler()
# 3.呼叫fit_transform()
data_new = transfer.fit_transform(data)
print('data_new:\n', data_new)
return None
在已有樣本足夠多的情況下比較穩定,適合現代嘈雜大資料場景,
5. 特征降維
降維是指在某些限定條件下,降低隨機變數(特征)個數,得到一組“不相關”主變數的程序
降維的兩種方式
- 特征選擇
- 主成分分析(可以理解一種特征提取的方式)
5.1 特征選擇
資料中包含冗余或無關變數(或稱特征、屬性、指標等),旨在從原有特征中找出主要特征,
方法:
- Filter(過濾式):主要探究特征本身特點、特征與特征和目標值之間關聯
方差選擇法:低方差特征過濾
相關系數 - Embedded (嵌入式):演算法自動選擇特征(特征與目標值之間的關聯)
決策樹:資訊熵、資訊增益
正則化:L1、L2
深度學習:卷積等
API:sklearn.feature_selection
5.1.1 低方差特征過濾
洗掉低方差的一些特征,前面講過方差的意義,再結合方差的大小來考慮這個方式的角度,
- 特征方差小:某個特征大多樣本的值比較相近
- 特征方差大:某個特征很多樣本的值都有差別
def variance_demo():
"""
過濾低方差特征
:return:
"""
# 1. 獲取資料
data = pd.read_csv('factor_returns.csv')
data = data.iloc[:, 1:-2]
print('data:\n', data)
# 2. 實體化一個轉換器類
transfer = VarianceThreshold(threshold=10)
# 3. 呼叫fit_transform()
data_new = transfer.fit_transform(data)
print('data_new:\n', data_new, data_new.shape)
return None
5.1.2 相關系數
皮爾遜相關系數(Pearson Correlation Coefficient)
- 反映變數之間相關關系密切程度的統計指標
def pearsonr_demo():
"""
相關系數計算
:return: None
"""
data = pd.read_csv("factor_returns.csv")
data = data.iloc[:, 1:-2]
# 計算某兩個變數之間的相關系數
r1 = pearsonr(data['pe_ratio'], data['pb_ratio'])
print('pe_ratio與pb_ratio相關系數:\n', r1)
r2 = pearsonr(data['revenue'], data['total_expense'])
print('revenue與total_expense相關系數:\n', r2)
return None
6. 主成分分析
-
定義:高維資料轉化為低維資料的程序,在此程序中可能會舍棄原有資料、創造新的變數
-
作用:是資料維數壓縮,盡可能降低原資料的維數(復雜度),損失少量資訊,
-
應用:回歸分析或者聚類分析當中
def pca_demo():
"""
PCA降維
:return:
"""
data = [[2, 8, 4, 5], [6, 3, 0, 8], [5, 4, 9, 1]]
# 1.實體化一個轉換器類
transfer = PCA(n_components=2)
# 2. 呼叫fit_transform()
data_new = transfer.fit_transform(data)
print('data_new:\n', data_new)
return None
總結
關于本節所有代碼及資料集相關檔案參考如下鏈接:
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/293699.html
標籤:AI