大家好,我是K同學啊!
你是否一直在關注不同的卷積神經網路 (CNN)?近年來,我們見證了無數CNN的誕生,這些網路已經變得如此之深,以至于很難將整個模型可視化,我們不再跟蹤它們,而是將它們視為黑盒模型,
這篇文章是 10 種常見CNN 架構的可視化,這些插圖提供了整個模型的更緊湊的視圖,而不必為了查看 softmax 層而向下滾動幾次,除了這些影像,我還附上了一些關于它們如何隨著時間“進化”的筆記——從 5 到 50 個卷積層,從普通卷積層到模塊,從 2-3 個塔到 32 個塔,從 7?7 到 5 ?5——但稍后會詳細介紹,

在這里我想補充一點,我們在網上看到的大量 CNN 架構是許多因素的結果——改進的計算機硬體、ImageNet 競爭、解決特定任務、新想法等等,谷歌研究員 Christian Szegedy 曾提到,
“[大部分]進步不僅僅是更強大的硬體、更大的資料集和更大的模型的結果,而且主要是新思想、演算法和改進網路架構的結果,” (塞格迪等人,2014 年)
關于可視化的一些說明,請注意,我已經排除了插圖中的卷積過濾器數量、填充、步幅、dropouts和flatten 等資訊,
目錄(按出版年份排序)
- 1. LeNet-5 (1998)
- 2. AlexNet (2012)
- 3. VGG-16 (2014)
- 4. Inception-v1 (2014)
- 5. Inception-v3 (2015)
- 6. ResNet-50 (2015)
- 7. Xception (2016)
- 8. Inception-v4 (2016)
- 9. Inception-ResNet-V2 (2016)
- 10. ResNeXt-50 (2017)
- 附錄:網路中的網路(2014)
1. LeNet-5 (1998)

LeNet-5 是最簡單的架構之一,它有 2 個卷積層和 3 個全連接層(因此“5”——神經網路的名稱通常來自于它們所具有的卷積層和全連接層的數量),我們現在所知道的平均池化層被稱為子采樣層,它具有可訓練的權重(這不是當今設計 CNN 的當前做法),這個架構有大約60,000 個引數,
??什么是小說?
這種架構已經成為標準的“模板”:用激活函式和池化層堆疊卷積,并以一個或多個全連接層結束網路,
📝刊物
- 論文:Gradient-Based Learning Applied to Document Recognition
- 作者:Yann LeCun、Léon Bottou、Yoshua Bengio 和 Patrick Haffner
- 發表于: IEEE Proceedings of the IEEE (1998)
📚實體
- 深度學習100例-卷積神經網路(LeNet-5)深度學習里的“Hello Word” | 第22天
2. AlexNet (2012)

60M 引數,AlexNet 有 8 層——5 層卷積和 3 層全連接,AlexNet 只是在 LeNet-5 上再堆疊了幾層,在發表時,作者指出他們的架構是“迄今為止在 ImageNet 子集上最大的卷積神經網路之一”,
??什么是小說?
他們是第一個將整流線性單元 (ReLU) 實作為激活函式的人,
📝刊物
- 論文:ImageNet Classification with Deep Convolutional Neural Networks
- 作者:Alex Krizhevsky、Ilya Sutskever、Geoffrey Hinton,加拿大多倫多大學,
- 發表于:NeurIPS 2012
3. VGG-16 (2014)

到現在為止,你可能已經注意到 CNN 開始變得越來越深入,這是因為提高深度神經網路性能最直接的方法是增加它們的大小(Szegedy 等人),Visual Geometry Group (VGG) 的人發明了 VGG-16,它有 13 個卷積層和 3 個全連接層,同時繼承了 AlexNet 的 ReLU 傳統,該網路在 AlexNet 上堆疊了更多層,并使用了更小的過濾器(2×2 和 3×3),它由138M的引陣列成,占用大約500MB的存盤空間😱,他們還設計了一個更深的變體,VGG-19,
??什么是小說?
正如他們在摘要中提到的,這篇論文的貢獻是設計了更深的網路(大約是 AlexNet 的兩倍),這是通過堆疊均勻卷積來完成的,
📝刊物
- 論文:Very Deep Convolutional Networks for Large-Scale Image Recognition
- 作者:Karen Simonyan、Andrew Zisserman,英國牛津大學,
- arXiv 預印本,2014
📚實體
- 深度學習100例-卷積神經網路(VGG-16)識別海賊王草帽一伙 | 第6天
- 深度學習100例-卷積神經網路(VGG-16)貓狗識別 | 第21天
4. Inception-v1 (2014)
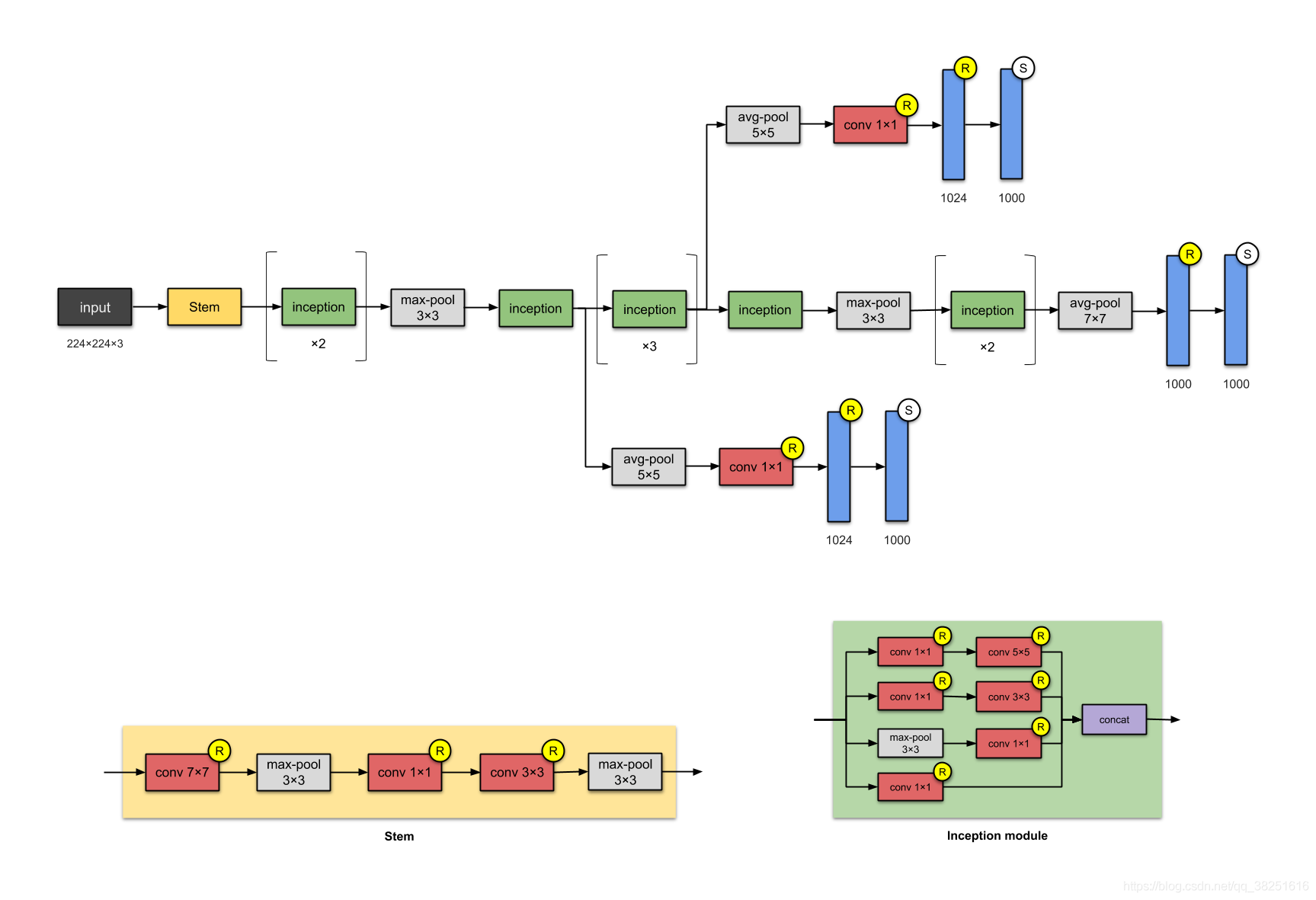
這種具有5M引數的22層架構稱為Inception-v1,在這里,網路中的網路(見附錄)方法被大量使用,如本文所述,這是通過“Inception模塊”完成的,Inception模塊的體系結構設計是近似稀疏結構研究的產物(閱讀論文了解更多!),每個模塊提出3個想法:
- 具有不同過濾器的并行卷積塔,然后進行串聯,在 1×1、3×3 和 5×5 處捕獲不同的特征,從而對它們進行“聚類”,這個想法是由阿羅拉等人的動機,在紙張可證明界學習的一些深層次的表示,表明層由層結構,其中一個應該分析的最后一層的相關統計資料,并將它們聚集到具有高相關單位團體,
- 1×1卷積用于維數降低,以除去計算瓶頸,
- 由于從1×1卷積激活函式,它的加入還增加了非線性,
- 作者還引入了兩個輔助分類器,以鼓勵在分類器的較低階段進行區分,增加傳播回來的梯度信號,并提供額外的正則化,所述輔助網路(被連接到輔助分類分支)在推理時間將被丟棄,
值得注意的是,“這種架構的主要特點是提高了網路內部計算資源的利用率,”
注意:
模塊的名稱(Stem和Inception)在其更高版本(即Inception-v4和Inception-ResNets)之前未用于此版本的Inception,我在這里添加了它們以便于比較,
??什么是小說?
使用密集模塊/塊構建網路,我們不是堆疊卷積層,而是堆疊模塊或塊,其中是卷積層,因此名稱為Inception(參考由Leonardo DiCaprio主演的2010年科幻電影Inception《盜夢空間》),
📝刊物
- 論文:Going Deeper with Convolutions
- 作者:Christian Szegedy、Wei Liu、Yangqing Jia、Pierre Sermanet、Scott Reed、Dragomir Anguelov、Dumitru Erhan、Vincent Vanhoucke、Andrew Rabinovich,谷歌、密歇根大學、北卡羅來納大學
- 發表于:2015 年 IEEE 計算機視覺和模式識別會議 (CVPR)
5. Inception-v3 (2015)
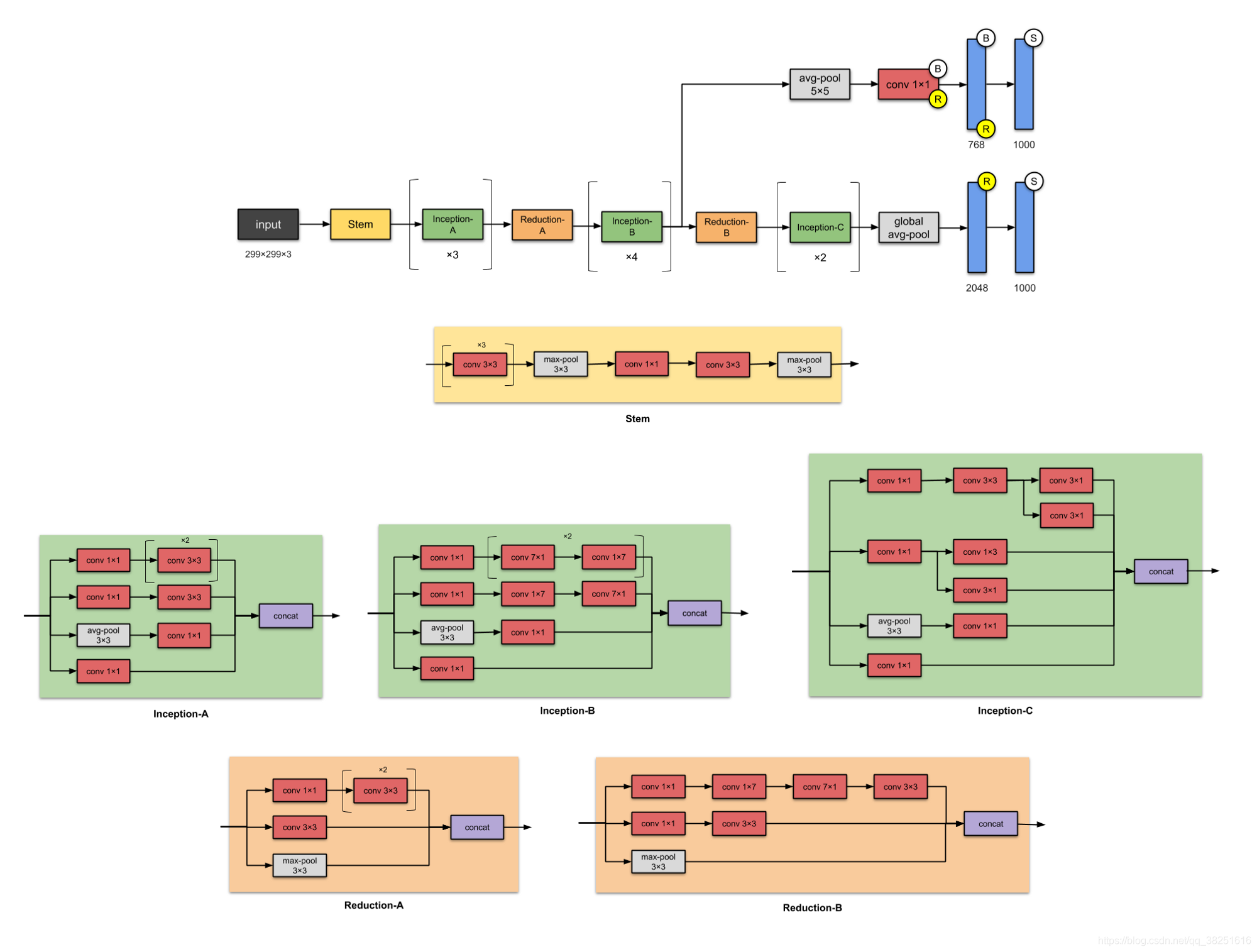
Inception-v3 是 Inception-v1 的繼承者,有24M引數,等等 Inception-v2 在哪里?別擔心——它是 v3 的早期原型,因此它與 v3 非常相似但不常用,當作者提出 Inception-v2 時,他們對其進行了許多實驗,并記錄了一些成功的調整,Inception-v3 是包含這些調整的網路(調整優化器、損失函式以及向輔助網路中的輔助層添加批量歸一化)
Inception-v2 和 Inception-v3 的動機是避免 代表性瓶頸 representational bottlenecks (這意味著大幅減少下一層的輸入維度)并通過使用因子分解方法進行更有效的計算,
注意:
模塊的名稱(Stem,Inception-A,Inception-B等)直到其更高版本即Inception-v4和Inception-ResNets才用于此版本的Inception,我在這里添加了它們以便于比較,
??什么是小說?
- 最早使用批量歸一化的設計者之一(為簡單起見,上圖中未反映),
?與之前的版本Inception-v1 相比有什么改進?
- 將n × n卷積分解為非對稱卷積:1× n和n ×1 卷積
- 將 5×5 卷積分解為兩個 3×3 卷積操作
- 將 7×7 替換為一系列 3×3 的卷積
📝刊物
- 論文:Rethinking the Inception Architecture for Computer Vision
- 作者:Christian Szegedy、Vincent Vanhoucke、Sergey Ioffe、Jonathon Shlens、Zbigniew Wojna,谷歌,倫敦大學學院
- 發表于:2016 年 IEEE 計算機視覺和模式識別會議 (CVPR)
📚實體
- 深度學習100例 - 卷積神經網路(Inception V3)識別手語 | 第13天
6. ResNet-50 (2015)
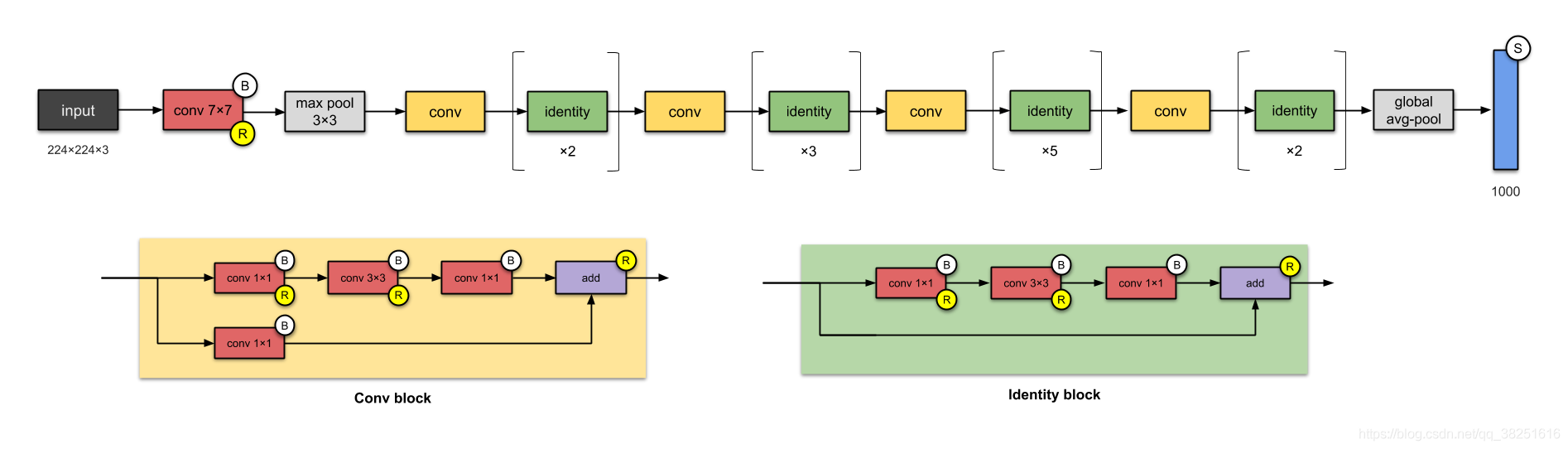
從過去的幾個 CNN 中,我們只看到設計中的層數越來越多,并獲得了更好的性能,但是“隨著網路深度的增加,準確度會飽和(這可能不足為奇)然后迅速下降,” 微軟研究院的人用 ResNet 解決了這個問題——使用跳過連接(又名快捷連接,殘差),同時構建更深層次的模型,
ResNet 是批標準化的早期采用者之一(由 Ioffe 和 Szegedy 撰寫的批規范論文于 2015 年提交給 ICML),上圖是 ResNet-50,有26M引數,
ResNets 的基本構建塊是 conv 和 identity 塊,因為它們看起來很像,你可以像這樣簡化 ResNet-50(不要為此參考我!):
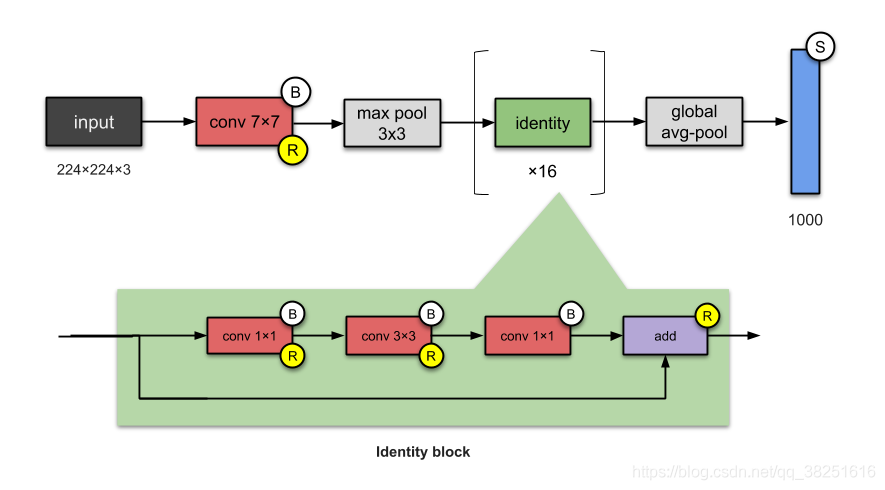
??什么是小說?
- 普及跳過連接(他們不是第一個使用跳過連接的人),
- 在不影響模型泛化能力的情況下設計更深的 CNN(最多 152 層)
- 最早使用批量標準化的人之一,
📝刊物
- 論文:Deep Residual Learning for Image Recognition
- 作者:Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun. Microsoft
- 發表于:2016 年 IEEE 計算機視覺和模式識別會議 (CVPR)
📚實體
- 深度學習100例 -卷積神經網路(ResNet-50)鳥類識別 | 第8天
7. Xception (2016)
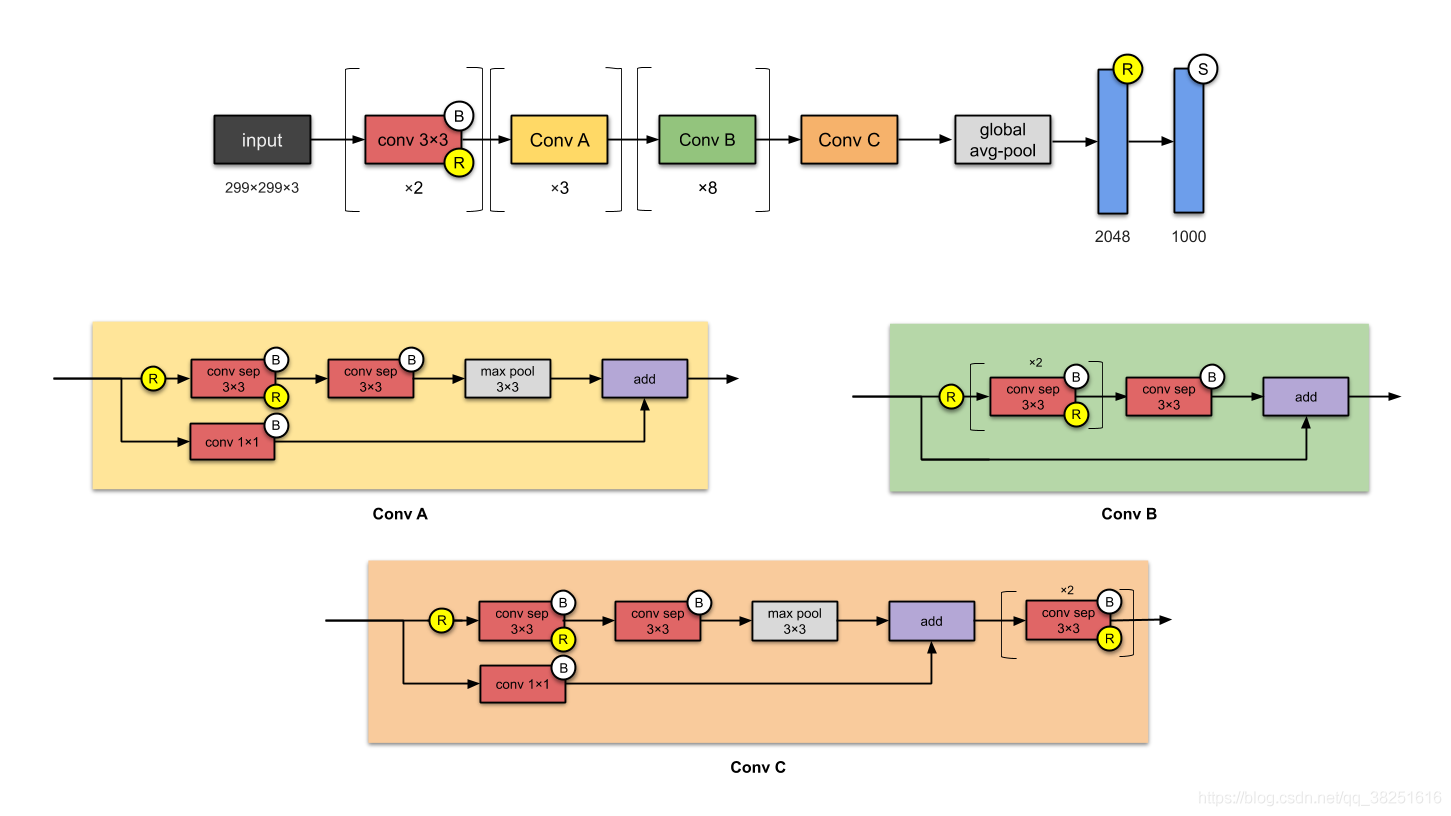
Xception 是對 Inception 的改編,其中 Inception 模塊已替換為深度可分離卷積,它的引數數量也與 Inception-v1 ( 23M )大致相同,
- 首先,跨通道(或跨特征圖)相關性由 1×1 卷積捕獲,
- 因此,通過常規的 3×3 或 5×5 卷積捕獲每個通道內的空間相關性,
將這個想法發揮到極致意味著對每個通道執行 1×1 ,然后對每個輸出執行 3×3 ,這與用深度可分離卷積替換 Inception 模塊相同,
??什么是小說?
- 引入了完全基于深度可分離卷積層的 CNN,
📝刊物
- 論文:Xception: Deep Learning with Depthwise Separable Convolutions
- 作者:Fran?ois Chollet. Google.
- 發表于:2017 IEEE 計算機視覺與模式識別會議 (CVPR)
8. Inception-v4 (2016)
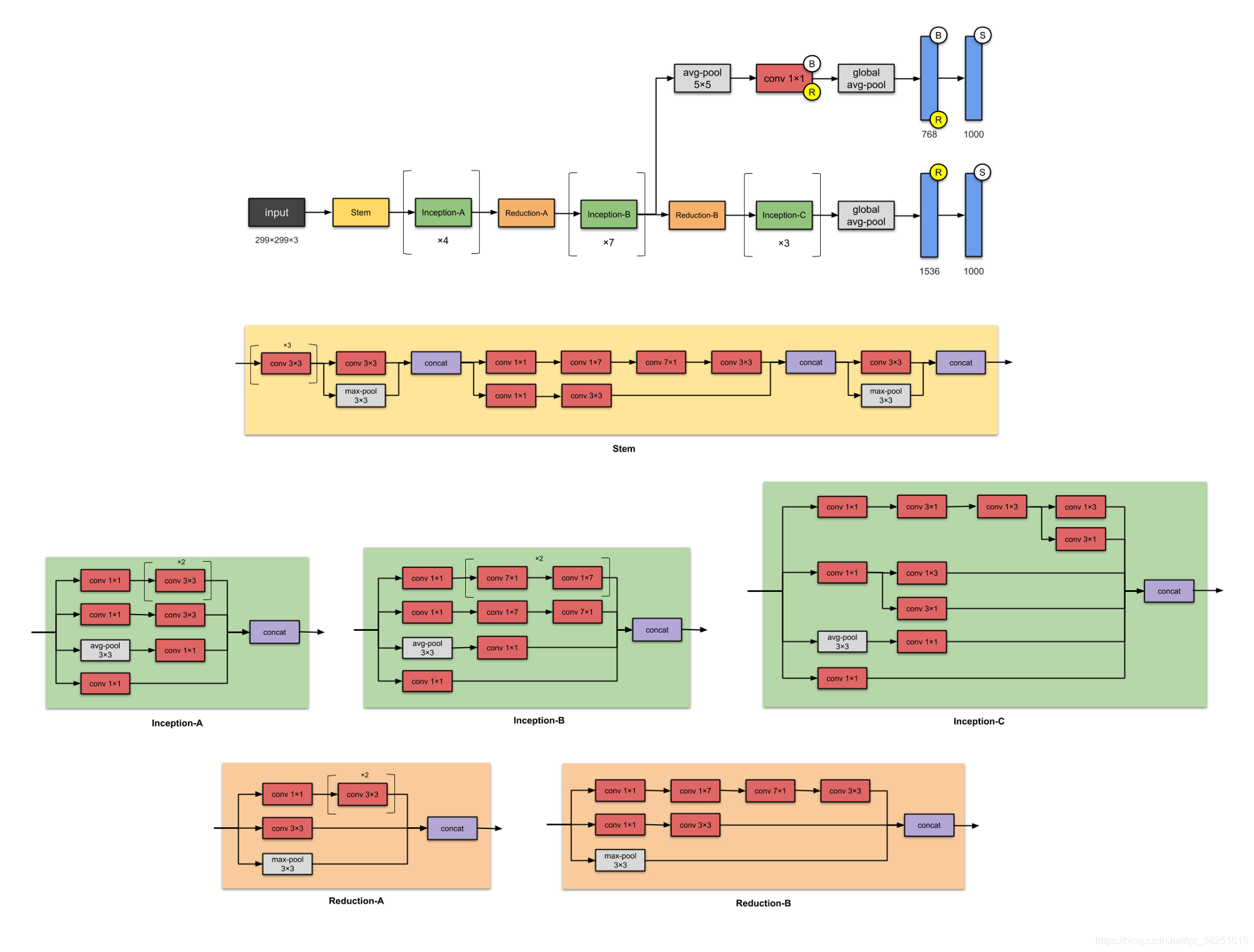
Google 的再次發起了 Inception- v4,43M 的引數,同樣,這是對 Inception-v3 的改進,主要區別在于 Stem 組和 Inception-C 模塊中的一些細微變化,作者還“為每個網格大小的 Inception 塊做出了統一的選擇”,他們還提到擁有“剩余連接(residual connections)可以顯著提高訓練速度”,
總而言之,請注意有人提到 Inception-v4 由于增加了模型尺寸而效果更好,
?與之前的版本Inception-v3 相比有什么改進?
- Stem 模塊的變化,
- 添加更多 Inception 模塊,
- Inception-v3 模塊的統一選擇,意味著對每個模塊使用相同數量的過濾器,
📝刊物
- 論文:Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
- 作者:Christian Szegedy, Sergey Ioffe, Vincent Vanhoucke, Alex Alemi. Google.
- 發表于: 第三十屆 AAAI 人工智能會議論文集
9. Inception-ResNet-V2 (2016)
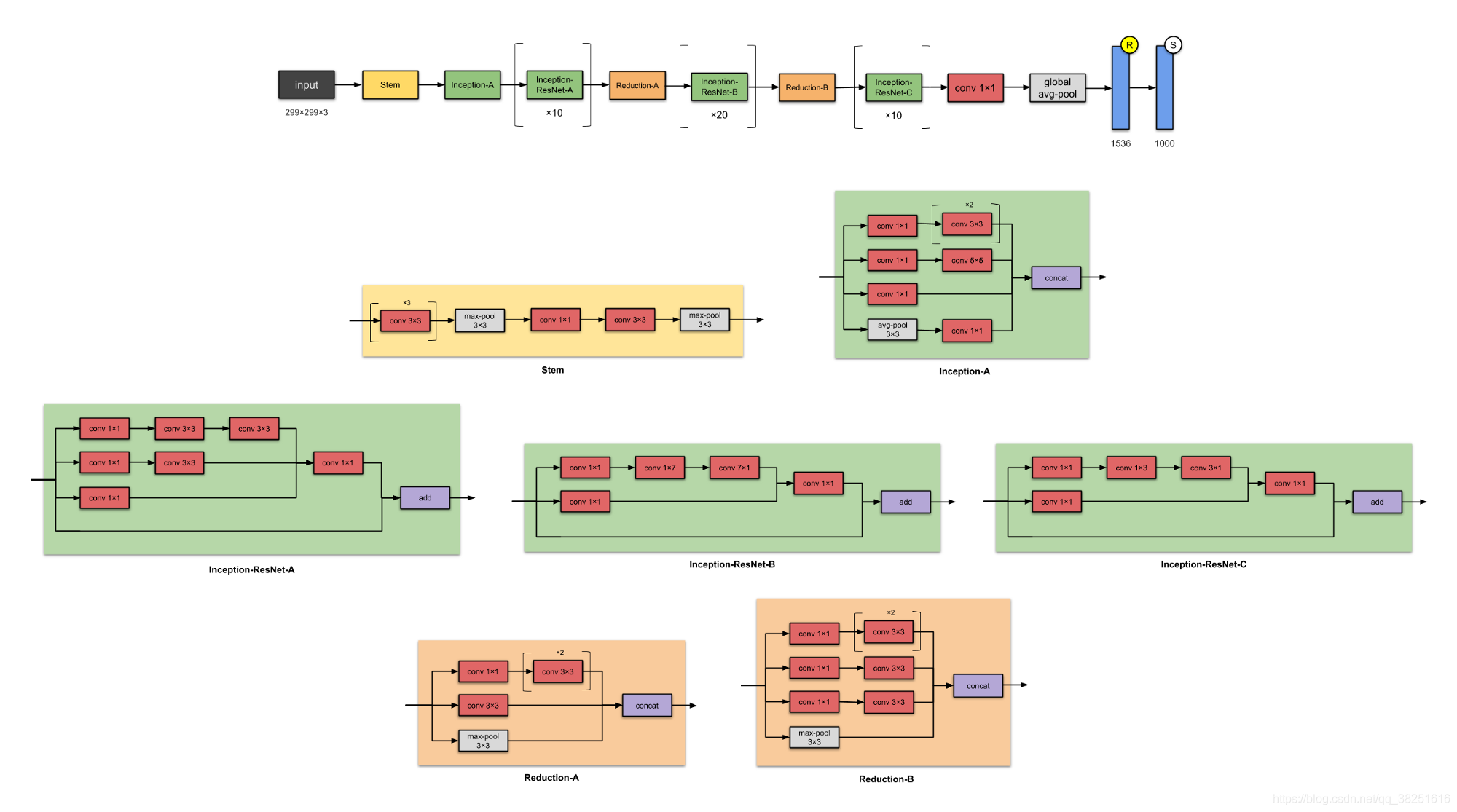
在與Inception-v4相同的論文中,同一作者還介紹了Inception-ResNets – 一系列Inception-ResNet-v1和Inception-ResNet-v2,該系列的后一個成員有56M引數,
?與之前的版本Inception-v3 相比有什么改進?
- 將 Inception 模塊轉換為Residual Inception 塊,
- 添加更多 Inception 模塊,
- 在 Stem 模塊之后添加了一種新型的 Inception 模塊(Inception-A),
📝刊物
- 論文:Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
- 作者:Christian Szegedy, Sergey Ioffe, Vincent Vanhoucke, Alex Alemi. Google
- 發表于: 第三十屆 AAAI 人工智能會議論文集
📚實體
- 深度學習100例-卷積神經網路(Inception-ResNet-v2)識別交通標志 | 第14天
10. ResNeXt-50 (2017)
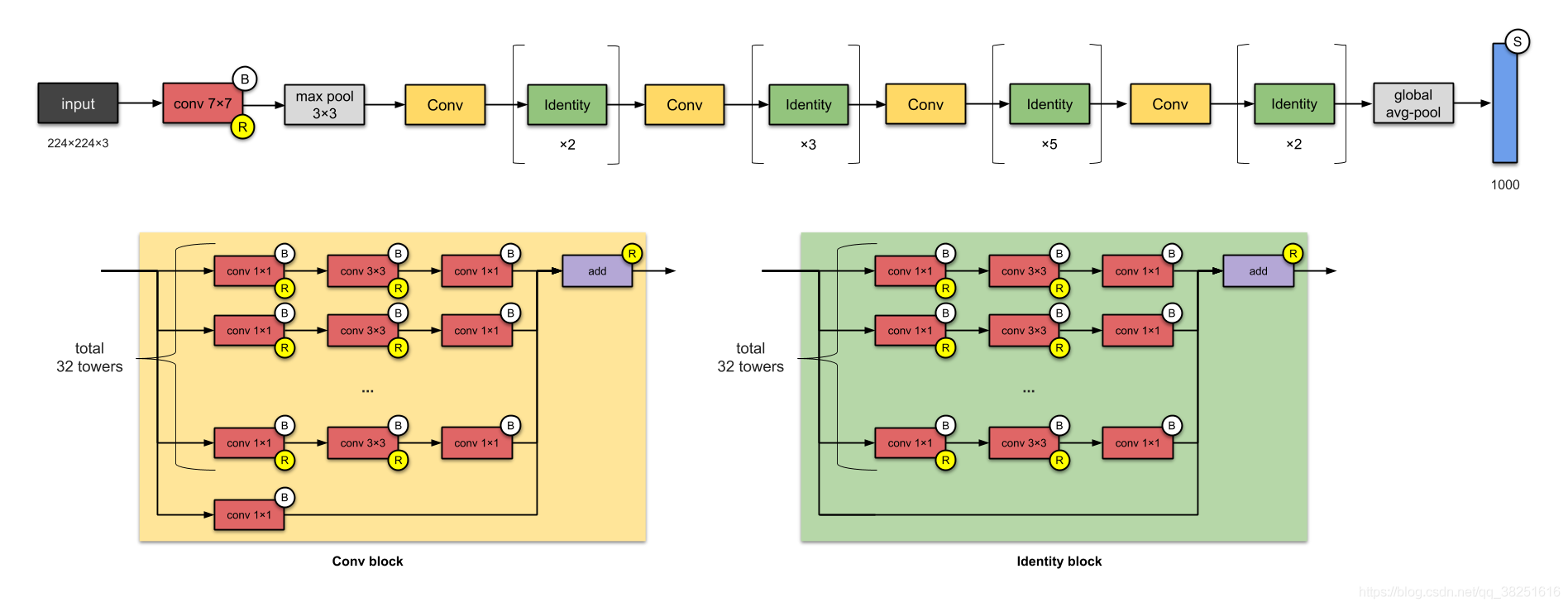
如果您正在考慮 ResNet,是的,它們是相關的,ResNeXt-50 有25M引數(ResNet-50 有 25.5M),ResNeXts 的不同之處在于在每個模塊中添加了平行的塔/分支/路徑,如上所示“總共 32 個塔(total 32 towers)”,
??什么是小說?
- 增加模塊內并行塔的數量(“基數”)(我的意思是 Inception 網路已經對此進行了探索,只是在此處添加了這些塔)
📝刊物
- 論文:Aggregated Residual Transformations for Deep Neural Networks
- 作者:Saining Xie, Ross Girshick, Piotr Dollár, Zhuowen Tu, Kaiming He. University of California San Diego, Facebook Research
- 發表于:2017 IEEE 計算機視覺與模式識別會議 (CVPR)
附錄:網路中的網路(2014)
回想一下,在卷積中,像素的值是過濾器中權重和當前滑動視窗的線性組合,作者提出,讓我們擁有一個帶有 1 個隱藏層的迷你神經網路,而不是這種線性組合,這就是他們創造的 Mlpconv,所以我們在這里處理的是(卷積神經)網路中的(簡單的 1 個隱藏層)網路,
Mlpconv 的這個想法被比作 1×1 卷積,并成為 Inception 架構的主要特征,
??什么是小說?
- MLP 卷積層,1×1 卷積
- 全域平均池化(取每個特征圖的平均值,并將結果向量送入 softmax 層)
📝刊物
- 論文:Network In Network
- 作者:Min Lin, Qiang Chen, Shuicheng Yan. National University of Singapore
- arXiv 預印本,2013
翻譯自:原文地址,有部分刪減及增加,如有不妥之處請聯系我,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/293708.html
標籤:AI
上一篇:機器學習 | 【05】集成學習
下一篇:sql-libs 手工注入步驟