文章目錄
- 一、繼承學習
- 1、簡介
- 2、boosting和Bagging
- 2.1 boosting
- 2.2 Bagging
- 2.3 隨機森林構造程序
- 2.4 boosting與bagging的區別
- 3、API
- 4、GBDT
一、繼承學習
1、簡介
原理:生成
多個分類器/模型,各自獨立學習并做出預測,在將這個預測組合,因此優于任何一個單分類的做出預測,
2、boosting和Bagging
2.1 boosting
- 隨著學習的積累從弱到強,每新加入一個
弱學習器,整體能力就會得到提升;- 解決欠擬合使用
boosting逐步增強學習【弱弱組合變強】;- 代表演算法:
Adaboost、GBDT、XGBoost;
實作程序
- 訓練第一個學習器;
- 調整資料分布【把錯誤資料放大,正確資料縮小】;
- 訓練第二個學習器,進行第二輪;
- 再次調整資料分布【把錯誤資料放大,正確資料縮小】;
AdaBoost構造程序:
- 初始化訓練資料權重相等,訓練第一個學習器;
- 計算該學習器在訓練資料中的錯誤率;
- 計算該學習器的投票權重;
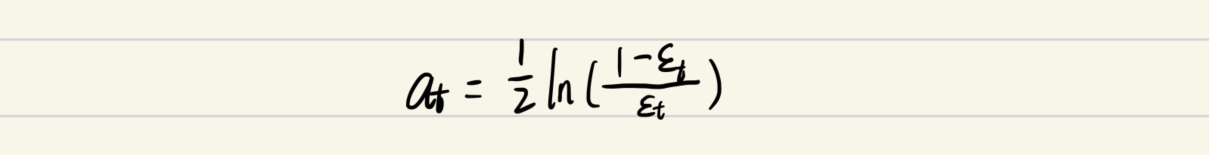
- 根據投票權重對訓練資料重新賦權,并注重錯誤資料;

- 對m個學習器進行加權投票,

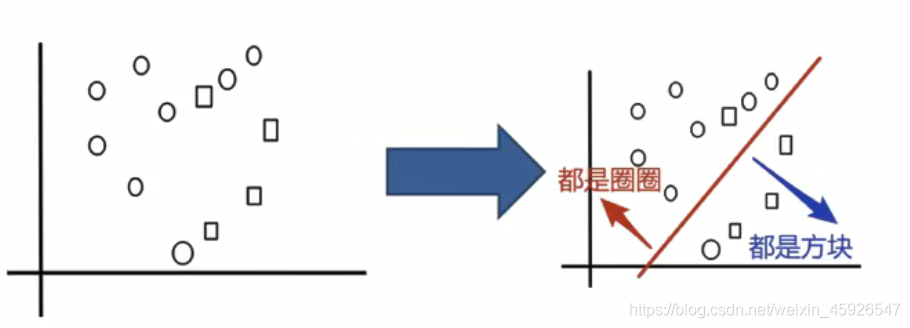
2.2 Bagging
解決過擬合使用
Bagging采樣學習集成【互相扼制變壯】;
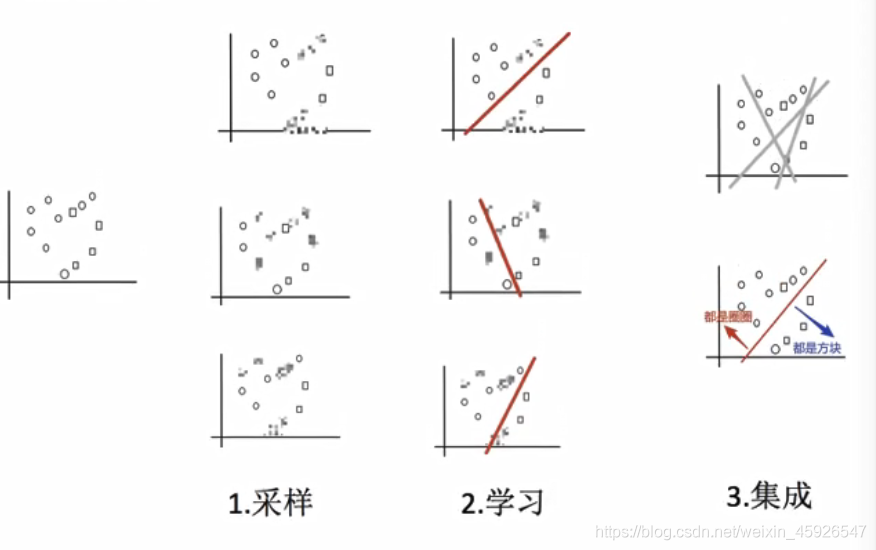
實作程序:
- 采樣:采樣不同資料集;
- 學習:訓練分類器;
- 集成:平權投票,獲取最終結果;
實作程序:
優點:
- 均可在原有演算法上提高約
2%左右的泛化正確率;簡單,方便通用,
2.3 隨機森林構造程序
隨機森林是一個包含
多個決策樹的分類器,并且其輸出的類別是由個別樹輸出的類別的眾數而定,
隨機森林= Bagging +決策樹
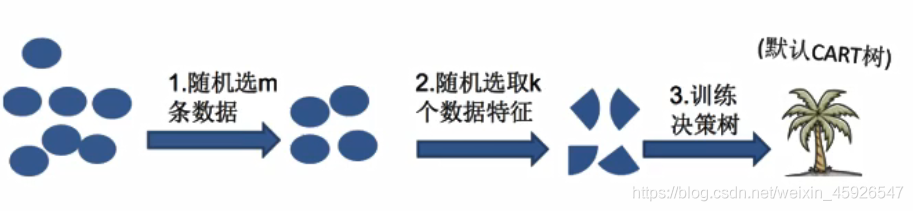
- 4、重復1-3步構造n個決策樹;
- 5、平均投票集成n個弱決策樹,
構造關鍵步驟:
- 一次隨機選出一個樣本,
有放回的抽樣,重復N次(有可能出現重復的樣本),【n為訓練樣本個數,M為特征數目】- 隨機去選出
m個特征,m <<M,建立決策樹,
為什么要隨機抽樣訓練集?
如果不進行隨機抽樣,每棵樹的訓練集都一樣,那么最終訓練出的樹分類結果也是
完全一樣的,
為什么要有放回地抽樣?
保證每個樣本都是等概率,如果
不是有放回抽樣,那么每棵樹的訓練樣本都是不同的,都是沒有交集的,這樣每棵樹訓練出來都是有很大的差異的;而隨機森林最后分類取決于多棵樹(弱分類器)的投票表決,
2.4 boosting與bagging的區別
| boosting | bagging | |
|---|---|---|
| 資料方面 | 權重調整 | 對資料進行采樣訓練 |
| 投票方面 | 對學習器進行加權投票 | 所有學習器平均投票 |
| 學習順序 | 學習是串行,有先后順序 | 學習是并行,每個學習器沒有依賴關系 |
| 主要作用 | 提高訓練精度,解決欠擬合,降低偏差 | 提高泛化性能,解決過擬合,降低方差 |
3、API
sklearn.ensemble.RandomForestClassifier(n_estimators=10, criterion='gini', max_depth=None, bootstrap=True, random_ state=None, min_samples_split=2)
n_estimators:integer, optional (default = 10)森林里的樹木數量;Criterion:string,可選(default ="*gini")分割特征的測量方法;max_depth:integer或None,可選(默認=無)樹的最大深度;max_features="auto":每個決策樹的最大特征數量;
- If"auto", then max_features=sqrt (n_features);
- If “sqrt”, then max_features=sqrt(n_features) (same as “auto”);
- If “log2”, then max_features=log2(n_features);
- If None, then max_features=n_features;
bootstrap:boolean, optional (default = True)是否在構建樹時使用放回抽樣;min_samples_split:節點劃分最少樣本數;min_samples_leaf:葉子節點的最小樣本數;- 引數調優:使用
GridSearchCV進行網格搜索,需要對樹的深度和樹的個數進行調整,
4、GBDT
梯度提升決策樹(GBDT Gradient Boosting Decision Tree)是一種
迭代的決策樹演算法,該演算法由多棵決策樹組成,所有樹的結論累加起來做最終答案,它在被提出之初就被認為是泛化能力(generalization)較強的演算法,近些年更因為被用于搜索排序的機器學習模型而引起大家關注,
GBDT=梯度下降+ Boosting +決策樹
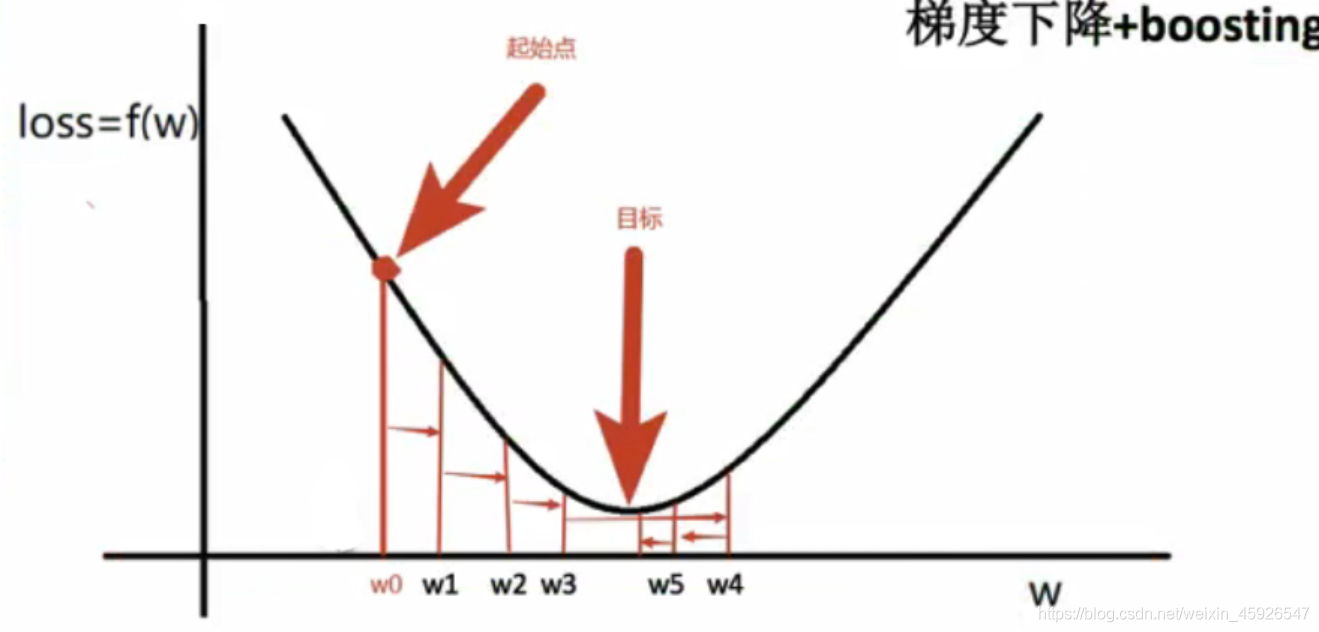
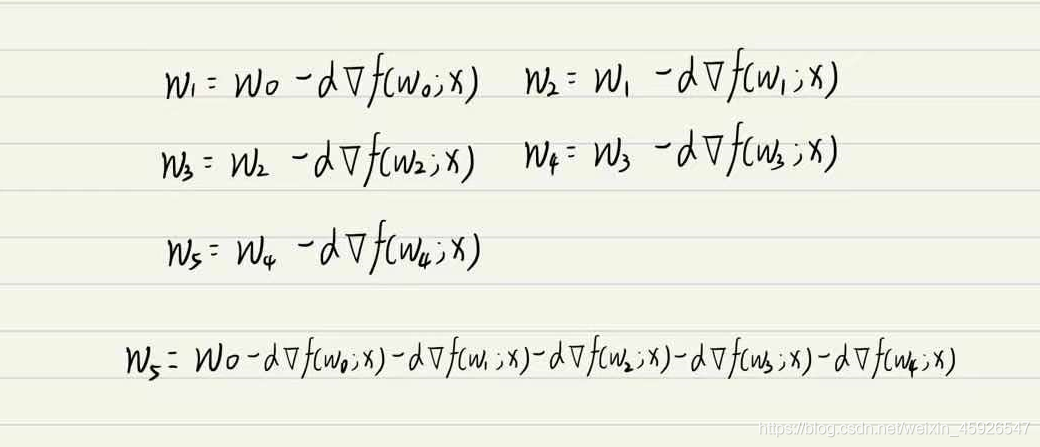
主要執行思想:
- 使用
梯度下降法優化代價函式;- 使用一層決策樹作為弱學習器,負梯度作為目標值;
- 利用
boosting思想進行集成,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/293707.html
標籤:AI
上一篇:【機器人】用Python做一個 “人工智能(障)”機器人 ——不過真的是人工智能嗎?
下一篇:「多圖」圖解10大CNN架構