目錄
- 一、什么是Pandas?
- 二、Pandas的常見資料結構
- 三、生成物件
- 1.Series資料
- 2.DataFrame資料
- 四、查看資料
- 五、獲取資料
- 六、提取資料
- 七、條件篩選
- 八、處理缺失值
- 九、Apple函式
- 十、合并(Merge)
- 1.結合(Concat)
- 2.連接(join)
- 3.追加(Append)
- 十一、分組
- 十二、資料透視表(Pivot Tables)
- 十三、資料可視化
- 十五、資料的輸入與輸出
- 1.寫入CSV檔案
- 2.讀取CSV檔案
最近要到七夕節了,某小學妹竟然找我聊天

結果我一看,原來是問pandas的,那我必須寫一篇關于pandas的教學博客啊!正好可以讓我好好地給小學妹深入的講解一下,,,,,,,
這還說明一個道理,只要你好好學習,一定會有女生來主動找你,這就是技巧,同時也祝兄弟們在七夕來臨之前找到屬于自己的另一半!

下面開始步入正題,我要好好開始講解了!
注意:學資料分析的小白必須要看會,不會的可以問我,😘

一、什么是Pandas?
官方檔案
Pandas 是 Python (opens new window)的核心資料分析支持庫,提供了快速、靈活、明確的資料結構,旨在簡單、直觀地處理關系型、標記型資料,Pandas 的目標是成為 Python 資料分析實踐與實戰的必備高級工具,其長遠目標是成為最強大、最靈活、可以支持任何語言的開源資料分析工具,經過多年不懈的努力,Pandas 離這個目標已經越來越近了,
Pandas 適用于處理以下型別的資料:
- 與 SQL 或 Excel 表類似的,含異構列的表格資料;
- 有序和無序(非固定頻率)的時間序列資料;
- 帶行列標簽的矩陣資料,包括同構或異構型資料;
- 任意其它形式的觀測、統計資料集, 資料轉入 Pandas 資料結構時不必事先標記,
二、Pandas的常見資料結構
| 名稱 | 描述 |
|---|---|
| Series | 帶標簽的一維同構陣列 |
| DataFrame | 帶標簽的,大小可變的,二維異構表格 |
三、生成物件
1.Series資料
**注意:**Pandas默認自動生成整數索引,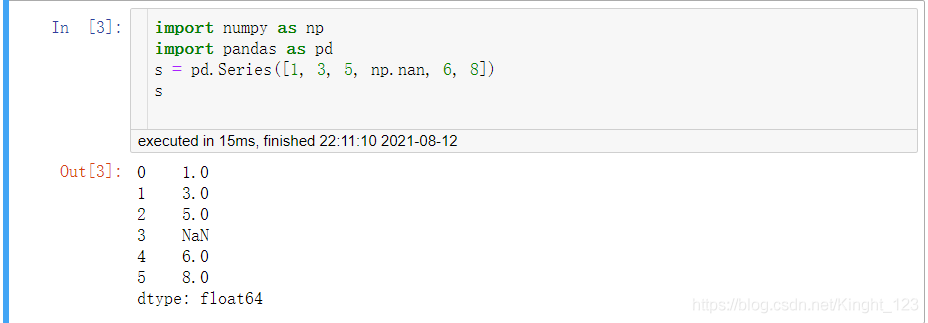
2.DataFrame資料
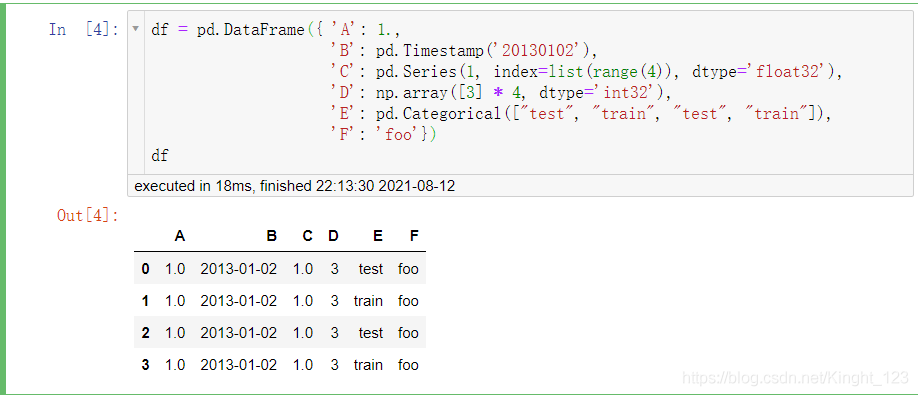
四、查看資料
.head()和.tail()方法
一個是查看頭部的資料,.head()默認查看資料的頭5行;.tail()是查看尾部的資料,默認也是后5行,
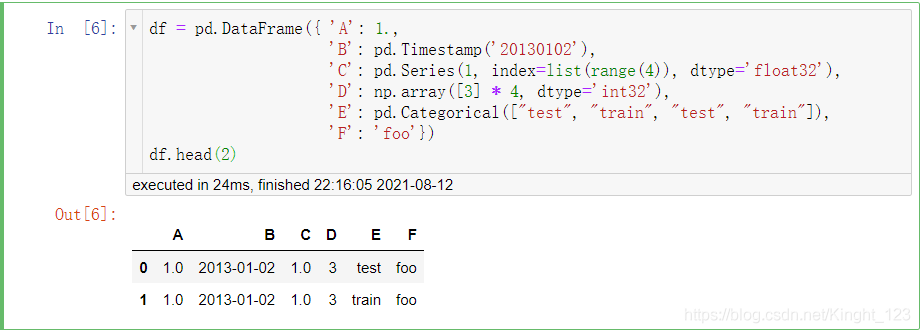
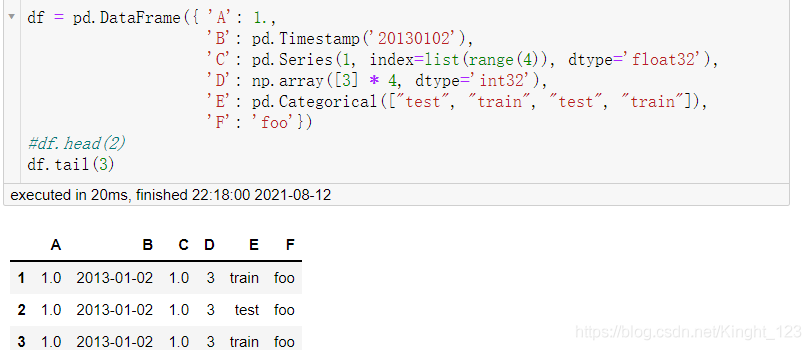
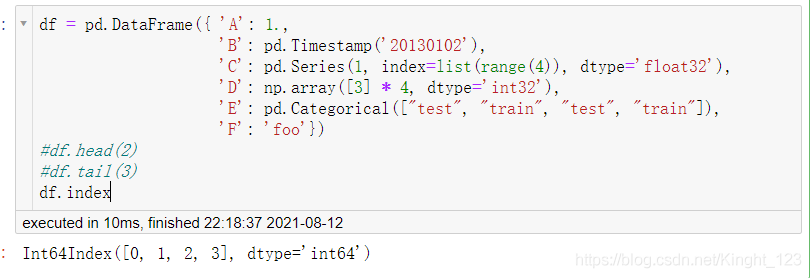
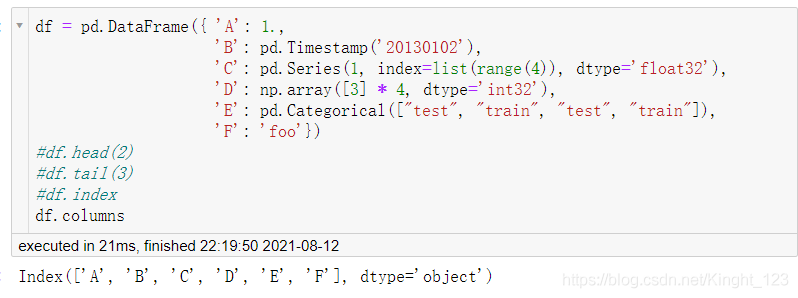
.index和.columns方法
分別用來查看資料的索引和列名,
五、獲取資料
用[]切片
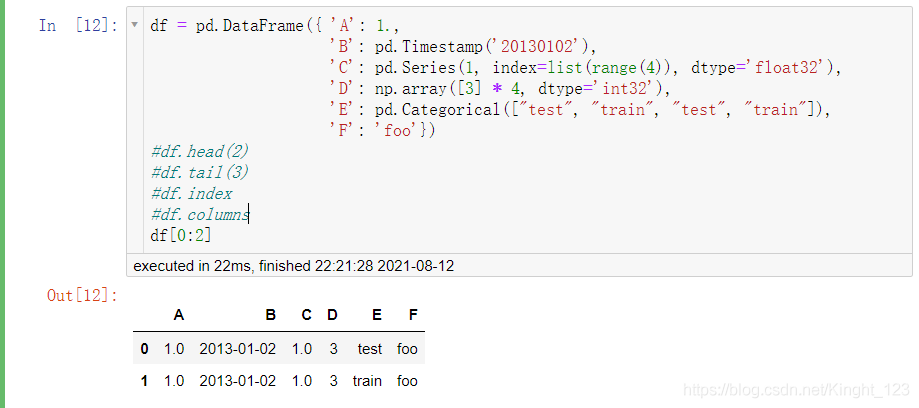
或者直接把想要獲取的資料寫出來,
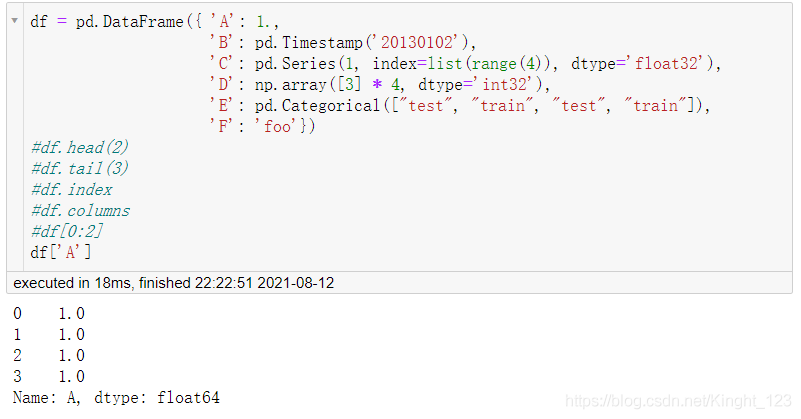
六、提取資料
.loc[]方法
提取特定行資料的方法
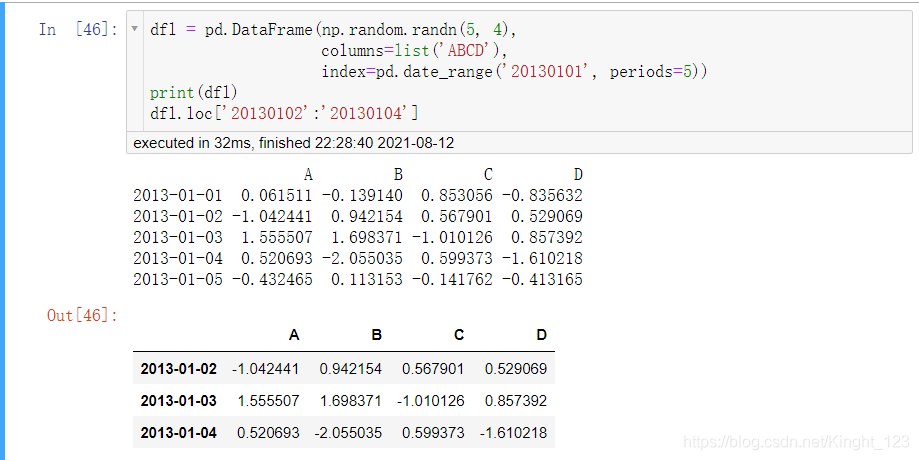
提取多列的資料
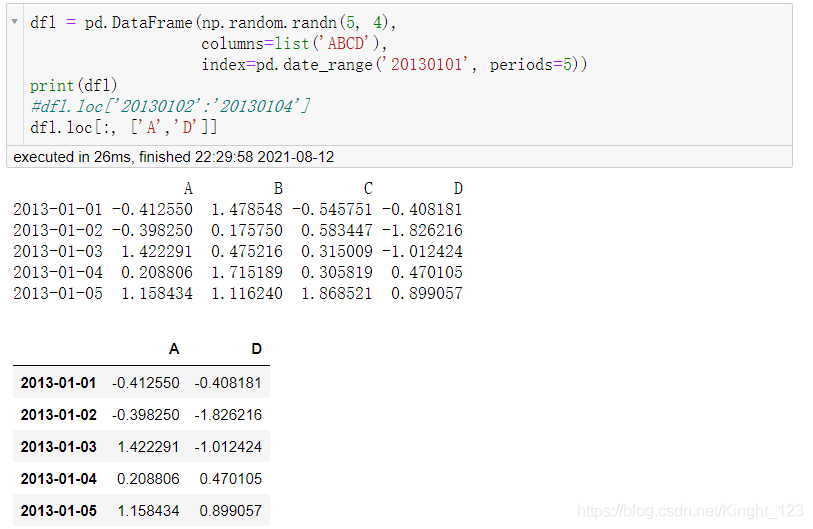
提取具體的資料
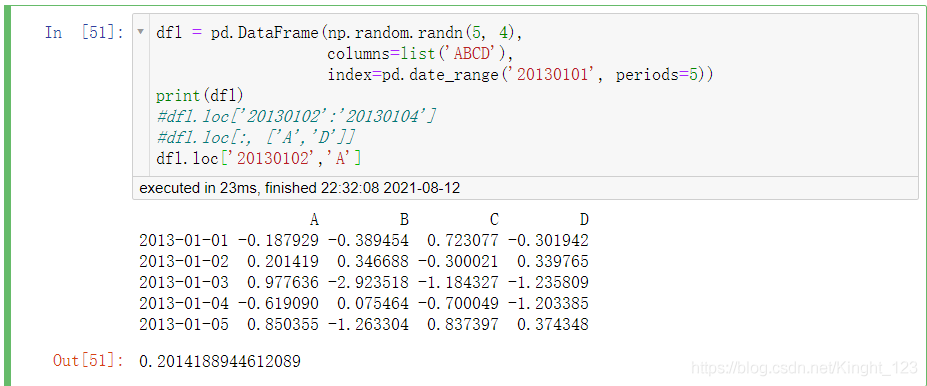
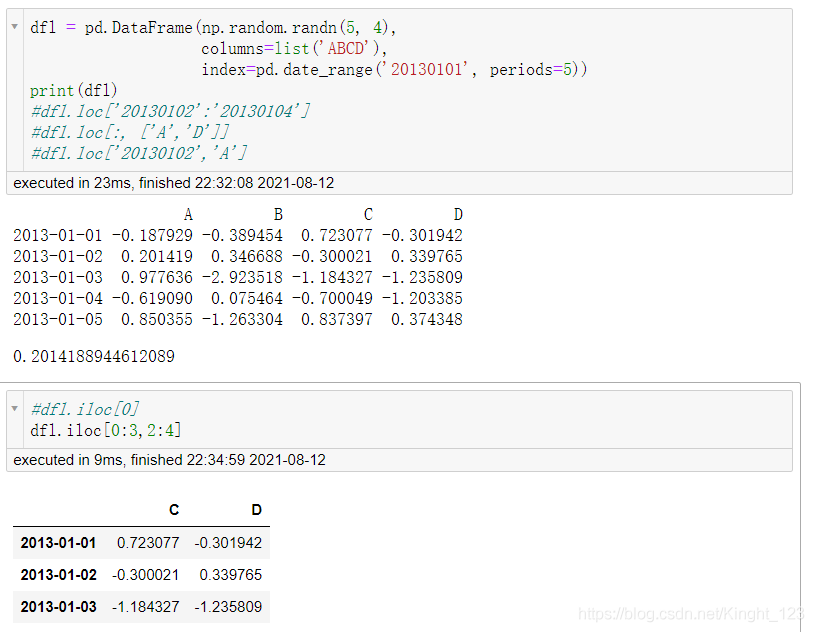
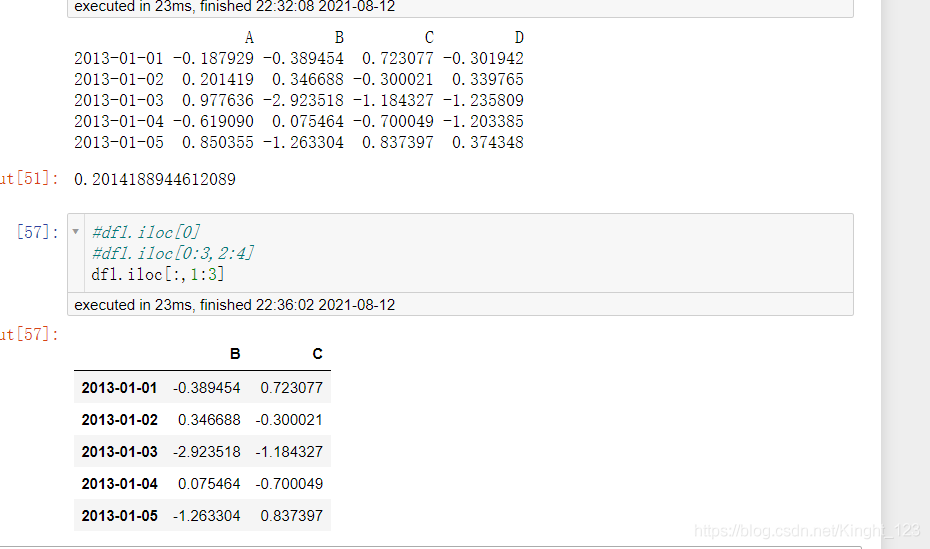
.iloc[]方法
按照行的索引提取資料
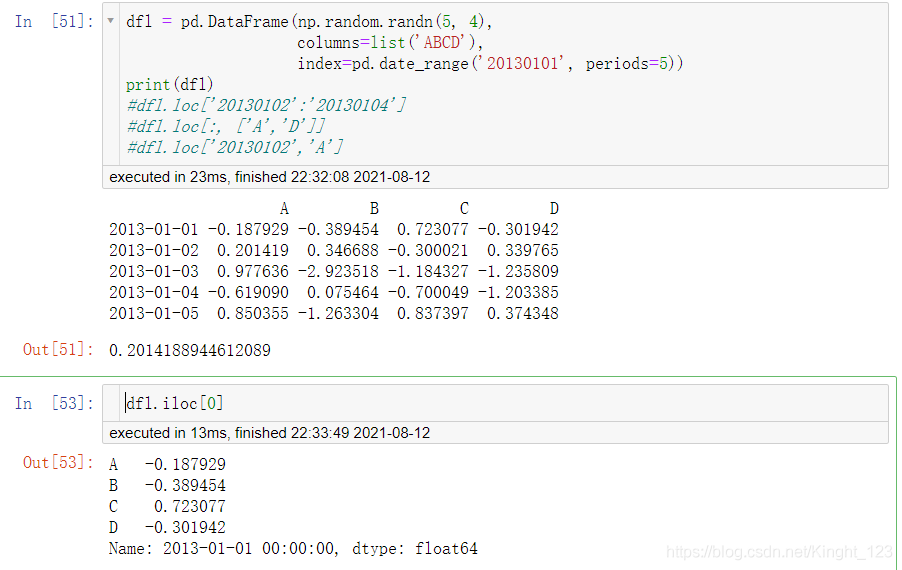
切片處理
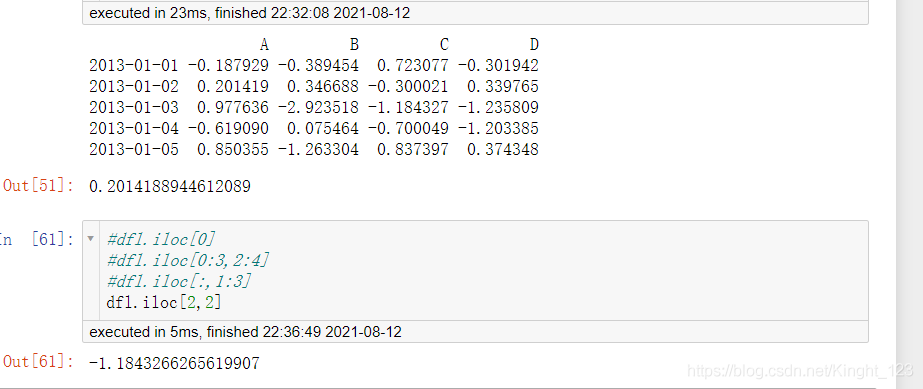
提取特定的資料
七、條件篩選
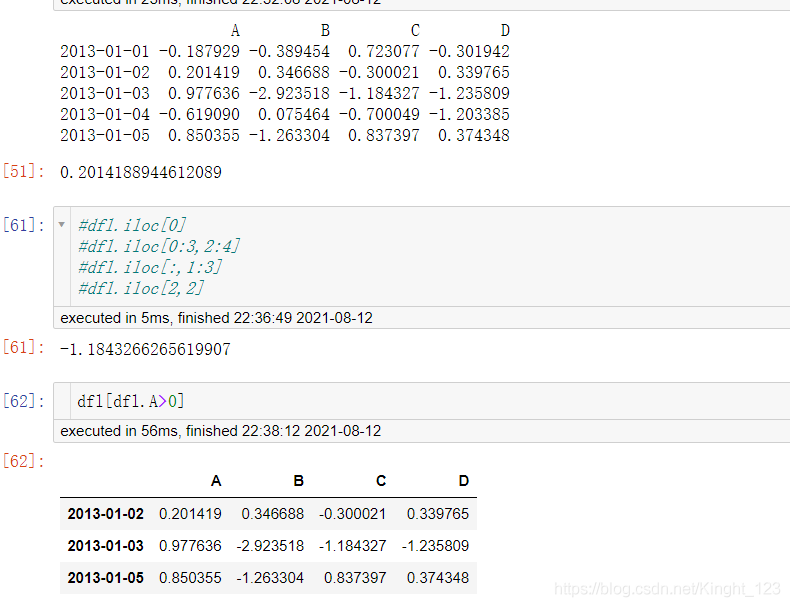
.isin()方法
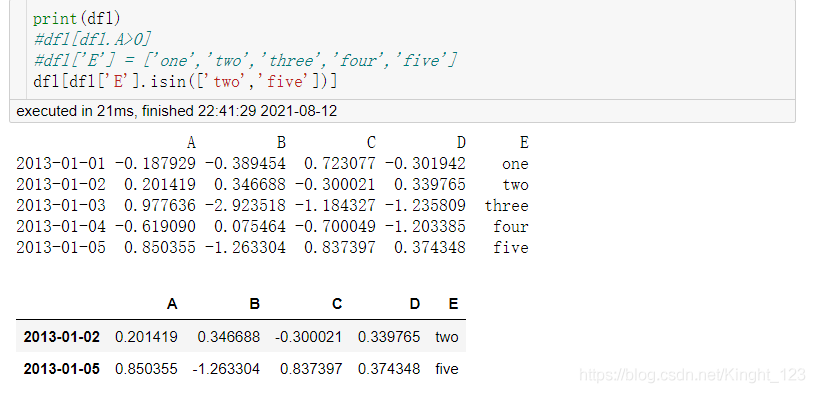
八、處理缺失值
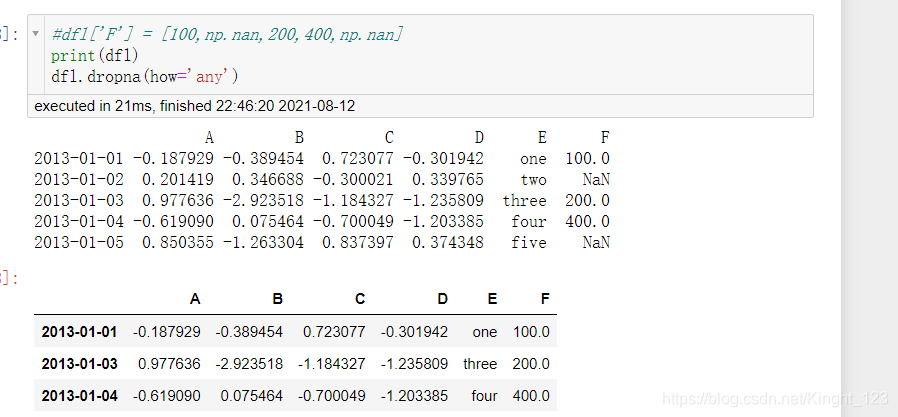
洗掉所有含有缺失值的行
.dropna()函式
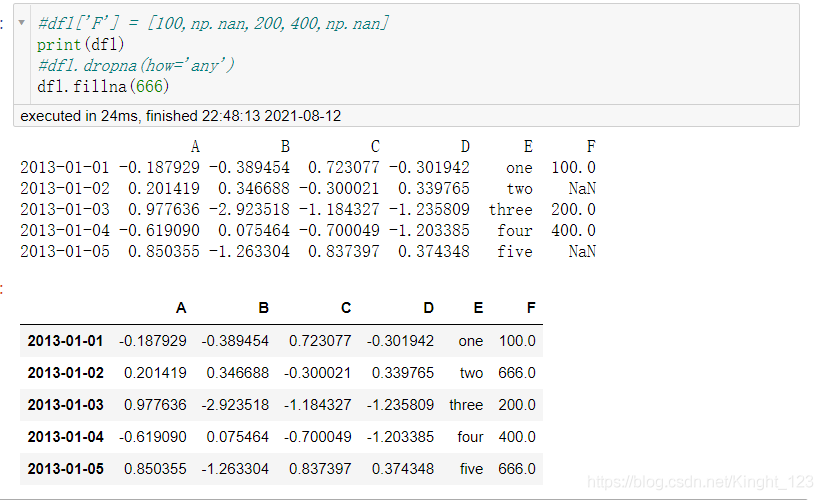
填充缺失值
.fillna()函式
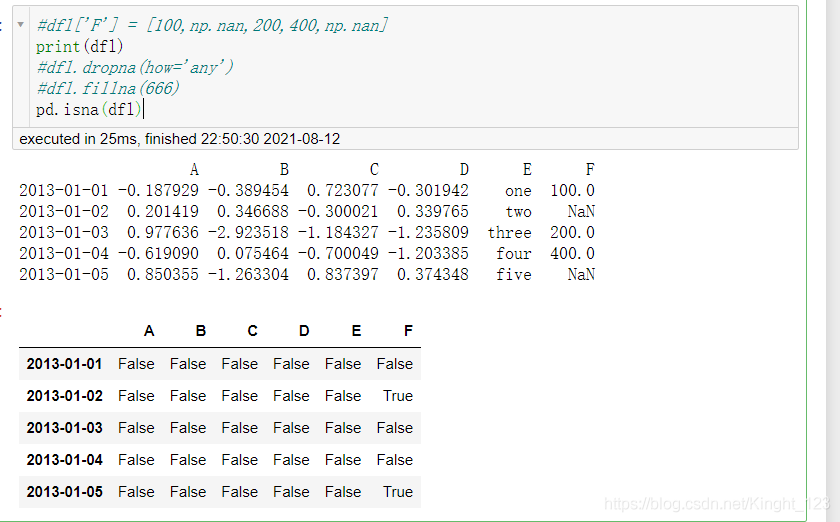
判斷是否為缺失值
pd.isna()函式
九、Apple函式
每行的疊加
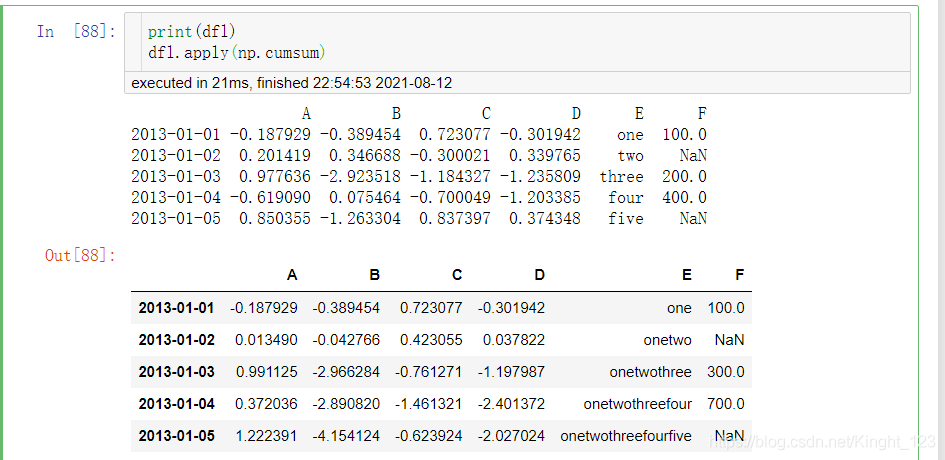
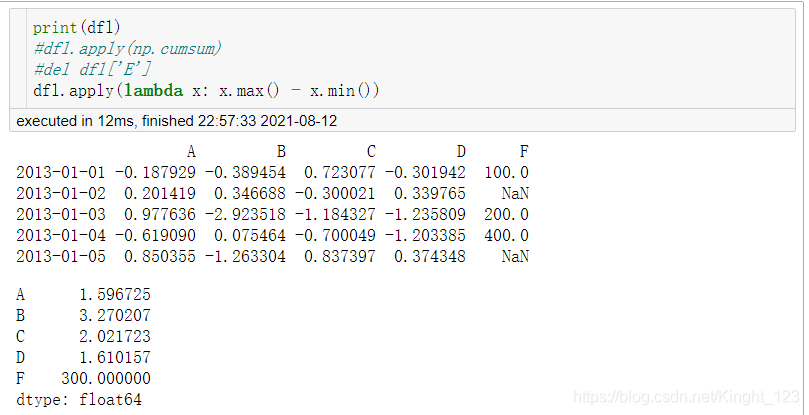
自定義函式:計算每一列的最大值減去最小值
十、合并(Merge)
Pandas 提供了多種將 Series、DataFrame 物件組合在一起的功能,用索引與關聯代數功能的多種設定邏輯可執行連接(join)與合并(merge)操作,
1.結合(Concat)
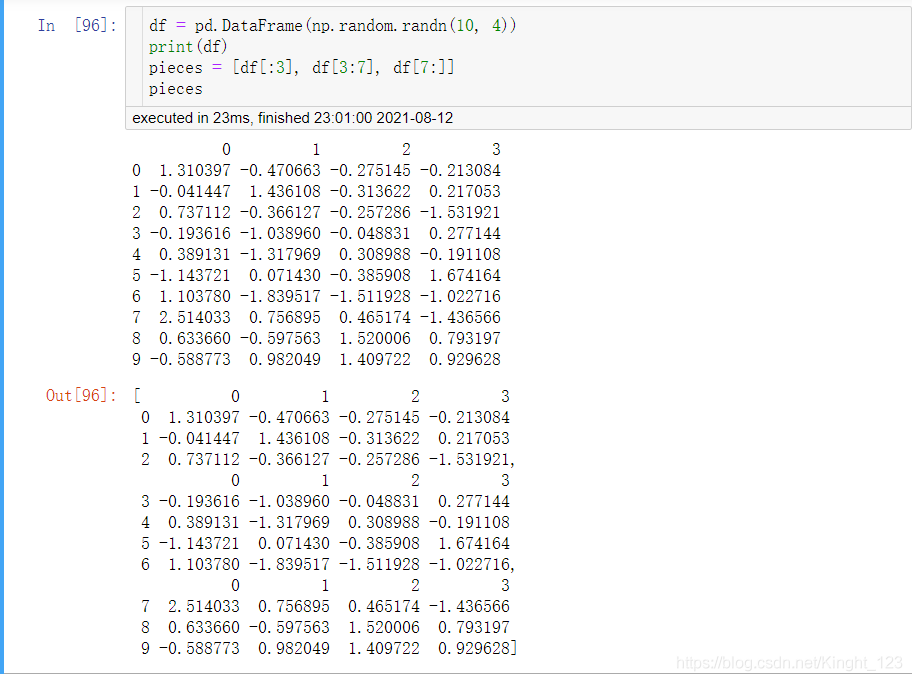
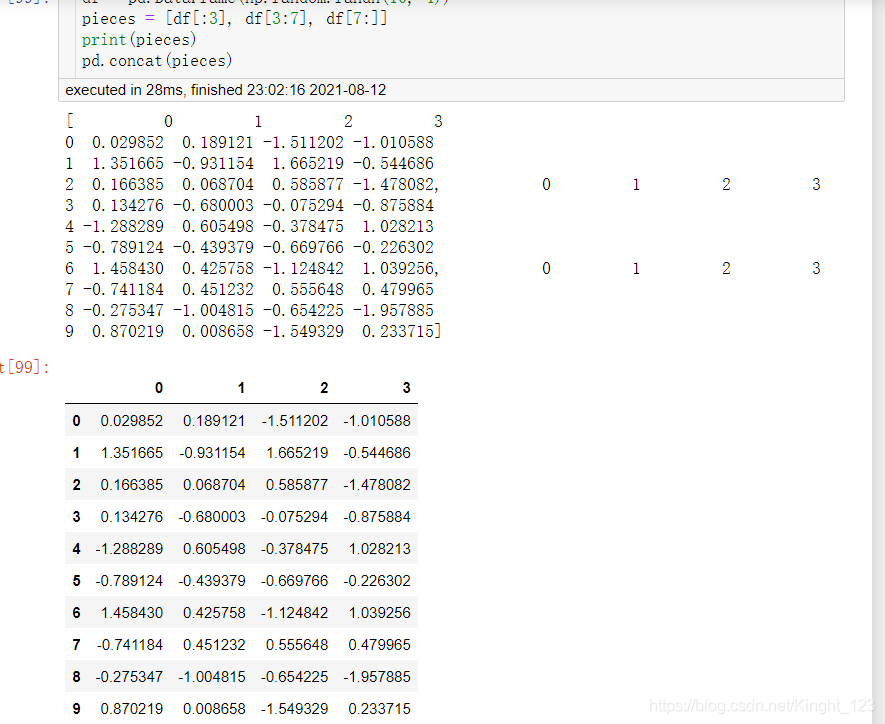
pd.concat()用于連接pandas物件
2.連接(join)
pd.merge()函式
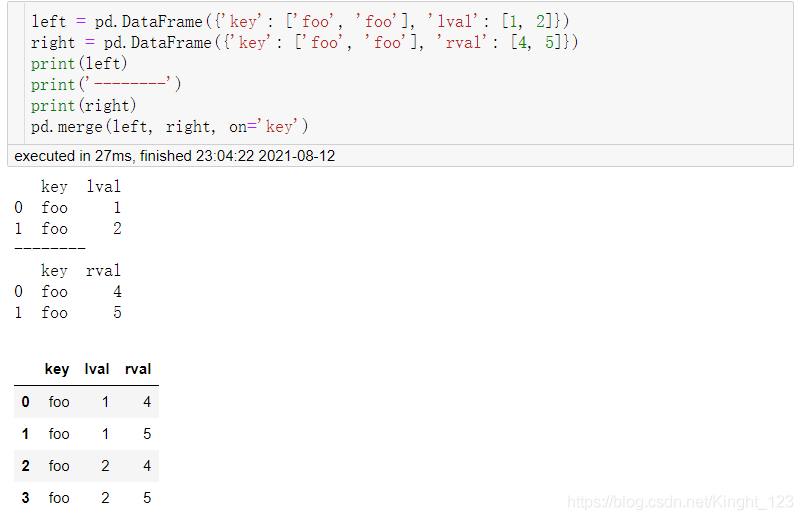
3.追加(Append)
.append()函式
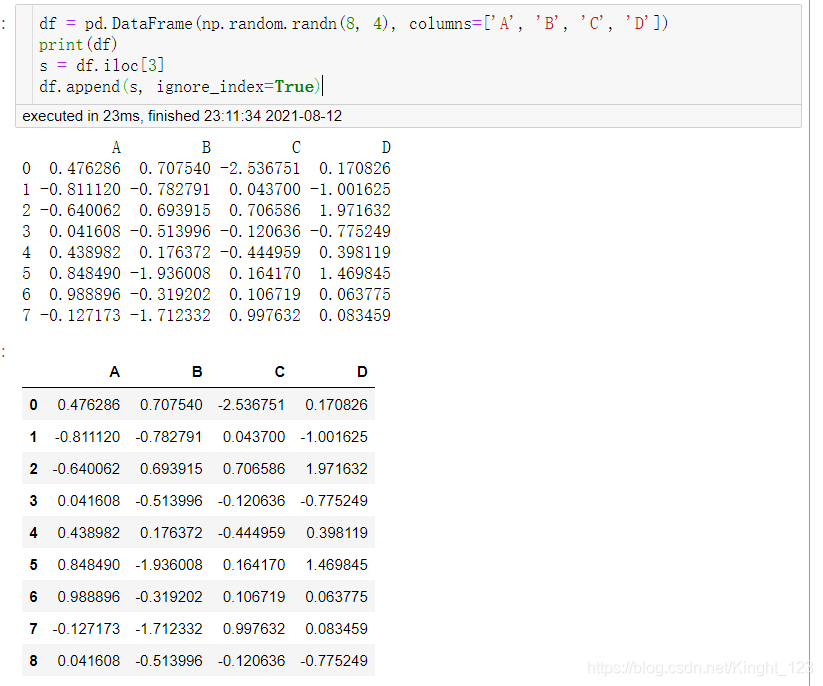
十一、分組
“group by” 指的是涵蓋下列一項或多項步驟的處理流程:
- 分割:按條件把資料分割成多組;
- 應用:為每組單獨應用函式;
- 組合:將處理結果組合成一個資料結構,
.groupby()函式
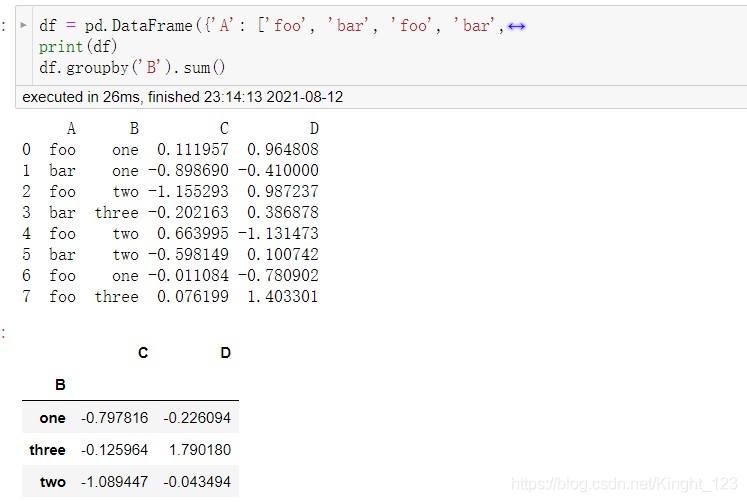
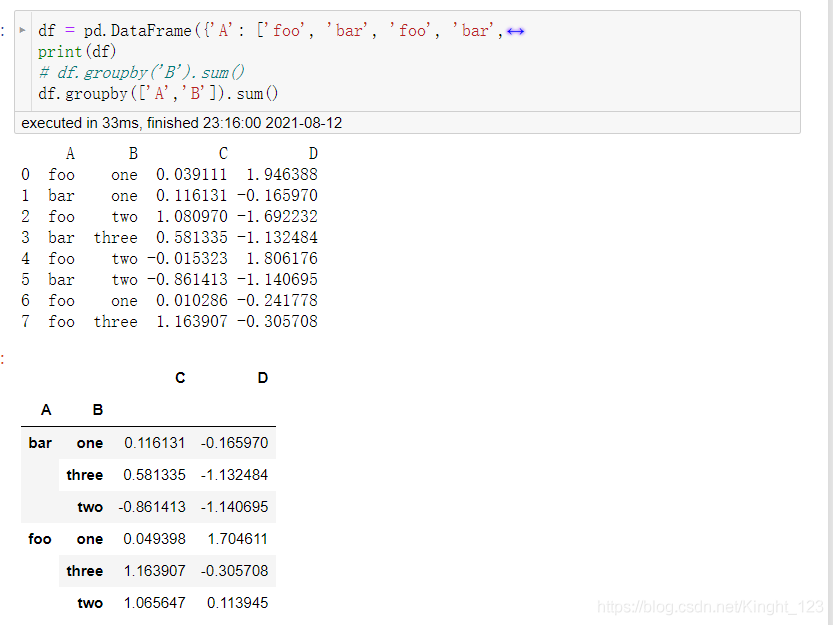
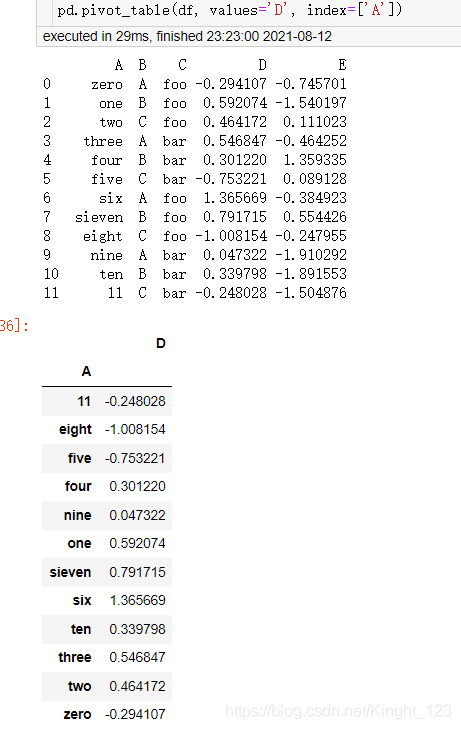
十二、資料透視表(Pivot Tables)
就是把一項資料或者多項資料和另一項資料或者另外多項資料聯系起來,
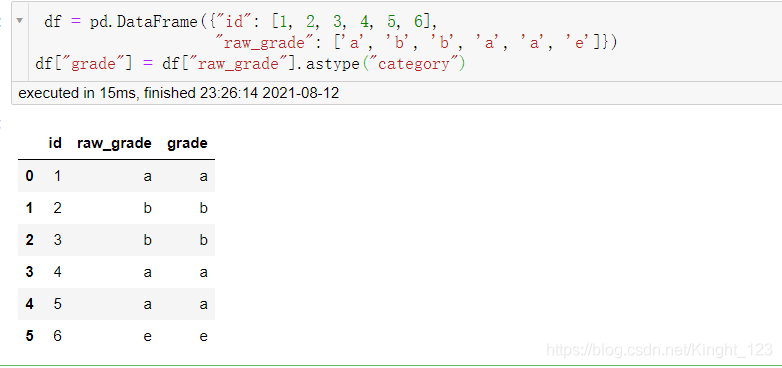
.astype()函式
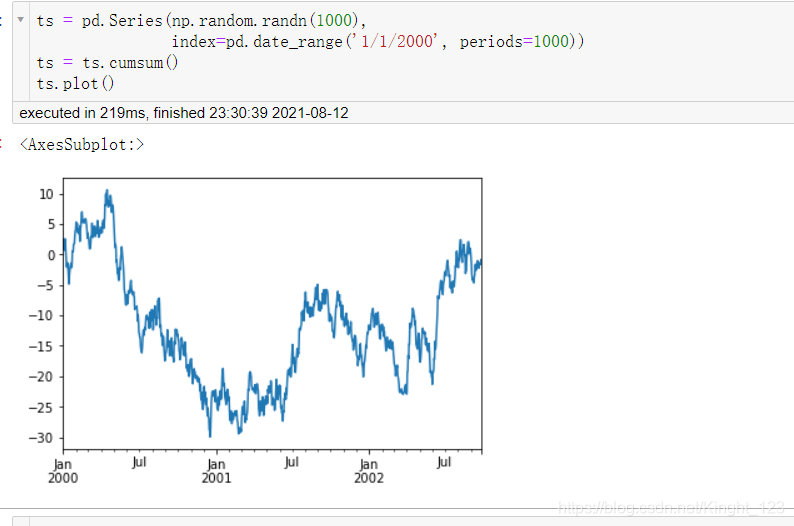
十三、資料可視化
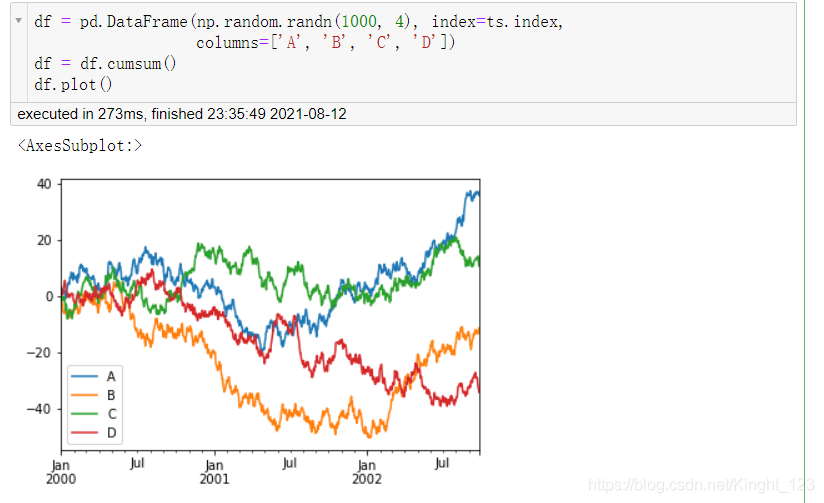
.plot()函式
十五、資料的輸入與輸出
1.寫入CSV檔案
df.to_csv('foo.csv')
2.讀取CSV檔案
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/293730.html
標籤:其他
上一篇:list介紹和基本使用