1、darknet編譯
git clone https://github.com/pjreddie/darknet.gitcd darknet- 修改Makefile
GPU=1 #加GPU
CUDNN=1 #
OPENCV=0 #加opencv
OPENMP=0
DEBUG=0
4、make
有時候make時候會報錯,下面列舉一些遇到的報錯資訊
1、
./src/convolutional_kernels.cu -o obj/convolutional_kernels.o
/bin/sh: 1: nvcc: not found
Makefile:89: recipe for target 'obj/convolutional_kernels.o' failed
make: *** [obj/convolutional_kernels.o] Error 12
上面報錯資訊喝nvcc有關,修改Makefile如下:
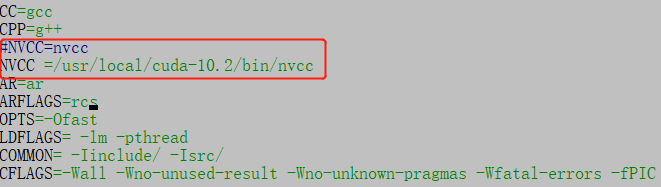
NVCC為自己安裝cuda時候的位置,
2、
./src/image_opencv.cpp:12:1: error: ‘IplImage’ 報錯
以前安裝的是opencv3系列的沒有出現上述問題,當安裝opencv4系列的就會遇到上述問題,主要是因為在opencv安裝時候3系列和4系列會有些不同,
opencv4安裝:
加入依賴:
sudo apt-get install build-essential
sudo apt-get install cmake git libgtk2.0-dev pkg-config libavcodec-dev libavformat-dev libswscale-dev
cmake -D CMAKE_BUILD_TYPE=Release -D CMAKE_INSTALL_PREFIX=/usr/local/myself_path -D OPENCV_GENERATE_PKGCONFIG=ON
重點:OPENCV_GENERATE_PKGCONFIG=ON,這樣在/usr/local/myself_path/lib能生成opencv4.pc檔案,
sudo cp /usr/local/lib/pkgconfig/opencv4.pc /usr/lib/pkgconfig
sudo mv /usr/lib/pkgconfig/opencv4.pc /usr/lib/pkgconfig/opencv.pc
make -j8
sudo make install
將opencv4.pc 改成opencv.pc,否則make時候會找不到opencv
重點:配置opencv的環境變數
sudo vim /etc/ld.so.conf.d/opencv.conf
輸入/usr/local/myself_path
sudo vim /etc/profile
在末尾加入:
export PKG_CONFIG_PATH=/usr/local/lib/pkgconfig:$PKG_CONFIG_PATH
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/myself_path/lib
更新環境變數:sudo source /etc/profile
sudo vim /etc/bash.bashrc
export PKG_CONFIG_PATH=$PKG_CONFIG_PATH:/usr/local/lib/pkgconfig
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/myself_path/lib
更新環境變數:sudo source ~/.bashrc
更新系統快取:sudo ldconfig
opencv安裝完成后修改darknet原始碼:
cd darknet/src
vim image_opencv.cpp
附上完整代碼,替換就好
#ifdef OPENCV
#include "stdio.h"
#include "stdlib.h"
#include "opencv2/opencv.hpp"
#include "image.h"
using namespace cv;
extern "C" {
Mat image_to_mat(image im)
{
image copy = copy_image(im);
constrain_image(copy);
if(im.c == 3) rgbgr_image(copy);
Mat m(cv::Size(im.w,im.h), CV_8UC(im.c));
int x,y,c;
int step = m.step;
for(y = 0; y < im.h; ++y){
for(x = 0; x < im.w; ++x){
for(c= 0; c < im.c; ++c){
float val = im.data[c*im.h*im.w + y*im.w + x];
m.data[y*step + x*im.c + c] = (unsigned char)(val*255);
}
}
}
free_image(copy);
return m;
}
image mat_to_image(Mat m)
{
int h = m.rows;
int w = m.cols;
int c = m.channels();
image im = make_image(w, h, c);
unsigned char *data = (unsigned char *)m.data;
int step = m.step;
int i, j, k;
for(i = 0; i < h; ++i){
for(k= 0; k < c; ++k){
for(j = 0; j < w; ++j){
im.data[k*w*h + i*w + j] = data[i*step + j*c + k]/255.;
}
}
}
rgbgr_image(im);
return im;
}
void *open_video_stream(const char *f, int c, int w, int h, int fps)
{
VideoCapture *cap;
if(f) cap = new VideoCapture(f);
else cap = new VideoCapture(c);
if(!cap->isOpened()) return 0;
if(w) cap->set(CAP_PROP_FRAME_WIDTH, w);
if(h) cap->set(CAP_PROP_FRAME_HEIGHT, w);
if(fps) cap->set(CAP_PROP_FPS, w);
return (void *) cap;
}
image get_image_from_stream(void *p)
{
VideoCapture *cap = (VideoCapture *)p;
Mat m;
*cap >> m;
if(m.empty()) return make_empty_image(0,0,0);
return mat_to_image(m);
}
image load_image_cv(char *filename, int channels)
{
int flag = -1;
if (channels == 0) flag = -1;
else if (channels == 1) flag = 0;
else if (channels == 3) flag = 1;
else {
fprintf(stderr, "OpenCV can't force load with %d channels\n", channels);
}
Mat m;
m = imread(filename, flag);
if(!m.data){
fprintf(stderr, "Cannot load image \"%s\"\n", filename);
char buff[256];
sprintf(buff, "echo %s >> bad.list", filename);
system(buff);
return make_image(10,10,3);
//exit(0);
}
image im = mat_to_image(m);
return im;
}
int show_image_cv(image im, const char* name, int ms)
{
Mat m = image_to_mat(im);
imshow(name, m);
int c = waitKey(ms);
if (c != -1) c = c%256;
return c;
}
void make_window(char *name, int w, int h, int fullscreen)
{
namedWindow(name, WINDOW_NORMAL);
if (fullscreen) {
setWindowProperty(name, WND_PROP_FULLSCREEN, WINDOW_FULLSCREEN);
} else {
resizeWindow(name, w, h);
if(strcmp(name, "Demo") == 0) moveWindow(name, 0, 0);
}
}
}
#endif
通過上述方法來解決./src/image_opencv.cpp:12:1: error: ‘IplImage’ 報錯問題
2、darknet訓練自己資料集
在darknet檔案夾下創建自己的資料集myData
/darknet/$mkdir myData
在myData檔案夾下創建三個檔案夾:
其中annotations下存放xml檔案(自己標注的格式是xml格式)
JPEGImages下存放標注的影像
在ImageSets下創建Main檔案夾存放影像的名字(.txt)
腳本代碼:
import os
src_path = "/darknet/myData/annotations/"
img_path = os.listdir(src_path)
save_path = "/darknet/myData/ImageSets/Main/train.txt"
for img_path1 in img_path:
if img_path1[-4:] == ".xml":
img_path_txt = img_path1[:-4]
with open(save_path,"a+") as f:
f.write(img_path_txt + "\n")
將xml格式轉換為darknet需要的格式,利用darknet/scripts檔案夾下的voc_label.py,代碼需要更改一下
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets=[('myData', 'train'), ('myData', 'val')] #替換為自己的資料集
classes = ["class1", "class2", "class3"] #修改為自己的類別
def convert(size, box):
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_id):
in_file = open('myData/annotations/%s.xml'%(image_id)) #將資料集放于當前目錄下
out_file = open('myData/labels/%s.txt'%(image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('myData/labels/'):
os.makedirs('myData/labels/')
image_ids = open('myData/ImageSets/Main/%s.txt'%(image_set)).read().strip().split()
list_file = open('myData/%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/myData/JPEGImages/%s.jpg\n'%(wd,image_id))
convert_annotation(year, image_id)
list_file.close()
#os.system("cat 2007_train.txt 2007_val.txt > train.txt") #修改為自己的資料集用作訓練
添加voc.data,目前將voc.data和voc.names 存放在mydata下
classes= 3 #修改為自己的類別數
train = /darknet/myData/myData_train.txt
valid = /darknet/myData/myData_val.txt
names = /darknet/myData/voc.names
backup = /darknet/backup
添加voc.names
class1
class2
class3
在/darknet下下載預權重
/darknet/$ wget https://pjreddie.com/media/files/darknet53.conv.74
修改cfg/yolov3-voc.cfg
[net]
# Testing
batch=64
subdivisions=32 #每批訓練的個數=batch/subvisions,根據自己GPU顯存進行修改,顯存不夠改大一些
# Training
# batch=64
# subdivisions=16
width=416
height=416
channels=3
momentum=0.9
decay=0.0005
angle=0
saturation = 1.5
exposure = 1.5
hue=.1
learning_rate=0.001
burn_in=1000
max_batches = 50200 #訓練步數
policy=steps
steps=40000,45000 #開始衰減的步數
scales=.1,.1
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
.....
[convolutional]
size=1
stride=1
pad=1
filters=24 #filters = 3 * ( classes + 5 ) here,filters=3*(3+5)
activation=linear
[yolo]
mask = 6,7,8
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=3 #修改為自己的類別數
num=9
jitter=.3
ignore_thresh = .5
truth_thresh = 1
random=1
[route]
layers = -4
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[upsample]
stride=2
[route]
layers = -1, 61
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=512
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=512
activation=leaky
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=512
activation=leaky
[convolutional]
size=1
stride=1
pad=1
filters=24 #filters = 3 * ( classes + 5 ) here,filters=3*(3+5)
activation=linear
[yolo]
mask = 3,4,5
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=3 #修改為自己的類別數
num=9
jitter=.3
ignore_thresh = .5
truth_thresh = 1
random=1
[route]
layers = -4
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[upsample]
stride=2
[route]
layers = -1, 36
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=256
activation=leaky
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=256
activation=leaky
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
size=3
stride=1
pad=1
filters=256
activation=leaky
[convolutional]
size=1
stride=1
pad=1
filters=24 #filters = 3 * ( classes + 5 ) here,filters=3*(3+5)
activation=linear
[yolo]
mask = 0,1,2
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=3 #修改為自己的類別數
num=9
jitter=.3
ignore_thresh = .5
truth_thresh = 1
random=1
訓練模型:
./darknet detector train myData/voc.data myData/yolov3-voc.cfg darknet53.conv.74 2>&1 | tee logs/train_yolov3.log
2>&1 | tee logs/train_yolov3.log:保存訓練log,如果多GPU的話,在末尾加入-gpus 0,1,2
訓練完模型,測驗命令
/darknet detector test myData/voc.data myData/yolov3-voc.cfg backup/yolov3-voc_20000.weights test.jpg
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/293839.html
標籤:其他