文章目錄
- 寫在前面
- 環境
- 網頁分析
- 爬蟲代碼實作及說明
寫在前面
很久之前就萌生了想爬取王者榮耀英雄臺詞語音,因為語音資源不是很好找,從官網獲得的話,也比較麻煩,最近剛好有朋友需要語音素材,于是我就順便幫了他一把,
完成這次爬蟲,前前后后大概花了8個小時左右,用了之前沒用到的庫,和一些函式用法,導致bug,以至于花費時間來解決,而且因為自己過于盲目地爬取,一開始沒有具體分析,到后來慢慢完善,總共寫了三個版本,通過這次的練習,自己也有些許識訓,
第一個版本,寫一半發現,爬取失敗;
第二個版本,能夠順利爬取語音及相關文本,但是不夠全面;
第三個版本,順利地爬取了全部語音及相關文本,并進行合理地合成,方便欣賞,
本文主要介紹第三個版本,
環境
- python3.9
- pycharm
網頁分析
首先來到含有英雄全部語音的頁面
https://pvp.qq.com/story201904/index.html#/voice?id=144
進入網頁后,進行檢查,如下圖,找到data_zlk_lb.json這個檔案,可以很清晰的見到想要爬取的臺詞語音及相關的文本,
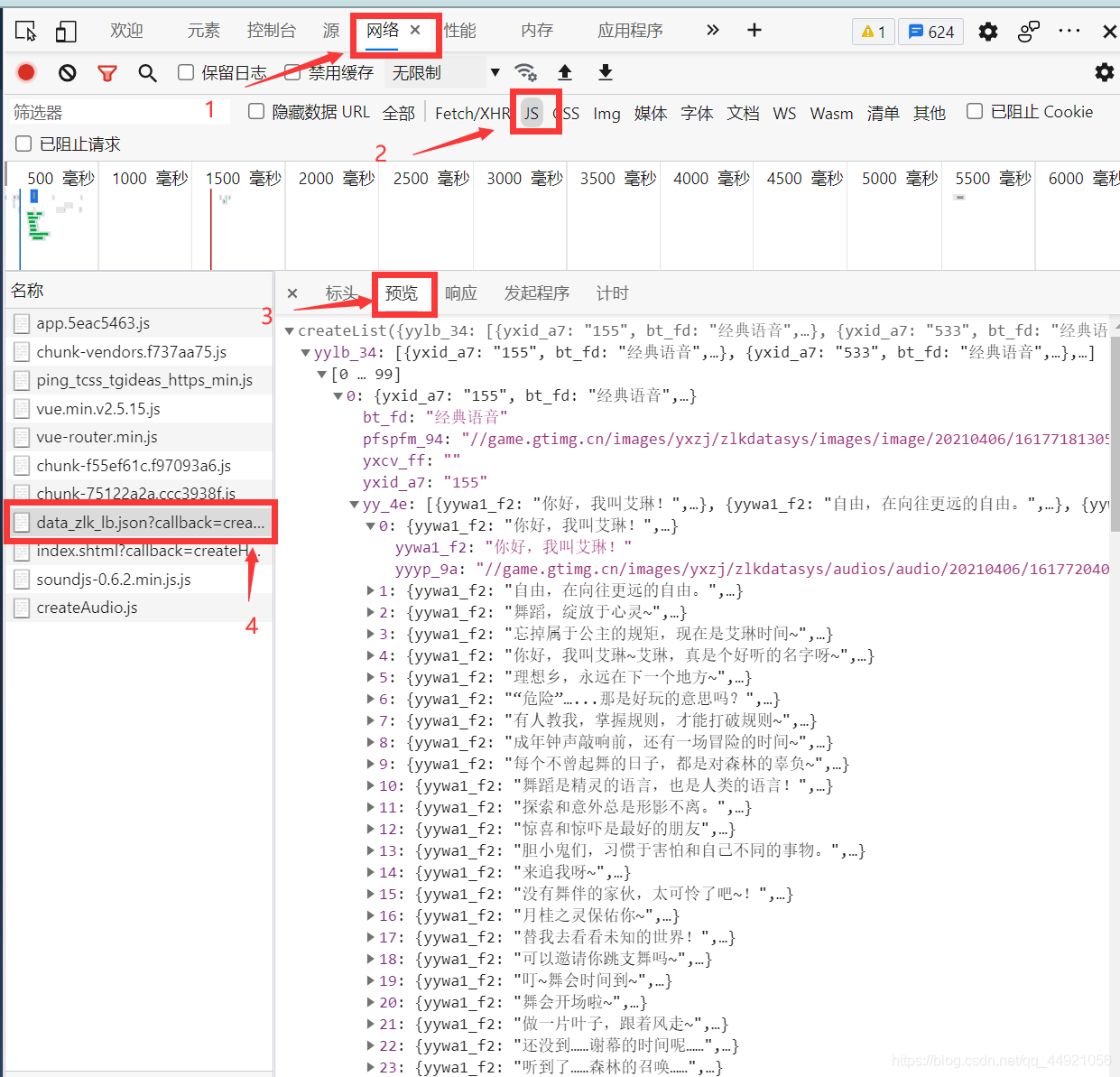
切換到標頭,即可找到需要的URL
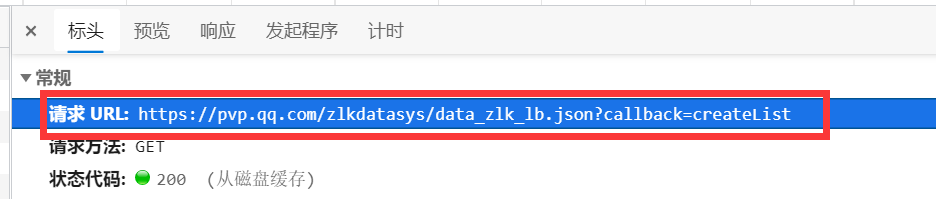
到這,目標一就找到了,
- 如:取一個語音的MP3檔案鏈接,做演示
//game.gtimg.cn/images/yxzj/zlkdatasys/audios/audio/20210406/16177204029921.mp3
這八秒的語音對應的臺詞就是:你好,我叫艾琳!
有了目標一,是不是有小伙伴想問,難道還有目標二?
當然!因為在這個頁面,除了這些,我們最多還能得到的是聲優的資訊,和英雄的編號,得不到英雄的名稱,不方便最后檔案的命名,
為了提高最后檔案的可讀性,最好能夠臺詞與英雄名相匹配,
匹配的關鍵橋梁就是,英雄編號!
可以來到第二個詳情頁:英雄資料頁面
https://pvp.qq.com/web201605/herolist.shtml
其實,我之前有寫過一篇關于這個頁面的內容爬取,可以參考一下:
python爬取王者榮耀英雄的背景故事
這樣就完成了目標二,
更多的思路體現在代碼的注釋中
爬蟲代碼實作及說明
# -*- coding: UTF-8 -*-
"""
# @Time: 2021/8/10 12:13
# @Author: 遠方的星
# @CSDN: https://blog.csdn.net/qq_44921056
"""
import os
import re
import json
import requests
import chardet
from pydub import AudioSegment
from fake_useragent import UserAgent
# 隨機產生請求頭
ua = UserAgent(verify_ssl=False, path='D:/Pycharm/fake_useragent.json')
# 提前創建一個檔案夾,方便創建子檔案夾
path_f = "./王者語音"
if not os.path.exists(path_f):
os.mkdir(path_f)
# 隨機切換請求頭
def random_ua():
headers = {
"accept-encoding": "gzip", # gzip壓縮編碼 能提高傳輸檔案速率
"user-agent": ua.random
}
return headers
# 創建檔案夾
def path_creat(name):
_path = "./王者語音/{}/".format(name)
if not os.path.exists(_path):
os.mkdir(_path)
return _path
# 下載語音內容
def download(file_name, text, path): # 下載函式
file_path = path + file_name
with open(file_path, 'wb') as f:
f.write(text)
f.close()
# 獲取英雄名稱及對應編號
def get_hero_num():
url = 'https://pvp.qq.com/web201605/js/herolist.json'
response = requests.get(url=url, headers=random_ua()).text
hero_list = re.findall('"ename": (.+?),', response, re.S) # 得到英雄的編號串列
hero_name = re.findall('"cname": "(.+?)"', response, re.S) # 得到英雄的名字串列
return hero_list, hero_name
def text_json():
url = 'https://pvp.qq.com/zlkdatasys/data_zlk_lb.json'
param = {
'callback': 'createList'
}
res = requests.get(url=url, headers=random_ua(), params=param)
res.encoding = chardet.detect(res.content)['encoding']
res = res.text.replace('createList(', '').replace(')', '') # 去掉不符合json格式的部分字串資料
res_json = json.loads(res) # 將字串json格式化
hero = res_json["yylb_34"] # 所有英雄語音資訊
return hero
# 處理臺詞文本
def text_deal(text):
text_result = '' # 為臺詞連接做準備
for j in range(len(text)):
text_result += text[j] # 將臺詞連起來
text_result += '\n\n' # 加一個斷句的換行符
text_result = text_result.encode(encoding='utf-8')
return text_result
def main():
hero_list, hero_name = get_hero_num() # 獲取英雄編號及名稱
hero_s = text_json()
for i in range(len(hero_s)): # len(hero_s)
hero = hero_s[i]["yxid_a7"] # 英雄編號
hero_index = hero_list.index(hero) # 獲取英雄名稱對應的索引
name_result = hero_name[hero_index] # 確定英雄名稱
path = path_creat(name_result) # 創建子檔案夾
voice_list = hero_s[i]["yy_4e"] # 語音串列
num = 1
text = []
silence = AudioSegment.silent(duration=1000) # 1秒的空期
try: # 有部分英雄的語音合成會失敗
for j in range(len(voice_list)):
voice_text = voice_list[j]["yywa1_f2"] # 語音文本
text.append(voice_text) # 拼接文本
voice_url = 'http:' + voice_list[j]["yyyp_9a"] # 語音mp3的url
voice = requests.get(url=voice_url, headers=random_ua()).content
voice_name = name_result + '{}.mp3'.format(num)
download(voice_name, voice, path) # 下載單個語音
sound = AudioSegment.from_file(path + voice_name, format="mp3") # 讀取下載的MP3檔案
silence += sound # 語音合成
num += 1
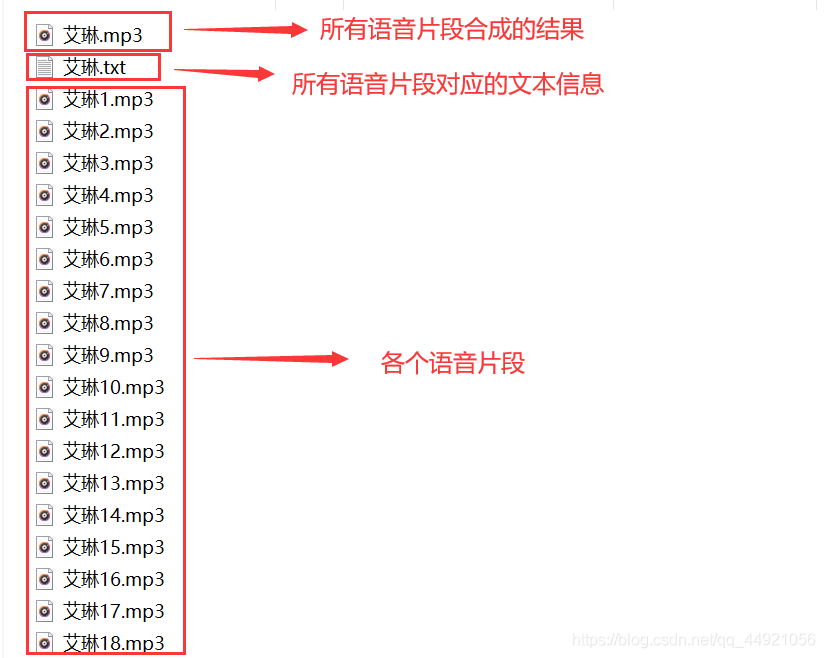
silence.export(path + '{}.mp3'.format(name_result), format="mp3") # 匯出合成語音
print('{}語音合成成功\n'.format(name_result))
except:
print('{}語音合成失敗\n'.format(name_result))
text_result = text_deal(text) # 最終的文本
text_name = name_result + '.txt' # 語音文本檔案名稱
download(text_name, text_result, path) # 下載語音文本
print("{}的語音文本資訊下載完畢!\n".format(name_result))
if __name__ == '__main__':
main()
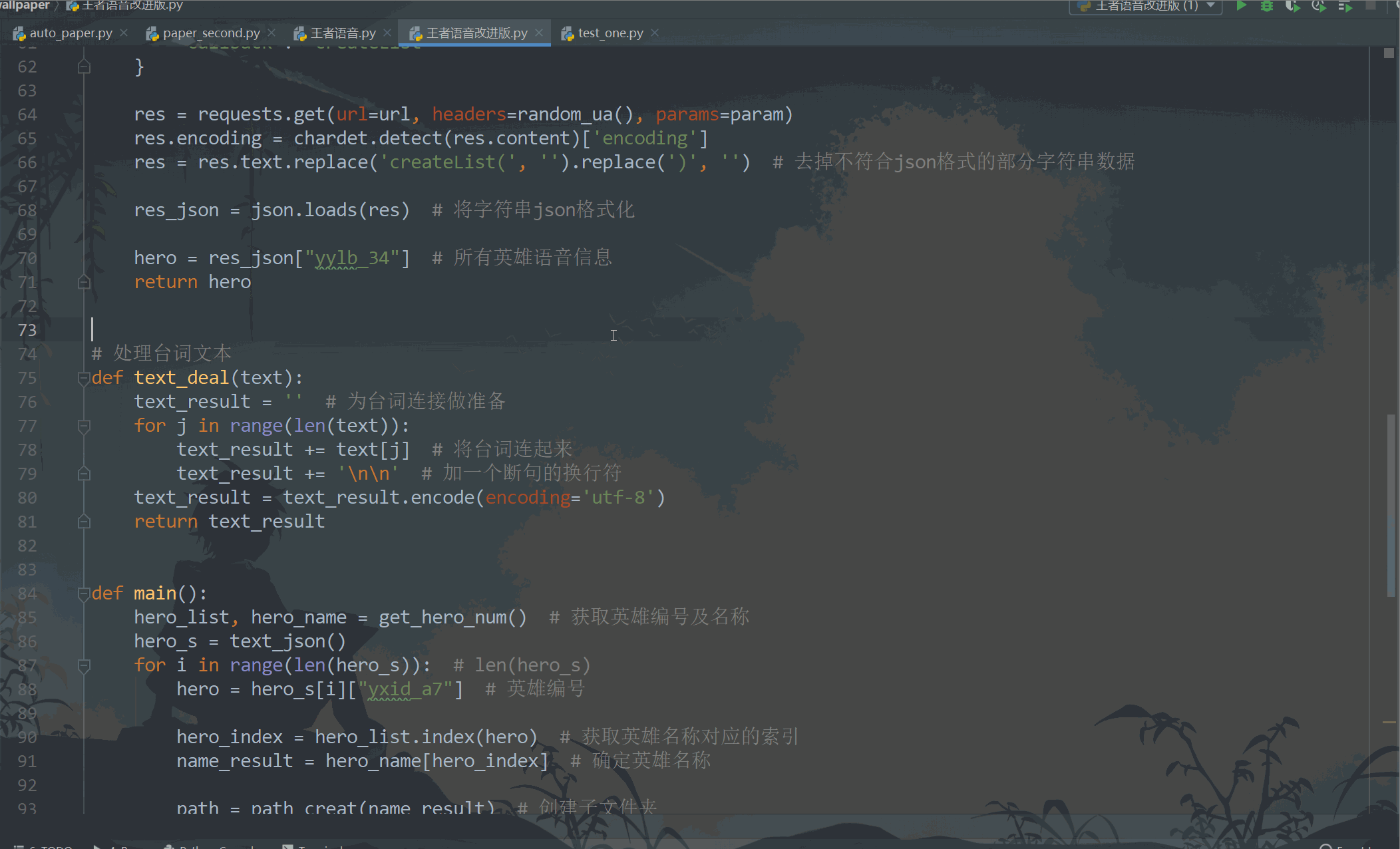
- 運行結果
- 代碼的簡單說明:
①、對于fake_useragent這個庫,可以參考
Python爬蟲有用的庫:fake_useragent,自動生成請求頭
②、對于chardet這個庫,可以參考
Python爬蟲有用的庫:chardet,自動檢測字符編碼
③、對于pydub這個庫,可以參考
Python爬蟲有用的庫:pydub,處理音視頻的庫
④、為什么提前創立path_f = "./王者語音"
在練習的程序中,我發現,使用os.mkdir只方便創建下一個等級的目錄,而我需要兩級,所以提前創立了一個,
⑤、json.loads(),將字串格式化
可以提前將爬取的txt檔案,放到json在線決議,嘗試一下,工具很多,
如:https://www.json.cn/
基本上出錯的原因都是格式錯誤,常見的錯誤有,是""而不是'',本文中遇到的錯誤是,多了幾個字串,用replace替換掉,或者洗掉掉都可以,本文采取的替換,
- 其它說明
①、通過本文爬蟲,可以幫助你了解 json 資料的決議和提取需要的資料,
②、本文利用 Python 爬蟲一鍵下載王者榮耀英雄臺詞語音,實作程序中也會遇到一些問題,多思考和除錯,最終解決問題,也能理解得更深刻,
③、代碼可直接復制運行,如果對你有幫助,記得點個贊哦,也是對作者最大的鼓勵,不足之處可以在評論區多多指正、交流,
作者:遠方的星
CSDN:https://blog.csdn.net/qq_44921056
本文僅用于交流學習,未經作者允許,禁止轉載,更勿做其他用途,違者必究,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/293840.html
標籤:其他
上一篇:darknet 訓練流程