注:因為硬體原因,這次的實驗并沒有生成圖片,但是代碼應該是沒有問題的,可以參考學習一下,
本次基于DCGAN實作動漫人物的生成,最終的效果可以參考大神K同學啊的博客,與上篇文章基于DCGAN生成手寫數字的步驟基本一致,
1.匯入庫
import tensorflow as tf
import numpy as np
import glob,imageio,os,PIL,pathlib
import matplotlib.pyplot as plt
# 支持中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用來正常顯示中文標簽
plt.rcParams['axes.unicode_minus'] = False # 用來正常顯示負號
2.資料準備
data_dir = "E:/tmp/.keras/datasets/car_face_photos"
data_dir = pathlib.Path(data_dir)
pic_paths = list(data_dir.glob('*'))
pic_paths = [str(path) for path in pic_paths]
img_count = len(list(pic_paths))#共21551張圖片
plt.figure(figsize=(10, 5))
plt.suptitle("資料示例", fontsize=15)
for i in range(40):
plt.subplot(5, 8, i + 1)
plt.xticks([])
plt.yticks([])
# 顯示圖片
images = plt.imread(pic_paths[i])
plt.imshow(images)
plt.show()
查看圖片:

資料預處理:
1.歸一化到[-1,1]之間
2.調整圖片大小為[64,64]
3.將資料按照batch_size劃分開,并打亂
#資料處理
def preprocess_image(image):
image = tf.image.decode_jpeg(image,channels=3)
image = tf.image.resize(image,[64,64])
return (image - 127.5)/127.5
def load_and_preprocess_image(path):
image = tf.io.read_file(path)
return preprocess_image(image)
path_ds = tf.data.Dataset.from_tensor_slices(pic_paths)
image_ds = path_ds.map(load_and_preprocess_image,num_parallel_calls=tf.data.experimental.AUTOTUNE)
buffer_size = 60000
batch_size = 256
dataset = image_ds.shuffle(buffer_size).batch(batch_size)
3.生成器與判別器的構建
生成器采用tf.keras.layers.Conv2DTranspose(上采樣層)從噪聲資料中產生圖片,以一個使用該種子作為輸入的 Dense 層開始,然后多次上采樣直到達到所期望的 64x64x3 的圖片尺寸,模型如下所示:
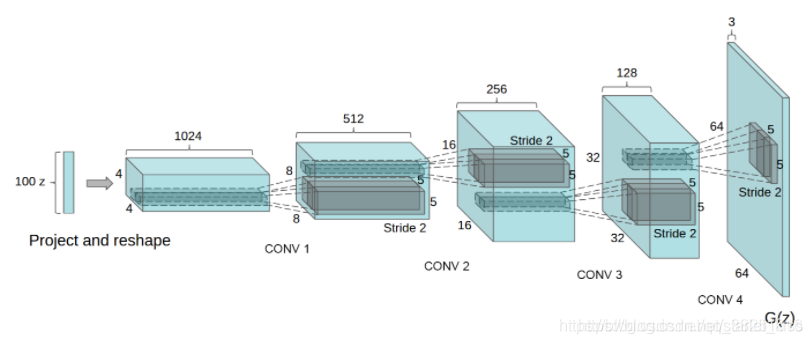
除了最后一層使用tanh作為激活函式外,其余的都采用LeakyReLU作為激活函式,
def Geberator_model():
model = tf.keras.Sequential([])
model.add(tf.keras.layers.Dense(4*4*1024,use_bias=False,input_shape=(100,)))
model.add(tf.keras.layers.BatchNormalization())
model.add(tf.keras.layers.LeakyReLU())
model.add(tf.keras.layers.Reshape((4,4,1024)))
assert model.output_shape == (None,4,4,1024)
#1
model.add(tf.keras.layers.Conv2DTranspose(512,(5,5),strides=(2,2),padding="same",use_bias=False))
assert model.output_shape == (None,8,8,512)
model.add(tf.keras.layers.BatchNormalization())
model.add(tf.keras.layers.LeakyReLU())
#2
model.add(tf.keras.layers.Conv2DTranspose(256, (5, 5), strides=(2, 2), padding="same", use_bias=False))
assert model.output_shape == (None, 16, 16, 256)
model.add(tf.keras.layers.BatchNormalization())
model.add(tf.keras.layers.LeakyReLU())
#3
model.add(tf.keras.layers.Conv2DTranspose(128, (5, 5), strides=(2, 2), padding='same', use_bias=False))
assert model.output_shape == (None, 32, 32, 128)
model.add(tf.keras.layers.BatchNormalization())
model.add(tf.keras.layers.LeakyReLU())
#4
model.add(tf.keras.layers.Conv2DTranspose(3, (5, 5), strides=(2, 2), padding='same', use_bias=False, activation='tanh'))
assert model.output_shape == (None, 64, 64, 3)
return model
generator = Geberator_model()
generator.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 16384) 1638400
_________________________________________________________________
batch_normalization (BatchNo (None, 16384) 65536
_________________________________________________________________
leaky_re_lu (LeakyReLU) (None, 16384) 0
_________________________________________________________________
reshape (Reshape) (None, 4, 4, 1024) 0
_________________________________________________________________
conv2d_transpose (Conv2DTran (None, 8, 8, 512) 13107200
_________________________________________________________________
batch_normalization_1 (Batch (None, 8, 8, 512) 2048
_________________________________________________________________
leaky_re_lu_1 (LeakyReLU) (None, 8, 8, 512) 0
_________________________________________________________________
conv2d_transpose_1 (Conv2DTr (None, 16, 16, 256) 3276800
_________________________________________________________________
batch_normalization_2 (Batch (None, 16, 16, 256) 1024
_________________________________________________________________
leaky_re_lu_2 (LeakyReLU) (None, 16, 16, 256) 0
_________________________________________________________________
conv2d_transpose_2 (Conv2DTr (None, 32, 32, 128) 819200
_________________________________________________________________
batch_normalization_3 (Batch (None, 32, 32, 128) 512
_________________________________________________________________
leaky_re_lu_3 (LeakyReLU) (None, 32, 32, 128) 0
_________________________________________________________________
conv2d_transpose_3 (Conv2DTr (None, 64, 64, 3) 9600
=================================================================
Total params: 18,920,320
Trainable params: 18,885,760
Non-trainable params: 34,560
_________________________________________________________________
判別器為基于CNN的圖片分類器
#判別器的構建
def Discriminator_model():
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(128,(5,5),strides=(2,2),padding="same",input_shape=[64,64,1]),
tf.keras.layers.LeakyReLU(),
tf.keras.layers.Dropout(0.3),
tf.keras.layers.Conv2D(128,(5,5),strides=(2,2),padding="same"),
tf.keras.layers.LeakyReLU(),
tf.keras.layers.Dropout(0.3),
tf.keras.layers.Conv2D(256, (5, 5), strides=(2, 2), padding="same"),
tf.keras.layers.LeakyReLU(),
tf.keras.layers.Dropout(0.3),
tf.keras.layers.Conv2D(512, (5, 5), strides=(2, 2), padding="same"),
tf.keras.layers.LeakyReLU(),
tf.keras.layers.Dropout(0.3),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(1,activation='sigmoid')
])
return model
discriminator = Discriminator_model()
discriminator.summary()
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 32, 32, 128) 3328
_________________________________________________________________
leaky_re_lu_4 (LeakyReLU) (None, 32, 32, 128) 0
_________________________________________________________________
dropout (Dropout) (None, 32, 32, 128) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 16, 16, 128) 409728
_________________________________________________________________
leaky_re_lu_5 (LeakyReLU) (None, 16, 16, 128) 0
_________________________________________________________________
dropout_1 (Dropout) (None, 16, 16, 128) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 8, 8, 256) 819456
_________________________________________________________________
leaky_re_lu_6 (LeakyReLU) (None, 8, 8, 256) 0
_________________________________________________________________
dropout_2 (Dropout) (None, 8, 8, 256) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 4, 4, 512) 3277312
_________________________________________________________________
leaky_re_lu_7 (LeakyReLU) (None, 4, 4, 512) 0
_________________________________________________________________
dropout_3 (Dropout) (None, 4, 4, 512) 0
_________________________________________________________________
flatten (Flatten) (None, 8192) 0
_________________________________________________________________
dense_1 (Dense) (None, 1) 8193
=================================================================
Total params: 4,518,017
Trainable params: 4,518,017
Non-trainable params: 0
_________________________________________________________________
4.loss值與優化器
計算交叉熵
cross_entropy = tf.keras.losses.BinaryCrossentropy(from_logits=True)
因為分為判別器的生成器,因此loss值的計算方式也是不同的,
判別器的loss值:判斷真實圖片為1的loss與判斷生成圖片為0的loss之和,因為判別器希望將真實圖片判別為1,將生成圖片判別為0.
生成器的loss值:判斷生成圖片為1的loss,因為生成器希望生成的圖片是真實圖片,即判別為1.
def Discriminator_loss(real_out,fake_out):
real_loss = cross_entropy(tf.ones_like(real_out),real_out)
fake_loss = cross_entropy(tf.zeros_like(fake_out),fake_out)
return real_loss+fake_loss
def Generator_loss(fake_out):
return cross_entropy(tf.ones_like(fake_out),fake_out)
優化器也分為兩個:
generator_opt = tf.keras.optimizers.Adam(learning_rate=1e-4)
discriminator_opt = tf.keras.optimizers.Adam(learning_rate=1e-4)
引數設定
epochs = 600
noise_dim = 100
num_exp_to_generate = 16
seed = tf.random.normal([num_exp_to_generate,noise_dim])
5.批次訓練
訓練回圈在生成器接收到一個隨機種子作為輸入時開始,該種子用于生產一張圖片,判別器隨后被用于區分真實圖片(選自訓練集)和偽造圖片(由生成器生成),針對這里的每一個模型都計算損失函式,并且計算梯度用于更新生成器與判別器,
def train_step(images):
noise = tf.random.normal([batch_size,noise_dim])#生成一個batch_size*noise_dim的資料,相當于生成了batch_size個長度為100的隨機向量
with tf.GradientTape() as gen_tape,tf.GradientTape() as dis_tape:#兩個Tape,一個代表生成器,一個代表判別器,
real_out = discriminator(images,training = True)#利用判別器對真實的圖片進行訓練,得到一個model
gen_image = generator(noise,training = True)#利用生成器對噪聲資料生成圖片
fake_out = discriminator(gen_image, training=True)#利用判別器對生成的圖片進行訓練
gen_loss = Generator_loss(fake_out)#利用判別器對生成圖片的判斷計算生成器的loss值
dis_loss = Discriminator_loss(real_out,fake_out)##利用判別器對生成圖片和真實圖片的判斷計算判別器的loss值
gradient_gen = gen_tape.gradient(gen_loss,generator.trainable_variables)#根據生成器的loss值和網路模型計算梯度
gradient_dis = dis_tape.gradient(dis_loss, discriminator.trainable_variables)#根據判別器的loss值和網路模型計算梯度
Generator_opt.apply_gradients(zip(gradient_gen,generator.trainable_variables))#根據梯度對生成器進行梯度更新
Discriminator_opt.apply_gradients(zip(gradient_dis,discriminator.trainable_variables))#根據梯度對判別器進行梯度更新
可視化圖片并保存到本地
def Generator_plot_image(gen_model,test_noise,epoch):
pre_images = gen_model.predict(test_noise,training = False)
fig = plt.figure(figsize=(4,4))
for i in range(pre_images.shape[0]):
plt.subplot(4,4,i+1)
plt.imshow((pre_images[i,:,:,0]+1)/2)
plt.axis('off')
fig.savefig("E:/tmp/.keras/datasets/cartoon_photos_gen_DCGAN/%05d.png" % epoch)
plt.close()
訓練模型:
def train(dataset,epochs):
for epoch in range(epochs):
for image_batch in dataset:
train_step(image_batch)
print('.',end='')
print()
Generator_plot_image(generator,seed,epoch)
train(dataset,epochs)
也可以用來生成其他的圖片,可以起到資料增強的效果,
努力加油a啊
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/293868.html
標籤:AI
上一篇:[論文閱讀筆記54]面向物體對齊的多視圖知識圖譜嵌入方法
下一篇:商品物體檢測專案介紹