1. 題目
Multi-view Knowledge Graph Embedding for Entity Alignment
面向物體對齊的多視圖知識圖譜嵌入方法
論文:https://arxiv.org/pdf/1906.02390.pdf
代碼:https://github.com/nju-websoft/MultiKE
2. 研究背景
研究的問題:
知識圖(KGs)之間基于嵌入的物體對齊問題;
目前存在問題:
以前的方法主要是在物體關系結構上,后面也有把屬性加入作為特征,可是也有大量的物體特征未被去研究,表現在兩方面的限制:
首先,知識圖譜中的物體具有不同的特性,但當前基于嵌入的物體對齊方法只利用了其中的一種或兩種型別;
例如[MTransE,IPTransE,BootEA]只是用了物體關系;另外,[JAPE,KDCoE, AttrE]加入了屬性,文本描述或文字等資訊;
其次,現有的基于嵌入的物體對齊方法依賴于豐富的種子物體對齊作為標記的訓練資料, 這個是成本有點大的,
貢獻:
提出了一種基于多視圖知識圖譜嵌入的物體對齊框架,稱為MultiKE;
具體來說,基于物體名稱、關系和屬性的視圖嵌入物體,并使用幾種組合策略;
在物體層面,關系層面,屬性層面設計了兩個跨資料庫的方法;
提出三種不同的組合多視圖的策略;
多視圖,跨圖譜推理,嵌入組合
3. 內容
3.1 多視圖嵌入
本質是想把知識中特征,分成多個子集,這里叫做views; 名稱/關系/屬性特性
多視圖特征例子:
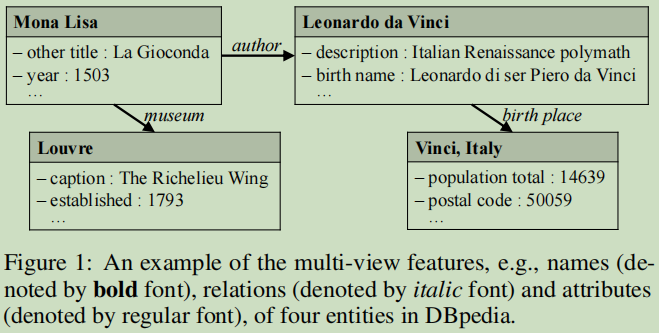
物體嵌入對這三種視圖中分別用不同的方法去學習,最后把學習結果聯合起來達到物體性能提高結果,
3.1.1 Literal Embedding(字面意思的嵌入):
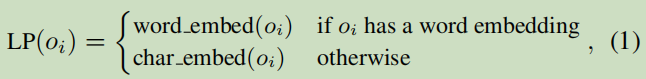
對于詞嵌入采用的方法–Advances in pre-training distributed word representations
對于字符—Skip-Gram
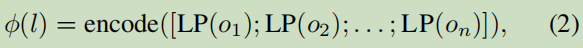
φ(·)表示輸入的字面嵌入, encode(·) 對嵌入的壓縮表示;[; ] 表示把字符拼接起來;這里n最大取5,超過的會被截斷,短的會用空格代替;
3.1.2 Name View Embedding
名字視的嵌入,是使用了字面嵌入的,
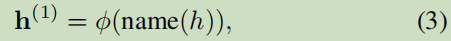
從物件抽取名字表示;
3.1.3 Relation View Embedding
基于TransE表達學習:
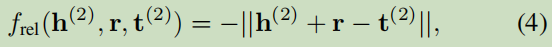
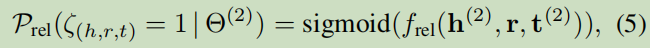
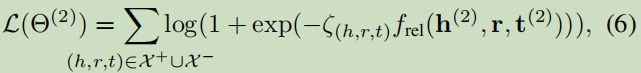
X _+ = X_a ∪ X_b:表示來自兩圖譜的正樣本;X _?表示被隨機替換了的負樣本;
3.1.4 Attribute View Embedding
使用CNN去抽取;
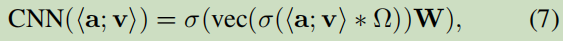
<a;v>:表示屬性及其值拼接成一個matrix; 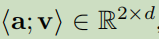
對于一個fact(h,a,v),如下定義:
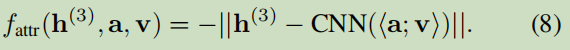
損失函式:
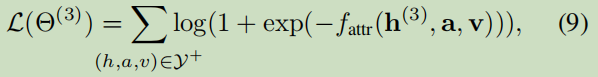
3.2 Cross-KG Training for Entity Alignment
基于種子物體對齊的跨kg物體對齊推斷來捕獲兩個kg之間的對齊資訊,
3.2.1 物體識別推理
我們利用少量已對齊的種子物體對作為監督資料:

關系:
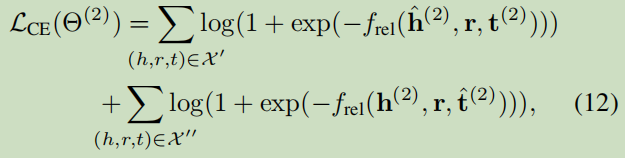
3.2.2 Relation and Attribute Identity Inference
與物體識別推理差不多,不過這里增加了一個搞了輔助概率;

這里采用軟相似性:由于不同知識圖譜在本體層面可能差異巨大,所以我們不要求關系對是嚴格對齊的,
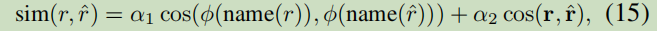
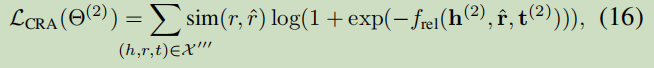
3.3 View Combination
3.3.1 Weighted View Averaging
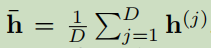 ,
,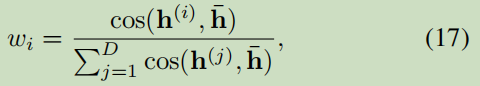 ,結果:
,結果: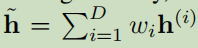
3.3.2 Shared Space Learning
引入一個正交矩陣,把視圖嵌入映射到共享空間中,
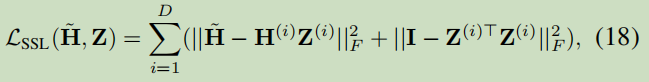 ,
,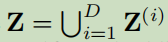
Z_i表示看作為第i個視圖嵌入空間映射到共享空間的映射矩陣,||·||F表示為Frobenius規范;
式中的第二項表示軟正則的規約,
3.3.3 In-training Combination
聯合多視圖訓練,
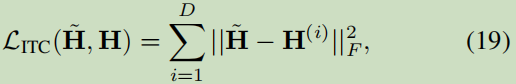
4. 訓練程序

首先訓練詞與char的嵌入,然后訓練其它的視圖嵌入,軟對齊也在迭代中計算;最后,如果是in-training的就不需要,否則進行合并,
5.實驗
Datasets:DBP-WD,DBP-YG
對比方法使用了7種:MTransE, IPTransE, JAPE,BootEA, KDCoE, GCN-Align,AttrE ,也加了:TransD, HolE ,ConvE
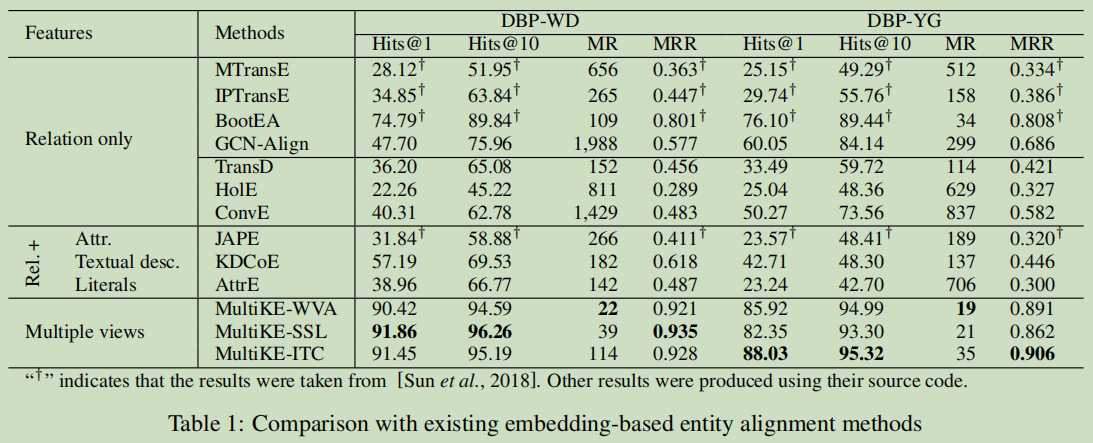
從這個對比來看,提出模型有很大性能上是有很大的提升的,
視圖影響分析:
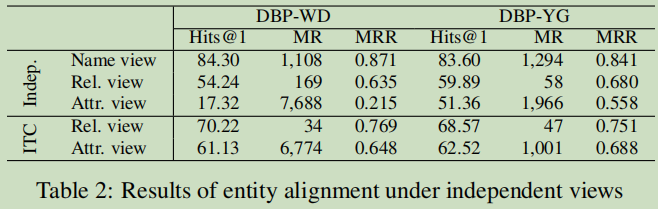
Name還是比加高的,字面意義起到很大的作用,不過這個也是很合理的,一般相同物體,名稱也是差不多相同的,ITC:in-training
combination
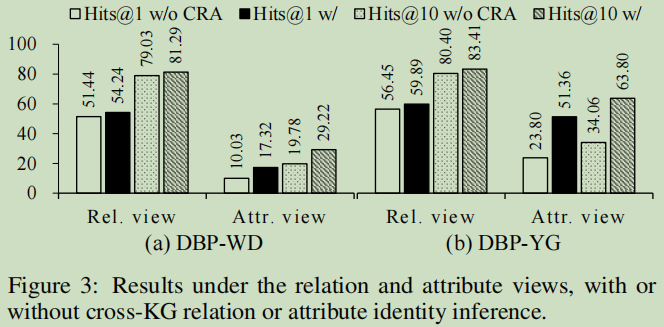
跨圖譜推理影響
無監督物體對齊的分析
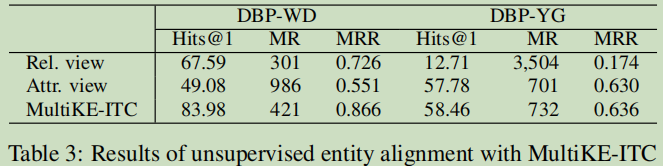
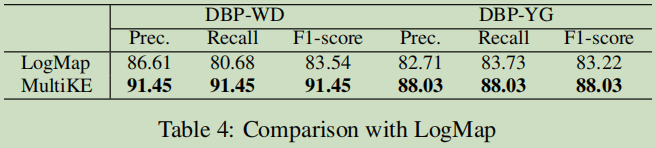
與常規方法對比分析
相關作業
KG embedding
分為三類:Translational 方法;Semantic matching方法;Neural方法
Embedding-based entity alignment
先嵌入,然后計算相似性;
Multi-view representation learning
多視圖的的方法分三步:
(i)識別能夠充分表示資料的多個視圖;
(ii)對每個視圖進行表示學習;
(iii)組合多個視圖特定的表示,
參考:
【1】IJCAI 2019 論文:面向物體對齊的多視圖知識圖譜嵌入方法
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/293867.html
標籤:AI