目錄
- 基本介紹
- RDD
- RDD基本介紹
- 核心屬性
- 執行原理
- 基礎編程
- RDD創建
- RDD 并行度與磁區
基本介紹
Spark 計算框架為了能夠進行高并發和高吞吐的資料處理,封裝了三大資料結構,用于處理不同的應用場景,三大資料結構分別是:
- RDD : 彈性分布式資料集
- 累加器:分布式共享只寫變數
- 廣播變數:分布式共享只讀變數
RDD
RDD基本介紹
RDD(Resilient Distributed Dataset)叫做彈性分布式資料集,是Spark 中最基本的資料處理模型,代碼中是一個抽象類,它代表一個彈性的、不可變、可磁區、里面的元素可并行計算的集合,
(1)彈性
- 存盤的彈性:記憶體與磁盤的自動切換;
- 容錯的彈性:資料丟失可以自動恢復;
- 計算的彈性:計算出錯重試機制;
- 分片的彈性:可根據需要重新分片,
(2) 分布式:資料存盤在大資料集群不同節點上
(3) 資料集:RDD 封裝了計算邏輯,并不保存資料
(4)資料抽象:RDD 是一個抽象類,需要子類具體實作
(5)不可變:RDD 封裝了計算邏輯,是不可以改變的,想要改變,只能產生新的RDD,在
新的RDD 里面封裝計算邏輯
(6)可磁區、并行計算
核心屬性
/**
* Internally, each RDD is characterized by five main properties:
*
* - A list of partitions
* - A function for computing each split
* - A list of dependencies on other RDDs
* - Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
* - Optionally, a list of preferred locations to compute each split on (e.g. block locations for
* an HDFS file)
* /
(1)磁區串列
RDD 資料結構中存在磁區串列,用于執行任務時并行計算,是實作分布式計算的重要性,
/**
* Implemented by subclasses to return the set of partitions in this RDD. This method will only
* be called once, so it is safe to implement a time-consuming computation in it.
*
* The partitions in this array must satisfy the following property:
* `rdd.partitions.zipWithIndex.forall { case (partition, index) => partition.index == index }`
*/
protected def getPartitions: Array[Partition]
(2)磁區計算函式
Spark 在計算時,是使用磁區函式對每一個磁區進行計算,
/**
* :: DeveloperApi ::
* Implemented by subclasses to compute a given partition.
*/
@DeveloperApi
def compute(split: Partition, context: TaskContext): Iterator[T]
(3) RDD 之間的依賴關系
RDD 是計算模型的封裝,當需求中需要將多個計算模型進行組合時,就需要將多個 RDD 建
立依賴關系
/**
* Implemented by subclasses to return how this RDD depends on parent RDDs. This method will only
* be called once, so it is safe to implement a time-consuming computation in it.
*/
protected def getDependencies: Seq[Dependency[_]] = deps
(4)磁區器(可選)
當資料為KV 型別資料時,可以通過設定磁區器自定義資料的磁區,
/** Optionally overridden by subclasses to specify how they are partitioned. */
@transient val partitioner: Option[Partitioner] = None
(5)首選位置(可選)
計算資料時,可以根據計算節點的狀態選擇不同的節點位置進行計算,
/**
* Optionally overridden by subclasses to specify placement preferences.
*/
protected def getPreferredLocations(split: Partition): Seq[String] = Nil
執行原理
從計算的角度來講,資料處理程序中需要計算資源(記憶體 & CPU)和計算模型(邏輯),執行時,需要將計算資源和計算模型進行協調和整合,
Spark 框架在執行時,先申請資源,然后將應用程式的資料處理邏輯分解成一個一個的計算任務,然后將任務發到已經分配資源的計算節點上, 按照指定的計算模型進行資料計算,最后得到計算結果,
RDD 是Spark 框架中用于資料處理的核心模型,在Yarn 環境中,RDD的作業原理:
(1)啟動Yarn 集群環境
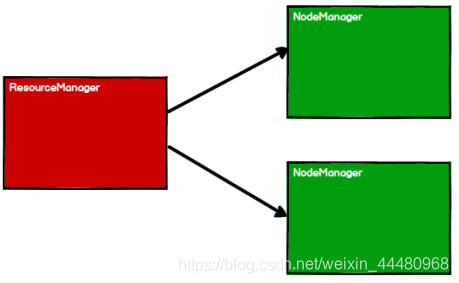
(2) Spark 通過申請資源創建調度節點和計算節點
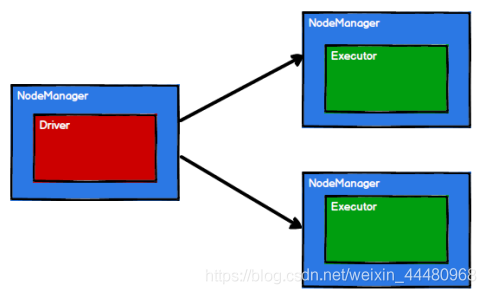
(3)Spark 框架根據需求將計算邏輯根據磁區劃分成不同的任務
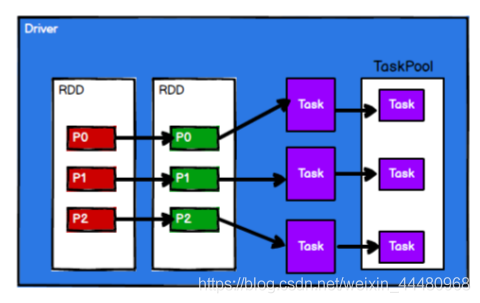
(4)調度節點將任務根據計算節點狀態發送到對應的計算節點進行計算
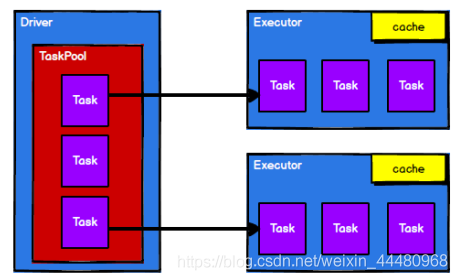
從以上流程可以看出 RDD 在整個流程中主要用于將邏輯進行封裝,并生成Task 發送給
Executor 節點執行計算,
基礎編程
RDD創建
在Spark 中創建RDD 的創建方式可以分為四種:
(1)從集合(記憶體)中創建 RDD
從集合中創建RDD,Spark 主要提供了兩個方法:parallelize ()和makeRDD()
package com.atguigu.bigdata.spark.core.rdd.builder
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark01_RDD_Memory {
def main(args: Array[String]): Unit = {
//TODO 準備環境
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
//TODO 創建RDD
//從記憶體中創建:將記憶體中集合的資料作為處理的資料源
val seq = Seq[Int](1,2,3,4)
//parallelize:并行
// val rdd: RDD[Int] = sc.parallelize(seq)
//另外一個方法makeRDD():在底層實作時候其實就是呼叫了rdd物件的paralleliz方法
val rdd: RDD[Int] = sc.makeRDD(seq)
rdd.collect().foreach(println)
//TODO 關倍訓境
sc.stop()
}
}
從底層代碼實作來講,makeRDD() 方法其實就是parallelize() 方法,底層代碼如下:
def makeRDD[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T] = withScope {
parallelize(seq, numSlices)
}
(2) 從外部存盤(檔案)創建RDD
由外部存盤系統的資料集創建RDD 包括:本地的檔案系統,所有Hadoop 支持的資料集,比如HDFS、HBase 等,
package com.atguigu.bigdata.spark.core.rdd.builder
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark02_RDD_File {
def main(args: Array[String]): Unit = {
//TODO 準備環境
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
//TODO 創建RDD
//從記憶體中創建:將檔案中的資料作為處理的資料源
//path路徑默認以當前環境的根路徑為基準,可以寫絕對路徑,也可以寫相對路徑
// val rdd: RDD[String] = sc.textFile("datas/1.txt") //相對路徑
//path路徑可以是檔案的具體路徑,也可以是目錄
// val rdd: RDD[String] = sc.textFile("datas") //統計目錄中所有檔案
//path路徑還可以使用通配符
val rdd: RDD[String] = sc.textFile("datas/1*.txt")
//path路徑還可以是分布式存盤系統路徑:HDFS
rdd.collect().foreach(println)
//TODO 關倍訓境
sc.stop()
}
}
(3)從其他RDD結果創建
主要是通過一個RDD 運算完后,再產生新的RDD,
(4)直接創建RDD(new)
RDD 并行度與磁區
默認情況下,Spark 可以將一個作業切分多個任務后,發送給Executor 節點并行計算,而能
夠并行計算的任務數量我們稱之為并行度,這個數量可以在構建RDD 時指定,
注意:這里的并行執行的任務數量,并不是指的切分任務的數量,
package com.atguigu.bigdata.spark.core.rdd.builder
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark01_RDD_Memory_Par {
def main(args: Array[String]): Unit = {
//TODO 準備環境
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
sparkConf.set("spark.default.parallelism","4") //也可以配
val sc = new SparkContext(sparkConf)
//TODO 創建RDD
//RDD的并行度 & 磁區
//makeRDD可以傳第二個引數,第二個引數表示磁區數
//第二個引數可以不傳遞,不傳的話,使用默認值:defaultParallelism(默認并行度)
// val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2)
// scheduler.conf.getInt("spark.default.parallelism", totalCores)
// spark在默認情況下,從配置物件中獲取配置引數:spark.default.parallelism
// 如果獲取不到,那么使用totalCores屬性,這個屬性取值為當前運行環境的最大可用核數,也可以自己配置
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4))
rdd.saveAsTextFile("output")
//TODO 關倍訓境
sc.stop()
}
}
讀取記憶體資料時,資料可以按照并行度的設定進行資料的磁區操作,資料磁區規則的Spark 核心原始碼如下:
def positions(length: Long, numSlices: Int): Iterator[(Int, Int)] = {
(0 until numSlices).iterator.map { i =>
val start = ((i * length) / numSlices).toInt
val end = (((i + 1) * length) / numSlices).toInt
(start, end)
}
}
讀取檔案資料時,資料是按照Hadoop 檔案讀取的規則進行切片磁區,而切片規則和數
據讀取的規則有些差異,具體 Spark 核心原始碼如下:
public InputSplit[] getSplits(JobConf job, int numSplits)
throws IOException {
long totalSize = 0; // compute total size
for (FileStatus file: files) { // check we have valid files
if (file.isDirectory()) {
throw new IOException("Not a file: "+ file.getPath());
}
totalSize += file.getLen();
}
long goalSize = totalSize / (numSplits == 0 ? 1 : numSplits);
long minSize = Math.max(job.getLong(org.apache.hadoop.mapreduce.lib.input.
FileInputFormat.SPLIT_MINSIZE, 1), minSplitSize);
...
for (FileStatus file: files) {
...
if (isSplitable(fs, path)) {
long blockSize = file.getBlockSize();
long splitSize = computeSplitSize(goalSize, minSize, blockSize);
...
}
protected long computeSplitSize(long goalSize, long minSize,
long blockSize) {
return Math.max(minSize, Math.min(goalSize, blockSize));
}
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/293904.html
標籤:其他