日志分析系統ELK(上)之elasticsearch
- 1、什么是elasticsearch?
- 2、單節點elasticsearch安裝
- 3、搭建elasticsearch集群
- 4、elasticsearch可視化方法1——cerebro插件
- 5、elasticsearch可視化方法2——elasticsearch-head插件
- 6、elasticsearch節點角色
ELK是elasticsearch、logstash、kibana的組合簡稱,安裝時,三個軟體的版本需要匹配,
其中elasticsearch主要用來存盤檢索資料和資料處理,logstash主要用來資料采集和過濾然后給es,kibana主要從es里面加載資料然后展示,
本文學習elasticsearch
1、什么是elasticsearch?
Elasticsearch 是一個開源的分布式搜索分析引擎,建立在一個全文搜索引擎庫 Apache Lucene基礎之上,Elasticsearch 不僅僅是 Lucene,并且也不僅僅只是一個全文搜索引擎,它具有如下特點:
- 一個分布式的實時檔案存盤,每個欄位可以被索引與搜索
- 一個分布式實時分析搜索引擎
- 能勝任上百個服務節點的擴展,并支持 PB 級別的結構化或者非結構化資料
| 基礎模塊 | 作用 |
|---|---|
| cluster | 管理集群狀態,維護集群層面的配置資訊 |
| alloction | 封裝了分片分配相關的功能和策略 |
| discovery | 發現集群中的節點,以及選舉主節點 |
| gateway | 對收到master廣播下來的集群狀態資料的持久化存盤 |
| indices | 管理全域級的索引設定 |
| http | 允許通過JSON over HTTP的方式訪問ES的API |
| transport | 用于集群內節點之間的內部通信 |
| engine | 封裝了對Lucene的操作及translog的呼叫 |
Elasticsearch的官網是https://www.elastic.co/cn/
Elasticsearch的功能強大,常用的應用場景有:
- 資訊檢索
- 日志分析
- 業務資料分析
- 資料庫加速
- 運維指標監控
2、單節點elasticsearch安裝
實驗準備三臺新虛擬機server3(172.25.77.3)、server4(172.25.77.4)、server5(172.25.77.5),三個虛擬機分別給了2G記憶體,先建立單節點,后面創建集群,
準備elasticsearch的安裝包,官網下載https://elasticsearch.cn/download/
我這里用了之前的server3和server4,server5是新創的,所以先清理server3環境
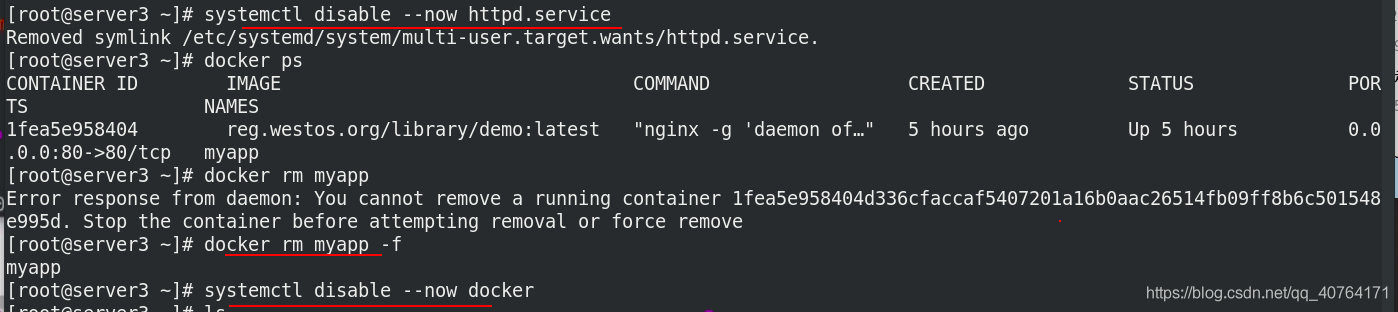
清理server4環境

安裝軟體
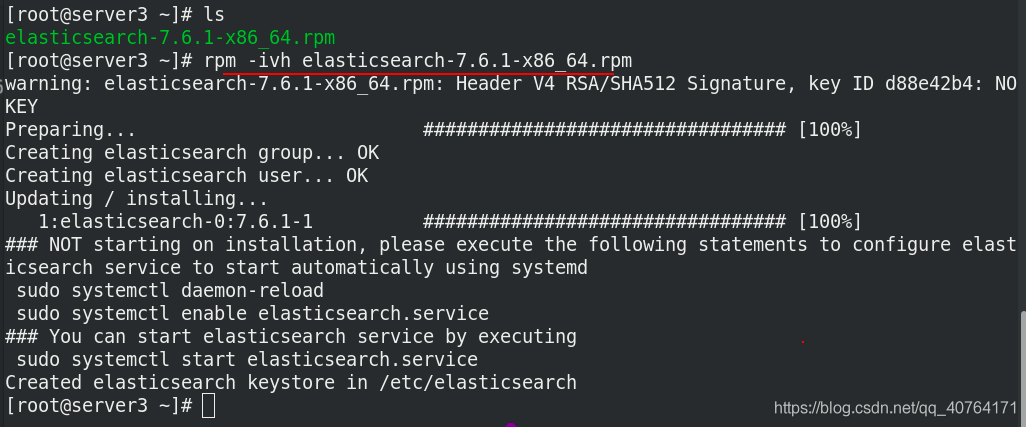
進入/etc/elasticsearch/,編輯主組態檔

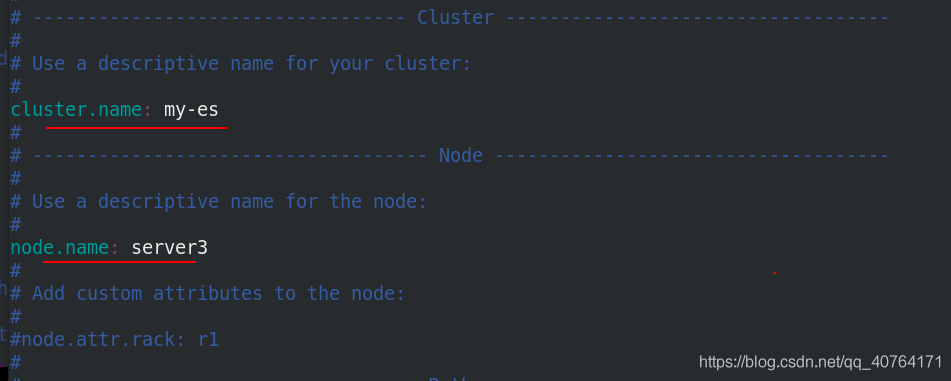
設定集群名稱為my-es,節點名稱為server3
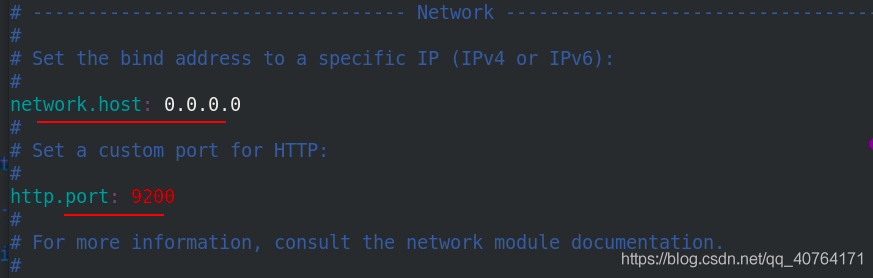
任何主機都可以訪問,http埠為9200
發現的主機有server3、server4、server5,初始化節點為server3
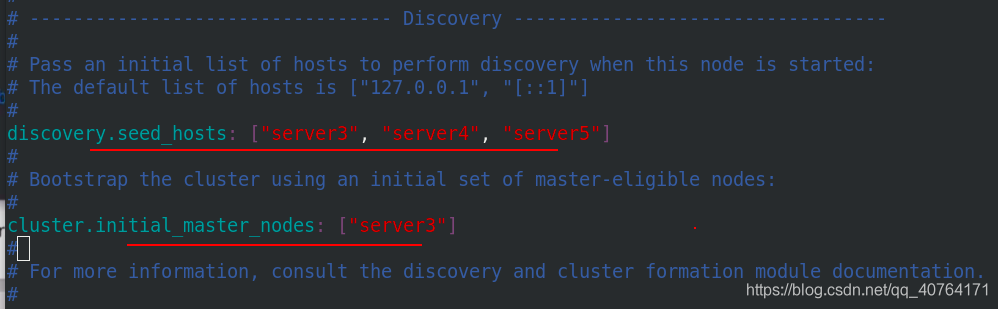
開啟elasticsearch,并設定開機自啟,查看開啟了9200埠
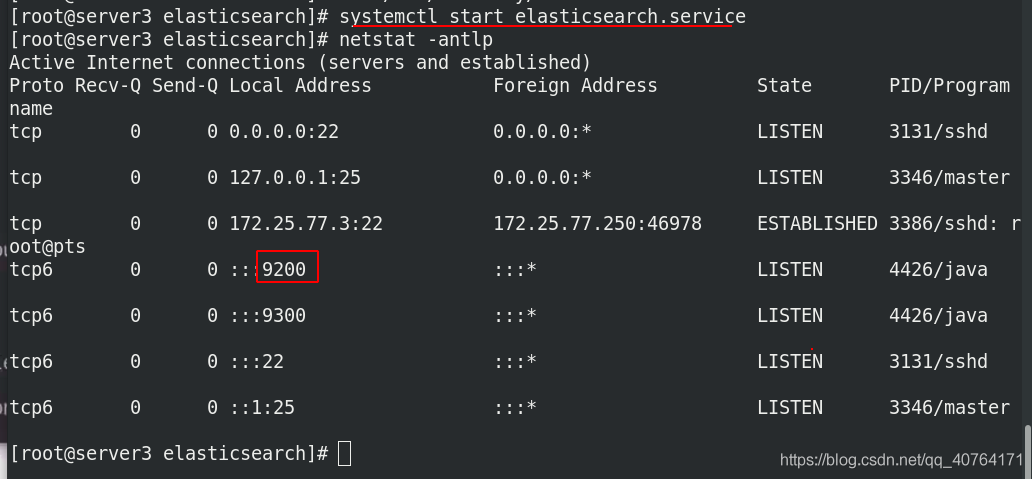
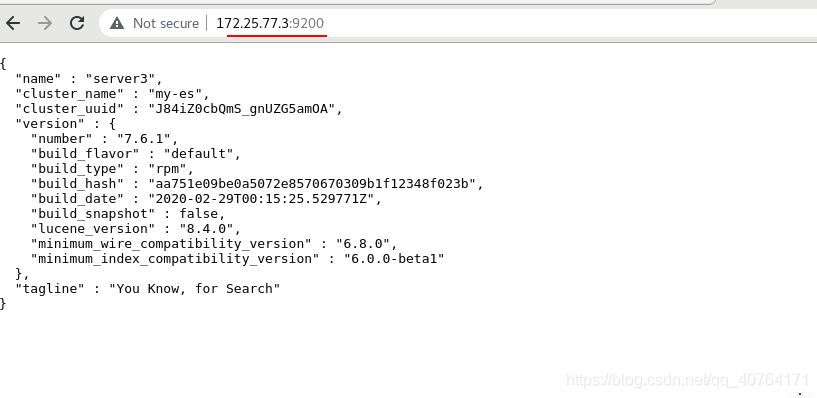
真機網頁訪問http://172.25.77.3:9200,測驗成功
由于修改了集群名字,現在查看日志用cat /var/log/elasticsearch/my-es.log,此處可以禁用swap磁區,實驗效果更加流暢,不禁用swap也沒問題
3、搭建elasticsearch集群
接下來給server4和server5配置
server3把rpm給server4和server5發一份,server4安裝elasticsearch
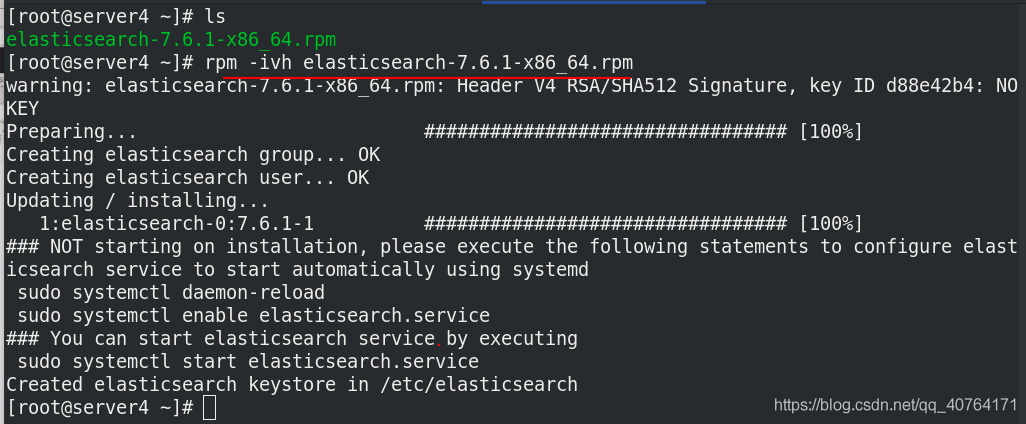
server5安裝elasticsearch
由于主組態檔基本一致,所以server3把elasticsearch.yml給server4和server5發一份,再改
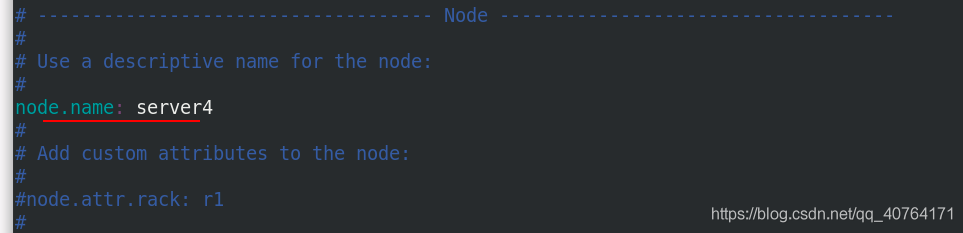
server4進入/etc/elasticsearch/目錄,編輯主組態檔elasticsearch.yml,把節點名稱改為server4,其他都不變
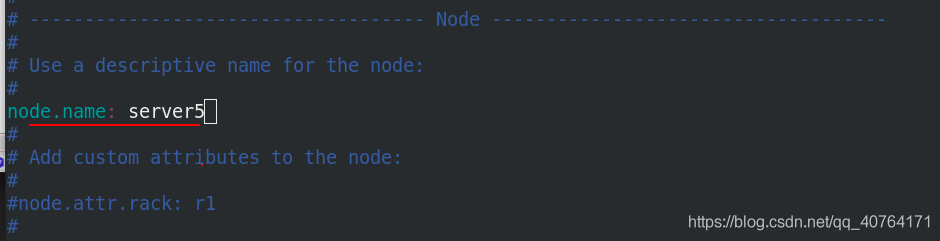
類似的,server5進入/etc/elasticsearch/目錄,編輯主組態檔elasticsearch.yml,把節點名稱改為server5,其他都不變
server4開啟elasticsearch,設定開機自啟

server5開啟elasticsearch,設定開機自啟

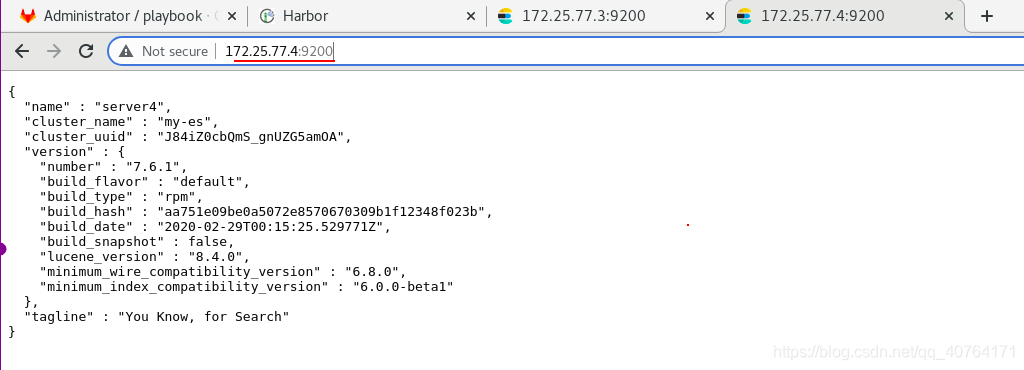
測驗,網頁訪問http://172.25.77.4:9200,測驗成功
測驗,網頁訪問http://172.25.77.5:9200,測驗成功
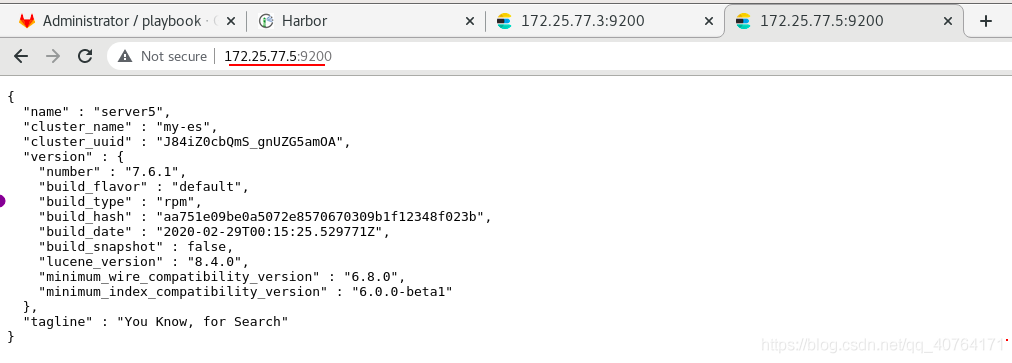
4、elasticsearch可視化方法1——cerebro插件
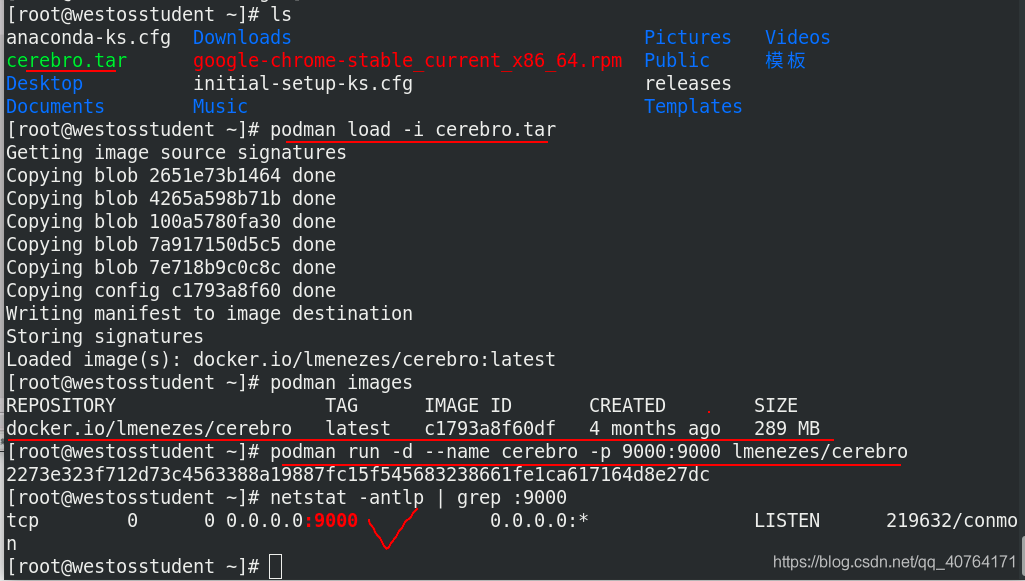
由于elasticsearch看著很不舒服,看不懂,所以想要圖形化的界面,引入了cerebro
cerebro是鏡像,正好真機是8.2的紅帽系統,自帶podman,所以在真機匯入鏡像,podman run -d --name cerebro -p 9000:9000 lmenezes/cerebro運行該鏡像,默認開放9000埠
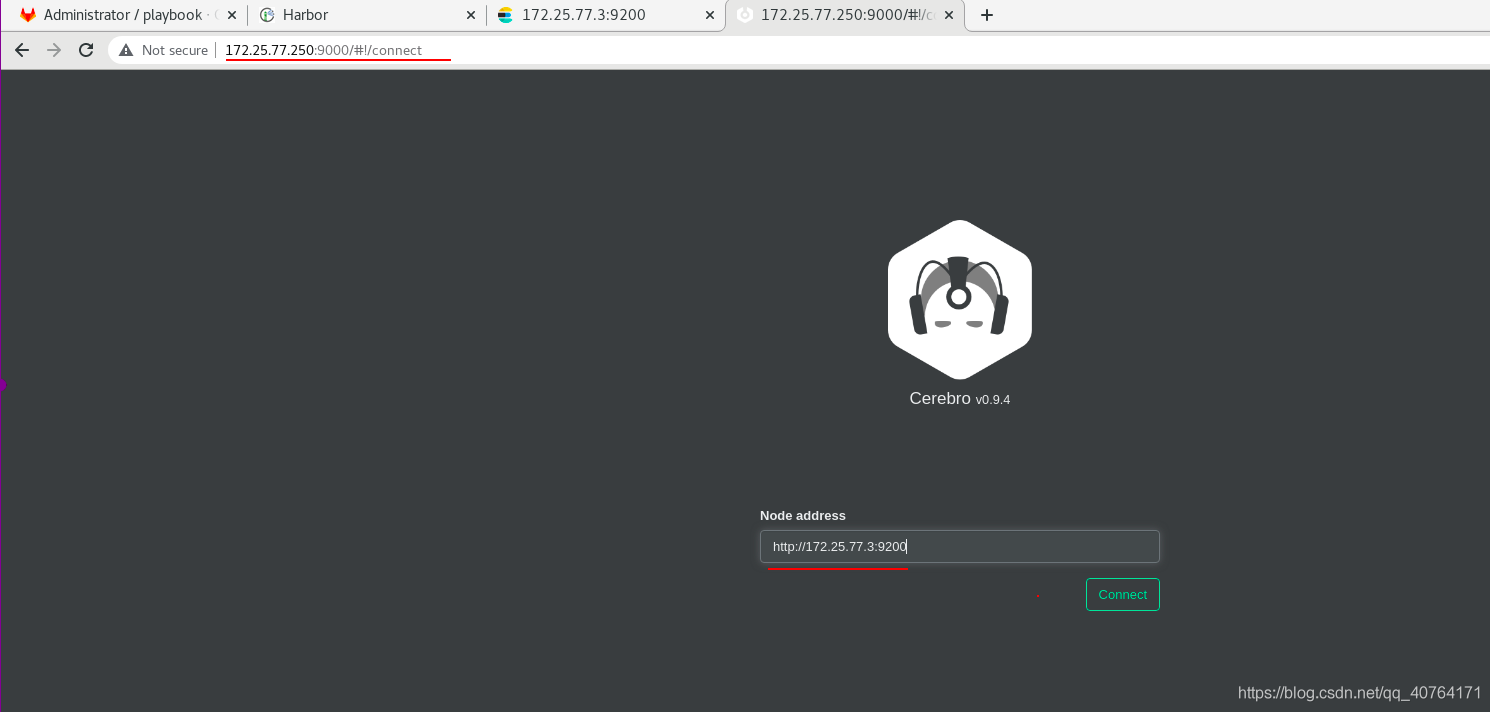
網頁訪問http://172.25.77.250:9000,進入,需要輸入監聽的地址,http://172.25.77.3:9200
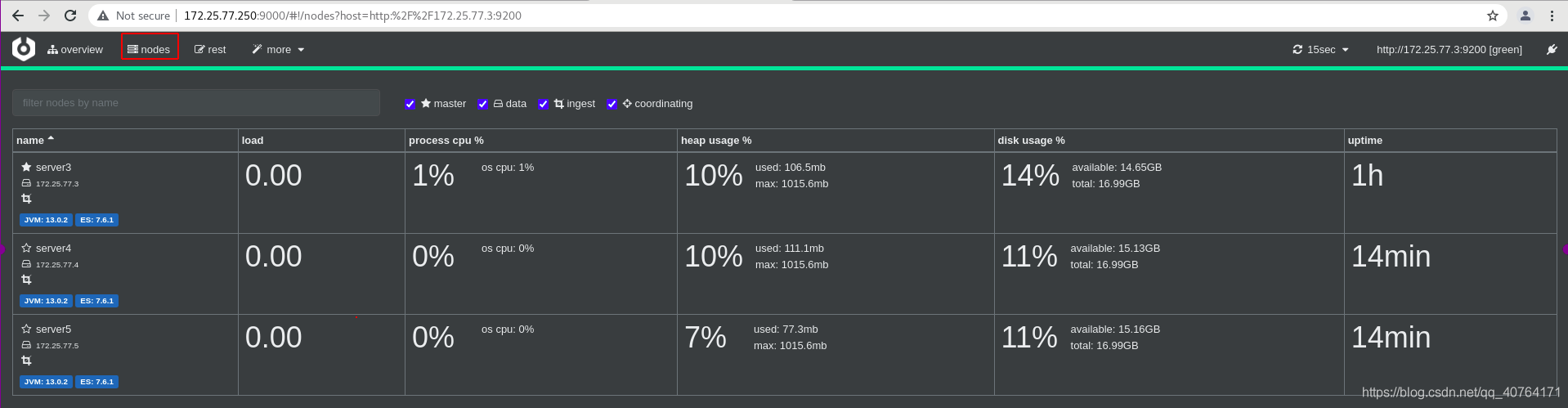
成功進入cerebro,點擊nodes,可以看到集群中三個節點都在
5、elasticsearch可視化方法2——elasticsearch-head插件
elasticsearch-head是elasticsearch自帶插件
下載elasticsearch-head插件,官網https://github.com/mobz/elasticsearch-head/archive/master.zip;head插件本質上是一個nodejs的工程,因此需要安裝nodejs,https://mirrors.tuna.tsinghua.edu.cn/nodesource/rpm_9.x/el/7/x86_64/nodejs-9.11.2-1nodesource.x86_64.rpm
先安裝nodejs,由于master.zip需要解壓工具,所以安裝unzip
解壓master.zip
進入解壓目錄elasticsearch-head-master,由于npm慢,所以更換為cnpm源,查看版本號
安裝bzip2,(安裝cnpm需要用到)
安裝cnpm
進入_site/子目錄,查看app.js檔案
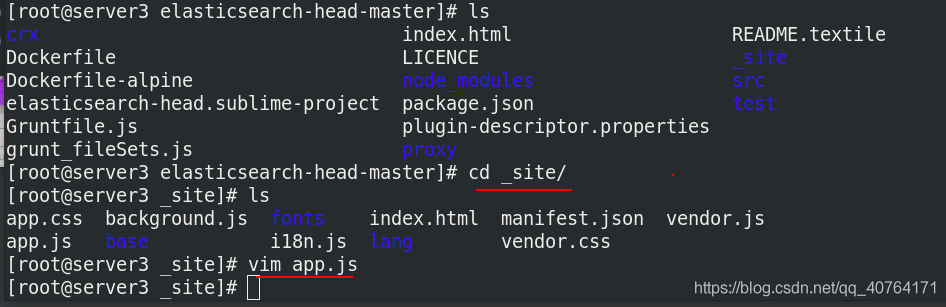
可以看到監控的是9200埠
server3后臺運行head插件,他的埠是9100
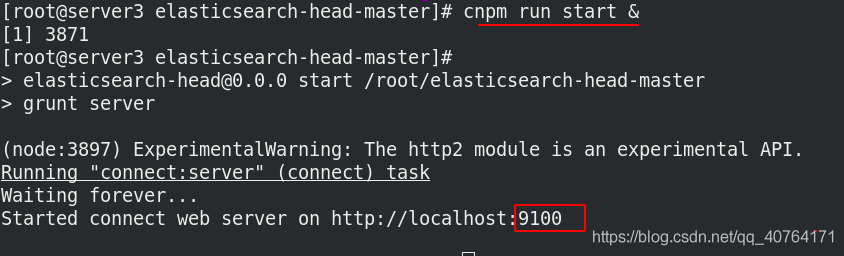
開啟埠為9100

進入/etc/elasticsearch目錄,修改主組態檔elasticsearch.yml

允許跨域,*表示支持所有域名
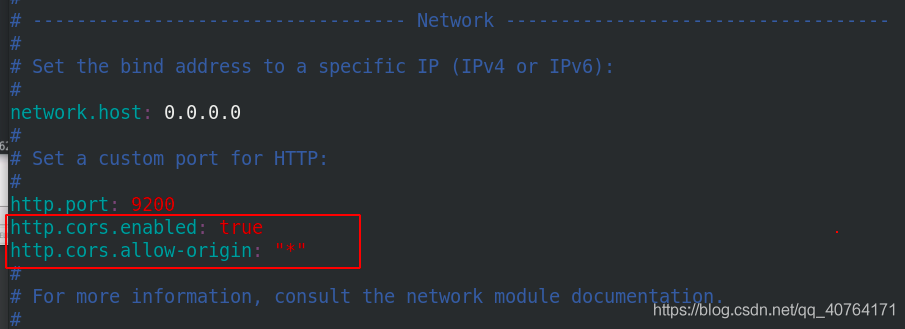
重啟elasticsearch

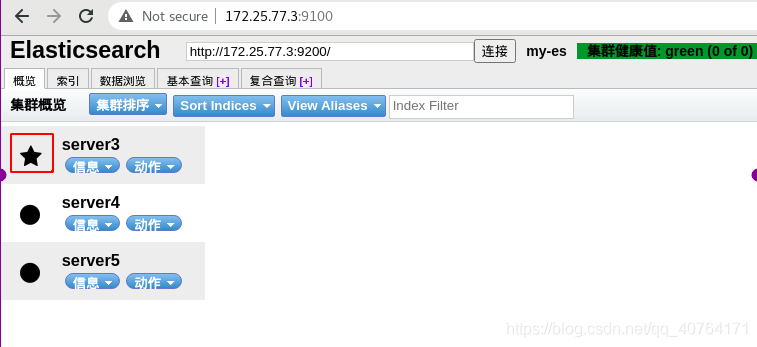
網頁訪問http://172.25.77.3:9100,監控http://172.25.77.3:9200的elasticsearch,可以看到集群的三個節點,*代表master節點
6、elasticsearch節點角色
| 節點角色 | 功能 |
|---|---|
| Master | 主要負責集群中索引的創建、洗掉以及資料的Rebalance等操作,Master不負責資料的索引和檢索,所以負載較輕,當Master節點失聯或者掛掉的時候,ES集群會自動從其他Master節點選舉出一個Leader |
| Data Node | 主要負責集群中資料的索引和檢索,一般壓力比較大 |
| Coordinating Node | 原來的Client node的,主要功能是來分發請求和合并結果的,所有節點默認就是Coordinating node,且不能關閉該屬性 |
| Ingest Node | 專門對索引的檔案做預處理 |
在生產環境下,如果不修改elasticsearch節點的角色資訊,在高資料量,高并發的場景下集群容易出現腦裂等問題,默認情況下,elasticsearch集群中每個節點都有成為主節點的資格,也都存盤資料,還可以提供查詢服務,
節點角色是由以下屬性控制
- node.master: 這個屬性表示節點是否具有成為主節點的資格(注意:此屬性的值為true,并不意味著這個節點就是主節點,只意味著有成為主節點的資格,因為真正的主節點,是由多個具有主節點資格的節點進行選舉產生的)
- node.data: 這個屬性表示節點是否存盤資料
- node.ingest: 是否對檔案進行預處理
- search.remote.connect: 是否禁用跨集群查詢
默認情況下這些屬性的值都是true
生產集群中可以對這些節點的職責進行劃分,專人負責專事
(1)建議集群中設定3臺以上的節點作為master節點,這些節點只負責成為主節點,維護整個集群的狀態,
(2)再根據資料量設定一批data節點,這些節點只負責存盤資料,后期提供建立索引和查詢索引的服務,這樣的話如果用戶請求比較頻繁,這些節點的壓力也會比較大,
(3)在集群中建議再設定一批協調節點,這些節點只負責處理用戶請求,實作請求轉發,負載均衡等功能,
下面簡單測驗,
server4編輯主編組態檔/etc/elasticsearch/elasticsearch.yml,添加node.data: false陳述句,表示該主機不存放資料
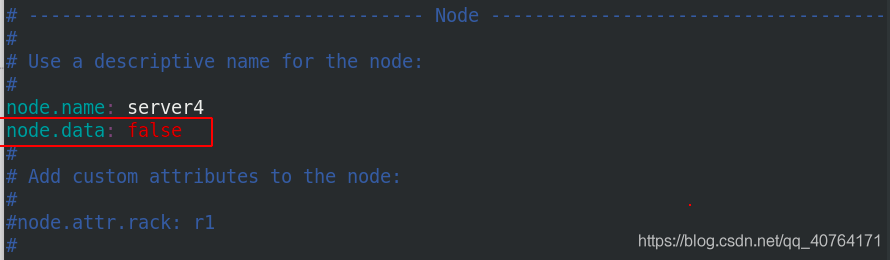
重啟elasticsearch服務
可以看到server4現在沒有data角色
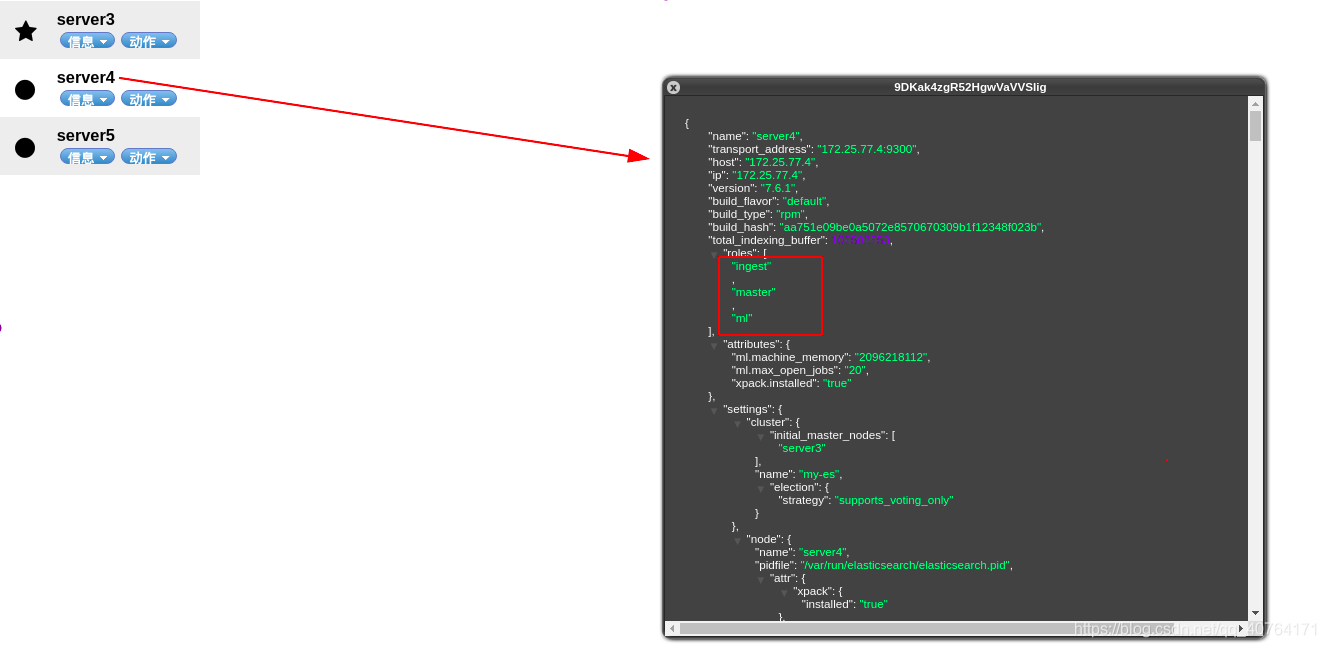
而server3有data角色
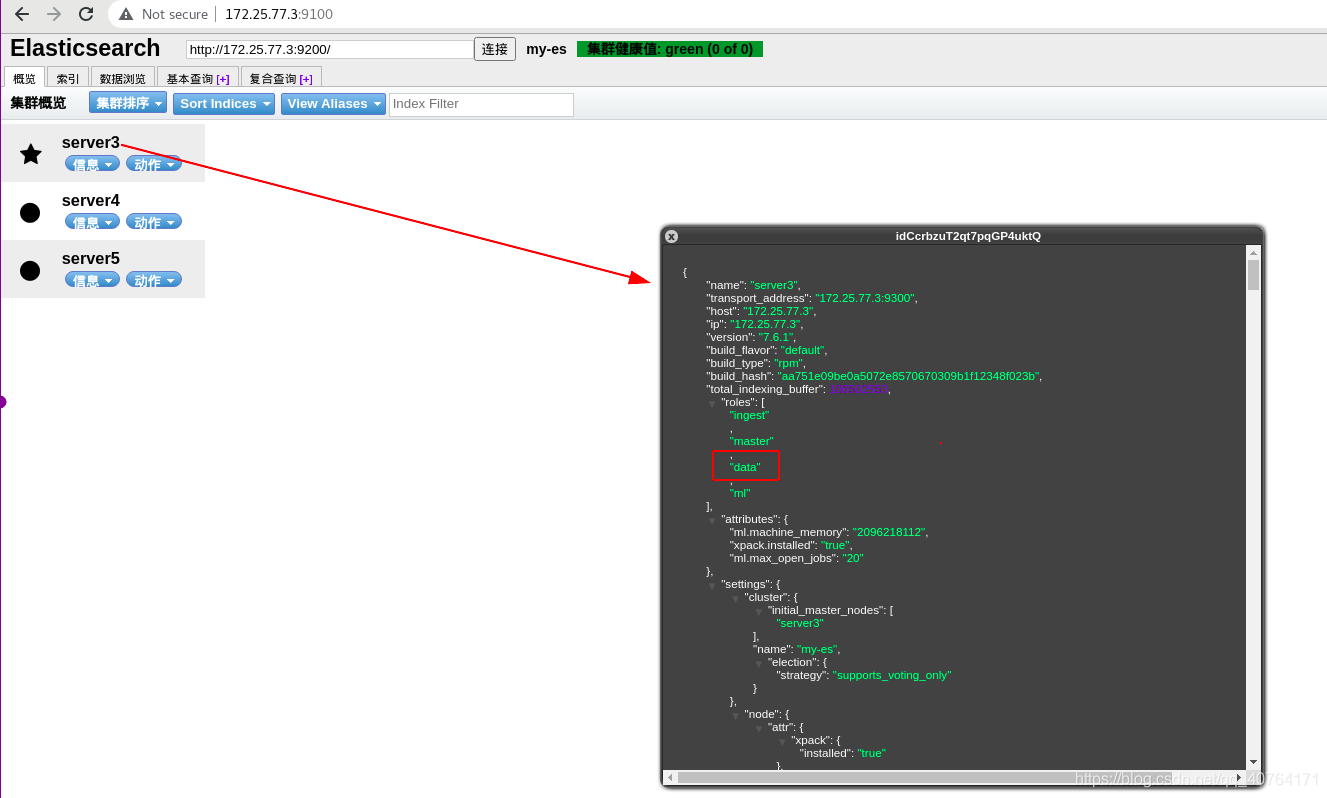
其他的角色都可以測驗,本文不再贅述
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/293903.html
標籤:其他
上一篇:通過Logstash全量和增量同步Mysql一對多關系到Elasticsearch
下一篇:Spark核心編程