資料結構
資料結構分為兩大類,線性結構和非線性結構,
- 線性結構:陣列、佇列、鏈表、堆疊
- 非線性結構:多維陣列、樹結構、圖結構
1.陣列
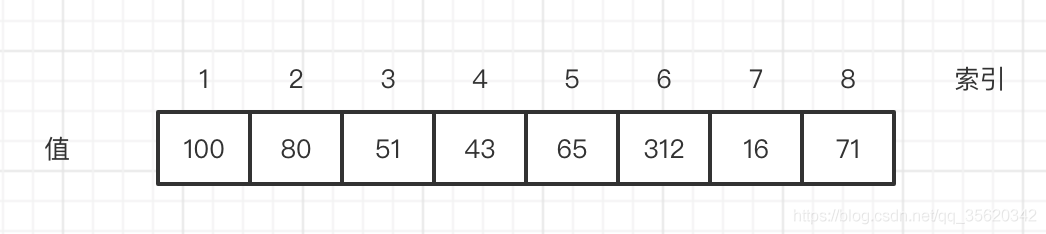
陣列是最常用的資料結構,用于存盤相同型別的資料,陣列的長度也是固定的,
陣列是有序的,存盤是按照先后順序進行的,陣列中的元素存盤在一個連續性的記憶體塊中,我們可以通過value和索引進行資料的訪問和更新,如圖所示:
優點:
①通過下標方式訪問元素,速度快,時間復雜度o(1),
②對于有序陣列,還可以使用二分查找提高檢索速度
缺點:
①插入、洗掉操作效率較低
②如果要檢索具體某一個值,需要遍歷所有效率較低,
時間復雜度:
查詢:o(1)
插入:o(n)
洗掉:o(n)
2.鏈表
鏈表是以節點的方式來存盤,每個節點包含資料和next指標,
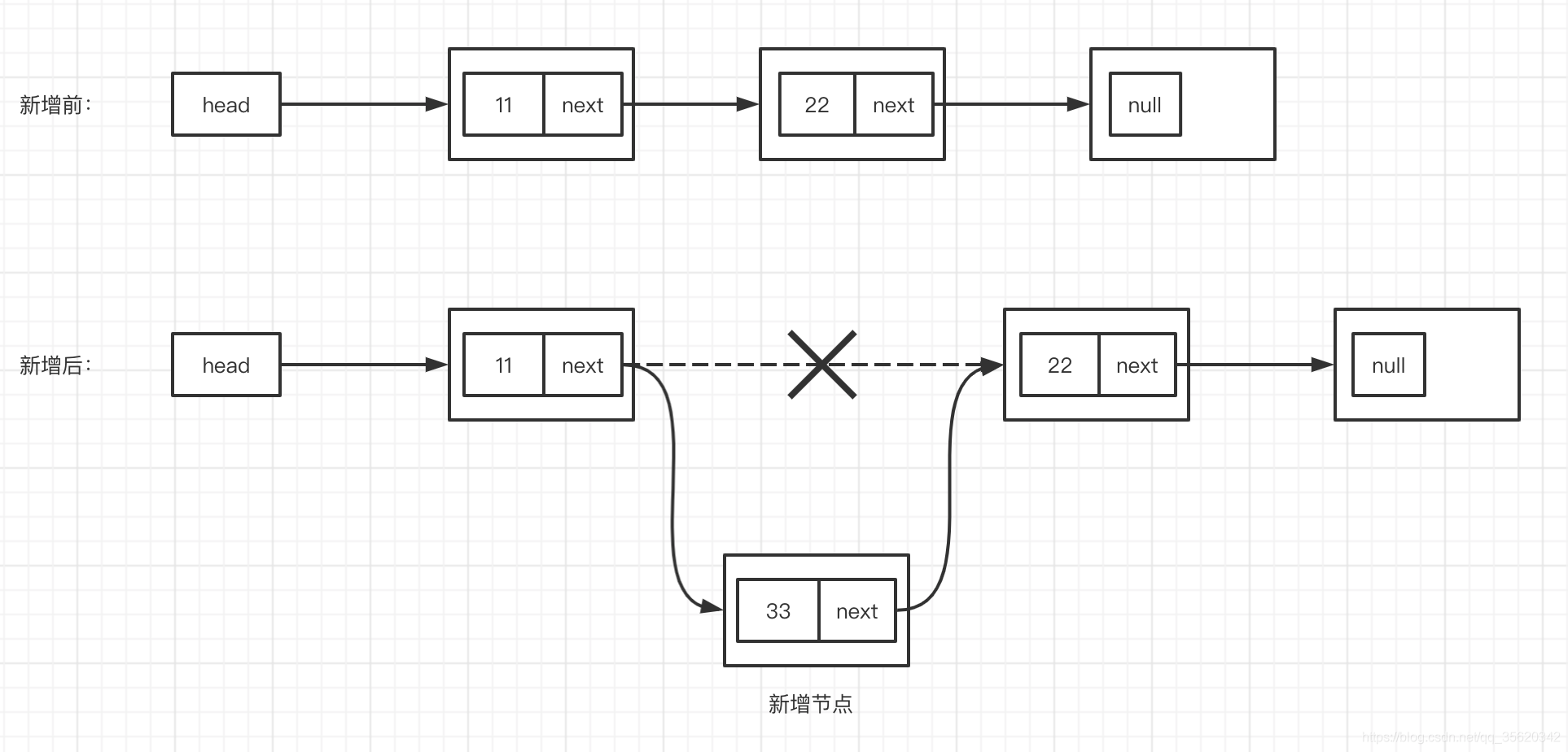
單向鏈表
插入:找到要插入的位置,把前面一個元素next指向新節點,新節點把next指向后面一個元素
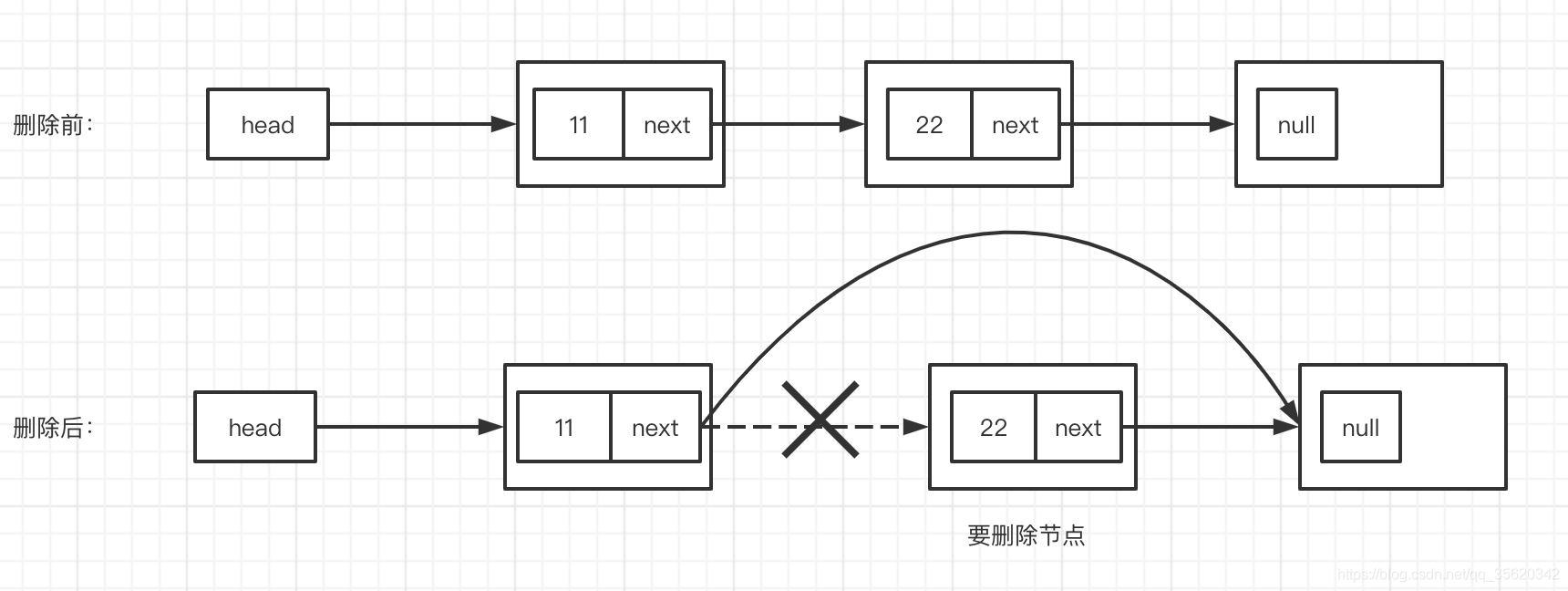
洗掉:把前面一個元素的next指向后面一個元素
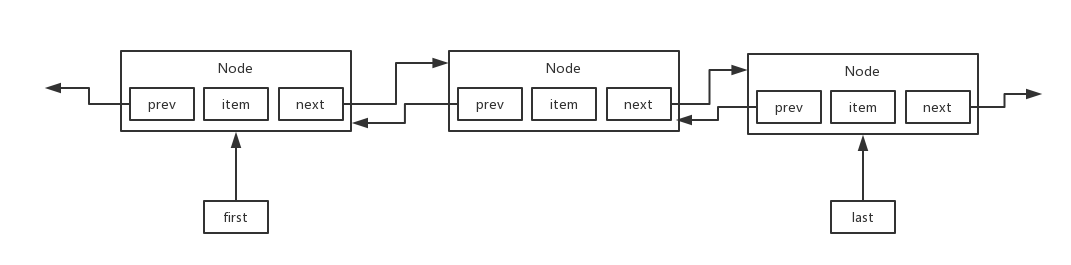
雙向鏈表
item是元素,prev、next是指標
插入元素的原理
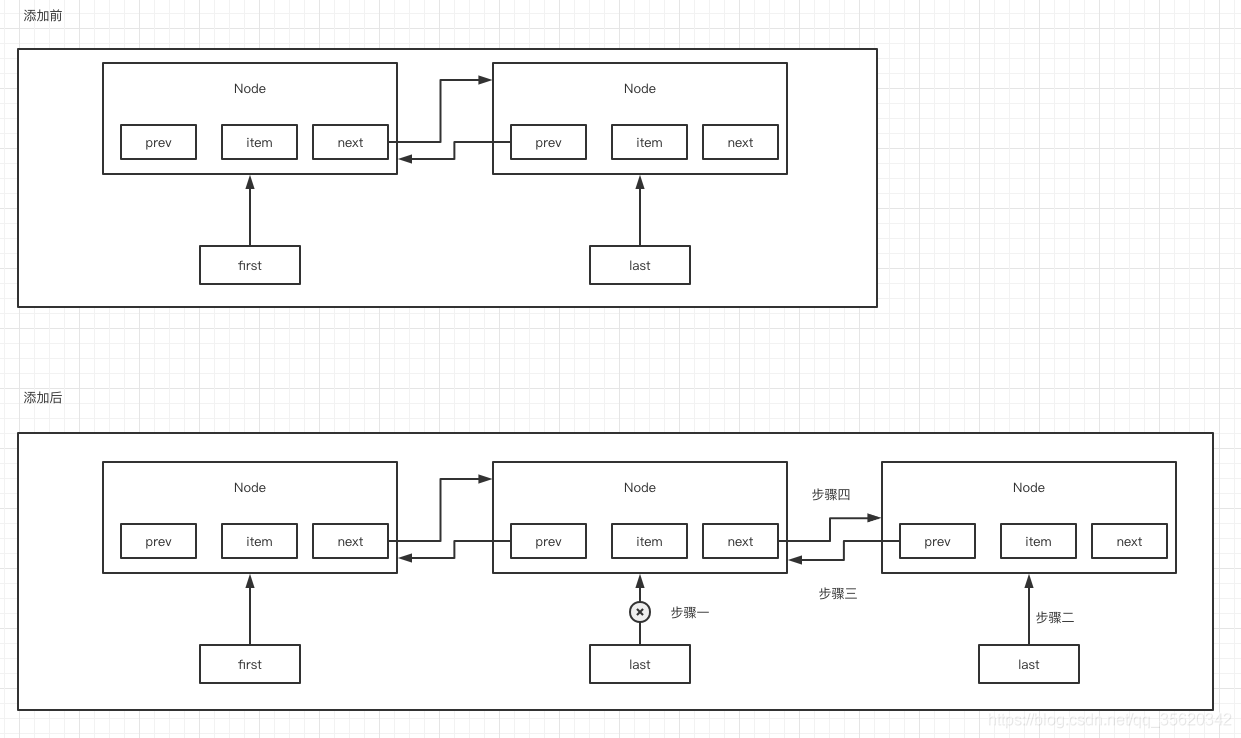
(1)尾部插入
add(),默認就是在佇列的尾部插入一個元素,在那個雙向鏈表的尾部插入一個元素
addLast(),跟add()方法是一樣的,也是在尾部插入一個元素
public boolean add(E e) {
linkLast(e);
return true;
}
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
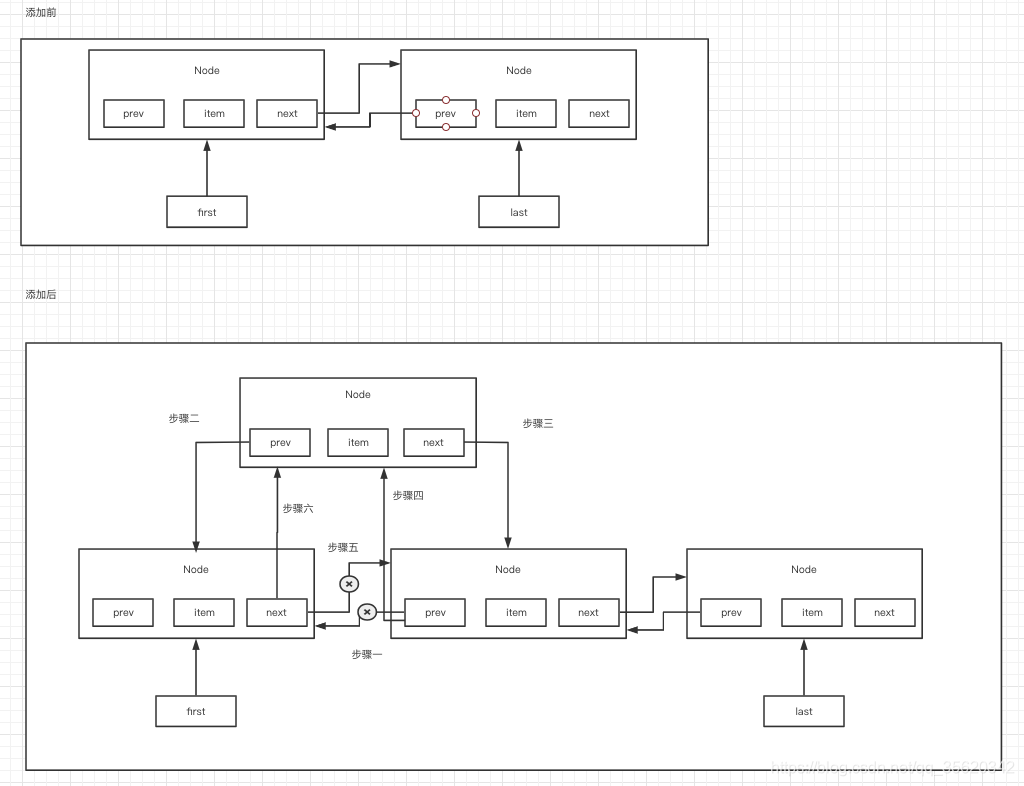
(2)佇列中間插入
add(index, element),是在佇列的中間插入一個元素
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
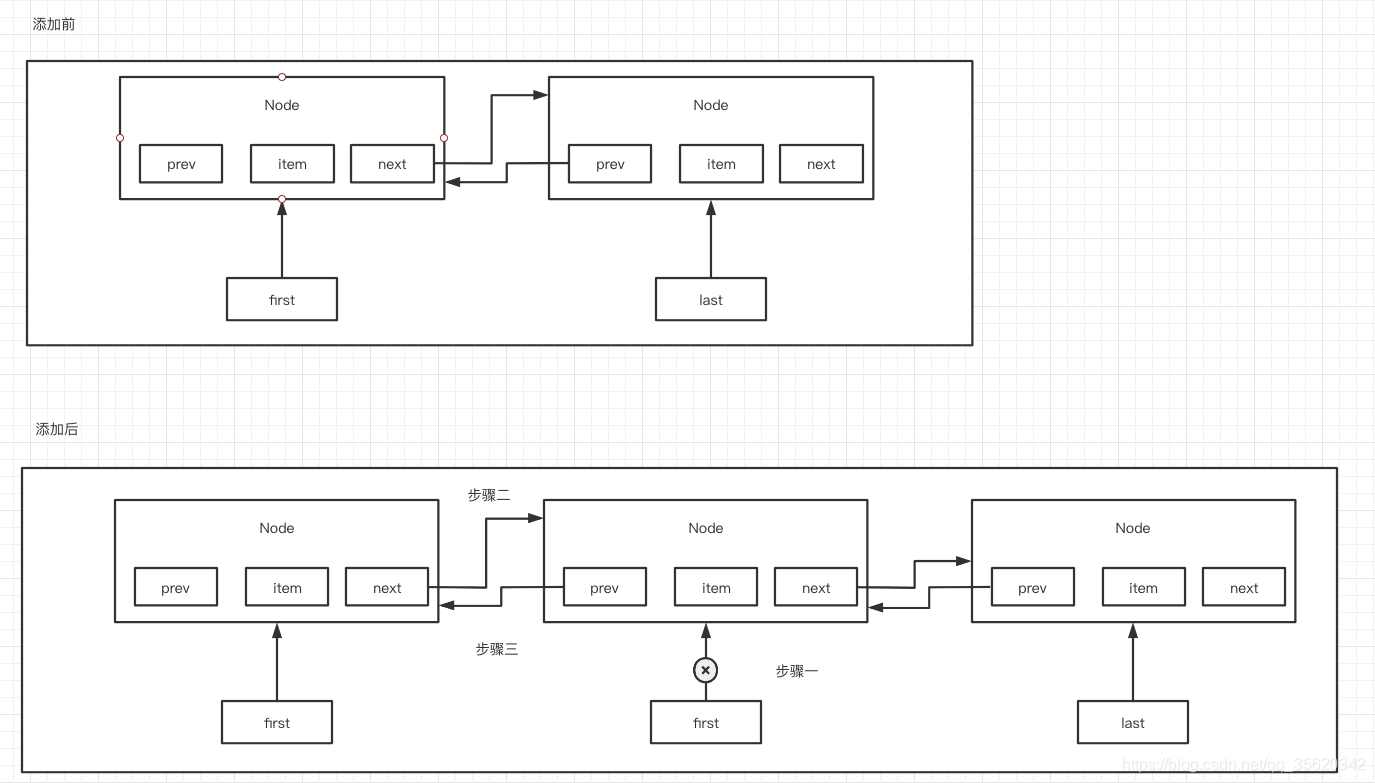
(3)頭部插入
addFirst(),在佇列的頭部插入一個元素
public void addFirst(E e) {
linkFirst(e);
}
private void linkFirst(E e) {
final Node<E> f = first;
final Node<E> newNode = new Node<>(null, e, f);
first = newNode;
if (f == null)
last = newNode;
else
f.prev = newNode;
size++;
modCount++;
}
獲取元素的原理
(1)獲取頭部元素
getFirst() 獲取頭部的元素,他其實就是直接回傳first指標指向的那個Node他里面的資料,他們都是回傳頭部的元素,getFirst()如果是對空list呼叫,會拋例外;peek()對空list呼叫,會回傳null
(2)獲取尾部元素
getLast():獲取尾部的元素,他其實就是直接回傳last指標指向的那個Node他里面的資料
public E getLast() {
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return l.item;
}
(3)獲取中間的元素
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
對于雙向鏈表而言,get(int index)這個方法,是他的弱項,也是他的缺點,如果他要獲取某個隨機位置的元素,需要使用node(index)這個方法,是要進行鏈表的遍歷,會判斷一下index和size >> 1進行比較,如果在前半部分,就會從頭部開始遍歷;如果在后半部分,就會從尾部開始遍歷
洗掉元素的原理
(1)洗掉尾部
(2)洗掉頭部
(3)洗掉中間的元素
新增和洗掉差不多,理解了新增,洗掉就so easy了,在這里我就不詳細說明了,
鏈表的優缺點:
優點:插入、洗掉效率較高,時間復雜度o(1)
缺點:查詢較慢,時間復雜度為o(n)
3.堆疊
堆疊stack:先入后出FILO(first in last out)
Push 推送:在堆疊頂部插入一個元素,
Pop 彈出:洗掉最上面的元素并回傳,
用佇列實作堆疊,LeetCode鏈接:https://leetcode-cn.com/problems/implement-stack-using-queues/solution/yong-dui-lie-shi-xian-zhan-by-leetcode-solution/
LeetCode里有動態程序圖,在這里我就不畫了,大家可以點開鏈接查看,
陣列實作堆疊
public class ArrayStack {
private int maxSize;// 最大的尺寸
private int[] stack;// 使用陣列模擬
private int top = -1;// 堆疊指標 , 初始為-1
public ArrayStack(int maxSize) {// 初始化
this.maxSize = maxSize;
stack = new int[this.maxSize];
}
// 判斷是否為空
public boolean isEmpty(){
return top == -1;
}
// 判斷是否為滿
public boolean isFull(){
return top == maxSize - 1;
}
// 進堆疊
public void push(int value){
// 判斷滿堆疊
if(isFull()){
System.out.println("堆疊滿~~");
return;
}
top++;
stack[top] = value;
}
// 出堆疊 -- 從堆疊頂出堆疊
public int pop(){
if(top == -1){
throw new RuntimeException("堆疊空~~");
}
int value = stack[top];
top--;
return value;
}
// 遍歷堆疊 == 從堆疊頂開始遍歷
public void stackList(){
if(isEmpty()){
throw new RuntimeException("堆疊空~~");
}
for (int i = 0; i < maxSize ; i++) {
System.out.printf("stack[%d]=%d\n",i,stack[i]);
}
}
}
public static void main(String[] args) {
// 初始化堆疊
ArrayStack arrayStack = new ArrayStack(5);
// 入堆疊
arrayStack.push(1);
arrayStack.push(2);
arrayStack.push(5);
arrayStack.push(8);
arrayStack.push(6);
// 遍歷
arrayStack.stackList();
// 出堆疊
int value1 = arrayStack.pop();
System.out.println(value1);
}
鏈表實作堆疊
/**
* 用單鏈表實作堆疊
* 表示鏈表的一個節點
*/
public class Node {
Object element;
Node next;
public Node(Object element){
this(element,null);
}
/**
* 創建一個新的節點
* 讓他的next指向,引數中的節點
* @param element
* @param n
*/
public Node(Object element,Node n){
this.element=element;
next=n;
}
public Object getElement() {
return element;
}
}
public class ListStack {
Node header;//堆疊頂元素
int elementCount;//堆疊內元素個數
int size;//堆疊的大小
/**
* 建構式,構造一個空的堆疊
*/
public ListStack(){
header=null;
elementCount=0;
size=0;
}
/**
* 通過構造器自定義堆疊的大小
* @param size
*/
public ListStack(int size) {
header=null;
elementCount=0;
this.size=size;
}
public void setHeader(Node header) {
this.header=header;
}
public boolean isFull() {
if (elementCount==size) {
return true;
}
return false;
}
public boolean isEmpty() {
if (elementCount==0) {
return true;
}
return false;
}
/**
* 入堆疊
* @param value
*/
public void push(Object value) {
if (this.isFull()) {
throw new RuntimeException("Stack is Full");
}
//注意這里面試將原來的header作為引數傳入,然后以新new出來的Node作為header
header=new Node(value, header);
elementCount++;
}
/**
* 出堆疊
* @return
*/
public Object pop() {
if (this.isEmpty()) {
throw new RuntimeException("Stack is empty");
}
Object object=header.getElement();
header=header.next;
elementCount--;
return object;
}
/**
* 回傳堆疊頂元素
*/
public Object peak(){
if (this.isEmpty()) {
throw new RuntimeException("Stack is empty");
}
return header.getElement();
}
}
時間復雜度:
查找:o(n)
插入:o(1)
洗掉:o(1)
堆疊的應用場景:
- 子程式的呼叫:在跳往子程式前,會先將下個指令的地址存到堆疊中,直到子程式執行完后再將地址取出,以回到原來的程式中,(學過JVM的同學是不是很熟悉)
- 處理遞回呼叫:和子程式的呼叫類似,只是除了存盤下一個指令的地址外,也將引數、區域變數等資料存入堆疊中,
4.佇列
佇列queue:先入先出FIFO(first in first out)
用堆疊實作佇列,LeetCode鏈接:https://leetcode-cn.com/problems/implement-queue-using-stacks/solution/yong-zhan-shi-xian-dui-lie-by-leetcode/
用陣列和鏈表實作佇列,LeetCode鏈接:https://leetcode-cn.com/problems/design-circular-queue/solution/she-ji-xun-huan-dui-lie-by-leetcode/
具體思路和代碼可以在LeetCode上查看,寫的挺好的,而且有動態的程序圖,我這里就不重復闡述了,
時間復雜度:
查找:o(n)
插入:o(1)
洗掉:o(1)
5.二叉樹
這里我給大家推薦一個非常棒的網站https://www.cs.usfca.edu/~galles/visualization/Algorithms.html,他可以看所有資料結構的演變程序,對于資料結構學習來說,非常重要,
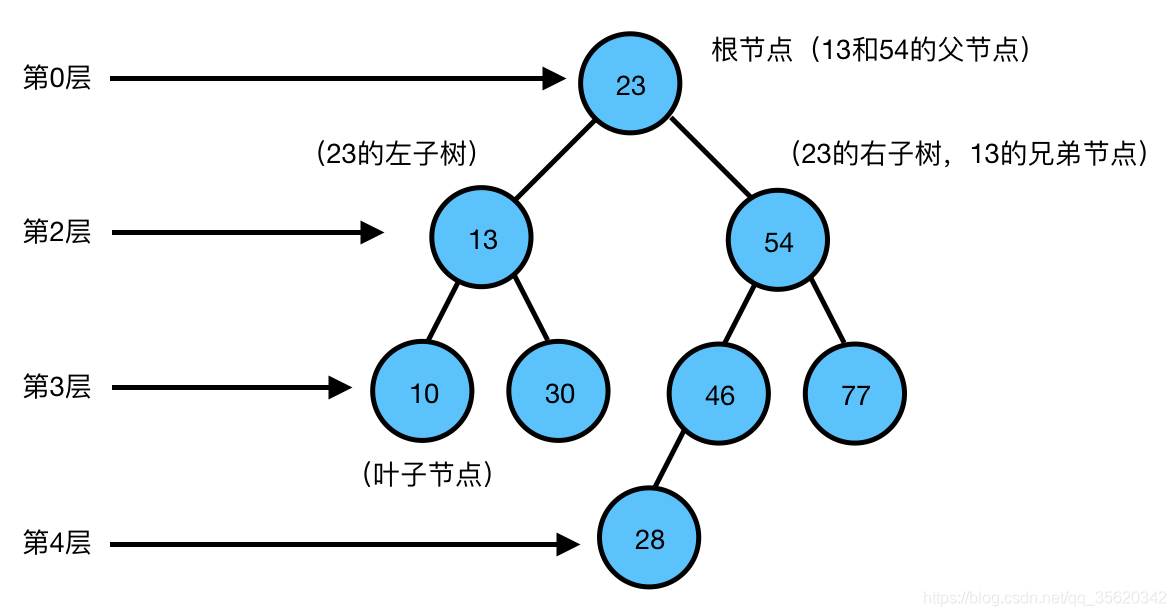
二叉樹:二叉樹是每個節點最多有兩個子樹的樹結構,
根節點:一棵樹最上面的節點稱為根節點,
父節點、子節點:如果一個節點下面連接多個節點,那么該節點稱為父節點,它下面的節點稱為子節點,例如23是13的父節點,13是10的父節點,13和54都是23的子節點,
葉子節點:沒有任何子節點的節點稱為葉子節點,例如10、30、28、77都是葉子節點,
兄弟節點:具有相同父節點的節點互稱為兄弟節點, 例如13和54都是23的子節點,那么13和54就是兄弟節點,
節點度:就是節點下子樹個樹,上圖中,13的度為2,46的度為1,28的度為0,
節點的權:節點的值
樹的深度:從根節點開始(其深度為0)自頂向下逐層累加的,上圖中,13的深度是1,30的深度是2,28的深度是3,
樹的高度:從葉子節點開始(其高度為0)自底向上逐層累加的,54的高度是2,根節點23的高度是3,
對于樹中相同深度的每個節點來說,它們的高度不一定相同,這取決于每個節點下面的葉子節點的深度,上圖中,13和54的深度都是1,但是13的高度是1,54的高度是2,
6.二叉搜索樹
左子樹上所有節點的值均小于它的根節點的值
右子樹上所有節點的值均大于它的根節點的值
二叉搜索樹:判斷二叉樹是否是搜索樹,滿足左子樹上所有節點的值均小于它的根節點的值且右子樹上所有節點的值均大于它的根節點的值,滿足這兩個條件的二叉樹就是二叉搜索樹,
時間復雜度o(log(n))
遍歷:
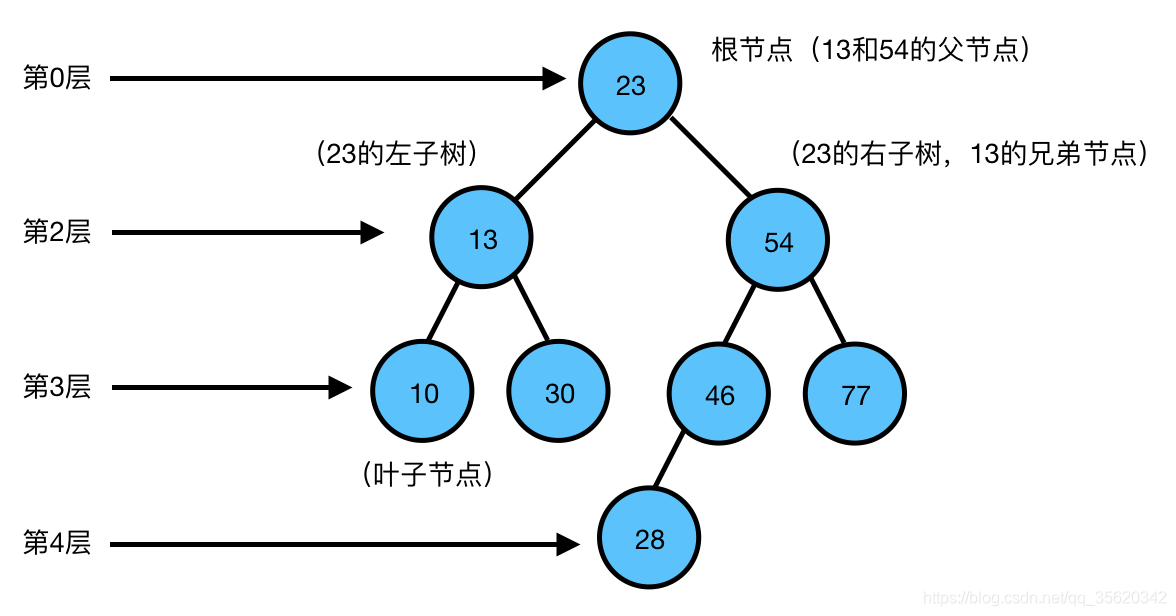
前序:23、13、10、30、54、46、28、77,(根、左、右),先輸出父節點,再遍歷左子樹,再遍歷右子樹
中序:10、13、30、23、28、46、54、77,(左、根、右),先遍歷左子樹,再輸出父節點,再遍歷右子樹
后序:10、30、13、28、46、77、54、23,(左、右、根),先遍歷左子樹,再遍歷右子樹,最后輸出父節點
總結:看輸出父親節點的順序,就可以確定是前序、中序、后序
優點:
①它的檢索效率較高,類似于二分查找,
②它的增刪改效率較高,因為它使用的是指標的方式,不會導致整個結構的移動,
缺點:
假如說沒有左子樹只有右子樹,每次都只有右子樹,之后就會變成一個鏈表,之后時間復雜度會退化成o(n)
7.二叉平衡樹
假如說沒有左子樹只有右子樹,每次都只有右子樹,之后就會變成一個鏈表,之后時間復雜度會退化成o(n),此時平衡二叉樹應運而生,
平衡二叉樹也叫平衡二叉搜索樹,又被稱為AVL樹,
補充:AVL樹得名于它的發明者G. M. Adelson-Velsky和E. M. Landis
特點:
它是一棵空樹或它的左右兩個子樹的高度差的絕對值不超過1,并且左右兩個子樹都是一棵平衡二叉樹,平衡二叉樹的常用實作方法有紅黑樹、AVL(演算法)、替罪羊樹、Treap、伸展樹,
當左子樹高度-右子樹高度>1,向右旋轉,目的是降低左子樹高度,
當右子樹高度-左子樹高度>1,向左旋轉,目的是降低右子樹高度,
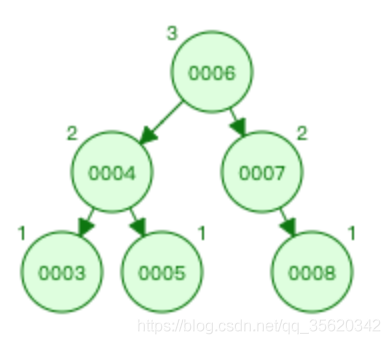
左選擇前:
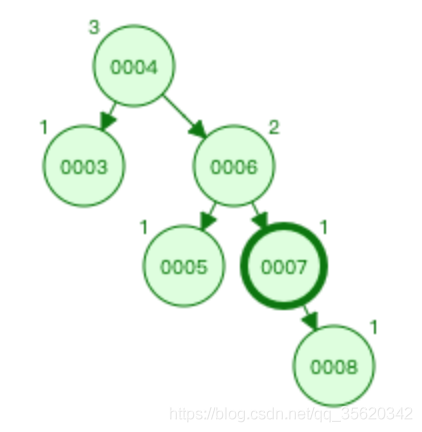
左選擇后:
8.平衡二叉樹之2-3樹
2-3樹是最簡單的B樹結構,其特點如下:
①所有的葉子節點都在同一層(只要是B樹都滿足這一條件)
補充:添加節點永遠不會添加到一個為空的位置,插入一個新節點,小于根節點插入到根節點左子樹,若左子樹為空,則新節點融合到根節點左邊
②有兩個子節點的節點叫做二節點,二節點要么沒有子節點,要么有兩個子節點
③有三個子節點的節點叫做三節點,三節點要么沒有子節點,要么有三個子節點
④2-3樹由二節點和三節點構成的樹,2就代表二節點,3就代表三節點
補充:2-3樹滿足二分搜索樹的基本性質
2-3名字由來:每個節點有2個或者3個孩子,所以叫2-3樹
多叉樹通過重新組織節點,降低樹的高度,從而提高操作效率,
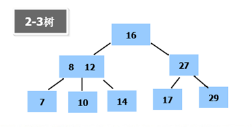
27就是二節點,8、12是三節點
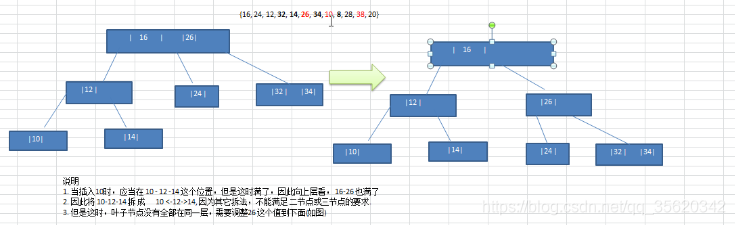
2-3樹是一棵絕對平衡的樹,從根節點到任意一個葉子節點,經過的節點數量是相同的
2-3樹是如何維持絕對的平衡?
1)加入節點:
1.1)二叉搜索樹:
插入一個新節點,小于根節點插入到根節點左子樹,若左子樹為空,則直接成為根節點的左孩子節點
插入數字:42、37、12
1.2)2-3樹:
①插入數字37

解釋:添加節點永遠不會添加到一個為空的位置,插入一個新節點,小于根節點插入到根節點左子樹,若左子樹為空,則新節點融合到根節點左邊
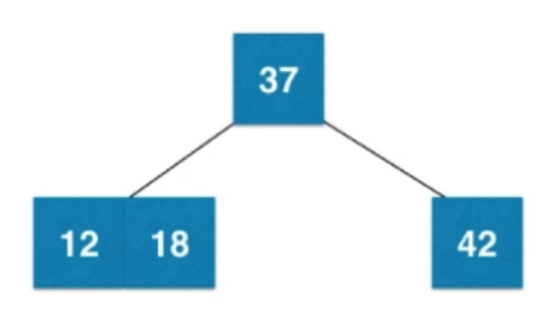
②插入數字12
同上,37的左子樹為空,則新節點融合到根節點左邊,然后形成臨時的4節點,(當節點有三個元素,就可以有4個孩子,但是2-3樹,最多只能有3個孩子,因此需要分裂),之后會進行分裂,如下圖所示:
由 分裂成
分裂成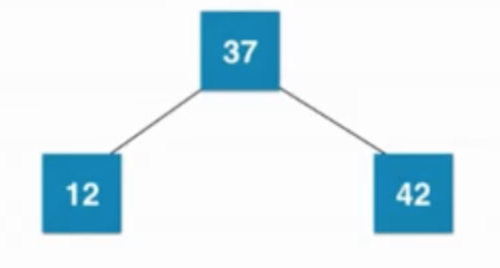
③插入數字18
④插入數字6
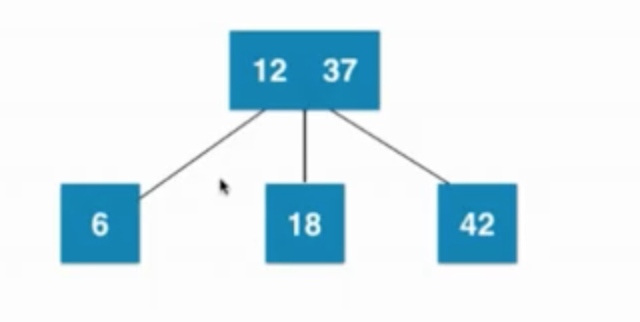
當葉子節點已經是3節點(12、18),父親節點是2節點(37),之后暫時融合成一個臨時4節點,然后再拆分,然后子樹新的根節點是12,12需要向上和父親節點融合
由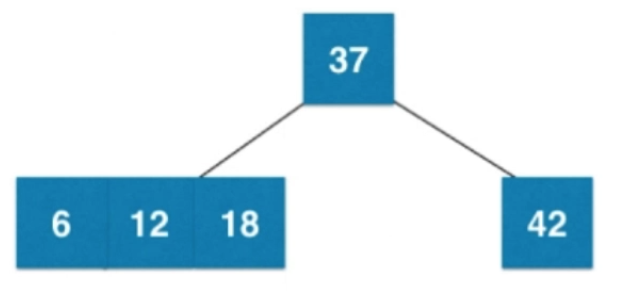 —>
—>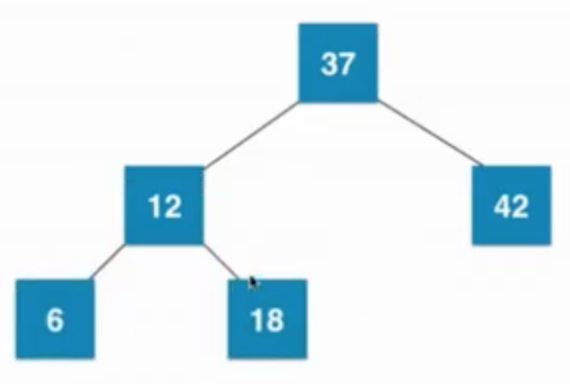 —>
—>
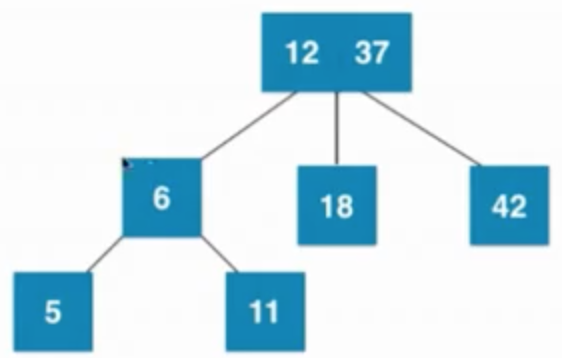
⑤插入數字11
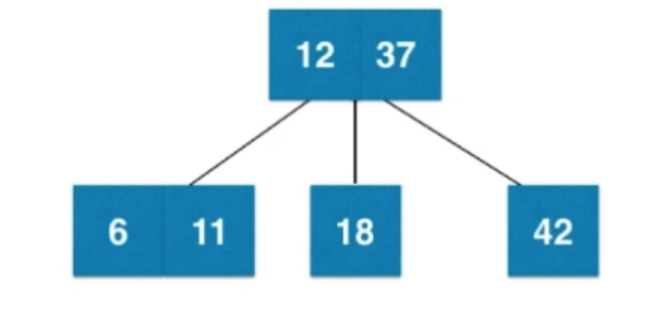
⑥插入數字5
當葉子節點已經是3節點(6、11),父親節點是3節點(12、37),之后暫時融合成4節點,然后再拆分,然后子樹新的根節點是6,6需要向上和父親節點融合,然后暫時融合成一個臨時4節點,之后在拆分成3個2節點組成的子樹
由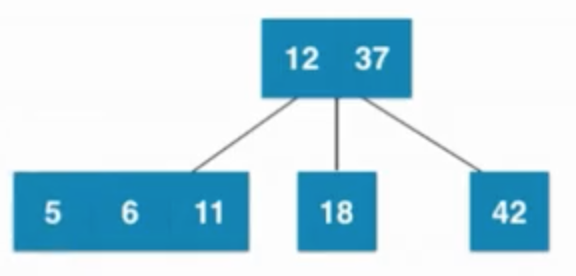 —>
—> —>
—>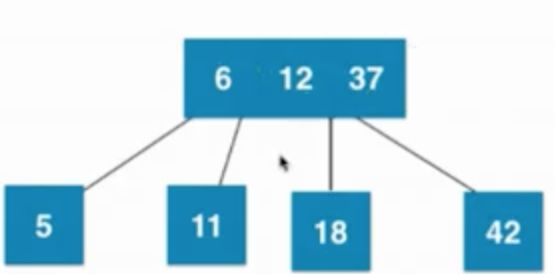 —>
—>
9.紅黑樹
紅黑樹特性:
①每個節點或者是紅色的,或者是黑色的
②根節點是黑色的
③每一個葉子節點(最后的空節點)是黑色的
④如果一個節點是紅色的,那么他的孩子節點都是黑色的
⑤從任意一個節點到葉子節點,經過的黑色節點是一樣的
補充:所有的紅色節點是左傾斜的
案例1:顏色翻轉
①添加數字42
紅黑樹為空,直接把42添加進去,變成黑色

②添加數字37
黑色節點左右子樹為空,直接把37添加進行就行
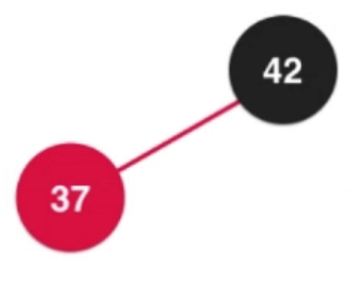
補充:黑色節點左右子樹為空,如果是添加到右子樹,需要進行左旋轉
補充:對應2-3樹的三節點
③添加數字66
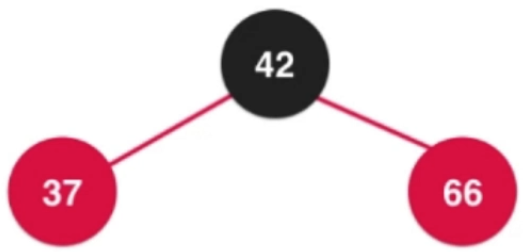 —>
—>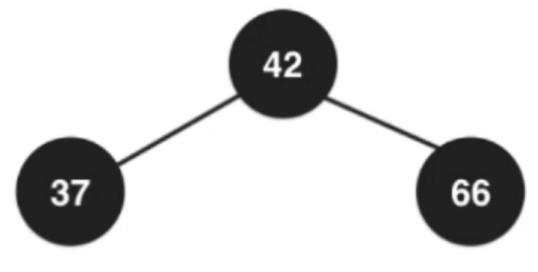 —>
—>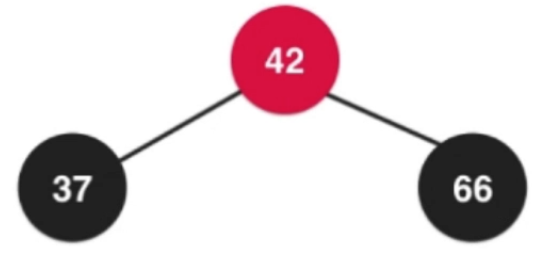
補充:對應2-3樹的四節點
補充:紅色節點指的是,它和它的父親節點是融合在一起的

注意:這里不準確,僅僅是便于理解顏色翻轉,在添加數字66時,不會做翻轉,然后在添加數字77時,才會進行顏色翻轉,翻轉完成后,根節點42是紅色的,需要變成黑色的,
案例2:右旋轉
場景:當左子樹發生傾斜,進行右旋轉
①添加數字42
紅黑樹為空,直接把42添加進去,變成黑色
②添加數字37
黑色節點左右子樹為空,直接把37添加進行就行
補充:對應2-3樹的三節點
③添加數字66
 —>
—>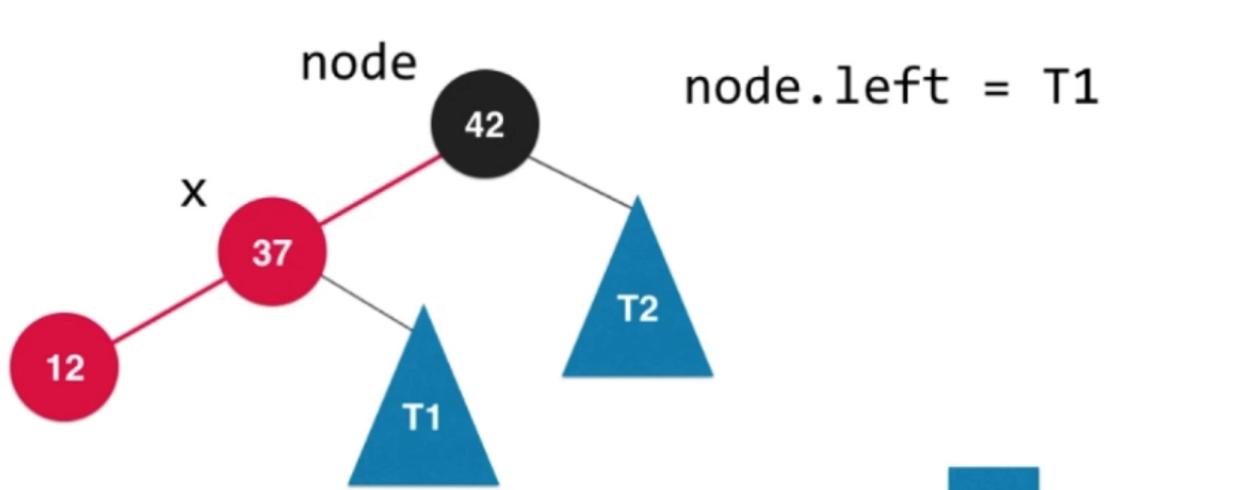 —>
—>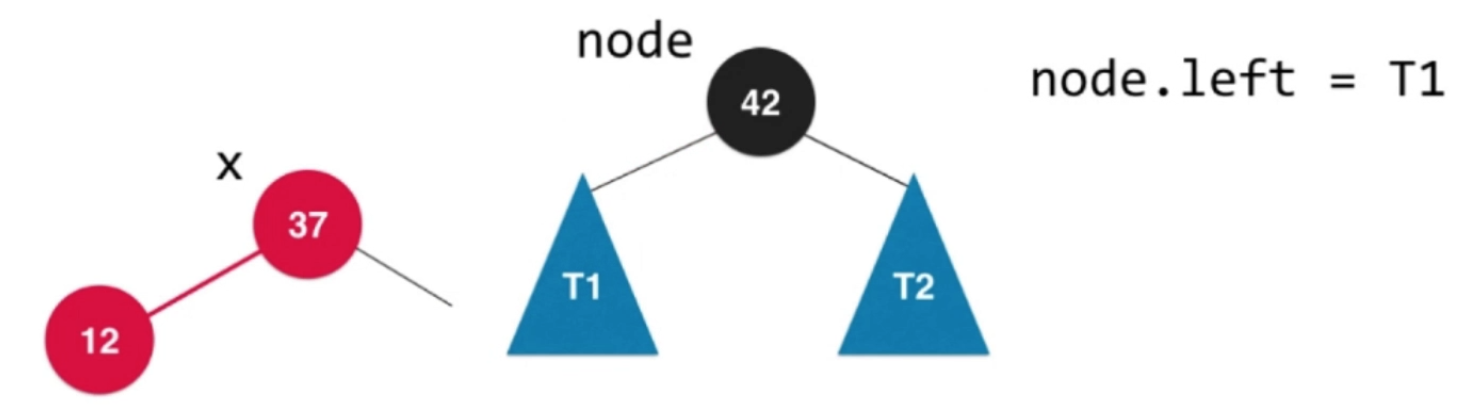 —>
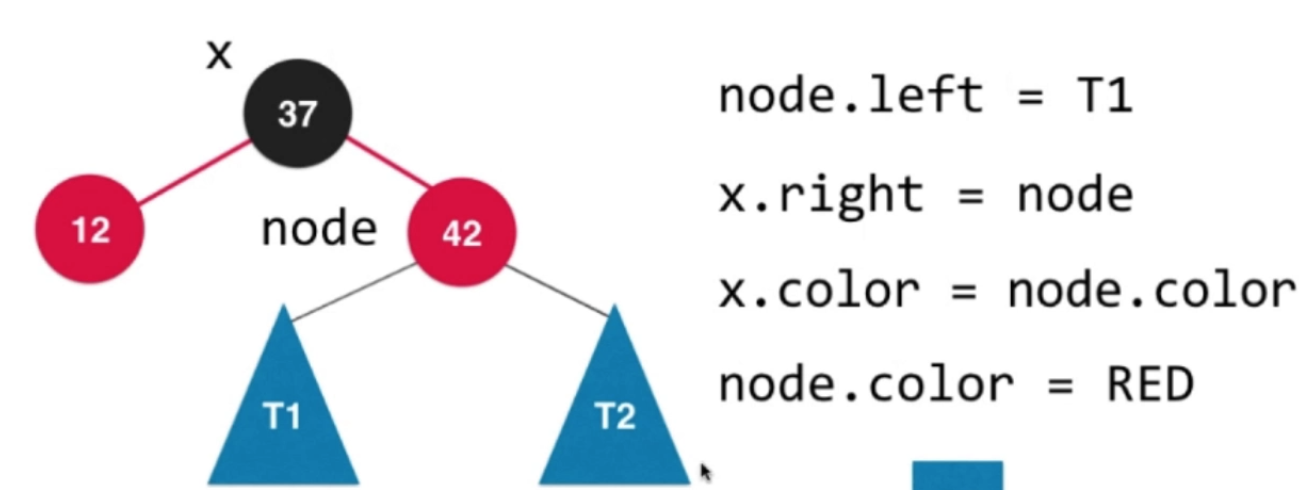
—>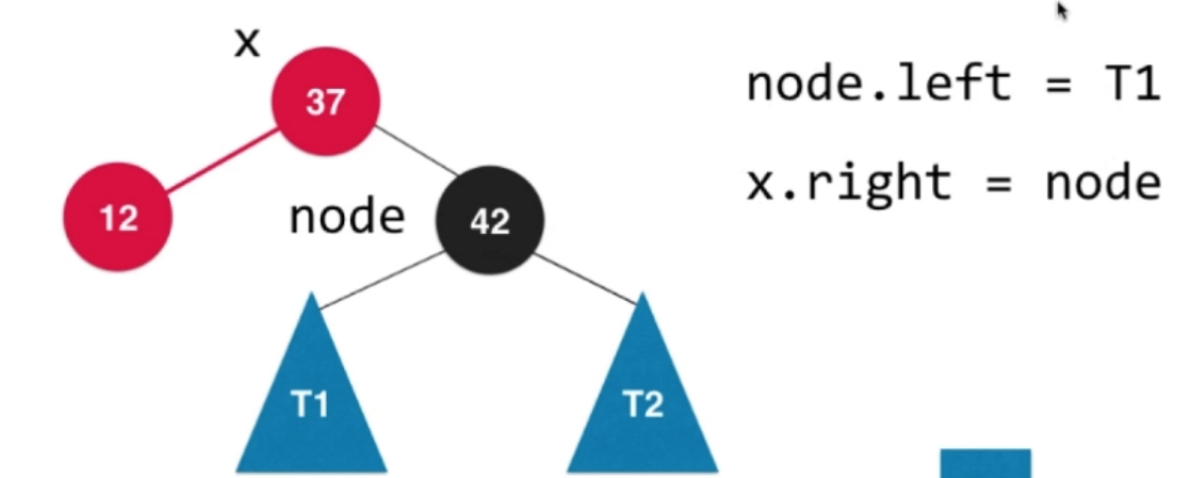 —>
—>
補充:對應2-3樹的四節點
補充:紅色節點指的是,它和它的父親節點是融合在一起的

案例3:復合型
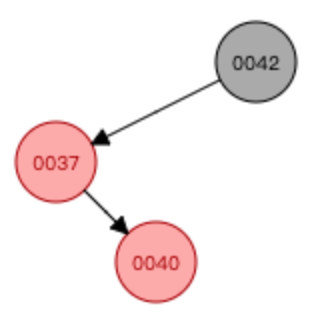 —>
—> —>
—>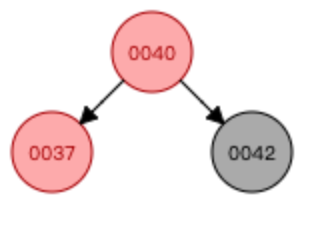 —>
—> 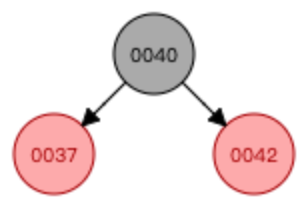
①基于37這個節點進行左旋轉
②基于40這個節點進行右旋轉
③右旋轉結束后,交換顏色
添加數字36
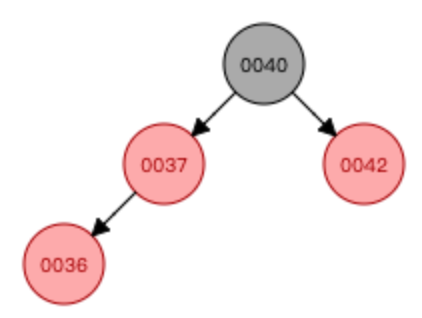 —>
—>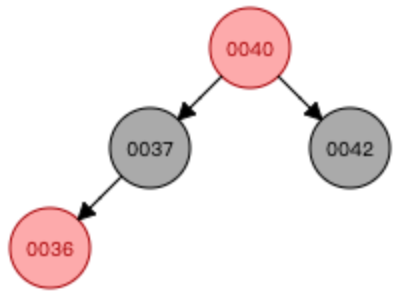 —>
—>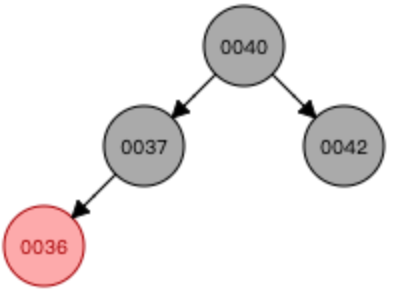
①先進行顏色翻轉(當節點(0036)和父節點(0037)都是紅色,節點叔叔也是紅色時(0042),從祖父母(0040)那里壓低黑度)
②然后根節點是黑色的
10.BTree
2-3樹和2-3-4樹就是B樹
B樹的階:節點的最多子節點個樹,比如2-3樹的階是3,2-3-4樹的階是4,
B-樹的搜索:從根節點開始,對節點內的關鍵字(有序)序列進行二分查找,如果命中則結束,否則進入查詢關鍵字所屬范圍的兒子節點;重復,直到所對應的兒子指標為空,或已經是葉子節點,
關鍵字集合分布在整顆樹中,即葉子節點和非葉子節點都存放資料,搜索可能在非葉子節點結束
其搜索性能等價于在關鍵字全集內做一次二分查找,
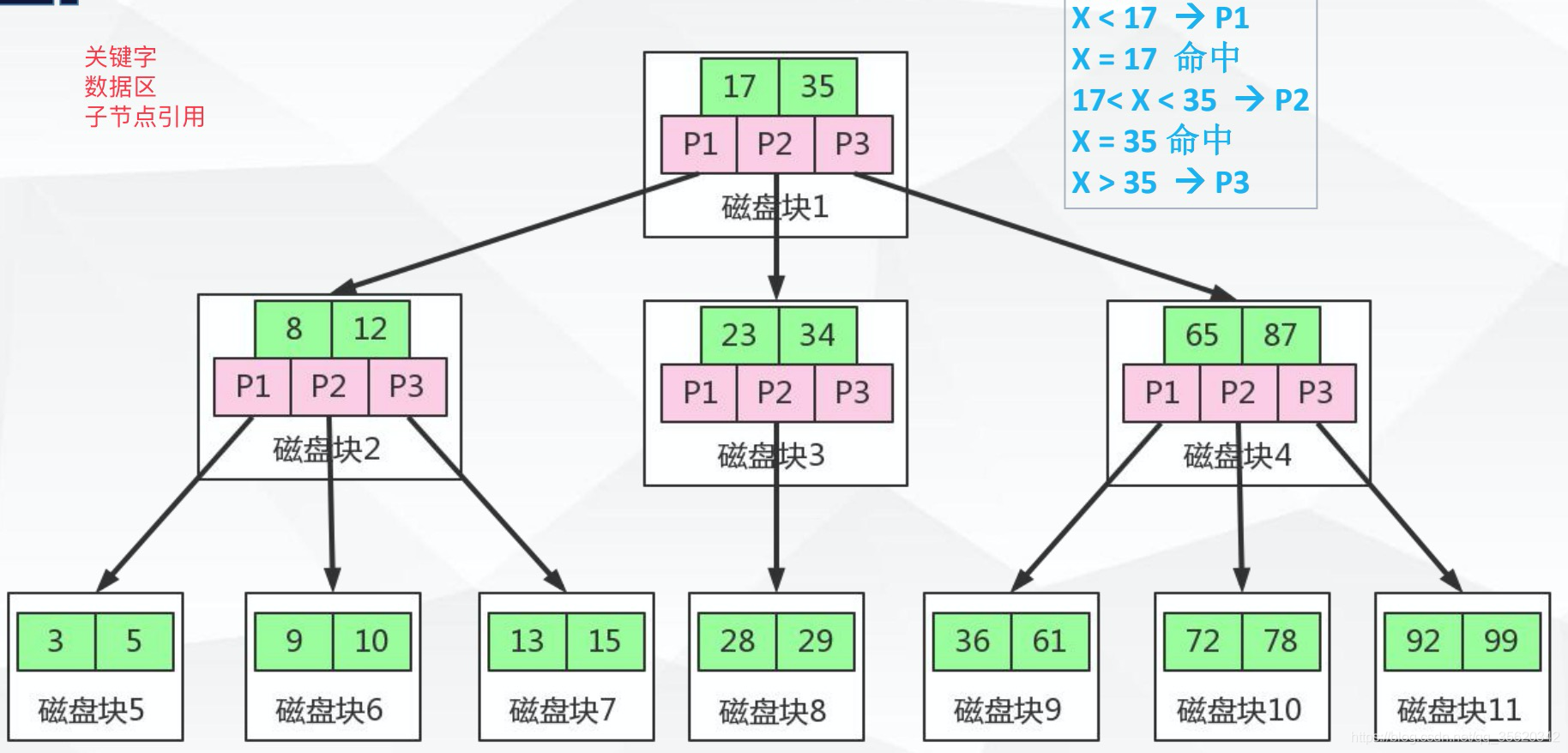
補充:假設檢索15,先把磁盤塊1加載到記憶體中,然后15與17和35比較,15比17小,然后基于P1子節點參考,P1是指向磁盤塊2的一個指標地址,基于P1參考可以通過順序IO快速加載磁盤塊2.然后15與8和12比,15大于12,通過P3子節點參考,加載磁盤塊7,然后命中,基于節點資料區加載資料,
補充:B-Tree首先是一個平衡樹,平衡樹的前提它是一顆搜索樹或排序樹
11.B+樹
B+Tree樹它是B-Tree數的變體,也是一種多路搜索樹
B+Tree和B-Tree基本相同,區別在于B-Tree樹非葉子節點和葉子節點都可以存放資料,而B+Tree樹關鍵字存盤在葉子節點上,非葉子節點不存真正的資料,
補充:
B+Tree非葉子節點只保存關鍵字和子節點參考(指向下一個葉子節點的指標)
葉子之間,增加了鏈表,獲取所有節點,不再需要中序遍歷;
所有的關鍵字都出現在葉子節點的鏈表中,且鏈表中的關鍵字(資料)恰好是有序的(即資料只能在葉子節點(稠密索引),因此不可能在非葉子節點命中)
非葉子節點相當于是葉子節點的索引(稀疏索引),葉子節點相當于是存盤(關鍵字)資料的資料層
更適合檔案索引系統
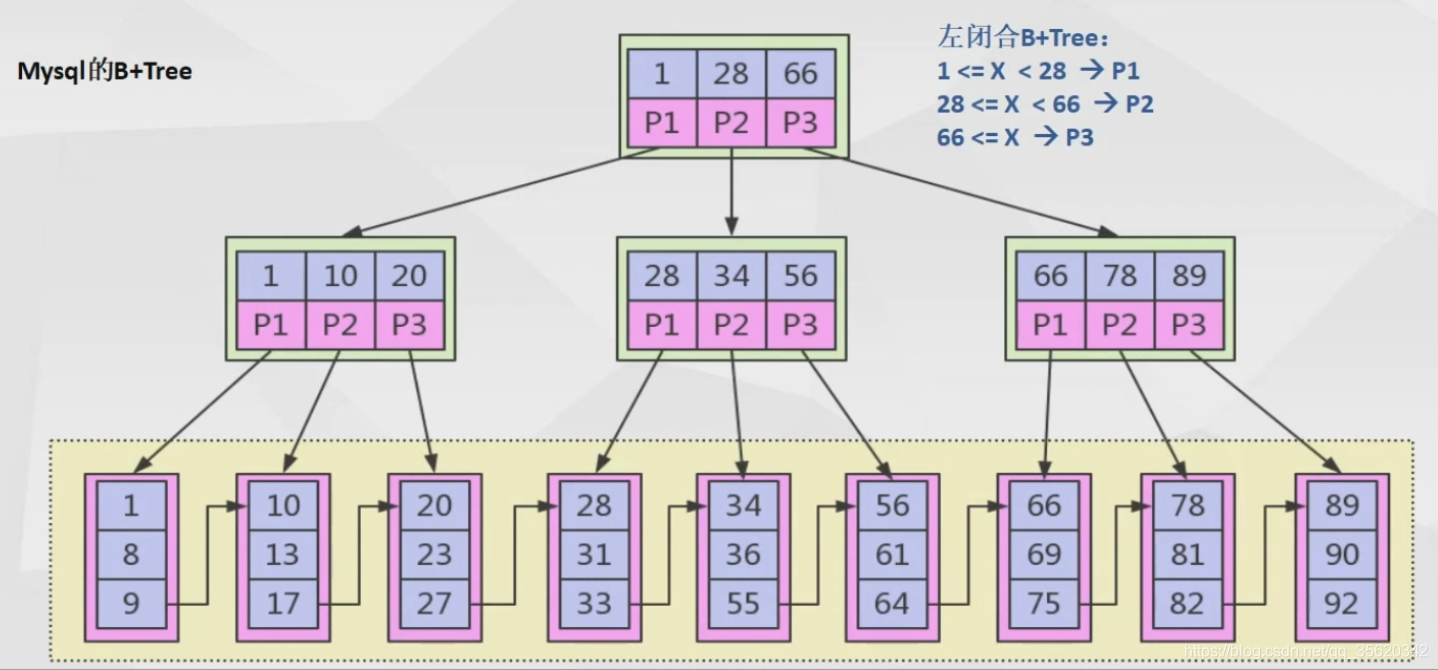
比如查找5,其實圖頂端的5是索引,并不是真實資料,他會繼續往下找,
這里把資料分成段,假如我們要找的資料是35,我們只需要找28指標下的所有子節點,這樣5和65兩塊砍掉,這樣砍掉的是2/3,而二分砍掉的是1/2,
補充:
B+Tree與B-Tree比較
B+Tree掃表和掃庫能力更強(B-Tree樹需要掃描整顆樹,B+Tree樹只需要掃描葉子節點)
B+Tree磁盤讀寫能力更強(葉子節點不保存真實資料,因此一個磁盤塊能保存的關鍵字更多,因此每次加載的關鍵字越多)
B+Tree的排序能力更強
B+Tree的查詢效率更加穩定(B-Tree樹檢索時間與關鍵字所在的樹的高度有必然的關系,可能在第1層很快,可能在第3層或者更高層所耗時間會增加,檢索效率不穩定,而B+Tree樹每次都需要尋址到最后一層)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/293957.html
標籤:其他
上一篇:七夕表白小代碼喜歡的拿去