文章目錄
- 前言
- 概念
- 綜述
- Bounding box(邊界框)
- Boundary coordinates(邊界坐標)
- Center-Size coordinates(中心坐標)
- 兩種坐標系統的轉換
- Jaccard Index(IoU,重疊程度)
- Multibox
- Single Shot Detector (SSD)
- Base convolutions(基礎卷積)
- 全連接層轉為卷積層(第一部分)
- 全連接層轉為卷積層(第二部分)
- 基礎卷積的代碼
- Auxiliary convolutions(輔助卷積)
- 輔助卷積的代碼
- Prediction convolutions(預測卷積)
- Priors(先驗)
- 可視化 prior
- priors的代碼
- 預測的方法
- 預測卷積
- 預測卷積的代碼
- SSD300模型的代碼
- Multibox loss(損失函式)
- 將預測框與真實框進行匹配
- 定位損失
- 置信損失
- 總損失
- 對預測進行處理
- SSD300代碼



前言
??由于初入物體檢測領域,我在學習SSD模型的時候遇到了很多的困難,一部分困難在于相關概念不清楚,專業詞匯不知其意,相關文章不知所云;另一部分困難在于網上大部分文章要么只是簡要介紹了SSD的總體原理,要么就是直接實戰,SSD作者的論文也已看過,但是看的還是蒙圈蒙圈的,
??我決定通過代碼來了解其原理,首先參考了https://blog.csdn.net/weixin_44791964/article/details/104981486這篇文章的代碼,但是并沒有看懂(I’m too vegetable),然后去GitHub上去搜了一下,一頁的搜索結果恰好點到了這個專案,https://github.com/sgrvinod/a-PyTorch-Tutorial-to-Object-Detection,于是,困擾我的一些問題終于看到了通路,這個作者對SSD關鍵的介紹非常清晰,代碼也是一目了然,我決定在其中添加自己的理解,并對代碼進行一些修改加解讀,一方面幫助我更清楚的理解物體檢測,一方面幫助像我一樣的人入門物體檢測,
概念
??在實作模型之前,我們需要對一些常見概念詞進行了解,后面大多數直接使用原英文單詞說明,當然這里只是粗略的解釋,是為了讓你明白一些專業的術語,即使不理解其含義也并無大礙,在文章中途會結合代碼進行更詳細的解釋,
- Object Detection(物體檢測):懂得都懂
- Single-Shot Detection(單步檢測) : 早期的物體檢測模型結構由兩部分組成——一個region proposal network(區域建議網路)用來定位物體的位置,一個classifier(分類器)檢測建議區域中物體的類別,這種分兩步的模型很消耗算力,因此它們不適合用來做實時檢測,單步檢測模型將定位與分類封裝在一次前向計算中,大大提高了檢測速度,同時使得模型可以部署在輕量級硬體中,
- Multiscale Feature Maps(多尺度特征圖):在影像分類任務中,我們根據最后一個卷積特征圖(原始影像的最小也是最深的表達)進行預測,在物體檢測任務中,中間的卷積特征圖也非常有用,因為它們代表了原影像不同的縮放比例,因此,由于這些特征圖自帶縮放,一個固定大小的 filter(濾波器,也就是卷積中的卷積核)在不同的特征圖上進行運算,就能夠檢測到各種大小的物體,
- Priors(先驗,以后只用英文單詞):這些 priors boxes(先驗框)是在 特定尺度的特征圖 上 特定位置 預先生成的 boxes(框),它們有特定的 aspect ratios(長寬比) 和 scales(比例),它們是精心選擇的,用來匹配資料集中物體邊界框(也叫 ground truths,這個詞經常使用,記住它指的就是資料集中物體的真實標記框)的特征,
- Multibox(實在不好翻譯,在后面會有更加清楚的解釋):這是一項將預測物體邊界框的任務轉變為一個回歸任務的技術,被檢測物體的坐標將被回歸到對應它的真實框的坐標,同時,對每一個預測框,會生成每一個類別的分數(框內的物體就屬于分數最高的類別,這與影像分類任務一樣),priors(先驗框) 可以作為可行的起點, 因為它們是以 ground truths(真實框) 為依據的,因此將會有和priors一樣多的預測框,但是大多數預測框不包含物體,
- Hard Negative Mining(硬負采樣):它明確指明了模型選擇預測最錯誤的假正例(即背景類),強迫模型通過這些樣例進行學習,換句話說,我們只對那些最難正確識別的錯誤因素進行采樣,在物體檢測任務中,我們生成的先驗框非常多(SSD中為8732個),不難想象這些 priors 絕大部分是不包含任何物體的,因此,對于分類任務,這導致了嚴重的樣本不均衡,會使預測結果變得非常差,硬負采樣只讓模型學習最難被識別的背景類,這極大減少了負樣本的數量,有利于平衡正負樣本,
- Non-Maximum Suppression(NMS,非極大抑制):我們生成的 priors 最終預測時將會有一部分重疊程度非常大的預測框,這些重疊程度大的預測框可能預測的是同一個物體, NMS(非極大抑制)是一種消除冗余預測的方法,它將洗掉除預測最高分之外其他所有重疊程度大的預測框,
綜述
??在本部分,我將介紹SSD模型的概述,在我們繼續進行下去的程序中,你應該會注意到相當多的工程設計導致了SSD非常特殊的結構和方法,如果你覺得有些步驟和方法顯得十分不自然(具有明顯的人為傾向,沒有理論支持,或者難以理解為何這樣做),不用擔心,請記住,它是建立在這個領域多年的研究(通常是經驗性的)上的,
Bounding box(邊界框)
?? bounding box(邊界框)就是包裹著一個物體的盒子,代表著這個物體的界限,在本教程中我們只會遇到兩種型別——普通框(不含物體的框)和邊界框,但是所有的框都是在影像上表示的,我們需要能夠測量它們的位置、形狀、大小和其他屬性,
Boundary coordinates(邊界坐標)
?? 表示一個框的最明顯的方法就是使用構成其邊界的線的像素坐標,一個框的邊界坐標很簡單的表示為
(
x
m
i
n
,
y
m
i
n
,
x
m
a
x
,
y
m
a
x
)
(x_{min}, y_{min}, x_{max}, y_{max})
(xmin?,ymin?,xmax?,ymax?) ,也就是框的左上角和右下角坐標 ,如下圖所示,

?? 但是如果我們不知道影像的實際大小,這種坐標將毫無意義,更好的方法是將所有坐標表示為比例的形式,即將
x
x
x 坐標值除以影像的寬度,將
y
y
y 坐標值除以影像的高度,

?? 這樣,如上圖所示,坐標值將被縮放到
[
0
,
1
]
[0,1]
[0,1] 之間,即使我們不知道圖片真實的大小,也可以知道框的位置,現在坐標是大小不變的,所有圖片上的所有框都以相同比例測量,
Center-Size coordinates(中心坐標)
?? 這是表示框的位置和尺寸的一種更明確的方法,

?? 一個框的中心坐標形式為
(
c
x
,
c
y
,
w
,
h
)
(c_x, c_y, w, h)
(cx?,cy?,w,h),其中各個字母的含義在上圖中可以非常明顯的看出,這里就不再進行贅述,需要注意的是這里的所有坐標都進行了上述的縮放,
??在這個代碼中,你會發現我們通常使用兩種坐標系統,這取決于它們對任務的適用性,并且總是以比例分數形式出現的(即進行了縮放),
兩種坐標系統的轉換
- 邊界坐標轉中心坐標
??從上面的介紹中,我們可以非常清楚的得出:
c x = x m i n + x m a x 2 , c y = y m i n + y m a x 2 c_x = \frac{x_{min} + x_{max}}{2} ,\quad c_y = \frac{y_{min} + y_{max}}{2} cx?=2xmin?+xmax??,cy?=2ymin?+ymax??
w = x m a x ? x m i n , h = y m a x ? y m i n w = x_{max} - x_{min} , \quad h = y_{max} - y_{min} w=xmax??xmin?,h=ymax??ymin?
def xy_to_cxcy(xy):
"""
邊界坐標轉中心坐標
:param xy: 一個shape為 [n,4]的tensor,表示n個邊界坐標
:return: 一個shape為 [n,4]的tensor,表示轉換后的n個中心坐標
"""
return torch.cat([
(xy[:, 2:] + xy[:, :2]) / 2, # cx, cy
xy[:, 2:] - xy[:, :2] # w, h
], dim=1)
- 中心坐標轉邊界坐標
??同樣,可以非常明顯地看出如下關系:
x m i n = c x ? w 2 , y m i n = c y ? h 2 x_{min} = c_x - \frac{w}{2}, \quad y_{min} = c_y - \frac{h}{2} xmin?=cx??2w?,ymin?=cy??2h?
x m a x = c x + w 2 , y m a x = c y + h 2 x_{max} = c_x + \frac{w}{2} , \quad y_{max} = c_y + \frac{h}{2} xmax?=cx?+2w?,ymax?=cy?+2h?
def cxcy_to_xy(cxcy):
"""
中心坐標轉邊界坐標
:param cxcy: 一個shape為 [n,4]的tensor,表示n個中心坐標
:return: 一個shape為 [n,4]的tensor,表示轉換后的n個邊界坐標
"""
return torch.cat([
cxcy[:, :2] - (cxcy[:, 2:] / 2), # x_min, y_min
cxcy[:, :2] + (cxcy[:, 2:] / 2) # x_max, y_max
], dim=1)
Jaccard Index(IoU,重疊程度)
??Jaccard Index(Jaccard 系數) 或稱作 Jaccard Overlap(Jaccard重疊) 或稱作 Intersection-over-Union(IoU,交并比),測量了兩個框的重疊程度,這個指標可以反映預測框與真實框的接近程度,在計算loss和進行NMS(非極大抑制)時會用到,如下圖所示,
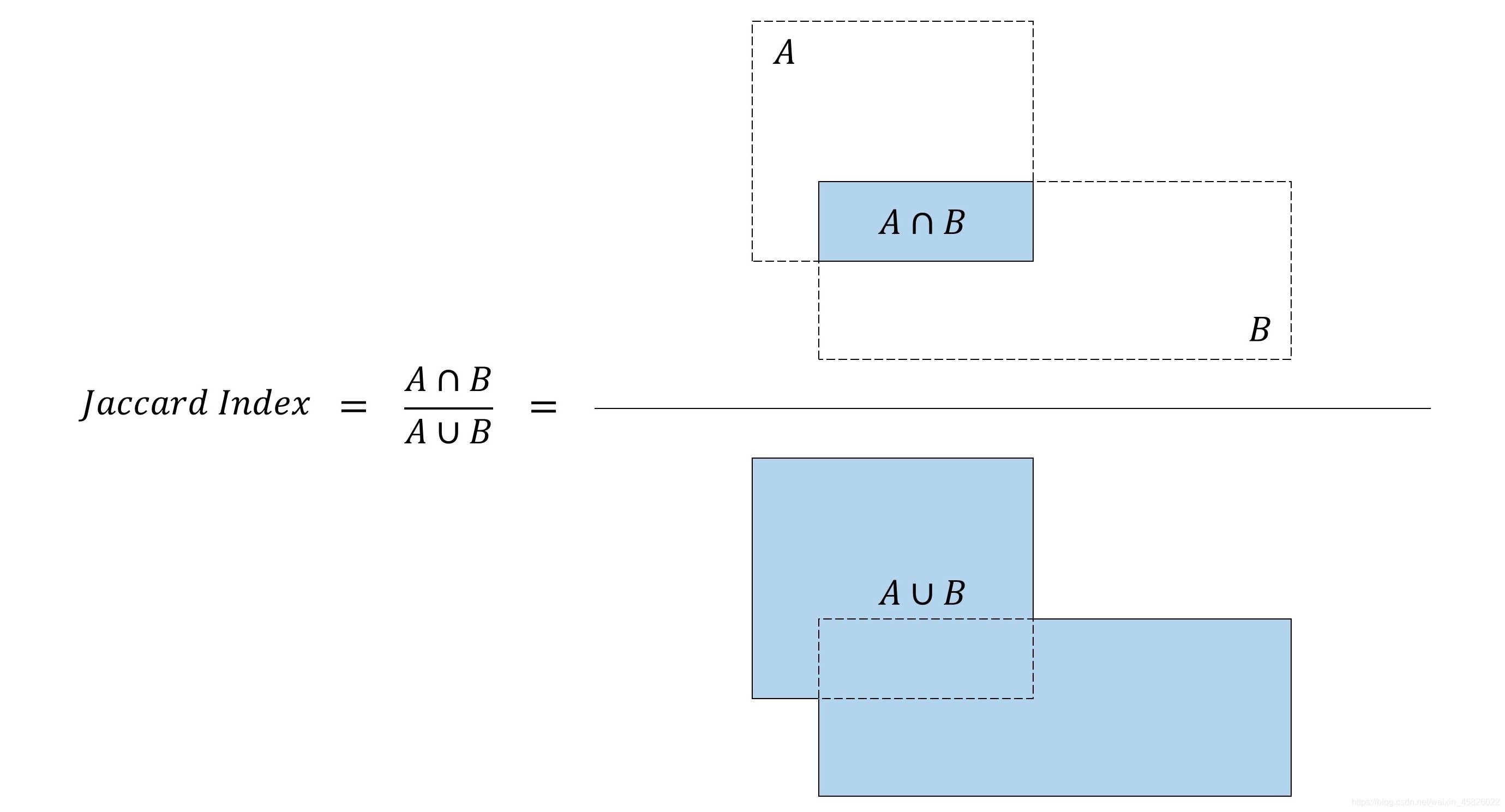
??顯然,Jaccard系數的取值在
[
0
,
1
]
[0, 1]
[0,1] 之間,取值為0時,說明兩個框的交集為0,也就是兩個框沒有重疊;取值為1時,說明兩個框的交集與并集相同,也就是兩個框完全重疊,
??Jaccard系數的代碼實作可能不能很好的理解,我們需要求兩個量,一個是交集面積,一個是并集面積,而且
并
集
面
積
=
框
A
的
面
積
+
框
B
的
面
積
?
交
集
面
積
并集面積=框A的面積+框B的面積-交集面積
并集面積=框A的面積+框B的面積?交集面積 ,框A和框B的面積都非常容易計算,因此我們將目光放在交集面積的計算上,考慮一些常見的交集方式,如下圖,綠色點表示交集區域左上角,藍色點表示交集區域右下角,
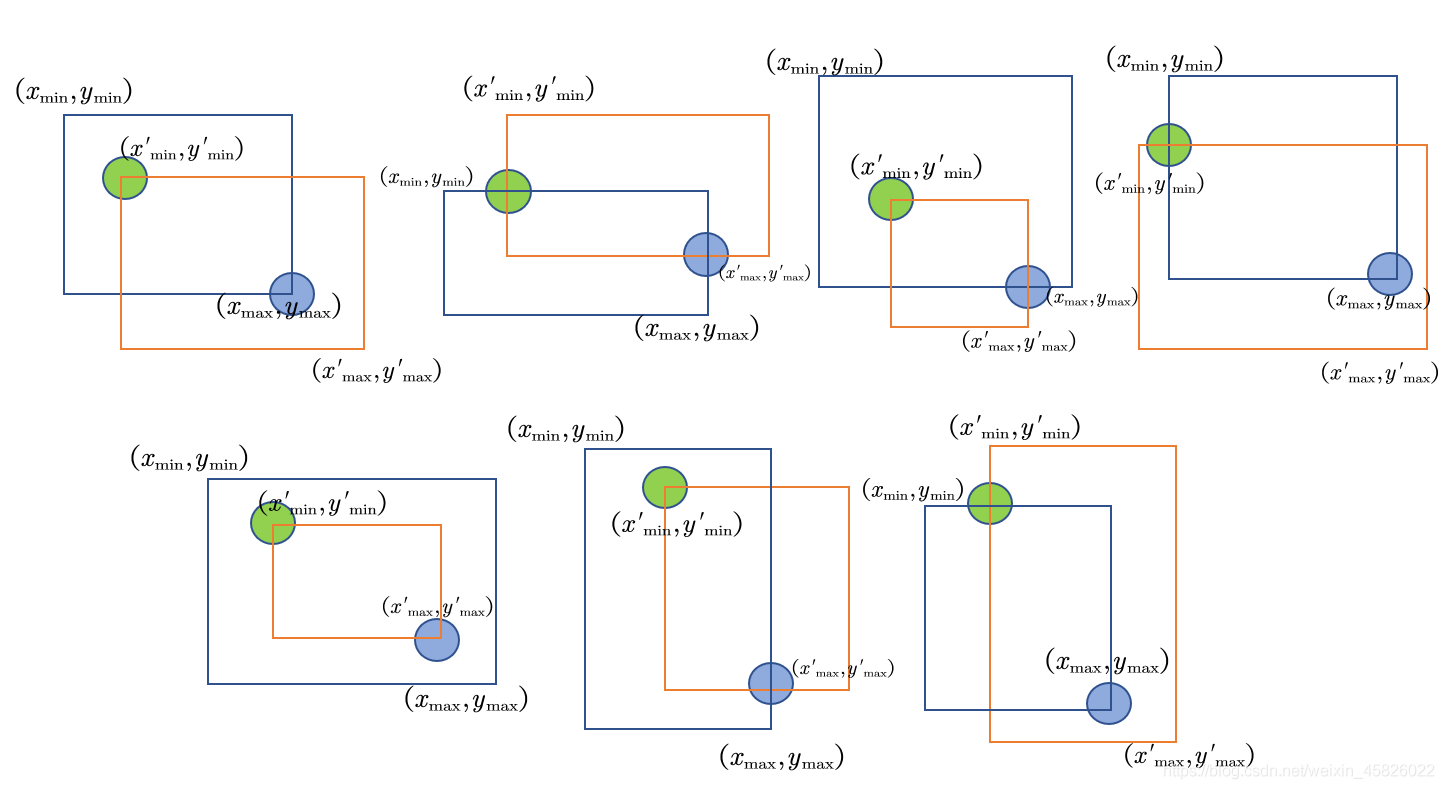
??從上圖中,我們可以看出,交集的區域都可以用兩個點表示,這正是交集區域的邊界坐標,整個交集區域的邊界坐標可以表示為:
(
I
x
min
?
,
I
y
min
?
,
I
x
max
?
,
I
y
max
?
)
(I_{x_{\min}}, I_{y_{\min}}, I_{x_{\max}}, I_{y_{\max}})
(Ixmin??,Iymin??,Ixmax??,Iymax??)
其
中
:
I
x
min
?
=
max
?
{
x
min
?
,
x
min
?
′
}
,
I
y
min
?
=
max
?
{
y
min
?
,
y
min
?
′
}
,
I
x
max
?
=
min
?
{
x
max
?
,
x
max
?
′
}
,
I
y
max
?
=
min
?
{
y
max
?
,
y
max
?
′
}
其中: I_{x_{\min}} =\max\{x_{\min}, x^{\prime}_{\min}\}, \quad I_{y_{\min}} =\max\{y_{\min}, y^{\prime}_{\min}\}, \\ I_{x_{\max}} =\min\{x_{\max}, x^{\prime}_{\max}\}, \quad I_{y_{\max}} =\min\{y_{\max}, y^{\prime}_{\max}\}
其中:Ixmin??=max{xmin?,xmin′?},Iymin??=max{ymin?,ymin′?},Ixmax??=min{xmax?,xmax′?},Iymax??=min{ymax?,ymax′?}
因此可以得到交集面積為
S
=
(
I
y
max
?
?
I
y
min
?
)
(
I
x
max
?
?
I
x
min
?
)
S = (I_{y_{\max}} - I_{y_{\min}})(I_{x_{\max}} - I_{x_{\min}})
S=(Iymax???Iymin??)(Ixmax???Ixmin??),
??然而當兩個框不重合時,這個式子會計算出什么?考慮不重合情形,如下圖所示,綠色點表示上述式子計算的“左上角”,藍色點表示上述式子計算的“右下角”:
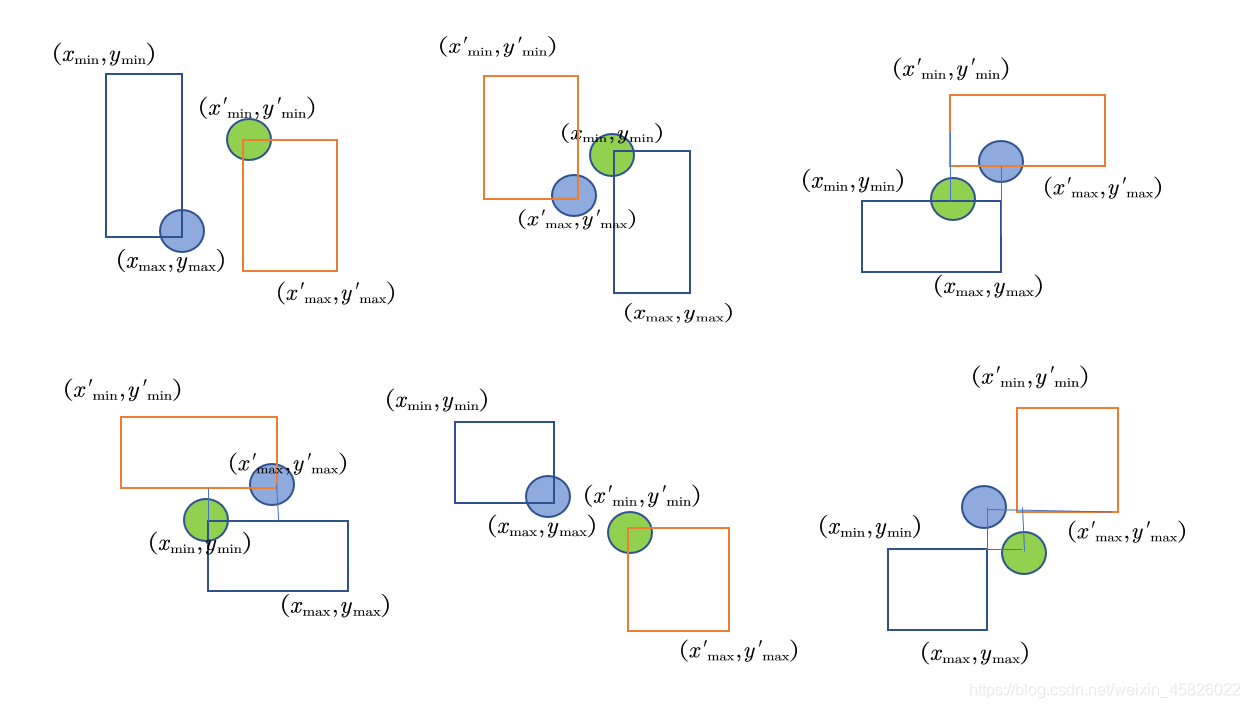
??此時,我們考慮上述面積式子:
S
=
(
I
y
max
?
?
I
y
min
?
)
(
I
x
max
?
?
I
x
min
?
)
S = (I_{y_{\max}} - I_{y_{\min}})(I_{x_{\max}} - I_{x_{\min}})
S=(Iymax???Iymin??)(Ixmax???Ixmin??),可以發現要么
I
y
max
?
?
I
y
min
?
<
0
I_{y_{\max}} - I_{y_{\min}} < 0
Iymax???Iymin??<0 ,要么
I
x
max
?
?
I
x
min
?
<
0
I_{x_{\max}} - I_{x_{\min}} < 0
Ixmax???Ixmin??<0 ,要么二者均小于0,因此我們可以這樣計算交集的面積:一旦這兩個式子小于0,我們就將其設定為0,這樣0乘任何數均是0,因此交集面積計算結果為0,否則就用上述式子得到交集面積,
??綜上我們可以得到如下求交集的代碼:
def find_intersection(set_1, set_2):
"""
計算第一個集合中每個框與第二個集合中每個框的交集面積
:param set_1: 一個shape為[m,4]的tensor,代表m個邊界坐標
:param set_2: 一個shape為[n,4]的tensor,代表n個邊界坐標
:return: 一個shape為[m,n]的tensor,例如:[0,:]表示set_1中第1個框與set_2中每個框的交集面積
"""
# max函式中的兩個tensor的shape分別為[m,1,2], [1,n,2],可以應用廣播機制,最后得到的tensor的shape為[m,n,2]
# 例如:[0, :, 2]表示set_1中第一個框與set_2中所有框交集的左上角坐標
lower_bounds = torch.max(set_1[:, :2].unsqueeze(1), set_2[:, :2].unsqueeze(0)) # [m, n, 2]
# 計算右下角的坐標
upper_bounds = torch.min(set_1[:, 2:].unsqueeze(1), set_2[:, 2:].unsqueeze(0)) # [m, n, 2]
# 將兩個減式小于0的設定為0
intersection_dims = torch.clamp(upper_bounds - lower_bounds, min=0) # [m, n, 2]
# 相乘得到交集面積
return intersection_dims[:, :, 0] * intersection_dims[:, :, 1] # [m, n]
??利用 并 集 面 積 = 框 A 的 面 積 + 框 B 的 面 積 ? 交 集 面 積 并集面積=框A的面積+框B的面積-交集面積 并集面積=框A的面積+框B的面積?交集面積 ,進而得到計算 Jaccard系數的代碼:
def find_jaccard_overlap(set_1, set_2):
"""
計算第一個集合中每個框與第二個集合中每個框的Jaccard系數
:param set_1: 一個shape為[m,4]的tensor,代表m個邊界坐標
:param set_2: 一個shape為[n,4]的tensor,代表n個邊界坐標
:return: 一個shape為[m,n]的tensor,例如:[0,:]表示set_1中第1個框與set_2中每個框的Jaccard系數
"""
# 每個框與其他框的交集
intersection = find_intersection(set_1, set_2) # [m, n]
# 計算每個集合中每個框的面積
areas_set_1 = (set_1[:, 2] - set_1[:, 0]) * (set_1[:, 3] - set_1[:, 1]) # [m]
areas_set_2 = (set_2[:, 2] - set_2[:, 0]) * (set_2[:, 3] - set_2[:, 1]) # [n]
# 總面積減去交集就是并集
# unsqueeze的作用同樣是為了滿足廣播機制的條件
union = areas_set_1.unsqueeze(1) + areas_set_2.unsqueeze(0) - intersection # [m, n]
# Jaccard系數 = 交集面積 / 并集面積
return intersection / union # [m, n]
Multibox
??Multibox 是一種檢測物體的技術,由兩部分組成:
- 方框的坐標,該方框可能包含也可能不包含物體,這是個回歸任務
- 這個框中的物體是每個類別的分數,其中包括一個背景類,這說明框內沒有物體,這是一個分類任務,
Single Shot Detector (SSD)
??SSD是一個純卷積(只有卷積層和池化層)網路,我們可以將它分為三個部分:
- Base convolutions(基礎卷積):派生自一個現有的影像分類模型,將提供低級別的特征圖,
- Auxiliary convolutions(輔助卷積):添加在基礎卷積之上,將提供較高級別的特征圖,
- Prediction convolutions(預測卷積):用來在特征圖中定位和識別物體,
??論文中提出了該模型的兩種變體:SSD300和SSD512,后綴的數字表示輸入圖片的大小,雖然這兩個網路的構造方式略有不同,但它們在原則上是相同的,SSD512只是一個更大的網路,性能更好些,為了簡便,我們將介紹SSD300.
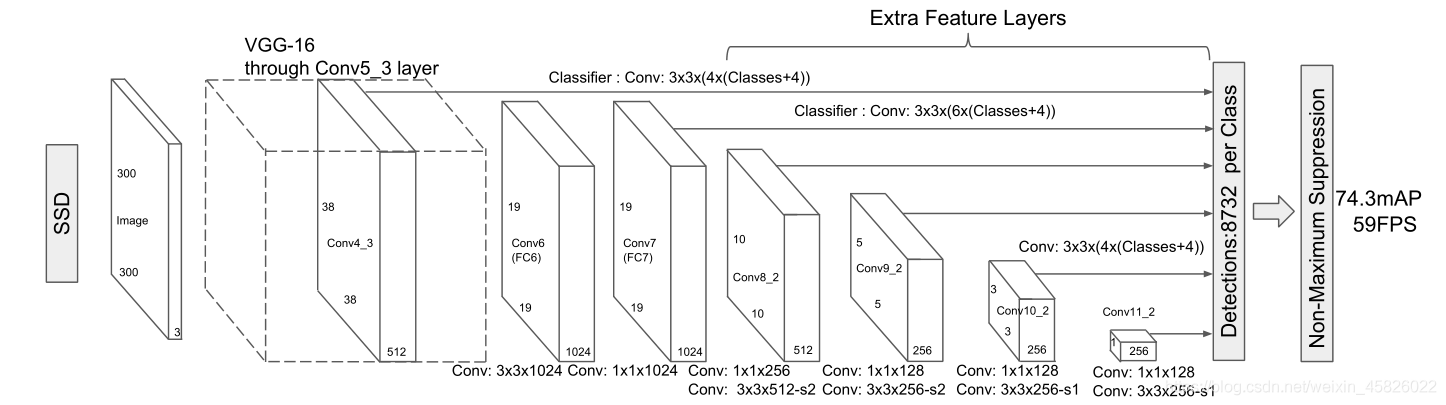
Base convolutions(基礎卷積)
- 首先,我們要知道為什么要使用一個現有網路的卷積?
- 因為已經證明:一個在影像分類任務上表現良好的模型已經能夠很好的捕獲影像的基本特征,同樣的卷積特征對物體檢測也很有用,盡管是在更區域的意義上——我們對影像整體不太感興趣,而是對存在物體的特定區域感興趣,
- 還有一個額外的優勢:我們可以使用在可靠的分類資料集上預先訓練的層,如你所知道的,這叫做 Transfer Learning(遷移學習),通過從不同但密切相關的任務中借取知識,我們甚至在還沒開始前就取得了進展,
??作者采用了VGG16結構作為基礎卷積,它的原始形式非常簡單:
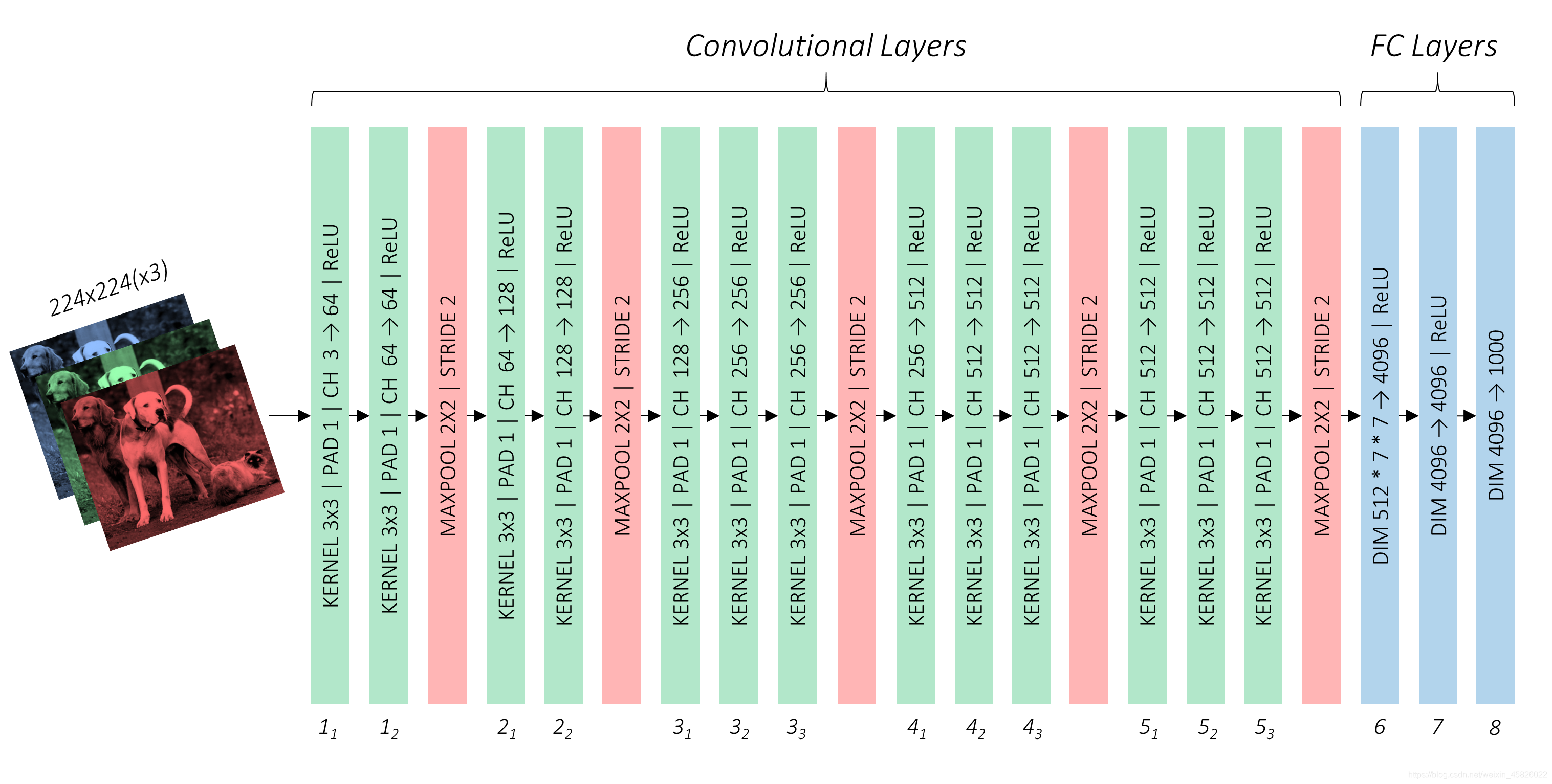
??作者建議使用在 ImageNet Large Scale Visual Recognition Competition (ILSVRC) 分類任務中訓練的模型,幸運的是,在Pytorch中已經有了一個可用的結構,其他流行的框架也是如此,如你所想,你可以選擇其他結構作為基礎卷積,比如ResNet,但是需要注意,這將導致計算量和記憶體開銷變大,
??我們需要對這個預訓練的網路進行調整,以適應我們的物體檢測任務,一些調整是合乎邏輯和必要的,一些則是出于方便和偏好,
- 如前文所述,輸入的圖片大小為
300,300 - 第三個最大池化層,用來減半影像大小,我們使用
ceil替換默認的floor,來決定輸出影像的大小,只有當特征圖的大小為奇數時才會有用,通過查看上面的影像,可以計算出當輸入影像大小為300, 300時,conv3_3的特征圖大小為75,75,通過這個改變它將減半為38, 38而不是37, 37, - 第五個最大池化層,將原來
2,2的卷積核和2,2的步長,改為3,3的卷積核和1,1的步長,這樣做使得它不再將前面的特征圖減半, - 我們不需要全連接層,因為它們在這里毫無用處,我們將完全拋棄
fc8,但是選擇將fc6和fc7重新制作為卷積層conv6和conv7.
??前三個修改很簡單,只需要修改一些引數即可,但是最后一個修改可能需要一些解釋,
全連接層轉為卷積層(第一部分)
??我們如何將一個全連接層重新引數化為一個卷積層?考慮下面的場景:
??在典型的影像分類任務中,第一個全連接層不能直接對前面的特征圖或影像進行計算,需要將特征圖 flatten(展平)為一個一維向量,
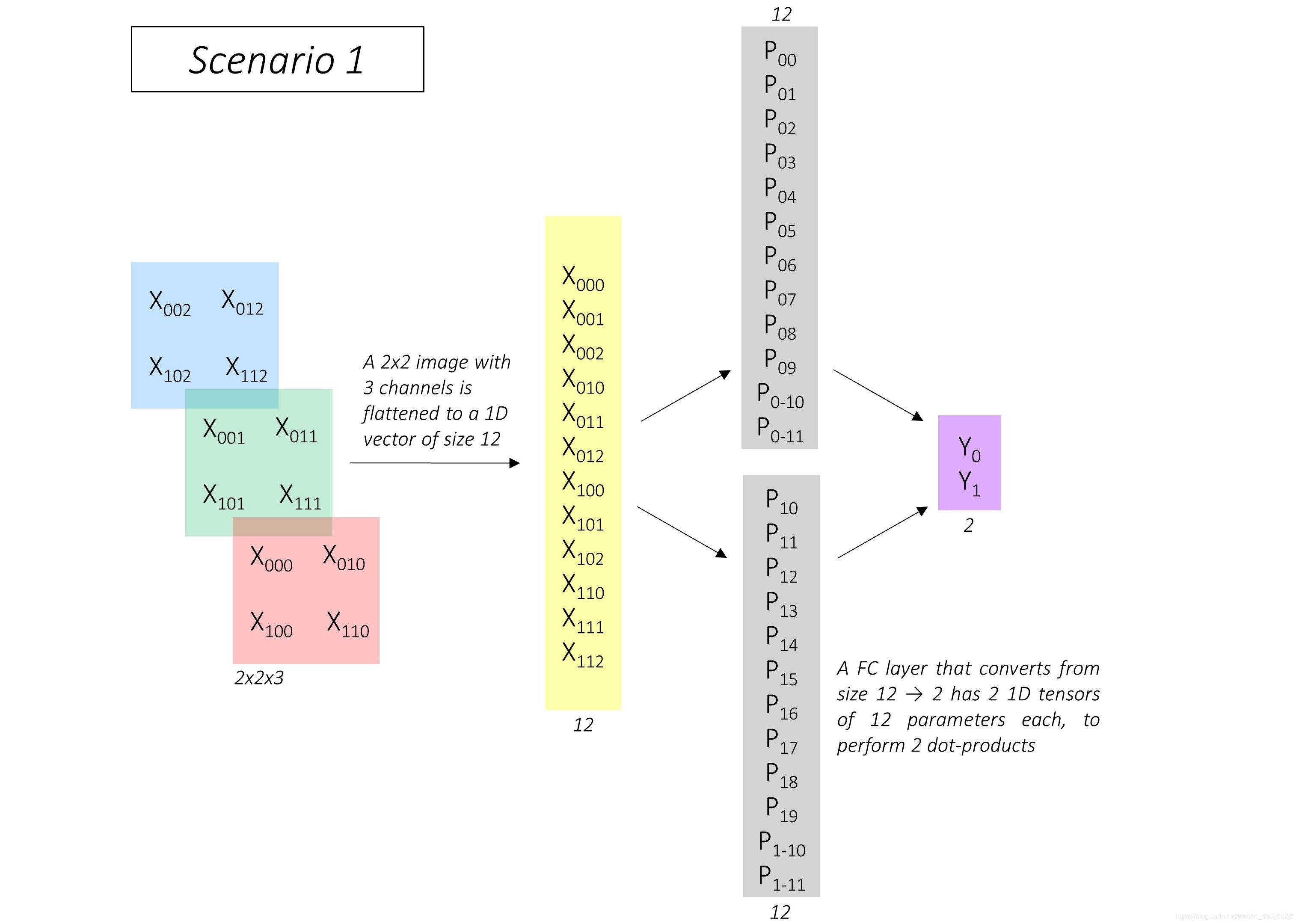
??在這個例子中,有一個 shape 為 2,2,3 的圖片被展平為大小為 12 的一維向量,輸出維度為2時,全連接層通過兩個大小也為12的一維向量與展平后的圖片進行點積運算得到輸出結果,這兩個向量由灰色表示,它們是全連接層的引數
??現在考慮另一個場景,我們需要用卷積輸出兩個值.
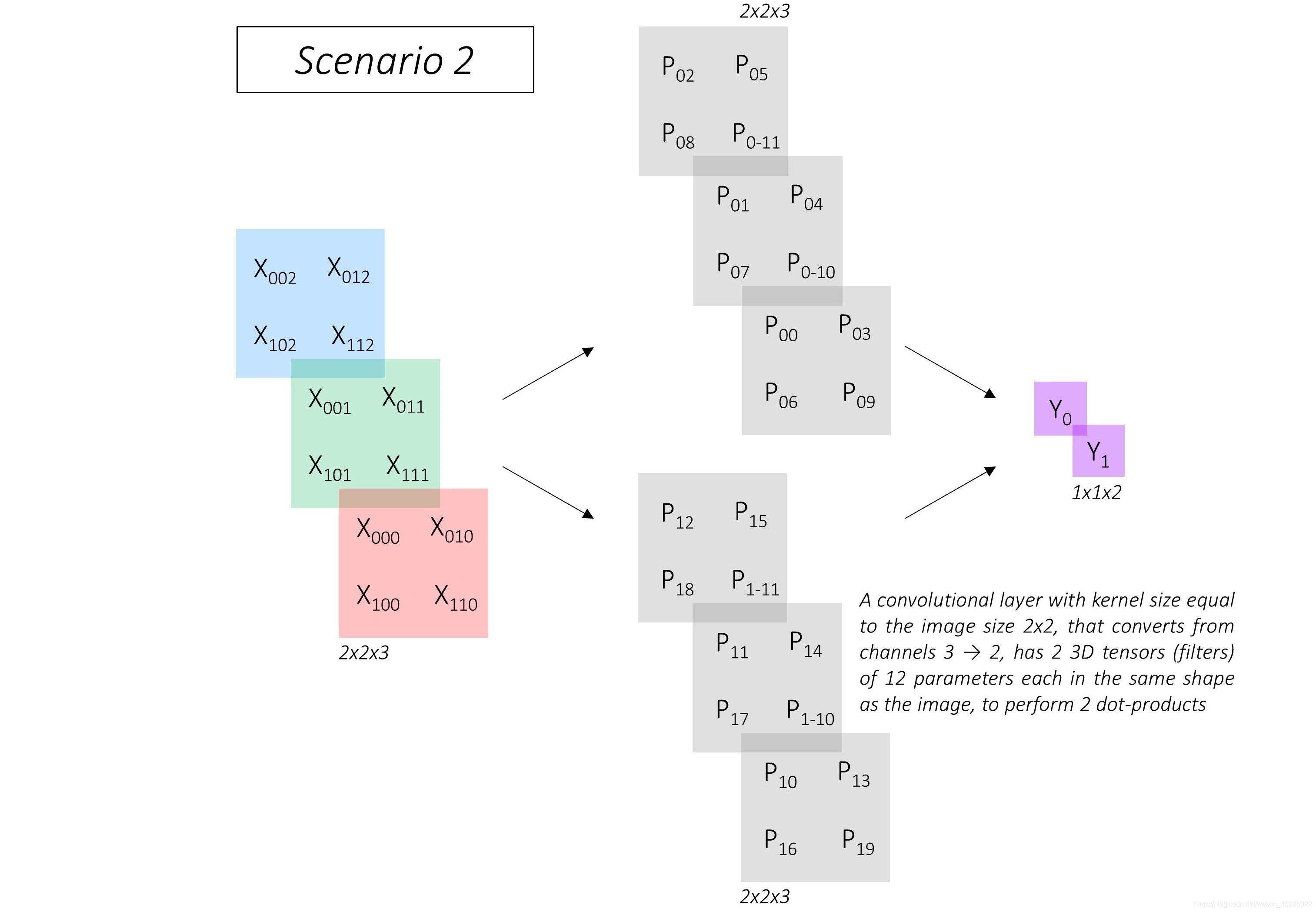
??很明顯,這里維度為2,2,3的圖片不需要展平操作,卷積層使用與影像維度相同的帶有12個引數的兩組 filters (濾波器),每個卷積核的大小為 2, 2 ,進行點積運算,得到輸出結果,這兩組 filters 也由灰色展示,它們是卷積層的引數,
??注意,這里有一個關鍵點——這兩種情景輸出的
y
0
y_0
y0? 和
y
1
y_1
y1? 是一樣的!
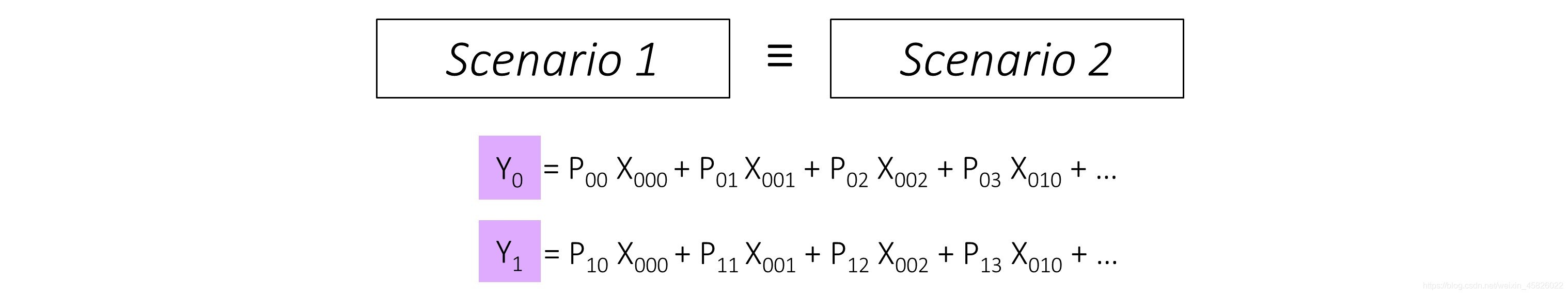
??這兩種情景是等價的,這告訴了我們什么?
??大小為 H, W 并且輸入通道數為 I 的圖片,倘若全連接層的引數 N, H×W×I 與卷積層的引數 N, H, W, I 相同,那么一個輸出大小為 N 的全連接層,等價于一個與圖片大小相同的 H, W 卷積核和 N 個輸出通道的卷積層,

??因此任何全連接層都可以通過 reshape 其引數的形狀轉變為等價的卷積層,
全連接層轉為卷積層(第二部分)
??現在我們已經知道怎么將VGG16結構中的 fc6 和 fc7 層轉換為 conv6 和 conv7 層,
??在ImageNet中VGG16的輸入圖片的維度為 224, 224, 3 ,經過 conv5_3 輸出后的特征圖大小為 7, 7, 512,因此:
fc6層的輸入大小為展平后的7 * 7 * 512,輸出大小為4096,它的引數維度為4096, 7 * 7 * 512,這等價于卷積核大小為7, 7,輸出通道數為4096的卷積層conv6,只需將fc6的引數 reshape 為4096, 7, 7, 512即可,fc7層的輸入大小為4096(fc6的輸出),輸出大小也是4096,因此它的引數維度為4096, 4096,此時的輸入可以看作一個大小為1, 1,通道數為4096的圖片,這等價于卷積核大小為1, 1,輸出通道數為4096的卷積層conv7,只需要將fc7的引數 reshape 為4096, 1, 1, 4096,
??我們可以看到 conv6 有4096組 filters,每組 filter 的維度為 7, 7, 512,conv7 有 4096 組 filters,每組維度為1, 1, 4096,
??這些 filters 數量眾多,引數量很大,會造成很大的計算開銷,為了緩解這個情況,作者通過對轉換后卷積層的引數進行采樣,進而減少 filters 的數量和大小,
conv6將使用1024組 filters,每組的維度為3, 3, 512,因此引數從原來的4096, 7, 7, 512被下采樣為1024, 3, 3, 512conv7將使用1024組 filters,每組的維度為1, 1, 1024,因此引數從原來的4096, 1, 1, 4096被下采樣為1024, 1, 1, 1024
??根據論文我們將沿著指定的維度,每隔 m 次取一個引數,達到下采樣的目的,
??我們以 fc6 為例,介紹一下如何進行采樣的,首先看單個卷積核,是如何從 7, 7 變為 3, 3 的,如下圖:
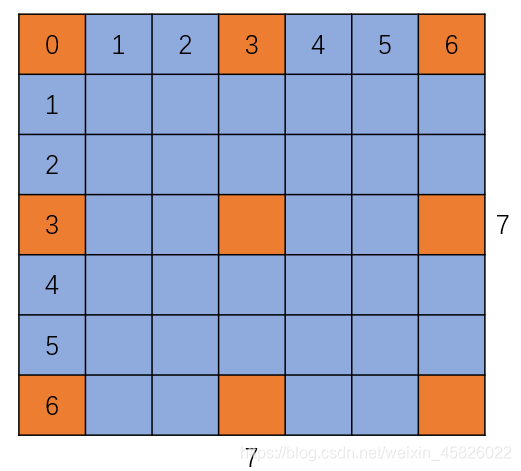
??從圖中我們可以看出,當步長取3時,就能將 7, 7 的卷積核采樣為 3, 3 的,這個步長的方式與張量切片步長的原理一模一樣!同理我們對第一個維度即 4096 設定采樣步長為 4 則可以得到 1024 的結果,因此對 fc6 層,我們將每個維度的采樣步長設定為 [4, 3, 3, None] 即可從 4096, 7, 7, 512 采樣為 1024, 3, 3, 512,None表示不對該維度進行采樣, 對 fc7 層,我們可以設定步長 [4, None, None, 4] 即可從 4096, 1, 1, 4096 采樣為 1024, 1, 1, 1024,這個步驟我們可以使用 torch.index_select() 函式實作,
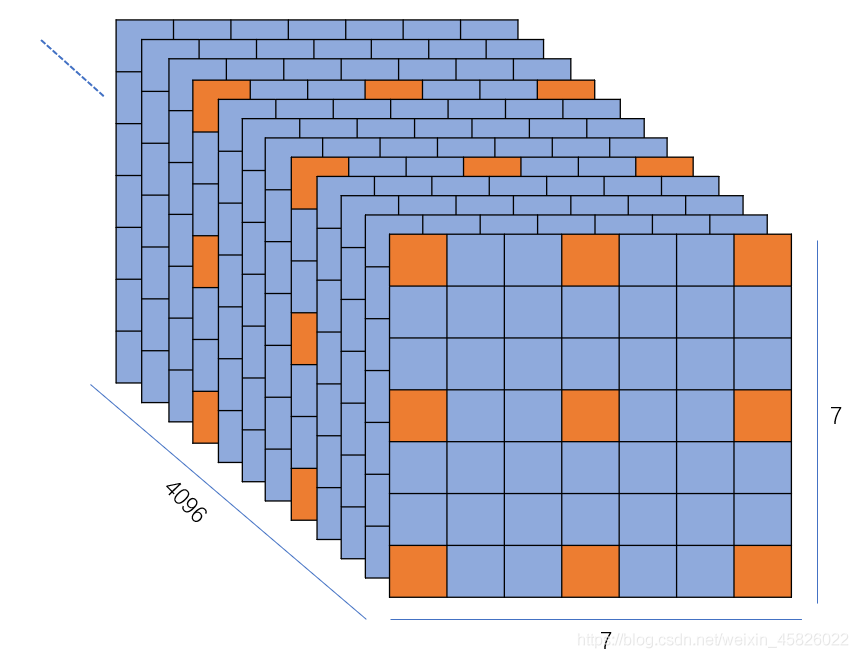
??進行采樣的代碼實作如下,
def decimate(tensor, interval=None):
"""
根據間隔點,對tensor進行采樣
:param tensor: 一個有n個維度,需要進行采樣的tensor
:param interval: 一個元素為n的串列,每個位置的元素表示該維度的采樣步長
:return: 對每個維度采樣后的n維tensor
"""
# tensor的維度必須和采樣的維度數量一樣
if tensor.dim() != len(interval):
raise ValueError('tensor and interval must have same dimensions !')
for d in range(tensor.dim()):
# 如果為None則不對該維度進行采樣
if interval[d] is not None:
# 根據步長進行采樣
tensor = tensor.index_select(
dim=d,
index=torch.arange(start=0, end=tensor.size(d), step=interval[d]).long()
)
return tensor
??由于 conv6的卷積核從 7, 7采樣為 3, 3,步長為3,因此在卷積核中有空洞,如前面的圖中所展示一樣(橙色之間有藍色的空洞),因此我們需要使用空洞卷積,由于我們采樣的步長為3,因此卷積的引數 dilation 也應設定為3,但是實際上論文作者設定為6,這可能是因為第五個最大池化層也進行了改變,沒有將特征圖變為一半,
??現在可以展示我們修改后的基礎卷積了,
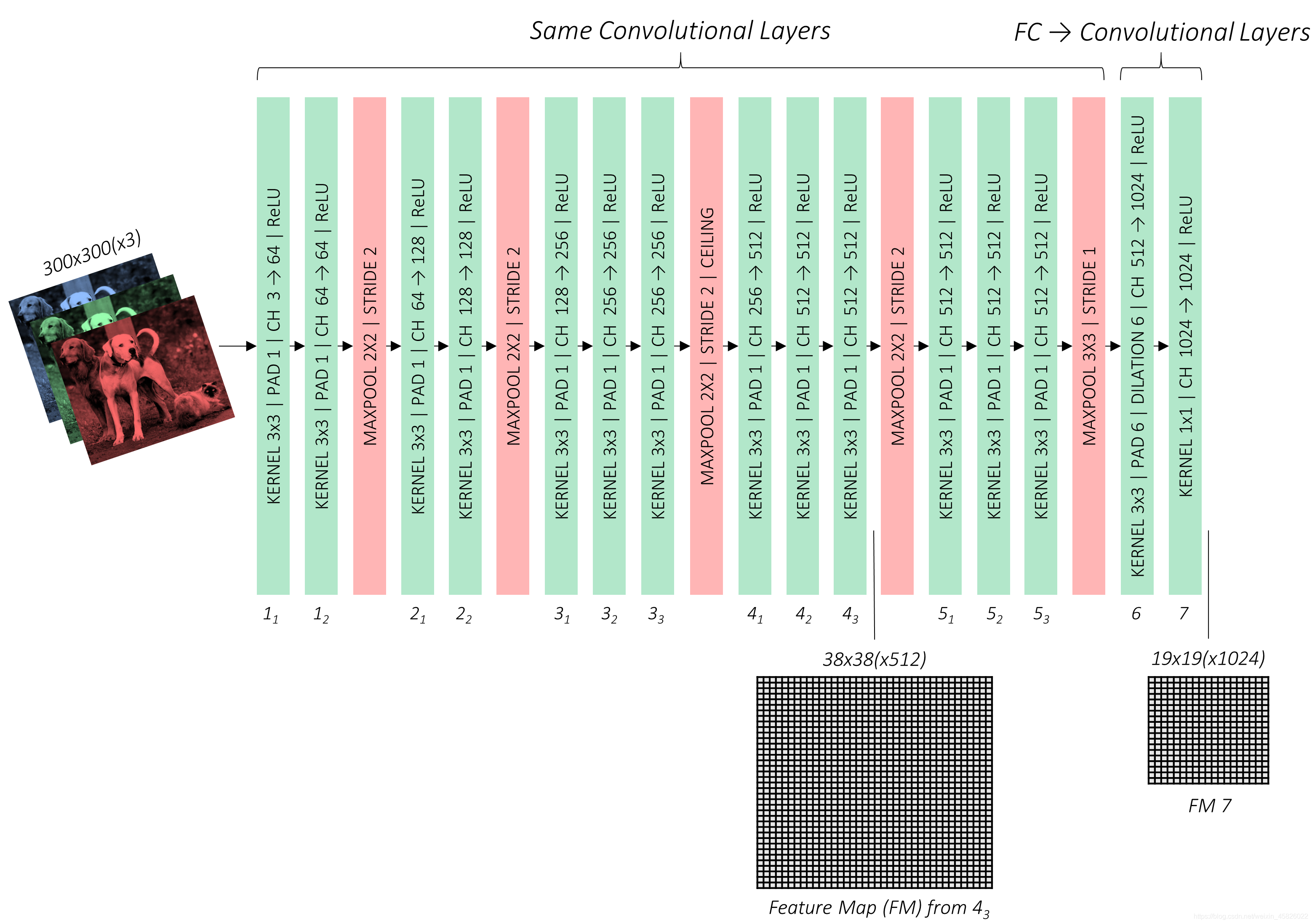
??在上圖中要特別注意 conv4_3 和 conv7 的輸出,你很快就能知道為什么,
基礎卷積的代碼
class VGGBase(nn.Module):
def __init__(self):
super(VGGBase, self).__init__()
# 標準VGG16卷積層
self.conv1_1 = nn.Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=1)
self.conv1_2 = nn.Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=1)
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv2_1 = nn.Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=1)
self.conv2_2 = nn.Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=1)
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv3_1 = nn.Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=1)
self.conv3_2 = nn.Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=1)
self.conv3_3 = nn.Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=1)
# 第三個最大池化層需要設定 ceil 模式
self.pool3 = nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True)
self.conv4_1 = nn.Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=1)
self.conv4_2 = nn.Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=1)
self.conv4_3 = nn.Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=1)
self.pool4 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv5_1 = nn.Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=1)
self.conv5_2 = nn.Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=1)
self.conv5_3 = nn.Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=1)
# 第五個最大池化層的引數需要進行修改
self.pool5 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
# 原VGG16的fc6和fc7層,需要從全連接層轉換為卷積層,同時洗掉部分權重
self.conv6 = nn.Conv2d(512, 1024, kernel_size=(3, 3), padding=6, dilation=(6, 6))
self.conv7 = nn.Conv2d(1024, 1024, kernel_size=(1, 1), stride=(1, 1))
# 為每個卷積層設定訓練好的權重
self.load_weights()
def load_weights(self):
"""
為卷積層加載訓練好的引數,同時對全連接層進行轉化和采樣
"""
state_dict = self.state_dict()
param_names = list(state_dict.keys())
# 獲取預訓練權重
pretrained_state_dict = vgg16(pretrained=True).state_dict()
pretrained_param_names = list(pretrained_state_dict.keys())
# 除了fc6和fc7層之外,其他的層直接加載權重
for i, param in enumerate(param_names[:-4]):
state_dict[param] = pretrained_state_dict[pretrained_param_names[i]]
def decimate(tensor, interval=None):
"""
根據間隔點,對tensor進行采樣
:param tensor: 一個有n個維度,需要進行采樣的tensor
:param interval: 一個元素為n的串列,每個位置的元素表示該維度的采樣步長
:return: 對每個維度采樣后的n維tensor
"""
# tensor的維度必須和采樣的維度數量一樣
if tensor.dim() != len(interval):
raise ValueError('tensor and interval must have same dimensions !')
for d in range(tensor.dim()):
# 如果為None則不對該維度進行采樣
if interval[d] is not None:
# 根據步長進行采樣
tensor = tensor.index_select(
dim=d,
index=torch.arange(start=0, end=tensor.size(d), step=interval[d]).long()
)
return tensor
# 將fc6的權重reshape為 4096,7,7,512,但是pytorch的通道數在前面,因此reshape為 4096,512,7,7
fc6_weight = pretrained_state_dict['classifier.0.weight'].view(4096, 512, 7, 7)
# fc6層偏置的權重
fc6_bias = pretrained_state_dict['classifier.0.bias']
# 對權重進行采樣,[4096, 512, 7, 7] -> [1024, 512, 3, 3]
state_dict['conv6.weight'] = decimate(fc6_weight, [4, None, 3, 3])
# 對偏置進行同樣的采樣,[4096] -> [1024]
state_dict['conv6.bias'] = decimate(fc6_bias, [4])
# fc7層與fc6層操作一樣
fc7_weight = pretrained_state_dict['classifier.3.weight'].view(4096, 4096, 1, 1)
fc7_bias = pretrained_state_dict['classifier.3.bias']
# [4096, 4096, 1, 1] -> [1024, 1024, 1, 1]
state_dict['conv7.weight'] = decimate(fc7_weight, [4, 4, None, None])
# [4096] -> [1024]
state_dict['conv7.bias'] = decimate(fc7_bias, [4])
del decimate
# 加載權重
self.load_state_dict(state_dict)
def forward(self, x):
x = F.relu(self.conv1_1(x)) # [b, 3, 300, 300] -> [b, 64, 300, 300]
x = F.relu(self.conv1_2(x)) # [b, 64, 300, 300] -> [b, 64, 300, 300]
x = self.pool1(x) # [b, 64, 300, 300] -> [b, 64, 150, 150]
x = F.relu(self.conv2_1(x)) # [b, 64, 150, 150] -> [b, 128, 150, 150]
x = F.relu(self.conv2_2(x)) # [b, 128, 150, 150] -> [b, 128, 150, 150]
x = self.pool2(x) # [b, 128, 150, 150] -> [b, 128, 75, 75]
x = F.relu(self.conv3_1(x)) # [b, 128, 75, 75] -> [b, 256, 75, 75]
x = F.relu(self.conv3_2(x)) # [b, 256, 75, 75] -> [b, 256, 75, 75]
x = F.relu(self.conv3_3(x)) # [b, 256, 75, 75] -> [b, 256, 75, 75]
x = self.pool3(x) # [b, 256, 75, 75] -> [b, 256, 38, 38]
x = F.relu(self.conv4_1(x)) # [b, 256, 38, 38] -> [b, 512, 38, 38]
x = F.relu(self.conv4_2(x)) # [b, 512, 38, 38] -> [b, 512, 38, 38]
conv4_3_feats = F.relu(self.conv4_3(x)) # [b, 512, 38, 38] -> [b, 512, 38, 38]
x = self.pool4(conv4_3_feats) # [b, 512, 38, 38] -> [b, 512, 19, 19]
x = F.relu(self.conv5_1(x)) # [b, 512, 19, 19] -> [b, 512, 19, 19]
x = F.relu(self.conv5_2(x)) # [b, 512, 19, 19] -> [b, 512, 19, 19]
x = F.relu(self.conv5_3(x)) # [b, 512, 19, 19] -> [b, 512, 19, 19]
x = self.pool5(x) # [b, 512, 19, 19] -> [b, 512, 19, 19]
x = F.relu(self.conv6(x)) # [b, 512, 19, 19] -> [b, 1024, 19, 19]
conv7_feats = F.relu(self.conv7(x)) # [b, 1024, 19, 19] -> [b, 1024, 19, 19]
# 注意這里的輸出有兩個
return conv4_3_feats, conv7_feats
Auxiliary convolutions(輔助卷積)
??現在我們將在基礎卷積上堆疊更多的卷積層,這些卷積提供了額外的特征圖,且一個比一個小,
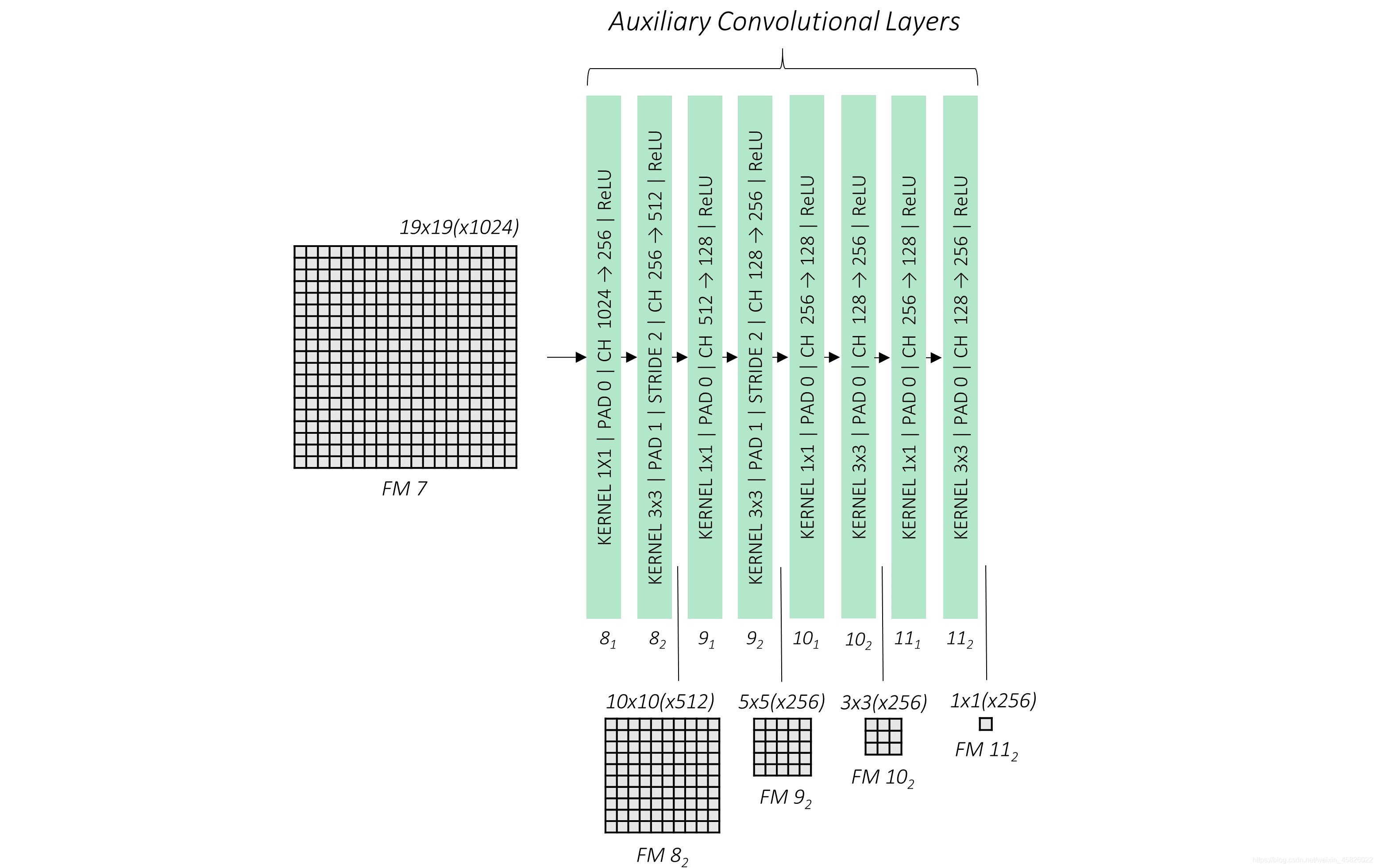
??我們引入了四個卷積塊,每個塊有兩個卷積層,雖然在基礎卷積中特征圖大小的改變是通過池化層實作的,但是這里是通過每個塊中第二個卷積實作的,其步長為2,
??另外,注意 conv8_2、conv9_2、conv10_2 和 conv11_2的輸出,
輔助卷積的代碼
class AuxiliaryConvolutions(nn.Module):
def __init__(self):
super(AuxiliaryConvolutions, self).__init__()
self.conv8_1 = nn.Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))
self.conv8_2 = nn.Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=1)
self.conv9_1 = nn.Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1))
self.conv9_2 = nn.Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=1)
self.conv10_1 = nn.Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1))
self.conv10_2 = nn.Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1))
self.conv11_1 = nn.Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1))
self.conv11_2 = nn.Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1))
# 初始化權重
self.init_weight()
def init_weight(self):
for conv in self.children():
if isinstance(conv, nn.Conv2d):
nn.init.xavier_normal_(conv.weight)
nn.init.constant_(conv.bias, 0.)
def forward(self, x):
# 這里的引數x是基礎卷積的conv7層輸出
x = F.relu(self.conv8_1(x)) # [b, 1024, 19, 19] -> [b, 256, 19, 19]
conv8_2_feats = F.relu(self.conv8_2(x)) # [b, 256, 19, 19] -> [b, 512, 10, 10]
x = F.relu(self.conv9_1(conv8_2_feats)) # [b, 512, 10, 10] -> [b, 128, 10, 10]
conv9_2_feats = F.relu(self.conv9_2(x)) # [b, 128, 10, 10] -> [b, 256, 5, 5]
x = F.relu(self.conv10_1(conv9_2_feats)) # [b, 256, 5, 5] -> [b, 128, 5, 5]
conv10_2_feats = F.relu(self.conv10_2(x)) # [b, 128, 5, 5] -> [b, 256, 3, 3]
x = F.relu(self.conv11_1(conv10_2_feats)) # [b, 256, 3, 3] -> [b, 128, 3, 3]
conv11_2_feats = F.relu(self.conv11_2(x)) # [b, 128, 3, 3] -> [b, 256, 1, 1]
return conv8_2_feats, conv9_2_feats, conv10_2_feats, conv11_2_feats
Prediction convolutions(預測卷積)
??在我們開始預測卷積之前,我們必須先要了解我們預測的是什么,當然,預測的是物體和它的位置,但是是什么形式的?
??在這里我們必須了解 priors ,它是 SSD 中的關鍵部分,
Priors(先驗)
??物體的檢測可以是多種多樣的,我指的不僅僅是它們的型別,它們可以出現在任何位置,并且可能是任意大小和形狀,請注意,我們不應該走得太遠,以至于說一個物體在哪里和如何發生有無限種可能,雖然這在數學上可能是正確的,但是現實中很多可能根本不會發生,是沒有意義的,此外,我們不必堅持 boxes 是像素完美的,
??實際上,我們可以將預測的潛在數學空間離散為成千上萬種可能,
??priors 是預先計算的,固定大小的框,所有的 prior 共同代表了這個潛在的被離散化的數學空間且它們與預測框接近,
??priors 是手工的但是是根據資料集中 ground truth 的形狀和大小精心選擇的,我們還考慮了位置的變化,以便將這些 priors 放在特征圖上每個可能位置,
??在定義 priors 時,作者指出:
- 它們將被應用于各種低級和高級的特征圖中,也就是前面圖中提到的
conv4_3、conv7、conv8_2、conv9_2、conv10_2、conv11_2, - 如果一個 prior 有一個scale
s, 那么它的面積就等于一個邊長為s的正方形的面積,最大的特征圖conv4_3,它的 priors 的 scale 是0.1,也就是特征圖尺寸的10%,其余的特征圖為 0.2到0.9線性增長,即0.2,0.375,0.55,0.725,0.9,如你所見,較大的特征圖有著較小 scale 的 priors,它們是用來檢測較小物體的, - 在特征圖的每個位置上,都有各種 aspect ratios(寬高比)的 priors,所有的特征圖都有
1:1, 1:2, 2:1比例的 prior,而中間的特征圖conv8_2、conv9_2、conv10_2會有1:3, 3:1的 prior ,此外,所有特征圖都有一個額外的比例為1:1的 prior,它的 scale 是 根號下 當前特征圖的 scale 乘后一個特征圖的 scale,
| 特征圖 | 特征圖的維度 | Prior Scale | Aspect Ratios | 每個位置上 prior 的個數 | 特征圖上 prior 的總個數 |
|---|---|---|---|---|---|
conv4_3 | 38, 38 | 0.1 | 1:1, 2:1, 1:2 + an extra prior | 4 | 5776 |
conv7 | 19, 19 | 0.2 | 1:1, 2:1, 1:2, 3:1, 1:3 + an extra prior | 6 | 2166 |
conv8_2 | 10, 10 | 0.375 | 1:1, 2:1, 1:2, 3:1, 1:3 + an extra prior | 6 | 600 |
conv9_2 | 5, 5 | 0.55 | 1:1, 2:1, 1:2, 3:1, 1:3 + an extra prior | 6 | 150 |
conv10_2 | 3, 3 | 0.725 | 1:1, 2:1, 1:2 + an extra prior | 4 | 36 |
conv11_2 | 1, 1 | 0.9 | 1:1, 2:1, 1:2 + an extra prior | 4 | 4 |
| Grand Total | – | – | – | – | 8732 priors |
??總共為SSD300定義了 8732 個 prior,
可視化 prior
??我們根據它們的 scale 和 aspect ratios 定義 prior,我們將 scale 記為 s,將aspect ratios記為 a,前面我們說過 prior 的面積等于
s
2
s^2
s2,則:
w
?
h
=
s
2
w
h
=
a
w · h = s^2 \\ \frac{w}{h} = a
w?h=s2hw?=a
??解出這些方程就可以得出 prior 的維度 w 和 h
w
=
s
?
a
h
=
s
a
w = s· \sqrt{a} \\ h = \frac{s}{\sqrt{a}}
w=s?a
?h=a
?s?
??現在我們可以在它們各自的特征圖上畫出它們了,
??作為一個例子,我們嘗試繪制 conv9_2 特征圖中心位置的 priors,
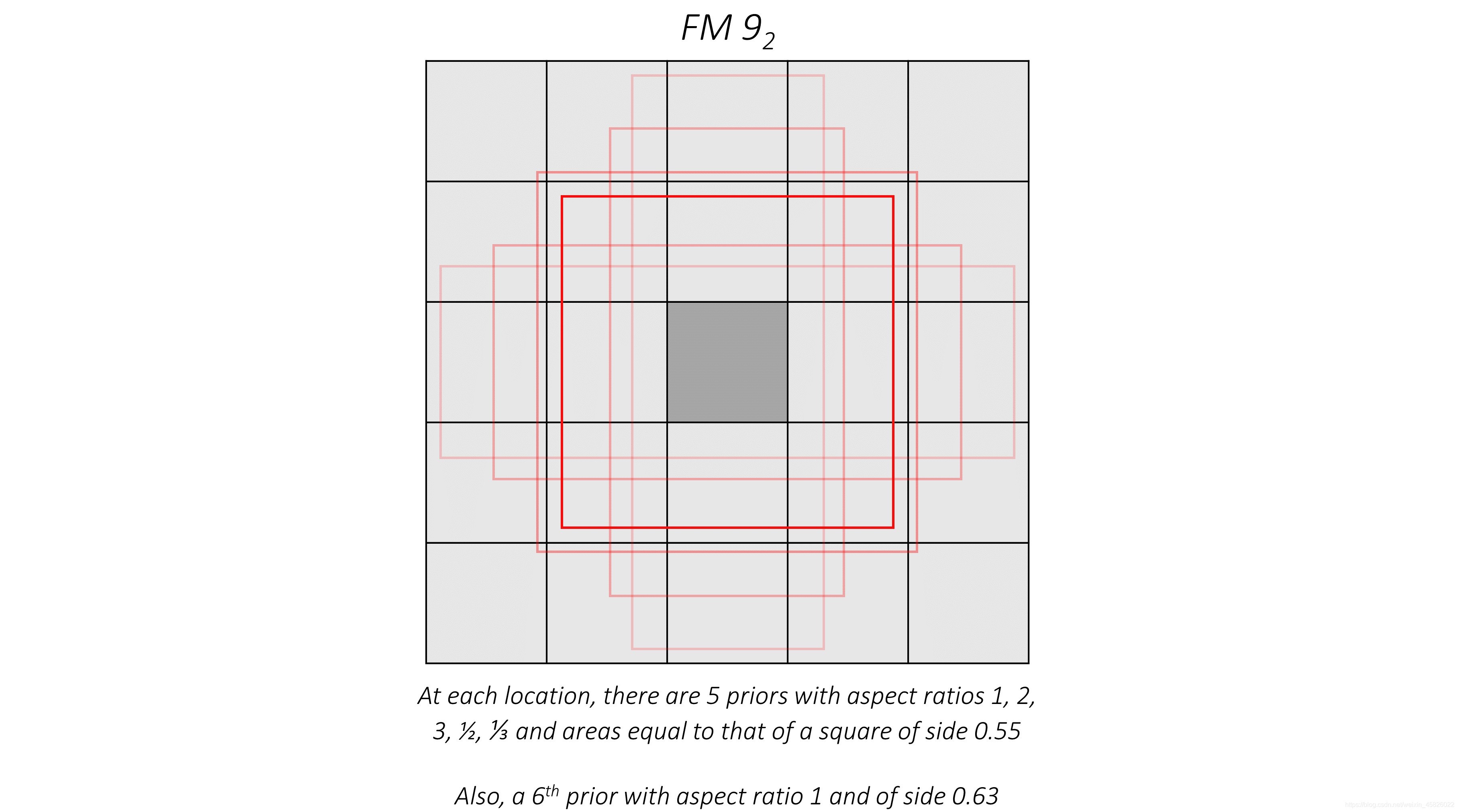
??對于其他位置也存在一樣的 prior
??現在你已經知道prior大概的樣子,那就來通俗的說一下prior如何計算,對于conv9_2特征圖來說,它的特征圖大小為 5, 5,而conv9_2的scale是 0.55,prior的 aspect ratios是 [1, 2:1, 3:1, 1:2, 1:3],因此通過上面的式子
w
=
s
a
,
h
=
s
a
w=s\sqrt{a}, h=\frac{s}{\sqrt{a}}
w=sa
?,h=a
?s?,我們可以求出每個prior的 w 和 h ,結果為:
[
0.55
1
0.55
1
0.55
2
0.55
2
0.55
3
0.55
3
0.55
1
2
0.55
1
2
0.55
1
3
0.55
1
3
0.55
×
0.725
0.55
×
0.725
]
=
[
0.5500
0.5500
0.7778
0.3889
0.9526
0.3175
0.3889
0.7778
0.3175
0.9526
0.6315
0.6315
]
\begin{bmatrix} 0.55\sqrt{1} & \frac{0.55}{\sqrt{1}} \\ 0.55\sqrt{2} & \frac{0.55}{\sqrt{2}} \\ 0.55\sqrt{3} & \frac{0.55}{\sqrt{3}} \\ 0.55\sqrt{\frac{1}{2}} & \frac{0.55}{\sqrt{\frac{1}{2}}} \\ 0.55\sqrt{\frac{1}{3}} & \frac{0.55}{\sqrt{\frac{1}{3}}} \\ \sqrt{0.55×0.725} & \sqrt{0.55×0.725} \end{bmatrix} = \begin{bmatrix} 0.5500 & 0.5500 \\ 0.7778 & 0.3889 \\ 0.9526 & 0.3175 \\ 0.3889 & 0.7778 \\ 0.3175 & 0.9526 \\ 0.6315 & 0.6315 \end{bmatrix}
?????????????0.551
?0.552
?0.553
?0.5521?
?0.5531?
?0.55×0.725
??1
?0.55?2
?0.55?3
?0.55?21?
?0.55?31?
?0.55?0.55×0.725
???????????????=?????????0.55000.77780.95260.38890.31750.6315?0.55000.38890.31750.77780.95260.6315??????????
??這就是每個prior的寬和高,而且是縮放后的,如果再加上中心,那不就是中心坐標了嗎?中心是什么?從上面的圖中可以明顯知道,prior的中心就是特征圖中每個格子的中心,例如第一個格子的中心是0.5, 0.5,第二個格子的中心是 1.5, 1.5,將這些中心除以 conv9_2 的大小 5 進行縮放,再與計算的prior的w 和 h 合并起來,就得到了每個格子所對應的 priors 的中心坐標,每個格子有6個prior,一共有5×5個格子,因此conv9_2特征圖上共有
6
×
5
×
5
=
150
6×5×5= 150
6×5×5=150 個prior,
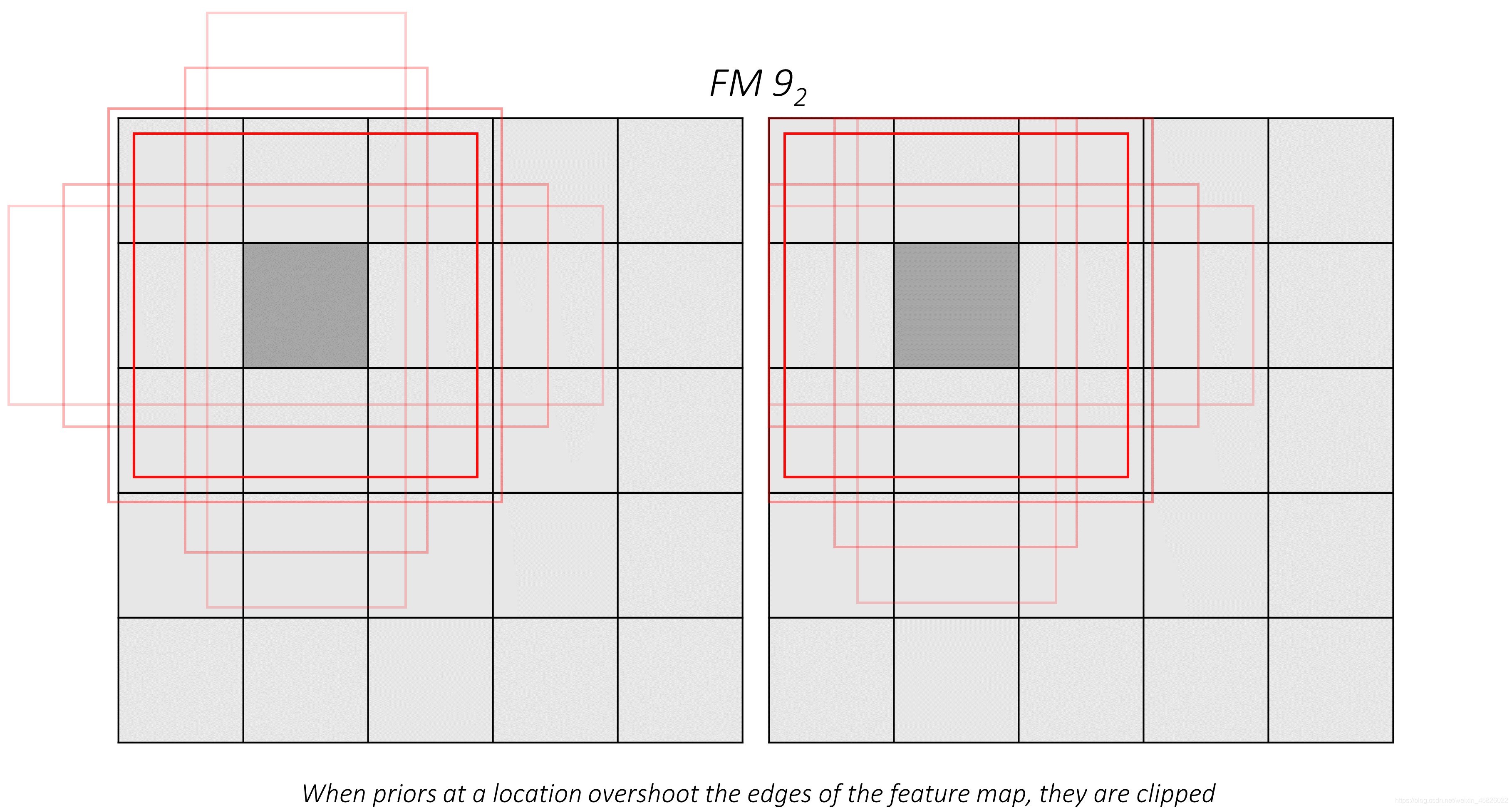
??需要注意的是,每個特征圖上的格子必須按照從左到右,從上到下的順序進行計算,也就是卷積移動的方式,這樣才能讓每個prior和其預測的偏移量對應上,
priors的代碼
??生成priors的代碼位于創建SSD300結構的類中,這里把它單獨提出作為演示,因為其沒有用到類中的其他變數,因此可以設定為一個靜態成員函式,
@staticmethod
def create_prior_boxes():
# 特征圖的尺寸
features_dim = {'conv4_3': 38, 'conv7': 19, 'conv8_2': 10,
'conv9_2': 5, 'conv10_2': 3, 'conv11_2': 1}
# prior的scale
object_scales = {'conv4_3': 0.1, 'conv7': 0.2, 'conv8_2': 0.375,
'conv9_2': 0.55, 'conv10_2': 0.725, 'conv11_2': 0.9}
# prior的aspect ratio
# conv7,conv8_2和conv9_2會多出 3:1 和 1:3
aspect_ratios = {
'conv4_3': [1., 2., 0.5],
'conv7': [1., 2., 3., 0.5, 0.333],
'conv8_2': [1., 2., 3., 0.5, 0.333],
'conv9_2': [1., 2., 3., 0.5, 0.333],
'conv10_2': [1., 2., 0.5],
'conv11_2': [1., 2., 0.5]
}
# 記錄特征圖的名稱,用來查找當前特征圖的下一個特征圖
features_name = list(features_dim.keys())
# 所有的priors
prior_boxes = []
# 每個特征圖都會有priors
for k, feature in enumerate(features_name):
# 每個特征圖的每個位置都有priors
# 模仿卷積的操作,按照從左到右,從上到下的順序計算priors,為了與預測卷積相匹配
for i in range(features_dim[feature]):
for j in range(features_dim[feature]):
# 當前特征圖的當前格子的中心坐標(需要進行縮放)
cx = (j + 0.5) / features_dim[feature]
cy = (i + 0.5) / features_dim[feature]
# 為當前格子按照aspect ratios生成priors
for ratio in aspect_ratios[feature]:
# w = s * sqrt(a), h = s / sqrt(a)
# 計算每個prior的中心坐標
prior_boxes.append([cx, cy, object_scales[feature] * sqrt(ratio),
object_scales[feature] / sqrt(ratio)])
# 當ratio時,需要額外添加一個prior
if ratio == 1.:
# 如果當前特征圖不是最后一個特征圖,即當前特征圖不是conv11_2
if k != len(features_name) - 1:
# 那么這個額外的prior的scale就是 sqrt(當前特征圖scale * 下一個特征圖scale)
additional_scale = sqrt(object_scales[feature] * object_scales[features_name[k + 1]])
else:
# 如果當前特征圖是最后一個,它就不存在下一個特征圖,直接將scale設定為1
additional_scale = 1.
# 添加額外的prior的中心坐標
prior_boxes.append([cx, cy, additional_scale, additional_scale])
# 最后將所有priors轉換為一個tensor
prior_boxes = torch.FloatTensor(prior_boxes).to(device) # [8732, 4]
return prior_boxes
預測的方法
??在前面,我們說過將使用回歸找到一個物體的邊界框,但是,priors 肯定不能代表我們最終預測的邊界框吧?肯定不能!
??我想再次重申,priors 只是近似的代表了預測的可能性,
??這意味著,我們使用每個 prior 作為近似的起點,然后找出需要調整多少才能獲得一個更精確的邊界框,
??因此,每一個預測的邊界框都與 prior 有所偏差,我們的目標就是計算這個偏差,我們需要一個方法來測量或量化偏差,
??考慮一只貓,它的預測邊界框,以及做出這個預測的 prior:

??假設它們用我們熟悉的中心坐標表示,然后:

??這就回答了我們在本節開始時提出的問題,考慮每個 prior 都被調整以獲得更精確的預測,這四個偏移量
(
g
c
x
,
g
c
y
,
g
w
,
g
h
)
(g_{c_x}, g_{c_y}, g_w, g_h)
(gcx??,gcy??,gw?,gh?)就是我們要回歸到 ground truth 坐標的形式,
??如你所見,每個偏移量都被相應的 prior 的維度標準化,這是有意義的,因為對于較大的 prior 來說,某些偏移的重要性要小于它對于較小的 prior 的重要性,
??類似于中心坐標和邊界坐標互相轉換一樣,我們也需要根據一個框和偏移量計算出真實框,也需要根據兩個框計算二者的偏移量,由圖中的式子我們知道應該用中心坐標體系,
- 計算兩組框之間的偏移量
??根據圖中的式子可以知道如何計算,但是需要注意,
g
c
x
、
g
c
y
g_{c_x}、g_{c_y}
gcx??、gcy?? 我們乘了10,
g
w
、
g
h
g_w、g_h
gw?、gh? 乘了5,這是圖中的式子沒有的,這是作者為了縮放梯度而提出的,完全是經驗性的,因此不用糾結為什么偏偏乘10和5而不是其他的數,
def cxcy_to_gcxgcy(cxcy, priors_cxcy):
"""
將對應的兩組框轉換為之間的偏移量
:param cxcy: 維度為 [n, 4] 的tensor,表示一組框的中心坐標
:param priors_cxcy: 維度為 [n, 4]的tensor,表示一組框的中心坐標
:return: 回傳對應兩個框之間的偏移量,維度為 [n, 4]
"""
# 10和5是為了縮放梯度,完全是經驗性的
return torch.cat([
(cxcy[:, :2] - priors_cxcy[:, :2]) / priors_cxcy[:, 2:] * 10, # g_cx, g_cy
torch.log(cxcy[:, 2:] / priors_cxcy[:, 2:]) * 5 # g_w, g_h
], dim=1)
- 根據一個框和偏移量計算偏移后的框
??因為上面的計算中分別乘了10和5,因此這里,作為逆操作,我們要除以10和5.
def gcxcy_to_cxcy(gcxcy, priors_cxcy):
"""
偏移量和對應的框,轉為偏移后的框
:param gcxcy: 維度為 [n, 4] 的tensor,表示偏移量
:param priors_cxcy: 維度為 [n, 4]的tensor,表示框的中心坐標
:return: 回傳偏移后的框,維度為 [n, 4]
"""
return torch.cat([
gcxcy[:, :2] * priors_cxcy[:, 2:] / 10 + priors_cxcy[:, :2], # cx,cy
torch.exp(gcxcy[:, 2:] / 5) * priors_cxcy[:, 2:] # w, h
], dim=1)
預測卷積
??在前面,我們對六個不同尺度和粒度的特征圖指定并定義了 priors,即conv4_3, conv7, conv8_2, conv9_2, conv10_2 和 conv11_2
??然后,對每個特征圖上每個位置的每個 prior,我們想要預測:
- 對邊界框的偏移量 ( g c x , g c y , g w , g h ) (g_{c_x}, g_{c_y}, g_w, g_h) (gcx??,gcy??,gw?,gh?)
- 每個邊界框的一組類別分數,總共有
n_classes個類別,其中包含背景類
??為了以最簡單的做到這些,我們需要為每個特征圖設定兩個卷積層——
- 一個預測位置的卷積層,它的卷積核大小為
3, 3(padding和步長均為1)在每個位置進行運算,每個 prior 有4個filters代表著位置,
一個prior 的4個 filters 計算這個 prior 生成的預測框的偏移量 ( g c x , g c y , g w , g h ) (g_{c_x}, g_{c_y}, g_w, g_h) (gcx??,gcy??,gw?,gh?) - 一個預測類別的卷積層,它的卷積核大小為
3, 3(padding和步長均為1)在每個位置進行運算,每個 prior 有n_classes個 filters,
一個 prior 的n_classes個 filters 計算了這個 prior 的類別分數
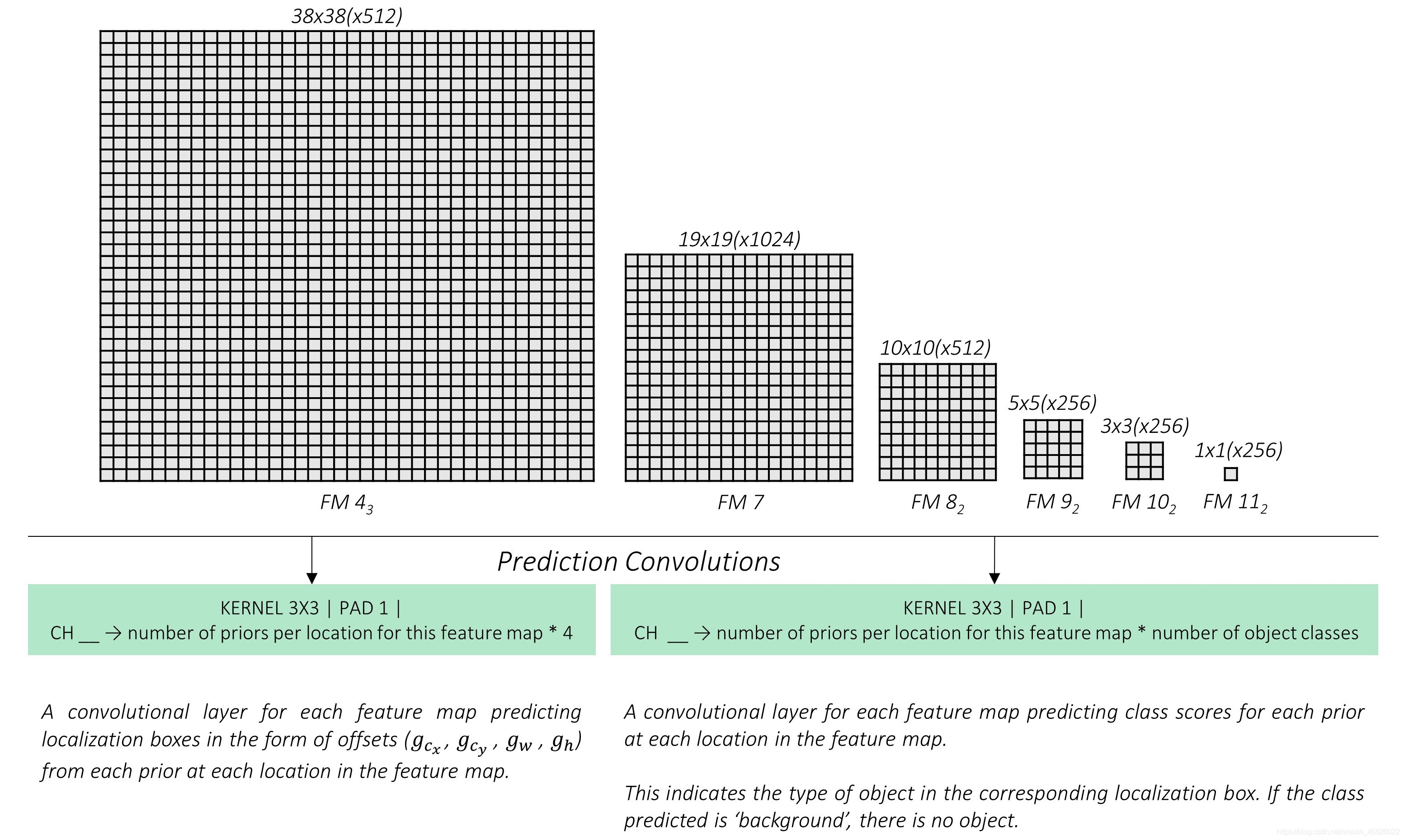
??所有的卷積核大小均為 3, 3,
??我們不需要與 priors 相同形狀的卷積核,因為不同的 filters 會學習對不同形狀的 priors 進行預測,
??讓我們看看這些卷積的輸出,仍然考慮 conv9_2 特征圖:
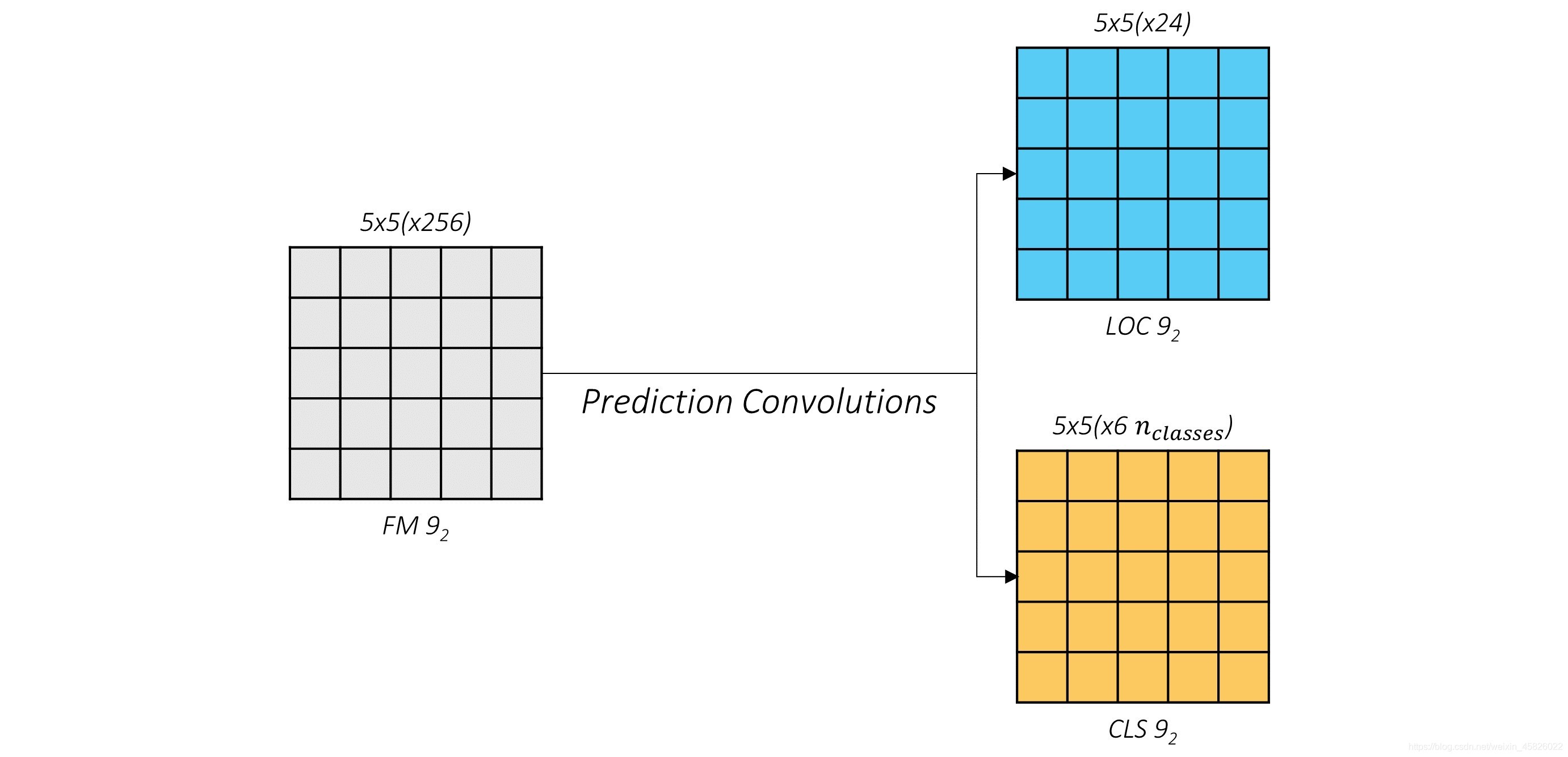
??位置預測層用藍色表示,類別預測層用黃色表示,你可以看到橫截面的大小(5, 5)不變,
??我們真正感興趣的是第三個維度,即通道數,它們包含了實際的預測,
??如果你選擇一個面,進行位置預測,并將預測結果展開,你將看到什么?
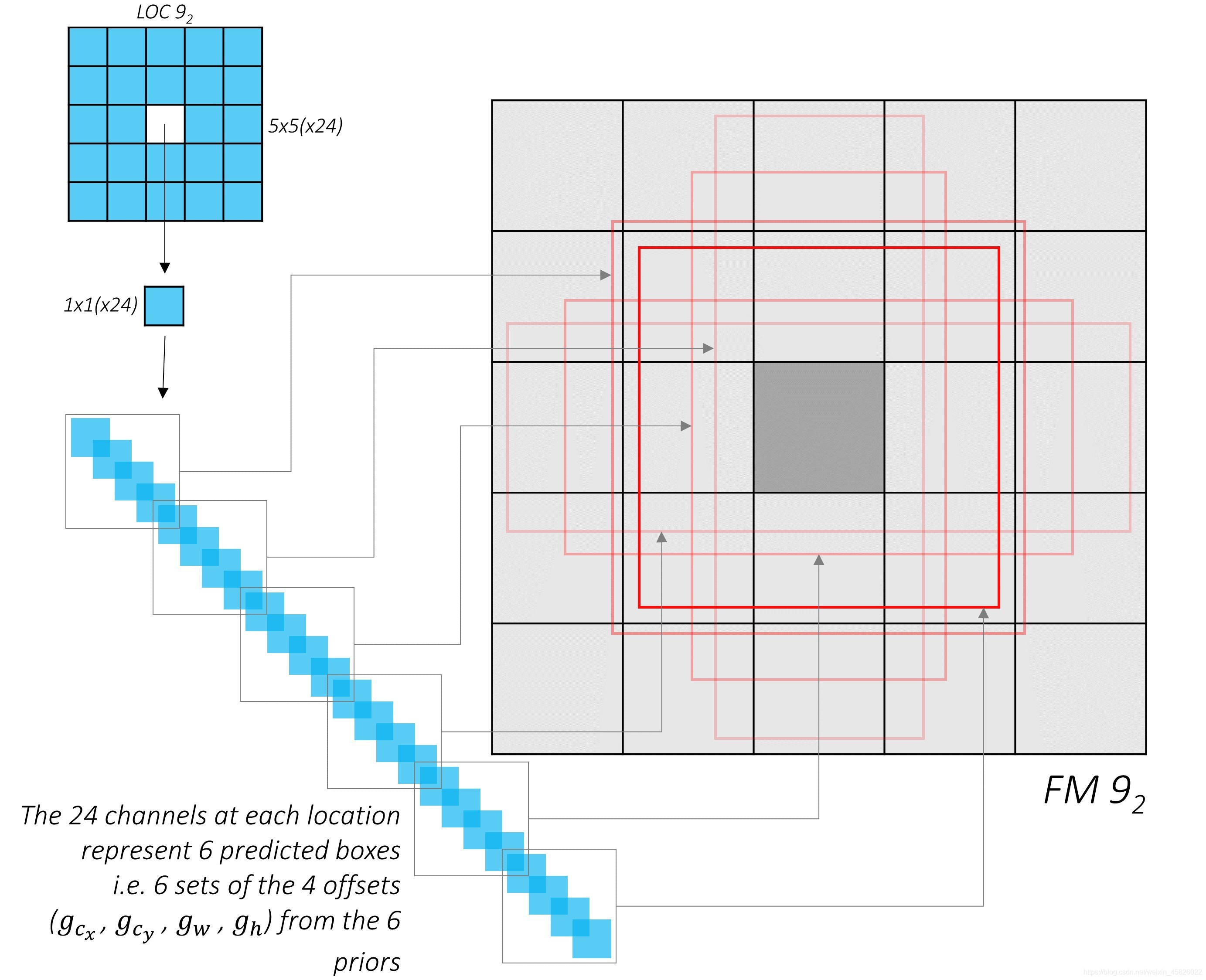
??那就是!位置預測結果的每個位置處的通道值代表了那個位置的 priors 的偏移量,
??現在,讓我們對類別預測做同樣的操作,考慮 n_classes = 3
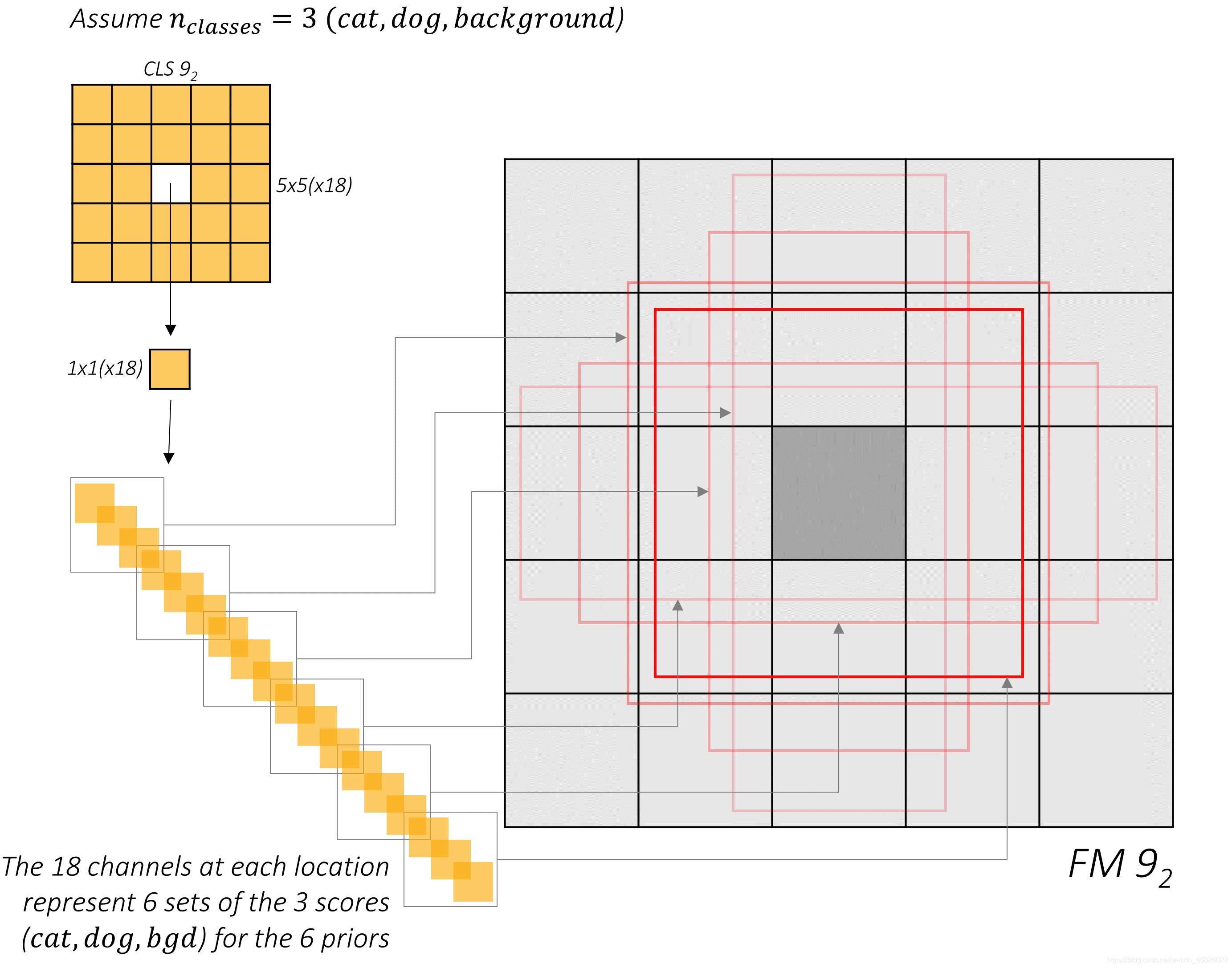
??和前面一樣,這些通道值代表了每一類的分數,
??現在我們已經了解了 conv9_2 特征圖的預測結果的樣子,我們可以把它們 reshape 為更容易理解的形式:
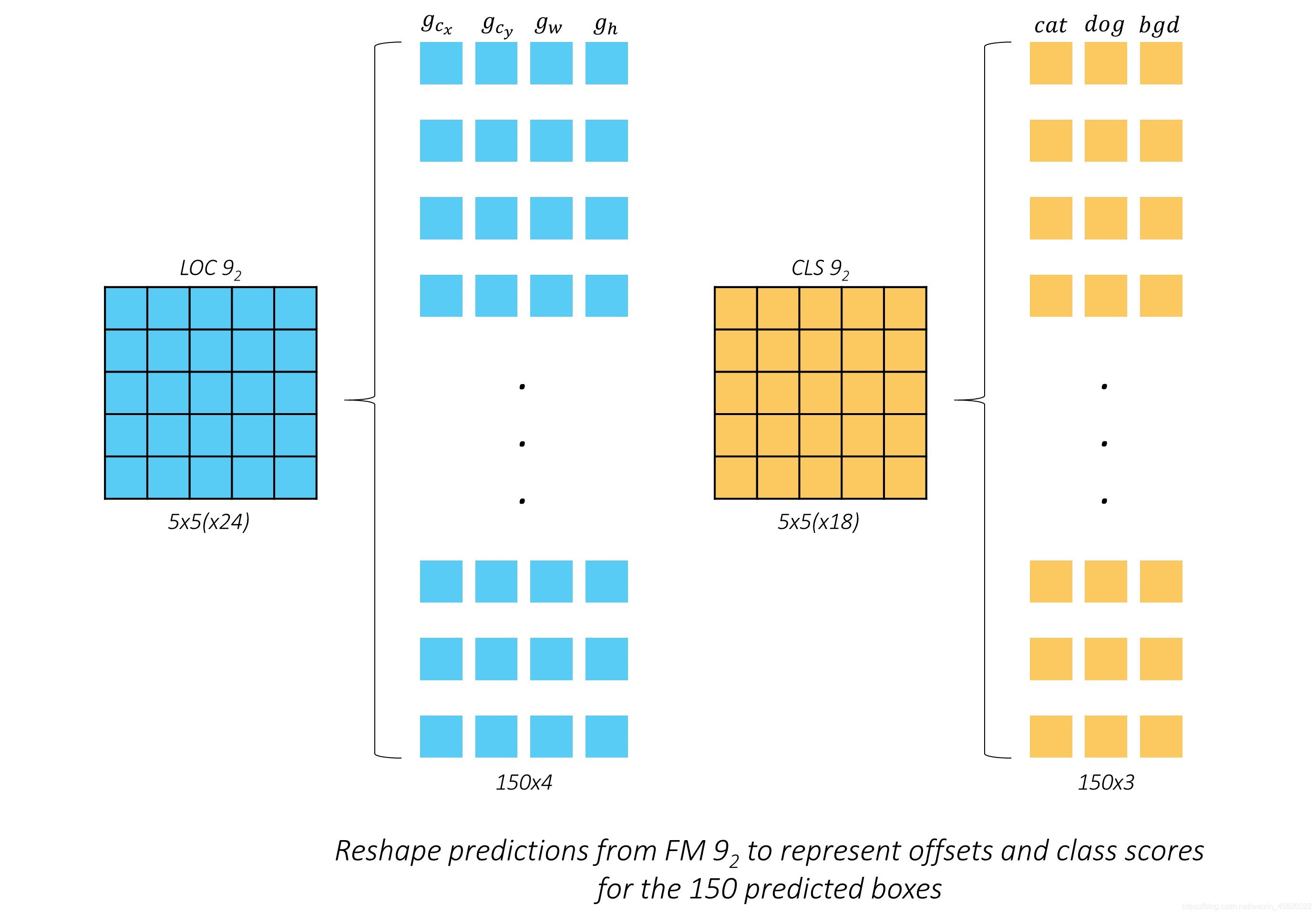
??我們將150個預測結果按順序排列,對于人來說,這樣應該顯得更加直觀,
??但是我們不能就此止步,我們可以對所有層做同樣的預測,然后將結果拼起來,
??我們之前計算過,一共生成了8732個 priors,因此,將有8732個編碼為偏移量形式的預測框和8732組類別分數,
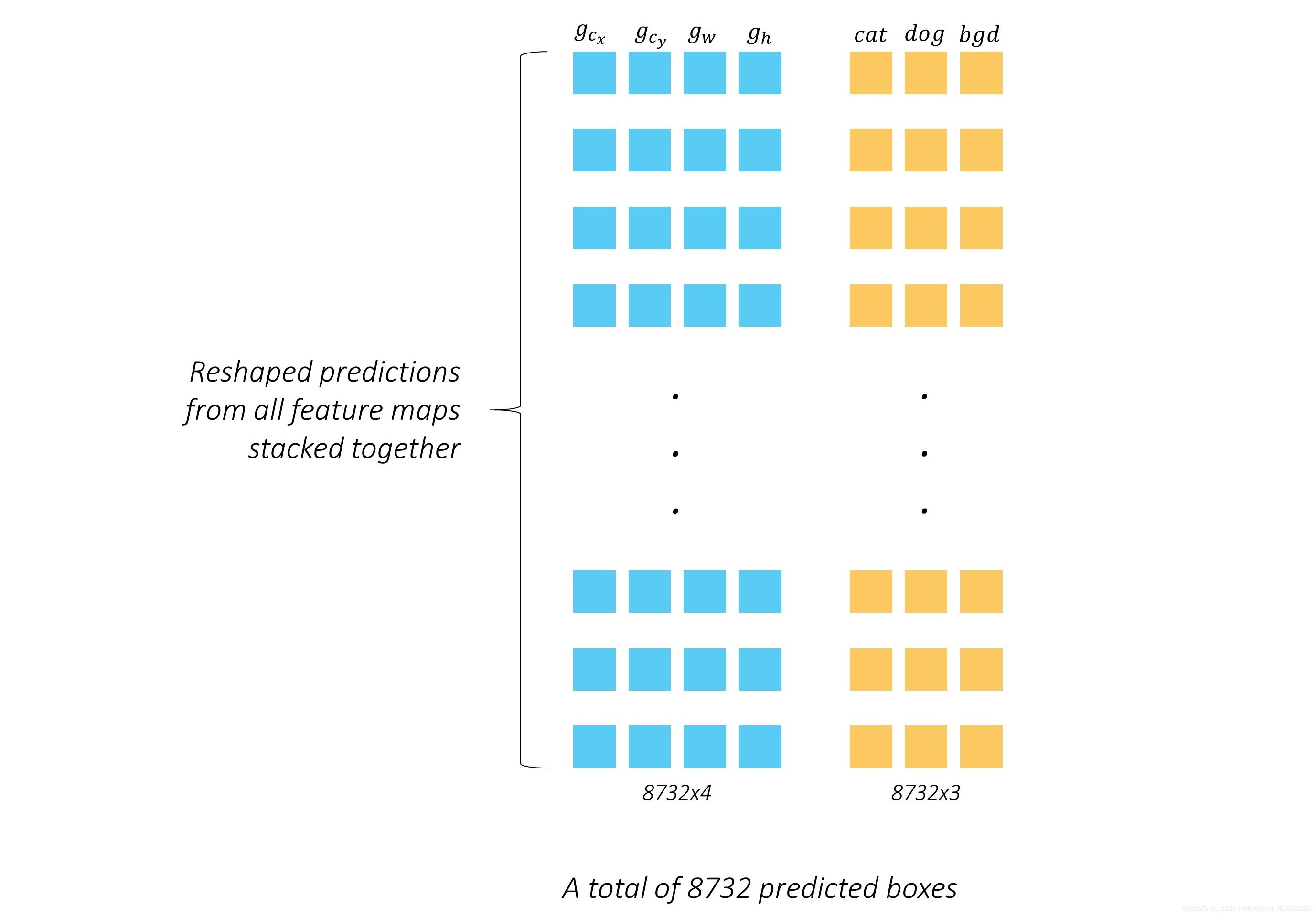
??這就是預測階段的最終輸出,一堆框,如果你愿意的話,還能估計里面有什么,
??一切都在一起,不是嗎?如果這是你第一次研究物體檢測,我想現在你應該看到了一絲光亮,
預測卷積的代碼
class PredictionConvolutions(nn.Module):
def __init__(self, n_classes):
super(PredictionConvolutions, self).__init__()
self.n_classes = n_classes
# 每個特征層上每一個點所設定的先驗框個數
n_priors_boxes = {'conv4_3': 4, 'conv7': 6, 'conv8_2': 6,
'conv9_2': 6, 'conv10_2': 4, 'conv11_2': 4}
# 位置預測卷積
self.loc_conv4_3 = nn.Conv2d(512, n_priors_boxes['conv4_3'] * 4, kernel_size=(3, 3), padding=1)
self.loc_conv7 = nn.Conv2d(1024, n_priors_boxes['conv7'] * 4, kernel_size=(3, 3), padding=1)
self.loc_conv8_2 = nn.Conv2d(512, n_priors_boxes['conv8_2'] * 4, kernel_size=(3, 3), padding=1)
self.loc_conv9_2 = nn.Conv2d(256, n_priors_boxes['conv9_2'] * 4, kernel_size=(3, 3), padding=1)
self.loc_conv10_2 = nn.Conv2d(256, n_priors_boxes['conv10_2'] * 4, kernel_size=(3, 3), padding=1)
self.loc_conv11_2 = nn.Conv2d(256, n_priors_boxes['conv11_2'] * 4, kernel_size=(3, 3), padding=1)
# 類別預測卷積
self.class_conv4_3 = nn.Conv2d(512, n_priors_boxes['conv4_3'] * n_classes, kernel_size=(3, 3), padding=1)
self.class_conv7 = nn.Conv2d(1024, n_priors_boxes['conv7'] * n_classes, kernel_size=(3, 3), padding=1)
self.class_conv8_2 = nn.Conv2d(512, n_priors_boxes['conv8_2'] * n_classes, kernel_size=(3, 3), padding=1)
self.class_conv9_2 = nn.Conv2d(256, n_priors_boxes['conv9_2'] * n_classes, kernel_size=(3, 3), padding=1)
self.class_conv10_2 = nn.Conv2d(256, n_priors_boxes['conv10_2'] * n_classes, kernel_size=(3, 3), padding=1)
self.class_conv11_2 = nn.Conv2d(256, n_priors_boxes['conv11_2'] * n_classes, kernel_size=(3, 3), padding=1)
# 初始化權重
self.init_weight()
def init_weight(self):
for conv in self.children():
if isinstance(conv, nn.Conv2d):
nn.init.xavier_normal_(conv.weight)
nn.init.constant_(conv.bias, 0.)
def forward(self, conv4_3_feats, conv7_feats, conv8_2_feats, conv9_2_feats, conv10_2_feats, conv11_2_feats):
batch_size = conv4_3_feats.size(0)
# 預測框的邊界
l_conv4_3 = self.loc_conv4_3(conv4_3_feats) # [b, 512, 38, 38] -> [b, 16, 38, 38]
l_conv4_3 = l_conv4_3.permute(0, 2, 3, 1).contiguous() # [b, 16, 38, 38] -> [b, 38, 38, 16]
l_conv4_3 = l_conv4_3.view(batch_size, -1, 4) # [b, 38, 38, 16] -> [b, 5776, 4]
l_conv7 = self.loc_conv7(conv7_feats) # [b, 1024, 19, 19] -> [b, 24, 19, 19]
l_conv7 = l_conv7.permute(0, 2, 3, 1).contiguous() # [b, 24, 19, 19] -> [b, 19, 19, 24]
l_conv7 = l_conv7.view(batch_size, -1, 4) # [b, 19, 19, 24] -> [b, 2166, 4]
l_conv8_2 = self.loc_conv8_2(conv8_2_feats) # [b, 512, 10, 10] -> [b, 24, 10, 10]
l_conv8_2 = l_conv8_2.permute(0, 2, 3, 1).contiguous() # [b, 24, 10, 10] -> [b, 10, 10, 24]
l_conv8_2 = l_conv8_2.view(batch_size, -1, 4) # [b, 10, 10, 24] -> [b, 600, 4]
l_conv9_2 = self.loc_conv9_2(conv9_2_feats) # [b, 256, 5, 5] -> [b, 24, 5, 5]
l_conv9_2 = l_conv9_2.permute(0, 2, 3, 1).contiguous() # [b, 24, 5, 5] -> [b, 5, 5, 24]
l_conv9_2 = l_conv9_2.view(batch_size, -1, 4) # [b, 5, 5, 24] -> [b, 150, 4]
l_conv10_2 = self.loc_conv10_2(conv10_2_feats) # [b, 256, 3, 3] -> [b, 16, 3, 3]
l_conv10_2 = l_conv10_2.permute(0, 2, 3, 1).contiguous() # [b, 16, 3, 3] -> [b, 3, 3, 16]
l_conv10_2 = l_conv10_2.view(batch_size, -1, 4) # [b, 3, 3, 16] -> [b, 36, 4]
l_conv11_2 = self.loc_conv11_2(conv11_2_feats) # [b, 256, 1, 1] -> [b, 16, 1, 1]
l_conv11_2 = l_conv11_2.permute(0, 2, 3, 1).contiguous() # [b, 16, 1, 1] -> [b, 1, 1, 16]
l_conv11_2 = l_conv11_2.view(batch_size, -1, 4) # [b, 1, 1, 16] -> [b, 4, 4]
# 預測框的類別
# [b, 512, 38, 38] -> [b, 4 * n_classes, 38, 38]
c_conv4_3 = self.class_conv4_3(conv4_3_feats)
# [b, 4 * n_classes, 38, 38] -> [b, 38, 38, 4 * n_classes]
c_conv4_3 = c_conv4_3.permute(0, 2, 3, 1).contiguous()
# [b, 38, 38, 4 * n_classes] -> [b, 5776, n_classes]
c_conv4_3 = c_conv4_3.view(batch_size, -1, self.n_classes)
# [b, 1024, 19, 19] -> [b, 6 * n_classes, 19, 19]
c_conv7 = self.class_conv7(conv7_feats)
# [b, 6 * n_classes, 19, 19] -> [b, 19, 19, 6 * n_classes]
c_conv7 = c_conv7.permute(0, 2, 3, 1).contiguous()
# [b, 19, 19, 6 * n_classes] -> [b, 2166, n_classes]
c_conv7 = c_conv7.view(batch_size, -1, self.n_classes)
# [b, 512, 10, 10] -> [b, 6 * n_classes, 10, 10]
c_conv8_2 = self.class_conv8_2(conv8_2_feats)
# [b, 6 * n_classes, 10, 10] -> [b, 10, 10, 6 * n_classes]
c_conv8_2 = c_conv8_2.permute(0, 2, 3, 1).contiguous()
# [b, 10, 10, 6 * n_classes] -> [b, 600, n_classes]
c_conv8_2 = c_conv8_2.view(batch_size, -1, self.n_classes)
# [b, 256, 5, 5] -> [b, 6 * n_classes, 5, 5]
c_conv9_2 = self.class_conv9_2(conv9_2_feats)
# [b, 6 * n_classes, 5, 5] -> [b, 5, 5, 6 * n_classes]
c_conv9_2 = c_conv9_2.permute(0, 2, 3, 1).contiguous()
# [b, 5, 5, 6 * n_classes] -> [b, 150, n_classes]
c_conv9_2 = c_conv9_2.view(batch_size, -1, self.n_classes)
# [b, 256, 3, 3] -> [b, 4 * n_classes, 3, 3]
c_conv10_2 = self.class_conv10_2(conv10_2_feats)
# [b, 4 * n_classes, 3, 3] -> [b, 3, 3, 4 * n_classes]
c_conv10_2 = c_conv10_2.permute(0, 2, 3, 1).contiguous()
# [b, 3, 3, 4 * n_classes] -> [b, 36, n_classes]
c_conv10_2 = c_conv10_2.view(batch_size, -1, self.n_classes)
# [b, 256, 1, 1] -> [b, 4 * n_classes, 1, 1]
c_conv11_2 = self.class_conv11_2(conv11_2_feats)
# [b, 4 * n_classes, 1, 1] -> [b, 1, 1, 4 * n_classes]
c_conv11_2 = c_conv11_2.permute(0, 2, 3, 1).contiguous()
# [b, 1, 1, 4 * n_classes] -> [b, 4, n_classes]
c_conv11_2 = c_conv11_2.view(batch_size, -1, self.n_classes)
# [b, 8732, 4]
loc = torch.cat([l_conv4_3, l_conv7, l_conv8_2, l_conv9_2, l_conv10_2, l_conv11_2], dim=1)
# [b, 8732, n_classes]
classes_scores = torch.cat([c_conv4_3, c_conv7, c_conv8_2, c_conv9_2, c_conv10_2, c_conv11_2], dim=1)
return loc, classes_scores
SSD300模型的代碼
??因為SSD300的代碼中有一個成員函式是用來對預測結果進行處理的,因此我打算介紹完處理后,再放代碼,處理將在最后一部分,如果你想看SSD300的代碼,只需到文章最后,
Multibox loss(損失函式)
??根據我們的預測結果,可能很容易理解為什么我們需要一個獨特的損失函式,我們很多人以前可能計算過回歸和分類任務的損失,但是很少同時計算,
??顯然,我們的損失必須是兩種預測型別損失的總和——邊界框的位置和類別分數,
??然后,這里有一些問題需要回答——
- 回歸邊界框將用什么損失函式?
- 我們會用多類別交叉熵作為類別分數的損失嗎?
- 我們以什么比例合并它們?
- 我們如何將預測的框與真實框進行匹配?
- 我們有8732個預測結果!其中大部分是不包含物體嗎?我們還需要考慮它們嗎?
讓我們繼續,
將預測框與真實框進行匹配
??記住,任何監督學習演算法的關鍵是我們需要能夠將預測結果與真實結果相匹配,這很棘手,因為物體檢測比一般學習任務更加開放,
??為了讓模型學習任何東西,我們需要以一種能夠將我們的預測與影像中實際存在的物體進行比較的方式來構造問題,
??priors 使我們能夠做到這一點!
- 計算 8732 個 priors 與 N個真實框的 Jaccard系數,這將得到一個維度為
[8732, N]的tensor - 找到每一個 prior 匹配最好(重疊程度最大)的真實框
- 如果一個 prior 與一個真實框的 Jaccard系數小于 0.5,我們就認為它不包含物體,因此它是一個負匹配,考慮到我們有成千上萬個 prior ,大多數 prior 都是負匹配,
- 另一方面,如果一個 prior 與一個真實框的 Jaccard 系數大于0.5,我們認為它包含這個物體,這是一個正匹配,
- 現在我們已經為 8732個priors 每一個都匹配到了真實框,實際上,我們還將相應的8732個預測匹配真實框,
??讓我們用一個例子重現這個邏輯:

??為了方便起見,我們僅假設有7個priors,由紅色顯示,真實框由黃色顯示,這張圖中一共有三個真實物體,
??按照前面概述的步驟,將生成以下匹配:
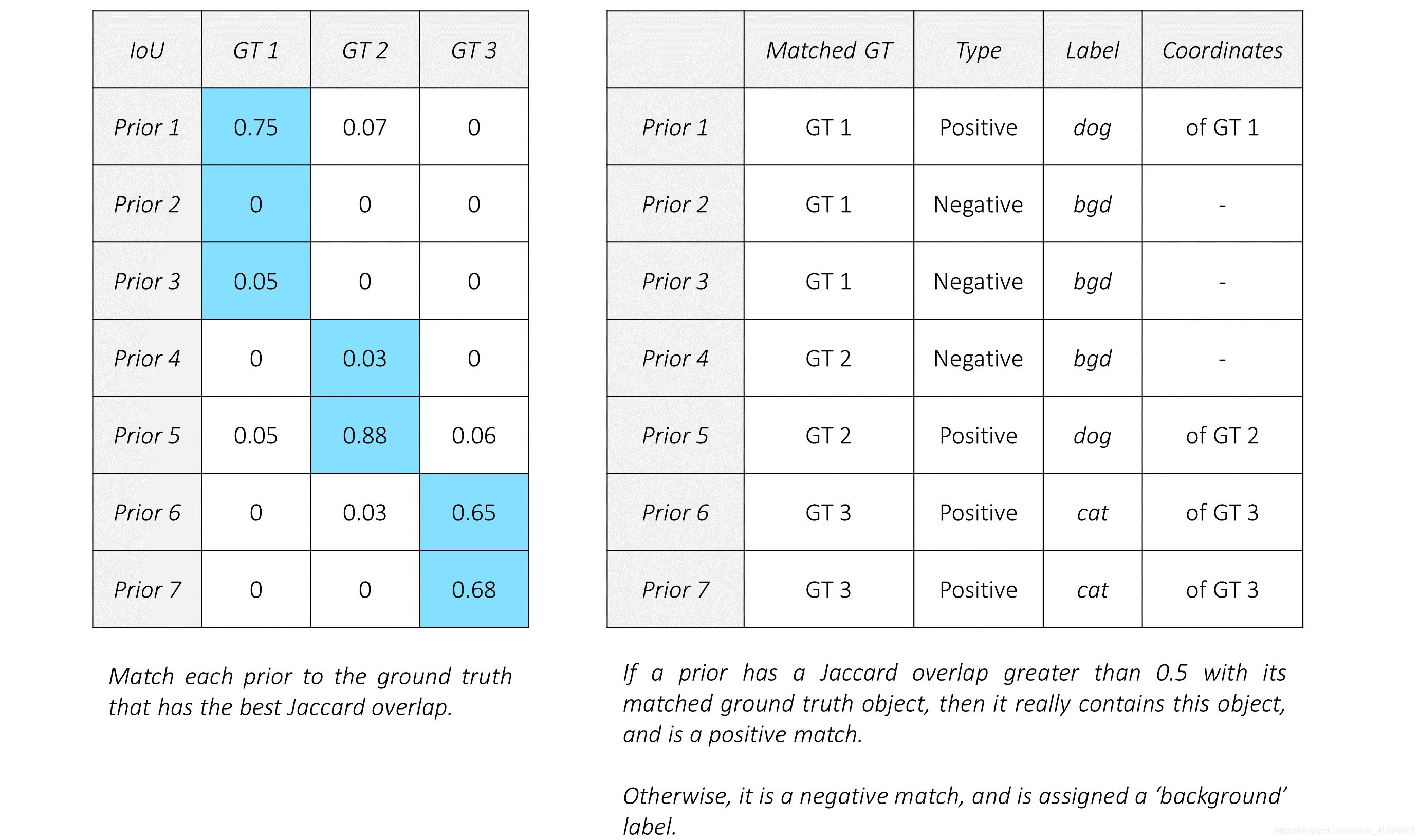
??現在每一個prior都有一個匹配,正或者負,擴展來說,每個預測都有一個匹配,正匹配或負匹配,
??預測為正匹配的結果,將存在一個真實框坐標與其對應,這個坐標將作為預測的目標,即回歸任務,當然,對于負匹配,沒有預測目標,
??所有的預測都有一個標簽,如果是正匹配,那么標簽就是真實物體標簽,如果是負匹配,那么標簽就是背景類,這些標簽將作為類別預測的目標,即分類任務,
定位損失
??我們沒有負匹配對應的真實坐標,這很有道理,我們為什么要訓練一個在空白處繪制框的模型?
??因此,定位損失的計算僅取決于我們如何準確地將預測框與相應的真實框坐標進行匹配,
??因為我們預測的定位框的形式是偏移量
(
g
c
x
,
g
c
y
,
g
w
,
g
h
)
(g_{c_x}, g_{c_y}, g_w, g_h)
(gcx??,gcy??,gw?,gh?),在計算損失之前,我們還需要相應的對真實框的坐標進行編碼,
??定位損失是正匹配的預測偏移量與其對應的真實框之間的 Smooth L1 損失的平均,

置信損失
??每一個預測,無論是正匹配還是負匹配,都有一個與之相應的標簽,重要的是,模型能夠同時識別物件和缺少物件,
??然而,考慮到影像中通常只有少量的物體,我們做的成千上萬的預測中,絕大多數實際上并不包含一個物體,如果負類比正類數量多很多,我們最終可能得到一個不太會檢測物體的模型,因為,它會更傾向預測背景類,
??解決辦法或許顯而易見,限制將在損失函式中評估的負匹配的數量,但我們該如何選擇呢?
??為什么不使用模型輸出最錯誤的那些呢?換句話說,只使用那些模型發現很難識別為沒有物體的預測,這叫做硬負采樣(Hard Negative Mining),
??我們通過硬負采樣的數量
N
h
n
N_{hn}
Nhn?,通常是這個圖片中正匹配個數的固定倍數,在該模型中,作者使用了3倍硬負采樣,即
N
h
n
=
3
?
N
p
N_{hn} = 3 * N_p
Nhn?=3?Np?,通過計算每個負匹配預測的交叉熵損失,并選取損失最大的前
N
h
n
N_{hn}
Nhn? 個,可以得到硬負采樣的損失,
??然后,置信損失就是正匹配和硬負匹配中的交叉熵損失之和,
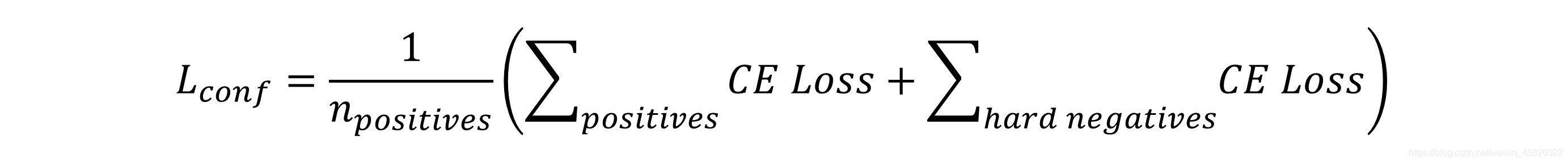
??從式子中,您將注意到,它是由正匹配的數量平均的,而不是正匹配數量和硬負采樣數量之和進行平均,
總損失
??Multibox loss是兩種損失的和,以比例
α
\alpha
α 進行組合,
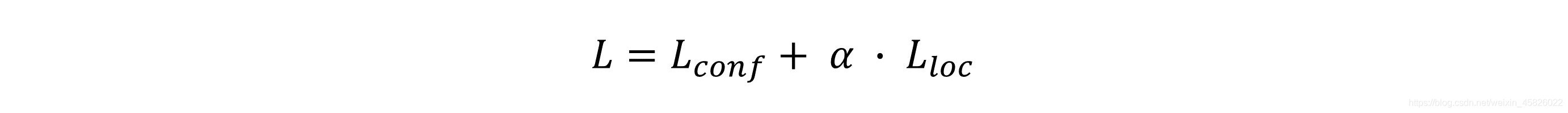
??一般來說我們不需要對
α
\alpha
α 設定值,它可以是一個可訓練引數,
??但是在SSD中,作者簡單地使用
α
=
1
\alpha = 1
α=1,我們也將使用它,
class MultiBoxLoss(nn.Module):
def __init__(self, priors_cxcy, threshold=0.5, neg_pos_ratio=3, alpha=1.):
"""
物體檢測的損失函式
:param priors_cxcy: tensor,默認生成的priors,中心坐標形式
:param threshold: 標量,表示設定重疊程度的閾值,當Jaccard系數大于閾值時認為是正匹配,默認為0.5
:param neg_pos_ratio: 標量,表示采樣的負樣本與正樣本的比例,默認為3
:param alpha: 標量,表示將定位損失和分類損失以什么比例相加,默認為1
"""
super(MultiBoxLoss, self).__init__()
self.priors_cxcy = priors_cxcy
# priors的邊界坐標表示
self.priors_xy = cxcy_to_xy(priors_cxcy)
self.threshold = threshold
self.neg_pos_ratio = neg_pos_ratio
self.alpha = alpha
self.smooth_l1 = nn.L1Loss()
self.cross_entropy = nn.CrossEntropyLoss(reduction='none')
def forward(self, predicted_loc, predicted_scores, boxes, labels):
"""
前向計算程序
:param predicted_loc: SSD300模型預測的位置,[b, 8732, 4]
:param predicted_scores: SSD300模型預測的類別分數 [b, 8732, n_classes]
:param boxes: 真實框 [b, n_objects, 4],注意n_objects不是固定數值,每張圖片內的物體個數可能不一樣
:param labels: 真實標簽 [b, n_objects]
:return: 標量,代表損失
"""
batch_size = predicted_loc.size(0)
n_priors = self.priors_cxcy.size(0)
n_classes = predicted_scores.size(2)
assert n_priors == predicted_loc.size(1) == predicted_scores.size(1)
true_loc = torch.zeros((batch_size, n_priors, 4), dtype=torch.float).to(device) # [b, 8732, 4]
true_classes = torch.zeros((batch_size, n_priors), dtype=torch.long).to(device) # [b, 8732]
# 對每張圖片
for i in range(batch_size):
n_objects = boxes[i].size(0)
# 計算先驗框與真實框的Jaccard系數
overlap = find_jaccard_overlap(boxes[i], self.priors_xy)
# 對于每個先驗框,找到具有最大重疊的物件
overlap_for_each_prior, object_for_each_prior = overlap.max(dim=0)
# 我們不希望遇到這樣的情況:存在某個物體沒有被正先驗框所表示,這包含兩種情況
# 1. 對每個先驗框,我們選擇其與真實框重疊最大的那個物體作為最佳檢測物體,這可能導致某個物體沒有一個先驗框與之對應
# 2. 對于有匹配物體的先驗框來說,如果其重疊程度低于設定的閾值(0.5),也將被設定為背景類
# 首先找到每個物體所對應的重疊程度最大的先驗框
_, prior_for_each_object = overlap.max(dim=1)
# 然后將每個物體分配給相應的具有最大重疊的先驗框,這解決了第1種情況
object_for_each_prior[prior_for_each_object] = torch.LongTensor(range(n_objects)).to(device)
# 為了保證這些先驗框合格,人為賦予一個大于閾值(0.5)的值,這解決了第2種情況
overlap_for_each_prior[prior_for_each_object] = 1.
# 每個先驗框的標簽
label_for_each_prior = labels[i][object_for_each_prior]
# 將重疊程度小于閾值的標簽設定為0(背景類)
label_for_each_prior[overlap_for_each_prior < self.threshold] = 0
true_classes[i] = label_for_each_prior
# 將真實框編碼為我們預測的偏移量形式,[8732, 4]
true_loc[i] = cxcy_to_gcxgcy(xy_to_cxcy(boxes[i][object_for_each_prior]), self.priors_cxcy)
positive_priors = true_classes != 0
# 僅在正先驗條件下計算定位損失
loc_loss = self.smooth_l1(predicted_loc[positive_priors], true_loc[positive_priors])
# 置信度損失是在每個圖片上的正先驗和最困難的負先驗上計算的
n_positives = positive_priors.sum(dim=1)
# 我們將使用最困難的(neg_pos_ratio * n_positives 個)負先驗,擁有最大的loss
# 這叫做硬負采樣,它專注于每張圖片上最困難的負先驗,同時也最大限度的減少了正負樣本不均衡問題
n_hard_negatives = self.neg_pos_ratio * n_positives
# 首先計算所有先驗的損失
conf_loss_all = self.cross_entropy(predicted_scores.view(-1, n_classes), true_classes.view(-1)) # [b * 8732]
conf_loss_all = conf_loss_all.view(batch_size, n_priors) # [b, 8732]
# 我們已經知道哪些先驗是正的
conf_loss_pos = conf_loss_all[positive_priors]
# 接著,我們需要尋找最困難的先驗
# 為了實作目標,我們僅根據每張圖片上的負先驗按照其loss的降序排列,然后取前 n_hard_negatives 個,作為最困難的負先驗
conf_loss_neg = conf_loss_all.clone()
conf_loss_neg[positive_priors] = 0. # 將正先驗設定為0,這樣按照降序排序的時候,負先驗會在前面
conf_loss_neg, _ = conf_loss_neg.sort(dim=1, descending=True)
hardness_ranks = torch.LongTensor(range(n_priors)).unsqueeze(0).expand_as(conf_loss_neg).to(device) # [b, 8732]
hard_negatives = hardness_ranks < n_hard_negatives.unsqueeze(1) # [b, 8732]
conf_loss_hard_neg = conf_loss_neg[hard_negatives]
# 像論文中一樣,僅在正先驗上求平均,盡管正先驗和負先驗都進行了計算
conf_loss = (conf_loss_hard_neg.sum() + conf_loss_pos.sum()) / n_positives.sum().float()
# 回傳總損失
return conf_loss + self.alpha * loc_loss
對預測進行處理
??在模型訓練后,我們可以將它應用到圖片上,然而,這些預測結果是未加工的——兩個tensor,包含8732個 priors 的偏移量和 類別分數,這些都需要經過處理,以獲得最終人類可以理解的帶有標簽的邊界框,
??這需要以下幾點:
- 我們有8732個表示為 prior 和其偏移量 ( g c x , g c y , g w , g h ) (g_{c_x}, g_{c_{y}}, g_w, g_h) (gcx??,gcy??,gw?,gh?) 的預測框,我們需要將它們解碼為邊界坐標,
- 然后,對每個非背景類:
- 為這8732個盒子中的每個盒子提取這個類的分數,
- 洗掉該分數低于指定閾值的框,
- 剩下的框是這個特定類別物體的候選框,
??此時,如果您要在原始影像上繪制這些候選框,您將看到許多高度重疊的框,這些框顯然是多余的,這是因為我們處理的數千個priors中,極有可能有多個預測對應于同一個物件,
??例如,考慮下面的圖片,

??很明顯,里面只有三個物體——兩只狗和一只貓,但是根據模型,有三只狗和兩只貓,
??請注意,這只是一個溫和的例子,真實情況可能會更糟,
??現在,對你來說,很明顯知道哪些盒子指的是同一個物體,這是因為你的大腦可以處理特定的盒子之間以及特定的物體之間顯著的重合,
??在實踐中,這將如何實作?
??首先,將每個類別的候選框按照它們的可能性排列,

??我們已經按分數對它們進行了排序,
??下一步是找出哪些候選框是多余的,我們已經有了一個工具來判斷兩個盒子有多相似——Jaccard系數,
??因此,如果我們計算所有相同類別盒子的兩兩之間的Jaccard系數,如下圖所示,我們可以查看每一對盒子之間的重疊程度,如果其顯著重疊(超過給定閾值),那么我們就留下分數最高的候選框,

??此時我們就淘汰了所有動物類別中的流氓候選框,
??這個步驟叫做非極大抑制(NMS),因為當發現多個候選框顯著重疊時,它們可能預測的是同一個物體,我們只保留分數最高的那一個,將其他的候選框全部抑制,
??在演算法上,它的實作如下:
- 在為每個候選框挑選其對應的最可能的類別后,對每個類別:
- 按照分數遞減的順序排列候選框
- 考慮得分最高的候選框,洗掉所有得分較低且與該最高分候選框重疊程度超過0.5的候選框
- 若存在下一個得分最高的候選框,則根據該候選框再次進行上述操作
- 重復這個操作直到對所有候選框都進行處理過
??最終的結果是,對于影像中的每個物體,你將只有一個單獨的盒子——最好的一個,

??非極大抑制對獲得高質量的預測是非常有用的,
??令人高興的是,這也是最后一步,
SSD300代碼
class SSD300(nn.Module):
def __init__(self, n_classes):
super(SSD300, self).__init__()
self.n_classes = n_classes
self.base = VGGBase() # 基礎卷積
self.aux_convs = AuxiliaryConvolutions() # 輔助卷積
self.pred_convs = PredictionConvolutions(n_classes) # 預測卷積
# 我們認為低級特征有很大的規模,因此使用 L2范數 重新進行縮放, 這是一個可訓練引數
# conv4_3_feats 有512個channels
self.rescale_factors = nn.Parameter(torch.FloatTensor(1, 512, 1, 1))
nn.init.constant_(self.rescale_factors, 20)
# 先驗框 priors
self.prior_cxcy_boxes = self.create_prior_boxes()
def forward(self, x):
# x shape -> [b, 3, 300, 300]
conv4_3_feats, conv7_feats = self.base(x) # [b, 512, 38, 38], [b, 1024, 19, 19]
# 對conv4_3使用L2規范化
norm = conv4_3_feats.pow(2).sum(dim=1, keepdim=True).sqrt() # [b, 1, 38, 38]
conv4_3_feats = conv4_3_feats / norm # [b, 512, 38, 38]
conv4_3_feats = conv4_3_feats * self.rescale_factors # [b, 512, 38, 38]
# [b, 512, 10, 10], [b, 256, 5, 5], [b, 256, 3, 3], [b, 256, 1, 1]
conv8_2_feats, conv9_2_feats, conv10_2_feats, conv11_2_feats = self.aux_convs(conv7_feats)
# [b, 8732, 4], [b, 8732, n_classes]
loc, classes_scores = self.pred_convs(conv4_3_feats, conv7_feats, conv8_2_feats,
conv9_2_feats, conv10_2_feats, conv11_2_feats)
return loc, classes_scores
@staticmethod
def create_prior_boxes():
# 特征圖的尺寸
features_dim = {'conv4_3': 38, 'conv7': 19, 'conv8_2': 10,
'conv9_2': 5, 'conv10_2': 3, 'conv11_2': 1}
# prior的scale
object_scales = {'conv4_3': 0.1, 'conv7': 0.2, 'conv8_2': 0.375,
'conv9_2': 0.55, 'conv10_2': 0.725, 'conv11_2': 0.9}
# prior的aspect ratio
# conv7,conv8_2和conv9_2會多出 3:1 和 1:3
aspect_ratios = {
'conv4_3': [1., 2., 0.5],
'conv7': [1., 2., 3., 0.5, 0.333],
'conv8_2': [1., 2., 3., 0.5, 0.333],
'conv9_2': [1., 2., 3., 0.5, 0.333],
'conv10_2': [1., 2., 0.5],
'conv11_2': [1., 2., 0.5]
}
# 記錄特征圖的名稱,用來查找當前特征圖的下一個特征圖
features_name = list(features_dim.keys())
# 所有的priors
prior_boxes = []
# 每個特征圖都會有priors
for k, feature in enumerate(features_name):
# 每個特征圖的每個位置都有priors
# 模仿卷積的操作,按照從左到右,從上到下的順序計算priors,為了與預測卷積相匹配
for i in range(features_dim[feature]):
for j in range(features_dim[feature]):
# 當前特征圖的當前格子的中心坐標(需要進行縮放)
cx = (j + 0.5) / features_dim[feature]
cy = (i + 0.5) / features_dim[feature]
# 為當前格子按照aspect ratios生成priors
for ratio in aspect_ratios[feature]:
# w = s * sqrt(a), h = s / sqrt(a)
# 計算每個prior的中心坐標
prior_boxes.append([cx, cy, object_scales[feature] * sqrt(ratio),
object_scales[feature] / sqrt(ratio)])
# 當ratio時,需要額外添加一個prior
if ratio == 1.:
# 如果當前特征圖不是最后一個特征圖,即當前特征圖不是conv11_2
if k != len(features_name) - 1:
# 那么這個額外的prior的scale就是 sqrt(當前特征圖scale * 下一個特征圖scale)
additional_scale = sqrt(object_scales[feature] * object_scales[features_name[k + 1]])
else:
# 如果當前特征圖是最后一個,它就不存在下一個特征圖,直接將scale設定為1
additional_scale = 1.
# 添加額外的prior的中心坐標
prior_boxes.append([cx, cy, additional_scale, additional_scale])
# 最后將所有priors轉換為一個tensor
prior_boxes = torch.FloatTensor(prior_boxes).to(device) # [8732, 4]
return prior_boxes
def detect_objects(self, predicted_loc, predicted_scores, min_score, max_overlap, top_k):
"""
根據預測結果檢測物體
:param predicted_loc: 預測的偏移量 [b, 8732, 4]
:param predicted_scores: 預測的分數 [b, 8732, n_classes]
:param min_score: 類別最低分數,如果低于此分數則認為這個物體不是該類
:param max_overlap: 最大重疊程度的閾值,非極大抑制所需
:param top_k: 最終只保留前k個結果
:return: 經過一系列篩選后的預測結果
"""
batch_size = predicted_loc.size(0)
n_priors = self.prior_cxcy_boxes.size(0)
predicted_scores = F.softmax(predicted_scores, dim=2) # [b, 8732, n_classes]
all_images_boxes = list()
all_images_labels = list()
all_images_scores = list()
assert n_priors == predicted_loc.size(1) == predicted_scores.size(1)
for i in range(batch_size):
# 將對priors預測的偏移量轉化為邊界坐標
decoded_loc = cxcy_to_xy(gcxcy_to_cxcy(predicted_loc[i], self.prior_cxcy_boxes)) # [8732, 4]
image_boxes = list()
image_labels = list()
image_scores = list()
# 檢查每一個類別
for c in range(1, self.n_classes): # 類別從1開始,0表示背景類
# 僅保留預測類別分數超過最低分數的預測框和類別
class_scores = predicted_scores[i][:, c] # [8732]
score_above_min_score = class_scores > min_score # torch.uint8 tensor, 索引
n_above_min_score = score_above_min_score.sum().item()
# 如果預測分數沒有超過最低分的,則該圖片認為不含物體
if n_above_min_score == 0:
continue
class_scores = class_scores[score_above_min_score]
class_decoded_loc = decoded_loc[score_above_min_score]
# 對預測框和類別,按照類別得分排序
class_scores, sort_index = class_scores.sort(dim=0, descending=True)
class_decoded_loc = class_decoded_loc[sort_index]
# 查找預測框之間的重疊
# 回傳一個 [n, n] 的張量,表示每個預測框與其他所有預測框的IoU值
overlap = find_jaccard_overlap(class_decoded_loc, class_decoded_loc) # [n, n]
# 非極大抑制
# 記錄要抑制的box,1表示抑制,0表示不抑制
suppress = torch.zeros(n_above_min_score, dtype=torch.uint8).to(device)
for box in range(class_decoded_loc.size(0)):
# 如果該box已經標記為抑制,則不必再次進行檢測
if suppress[box] == 1:
continue
# 抑制重疊大于允許最大重疊的box
suppress = torch.max(suppress, overlap[box] > max_overlap)
# 自身與自身重疊為1,但是不應該抑制本身
suppress[box] = 0
image_boxes.append(class_decoded_loc[1 - suppress])
image_labels.append(torch.LongTensor((1 - suppress).sum().item() * [c]).to(device))
image_scores.append(class_scores[1 - suppress])
if len(image_boxes) == 0:
# 如果沒有任何類別被檢測到,則為背景存一個占位符
image_boxes.append(torch.FloatTensor([[0., 0., 1., 1.]]).to(device))
image_labels.append(torch.FloatTensor([0]).to(device))
image_scores.append(torch.FloatTensor([0.]).to(device))
# 拼接為單個tensor
image_boxes = torch.cat(image_boxes, dim=0)
image_labels = torch.cat(image_labels, dim=0)
image_scores = torch.cat(image_scores, dim=0)
n_objects = image_scores.size(0)
# 僅保留前k個物件
if n_objects > top_k:
image_scores, sort_index = image_scores.sort(dim=0, descending=True)
image_scores = image_scores[:top_k] # (top_k)
image_boxes = image_boxes[sort_index][:top_k] # (top_k, 4)
image_labels = image_labels[sort_index][:top_k] # (top_k)
all_images_boxes.append(image_boxes)
all_images_labels.append(image_labels)
all_images_scores.append(image_scores)
return all_images_boxes, all_images_labels, all_images_scores
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/293962.html
標籤:其他
上一篇:順序表基本功能函式的實作
下一篇:c語言實作順序表(初階資料結構)