內容參考:《基于卷積神經網路的軸承故障 診斷演算法研究》–張偉
代碼參考:
https://github.com/AaronCosmos/wdcnn_bearning_fault_diagnosis
1 背景:
基于信號處理的特征提取+分類器的傳統智能診斷演算法,對專家經驗要求高,設計耗時且不能保證通用性,已經不能滿足機械大資料的要求,提出使用基于卷積神經網路智能診斷演算法來自動完成特征提取以及故障識別,
1.1 挑戰
機電產品故障診斷面臨的挑戰,有三大特點:
(1)資料量大,專業分析人員的數量嚴重不足,僅依靠人力進行檢測已不能滿足要求,亟需能夠進行自動診斷的智能演算法,
(2)資料型別多樣化,每條資料來源于不同機械設備,工況,以及物理位置,資料特征難挖掘,診斷的難度加大 ,
(3)高速率情況下,裝備中各零部件的聯系更加緊密,一個零件的微小故障很可能引發連鎖發應,致使整個設備癱瘓,
1.2 軸承智能故障診斷演算法研究現狀
軸承故障診斷時機械狀態監測的熱門研究方向,其演算法的核心在于信號特征提取與模式分類兩個部分,在軸承故障診斷領域,常見的特征提取演算法有快速傅里葉變化,小波變換,經驗模式分解以及信號的統計學特征等,常見的模式分類演算法有支持向量機,BP 神經網路(也稱為多層感知器),貝葉斯分類器以及最近鄰分類器等,當下軸承故障診斷的研究熱點是可以歸結為 3 類:尋找更好的特征表達;尋找最適合的特征表達以及分類器的組合;以及發明新的傳感器,
1.3 智能診斷演算法的研究存在以下幾個問題:
1)在一個機械系統中表現很好的特征提取器與分類器組合,當裝置變化時,不能保證其能否繼續保持高識別率,即演算法組合的通用性不能保證,
2)在進行故障診斷時,需要先分析機械系統的內在運行機理,再利用信號處理技術分析故障信號,這種做法,對設計人員的技術要求高,難度較大,
3)目前利用資料驅動的特征提取方法,需要預先對信號進行快速傅里葉變換或者小波變換,這種做法存在丟失重要時域特征的可能,
為了解決以上問題,最理想的方式是將特征提取與分類兩個環節合二為一,這樣不存在相互組合的難題,無需分析機械裝置的內在機理,由于直接作用在原始信號上,也不會造成資訊的缺失,
然而,卷積神經網路具有“端到端”的特點,即可以通過一個神經網路完成特征提取、特征降維與分類器分類這一整套程序,卷積神經網路的這個特點無疑彌補了當下故障診斷方式的不足,為故障診斷提供了一種嶄新的研究思路,
如下圖,為軸承智能診斷演算法步驟分解 :
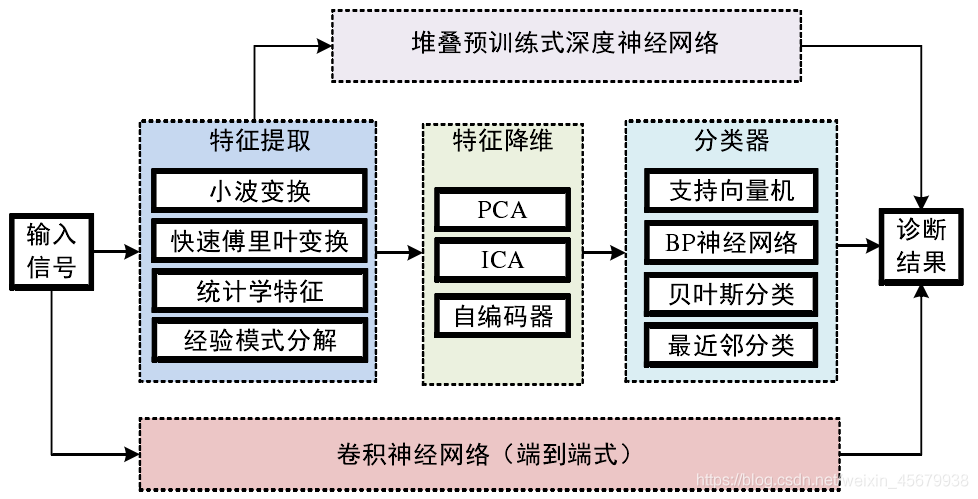
2 搭建卷積神經網路進行故障診斷(簡稱WDCNN)
WDCNN網路搭建的兩個關鍵點:
1)WDCNN第一層為大卷積核,目的是為了提取短時特征,其作用與短時傅里葉變換類似,不同點在于,短時傅里葉變換的視窗函式是正弦函式,而 WDCNN 的第一層大卷積核,是通過優化演算法訓練得到,其優點是可以自動學習面向診斷的特征,而自動去除對診斷沒有幫助的特征,
2)為了增強 WDCNN 的表達能力,除第一層外,其與卷積層的卷積核大小均為3×1,由于卷積核引數少,這樣有利于加深網路,同時可以抑制過擬合,每層卷積操作之后均進行批量歸一化處理 BN(Batch Normalization),然后進行 2×1 的最大值池化,
其中,BN目的是減少內部協變數轉移,提高網路的訓練效率,增強網路的泛化能力,
網路結構圖如下:
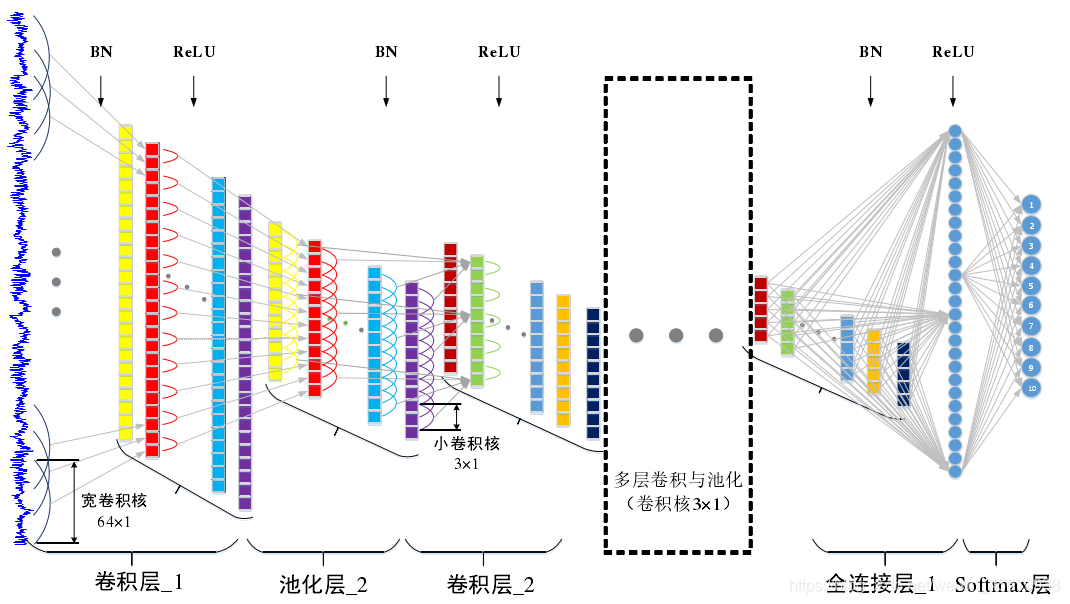
網路結構引數表如下:
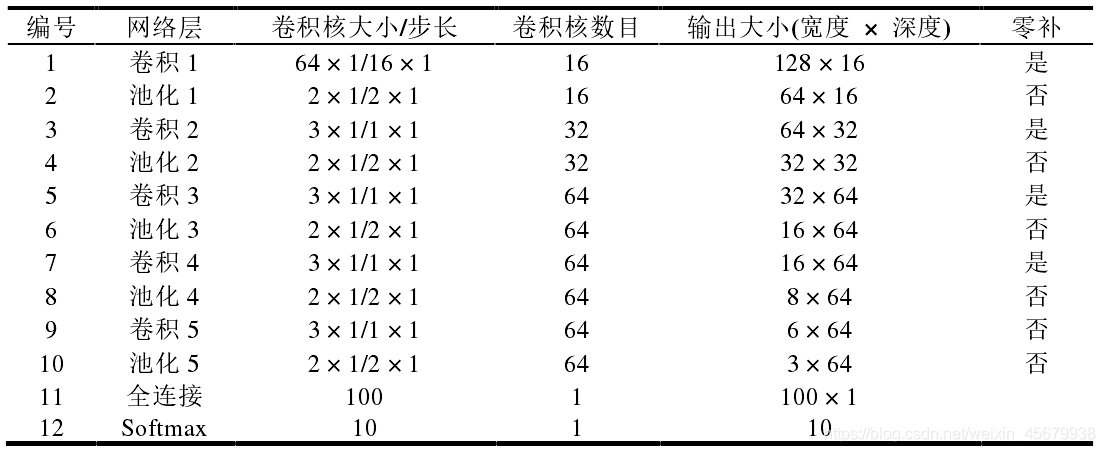
3 實驗
資料集:凱斯西儲大學(CWRU)滾動軸承資料中心
資料網址:https://csegroups.case.edu/bearingdatacenter/pages/download-data-file
試驗物件:為下圖中的驅動端軸承,被診斷的軸承型號為深溝球軸承 SKF6205,有故障的軸承由電火花加工制作而成,系統的采樣頻率為 12kHz,被診斷的軸承一共有 3 種缺陷位置,分別是滾動體損傷,外圈損傷與內圈損傷,損傷直徑的大小分別為包括 0.007inch, 0.014inch 和 0.021inch,共計 9 種損傷狀態,
如下圖,為CWRU 滾動軸承資料采集系統:

3.1 實驗代碼
(基于Tensorflow1.5進行操作,win10,i7-9700k,RTX2070SUPER)
(1)資料預處理代碼如下:
from scipy.io import loadmat
import numpy as np
import os
from sklearn import preprocessing # 0-1編碼
from sklearn.model_selection import StratifiedShuffleSplit # 隨機劃分,保證每一類比例相同
def prepro(d_path, length=864, number=1000, normal=True, rate=[0.5, 0.25, 0.25], enc=True, enc_step=28):
"""對資料進行預處理,回傳train_X, train_Y, valid_X, valid_Y, test_X, test_Y樣本.
:param d_path: 源資料地址
:param length: 信號長度,默認2個信號周期,864
:param number: 每種信號個數,總共10類,默認每個類別1000個資料
:param normal: 是否標準化.True,Fales.默認True
:param rate: 訓練集/驗證集/測驗集比例.默認[0.5,0.25,0.25],相加要等于1
:param enc: 訓練集、驗證集是否采用資料增強.Bool,默認True
:param enc_step: 增強資料集采樣順延間隔
:return: Train_X, Train_Y, Valid_X, Valid_Y, Test_X, Test_Y
```
import preprocess.preprocess_nonoise as pre
train_X, train_Y, valid_X, valid_Y, test_X, test_Y = pre.prepro(d_path=path,
length=864,
number=1000,
normal=False,
rate=[0.5, 0.25, 0.25],
enc=True,
enc_step=28)
```
"""
# 獲得該檔案夾下所有.mat檔案名
filenames = os.listdir(d_path)
def capture(original_path):
"""讀取mat檔案,回傳字典
:param original_path: 讀取路徑
:return: 資料字典
"""
files = {}
for i in filenames:
# 檔案路徑
file_path = os.path.join(d_path, i)
file = loadmat(file_path)
file_keys = file.keys()
for key in file_keys:
if 'DE' in key:
files[i] = file[key].ravel()
return files
def slice_enc(data, slice_rate=rate[1] + rate[2]):
"""將資料切分為前面多少比例,后面多少比例.
:param data: 單挑資料
:param slice_rate: 驗證集以及測驗集所占的比例
:return: 切分好的資料
"""
keys = data.keys()
Train_Samples = {}
Test_Samples = {}
for i in keys:
slice_data = data[i]
all_lenght = len(slice_data)
end_index = int(all_lenght * (1 - slice_rate))
samp_train = int(number * (1 - slice_rate)) # 700
Train_sample = []
Test_Sample = []
if enc:
enc_time = length // enc_step
samp_step = 0 # 用來計數Train采樣次數
for j in range(samp_train):
random_start = np.random.randint(low=0, high=(end_index - 2 * length))
label = 0
for h in range(enc_time):
samp_step += 1
random_start += enc_step
sample = slice_data[random_start: random_start + length]
Train_sample.append(sample)
if samp_step == samp_train:
label = 1
break
if label:
break
else:
for j in range(samp_train):
random_start = np.random.randint(low=0, high=(end_index - length))
sample = slice_data[random_start:random_start + length]
Train_sample.append(sample)
# 抓取測驗資料
for h in range(number - samp_train):
random_start = np.random.randint(low=end_index, high=(all_lenght - length))
sample = slice_data[random_start:random_start + length]
Test_Sample.append(sample)
Train_Samples[i] = Train_sample
Test_Samples[i] = Test_Sample
return Train_Samples, Test_Samples
# 僅抽樣完成,打標簽
def add_labels(train_test):
X = []
Y = []
label = 0
for i in filenames:
x = train_test[i]
X += x
lenx = len(x)
Y += [label] * lenx
label += 1
return X, Y
# one-hot編碼
def one_hot(Train_Y, Test_Y):
Train_Y = np.array(Train_Y).reshape([-1, 1])
Test_Y = np.array(Test_Y).reshape([-1, 1])
Encoder = preprocessing.OneHotEncoder()
Encoder.fit(Train_Y)
Train_Y = Encoder.transform(Train_Y).toarray()
Test_Y = Encoder.transform(Test_Y).toarray()
Train_Y = np.asarray(Train_Y, dtype=np.int32)
Test_Y = np.asarray(Test_Y, dtype=np.int32)
return Train_Y, Test_Y
def scalar_stand(Train_X, Test_X):
# 用訓練集標準差標準化訓練集以及測驗集
scalar = preprocessing.StandardScaler().fit(Train_X)
Train_X = scalar.transform(Train_X)
Test_X = scalar.transform(Test_X)
return Train_X, Test_X
def valid_test_slice(Test_X, Test_Y):
test_size = rate[2] / (rate[1] + rate[2])
ss = StratifiedShuffleSplit(n_splits=1, test_size=test_size)
for train_index, test_index in ss.split(Test_X, Test_Y):
X_valid, X_test = Test_X[train_index], Test_X[test_index]
Y_valid, Y_test = Test_Y[train_index], Test_Y[test_index]
return X_valid, Y_valid, X_test, Y_test
# 從所有.mat檔案中讀取出資料的字典
data = capture(original_path=d_path)
# 將資料切分為訓練集、測驗集
train, test = slice_enc(data)
# 為訓練集制作標簽,回傳X,Y
Train_X, Train_Y = add_labels(train)
# 為測驗集制作標簽,回傳X,Y
Test_X, Test_Y = add_labels(test)
# 為訓練集Y/測驗集One-hot標簽
Train_Y, Test_Y = one_hot(Train_Y, Test_Y)
# 訓練資料/測驗資料 是否標準化.
if normal:
Train_X, Test_X = scalar_stand(Train_X, Test_X)
else:
# 需要做一個資料轉換,轉換成np格式.
Train_X = np.asarray(Train_X)
Test_X = np.asarray(Test_X)
# 將測驗集切分為驗證集合和測驗集.
Valid_X, Valid_Y, Test_X, Test_Y = valid_test_slice(Test_X, Test_Y)
return Train_X, Train_Y, Valid_X, Valid_Y, Test_X, Test_Y
if __name__ == "__main__":
path = r'data\0HP'
train_X, train_Y, valid_X, valid_Y, test_X, test_Y = prepro(d_path=path,
length=864,
number=1000,
normal=False,
rate=[0.5, 0.25, 0.25],
enc=False,
enc_step=28)
(2)主程式代碼如下:
from keras.layers import Conv1D, Dense, Dropout, BatchNormalization, MaxPooling1D, Activation, Flatten
from keras.models import Sequential
from keras.utils import plot_model
from keras.regularizers import l2
import preprocess
from keras.callbacks import TensorBoard
import numpy as np
# 訓練引數
batch_size = 128
epochs = 20
num_classes = 10
length = 2048
BatchNorm = True # 是否批量歸一化
number = 1000 # 每類樣本的數量
normal = True # 是否標準化
rate = [0.7,0.2,0.1] # 測驗集驗證集劃分比例
path = r'data\0HP'
x_train, y_train, x_valid, y_valid, x_test, y_test = preprocess.prepro(d_path=path,length=length,
number=number,
normal=normal,
rate=rate,
enc=True, enc_step=28)
# 輸入卷積的時候還需要修改一下,增加通道數目
x_train, x_valid, x_test = x_train[:,:,np.newaxis], x_valid[:,:,np.newaxis], x_test[:,:,np.newaxis]
# 輸入資料的維度
input_shape =x_train.shape[1:]
print('訓練樣本維度:', x_train.shape)
print(x_train.shape[0], '訓練樣本個數')
print('驗證樣本的維度', x_valid.shape)
print(x_valid.shape[0], '驗證樣本個數')
print('測驗樣本的維度', x_test.shape)
print(x_test.shape[0], '測驗樣本個數')
# 定義卷積層
def wdcnn(filters, kernerl_size, strides, conv_padding, pool_padding, pool_size, BatchNormal):
"""wdcnn層神經元
:param filters: 卷積核的數目,整數
:param kernerl_size: 卷積核的尺寸,整數
:param strides: 步長,整數
:param conv_padding: 'same','valid'
:param pool_padding: 'same','valid'
:param pool_size: 池化層核尺寸,整數
:param BatchNormal: 是否Batchnormal,布林值
:return: model
"""
model.add(Conv1D(filters=filters, kernel_size=kernerl_size, strides=strides,
padding=conv_padding, kernel_regularizer=l2(1e-4)))
if BatchNormal:
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling1D(pool_size=pool_size, padding=pool_padding))
return model
# 實體化序貫模型
model = Sequential()
# 搭建輸入層,第一層卷積,因為要指定input_shape,所以單獨放出來
model.add(Conv1D(filters=16, kernel_size=64, strides=16, padding='same',kernel_regularizer=l2(1e-4), input_shape=input_shape))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling1D(pool_size=2))
# 第二層卷積
model = wdcnn(filters=32, kernerl_size=3, strides=1, conv_padding='same',
pool_padding='valid', pool_size=2, BatchNormal=BatchNorm)
# 第三層卷積
model = wdcnn(filters=64, kernerl_size=3, strides=1, conv_padding='same',
pool_padding='valid', pool_size=2, BatchNormal=BatchNorm)
# 第四層卷積
model = wdcnn(filters=64, kernerl_size=3, strides=1, conv_padding='same',
pool_padding='valid', pool_size=2, BatchNormal=BatchNorm)
# 第五層卷積
model = wdcnn(filters=64, kernerl_size=3, strides=1, conv_padding='valid',
pool_padding='valid', pool_size=2, BatchNormal=BatchNorm)
# 從卷積到全連接需要展平
model.add(Flatten())
# 添加全連接層
model.add(Dense(units=100, activation='relu', kernel_regularizer=l2(1e-4)))
# 增加輸出層
model.add(Dense(units=num_classes, activation='softmax', kernel_regularizer=l2(1e-4)))
# 編譯模型 評價函式和損失函式相似,不過評價函式的結果不會用于訓練程序中
model.compile(optimizer='Adam', loss='categorical_crossentropy',
metrics=['accuracy'])
# TensorBoard呼叫查看一下訓練情況
tb_cb = TensorBoard(log_dir='logs')
# 開始模型訓練
model.fit(x=x_train, y=y_train, batch_size=batch_size, epochs=epochs,
verbose=1, validation_data=(x_valid, y_valid), shuffle=True,
callbacks=[tb_cb])
# 評估模型
score = model.evaluate(x=x_test, y=y_test, verbose=0)
print("測驗集上的損失:", score[0])
print("測驗集上的準確度:",score[1])
# plot_model(model=model, to_file='wdcnn.png', show_shapes=True)
(3)運行結果如下:
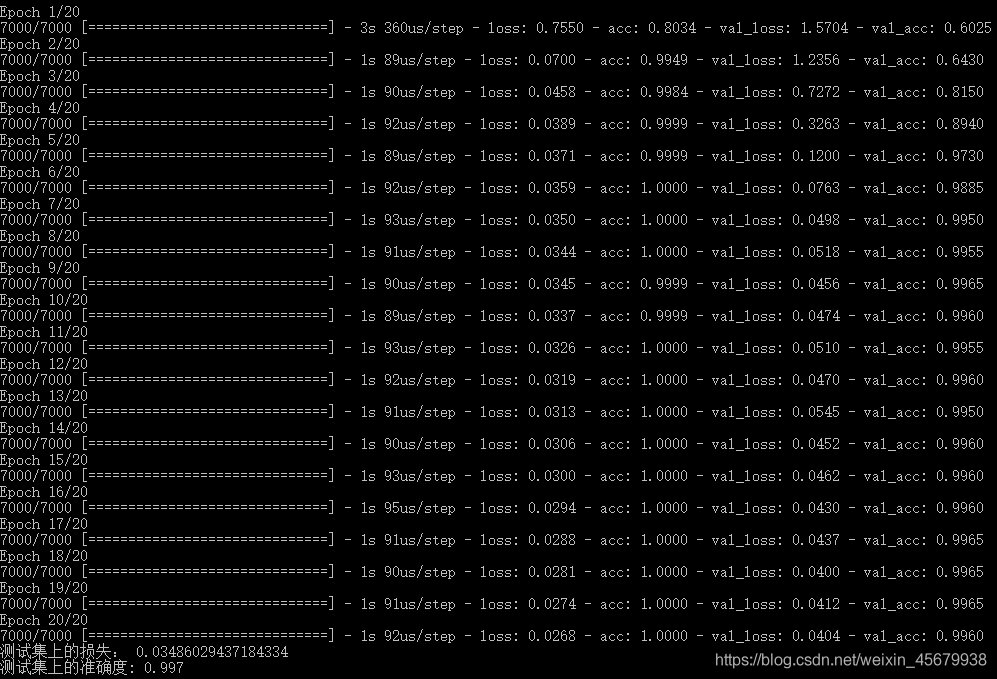
(4)啟用tensorboard觀察訓練效果如下:
命令:tensorboard --logdir=logs 或者python -m tensorboard.main --logdir=logs(前面不行用后面)
4 問題延申
4.1 關于噪聲與變載問題
在實際的工業應用中,作業環境十分復雜,有兩個問題在故障診斷領域值得關注:
1)工業現場的噪聲無法避免,使用加速度計測得的振動信號易被污染,如何從含有噪聲的信號中診斷出軸承的故障成為眾多學者研究的重點;
2)由于作業任務的變化,機器作業負載也會隨之改變,如何利用在一個負載下的資料進行訓練,對另一個負載下的信號進行診斷,是衡量智能診斷演算法適應能力的重要指標,
針對問題1:(噪聲影響)
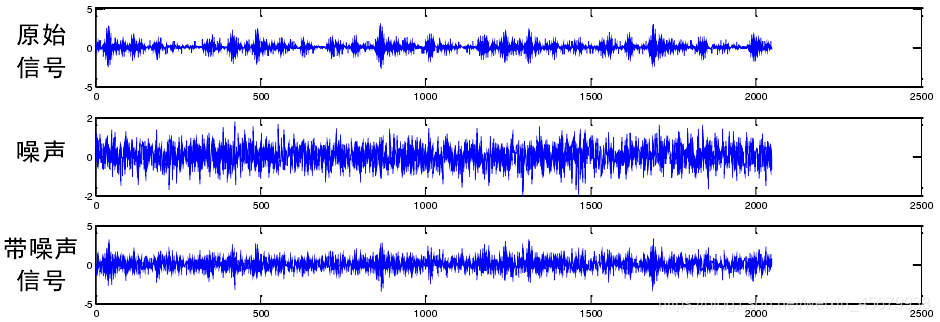
問題描述:信號被噪聲嚴重污染,人眼幾乎無法辨析出原型號的振動特征,因此,從帶有噪聲的信號中提取出有效的故障資訊,難度很大,
如下圖,為內圈故障信號,加性高斯白噪聲及兩者相加后 SNR=0dB 的信號 :
針對問題2:(變載情況)
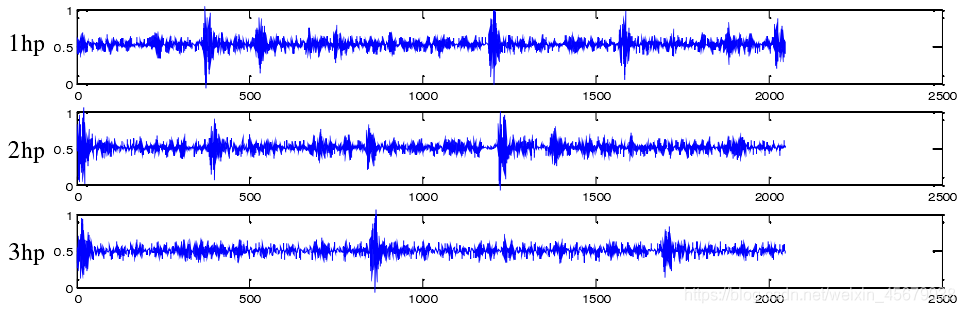
問題描述:作業負載的變化對一個機械系統很常見,當負載發生變化后,由傳感器測得的信號也會發生變化,不同負載下,振動信號中特征的個數不相同,幅值大小也不一致,波動周期與相位差別也很大,以上情況會造成分類器對提取的特征無法進行正確歸類,從而降低智能診斷系統的識別率,
如下圖,為不同負載下,歸一化后內圈缺陷大小為 0.014inch 的診斷信號:
解決方案:
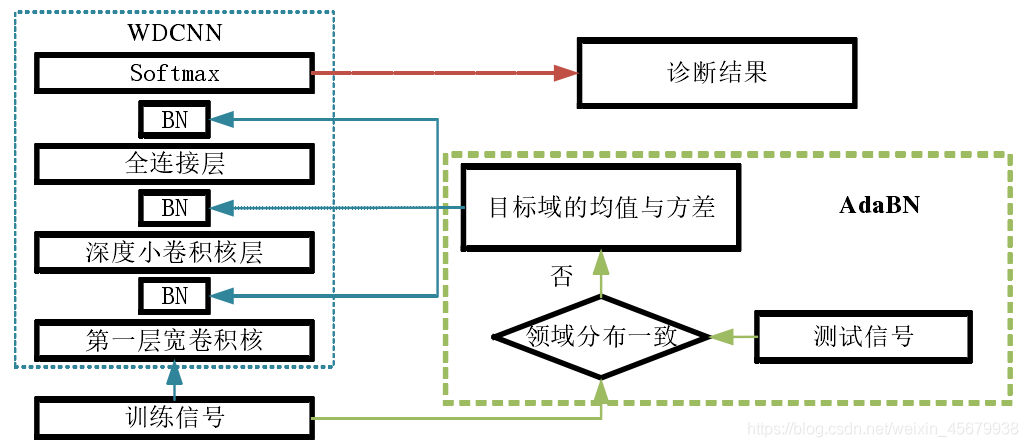
結合AdaBN 演算法,AdaBN是基于 BN 的領域自適應演算法,主要用于影像識別領域,該演算法使用目標領域樣本在每一個 BN 層的均值與方差,替換原來 BN 層所使用的由源領域樣本計算出的均值與方差,由于 BN 可以減少內部協變數,通過 BN 對源領域樣本的作用,以及 AdaBN 對目標領域樣本的作用,可以源領域與目標領域調整到一個新的分布空間,在此空間內,兩者近似一致,從而達到領域自適應的目的,因為 WDCNN演算法采用了 BN 演算法,所以可以使用 AdaBN 演算法來提高 WDCNN 模型的領域自適應能力,進而增強 WDCNN 模型在噪聲以及負載變化的情況下的適應能力,
框架圖如下:
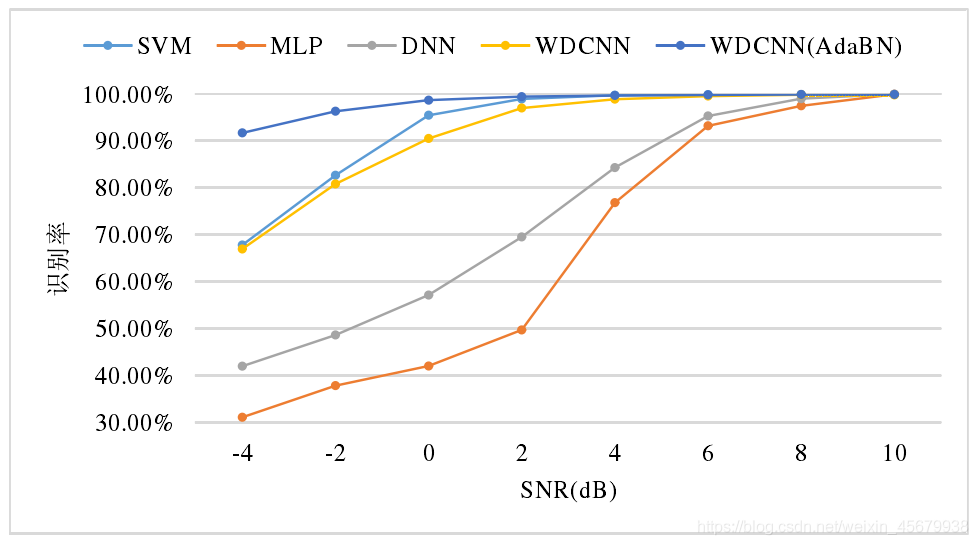
如下圖,WDCNN(AdaBN)在不同噪聲環境下與其它演算法的診斷率的對比:
4.2 AdaBN 演算法依賴測驗集統計學資訊問題
問題描述:
雖然 AdaBN 演算法可以提高 WDCNN 模型的抗噪能力與變載領域自適應能力,但 AdaBN 演算法需要整個測驗集的樣本在 WDCNN 每一個 BN 層的均值與方差,這對于一個故障診斷系統,在初期是難以滿足的,
解決思路:
1)根據部分測驗樣本的均值方差,對整體測驗樣本的均值方差進行估計;
2)不獲取任何測驗集的資訊,通過對 WDCNN 模型本身結構與訓練方式進行改進,增強其泛化能力,
具體措施:
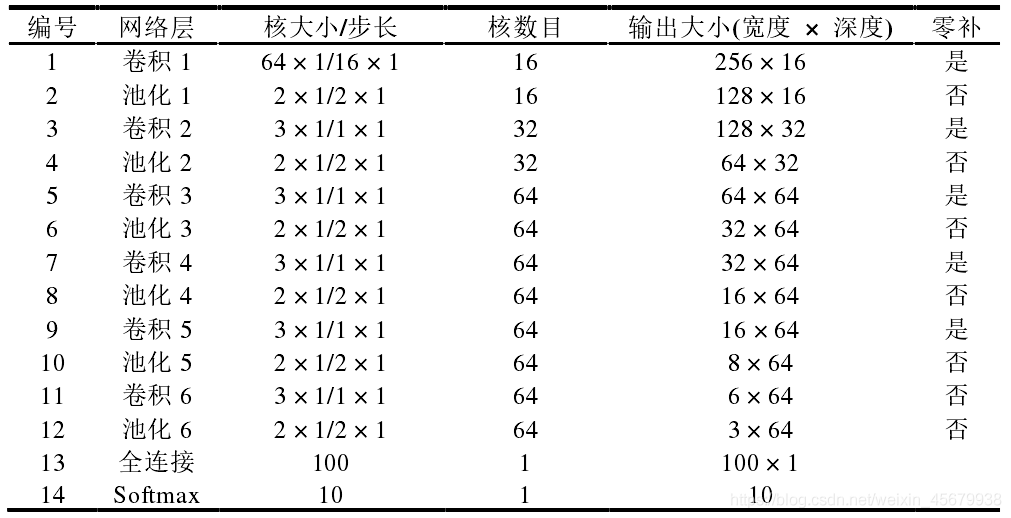
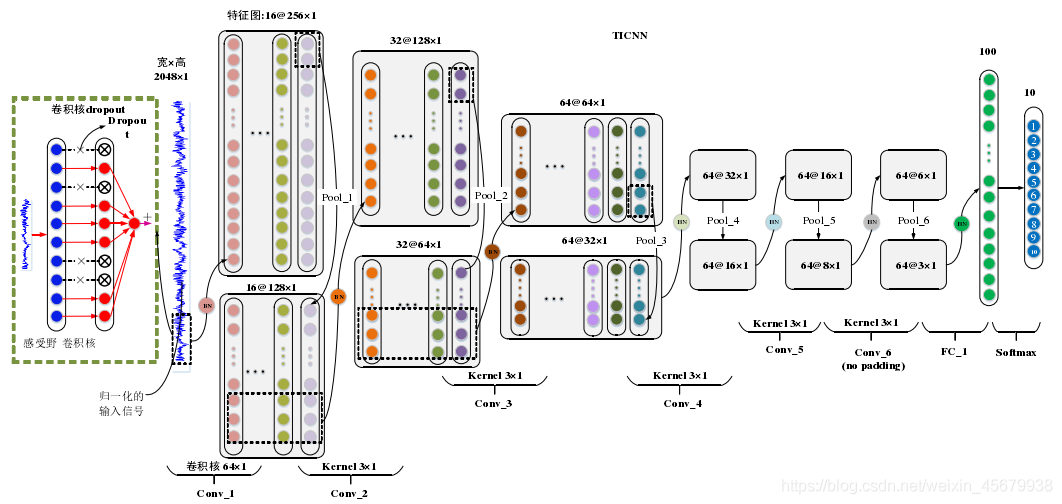
(1)TICNN 模型的結構與 WDCNN 類似,第一層卷積核均為大卷積核,大小為 64×1,之后的卷積核均為 3×1 的小卷積核,兩者結構上有兩點不同:1)TICNN 模型的第一個卷積層的步長從 16 減少到了 8,這樣做增加了 TICNN 模型在時域上的解析度;2)TICNN 增加了一個卷積層與池化層,這樣做可以增強網路的非線性表達能力,具體的模型引數如表 5-1 所示,其中第六個卷積層在卷積時沒有采用零補,其余的卷積操作均采用零補,此外,第一個卷積層的輸出神經元的個數為 4096,大于原始信號的長度 2048,表明第一個卷積層的特征是原始信號的過完備表達,
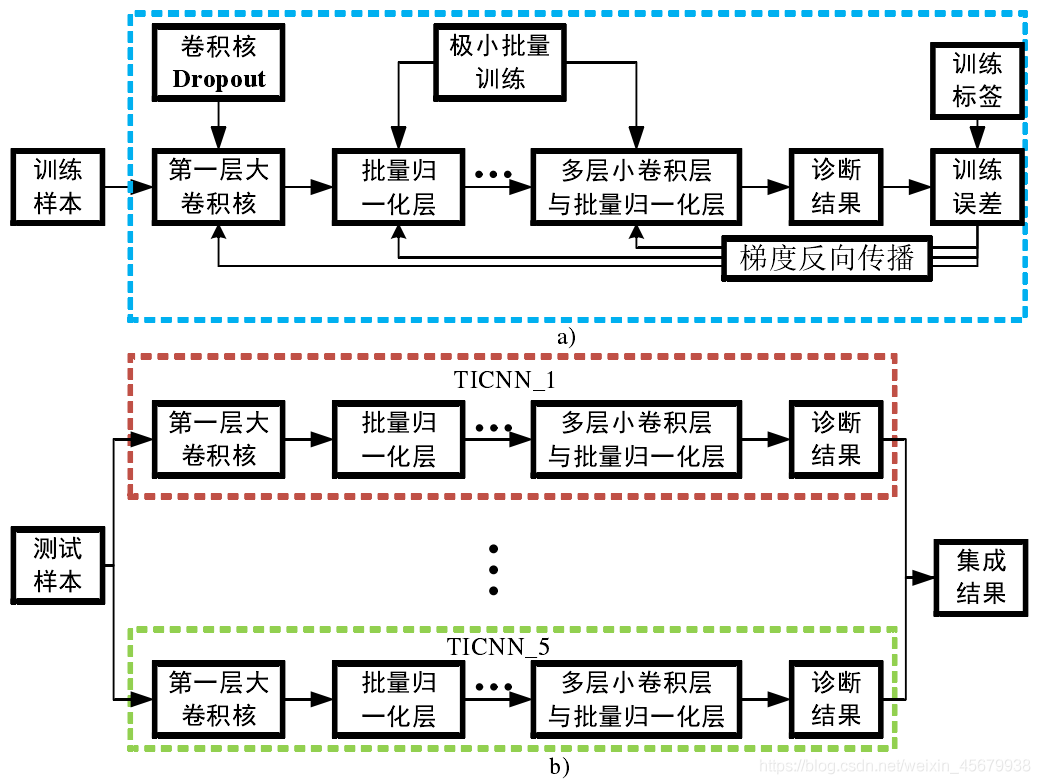
(2)在使用第一層大卷積核進行卷積時,先對卷積核進行 Dropout 操作,這是 TICNN 模型的第一個訓練干擾,目的是給 TICNN訓練時提供不完整的信號,從而強化 TICNN 在信號部分缺失時的診斷能力,
(3)TICNN 使用了極小的mini-batch 來進行批量訓練,這是 TICNN 模型的第二個訓練干擾,目的是增大 mini-batch 的均值方差變化范圍增加,增強模型對測驗集的均值方差于訓練集發生的偏移時容忍度,
(4)在測驗階段,采用集成學習的方式(Ensemble Learning)來進行預測,文中采用的是多數同意規則(Majority Voting),即獨立訓練 5 個 TICNN模型,對于同一個測驗樣本,采用投票的方式來決定信號所屬故障,集成學習被用來提高模型的識別率,增強模型的穩定性,
如下圖,為TICNN結構引數表:
如下圖,為TICNN網路結構:
如下圖,為TICNN 模型的訓練程序及測驗程序流程圖:
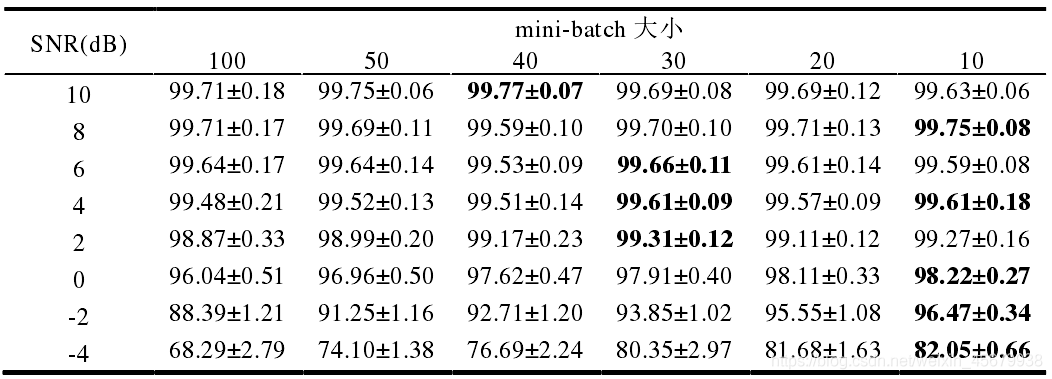
如下圖,為不同大小的 minibatch 下,TICNN 對噪聲信號的識別率:
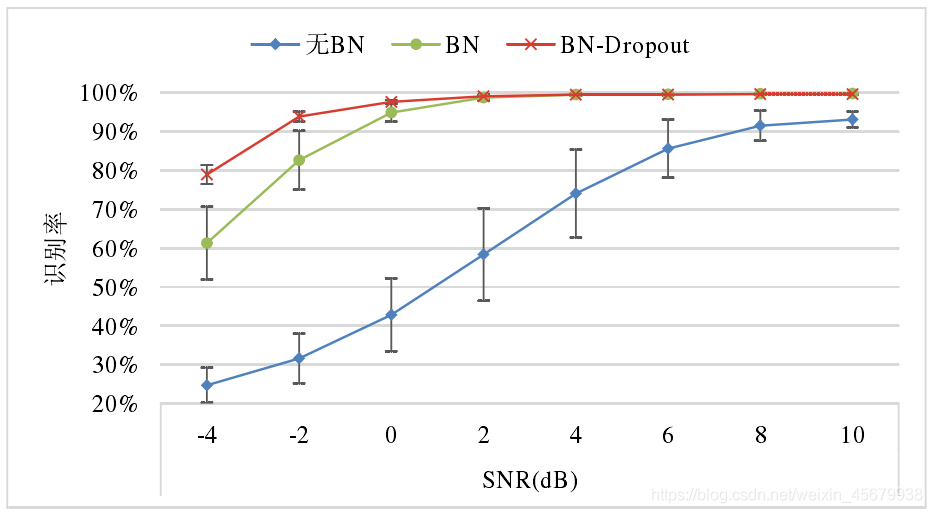
如下圖,為TICNN 在三種模式下的識別率:
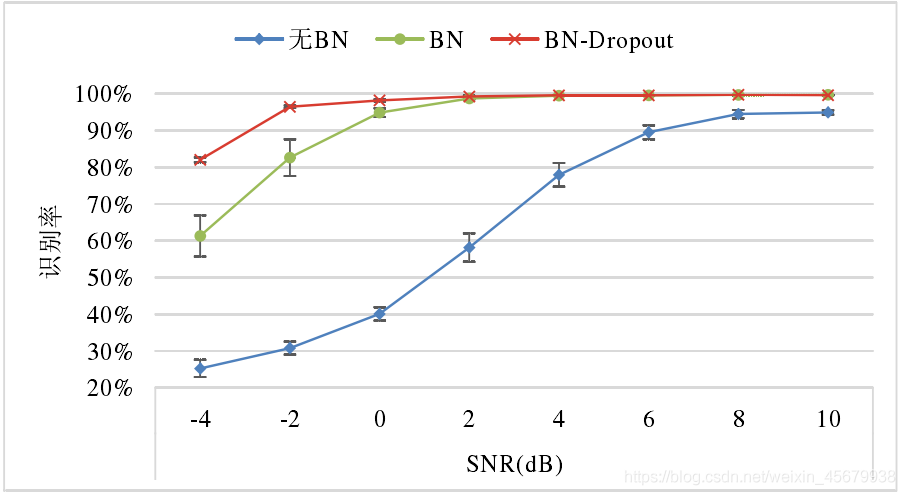
如下圖,為集成 TICNN 在三種模式下的識別率:
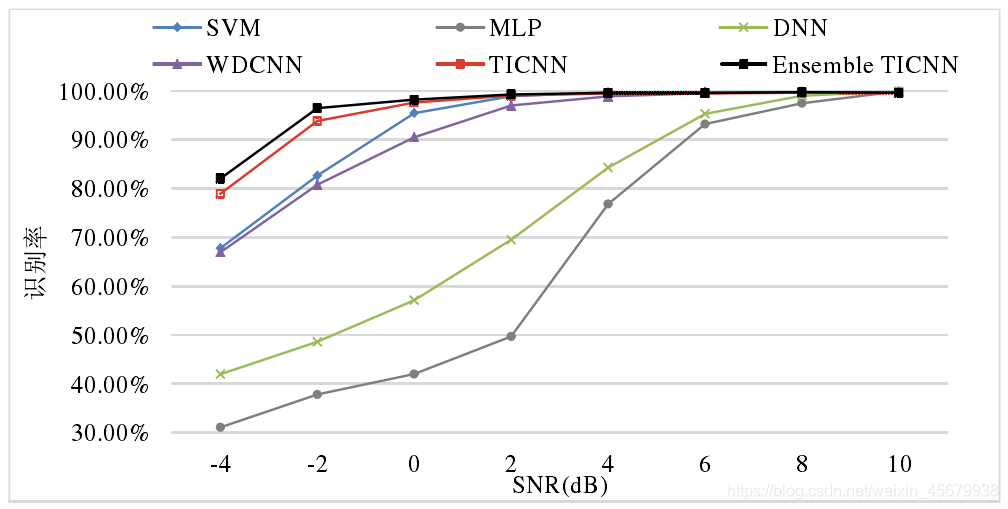
如下圖,為TICNN 在不同噪聲環境下與其它演算法的識別率對比 :
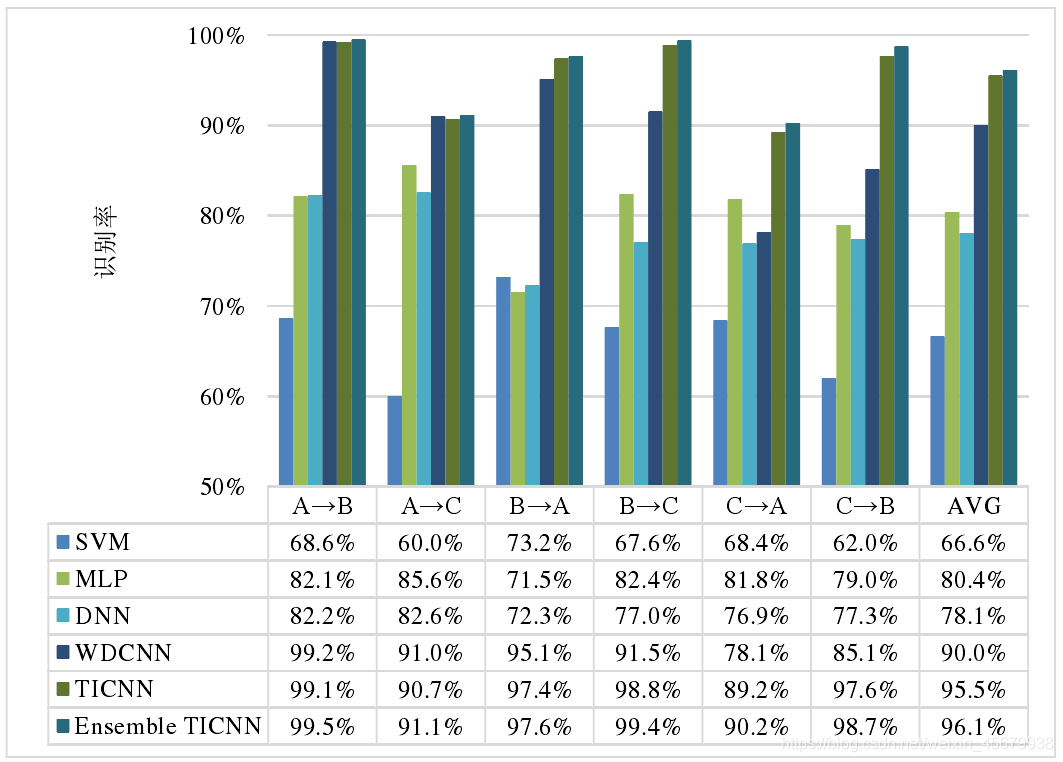
如下圖,為TICNN 演算法及對照演算法在 6 種不同域自適應場景中的識別率 :
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/294067.html
標籤:其他
上一篇:OpenCV實作桌面版陰陽師自動御魂和覺醒雙開、突破、業原火、御靈等功能
下一篇:KNN最近鄰分類演算法