如題所示,該演算法簡稱KNN,采用的方法是最近鄰,目的是分類,
KNN演算法概述
在已有資料集中已將資料分為n類,那么如果此時再進來一個新的資料如何給他分類呢?
應該選取距離他最近的k個鄰居(k由你定),選擇范圍內樣本數量最多的類別作為新資料的類別,
如果多個類別的樣本數量同時最多時,根據距離權重來判斷,離的近的決定其類別,
OpenCv中的KNN
import cv2 as cv
import numpy as np
import matplotlib.pyplot as plt
# 包含(x,y)值的25個已知/訓練資料的特征集
trainData = np.random.randint(0,100,(25,2)).astype(np.float32)
# 用數字0和1分別標記紅色或藍色
responses = np.random.randint(0,2,(25,1)).astype(np.float32)
# 新來物
newcomer = np.random.randint(0,100,(1,2)).astype(np.float32)
# KNN
knn = cv.ml.KNearest_create()
knn.train(trainData, cv.ml.ROW_SAMPLE, responses)
ret, results, neighbours ,dist = knn.findNearest(newcomer, 5)
print( "result: {}\n".format(results) )
print( "neighbours: {}\n".format(neighbours) )
print( "distance: {}\n".format(dist) )
# 繪圖方面:
# 取紅色族并繪圖
red = trainData[responses.ravel()==0]
plt.scatter(red[:,0],red[:,1],80,'r','^')
# 取藍色族并繪圖
blue = trainData[responses.ravel()==1]
plt.scatter(blue[:,0],blue[:,1],80,'b','s')
# 新來物繪圖
plt.scatter(newcomer[:,0],newcomer[:,1],80,'g','o')
plt.show()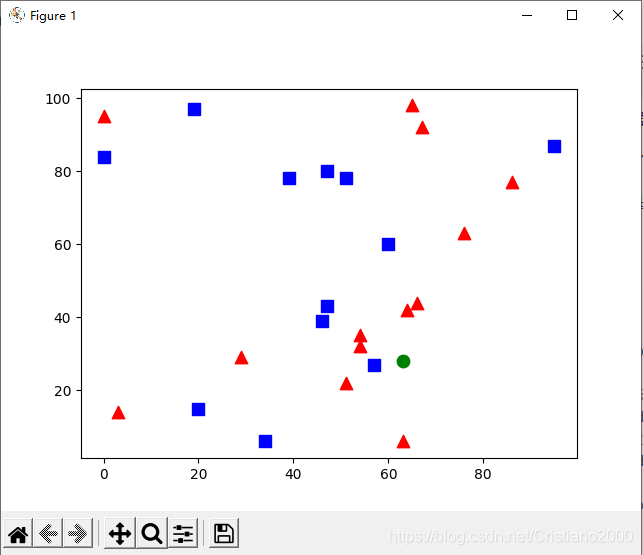

其他參考:
python散點圖繪制scatter
cv::ml::StatModel::train
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/294068.html
標籤:其他
上一篇:基于CNN網路的軸承故障診斷