塞翁失馬,焉知非福
添加
INSERT INTO <表名> (欄位1, 欄位2, ...) VALUES (值1, 值2, ...);
洗掉
DELETE FROM <表名> WHERE ...;
修改
UPDATE <表名> SET 欄位1=值1, 欄位2=值2, ... WHERE ...;
查詢
SELECT <列名> FROM <表名>; //基本查詢
SELECT <列名> FROM <表名> WHERE <條件運算式>; //條件查詢
SELECT <列名> FROM <表名> WHERE <條件運算式1> AND <條件運算式2>; //滿足條件1和條件2
SELECT <列名> FROM <表名> WHERE <條件運算式1> OR <條件運算式2>; //滿足條件1或條件2
SELECT <列名> FROM <表名> WHERE NOT <條件運算式>; //不滿足條件,用<>也可以做到
SELECT DISTINCT <列名> FROM <表名> WHERE <條件運算式>; //去除相同列名的資料
SELECT <列名> FROM <表名> WHERE (<條件運算式1> OR <條件運算式2>) AND <條件運算式3>;
如果大于三個約束條件,用小括號 (),如果不加括號,條件運算按照NOT、AND、OR的優先級進行,即NOT優先級最高,其次是AND,最后是OR,加上括號可以改變優先級,
SELECT <列名> <新名稱> FROM <表名>; //列重命名
排序
SELECT <列名> FROM <表名> ORDER BY <列名>; //按指定欄位排序,大部分資料庫默認按id排序
SELECT <列名> FROM <表名> ORDER BY <列名> ASC; //按指定欄位升序排序(默認)
SELECT <列名> FROM <表名> ORDER BY <列名> DESC; //按指定欄位倒序排序
如果有WHERE子句,那么ORDER BY子句要放到WHERE子句后面
SELECT <列名> FROM <表名> WHERE <條件運算式> ORDER BY <列名> DESC;
分頁
SELECT <列名> FROM <表名> LIMIT <記錄數x>; //每頁x條記錄
SELECT <列名> FROM <表名> LIMIT <記錄數x> OFFSET <索引y>; //每頁x條記錄,從第y條記錄開始
SELECT <列名> FROM <表名> LIMIT <記錄數x>, <索引y>; //MYSQL里可簡寫
使用LIMIT <M> OFFSET <N>分頁時,隨著N越來越大,查詢效率也會越來越低,
通配符
SELECT <列名> FROM <表名> WHERE <列名> LIKE 'xx%'; // %表示任何字符出現任意次數,查找以xx開頭的資料
SELECT <列名> FROM <表名> WHERE <列名> LIKE 'xx_'; // _表示任何字符出現一次,查找以xx開頭的三個字符的資料
正則運算式
SELECT <列名> FROM <表名> WHERE <列名> REGEXP 'xxx'; //檢索包含xxx的資料
拼接欄位
SELECT CONCAT(<列名1>, '(', <列名2>, ')') FROM <表名>; //將欄位1欄位2拼接成'欄位1(欄位2)'
聚合函式
SELECT COUNT(*) FROM <表名>; //查詢表內一共有多少條記錄
SELECT COUNT(*) <別名> FROM <表名>; //給列名設定別名便于處理結果
SUM() 計算某一列的合計值,該列必須為數值型別
SELECT SUM(<列名>) FROM <表名>;
AVG() 計算某一列的平均值,該列必須為數值型別
SELECT AVG(<列名>) FROM <表名>;
MAX() 計算某一列的最大值
MIN() 計算某一列的最小值
注意,MAX()和MIN()函式并不限于數值型別,如果是字符型別,MAX()和MIN()會回傳排序最后和排序最前的字符,
分組
SELECT COUNT(*) FROM <表名> GROUP BY <列名>; //按列分組查詢
SELECT <列名>, COUNT(*) FROM <表名> GROUP BY <列名>; //顯示列名,方便查看
過濾分組
SELECT COUNT(*) FROM <表名> GROUP BY <列名> HAVING <條件運算式>; //只回傳符合條件運算式的組
多表查詢
SELECT * FROM <表1> <表2>;
FROM子句給表設定別名的語法是FROM <表名1> <別名1>, <表名2> <別名2>
因為查詢的結果是笛卡爾積,所以盡量用WHERE限制條件查詢
連接查詢
內連接 INNER JOIN
SELECT <列名> FROM <表1> INNER JOIN <表2> ON <條件...>; //表1連接表2,
INNER JOIN只回傳同時存在于兩張表的行資料,由于表1包含1,2,3,表2包含1,2,3,4,所以,INNER JOIN根據條件s.id = c.id回傳的結果集僅包含1,2,3,
RIGHT OUTER JOIN回傳右表都存在的行,如果某一行僅在右表存在,那么結果集就會以NULL填充剩下的欄位,
LEFT OUTER JOIN則回傳左表都存在的行,如果某一行僅在左表存在,那么結果集就會以NULL填充剩下的欄位,
FULL OUTER JOIN回傳兩張表的所有記錄,并且,自動把對方不存在的列填充為NULL:
事務四大特性ACID
原子性(Atomicity)是指事務包含的所有操作要么全部成功,要么全部失敗回滾,因此事務的操作如果成功就必須要完全應用到資料庫,如果操作失敗則不能對資料庫有任何影響,
一致性(Consistency)一個事務執行之前和執行之后都必須處于一致性狀態,舉例來說,假設用戶A和用戶B兩者的錢加起來一共是1000,那么不管A和B之間如何轉賬、轉幾次賬,事務結束后兩個用戶的錢相加起來應該還得是1000,這就是事務的一致性,
隔離性(Isolation)是當多個用戶并發訪問資料庫時,比如同時操作同一張表時,資料庫為每一個用戶開啟的事務,不能被其他事務的操作所干擾,多個并發事務之間要相互隔離,
持久性(Durability)是指一個事務一旦被提交了,那么對資料庫中的資料的改變就是永久性的,即便是在資料庫系統遇到故障的情況下也不會丟失提交事務的操作,
事務的隔離級別
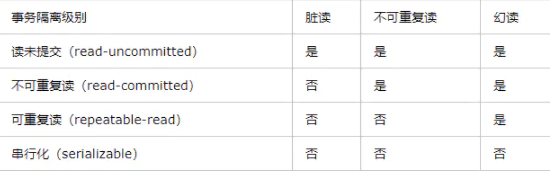
讀未提交(read-uncommitted)
一個事務會讀到另一個事務更新后但未提交的資料,如果另一個事務回滾,那么當前事務讀到的資料就是臟資料,這就是臟讀(Dirty Read),
不可重復讀(read-committed)
在一個事務內,多次讀同一資料,在這個事務還沒有結束時,如果另一個事務恰好修改了這個資料,那么,在第一個事務中,兩次讀取的資料就可能不一致,
可重復讀(repeatable-read)
在一個事務中,第一次查詢某條記錄,發現沒有,但是,當試圖更新這條不存在的記錄時,竟然能成功,并且,再次讀取同一條記錄,它就神奇地出現了,
不可重復讀的和幻讀很容易混淆,不可重復讀側重于修改,幻讀側重于新增或洗掉,解決不可重復讀的問題只需鎖住滿足條件的行,解決幻讀需要鎖表
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/294192.html
標籤:其他