前面已經整理了很多的面試文章,小伙伴反饋極好:
1,??爆肝!整理了一周的Spring面試大全【含答案】,吊打Java面試官【建議收藏】!??
2,??肝完了,一天掌握資料結構和演算法面試題,吊打面試官,建議收藏??
因此猛哥跟來勁了,干了三瓶紅牛,放棄了七夕和女友逛街,又肝了一篇集合的面試干貨,不叨叨直接上干貨,
目錄
Q1:說?說 ArrayList
Q2:說?說 LinkedList
Q3:ArrayList和LinkList的區別
Q4:Set 有什么特點,有哪些實作?
Q5:TreeMap 有什么特點?
Q6:HashMap 有什么特點?
Q7:HashMap為什么執行緒不安全?
Q8:說下你對HaspMap的認識!【重點,重點】
Q9:HashMap和HashTable的區別

Q1:說?說 ArrayList
ArrayList 是容量可變的?執行緒安全串列,使?陣列實作,集合擴容時會創建更?的陣列,把原有陣列復制到新陣列,?持對元素的快速隨機訪問,但插?與洗掉速度很慢,ArrayList 實作了 RandomAcess 標記接?,如果?個類實作了該接?,那么表示使?索引遍歷?迭代器更快,
elementData是 ArrayList 的資料域,被 transient 修飾,序列化時會調? writeObject 寫?流,反序列化時調? readObject 重新賦值到新物件的 elementData,原因是 elementData 容量通常?于實際存盤元素的數量,所以只需發送真正有實際值的陣列元素,size 是當前實際大小,elementData ???于等于 size,
modCount 記錄了 ArrayList 結構性變化的次數,繼承? AbstractList,所有涉及結構變化的?法都會增加該值,expectedModCount 是迭代器初始化時記錄的 modCount 值,每次訪問新元素時都會檢查modCount 和 expectedModCount 是否相等,不相等就會拋出例外,這種機制叫做 fail-fast,所有集合類都有這種機制,
Q2:說?說 LinkedList
LinkedList 本質是雙向鏈表,與 ArrayList 相?插?和洗掉速度更快,但隨機訪問元素很慢,除繼承AbstractList 外還實作了 Deque 接?,這個接?具有佇列和堆疊的性質,成員變數被 transient 修飾,原理和 ArrayList 類似,
LinkedList 包含三個重要的成員:size、?rst 和 last,size 是雙向鏈表中節點的個數,?rst 和 last 分別指向?尾節點的參考,
LinkedList 的優點在于可以將零散的記憶體單元通過附加引?的方式關聯起來,形成按鏈路順序查找的線性結構,記憶體利?率較?,
Q3:ArrayList和LinkList的區別
看一段簡單的ArrayList和LinkList的代碼,具體的大家可以自己去看下;
ArrayList:
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
/**
* Constructs an empty list with an initial capacity of ten.
*/
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
/**
* Constructs a list containing the elements of the specified
* collection, in the order they are returned by the collection's
* iterator.
*
* @param c the collection whose elements are to be placed into this list
* @throws NullPointerException if the specified collection is null
*/
public ArrayList(Collection<? extends E> c) {
elementData = c.toArray();
if ((size = elementData.length) != 0) {
// c.toArray might (incorrectly) not return Object[] (see 6260652)
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
// replace with empty array.
this.elementData = EMPTY_ELEMENTDATA;
}
}
/**
* Trims the capacity of this <tt>ArrayList</tt> instance to be the
* list's current size. An application can use this operation to minimize
* the storage of an <tt>ArrayList</tt> instance.
*/
public void trimToSize() {
modCount++;
if (size < elementData.length) {
elementData = (size == 0)
? EMPTY_ELEMENTDATA
: Arrays.copyOf(elementData, size);
}
}
類繼承圖關系:
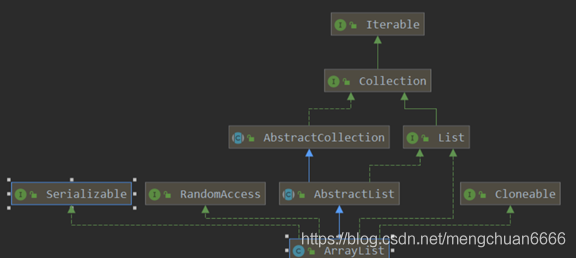
LinkList:
public class LinkedList<E> extends AbstractSequentialList<E> implements
List<E>, Deque<E>, Cloneable, java.io.Serializable {}
類繼承圖關系:
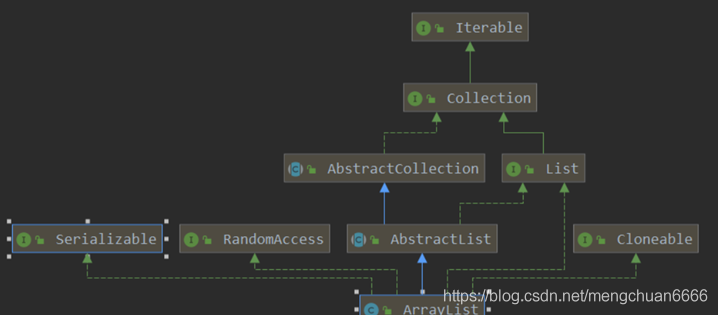
資料結構實作:ArrayList 是動態陣列的資料結構實作,而 LinkedList 是雙向鏈表的資料結構實作,
隨機訪問效率:ArrayList 比 LinkedList 在隨機訪問的時候效率要高,因為 LinkedList 是線性的資料存盤方式,所以需要移動指標從前往后依次查找,
增加和洗掉效率:在非首尾的增加和洗掉操作,LinkedList 要比 ArrayList 效率要高,因為 ArrayList 增刪操作要影響陣列內的其他資料的下標,
綜合來說,在需要頻繁讀取集合中的元素時,更推薦使用 ArrayList,而在插入和洗掉操作較多時,更推薦使用 LinkedList,
1. 是否保證執行緒安全: ArrayList 和 LinkedList 都是不同步的,也就是不保證執行緒安全;
2. 底層資料結構: Arraylist 底層使用的是 Object 陣列;LinkedList 底層使用的是 雙向鏈表 資料結構(JDK1.6之前為回圈鏈表,JDK1.7取消了回圈,注意雙向鏈表和雙向回圈鏈表的區別,下面有介紹到!)
3. 插入和洗掉是否受元素位置的影響: ① ArrayList 采用陣列存盤,所以插入和洗掉元素的時間復雜度受元素位置的影響, 比如:執行add(E e) 方法的時候, ArrayList 會默認在將指定的元素追加到此串列的末尾,這種情況時間復雜度就是O(1),但是如果要在指定位置 i 插入和洗掉元素的話(add(int index, E element) )時間復雜度就為 O(n-i),因為在進行上述操作的時候集合中第 i 和第 i 個元素之后的(n-i)個元素都要執行向后位/向前移一位的操作, ② LinkedList 采用鏈表存盤,所以對于add( E e)方法的插入,洗掉元素時間復雜度不受元素位置的影響,近似 O(1),如果是要在指定位置i插入和洗掉元素的話((add(int index, E element)) 時間復雜度應為o(n))因為需要新創立一個新的鏈表,復制前i-1個元素并在第i位加入新的元素,最后附上n-i個元素,
4. 是否支持快速隨機訪問: LinkedList 不支持高效的隨機元素訪問,而 ArrayList 支持,快速隨機訪問就是通過元素的序號快速獲取元素物件(對應于get(int index) 方法),
5. 記憶體空間占用: ArrayList的空 間浪費主要體現在在list串列的結尾會預留一定的容量空間,而LinkedList的空間花費則體現在它的每一個元素都需要消耗比ArrayList更多的空間(因為要存放直接后繼和直接前驅以及資料),
Q4:Set 有什么特點,有哪些實作?
Set 不允許元素重復且?序,常?實作有 HashSet、LinkedHashSet 和 TreeSet,
HashSet 通過 HashMap 實作,HashMap 的 Key 即 HashSet 存盤的元素,所有 Key 都使?相同的Value ,?個名為 PRESENT 的 Object 型別常量,使? Key 保證元素唯?性,但不保證有序性,由于HashSet 是 HashMap 實作的,因此執行緒不安全,
HashSet 判斷元素是否相同時,對于包裝型別直接按值?較,對于引?型別先?較 hashCode 是否相同,不同則代表不是同?個物件,相同則繼續?較 equals,都相同才是同?個物件,
LinkedHashSet 繼承? HashSet,通過 LinkedHashMap 實作,使?雙向鏈表維護元素插?順序,
TreeSet 通過 TreeMap 實作的,添加元素到集合時按照?較規則將其插?合適的位置,保證插?后的集合仍然有序,

Q5:TreeMap 有什么特點?
TreeMap 基于紅?樹實作,增刪改查的平均和最差時間復雜度均為 O(logn) ,最?特點是 Key 有序,
Key 必須實作 Comparable 接?或提供的 Comparator ?較器,所以 Key 不允許為 null,
HashMap 依靠hashCode和equals去重,? TreeMap 依靠 Comparable 或 Comparator,
TreeMap 排序時,如果?較器不為空就會優先使??較器的compare?法,否則使? Key 實作的,
Comparable 的Compareto?法,兩者都不滿?會拋出例外,TreeMap 通過put和deleteEntry實作增加和洗掉樹節點,插?新節點的規則有三個:① 需要調整的新節點總是紅?的,② 如果插?新節點的?節點是??的,不需要調整,③ 如果插?新節點的?節點是紅?的,由于紅?樹不能出現相鄰紅?,進?回圈判斷,通過重新著?或左右旋轉來調整,TreeMap 的插?操作就是按照 Key 的對?往下遍歷,?于節點值向右查找,?于向左查找,先按照?叉查找樹的特性操作,后續會重新著?和旋轉,保持紅?樹的特性,
Q6:HashMap 有什么特點?
JDK8 之前底層實作是陣列 + 鏈表,JDK8 改為陣列 + 鏈表/紅?樹,節點型別從Entry 變更為 Node,主要成員變數包括存盤資料的 table 陣列、元素數量 size、加載因? loadFactor,
table 陣列記錄 HashMap 的資料,每個下標對應?條鏈表,所有哈希沖突的資料都會被存放到同?條鏈表,Node/Entry 節點包含四個成員變數:key、value、next 指標和 hash 值,
HashMap 中資料以鍵值對的形式存在,鍵對應的 hash 值?來計算陣列下標,如果兩個元素 key 的hash 值?樣,就會發?哈希沖突,被放到同?個鏈表上,為使查詢效率盡可能?,鍵的 hash 值要盡可能分散,
HashMap 默認初始化容量為 16,擴容容量必須是 2 的冪次?、最?容量為 1<< 30 、默認加載因?為
0.75,
Q7:HashMap為什么執行緒不安全?
大家都應該知道HashMap不是執行緒安全的,具體存在問題的場景有:
1. 資料丟失
2. 資料重復
3. 死回圈
關于死回圈的問題,在Java8中個人認為是不存在了,在Java8之前的版本中之所以出現死回圈是因為在resize的程序中對鏈表進行了倒序處理;在Java8中不再倒序處理,自然也不會出現死回圈,
曾經有大神這樣解釋的:
通過上面Java7中的原始碼分析一下為什么會出現資料丟失,如果有兩條執行緒同時執行到這條陳述句 table[i]=null,時兩個執行緒都會區創建Entry,這樣存入會出現資料丟失, 如果有兩個執行緒同時發現自己都key不存在,而這兩個執行緒的key實際是相同的,在向鏈表中寫入的時候第一執行緒將e設定為了自己的Entry,而第二個執行緒執行到了e.next,此時拿到的是最后一個節點,依然會將自己持有是資料插入到鏈表中,這樣就出現了資料 重復, 通過商品put原始碼可以發現,是先將資料寫入到map中,再根據元素到個數再決定是否做resize.在resize程序中還會出現一個更為詭異都問題死回圈, 這個原因主要是因為hashMap在resize程序中對鏈表進行了一次倒序處理,假設兩個執行緒同時進行resize, A->B 第一執行緒在處理程序中比較慢,第二個執行緒已經完成了倒序編程了B-A 那么就出現了回圈,B->A->B.這樣就出現了就會出現CPU使用率飆升, 在下午突然收到其中一臺機器CPU利用率不足告警,將jstack內容分析發現,可能出現了死回圈和資料丟失情況,當然對于鏈表的操作同樣存在問題, PS:在這個程序中可以發現,之所以出現死回圈,主要還是在于對于鏈表對倒序處理,在Java 8中,已經不在使用倒序串列,死回圈問題得到了極大改善,
HashMap的執行緒不安全主要體現在下面兩個方面:
1.在JDK1.7中,當并發執行擴容操作時會造成環形鏈和資料丟失的情況,
2.在JDK1.8中,在并發執行put操作時會發生資料覆寫的情況,
Q8:說下你對HaspMap的認識!【重點,重點】
首先大家都知道HashMap是一個集合,是<key、value>的集合,每個節點都有一個key和value,具體的參考代碼:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Hashmap的陣列結構為陣列+(鏈表或者紅黑樹)
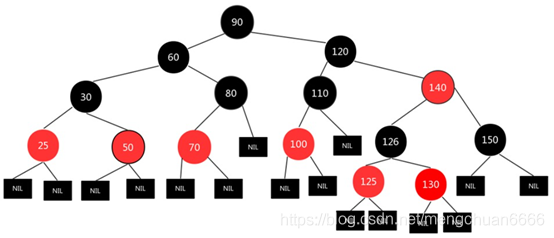
為什么要采用這種結構來存盤元素呢?首先得分析下陣列和鏈表的特點:
陣列:查詢效率高,插入,洗掉效率低,
鏈表:查詢效率低,插入洗掉效率高,
在HashMap底層使用陣列加(鏈表或紅黑樹)的結構完美的解決了陣列和鏈表的問題,使得查詢和插入,洗掉的效率都很高,
HashMap的繼承圖:
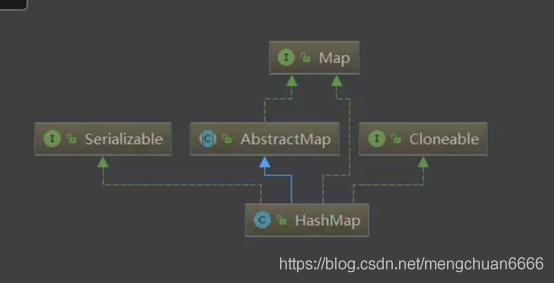
JDK8 之前,hash:計算元素 key 的散列值
① 處理 String 型別時,呼叫 stringHash32 方法獲取 hash 值,
② 處理其他型別資料時,提供一個相對于 HashMap 實體唯一不變的隨機值 hashSeed 作為計算初始量,
③ 執行異或和無符號右移使 hash 值更加離散,減小哈希沖突概率,
indexFor:計算元素下標
將 hash 值和陣列長度-1 進行與操作,保證結果不會超過 table 陣列范圍,
大家可以參考下代碼看下解釋,然后就很明白了,我們可以簡單總結出HashMap:
無序,允許為null,非同步;
底層由散串列(哈希表)實作;
初始容量和裝載因子對HashMap影響挺大的,設定小了不好,設定大了也不好,
resize:擴容陣列
① 如果當前容量達到了最大容量,將閾值設定為 Integer 最大值,之后擴容不再觸發,
② 否則計算新的容量,將閾值設為 newCapacity x loadFactor 和 最大容量 + 1 的較小值,
③ 創建一個容量為 newCapacity 的 Entry 陣列,呼叫 transfer 方法將舊陣列的元素轉移到新陣列,
transfer:轉移元素
① 遍歷舊陣列的所有元素,呼叫 rehash 方法判斷是否需要哈希重構,如果需要就重新計算元素 key 的 hash 值,
② 呼叫 indexFor 方法計算元素存放的下標 i,利用頭插法將舊陣列的元素轉移到新陣列,
JDK8
hash:計算元素 key 的散列值
如果 key 為 null 回傳 0,否則就將 key 的 hashCode 方法回傳值高低16位異或,讓盡可能多的位參與運算,讓結果的 0 和 1 分布更加均勻,降低哈希沖突概率,
put:添加元素
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
我們來決議下實作的方法
① 呼叫 putVal 方法添加元素,
② 如果 table 為慷訓長度為 0 就進行擴容,否則計算元素下標位置,不存在就呼叫 newNode 創建一個節點,
③ 如果存在且是鏈表,如果首節點和待插入元素的 hash 和 key 都一樣,更新節點的 value,
④ 如果首節點是 TreeNode 型別,呼叫 putTreeVal 方法增加一個樹節點,每一次都比較插入節點和當前節點的大小,待插入節點小就往左子樹查找,否則往右子樹查找,找到空位后執行兩個方法:balanceInsert 方法,插入節點并調整平衡、moveRootToFront 方法,由于調整平衡后根節點可能變化,需要重置根節點,
⑤ 如果都不滿足,遍歷鏈表,根據 hash 和 key 判斷是否重復,決定更新 value 還是新增節點,如果遍歷到了鏈表末尾則添加節點,如果達到建樹閾值 7,還需要呼叫 treeifyBin 把鏈表重構為紅黑樹,
⑥ 存放元素后將 modCount 加 1,如果 ++size > threshold ,呼叫 resize 擴容,
get :獲取元素的 value 值
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
/**
* Implements Map.get and related methods.
*
* @param hash hash for key
* @param key the key
* @return the node, or null if none
*/
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
我們來解釋下上面的代碼:
① 呼叫 getNode 方法獲取 Node 節點,如果不是 null 就回傳其 value 值,否則回傳 null,
② getNode 方法中如果陣列不為空且存在元素,先比較第一個節點和要查找元素的 hash 和 key ,如果都相同則直接回傳,
③ 如果第二個節點是 TreeNode 型別則呼叫 getTreeNode 方法進行查找,否則遍歷鏈表根據 hash 和 key 查找,如果沒有找到就回傳 null,
resize:擴容陣列
重新規劃長度和閾值,如果長度發生了變化,部分資料節點也要重新排列,
重新規劃長度
① 如果當前容量 oldCap > 0 且達到最大容量,將閾值設為 Integer 最大值,return 終止擴容,
② 如果未達到最大容量,當 oldCap << 1 不超過最大容量就擴大為 2 倍,
③ 如果都不滿足且當前擴容閾值 oldThr > 0,使用當前擴容閾值作為新容量,
④ 否則將新容量置為默認初始容量 16,新擴容閾值置為 12,
重新排列資料節點
① 如果節點為 null 不進行處理,
② 如果節點不為 null 且沒有next節點,那么通過節點的 hash 值和 新容量-1 進行與運算計算下標存入新的 table 陣列,
③ 如果節點為 TreeNode 型別,呼叫 split 方法處理,如果節點數 hc 達到6 會呼叫 untreeify 方法轉回鏈表,
④ 如果是鏈表節點,需要將鏈表拆分為 hash 值超出舊容量的鏈表和未超出容量的鏈表,對于hash & oldCap == 0 的部分不需要做處理,否則需要放到新的下標位置上,新下標 = 舊下標 + 舊容量,
Q9:HashMap和HashTable的區別
從上面整理的可以看出HashMap和HashTable的區別,小孟給大家整理了個表格,加大體看下:
| springmeng整理 | |||||||
| shmap | 執行緒不安全 | 允許有null的鍵和值 | 效率高一點、 | 方法不是Synchronize的要提供外同步 | 有containsvalue和containsKey方法 | HashMap 是Java1.2 引進的Map interface 的一個實作 | HashMap是Hashtable的輕量級實作 |
| hashtable | 執行緒安全 | 不允許有null的鍵和值 | 效率稍低、 | 方法是是Synchronize的 | 有contains方法 | Hashtable 繼承于Dictionary 類 | Hashtable 比HashMap 要舊 |
參考:https://www.zhihu.com/question/28516433
好了,spring面試整理結束,小伙伴們點贊、收藏、評論,一鍵三連走起呀,下期見~~

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/294214.html
標籤:其他
上一篇:??《畫解資料結構》全網最全堆疊總結,九個影片組圖輪播,不懂都難??(建議收藏)
下一篇:c# 串口關閉死機