Spark 內核泛指
Spark
的核心運行機制,包括
Spark
核心組件的運行機制、
Spark
任務調度機制、Spark
記憶體管理機制、
Spark
核心功能的運行原理等
一、部署模式
Spark 支持多種集群管理器(Cluster Manager),分別為:
1) Standalone
:獨立模式,
Spark
原生的簡單集群管理器,自帶完整的服務,可單獨部署到
一個集群中,無需依賴任何其他資源管理系統,使用
Standalone
可以很方便地搭建一個
集群;
2) Hadoop YARN
:統一的資源管理機制,在上面可以運行多套計算框架,如
MR
、
Storm
等,根據
Driver
在集群中的位置不同,分為
yarn client
(集群外)和
yarn cluster
(集群
內部)
3) Apache Mesos
:一個強大的分布式資源管理框架,它允許多種不同的框架部署在其上,
包括
Yarn
,
4) K8S :
容器式部署環境,
1、YARN 模式運行機制
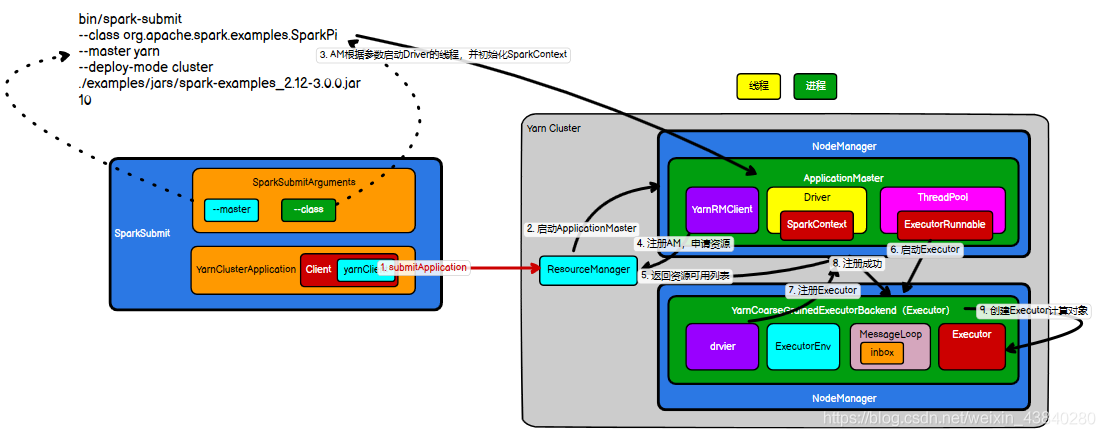
(1)YARN Cluster 模式
1)
執行腳本提交任務,實際是啟動一個
SparkSubmit
的
JVM
行程;
2) SparkSubmit
類中的
main
方法反射呼叫
YarnClusterApplication
的
main
方法;
3) YarnClusterApplication
創建
Yarn
客戶端,然后向
Yarn
服務器發送執行指令:
bin/java
ApplicationMaster
;
4) Yarn
框架收到指令后會在指定的
NM
中啟動
ApplicationMaster
;
5) ApplicationMaster
啟動
Driver
執行緒
,執行用戶的作業;
6) AM
向
RM
注冊,申請資源;
7)
獲取資源后
AM
向
NM
發送指令:
bin/java
Yarn
CoarseGrainedExecutorBackend
;
8) CoarseGrainedExecutorBackend
行程會接收訊息,跟
Driver
通信,注冊已經啟動的
Executor
;然后啟動計算物件
Executor
等待接收任務
9) Driver
執行緒繼續執行完成作業的調度和任務的執行,
10) Driver
分配任務并監控任務的執行,
注意:
SparkSubmit
、
ApplicationMaster
和
CoarseGrainedExecutorBackend
是獨立的行程;
Driver 是獨立的執行緒;Executor
和
YarnClusterApplication
是物件,
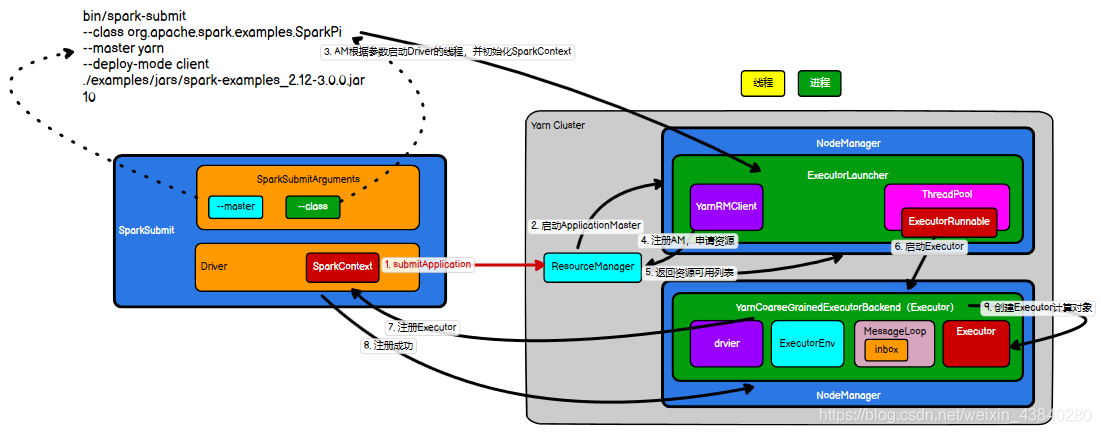
(2)YARN Client 模式
1)
執行腳本提交任務,實際是啟動一個
SparkSubmit
的
JVM
行程;
2) SparkSubmit
類中的
main
方法反射呼叫用戶代碼的
main
方法;
3)
啟動
Driver
執行緒,執行用戶的作業,并創建
ScheduleBackend
;
4) YarnClientSchedulerBackend
向
RM
發送指令:
bin/java ExecutorLauncher
;
5) Yarn
框架收到指令后會在指定的
NM
中啟動
ExecutorLauncher
(實際上還是呼叫 ApplicationMaster 的
main
方法);
6) AM
向
RM
注冊,申請資源;
7)
獲取資源后
AM
向
NM
發送指令:
bin/java CoarseGrainedExecutorBackend
;
8) CoarseGrainedExecutorBackend
行程會接收訊息,跟
Driver
通信,注冊已經啟動的
Executor
;然后啟動計算物件
Executor
等待接收任務
9) Driver
分配任務并監控任務的執行,
注意:
SparkSubmit
、
ApplicationMaster
和
YarnCoarseGrainedExecutorBackend
是獨立的進
程;
Executor
和
Driver
是物件,
二、通信架構
Netty:通信框架,AIO
- BIO:阻塞式IO
- NIO:非阻塞式IO
- AIO:異步非阻塞式IO
核心概念表示:
- RPCEnv:通信環境
- Backend:后臺
- Endpoint:終端
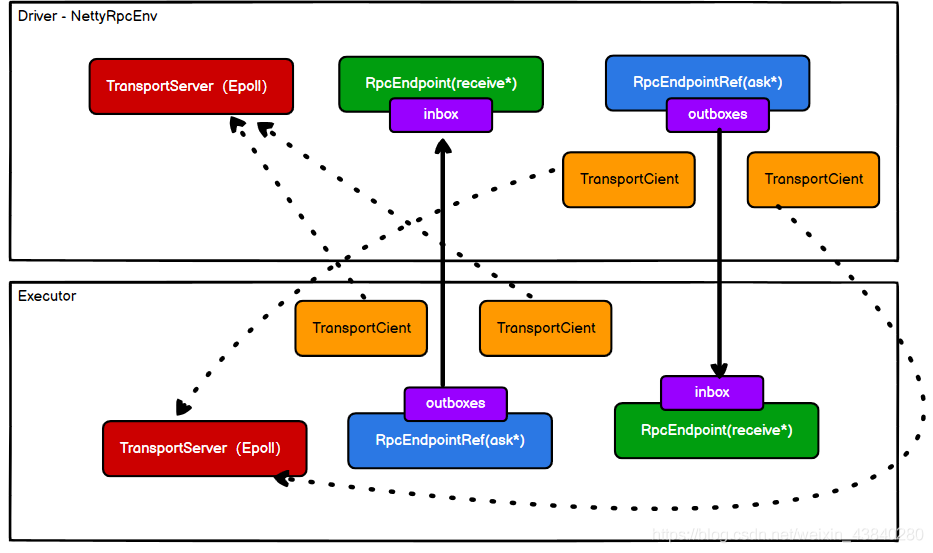
Linux對AIO支持不夠好,Windows支持好,Linux采用Epoll方式模仿AIO操作,簡單的通信框架如圖1所示:
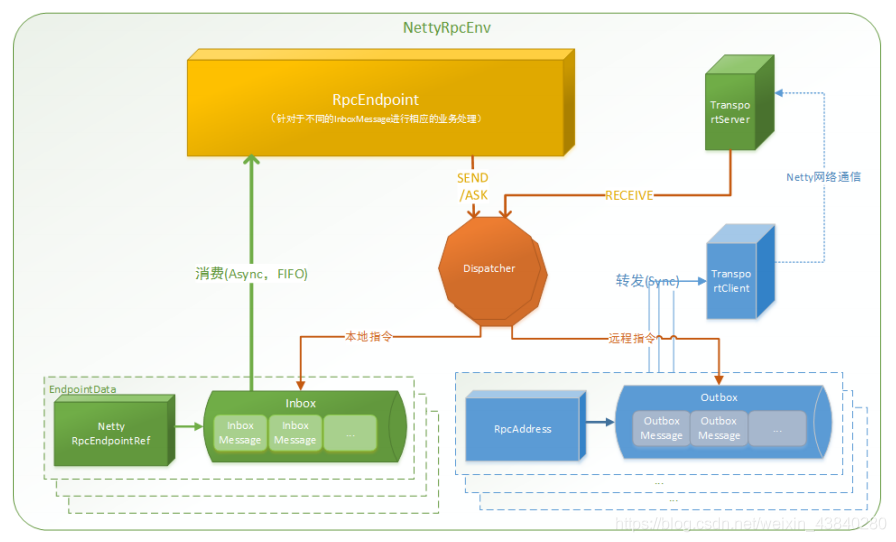
完整的通信框架如圖2所示:
三、任務調度機制
在生產環境下,Spark
集群的部署方式一般為
YARN-Cluster
模式,之后的內核分析內容
中我們默認集群的部署方式為
YARN-Cluster
模式,
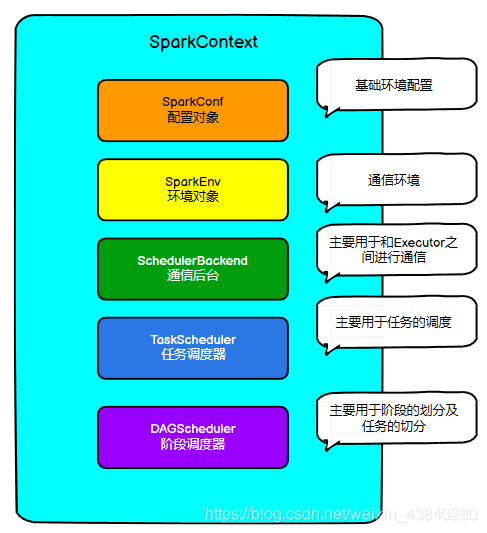
Driver具體的作業流程:
Driver
執行緒 主 要 是 初 始 化 SparkContext
對 象,準備運行所需的背景關系 , 然后一方面保 持與ApplicationMaster的
RPC
連接,通過
ApplicationMaster
申請資源,另一方面根據用戶業務邏輯開始調度任務,將任務下發到已有的空閑Executor
上,
當 ResourceManager
向
ApplicationMaster
回傳
Container
資源時,
ApplicationMaster
就嘗
試在對應的
Container
上啟動
Executor
行程,
Executor
行程起來后,會向
Driver
反向注冊,
注冊成功后保持與
Driver
的心跳,同時等待
Driver
分發任務,當分發的任務執行完畢后,
將任務狀態上報給
Driver
,
其核心物件如下:
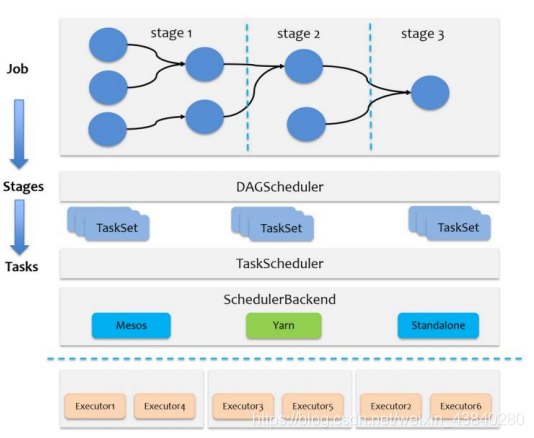
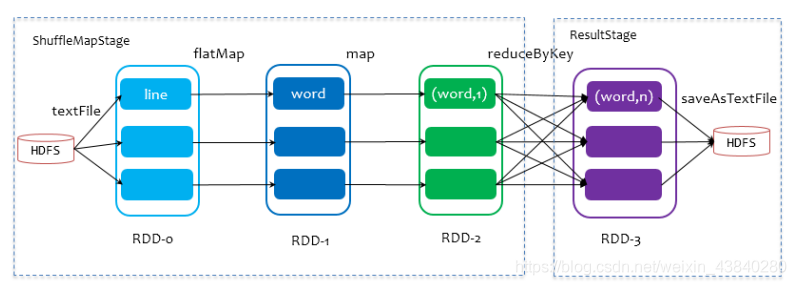
1、任務調度概述
當 Driver
起來后,
Driver
則會根據用戶程式邏輯準備任務,并根據
Executor
資源情況
逐步分發任務,在詳細闡述任務調度前,首先說明下
Spark
里的幾個概念,一個
Spark
應用
程式包括
Job
、
Stage
以及
Task
三個概念:
1) Job
是以
Action
方法為界,遇到一個
Action
方法則觸發一個
Job
;
2) Stage
是
Job
的子集,以
RDD
寬依賴
(
即
Shuffle)
為界,遇到
Shuffle
做一次劃分;
3) Task
是
Stage
的子集,以并行度
(
磁區數
)
來衡量,磁區數是多少,則有多少個
task
,
Spark 的任務調度總體來說分兩路進行,一路是
Stage
級的調度,一路是
Task
級的調度,總
體調度流程如下圖所示:
Spark RDD 通過其
Transactions
操作,形成了
RDD
血緣(依賴)關系圖,即
DAG
,最
后通過
Action
的呼叫,觸發
Job
并調度執行,執行程序中會創建兩個調度器:
DAGScheduler
和
TaskScheduler
,
- DAGScheduler 負責 Stage 級的調度,主要是將 job 切分成若干 Stages,并將每個 Stage打包成 TaskSet 交給 TaskScheduler 調度,
- TaskScheduler 負責 Task 級的調度,將 DAGScheduler 給過來的 TaskSet 按照指定的調度策略分發到 Executor 上執行,調度程序中 SchedulerBackend 負責提供可用資源,其中SchedulerBackend 有多種實作,分別對接不同的資源管理系統,
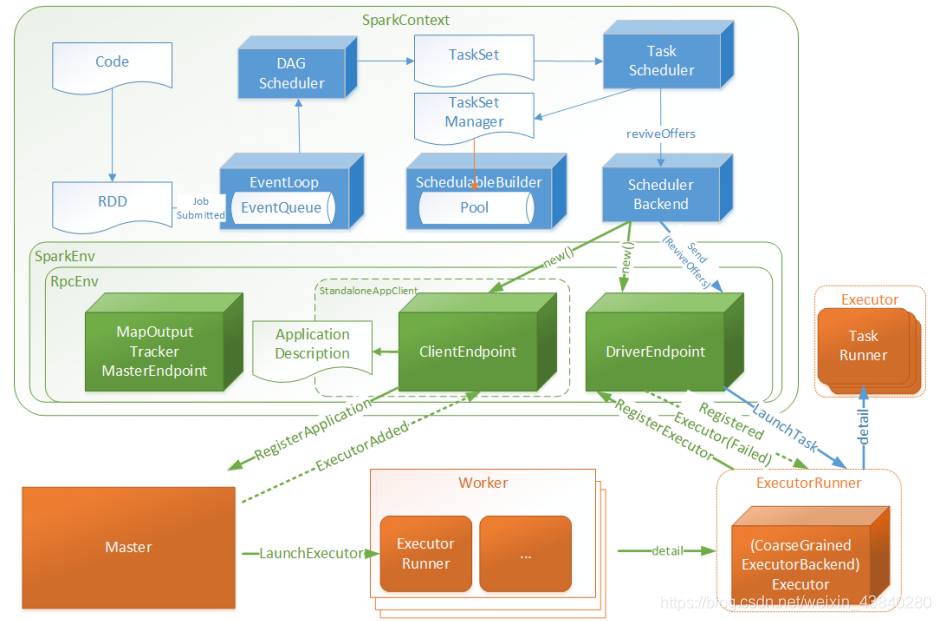
Driver 初始化 SparkContext 程序中,會分別初始化 DAGScheduler、TaskScheduler、 SchedulerBackend 以及 HeartbeatReceiver,并啟動 SchedulerBackend 以及 HeartbeatReceiver, SchedulerBackend 通過 ApplicationMaster 申請資源,并不斷從 TaskScheduler 中拿到合適的 Task 分發到 Executor 執行,HeartbeatReceiver 負責接收 Executor 的心跳資訊,監控Executor的存活狀況,并通知到 TaskScheduler,
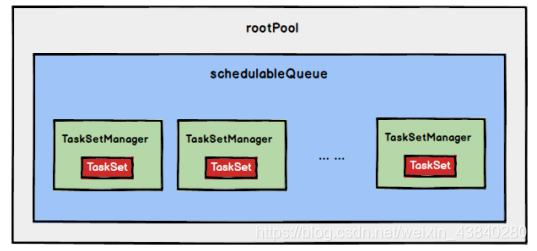
2、Stage 級調度
Spark Task 的調度是由
TaskScheduler
來完成,由前文可知,
DAGScheduler
將
Stage
打
包到交給
TaskScheTaskSetduler
,
TaskScheduler
會將
TaskSet
封裝為
TaskSetManager
加入到
調度佇列中,
TaskSetManager
結構如下圖所示,
3、Task 級調度
Spark Task 的調度是由 TaskScheduler
來完成,由前文可知,
DAGScheduler
將
Stage
打
包到交給
TaskScheTaskSetduler
,
TaskScheduler
會將
TaskSet
封裝為
TaskSetManager
加入到
調度佇列中,
TaskSetManager
結構如下圖所示,
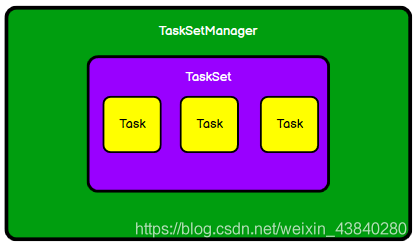
TaskSetManager 負 責監控 管理 同一 個
Stage
中的
Tasks
,
TaskScheduler
就是以
TaskSetManager
為單元來調度任務,
前面也提到,TaskScheduler
初始化后會啟動
SchedulerBackend
,它負責跟外界打交道,
接收
Executor
的注冊資訊,并維護
Executor
的狀態,所以說
SchedulerBackend
是管
“
糧食
”
的,同時它在啟動后會定期地去
“
詢問
”TaskScheduler
有沒有任務要運行,也就是說,它會定
期地
“
問
”TaskScheduler“
我有這么余糧,你要不要啊
”
,
TaskScheduler
在
SchedulerBackend“
問
”
它的時候,會從調度佇列中按照指定的調度策略選擇
TaskSetManager
去調度運行
(1)調度策略
TaskScheduler 支持兩種調度策略,
一種是
FIFO
,也是默認的調度策略,另一種是
FAIR
,
在
TaskScheduler
初始化程序中會實體化
rootPool
,表示樹的根節點,是
Pool
型別,
1) FIFO
調度策略
如果是采用 FIFO
調度策略,則直接簡單地將
TaskSetManager
按照先來先到的方式入
隊,出隊時直接拿出最先進隊的
TaskSetManager
,其樹結構如下圖所示,
TaskSetManager
保
存在一個
FIFO
佇列中,
2) FAIR 調度策略
FAIR 調度策略的樹結構如下圖所示:
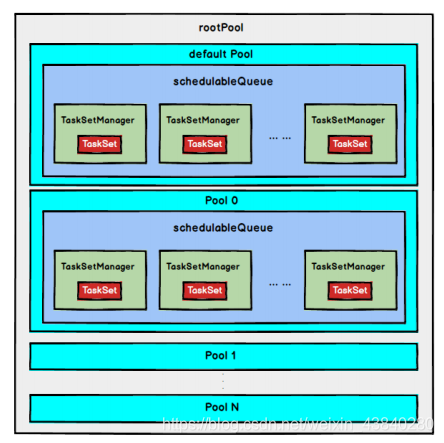
FAIR 模式中有一個
rootPool
和多個子
Pool
,各個子
Pool
中存盤著所有待分配的
TaskSetMagager,
在 FAIR
模式中,需要先對子
Pool
進行排序,再對子
Pool
里面的
TaskSetMagager
進行
排序,因為Pool
和
TaskSetMagager
都繼承了
Schedulable
特質,因此使用相同的排序演算法,
(2)本地化調度
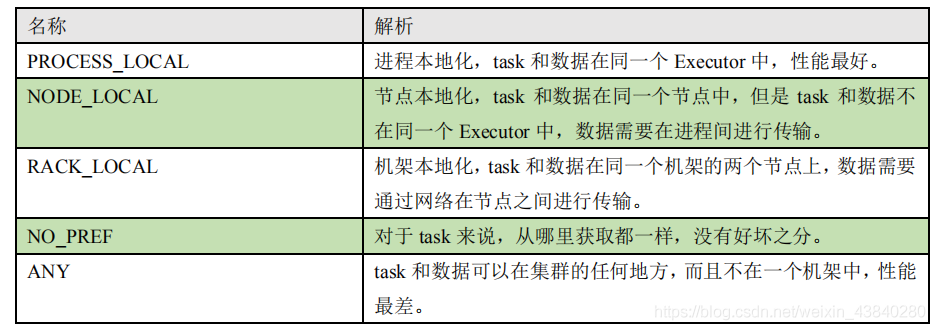
計算和資料的位置存在不同的級別,這個級別稱之為本地化級別,分為四種:
- 行程本地化:資料和計算在同一個行程中
- 節點本地化:資料和計算在同一個節點中
- 機架本地化:資料和計算在同一個機架中
- 任意
在調度執行時,Spark
調度總是會盡量讓每個
task
以最高的本地性級別來啟動,當一個
task
以
X
本地性級別啟動,但是該本地性級別對應的所有節點都沒有空閑資源而啟動失敗,
此時并不會馬上降低本地性級別啟動而是在某個時間長度內再次以
X
本地性級別來啟動該
task
,若超過限時時間則降級啟動,去嘗試下一個本地性級別,依次類推,
可以通過調大每個類別的最大容忍延遲時間,在等待階段對應的 Executor
可能就會有
相應的資源去執行此
task
,這就在在一定程度上提到了運行性能,
(3)失敗重試與黑名單機制
對于失敗的 Task
,會記錄它失敗的次數,如果失敗次數還沒有超過最大重試次數,那么就把它放回待調度的 Task
池子中,否則整個
Application
失敗,
在記錄 Task
失敗次數程序中,會記錄它上一次失敗所在的
Executor Id
和
Host
,這樣下次再調度這個Task
時,會使用黑名單機制,避免它被調度到上一次失敗的節點上,起到一定的容錯作用,黑名單記錄Task
上一次失敗所在的
Executor Id
和
Host
,以及其對應的“拉黑”時間,“拉黑”時間是指這段時間內不要再往這個節點上調度這個Task
了,
四、Shuffle決議
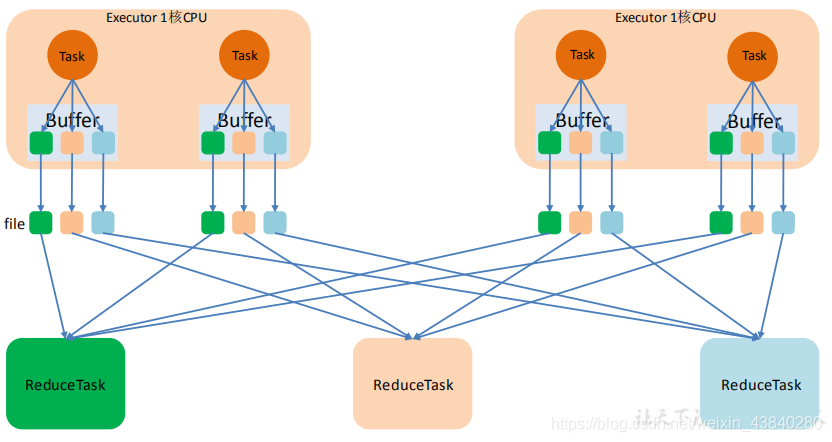
1、未優化的 HashShuffle
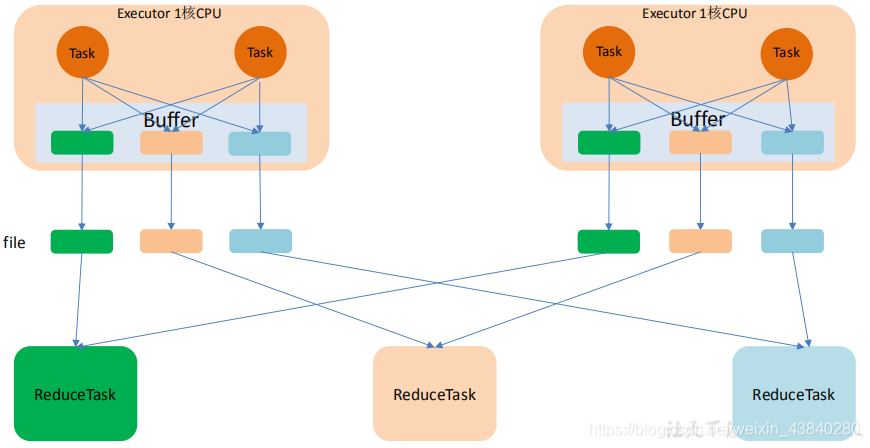
2、優化后的 HashShuffle
3、普通 SortShuffle
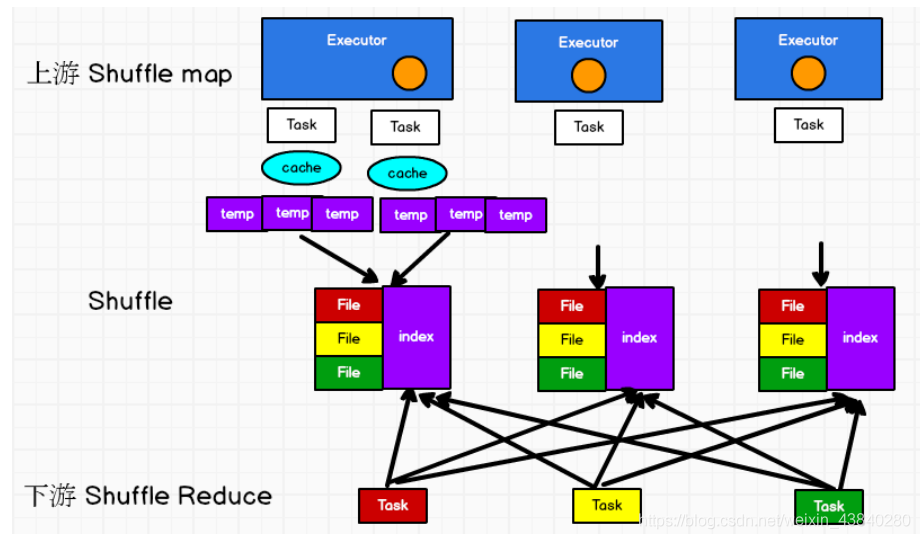
在該模式下,資料會先寫入一個資料結構,reduceByKey 寫入 Map,一邊通過 Map 局 部聚合,一遍寫入記憶體,Join 算子寫入 ArrayList 直接寫入記憶體中,然后需要判斷是否達到閾值,如果達到就會將記憶體資料結構的資料寫入到磁盤,清空記憶體資料結構,
在溢寫磁盤前,先根據 key
進行排序,排序過后的資料,會分批寫入到磁盤檔案中,默
認批次為
10000
條,資料會以每批一萬條寫入到磁盤檔案,寫入磁盤檔案通過緩沖區溢寫的
方式,每次溢寫都會產生一個磁盤檔案,
也就是說一個
Task
程序會產生多個臨時檔案,
最后在每個 Task
中,將所有的臨時檔案合并,這就是
merge
程序,此程序將所有臨時
檔案讀取出來,一次寫入到最終檔案,
意味著一個
Task
的所有資料都在這一個檔案中,同
時單獨寫一份索引檔案,標識下游各個
Task
的資料在檔案中的索引,
start offset
和
end offset
,
4、bypass SortShuffle
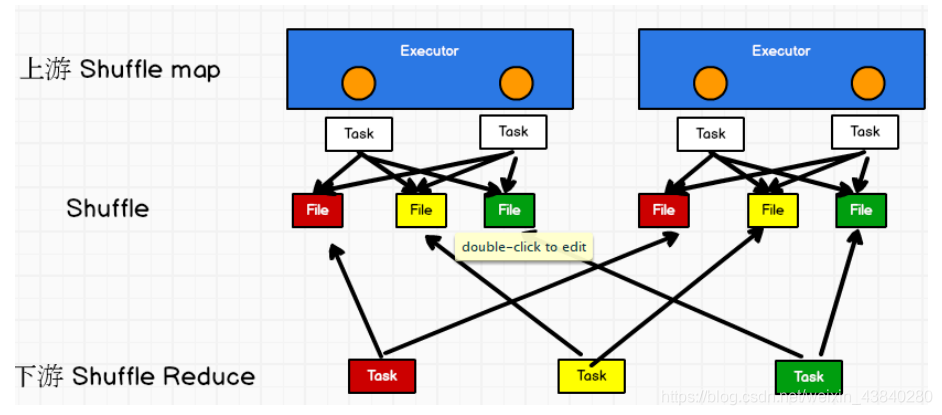
而該機制與普通 SortShuffleManager
運行機制的不同在于:不會進行排序,也就是說,
啟用該機制的最大好處在于,
shuffle write
程序中,不需要進行資料的排序操作,也就節省
掉了這部分的性能開銷,
五、記憶體管理
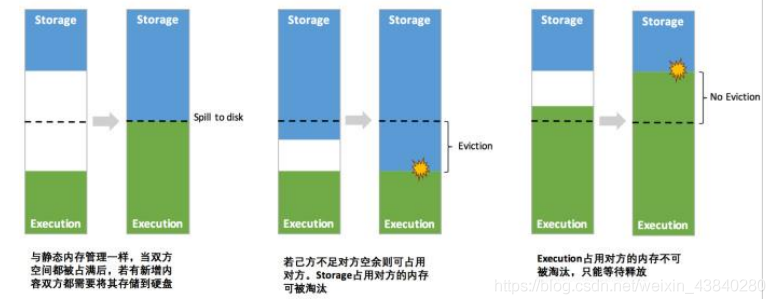
Spark3.x以后將采用統一記憶體管理:
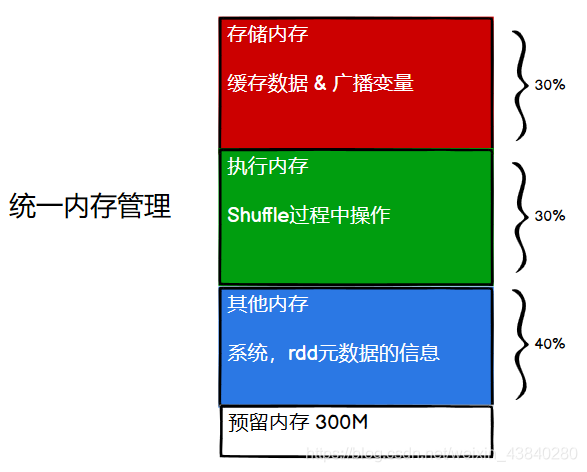
其中最重要的優化在于動態占用機制,其規則如下:
1)
設定基本的存盤記憶體和執行記憶體區域(
spark.storage.storageFraction
引數),該設定確定了雙方各自擁有的空間的范圍;
2)
雙方的空間都不足時,則存盤到硬碟;若己方空間不足而對方空余時,可借用對方的空間;
(存盤空間不足是指不足以放下一個完整的
Block
)
3)
執行記憶體的空間被對方占用后,可讓對方將占用的部分轉存到硬碟,然后
”
歸還
”
借用的空間;
4)
存盤記憶體的空間被對方占用后,無法讓對方
”
歸還
”
,因為需要考慮
Shuffle
程序中的很
多因素,實作起來較為復雜,
統一記憶體管理的動態占用機制如圖所示: