目錄
MapReduce介紹
分布式計算介紹
移動資料
移動計算
MapReduce原理剖析
官方的mapreduce原理圖
block和split之間有什么關系?
MapReduce之Map階段
MapReduce之Reduce階段
單檔案wordConut圖例
多檔案wordCount圖例
wordCount java代碼實作
wordCount程式在hadoop上的執行
MapReduce任務日志查看
MapReduce介紹
計算撲克牌中的黑桃個數
就是我們平時打牌時用的撲克牌,現在呢,有一摞牌,我想知道這摞牌中有多少張黑桃
最直接的方式是一張一張檢查并且統計出有多少張是黑桃,但是這種方式的效率比較低,如果說這一摞牌只有幾十張也就無所謂了,如果這一摞拍有上千張呢?你一張一張去檢查還不瘋了?
這個時候我們可以使用MapReduce的計算方法
第一步:把這摞牌分配給在座的所有玩家
第二步:讓每個玩家查一下自己手中的牌有多少張是黑桃,然后把這個數目匯報給你
第三步:你把所有玩家告訴你的數字加起來,得到最終的結果
之前是一張一張的串行計算,現在使用mapreduce是把資料分配給多個人,并行計算,每一個人獲得一個區域聚合的臨時結果,最終再統一匯總一下,
這樣就可以快速得到答案了,這其實就是MapReduce的計算思想,
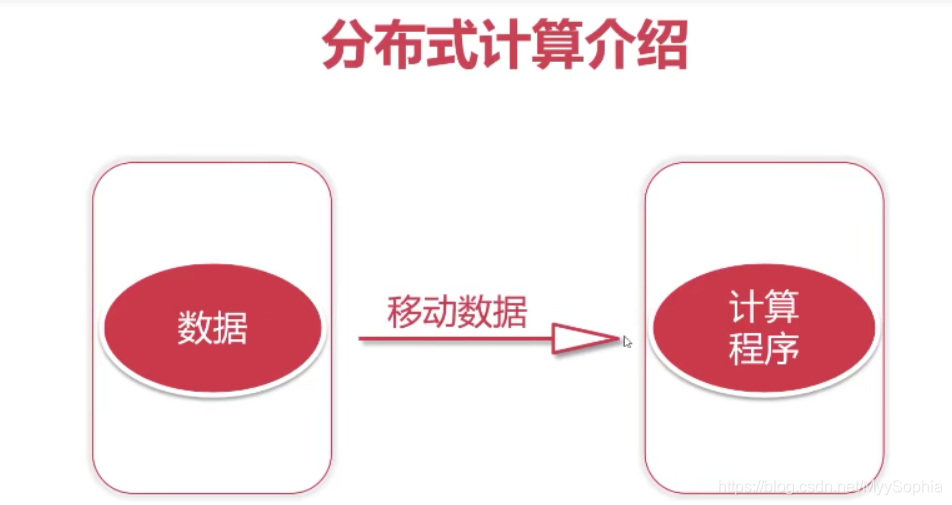
分布式計算介紹
移動資料
我們自己寫的JDBC代碼是在一臺機器上運行,mysql資料庫是在另一臺機器上運行,正常情況下,我們通過jdbc代碼去mysql中獲取一條資料,速度還是很快的,
但是有一個極端情況,如果我們要獲取的資料量很大,達到了幾個G,甚至于幾十G,這個時候我們使用jdbc代碼去拉取資料的時候,就會變得非常慢,
這個慢主要是由于兩個方面造成的, 一個是磁盤io(會進行磁盤讀寫操作), 一個是網路io(網路傳輸),
這兩個里面其實最耗時的還是網路io,我們平時在兩臺電腦之間傳輸一個幾十G的檔案也需要很長時間的,但是如果是使用U盤拷貝就很快了,所以可以看出來主要耗時的地方是在網路IO上面,
這種計算方式我們稱之為移動資料
新思潮: 移動計算比移動資料更劃算,因為大量資料的時間耗時主要是在網路I/O 和磁盤I/O.
案例:
如果copy一個50G的內容,就算是內網的兩臺機器也很慢,如果是用U盤,那就比較快,
為什么呢? 因為沒有網路IO,而磁盤IO一直是存在的,
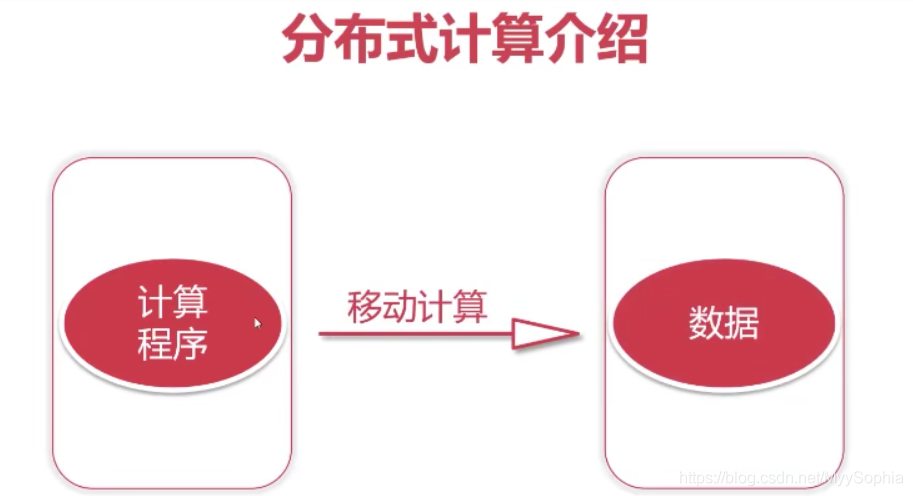
移動計算
如果我們考慮把計算程式移動到mysql上面去執行,是不是就可以節省網路io了,是的! 這種方式稱之為移動計算,就是把計算程式移動到資料所在的節點上面
如果我們資料量很大的話,我們的資料肯定是由很多個節點存盤的,這個時候我們就可以把我們的程式代碼拷貝到對應的節點上面去執行,程式代碼都是很小的,一般也就幾十KB或者幾百KB,加上外部依賴包,最大也就幾兆 ,甚至幾十兆,但是我們需要計算的資料動輒都是幾十G、幾百G,他們兩個之間的差距不是一星半點
這樣我們的代碼就可以在每個資料節點上面執行了,但是這個代碼只能計算當前節點上的資料的,如果我們想要統計資料的總行數,這里每個資料節點上的代碼只能計算當前節點上資料的行數,所以還的有一個匯總程式,這樣每個資料節點上面計算的臨時結果就可以通過匯總程式得到最終的結果了,
此時匯總程式需要傳遞的資料量就很小了,只需要接收一個數字即可,
這個計算程序就是分布式計算,這個步驟分為兩步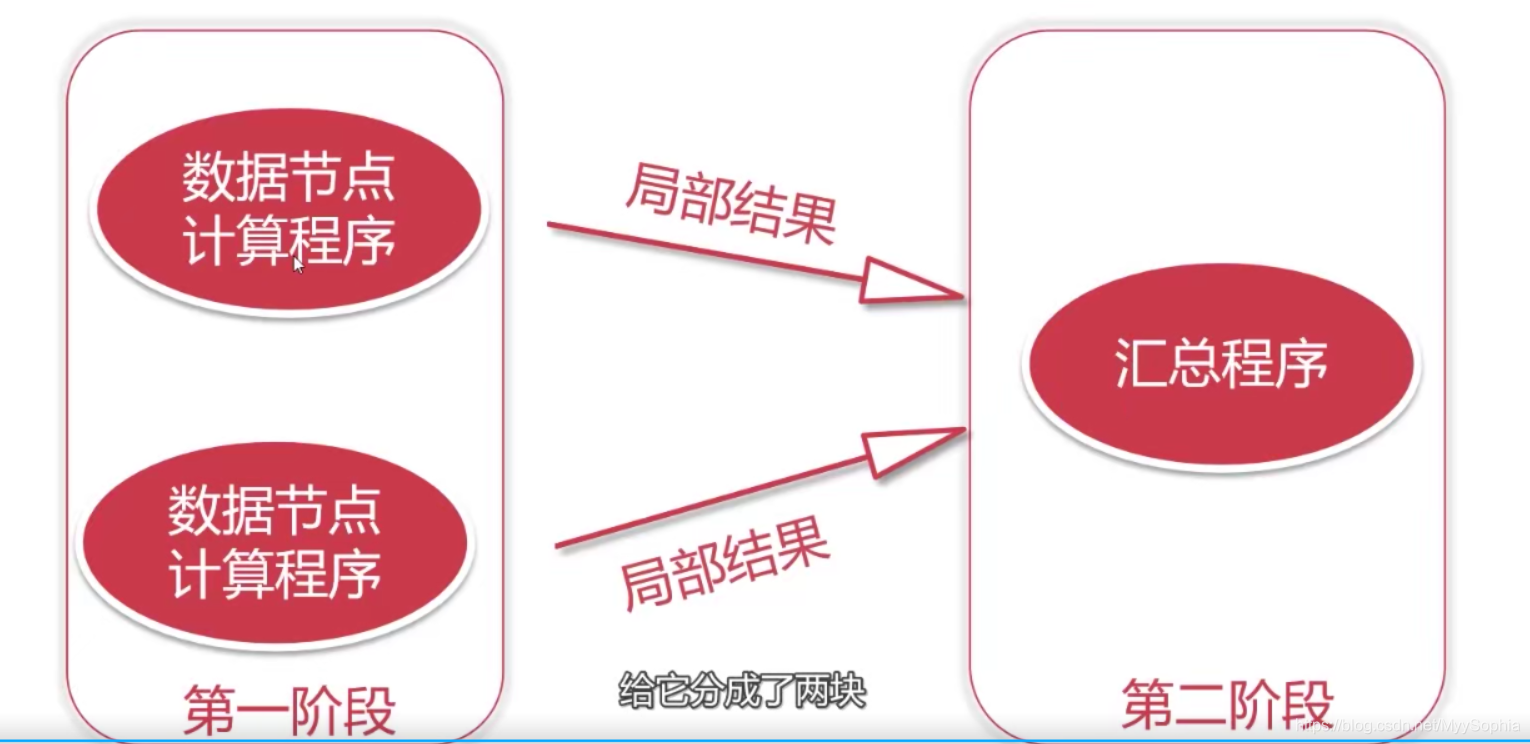
第一步:對每個節點上面的資料進行區域計算
第二步:對每個節點上面計算的區域結果進行最終全域匯總
MapReduce原理剖析
MapReduce是一種分布式計算模型,是Google提出來的,主要用于搜索領域,解決海量資料的計算問 題.
MapReduce是分布式運行的,由兩個階段組成:Map和Reduce,
Map階段是一個獨立的程式,在很多個節點同時運行,每個節點處理一部分資料,
Reduce階段也是一個獨立的程式,可以在一個或者多個節點同時運行,每個節點處理一部分資料
在這map就是對資料進行區域匯總,reduce就是對區域資料進行最侄訓總,
結合到我們前面分析的統計黑桃的例子中,這里的map階段就是指每個人統計自己手里的黑桃的個數,reduce就是對每個人統計的黑桃個數進行最侄訓總
在這我們再舉一個例子,看這個圖
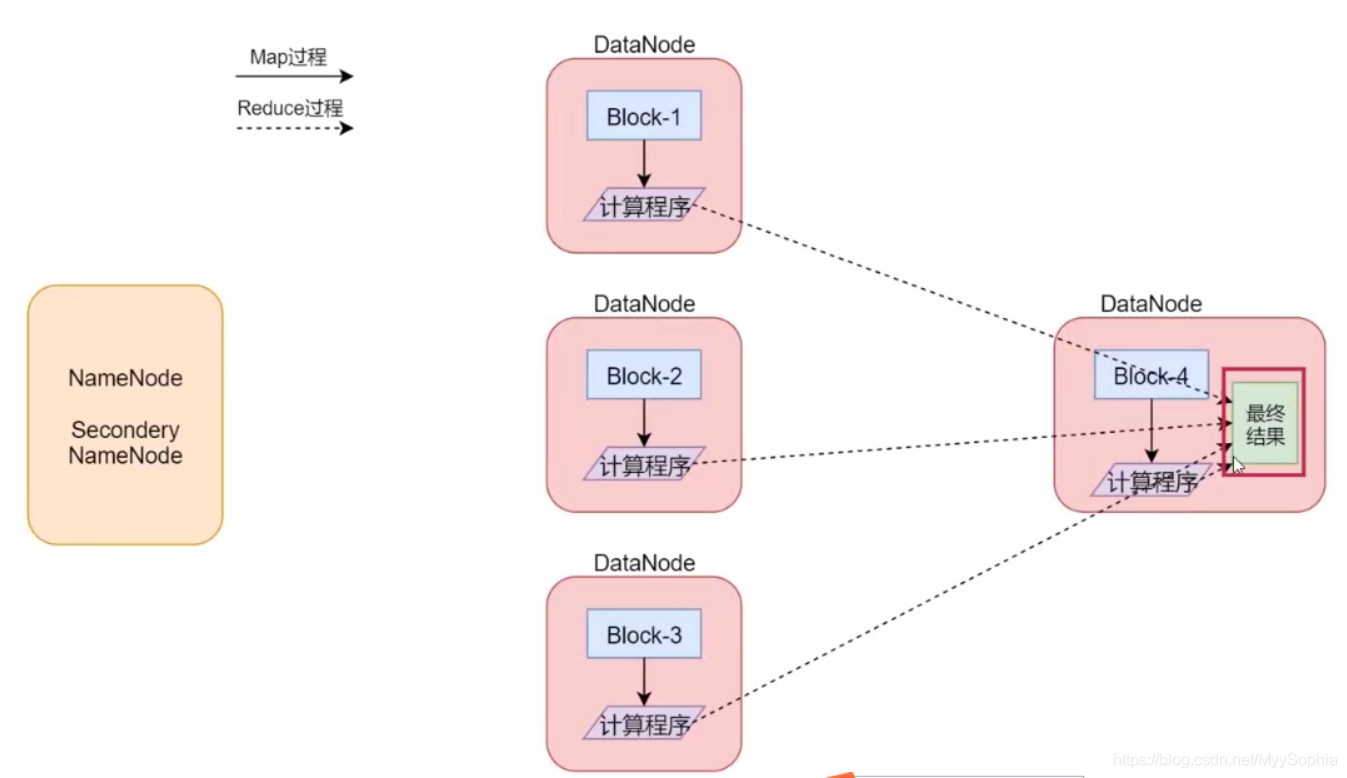
這是一個Hadoop集群,一共5個節點一個主節點,四個從節點
假設我們有一個512M的檔案,這個檔案會產生4個block塊,假設這4個block塊正好分別存盤到了 4個節點上,我們的計算程式會被分發到每一個資料所在的節點,然后開始執行計算,在map階段每一個block塊對應的資料都會產生一個map任務(這個map任務其實就是執行這個計算程式的), 也就意味著會產生4個map任務并行執行,4個map階段都執行完畢以后,會執行reduce階段,在r 階段中會對這4個map任務的輸出資料進行匯總統計,得到最終的結果,
官方的mapreduce原理圖

左下角是一個檔案,檔案最下面是幾個block塊,說明這個檔案被切分成了這幾個block塊,檔案上面是一些split,注意,咱們前面說的每個block產生一個map任務,其實這是不嚴謹的,其實嚴謹一點來說的話 應該是一個split產生一個map任務,
block和split之間有什么關系?
block塊是檔案的物理切分,在磁盤上是真實存在的,是對檔案的真正切分
split是邏輯劃分,不是對檔案真正的切分,默認情況下我們可以認為一個split的大小和一個block的大 小是一樣的,所以實際上是一個split會產生一個map task
這里面的map Task就是咱們前面說的map任務,看后面有一個reduce Task,reduce會把結果資料輸出到hdfs上,有幾個reduce任務就會產生幾個檔案,這里有三個reduce任務,就產生了3個檔案,
map的輸入 輸出 reduce的輸入 輸出
map的輸入是k1,v1 輸出是k2,v2
reduce的輸入是k2,v2 輸出是k3,v3 都是鍵值對的形式,
map端做的是區域的聚合排序,reduce是全域的聚合和排序,reduce是處理多個map多個磁區的聚合結果,不可以混淆兩者
MapReduce之Map階段
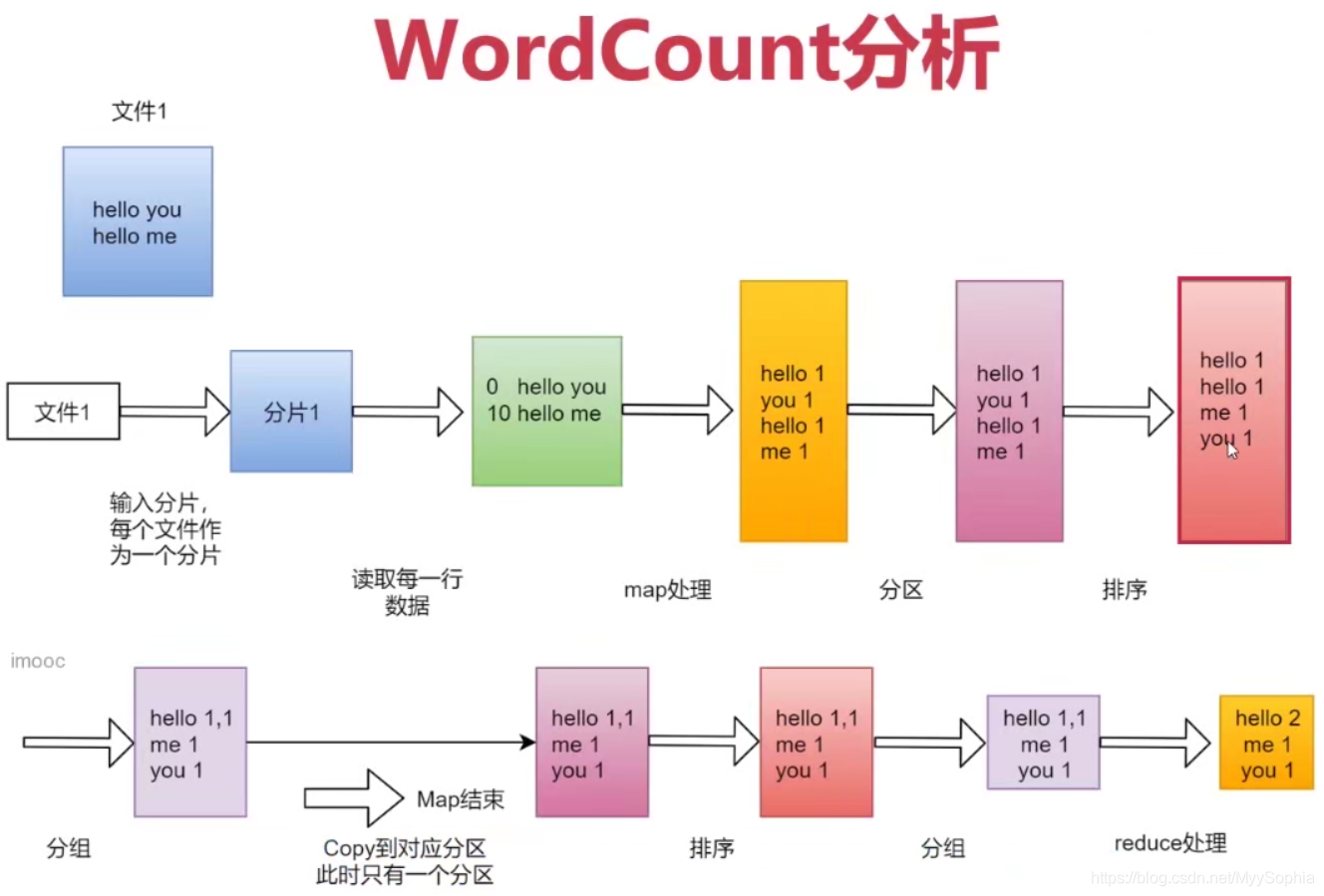
mapreduce主要分為兩大步驟 map和reduce,map和reduce在代碼層面對應的就是兩個類,map對應的是mapper類,reduce對應的是reducer類,下面我們就來根據一個案例具體分析一下這兩個步驟
假設我們有一個檔案,檔案里面有兩行內容
第一行是hello you
第二行是hello me
首先是map階段
第一步框架會把輸入檔案(夾)劃分為很多InputSplit,這里的inputsplit就是前面我們所說的split 件進行邏輯劃分產生的,默認情況下,每個HDFS的Block對應一個InputSplit,再通過Record 類,把每個InputSplit決議成一個一個的<k1,v1>,k1是指每一行的起始偏移量,v1代表的是那一行內容,
所以,針對檔案中的資料,經過map處理之后的結果是這樣的
<0,hello you>
<10,hello me> 這里的10指的是第二行的開始偏移量.
注意:map第一次執行會產生<0,hello you>,第二次執行會產生<10,hello me>
不是執行一次就獲取到這兩行結果了,因為每次只會讀取一行資料
第二步:框架呼叫Mapper類中的map(…)函式,map函式的輸入是<k1,v1>,輸出是<k2,v2>,一個InputSplit對應一個map task,程式員需要自己覆寫Mapper類中的map函式,實作具體的業務邏輯,因為我們需要統計檔案中每個單詞出現的總次數,所以需要先把每一行內容中的單詞切開,然后記錄出現次數為1,這個邏輯就需要我們在map函式中實作了
那針對<0,hello you>執行這個邏輯之后的結果就是
<hello,1>
<you,1>
針對<10,hello me>執行這個邏輯之后的結果是
<hello,1>
<me,1>
第三步:框架對map函式輸出的<k2,v2>進行磁區,不同磁區中的<k2,v2>由不同的reduce task處理
默認只有1個磁區,所以所有的資料都在一個磁區,最后只會產生一個reduce task,
經過這個步驟之后,資料沒什么變化,如果有多個磁區的話,需要把這些資料根據磁區規則分開,在這里默認只有1個磁區,
<hello,1>
<you,1>
<hello,1>
<me,1>
單詞計數,其實就是把每個單詞出現的次數進行匯總即可,需要進行全域的匯總,不需要進行磁區,所以一個redeuce任務就可以搞定,
如果你的業務邏輯比較復雜,需要進行磁區,那么就會產生多個reduce任務了,
map任務輸出的資料到底給哪個reduce使用?這個就需要劃分一下,要不然就亂套了, 假設有兩個reduce,map的輸出到底給哪個reduce,如何分配,這是一個問題,
這個問題,由磁區來完成,
map輸出的那些資料到底給哪個reduce使用,這個就是磁區干的事了,
第四步:框架對每個磁區中的資料,都會按照k2進行排序、分組,分組指的是相同k2的v2分成一個組,先按照k2排序
<hello,1>
<hello,1>
<me,1>
<you,1>
然后按照k2進行分組,把相同k2的v2分成一個組
<hello,{1,1}>
<me,{1}>
<you,{1}>
第五步:在map階段,框架可以選擇執行Combiner程序【可選步驟】
Combiner可以翻譯為規約,規約是什么意思呢?
在剛才的例子中,咱們最終是要在reduce端計算單詞出現的總次數的,所以其實是可以在map端提前執行reduce的計算邏輯,先對在map端對單詞出現的次 數進行區域求和操作,這樣就可以減少map端到reduce端資料傳輸的大小,這就是規約的好處,當然 了,并不是所有場景都可以使用規約,針對求平均值之類的操作就不能使用規約了,否則最終計算的結果就不準確了,
Combiner一個可選步驟,默認這個步驟是不執行的,
第六步:框架會把map task輸出的<k2,v2>寫入到linux 的磁盤檔案中
<hello,{1,1}>
<me,{1}>
<you,{1}>
至此,整個map階段執行結束最后注意一點:
MapReduce程式是由map和reduce這兩個階段組成的,但是reduce階段不是必須的,也就是說有的
mapreduce任務只有map階段,為什么會有這種任務呢?
reduce主要是做最終聚合的,如果我們這個需求是不需要聚合操作,直接對資料做過濾處理就行了,那也就意味著資料經過map階段處理完就結束了,所以如果reduce階段不存在的話,map的結果是可以直接保存到HDFS中的
注意,如果沒有reduce階段,其實map階段只需要執行到第二步就可以,第二步執行完成以后,結果就可以直接輸出到HDFS了,
MapReduce之Reduce階段
第一步:框架對多個map任務的輸出,按照不同的磁區,通過網路copy到不同的reduce節點,這個程序 稱作shu?e
針對我們這個需求,只有一個磁區,所以把資料拷貝到reduce端之后還是老樣子
<hello,{1,1}>
<me,{1}>
<you,{1}>
第二步:框架對reduce端接收的相同磁區的<k2,v2>資料進行合并、排序、分組,
reduce端接收到的是多個map的輸出,對多個map任務中相同磁區的資料進行合并 排序 分組
注意,之前在map中已經做了排序 分組,這邊也做這些操作 重復嗎?
不重復,因為map端是區域的操作 reduce端是全域的操作
之前是每個map任務內進行排序,是有序的,但是多個map任務之間就是無序的了,
不過針對我們這個需求只有一個map任務一個磁區,所以最終的結果還是老樣子
<hello,{1,1}>
<me,{1}>
<you,{1}>
第三步:框架呼叫Reducer類中的reduce方法,reduce方法的輸入是<k2,{v2}>,輸出是<k3,v3>,一個
<k2,{v2}>呼叫一次reduce函式,程式員需要覆寫reduce函式,實作具體的業務邏輯,
那我們在這里就需要在reduce函式中實作最終的聚合計算操作了,將相同k2的{v2}累加求和,然后再轉
化為k3,v3寫出去,在這里最侄訓呼叫三次reduce函式
<hello,2>
<me,1>
<you,1>
第四步:框架把reduce的輸出結果保存到HDFS中,
hello 2
me 1
you 1
至此,整個reduce階段結束,
單檔案wordConut圖例
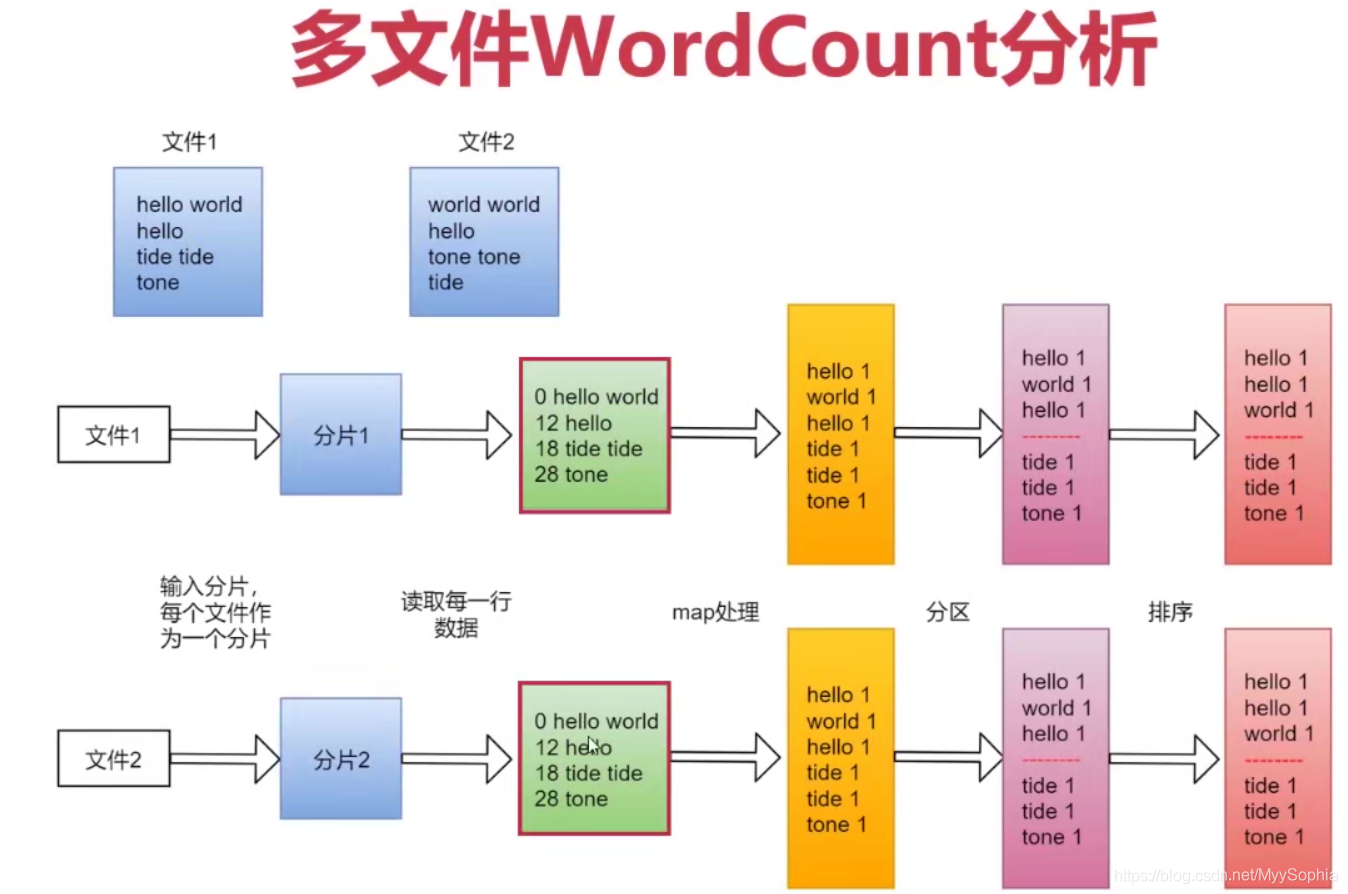
多檔案wordCount圖例
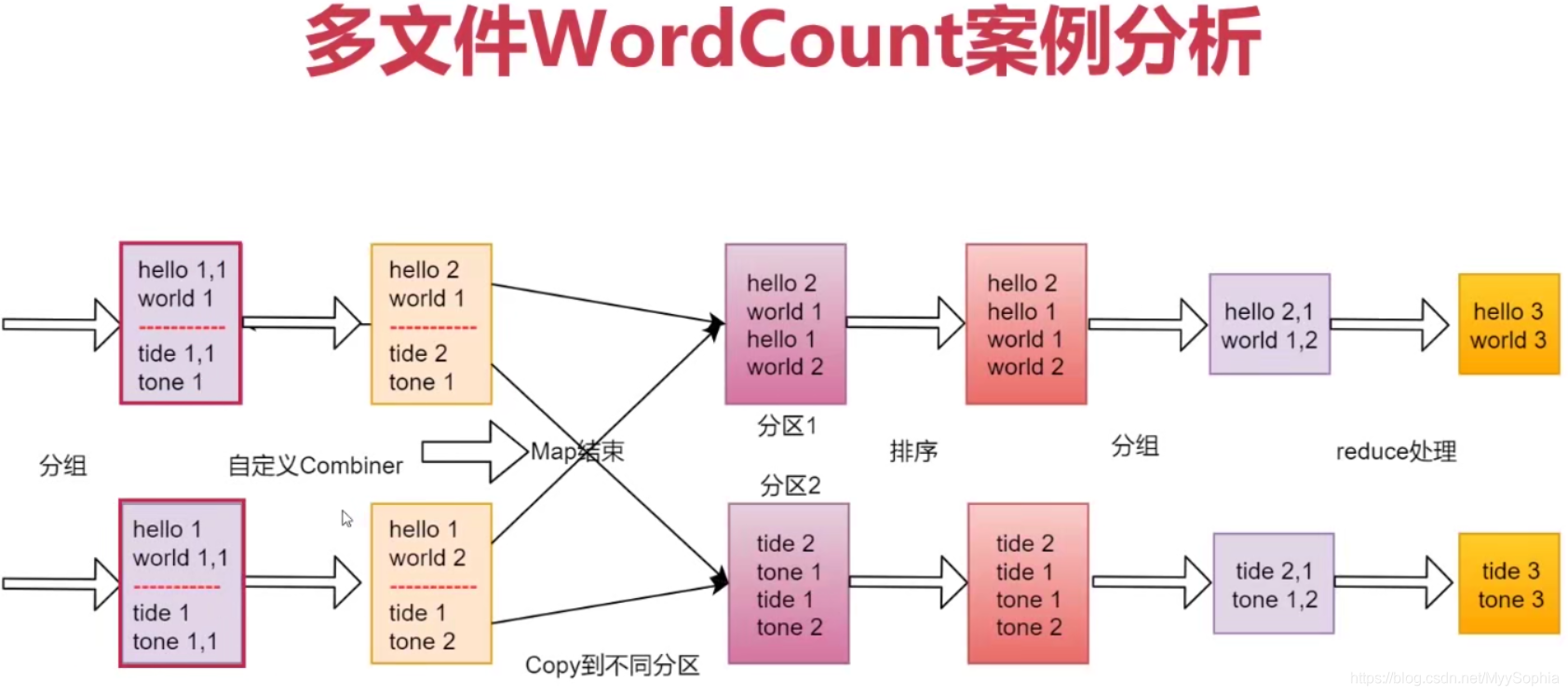
wordCount java代碼實作
/**
* Map階段
*/
public static class MyMapper extends Mapper<LongWritable, Text,Text,LongWritable>{
Logger logger = LoggerFactory.getLogger(MyMapper.class);
/**
* 需要實作map函式
* 這個map函式就是可以接收<k1,v1>,產生<k2,v2>
* @param k1
* @param v1
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable k1, Text v1, Context context)
throws IOException, InterruptedException {
//輸出k1,v1的值
//System.out.println("<k1,v1>=<"+k1.get()+","+v1.toString()+">");
//logger.info("<k1,v1>=<"+k1.get()+","+v1.toString()+">");
//k1 代表的是每一行資料的行首偏移量,v1代表的是每一行內容
//對獲取到的每一行資料進行切割,把單詞切割出來
String[] words = v1.toString().split(" ");
//迭代切割出來的單詞資料
for (String word : words) {
//把迭代出來的單詞封裝成<k2,v2>的形式
Text k2 = new Text(word);
LongWritable v2 = new LongWritable(1L);
//把<k2,v2>寫出去
context.write(k2,v2);
}
}
}
/**
* Reduce階段
*/
public static class MyReducer extends Reducer<Text,LongWritable,Text,LongWritable>{
Logger logger = LoggerFactory.getLogger(MyReducer.class);
/**
* 針對<k2,{v2...}>的資料進行累加求和,并且最終把資料轉化為k3,v3寫出去
* @param k2
* @param v2s
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text k2, Iterable<LongWritable> v2s, Context context)
throws IOException, InterruptedException {
//創建一個sum變數,保存v2s的和
long sum = 0L;
//對v2s中的資料進行累加求和
for(LongWritable v2: v2s){
//輸出k2,v2的值
//System.out.println("<k2,v2>=<"+k2.toString()+","+v2.get()+">");
//logger.info("<k2,v2>=<"+k2.toString()+","+v2.get()+">");
sum += v2.get();
}
//組裝k3,v3
Text k3 = k2;
LongWritable v3 = new LongWritable(sum);
//輸出k3,v3的值
//System.out.println("<k3,v3>=<"+k3.toString()+","+v3.get()+">");
//logger.info("<k3,v3>=<"+k3.toString()+","+v3.get()+">");
// 把結果寫出去
context.write(k3,v3);
}
}
/**
* 組裝Job=Map+Reduce
*/
public static void main(String[] args) {
try{
if(args.length!=2){
//如果傳遞的引數不夠,程式直接退出
System.exit(100);
}
//指定Job需要的配置引數
Configuration conf = new Configuration();
//創建一個Job
Job job = Job.getInstance(conf);
//注意了:這一行必須設定,否則在集群中執行的時候是找不到WordCountJob這個類的
job.setJarByClass(WordCountJob.class);
//指定輸入路徑(可以是檔案,也可以是目錄)
FileInputFormat.setInputPaths(job,new Path(args[0]));
//指定輸出路徑(只能指定一個不存在的目錄)
FileOutputFormat.setOutputPath(job,new Path(args[1]));
//指定map相關的代碼
job.setMapperClass(MyMapper.class);
//指定k2的型別
job.setMapOutputKeyClass(Text.class);
//指定v2的型別
job.setMapOutputValueClass(LongWritable.class);
//指定reduce相關的代碼
job.setReducerClass(MyReducer.class);
//指定k3的型別
job.setOutputKeyClass(Text.class);
//指定v3的型別
job.setOutputValueClass(LongWritable.class);
//提交job
job.waitForCompletion(true);
}catch(Exception e){
e.printStackTrace();
}
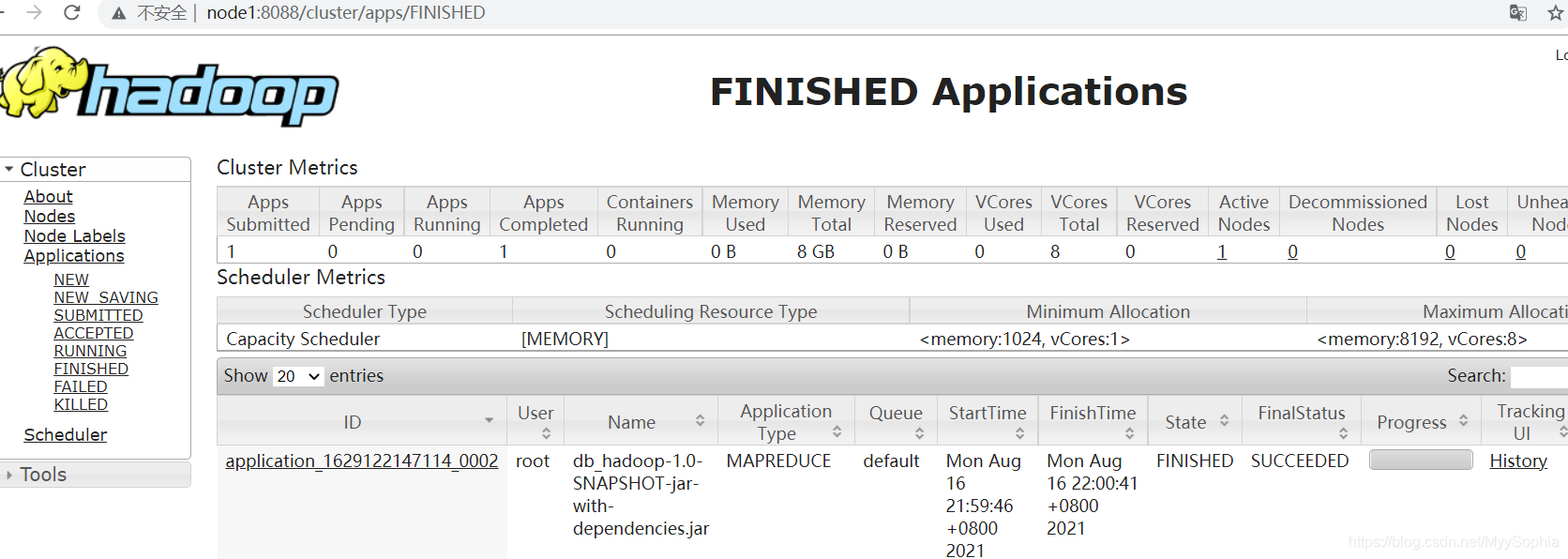
}wordCount程式在hadoop上的執行
note: 通過host訪問hadoop yarn界面
需要修改C:\Windows\System32\drivers\etc\host
添加一下內容
192.168.56.10 node1
hadoop-2.7.5]# hadoop jar /opt/soft/hadoop-2.7.5/db_hadoop-1.0-SNAPSHOT-jar-with-dependencies.jar com.imooc.mr.WordCountJob /test/hello.txt /out
21/08/16 13:59:42 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
21/08/16 13:59:44 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
21/08/16 13:59:45 INFO input.FileInputFormat: Total input paths to process : 1
21/08/16 13:59:45 INFO mapreduce.JobSubmitter: number of splits:1
21/08/16 13:59:46 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1629122147114_0002
21/08/16 13:59:47 INFO impl.YarnClientImpl: Submitted application application_1629122147114_0002
21/08/16 13:59:47 INFO mapreduce.Job: The url to track the job: http://node1:8088/proxy/application_1629122147114_0002/
21/08/16 13:59:47 INFO mapreduce.Job: Running job: job_1629122147114_0002
21/08/16 14:00:11 INFO mapreduce.Job: Job job_1629122147114_0002 running in uber mode : false
21/08/16 14:00:11 INFO mapreduce.Job: map 0% reduce 0%
21/08/16 14:00:27 INFO mapreduce.Job: map 100% reduce 0%
21/08/16 14:00:41 INFO mapreduce.Job: map 100% reduce 100%
21/08/16 14:00:42 INFO mapreduce.Job: Job job_1629122147114_0002 completed successfully
21/08/16 14:00:44 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=65
FILE: Number of bytes written=243715
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=116
HDFS: Number of bytes written=19
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=13624
Total time spent by all reduces in occupied slots (ms)=12076
Total time spent by all map tasks (ms)=13624
Total time spent by all reduce tasks (ms)=12076
Total vcore-milliseconds taken by all map tasks=13624
Total vcore-milliseconds taken by all reduce tasks=12076
Total megabyte-milliseconds taken by all map tasks=13950976
Total megabyte-milliseconds taken by all reduce tasks=12365824
Map-Reduce Framework
Map input records=2
Map output records=4
Map output bytes=51
Map output materialized bytes=65
Input split bytes=97
Combine input records=0
Combine output records=0
Reduce input groups=3
Reduce shuffle bytes=65
Reduce input records=4
Reduce output records=3
Spilled Records=8
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=365
CPU time spent (ms)=2800
Physical memory (bytes) snapshot=311902208
Virtual memory (bytes) snapshot=4160294912
Total committed heap usage (bytes)=165810176
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=19
File Output Format Counters
Bytes Written=19

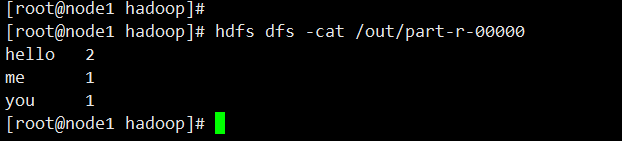
MapReduce任務日志查看
在自定義mapper類的map函式中增加一個輸出,將k1,v1的值列印出來
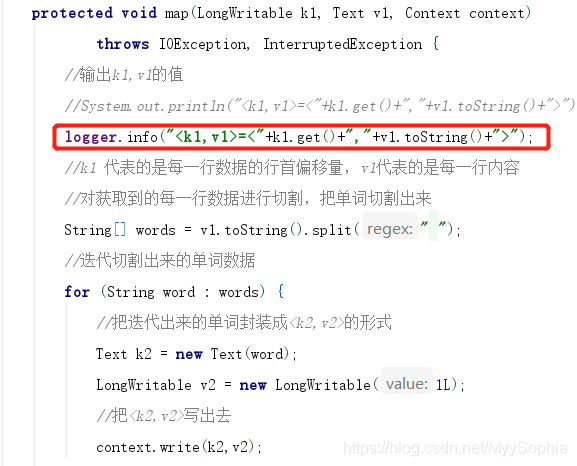
重新打包在hadoop集群上執行
注意,針對輸出目錄,要么換一個新的不存在的目錄,要么把之前的out目錄刪掉

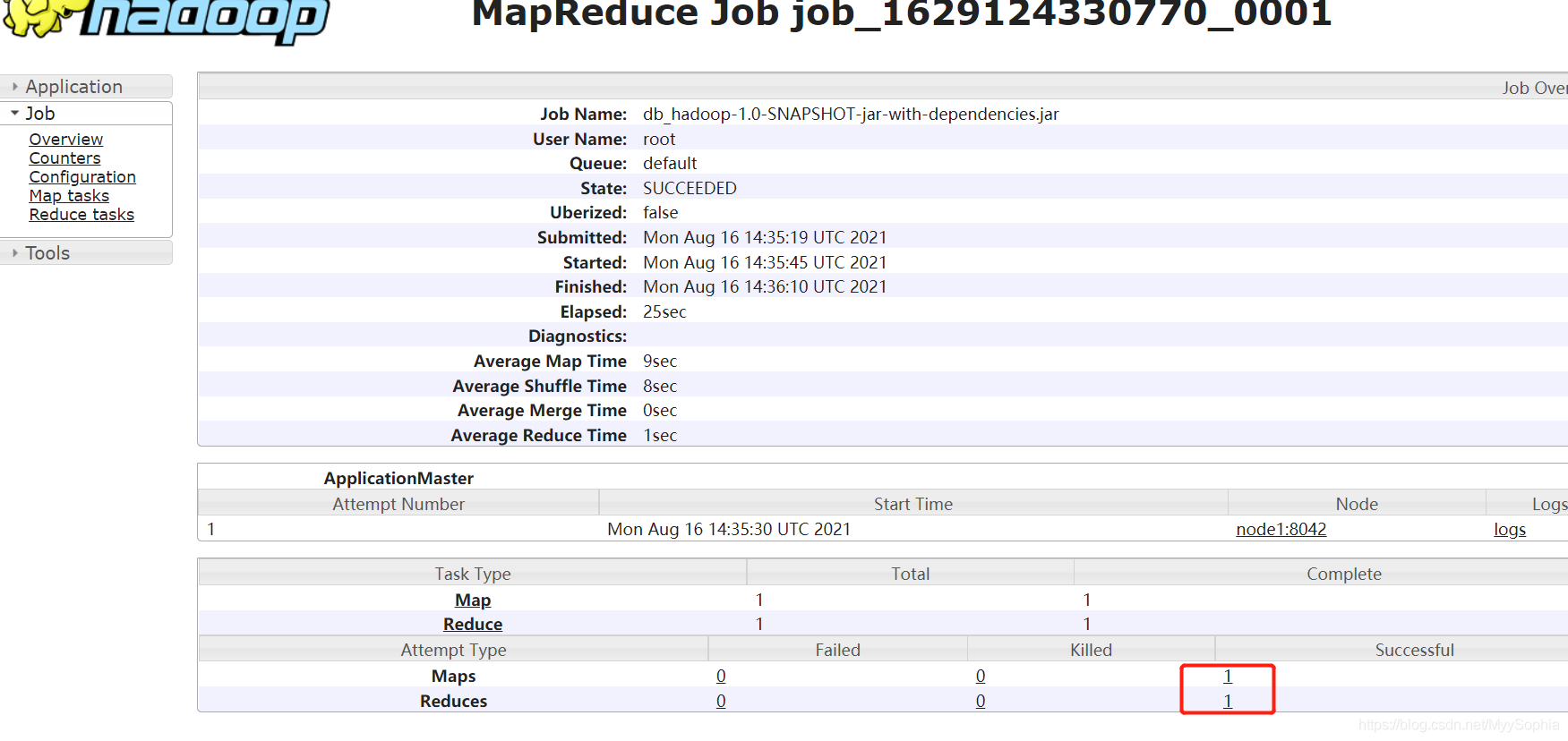
mapreduce任務正在執行的時候是可以通過history查看log,包括map類中自定義的log,
當任務執行完畢之后,這個鏈接就點不開了.
如果想查看應該怎么辦呢?
1、yarn-site增加配置log server
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://node1:19888/jobhistory/logs/</value>
</property>2、重啟集群
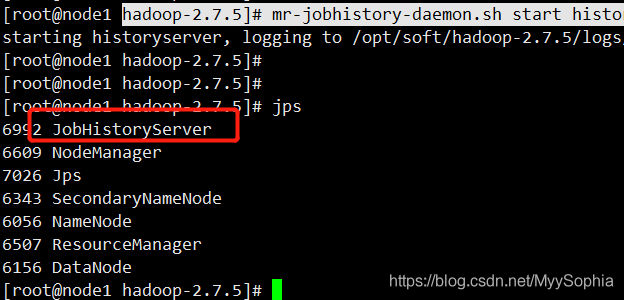
3、啟動historyserver行程,需要在集群的所有節點上都啟動這個行程
bin/mapred --daemon start historyserver如果是hadoop2.7使用
hadoop-2.7.5]# mr-jobhistory-daemon.sh start historyserver4、jps確認
5、重新提交任務并通過yarn界面查看log
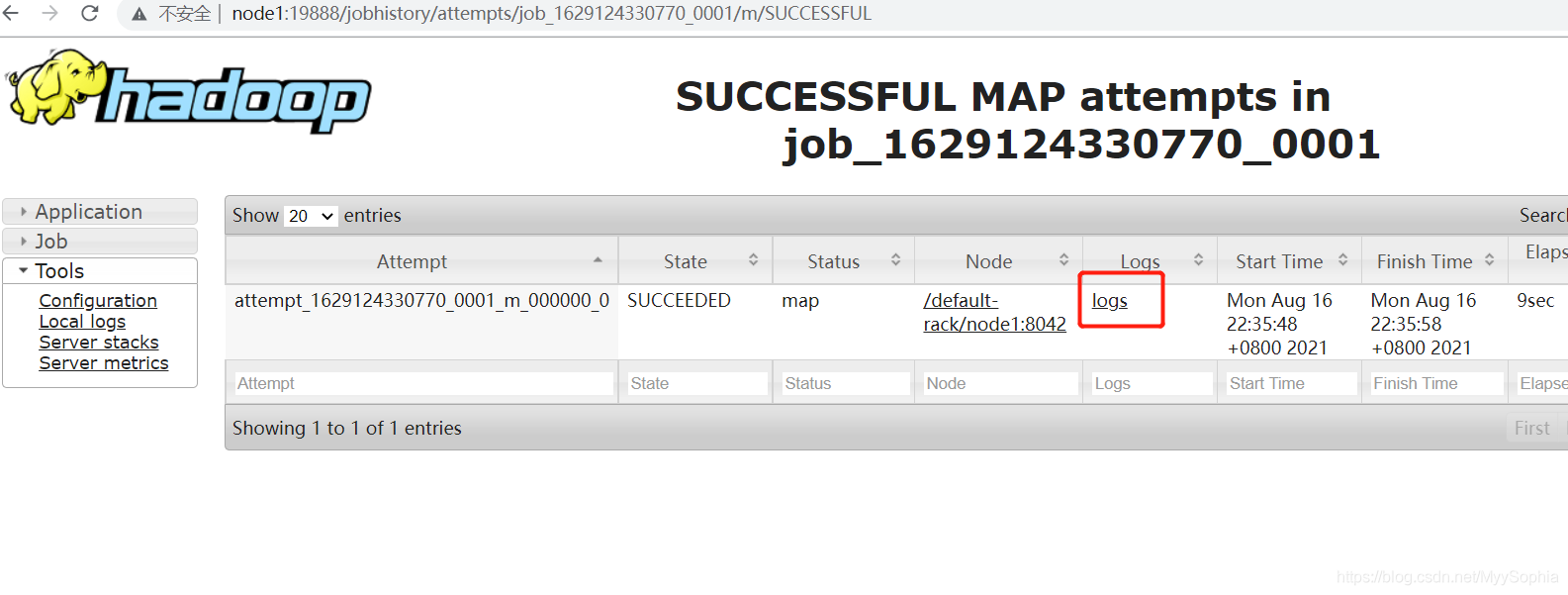
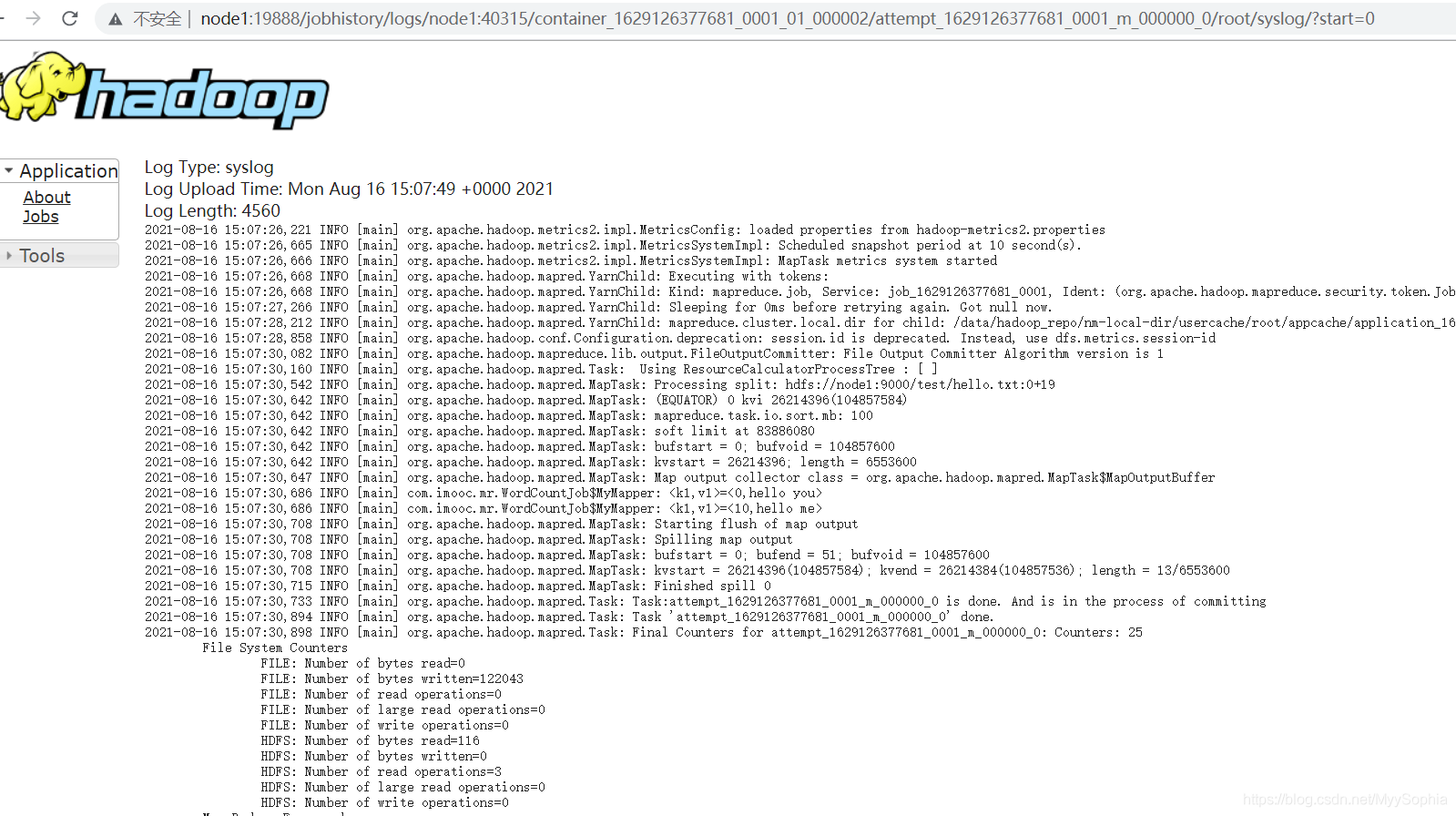
這邊還有一個報錯,等待解決.

此外還可以直接用yarn 命令來查看log
按照這片文章修復這個問題: https://blog.csdn.net/yh_zeng2/article/details/52281712
停止Hadoop集群中的任務
如果一個mapreduce任務處理的資料量比較大的話,這個任務會執行很長時間,可能幾十分鐘或者幾個小時都有可能,假設一個場景,任務執行了一半了我們發現我們的代碼寫的有問題,需要修改代碼重新提交執行,這個時候之前的任務就沒有必要再執行了,沒有任何意義了,最終的結果肯定是錯誤的,所以我們就想把它停掉,要不然會額外浪費集群的資源,如何停止呢?
CTRL +C是無法停止已經提交到集群的任務的.
yarn application -kill application_1629126377681_0001MapReduce程式擴展
reduce階段不是必須的,那也就意味著MapReduce程式可以只包含map階段,什么場景下會只需要map階段呢?
當資料只需要進行普通的過濾、決議等操作,不需要進行聚合,這個時候就不需要使用reduce階段了,代碼中如何設定呢?
//禁用reduce階段
job.setNumReduceTasks(0);轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/294417.html
標籤:其他
上一篇:Spark之Spark內核