目錄
- 一. Hadoop簡介
- 1 hadoop的演變
- 2 hadoop的簡介
- 3 作業原理
- Nn和Dn
- 節點故障/網路故障/資料塊損壞
- RM:resourcemanager
- 二. hadoop作業模式
- 1 偽分布式
- 2 完全分布式
- 三. yarn 調度
- 四. hadoop高可用
- 1 zookeeper集群
- 2 hdfs高可用
- 3 yarn 高可用
- 4 hbase 高可用
操作參考手冊:https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html
一. Hadoop簡介
1 hadoop的演變
Hadoop起源于Google的三大論文:
- GFS:Google的分布式檔案系統Google File System
- MapReduce:Google的MapReduce開源分布式并行計算框架
- BigTable:一個大型的分布式資料庫
演變關系:
GFS—->HDFS
Google MapReduce—->Hadoop MapReduce
BigTable—->HBase
Hadoop名字不是一個縮寫,是Hadoop之父Doug Cutting兒子毛絨玩具象命名的
hadoop主流版本:
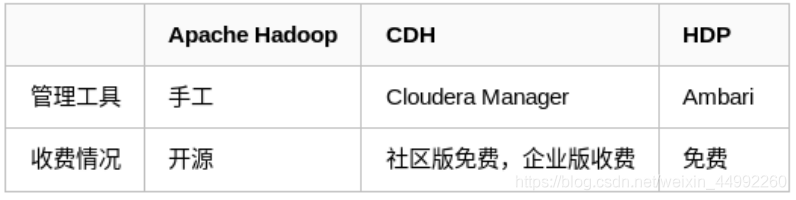
- Apache基金會hadoop
- Cloudera版本(Cloudera’s Distribution Including Apache Hadoop,簡稱“CDH”)
- Hortonworks版本(Hortonworks Data Platform,簡稱“HDP”)
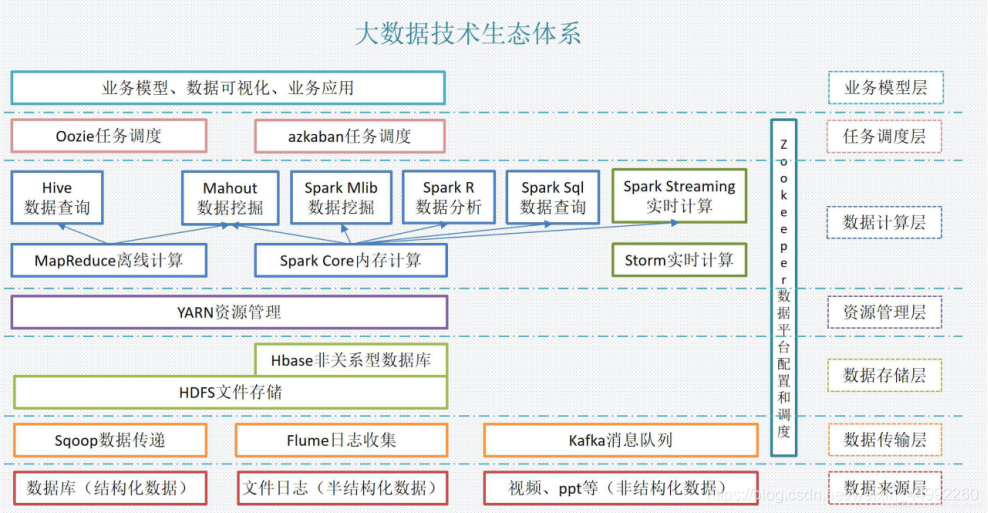
Hadoop的框架最核心的設計就是:HDFS和MapReduce,
- HDFS為海量的資料提供了存盤,
- MapReduce為海量的資料提供了計算,
Hadoop框架包括以下四個模塊:
Hadoop Common: 這些是其他Hadoop模塊所需的Java庫和實用程式,這些庫提供檔案系統和作業系統級抽象,并包含啟動Hadoop所需的Java檔案和腳本,Hadoop YARN: 這是一個用于作業調度和集群資源管理的框架,Hadoop Distributed File System (HDFS): 分布式檔案系統,提供對應用程式資料的高吞吐量訪問,Hadoop MapReduce:這是基于YARN的用于并行處理大資料集的系統,
hadoop應用場景:
- 在線旅游
- 移動資料
- 電子商務
- 能源開采與節能
- 基礎架構管理
- 影像處理
- 詐騙檢測
- IT安全
- 醫療保健
2 hadoop的簡介
-
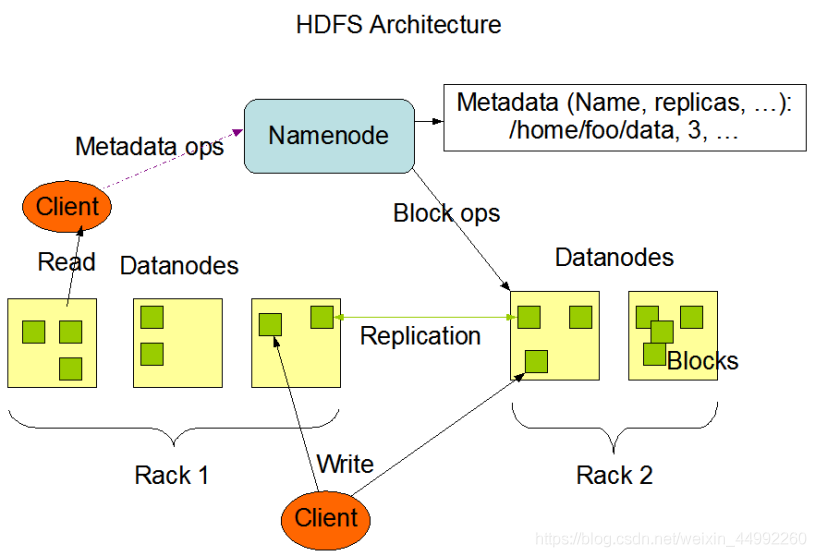
HDFS屬于
Master與Slave結構,一個集群中只有一個NameNode,可以有多個DataNode, -
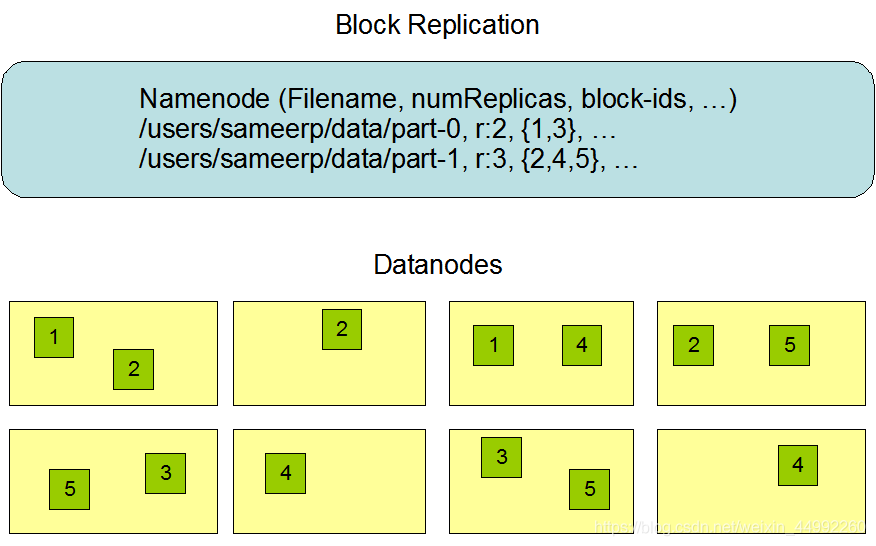
HDFS存盤機制保存了多個副本,當寫入1T檔案時,我們需要3T的存盤,3T的網路流量帶寬;系統提供容錯機制,副本丟失或宕機可自動恢復,保證系統高可用性,
-
HDFS默認會將檔案分割成block,然后將block按鍵值對存盤在HDFS上,并將鍵值對的映射存到記憶體中,如果小檔案太多,會導致記憶體的負擔很重, -
HDFS采用的是
一次寫入多次讀取的檔案訪問模型,一個檔案經過創建、寫入和關閉之后就不需要改變,這一假設簡化了資料一致性問題,并且使高吞吐量的資料訪問成為可能, -
HDFS
存盤理念是以最少的錢買最爛的機器并實作最安全、難度高的分布式檔案系統(高容錯性低成本),HDFS認為機器故障是種常態,所以在設計時充分考慮到單個機器故障,單個磁盤故障,單個檔案丟失等情況, -
HDFS
容錯機制:
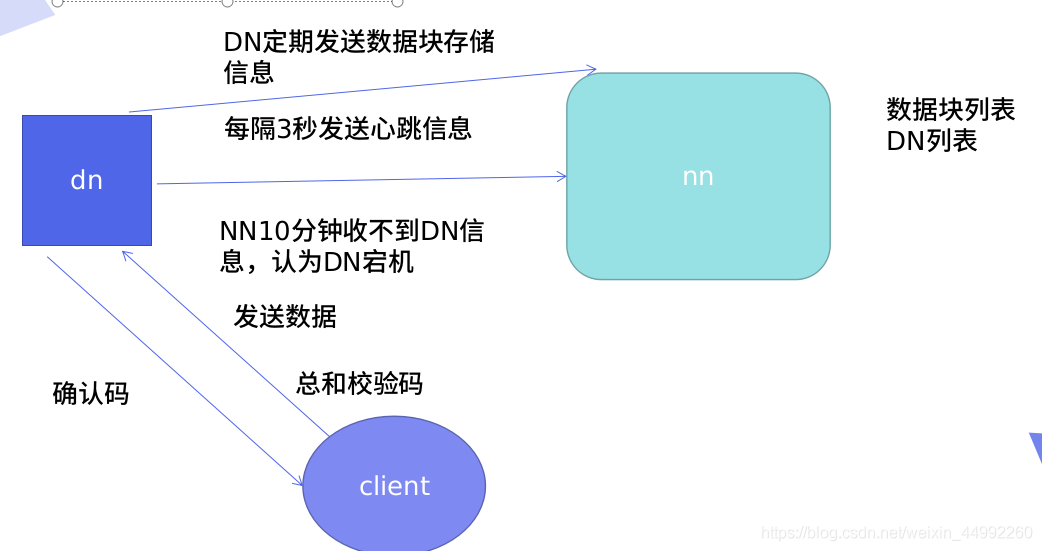
節點失敗監測機制:DN每隔3秒向NN發送心跳信號,10分鐘收不到,認為DN宕機,
通信故障監測機制:只要發送了資料,接收方就會回傳確認碼,
資料錯誤監測機制:在傳輸資料時,同時會發送總和校驗碼,
3 作業原理
Nn和Dn
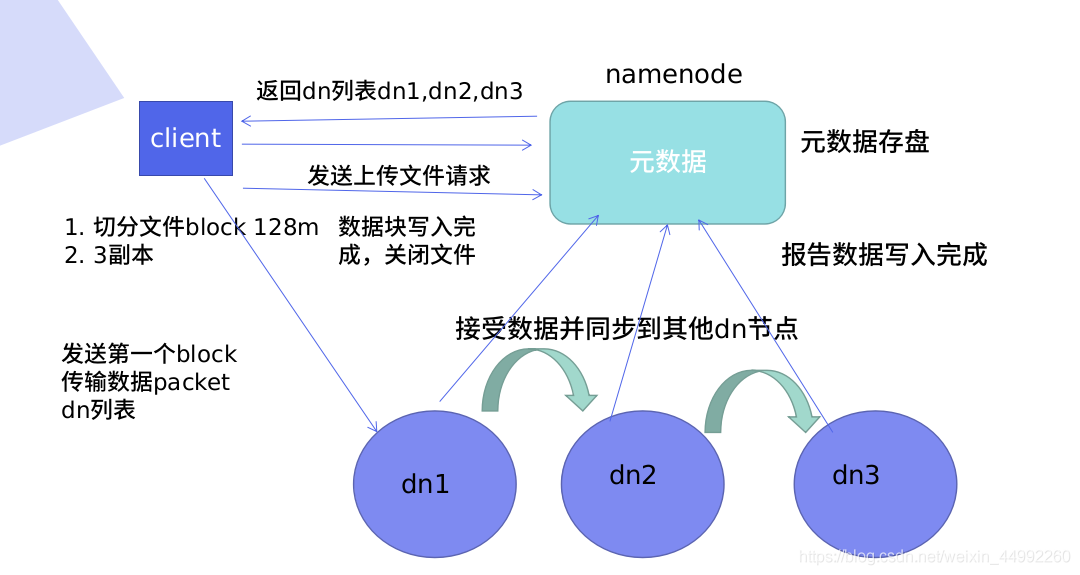
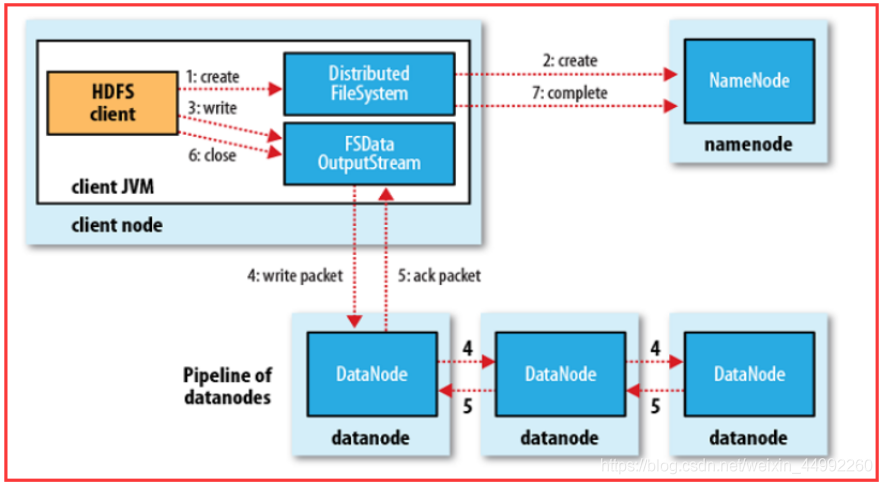
作業原理:
Cliet向Namenode請求,Nn向cl回傳Dn串列(Dn串列有順序,校驗資料的距離,根據距離排序),Nn知道所有節點的狀態,Cl知道會以多大的block切分,設定副本數,Cl連接dn串列,(發送第一個block傳輸資料packet和dn串列),Nn接收block并保存dn串列資料,同步其他Dn節點(邊接收邊同步),Dn報告Block存盤完成,
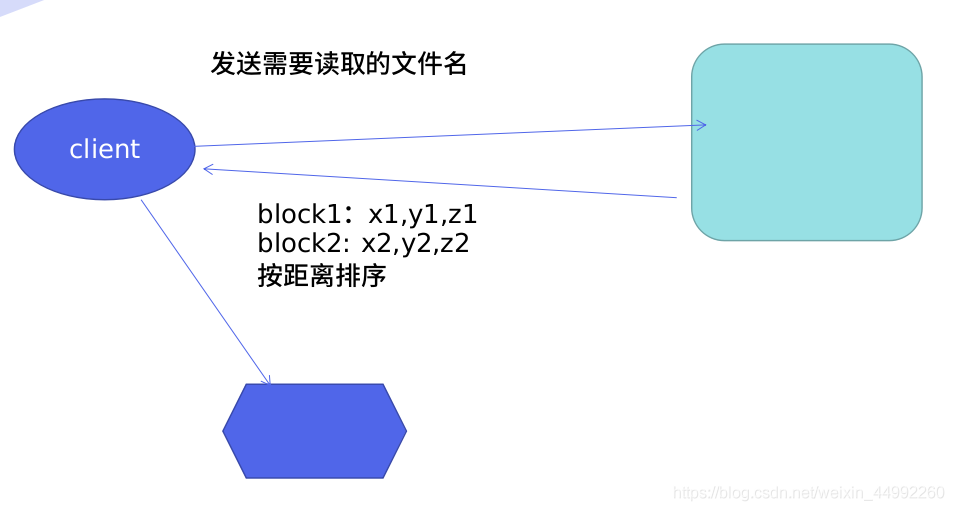
回傳Dn串列順序
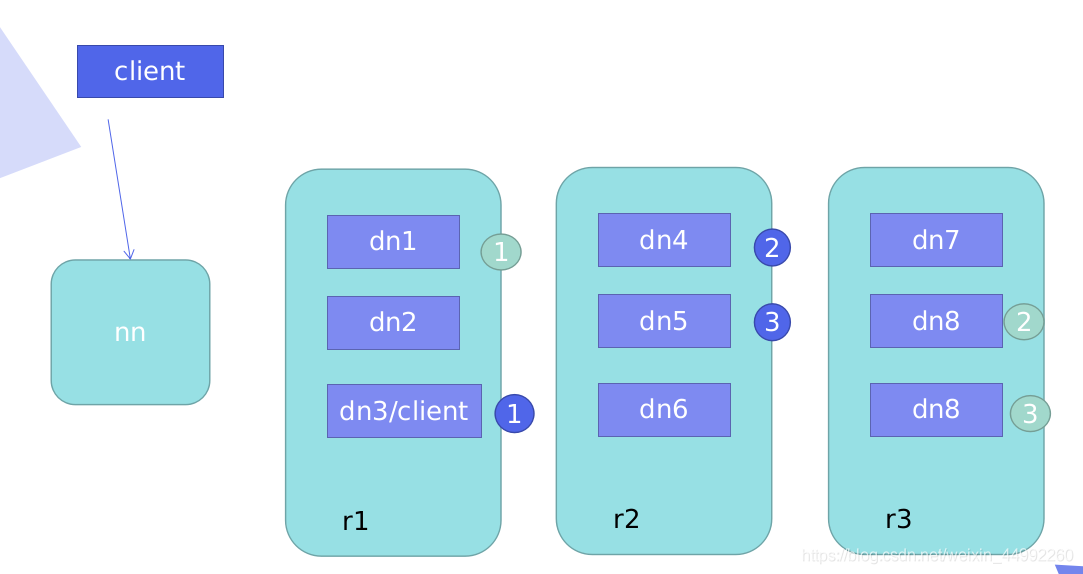
-
Cl和Dn節點在同一臺機器,存盤副本(默認3個),Nn回傳的Dn串列順序:本機–不同機架的不同Dn上----同機架的不同Dn上(down后,找本機架其他的Dn)其他的隨機,只是控制前3 -
Cl和Dn節點不在同一臺機器:第一個副本隨機,2,3副本一樣
hdfs中文漫畫:https://blog.csdn.net/lsziri/article/details/102503486
節點故障/網路故障/資料塊損壞
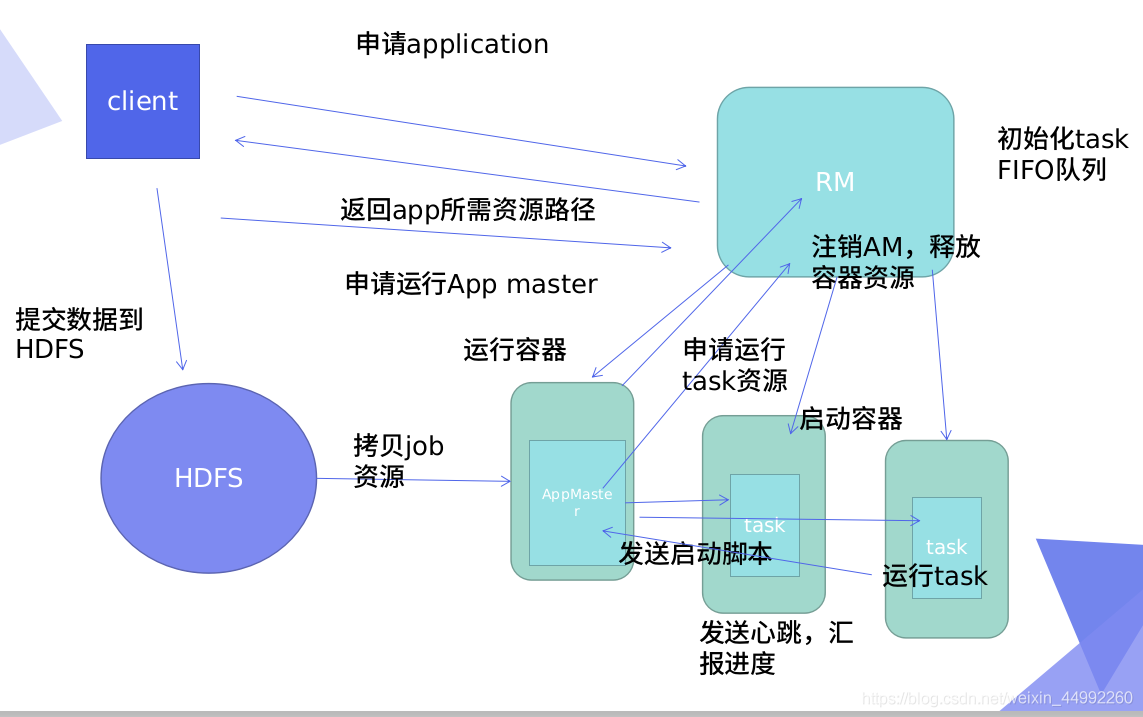
RM:resourcemanager
v1: jobTrack,不能過2000節點
v2:過2000節點
作業原理:
Cl向RM申請,任務佇列,RM回傳app所需資源路徑,Cl需要的資源資料存盤到HDFS,Cl申請運行App master,RM運行容器(分配資源)AM,AM拷貝HDFS中的job資源,AM向RM申請運行資源,RM會分配到下面的多個task中,實時匯總AM,AM持續監控job
完成任務后,申請釋放資源,RM注銷AM,釋放容器資源
二. hadoop作業模式
1 偽分布式
實驗環境:
| 主機名 | ip |
|---|---|
| vm1 | 172.25.28.11(2G) |
Nn和Dn不分離:
hadoop安裝有jdk要求,不用rpm包,使用原始碼tar.gz,
建立hadoop用戶,解壓縮jdk包,普通用戶hadoop運行
hadoop和java作軟鏈接,方便更新版本
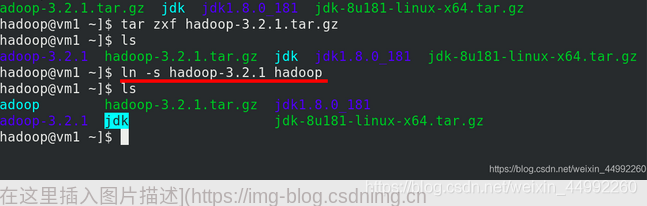

編輯檔案,修改java和hadoop的環境變數

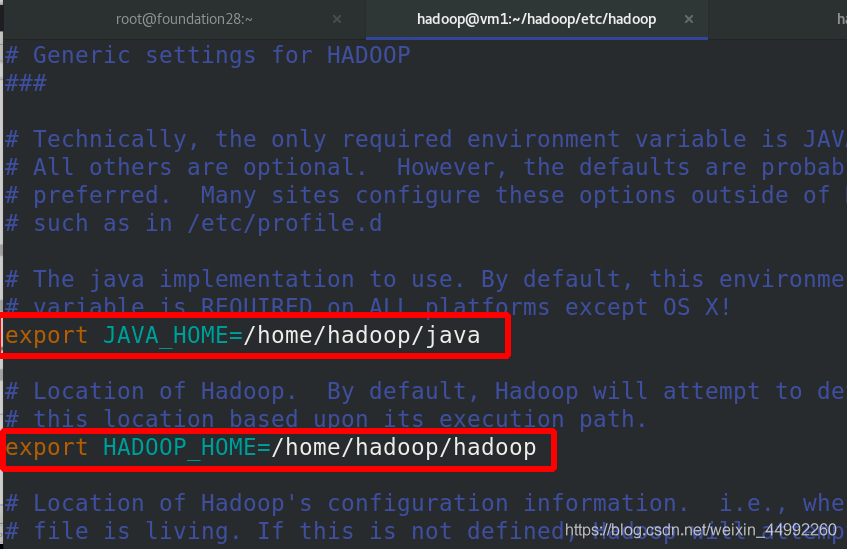
新建input目錄
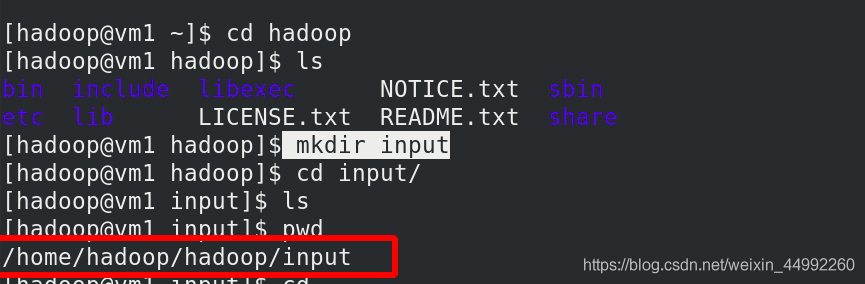
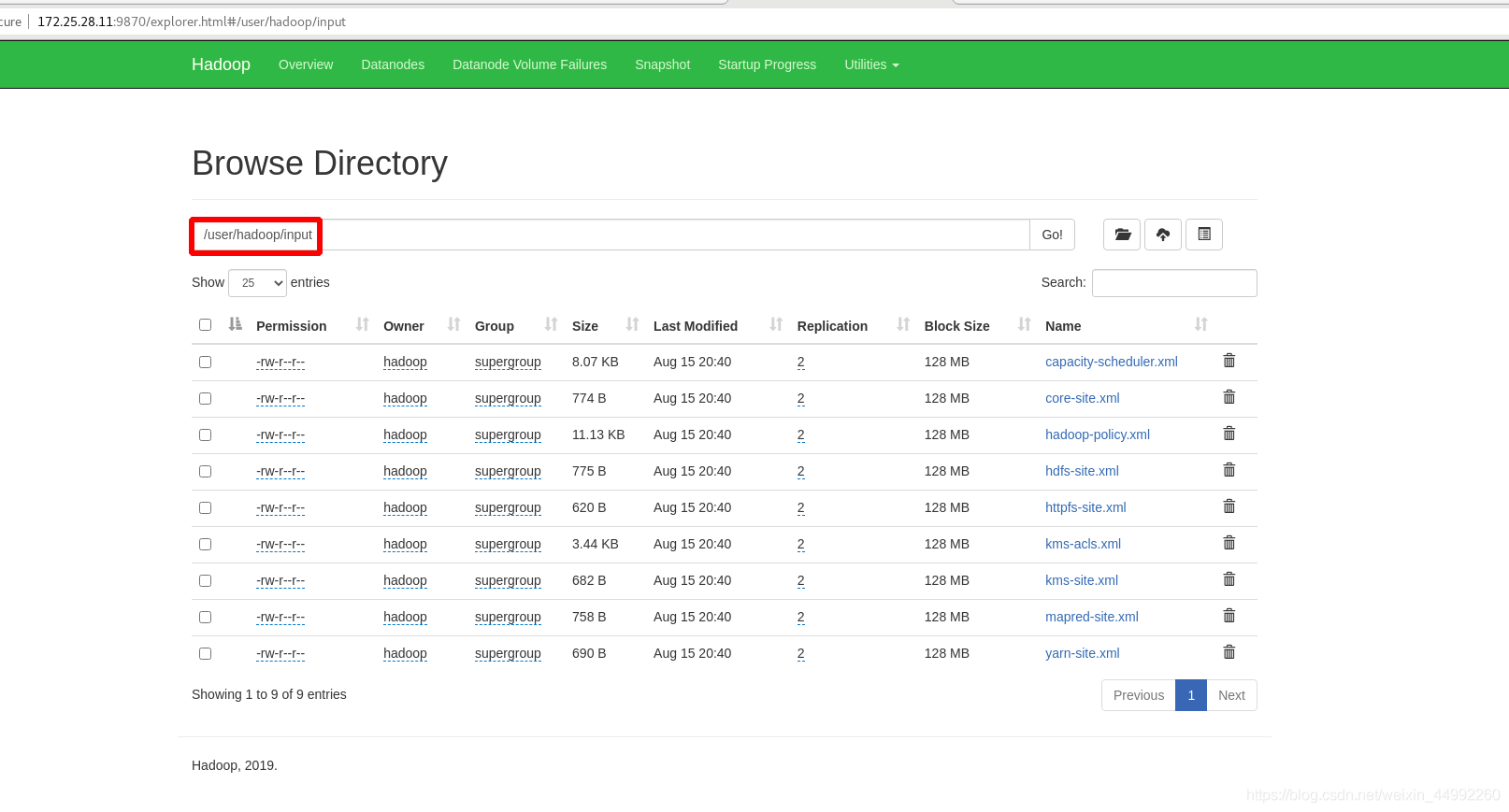
將etc/hadoop中.xml 檔案復制到input目錄
Hadoop 配置為在非分布式模式下作為單個 Java 行程運行,查找并顯示給定正則運算式的每個匹配項, 輸出寫入給定的輸出目錄 output,outpot不用創建,過濾dfs的關鍵字,
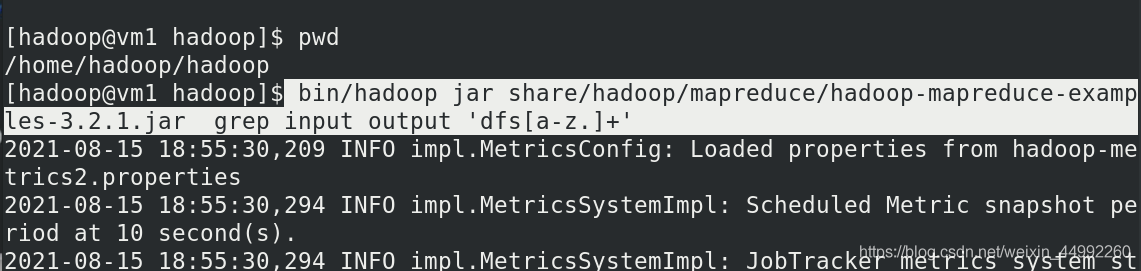
查看output目錄中的內容
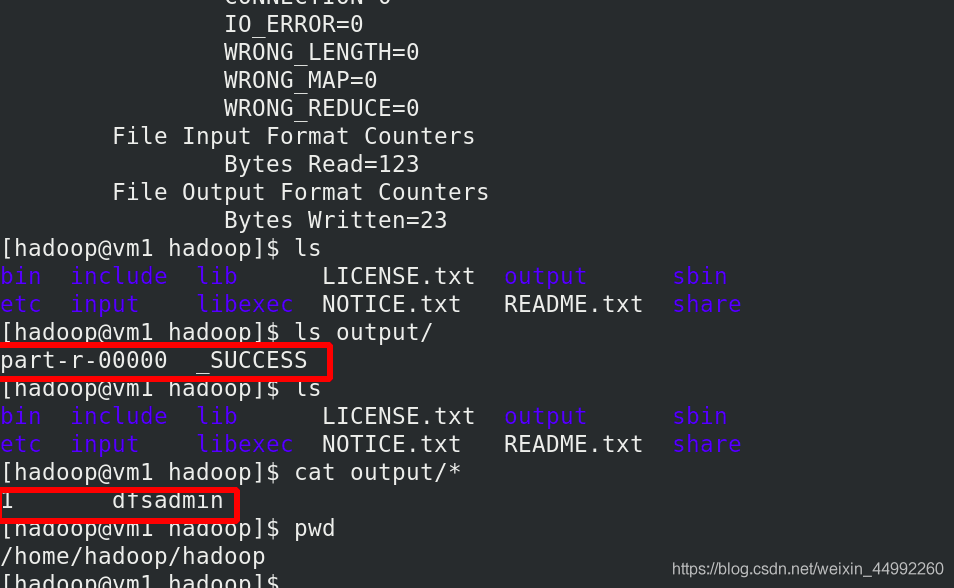
Hadoop 也可以以偽分布式模式在單節點上運行,其中每個 Hadoop 守護行程在單獨的 Java 行程中運行,
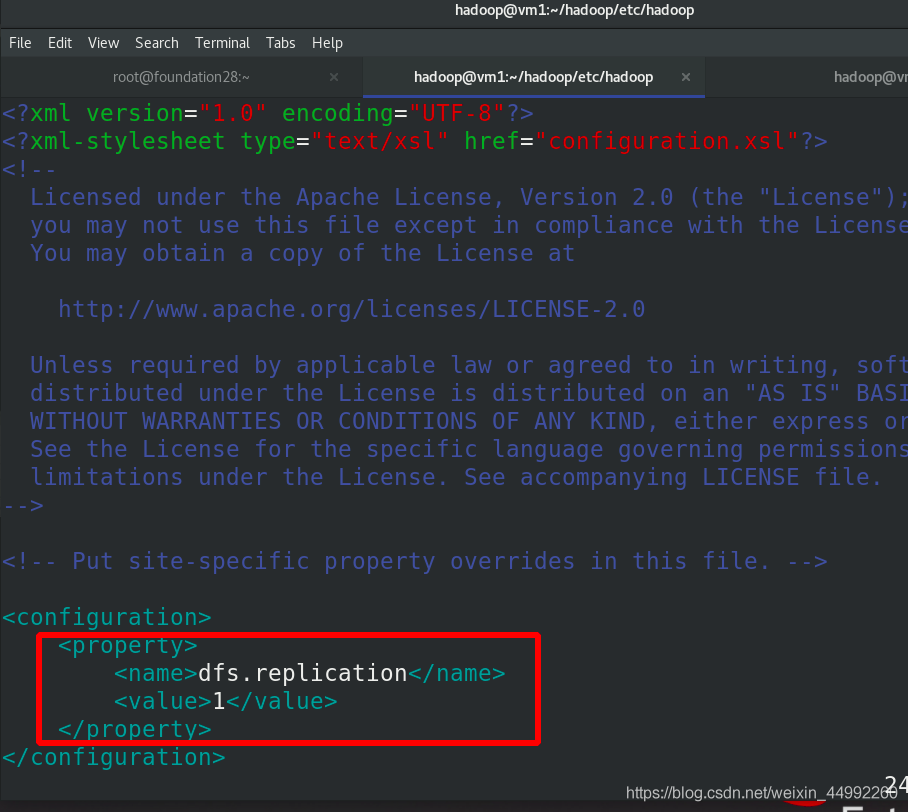
編輯 etc/hadoop/hdfs-site.xml 檔案,副本數為1
編輯etc/hadoop/core-site.xml 檔案,分布式檔案系統的master,主從都是自己
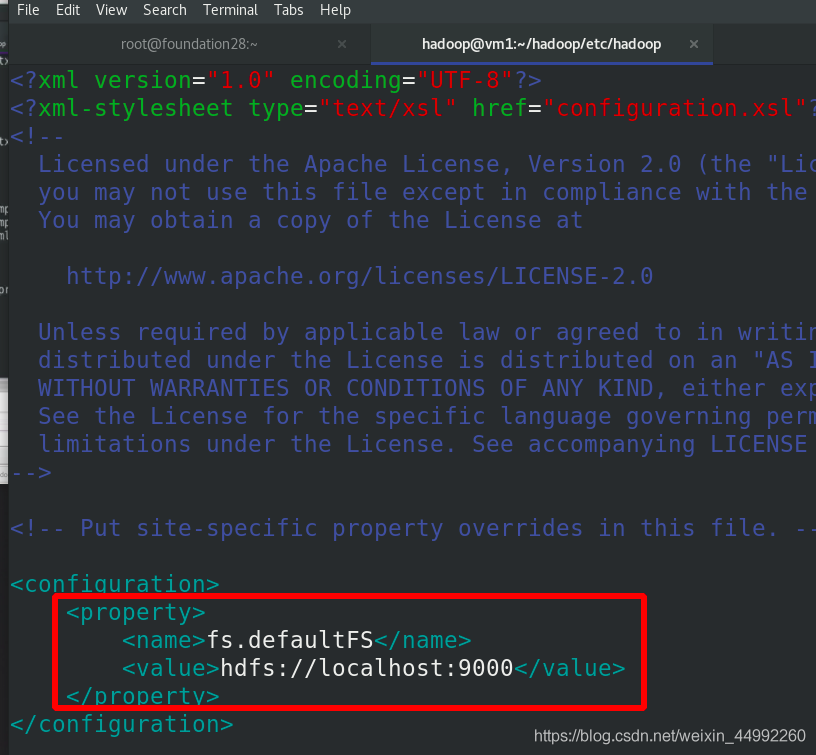
master和worker都是自己!!!
與localhost進行ssh免密
與localhost免密測驗
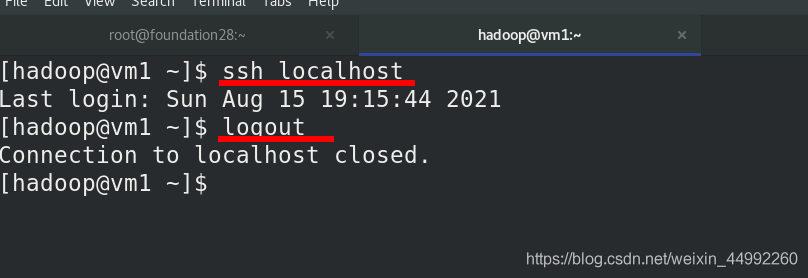
查看生成的公鑰和私鑰
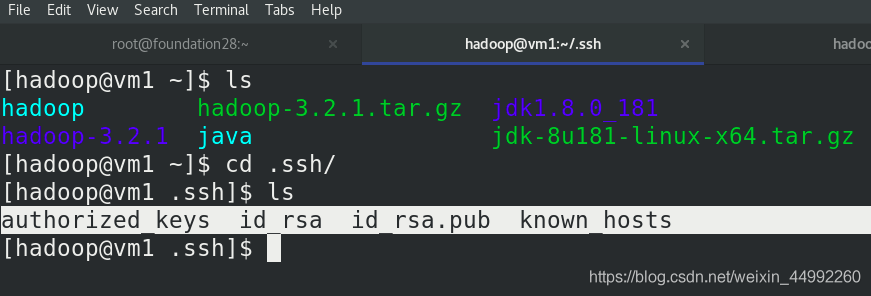
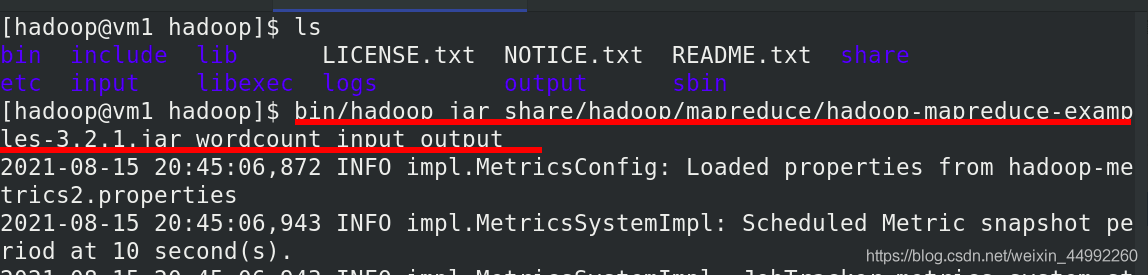
本地運行 MapReduce 作業
初始化檔案系統
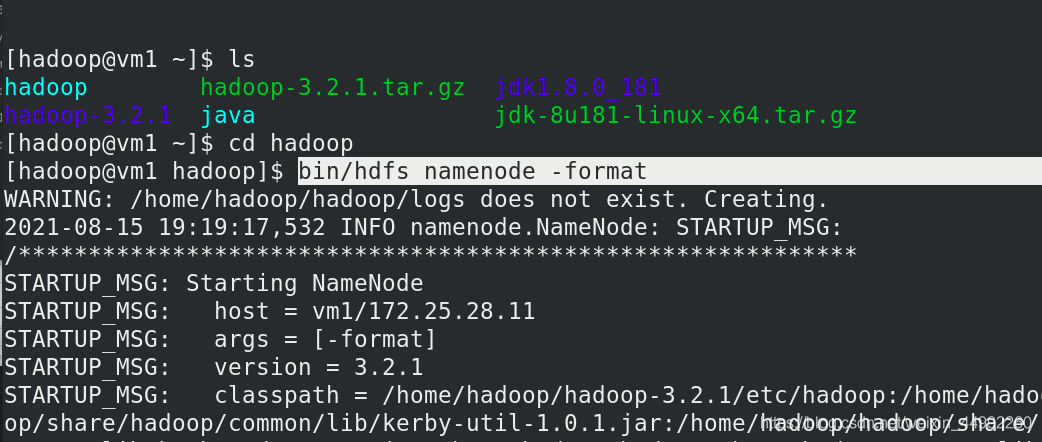
啟動 NameNode 守護行程和 DataNode 守護行程
namenode啟動master,datanode啟動worker
當前master和worker都是本機vm1 !!!
資料存盤位置:/tmp
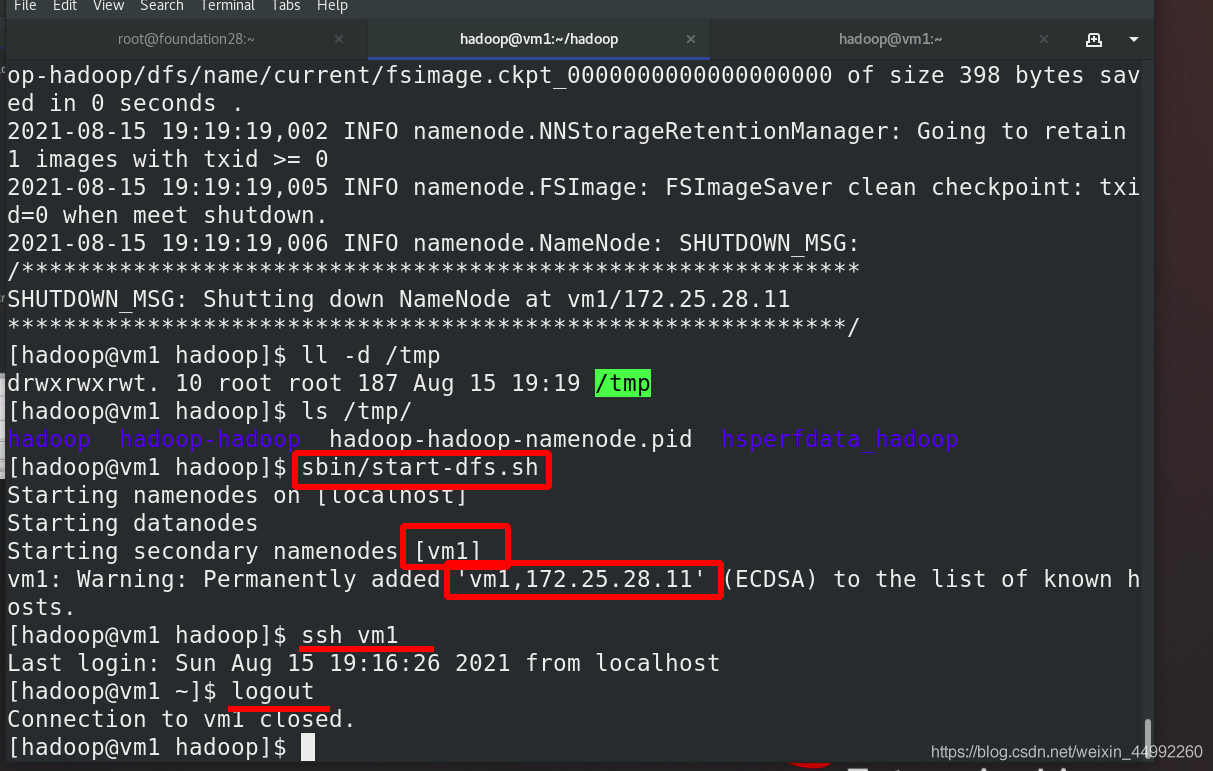
jps:java行程查看,代替ps ax
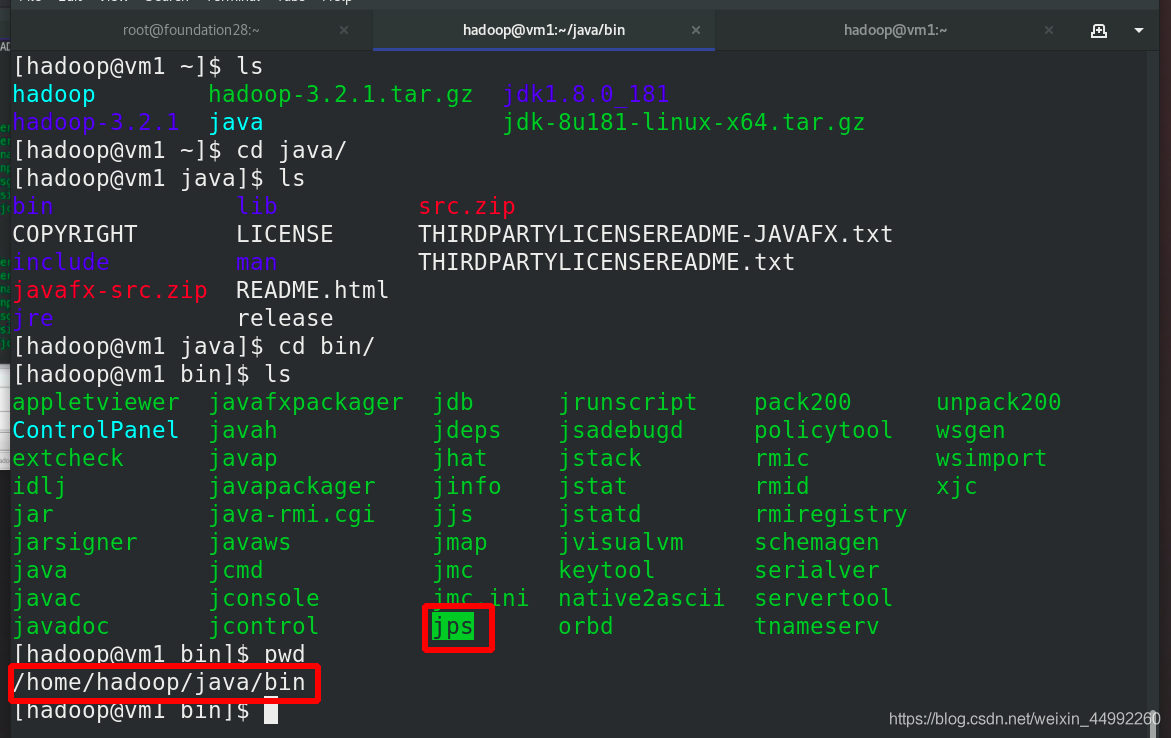
編輯java的環境變數
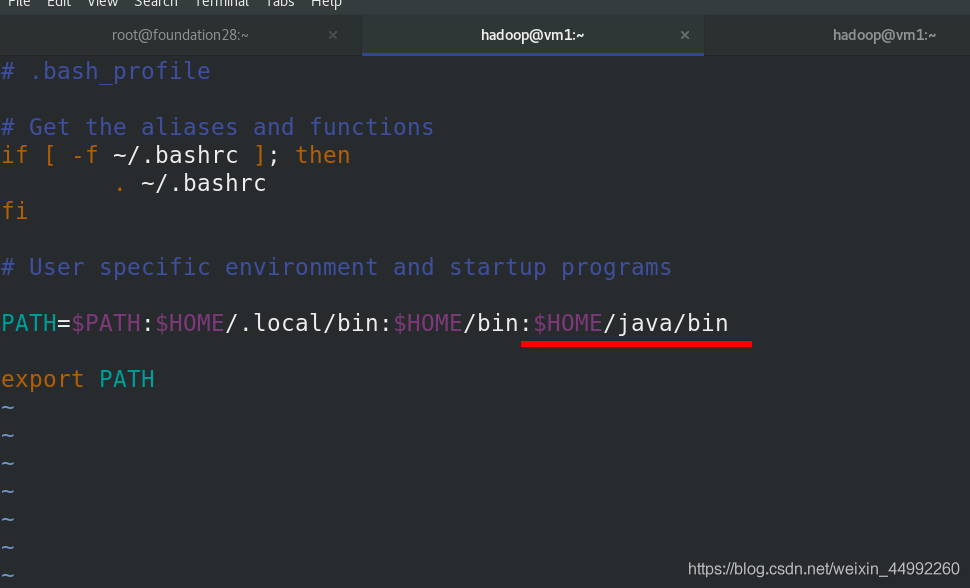
jps查看行程,其中secondnode表示當master的namenode down掉后,接管
由于hadoop的master和worker都是vm1,所以同時出現Namenode和DataNode !!!
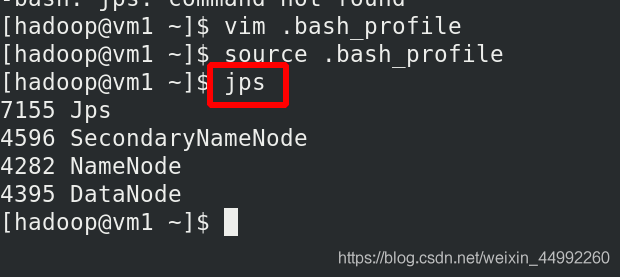
外部訪問:
172.25.28.11:9870
9870:hadoop默認的監聽埠
9000:Namenode和Datanode的連接埠
查看日志:
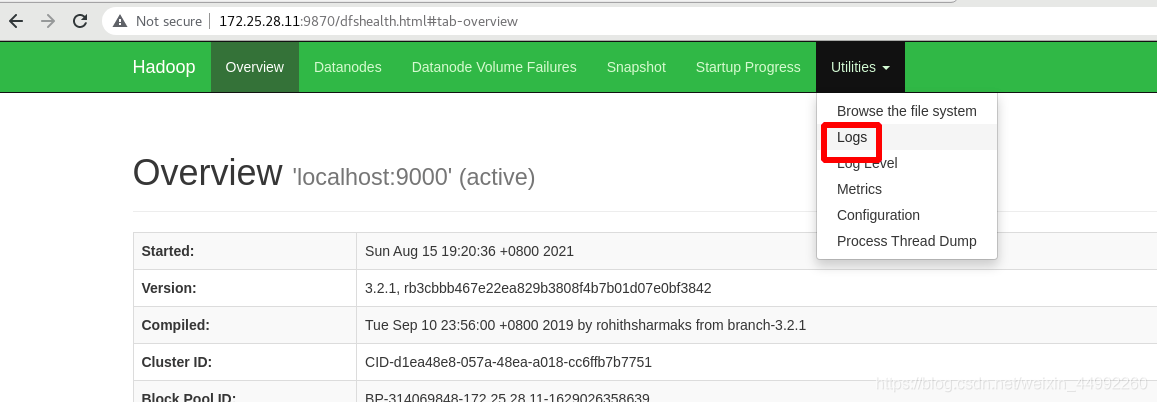
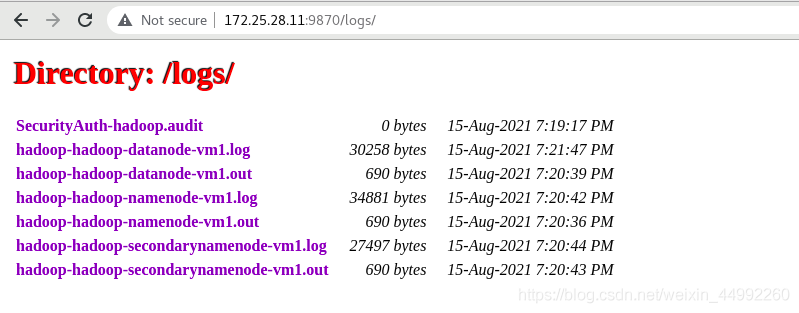
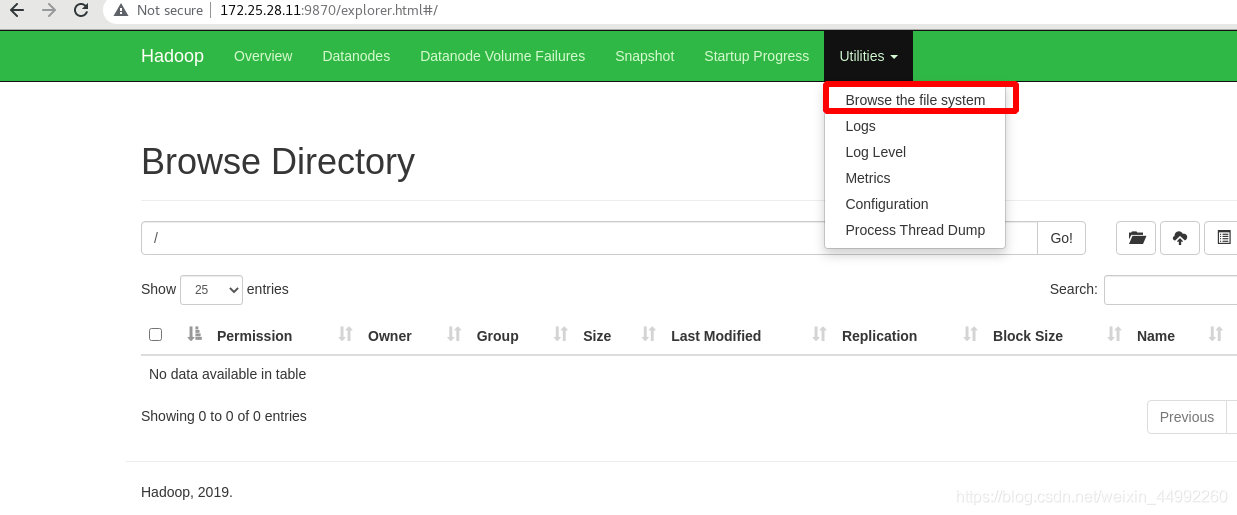
查看檔案系統,此時沒有內容:
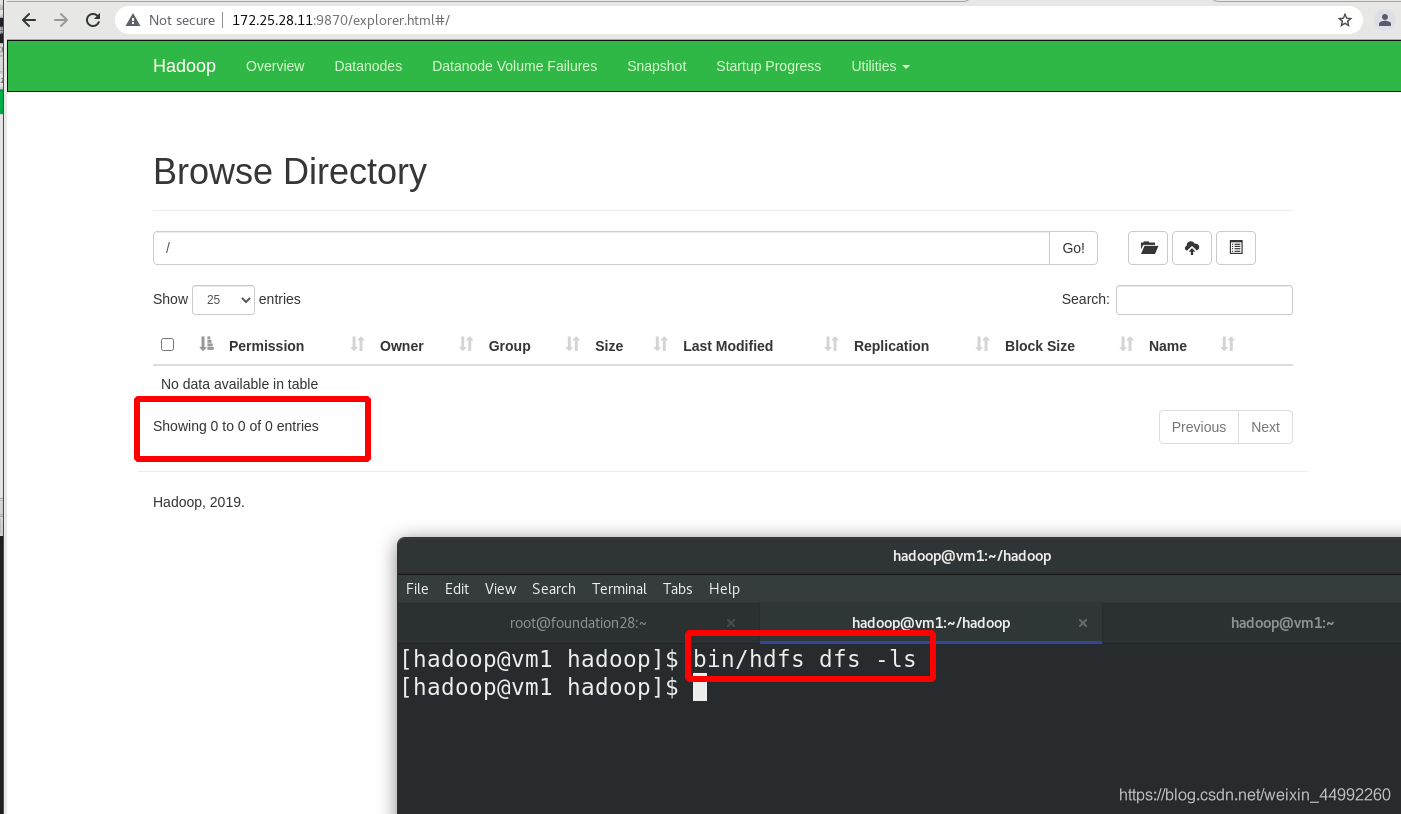
兩種方式:命令列和圖形化

創建執行 MapReduce 作業所需的 HDFS 目錄: 用戶與當前id保持一致

ls 默認查看的是這個目錄/user/haddop
將輸入檔案復制到分布式檔案系統中
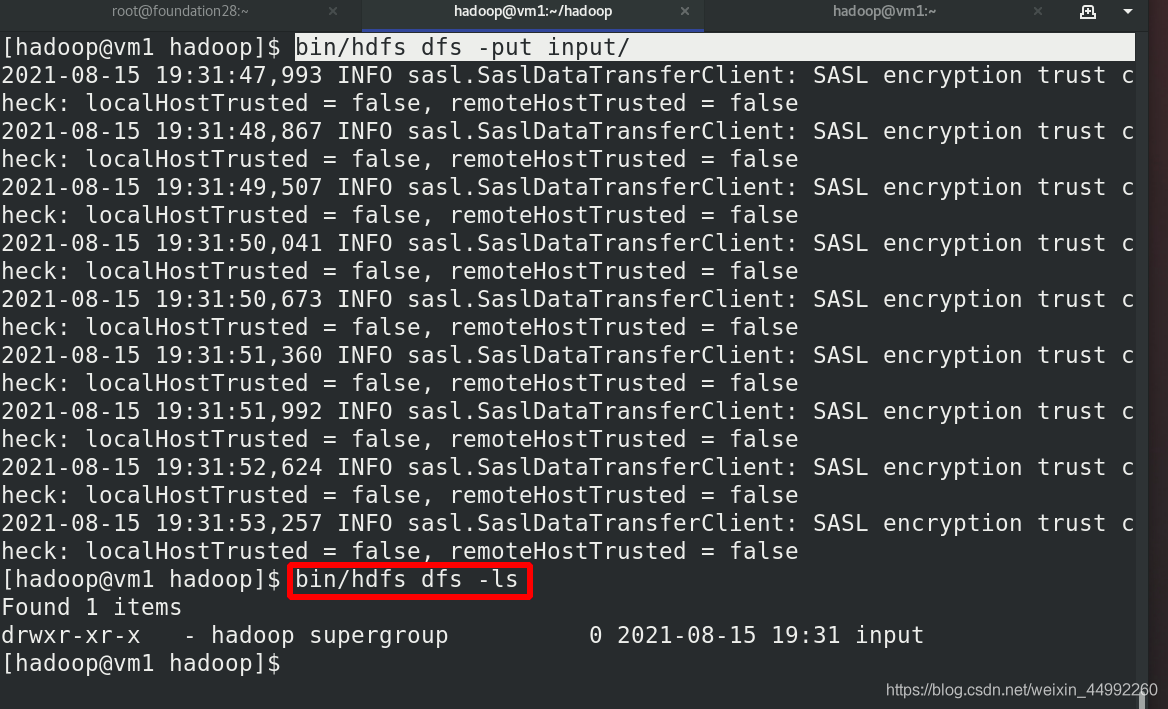
外部查看,存在(圖形化)
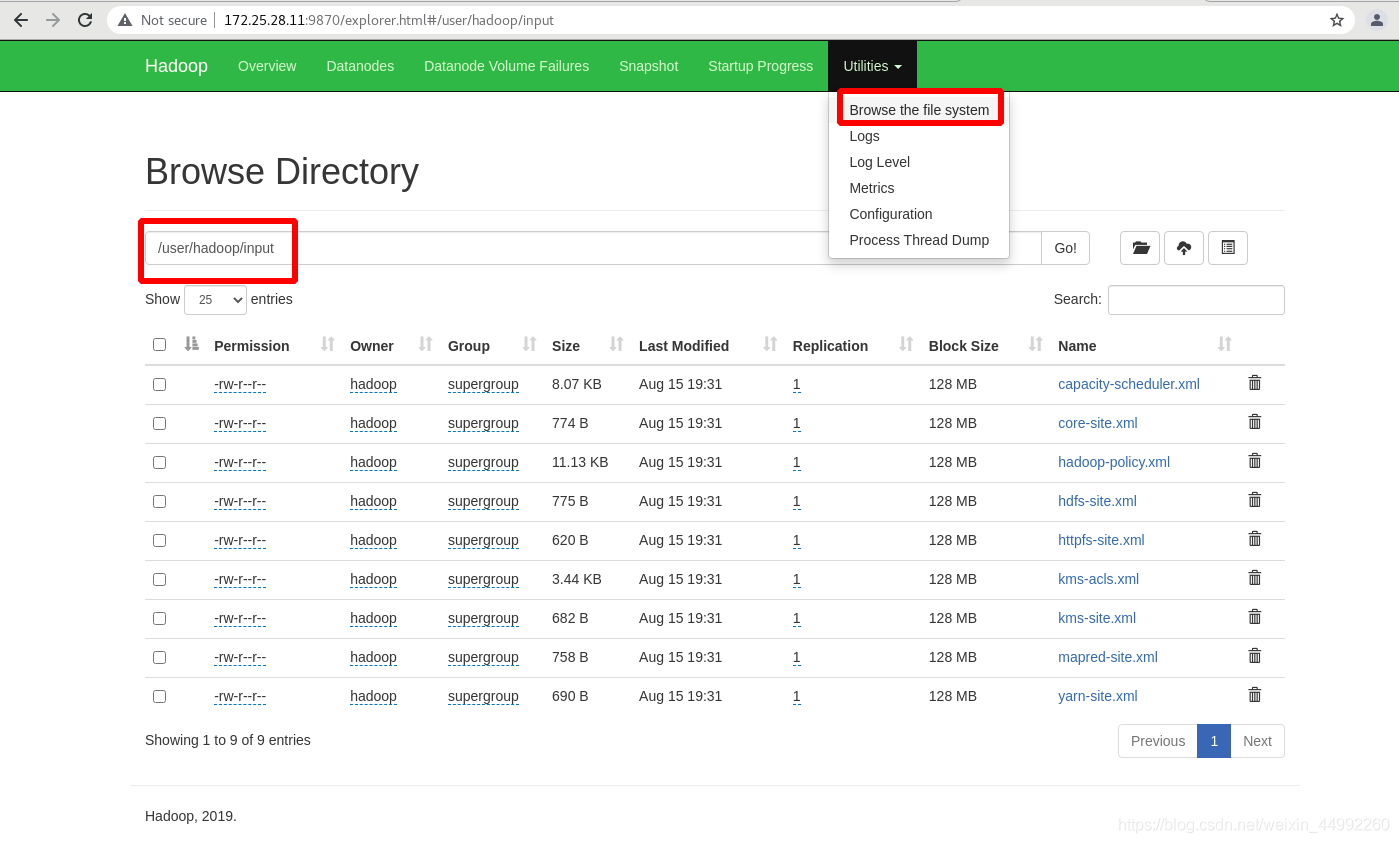
本地查看(命令列)
單詞數,
input,output :和本地無關,分布式中的輸入輸出目錄
本地查看
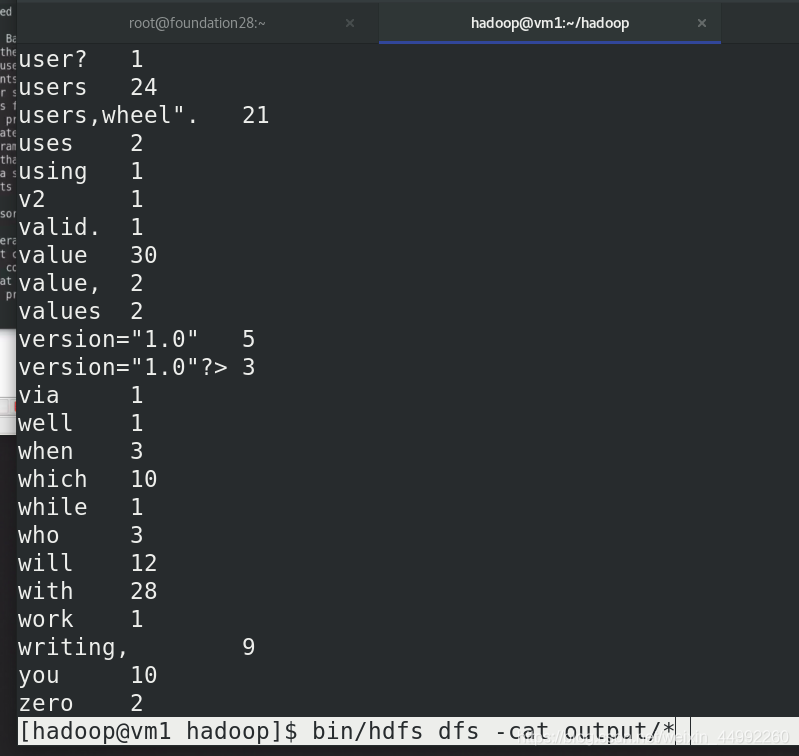
本地洗掉

此時查看,是分布式中的輸入輸出目錄
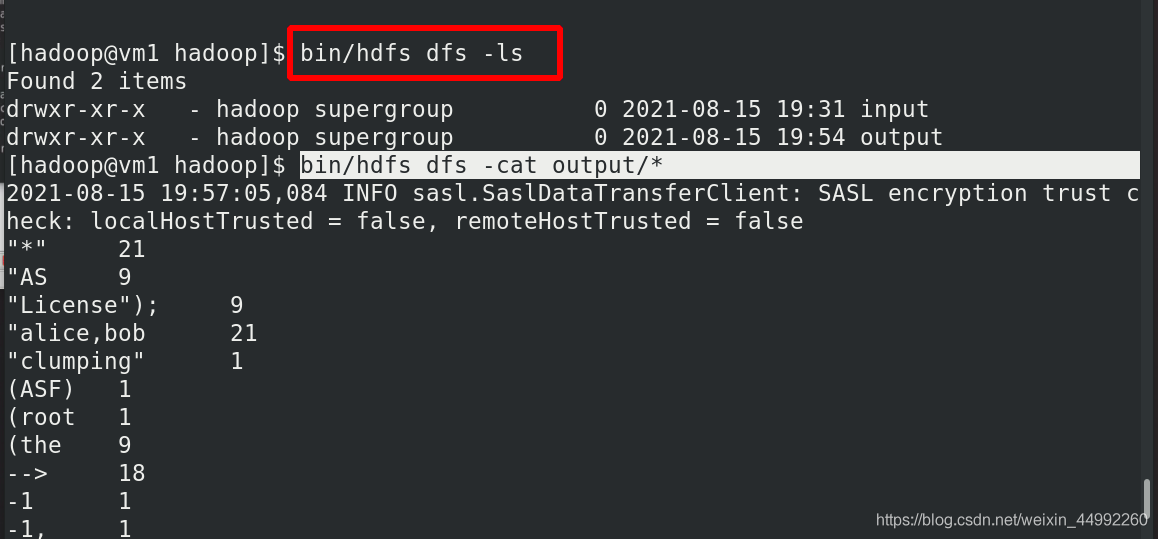
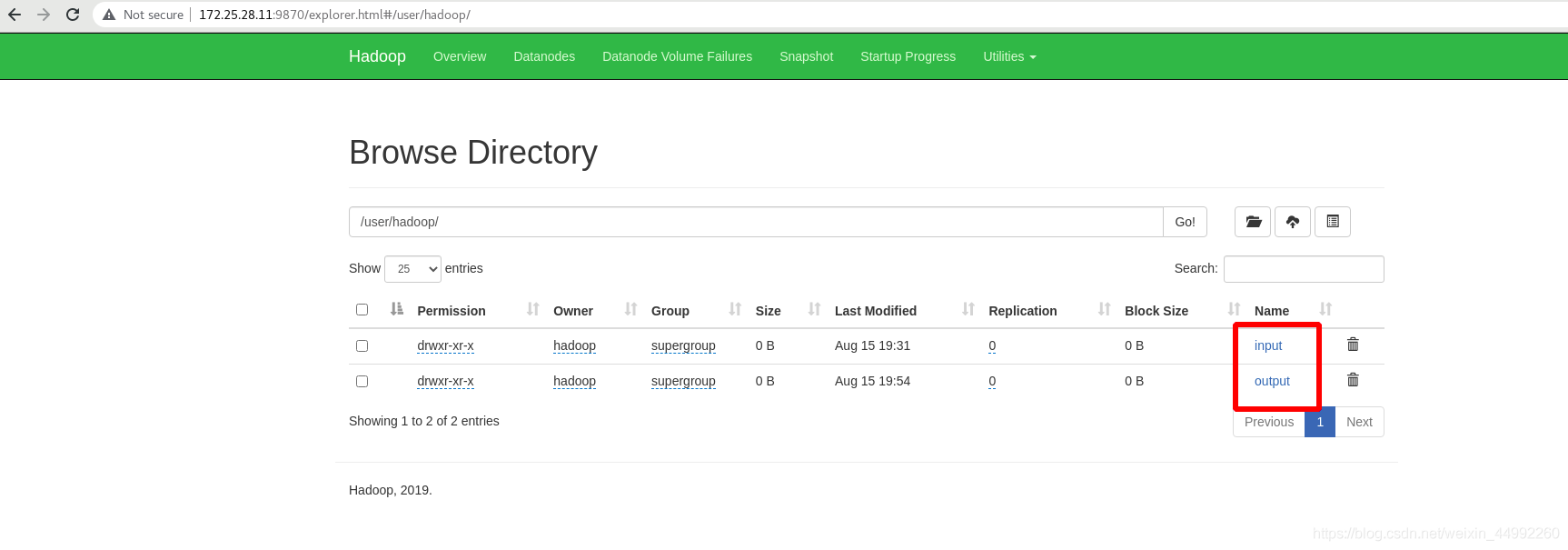
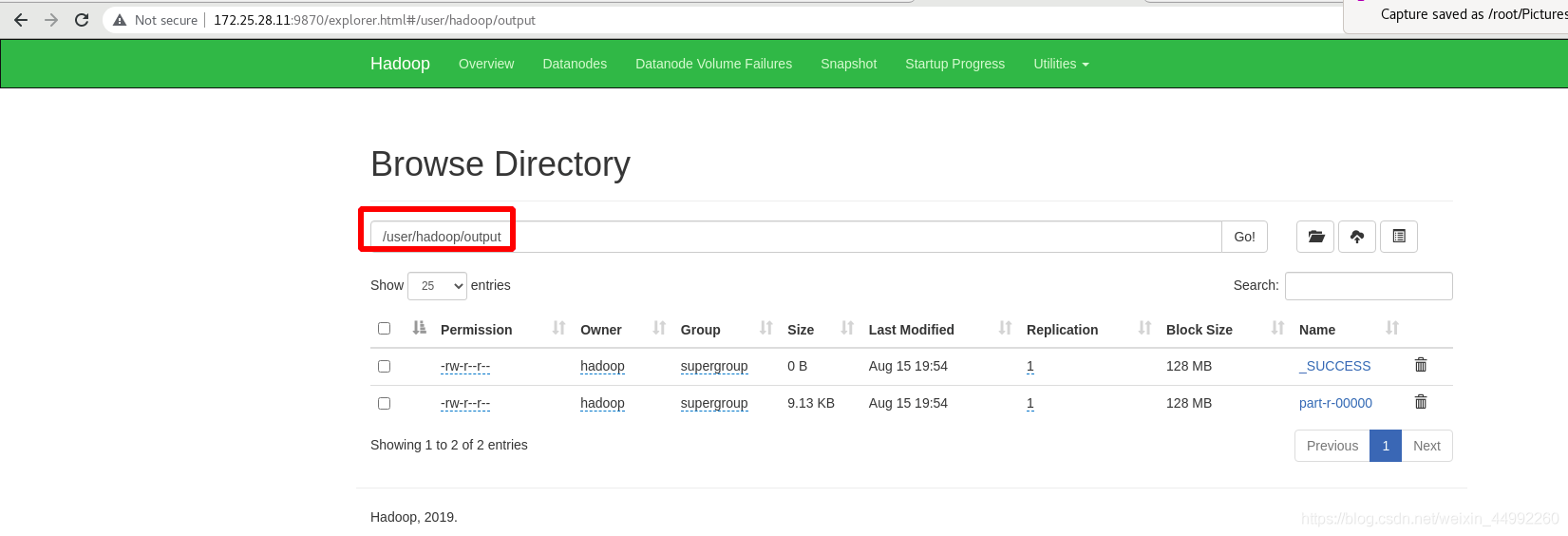
重新獲取分布式中的輸出目錄
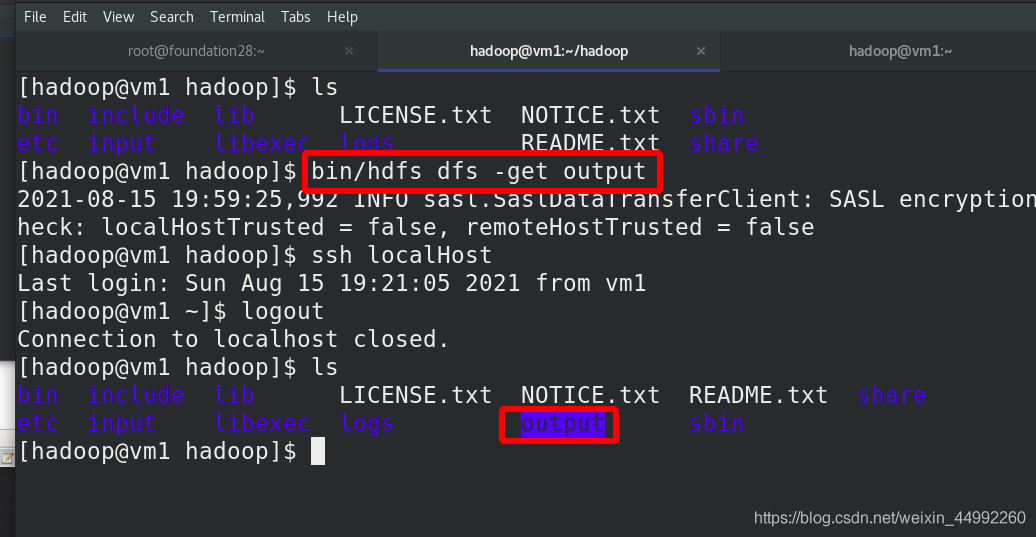
本地查看成功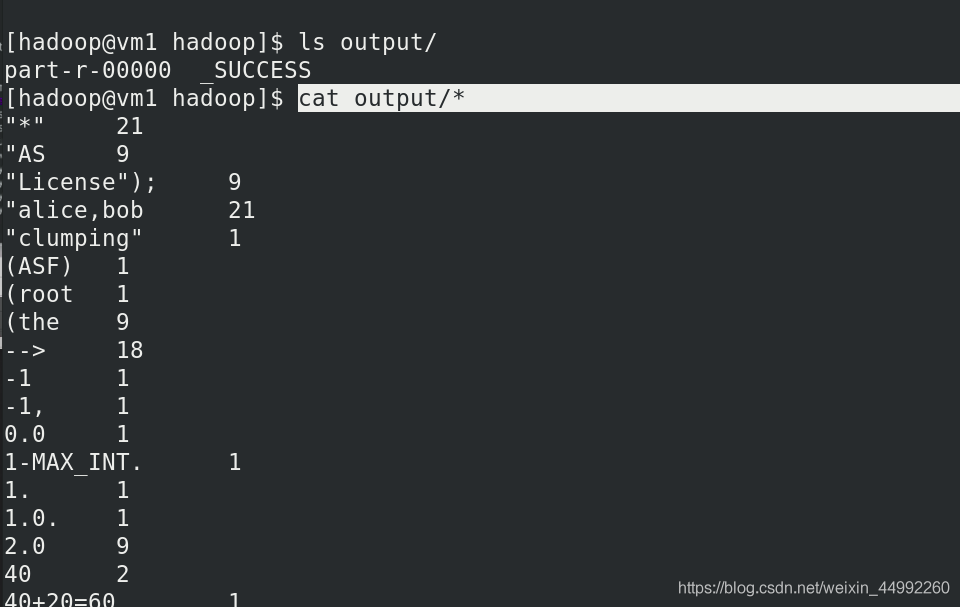
2 完全分布式
3臺虛擬機
實驗環境:
| 主機名 | ip | 功能 |
|---|---|---|
| vm1 | 172.25.28.11(2G) | master |
| vm2 | 172.25.28.12 | worker |
| vm3 | 172.25.28.13 | worker |
| vm4 | 172.25.28.14 | worker |
Nn和Dn分離
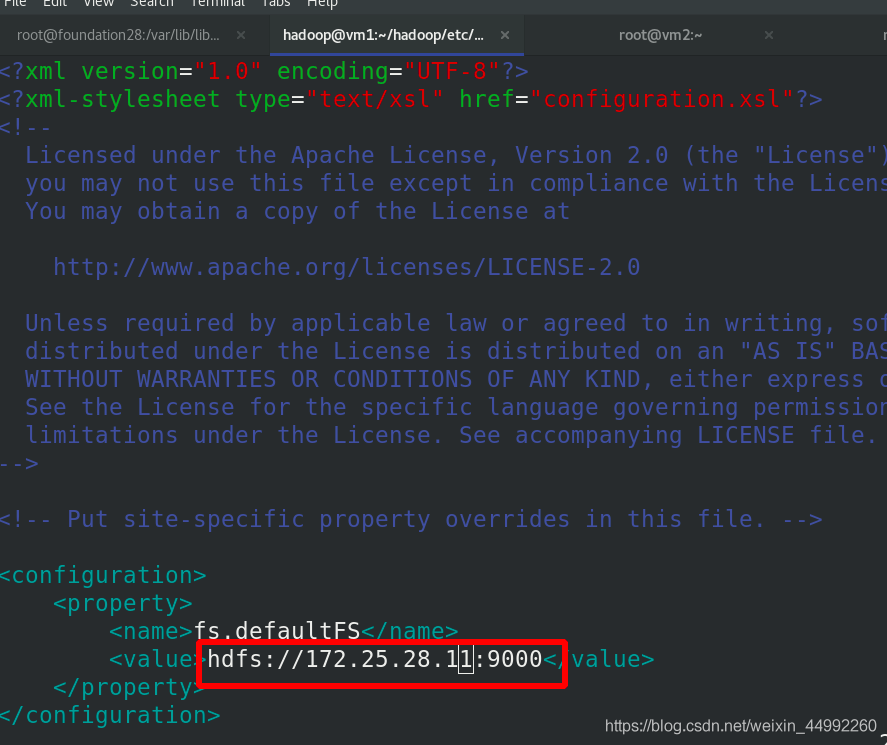
編輯 etc/hadoop/core-site.xml 檔案,修改master為vm1的ip
編輯 etc/hadoop/hdfs-site.xml 檔案,副本數為2
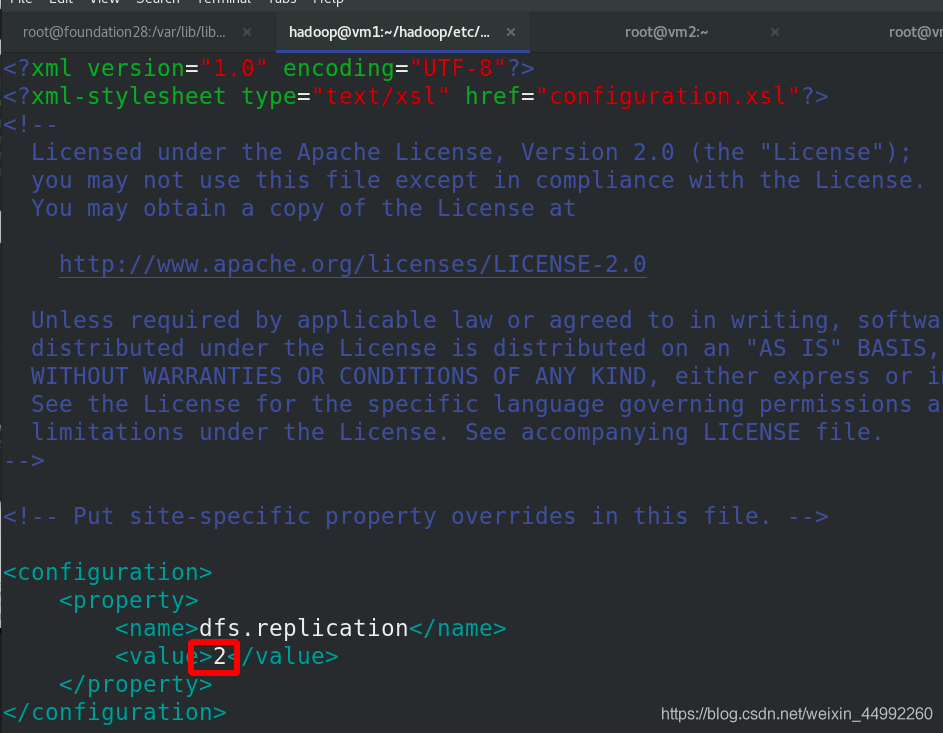
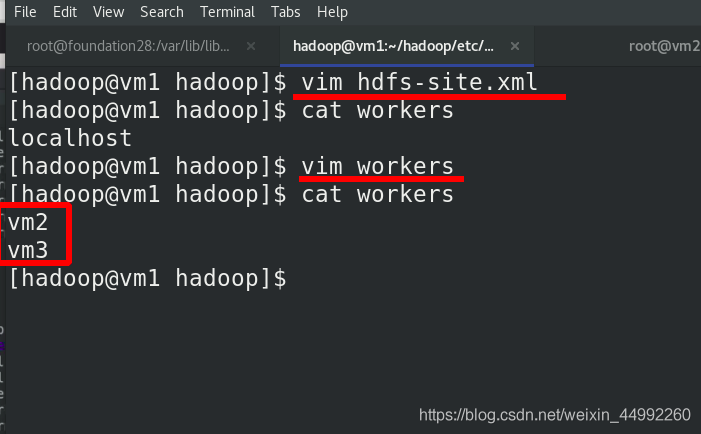
修改worker為vm2和vm3
vm1安裝nfs檔案系統,
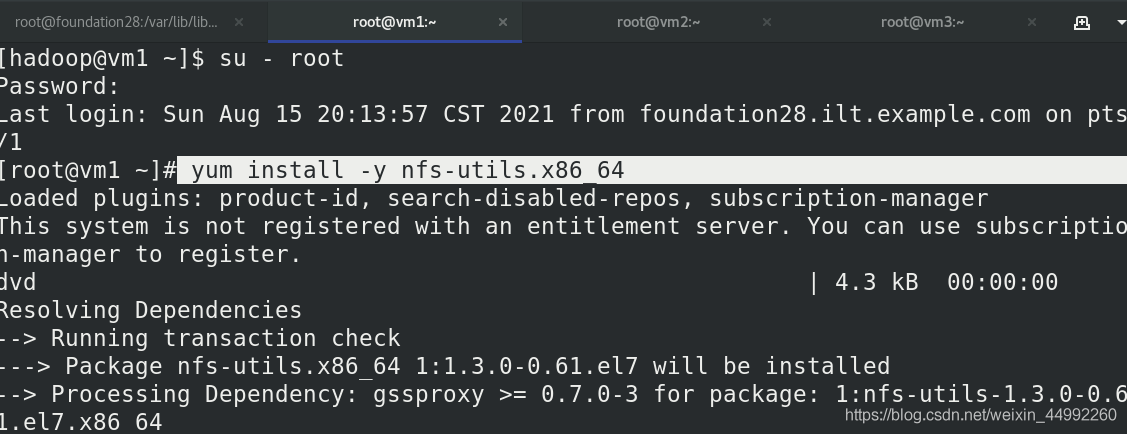
修改檔案,啟動nfs服務
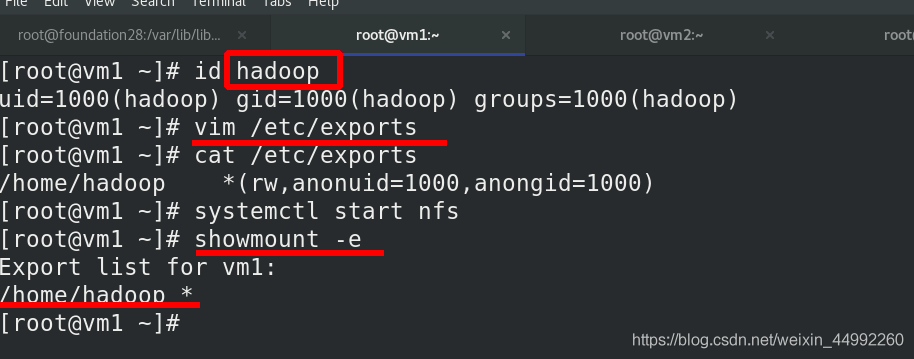
vm2新建hadoop用戶,安裝nfs檔案系統
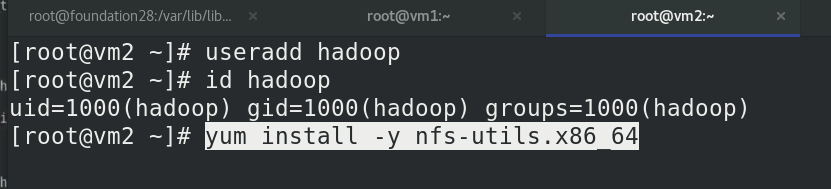
vm3新建hadoop用戶,安裝nfs檔案系統

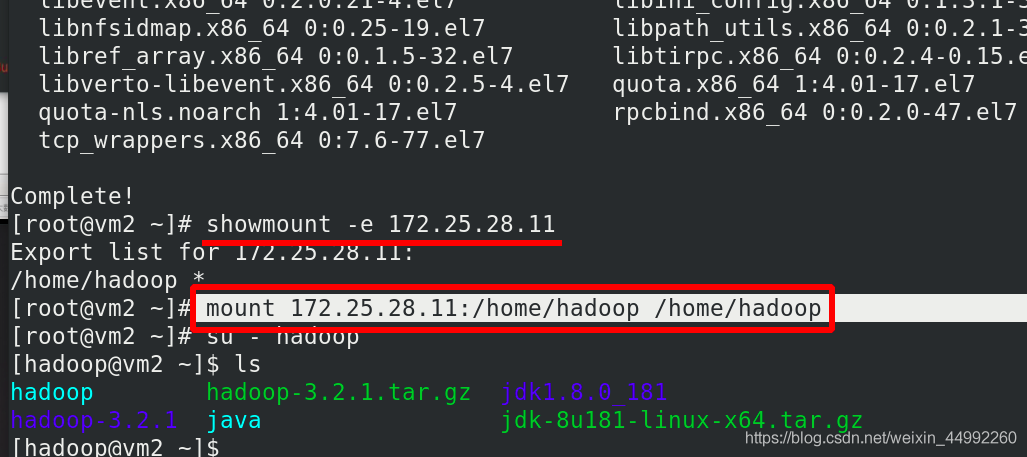
掛載nfs到vm2中的/home/hadoop
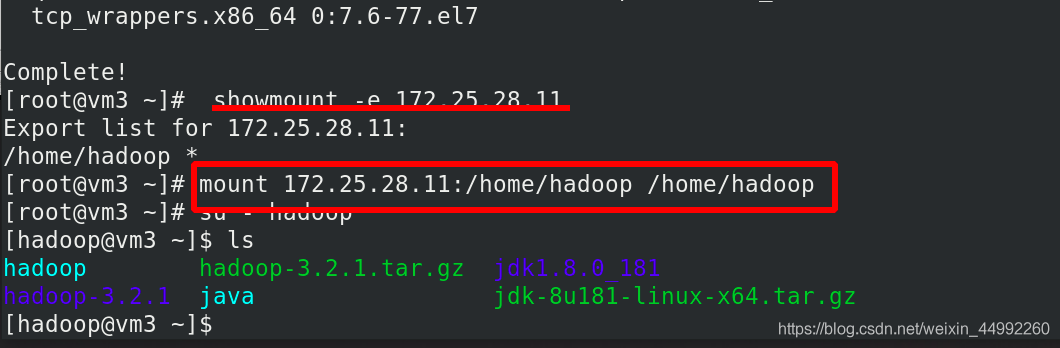
掛載nfs到vm3中的/home/hadoop
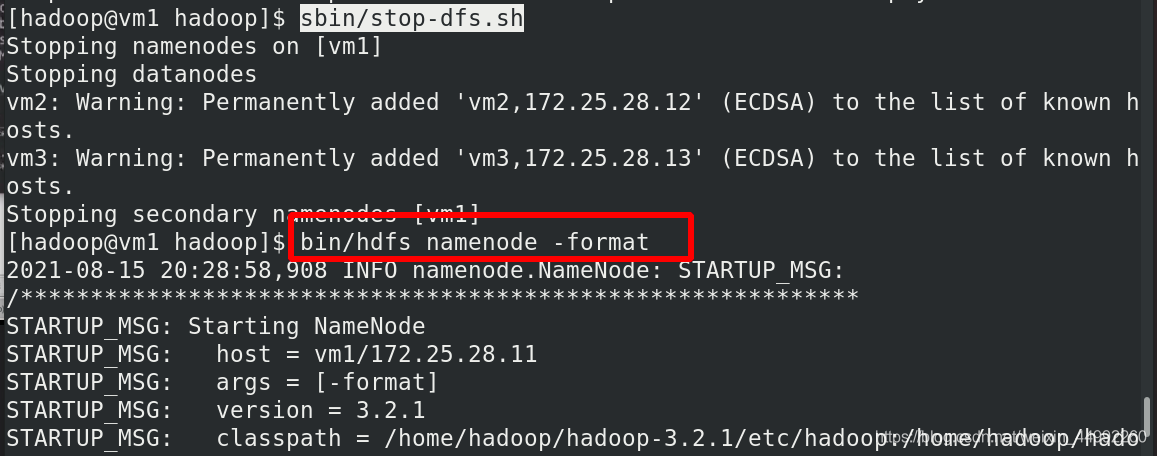
重新初始化檔案系統,先stop
測驗免密連接
外部訪問:
172.25.28.11:9870
9870:hadoop默認的監聽埠
此時vm2和vm3已成功加入
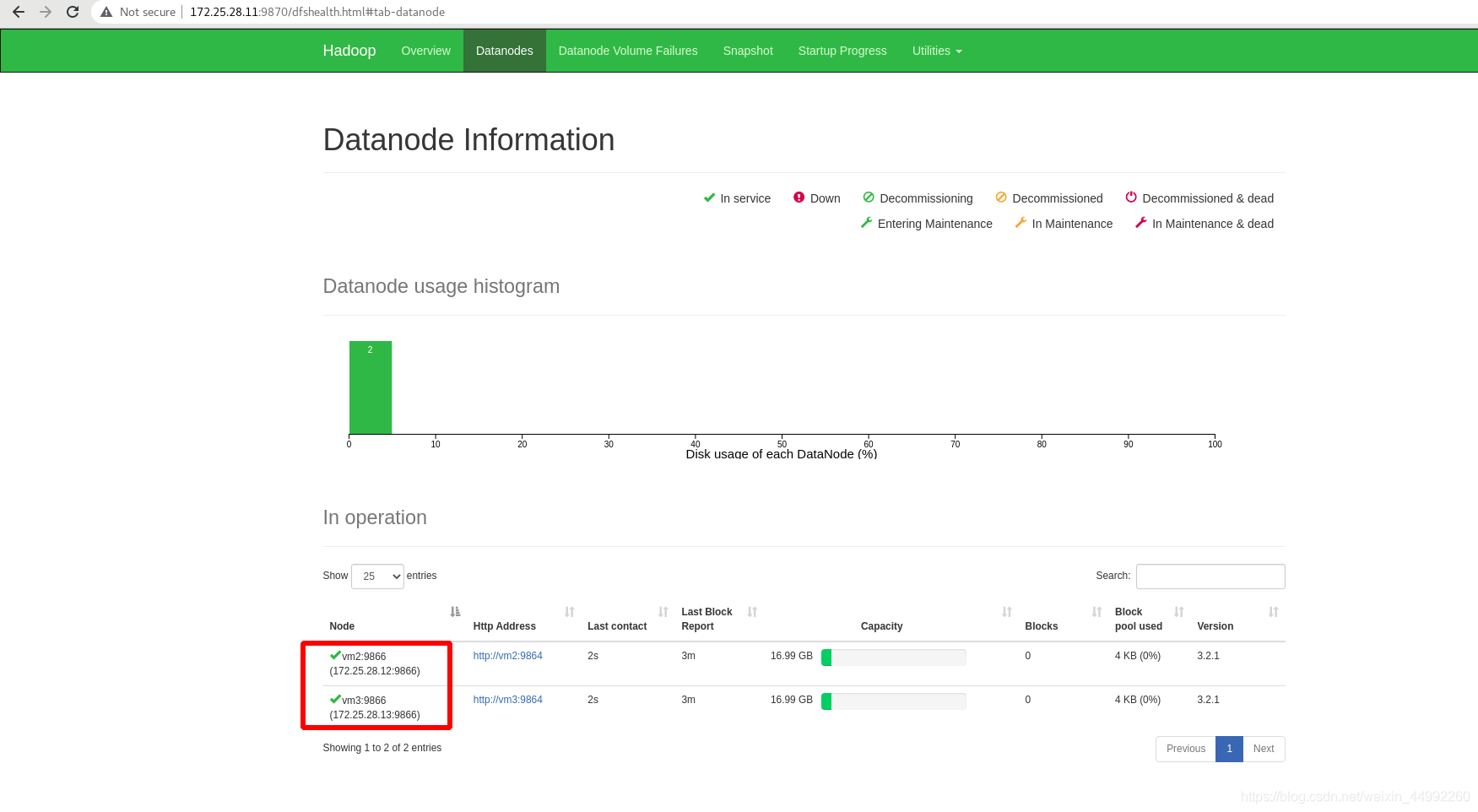
vm2和vm3上,jps查看行程,都有DataNode!!!

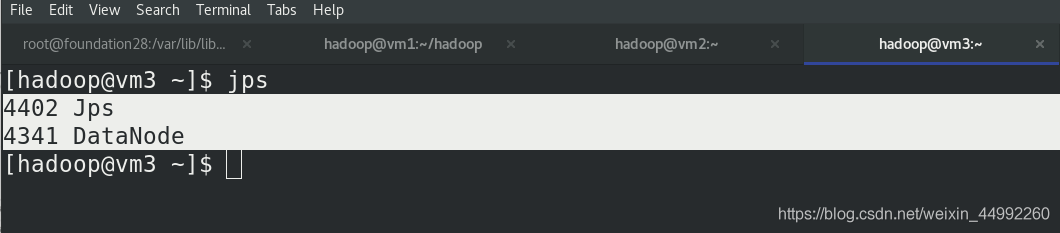
vm1上啟動 NameNode 守護行程,此時vm1是沒有Datanode,只有Namenode,此處由于版本問題,vm1作為master,Nn是只保留原始資料,不存盤資料
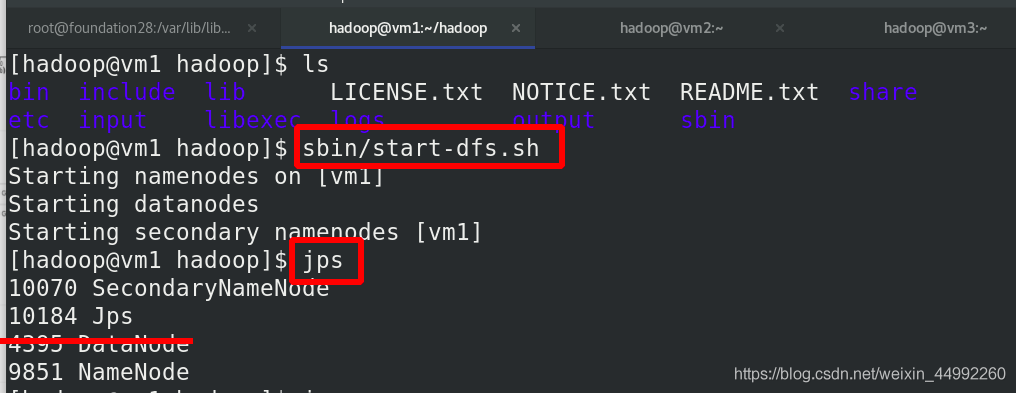
外部訪問,查看檔案系統
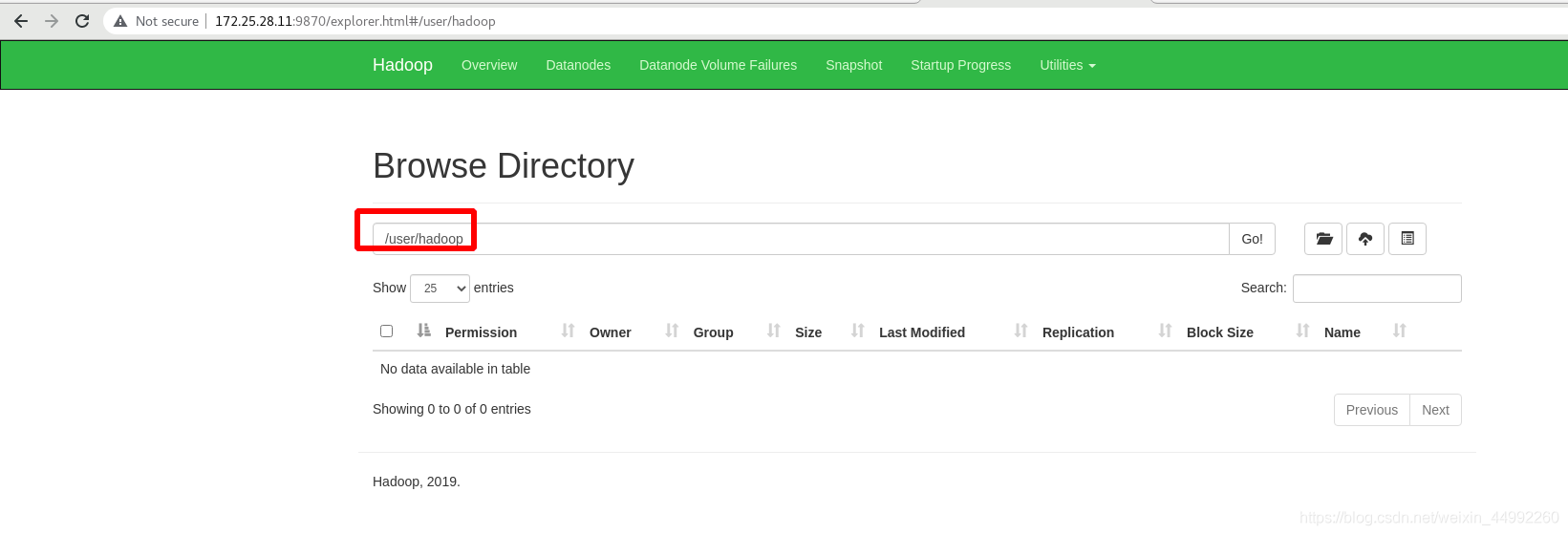
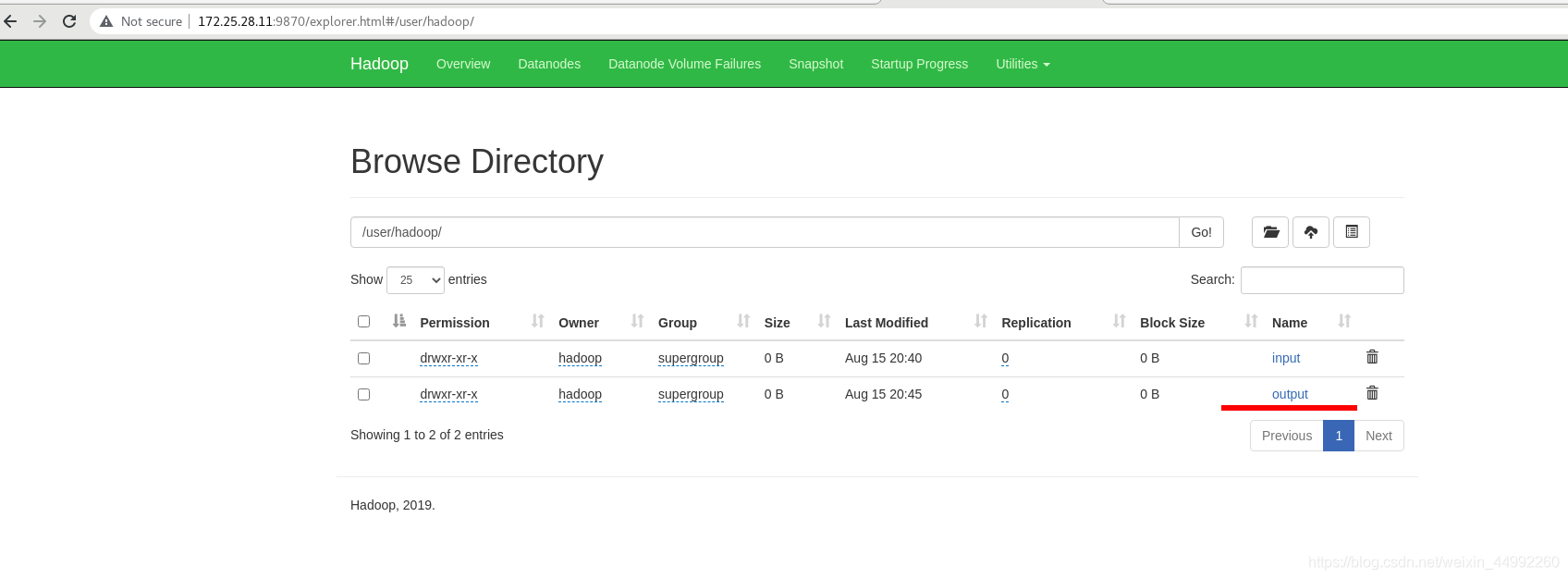
上傳input目錄至分布式檔案系統中
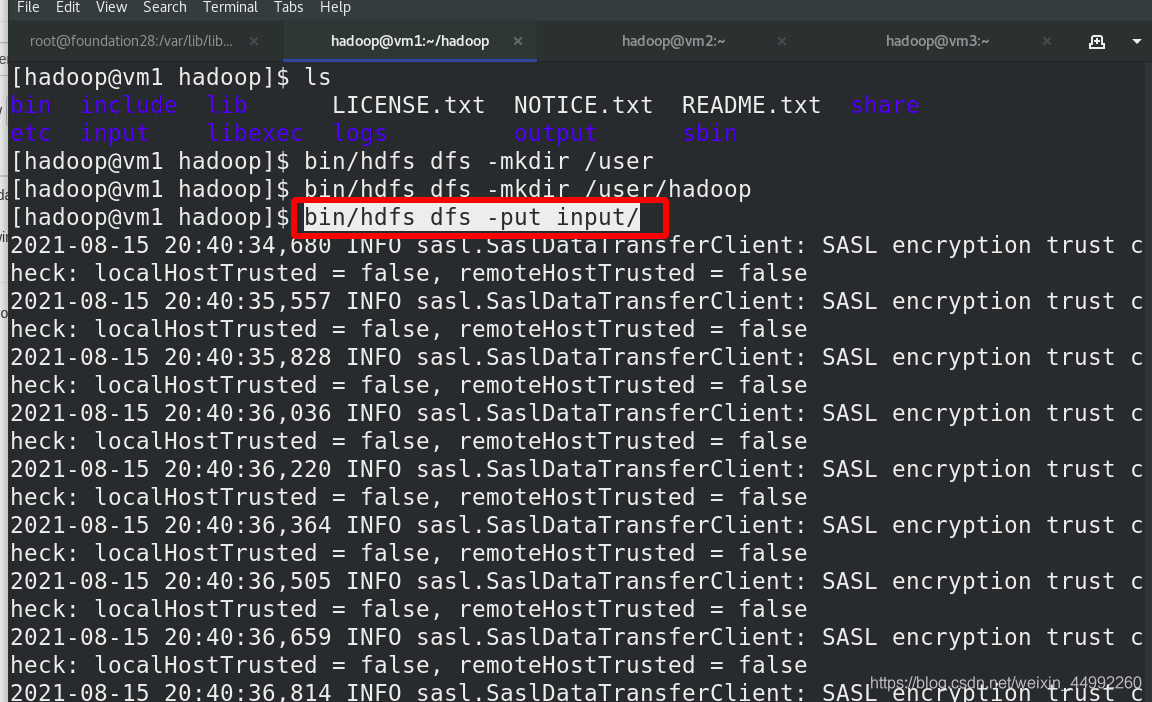
外部再次查看
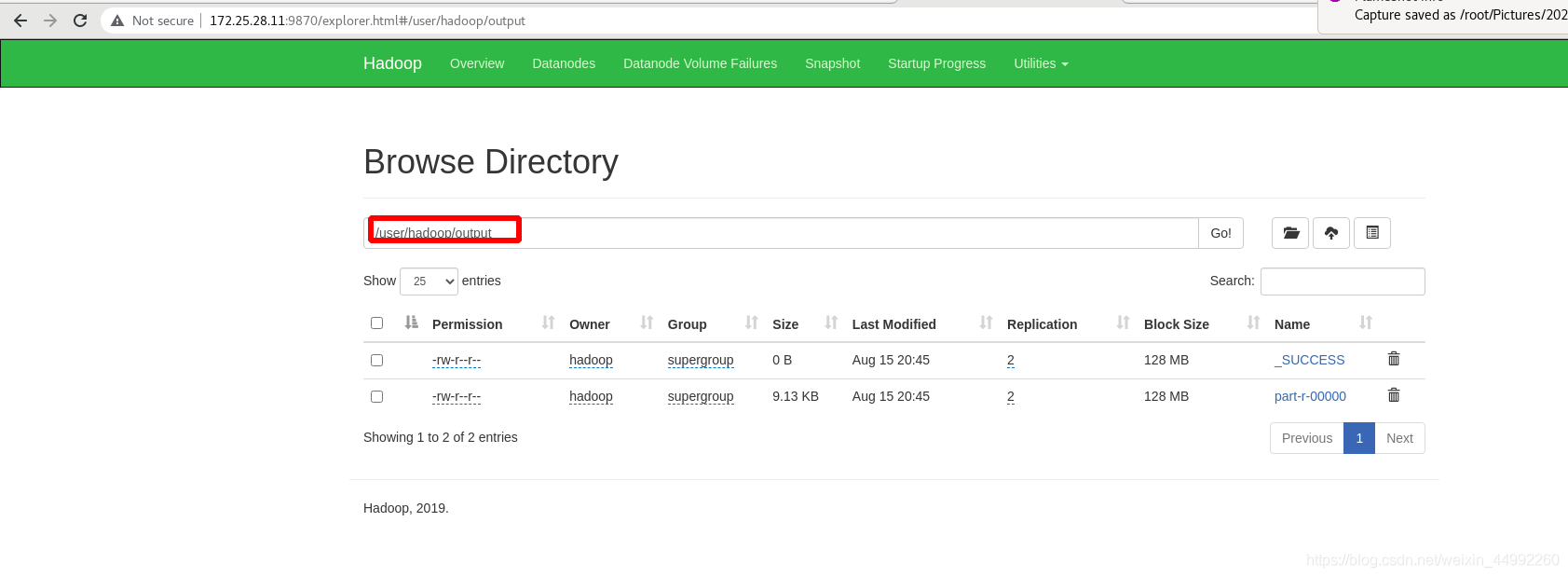
單詞數,
input,output :和本地無關,分布式中的輸入輸出目錄
外部查看:分布式中的輸出目錄
將vm1加入此分布式中:
安裝nfs,掛載,編輯worker檔案
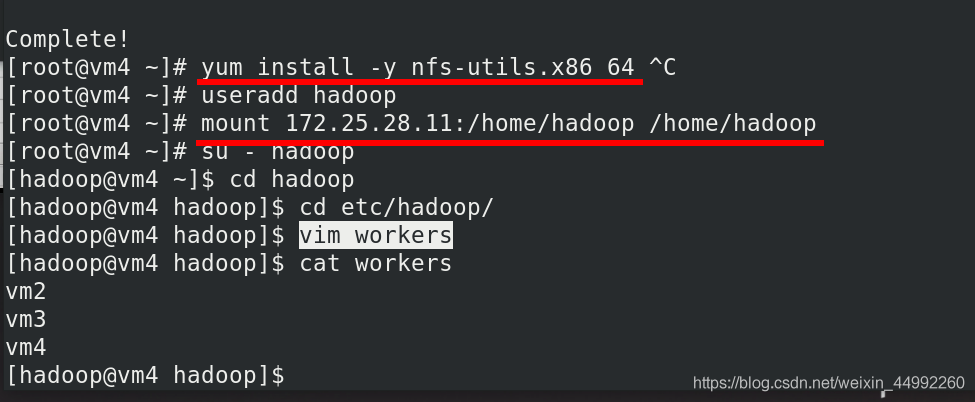
vm4啟動namenode,jps查看java行程,已經出現Datanode

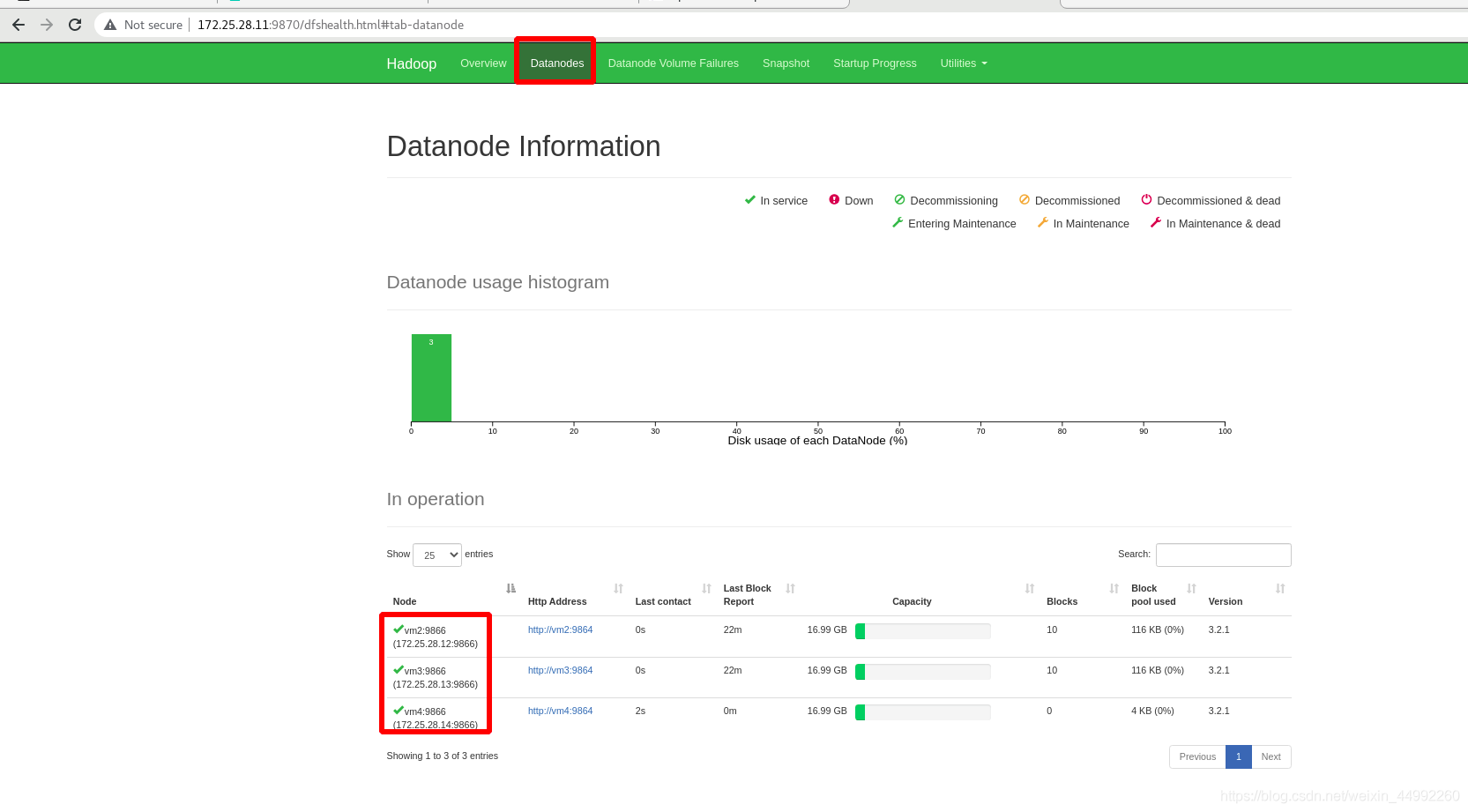
外部查看:vm4已經成功加入此分布式!!!
三. yarn 調度
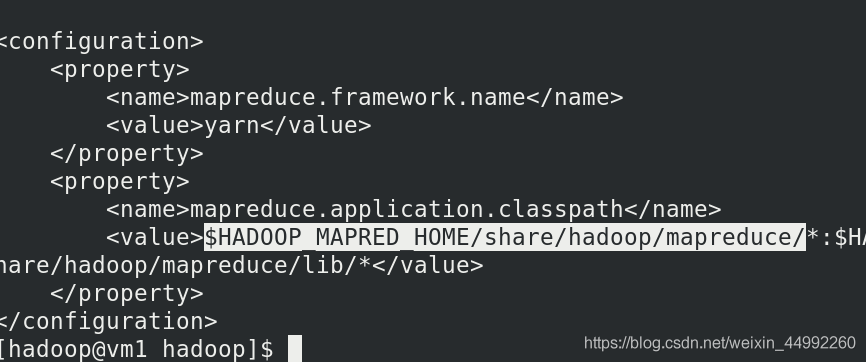
編輯etc/hadoop/mapred-site.xml:檔案
編輯etc/hadoop/yarn-site.xml檔案
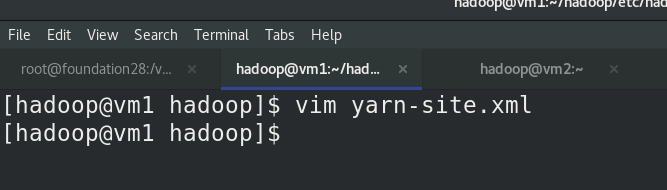
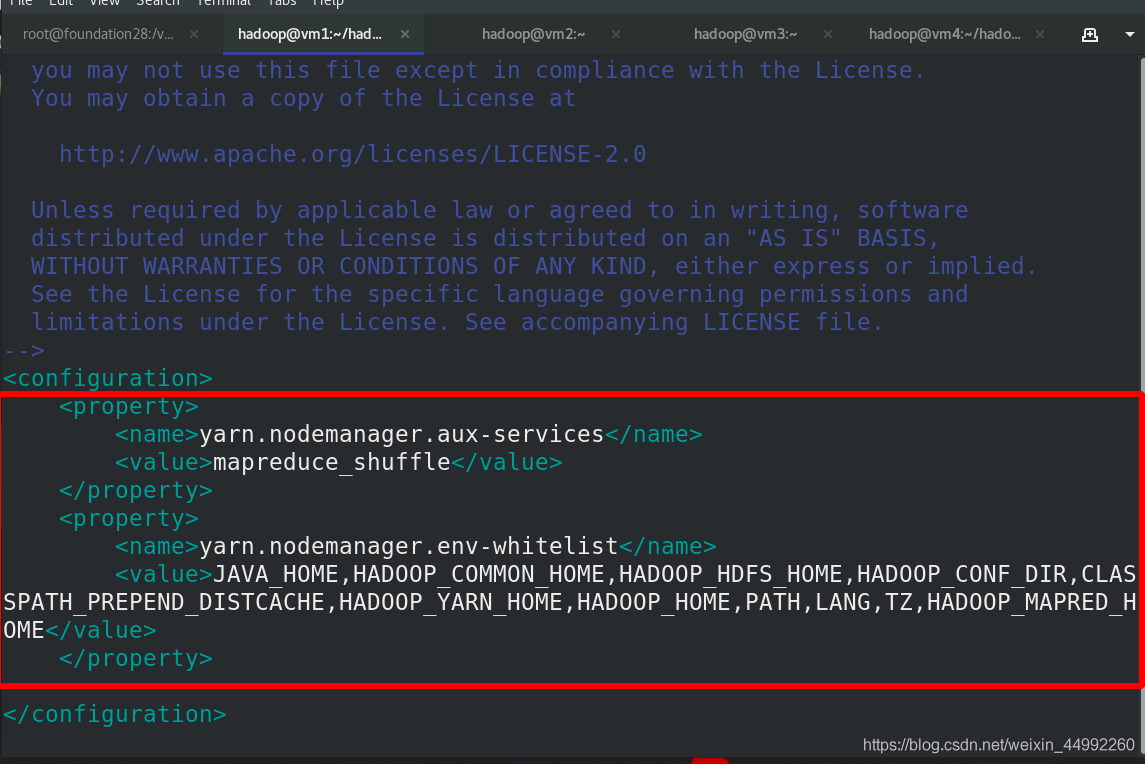
編輯環境變數,加入$HADOOP_HOME

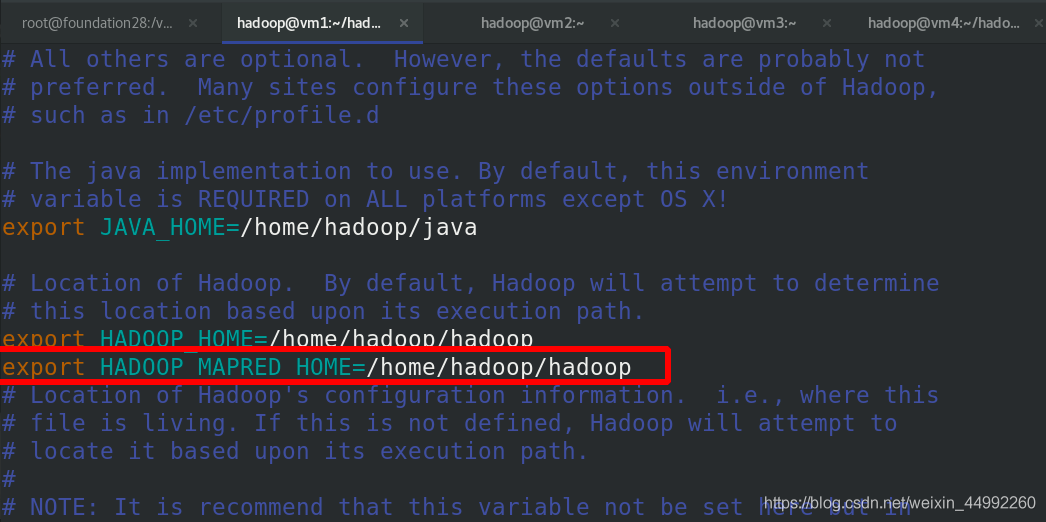
$HADOOP_HOME 就是 /home/hadoop/hadoop/share/hadoop/mapreduce
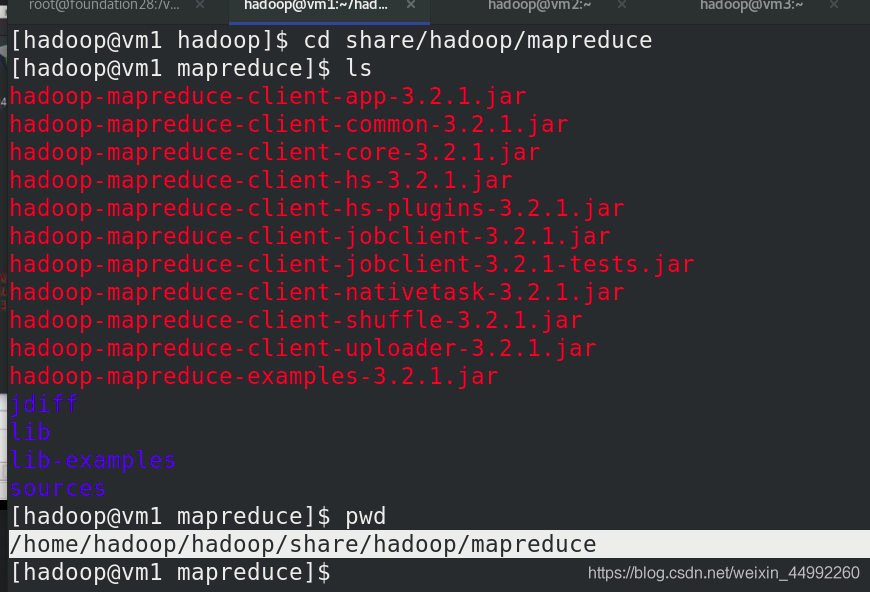
啟動 ResourceManager 行程和 NodeManager 行程
vm1上有ResourceManager 行程
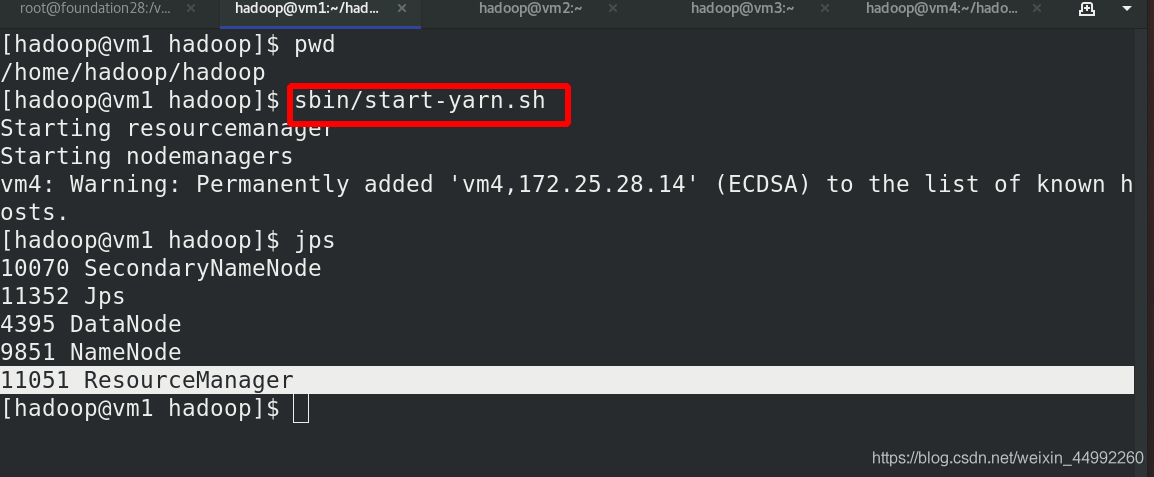
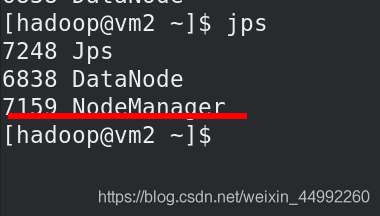
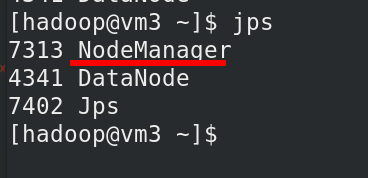
vm 2,3,4 有 NodeManager 行程
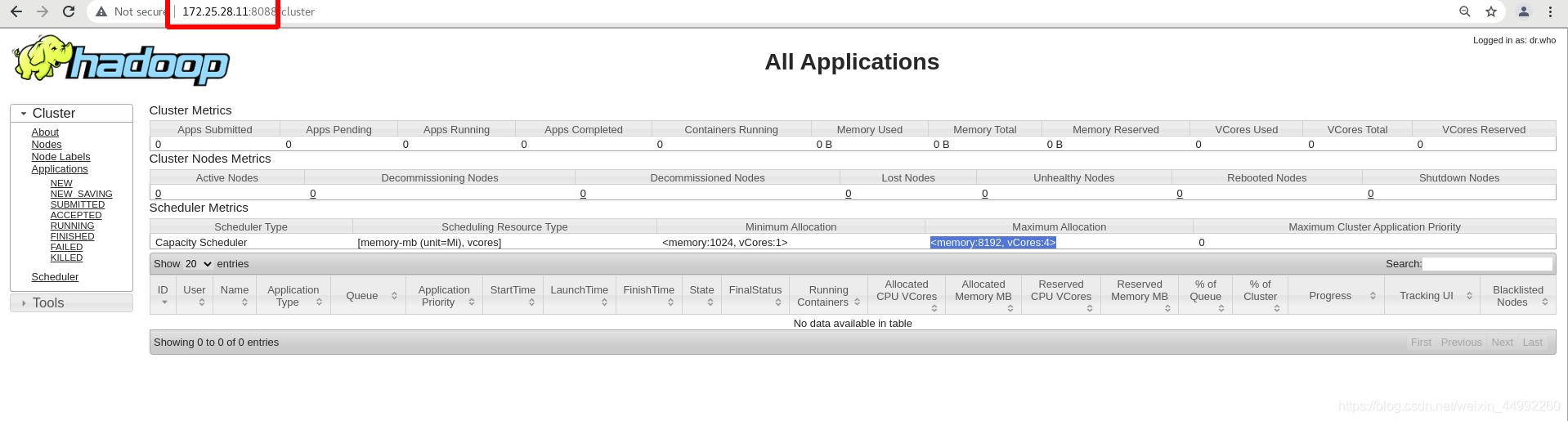
外部訪問:
172.25.28.11:8088
調度記憶體消耗較大
四. hadoop高可用
參考pdf:/pub/docs/hadoop
實驗環境:
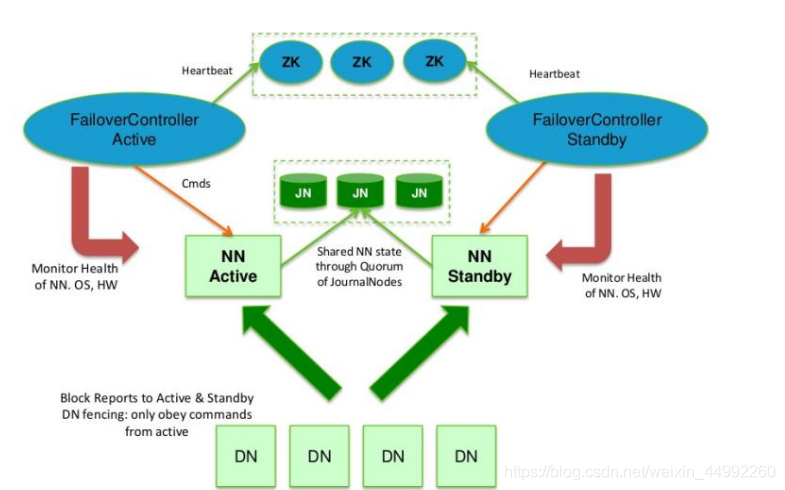
ZK(3); JN(3); 雙機熱備;(NN主備模式2); DN(4)
在典型的 HA 高可用集群中,通常有兩臺不同的機器充當 NN,在任何時間,只有一臺機器處于Active 狀態;另一臺機器是處于 Standby 狀態,Active NN 負責集群中所有客戶端的操作;而 Standby NN 主要用于備用,它主要維持足夠的狀態,如果必要,可以提供快速的故障恢
復,
| 主機名 | ip | 功能 |
|---|---|---|
| vm1 | 172.25.28.11(2G) | (Namenode)master,雙機熱備的主Active |
| vm2 | 172.25.28.12 | (Datanode)worker, zookeeper,JN |
| vm3 | 172.25.28.13 | (Datanode)worker, zookeeper,JN |
| vm4 | 172.25.28.14 | (Datanode)worker, zookeeper,JN |
| vm5 | 172.25.28.15 | (Namenode)master,雙機熱備的備Standby |
為了讓 Standby NN 的狀態和 Active NN 保持同步,即元資料保持一致,它們都將會和JournalNodes 守護行程通信,
1 zookeeper集群
所有主機停止


/tmp資料全部洗掉
vm5 安裝nfs,掛載,新建hadoop用戶
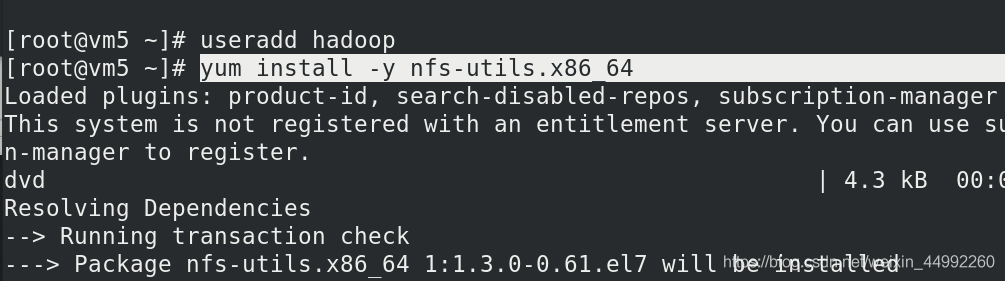
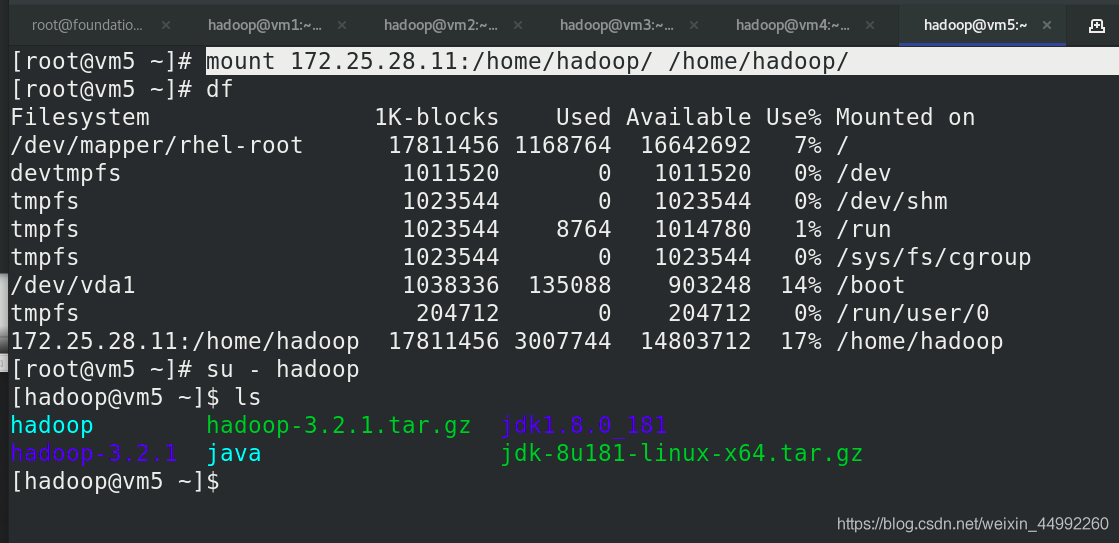 安裝 JDK
安裝 JDK
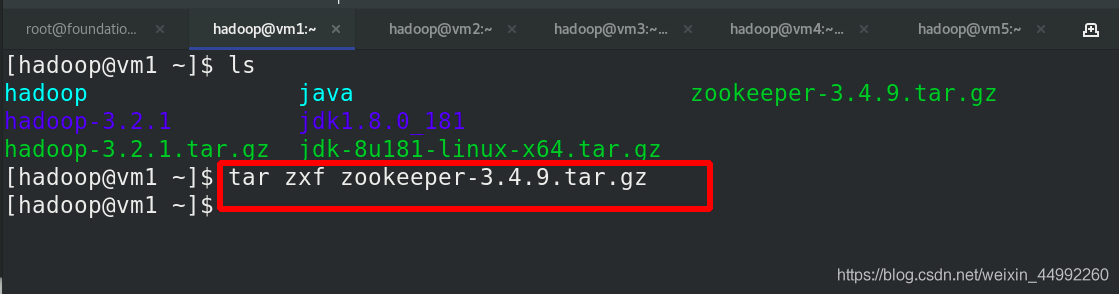
安裝 zookeeper
解壓縮zookeeper包
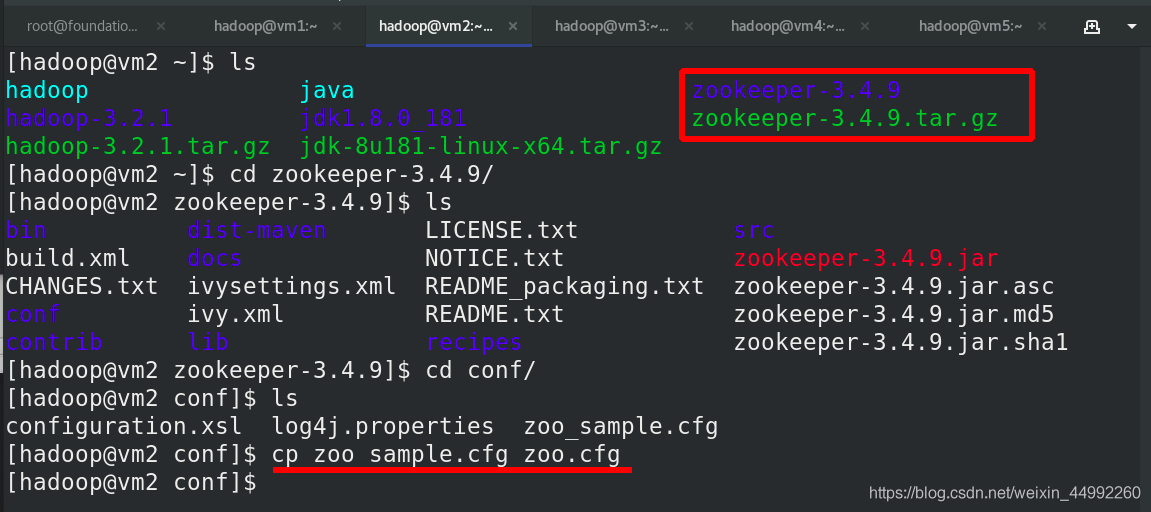
編輯 zoo.cfg 檔案,各節點組態檔相同,(已經掛載)
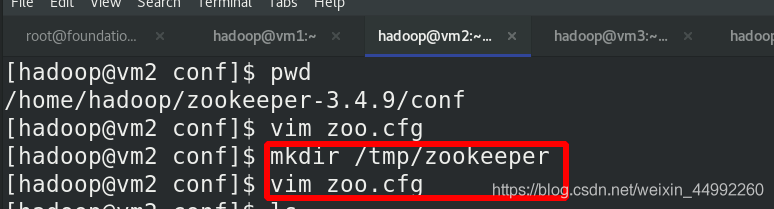
2888(資料同步)和38888(選舉的)通信埠
需要在/tmp/zookeeper 目錄中創建 myid 檔案,
寫入 一個唯一的數字,取值范圍在 1-255
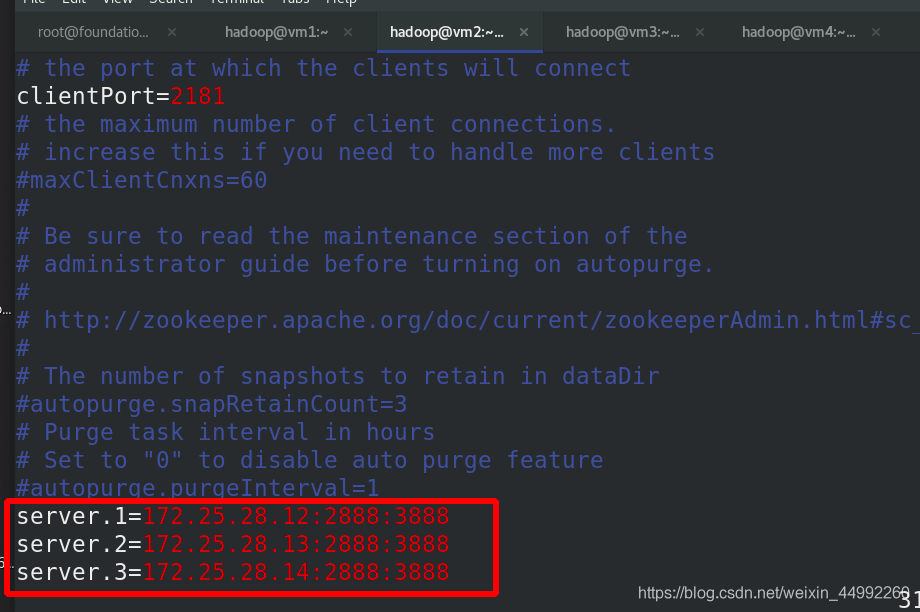
比如:172.25.28.12 節點的 myid 檔案寫入數
字“1”,此數字與組態檔中的定義保持一致,(server.1=172.25.28.12:2888:3888)其它節點依次類推,


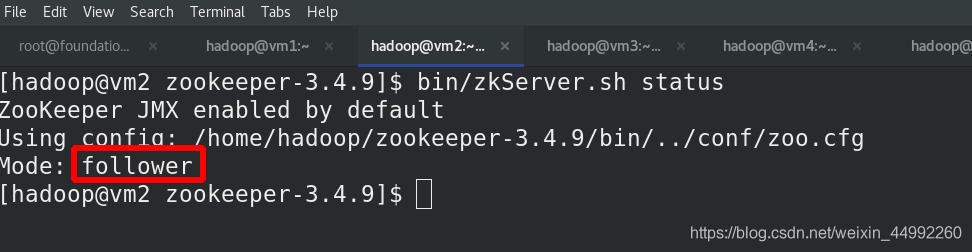
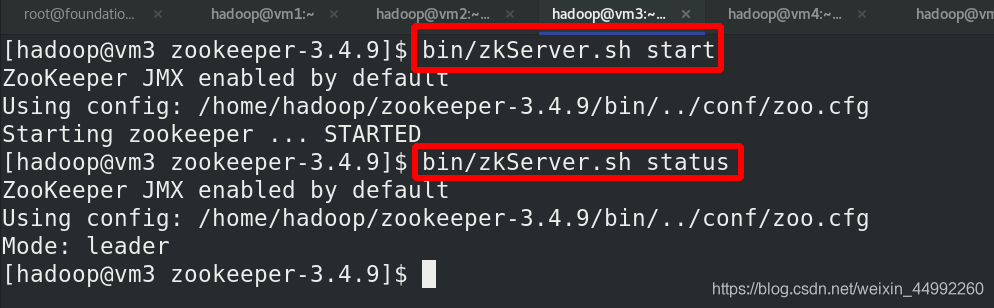
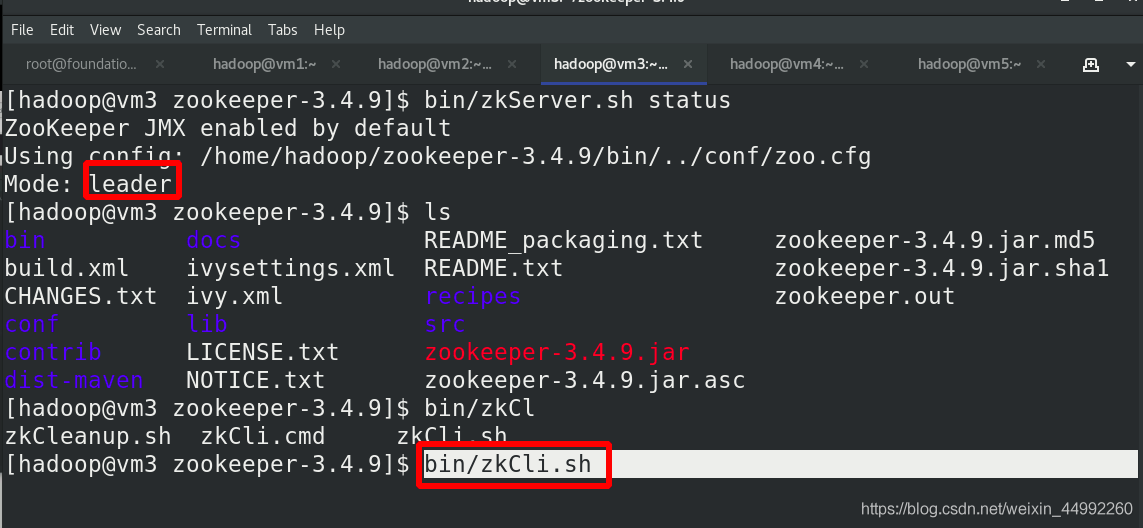
在各節點(vm2,vm3,vm4)啟動服務,vm3為leader,隨機


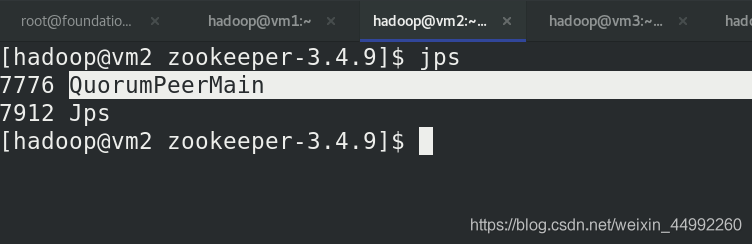
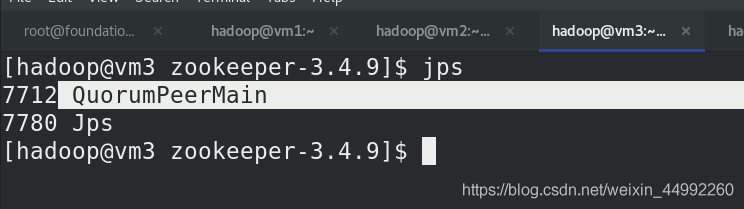
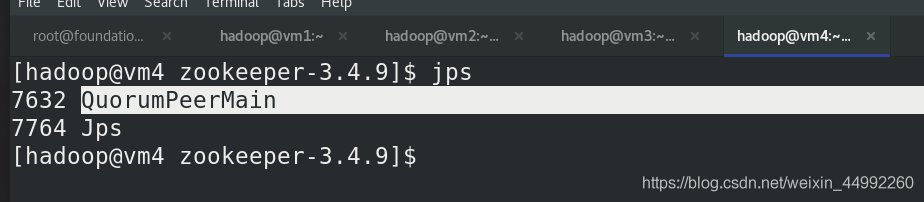
(vm2,vm3,vm4)jps查看行程
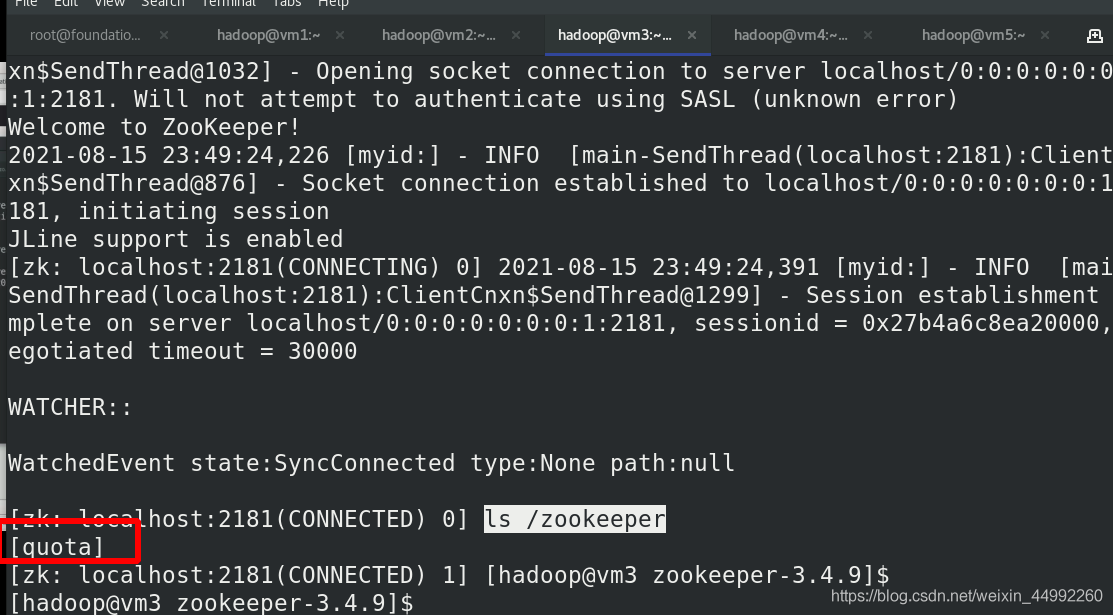
連接 zookeeper
查看
2 hdfs高可用
編輯etc/hadoop/core-site.xml檔案
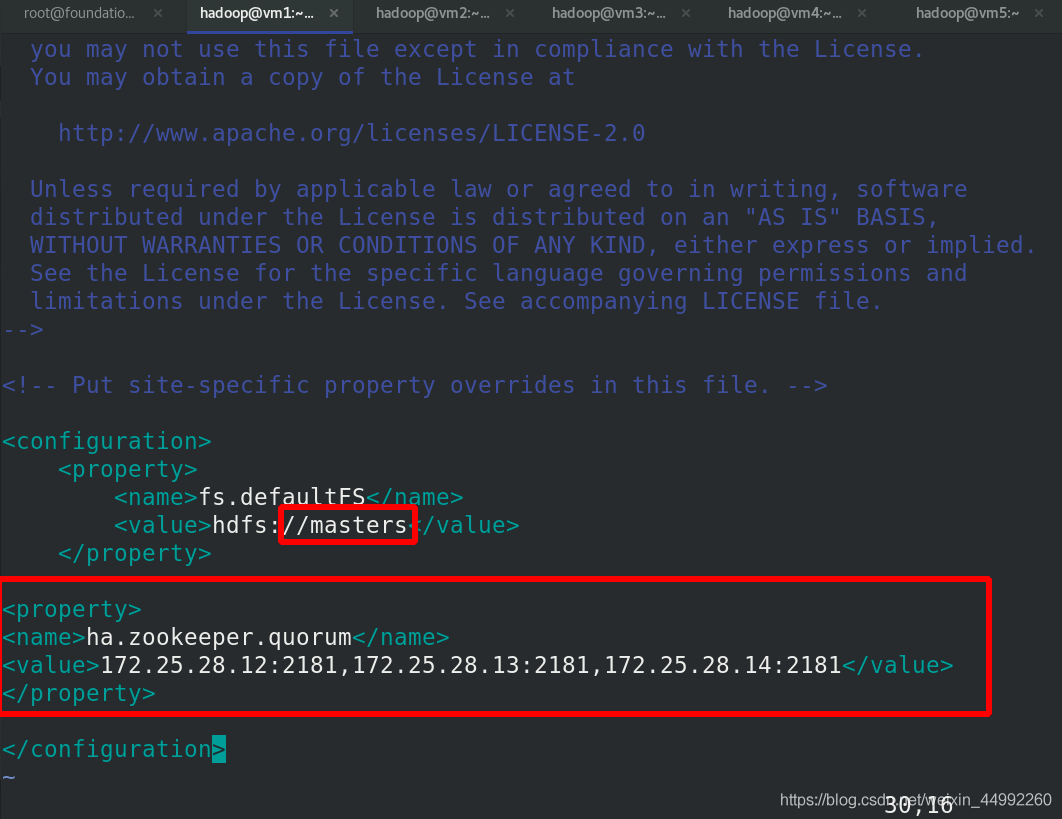
<configuration>
<!-- 指定 hdfs 的 namenode 為 masters (名稱可自定義)-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://masters</value>
</property>
<!-- 指定 zookeeper 集群主機地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>172.25.28.12:2181;172.25.28.13:2181;172.25.28.14:2181</value>
</property>
</configuration>
編輯 etc/hadoop/hdfs-site.xml 檔案,副本數為3(vm2,3,4)
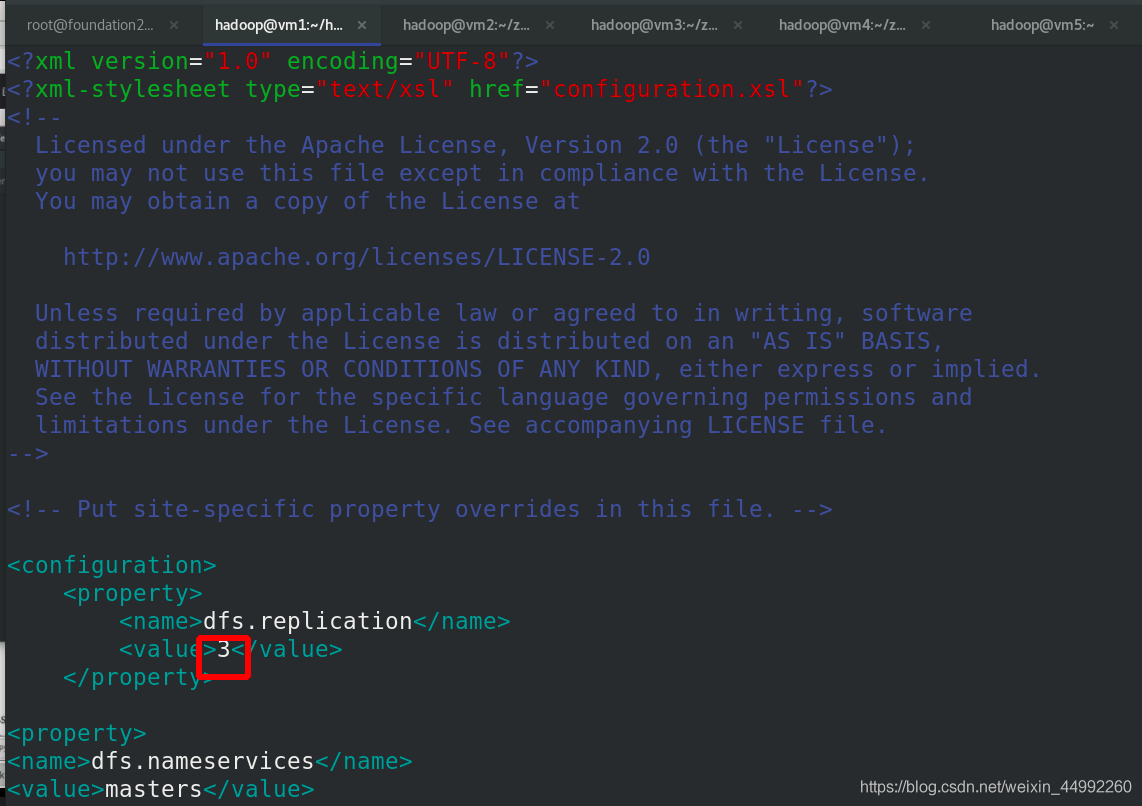
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<!-- 指定 hdfs 的 nameservices 為 masters,和 core-site.xml 檔案中的設定保持一致 -->
<name>dfs.nameservices</name>
<value>masters</value>
</property>
<property>
<!-- masters 下面有兩個 namenode 節點,分別是 h1 和 h2 (名稱可自定義)
-->
<name>dfs.ha.namenodes.masters</name>
<value>h1,h2</value>
</property>
<property>
<!-- 指定 h1 節點的 rpc 通信地址 -->
<name>dfs.namenode.rpc-address.masters.h1</name>
<value>172.25.28.11:9000</value>
</property>
<property>
<!-- 指定 h1 節點的 http 通信地址 -->
<name>dfs.namenode.http-address.masters.h1</name>
<value>172.25.28.11:9870</value>
</property>
<property>
<!-- 指定 h2 節點的 rpc 通信地址 -->
<name>dfs.namenode.rpc-address.masters.h2</name>
<value>172.25.28.15:9000</value>
</property>
<property>
<!-- 指定 h2 節點的 http 通信地址 -->
<name>dfs.namenode.http-address.masters.h2</name>
<value>172.25.28.15:9870</value>
</property>
<property>
<!-- 指定 NameNode 元資料在 JournalNode 上的存放位置 -->
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://172.25.28.12:8485;172.25.28.13:8485;172.25.28.14:8485/masters</value>
</property>
<property>
<!-- 指定 JournalNode 在本地磁盤存放資料的位置 -->
<name>dfs.journalnode.edits.dir</name>
<value>/tmp/journaldata</value>
</property>
<property>
<!-- 開啟 NameNode 失敗自動切換 -->
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<!-- 配置失敗自動切換實作方式 -->
<name>dfs.client.failover.proxy.provider.masters</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<!-- 配置隔離機制方法,每個機制占用一行-->
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<property>
<!-- 使用 sshfence 隔離機制時需要 ssh 免密碼 -->
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<property>
<!-- 配置 sshfence 隔離機制超時時間 -->
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>
啟動 hdfs 集群(按順序啟動)
在三個 DN 上依次啟動 zookeeper 集群
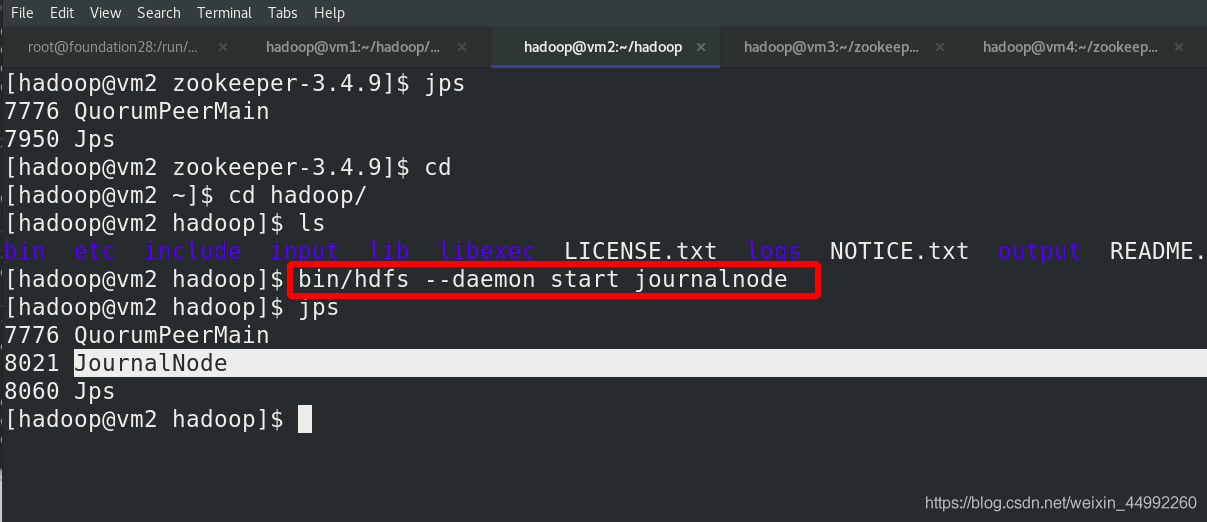
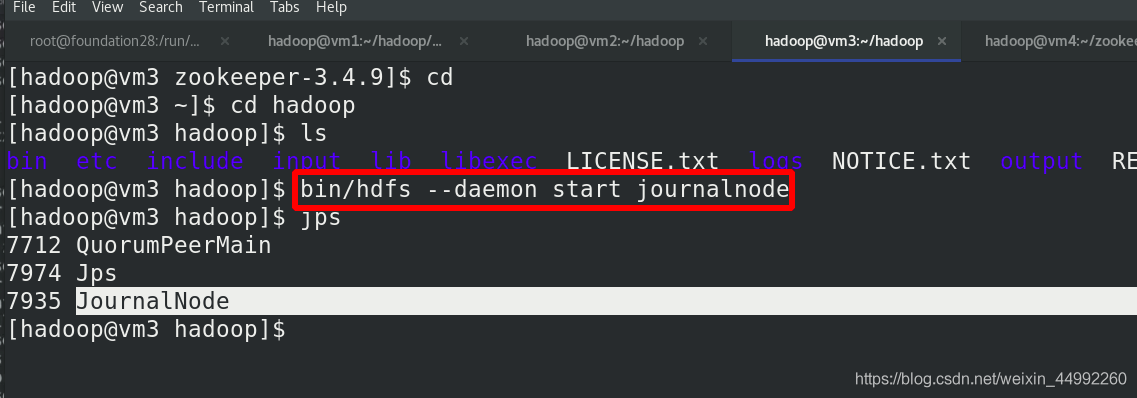
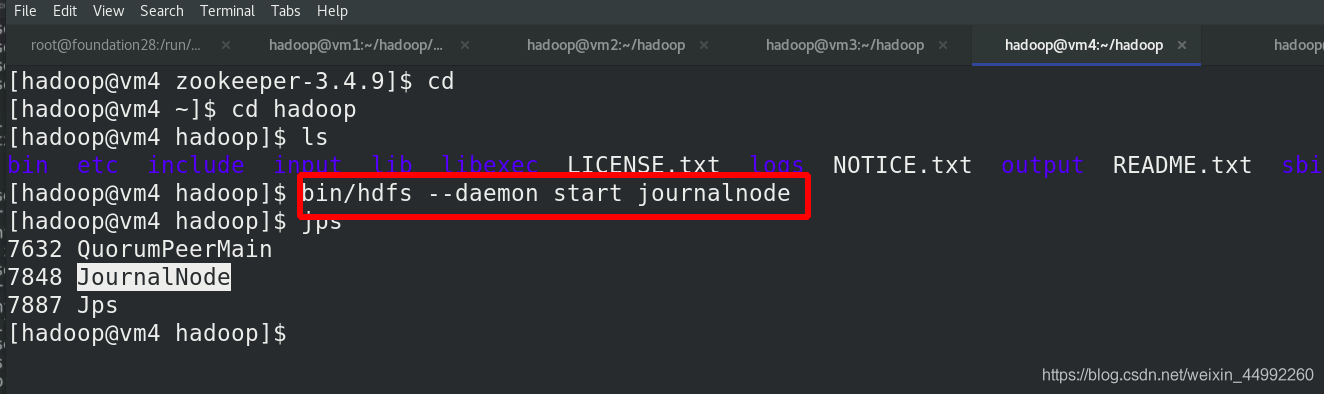 在三個 DN 上依次啟動 journalnode(之前已經都啟動!!!)
在三個 DN 上依次啟動 journalnode(之前已經都啟動!!!)
格式化 HDFS 集群
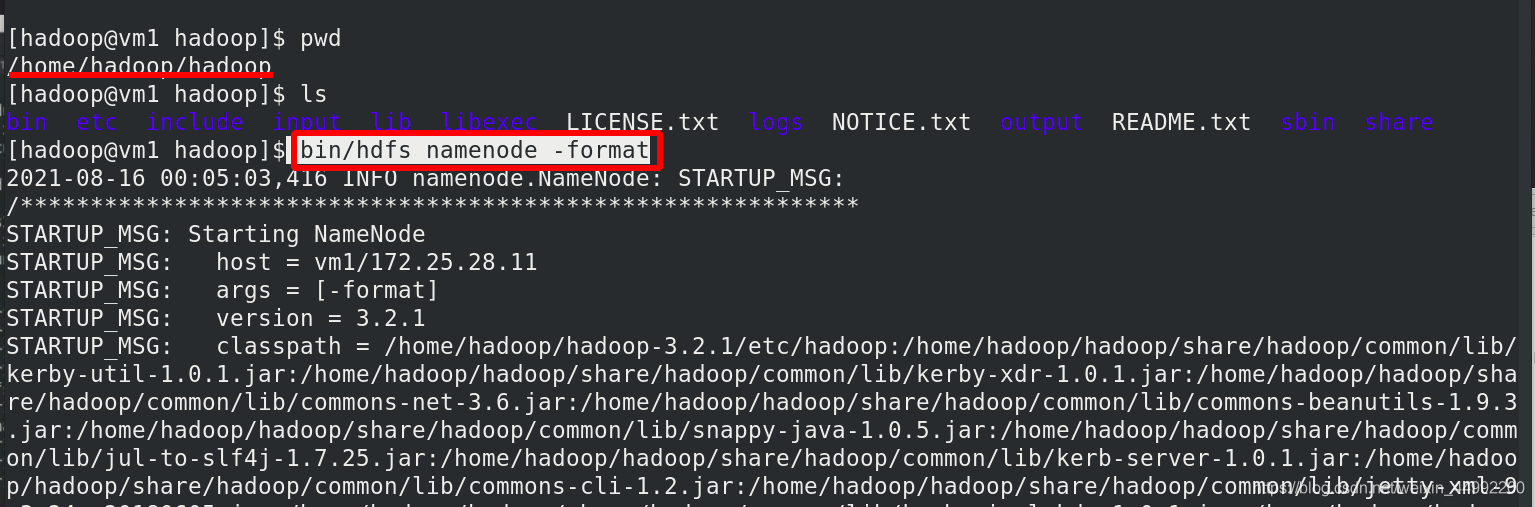 Namenode 資料默認存放在/tmp,需要把資料拷貝到 h2(vm5)
Namenode 資料默認存放在/tmp,需要把資料拷貝到 h2(vm5)
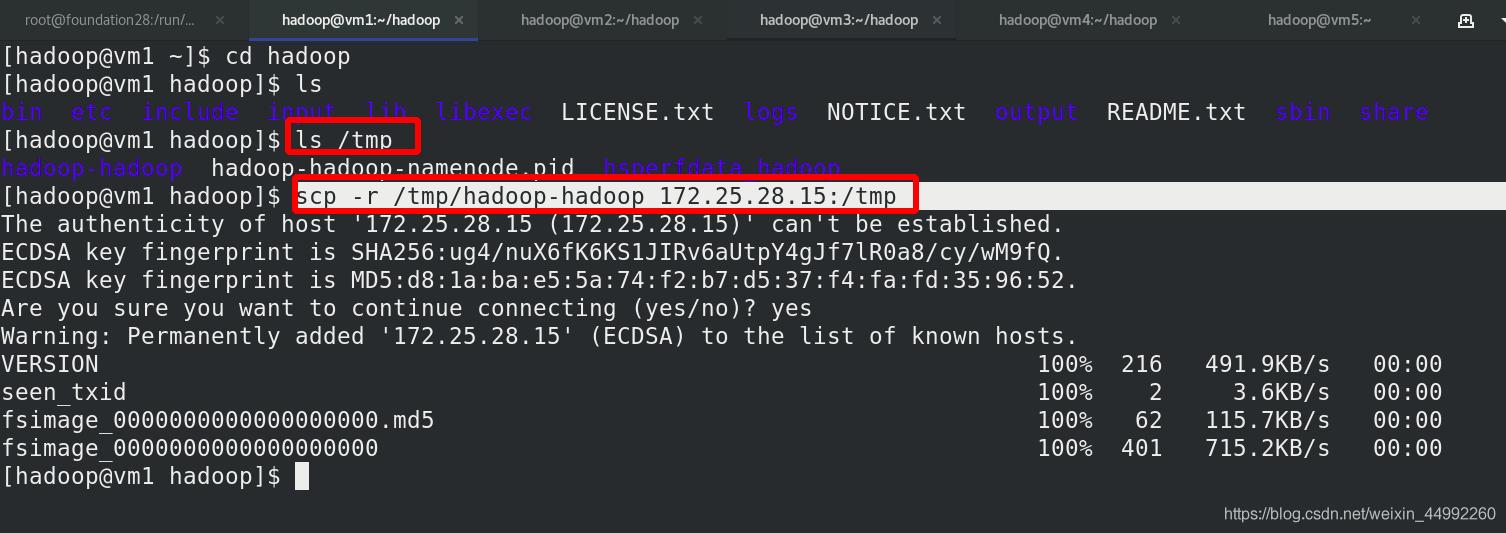 格式化 zookeeper (只需在 h1 上執行即可)
格式化 zookeeper (只需在 h1 上執行即可)
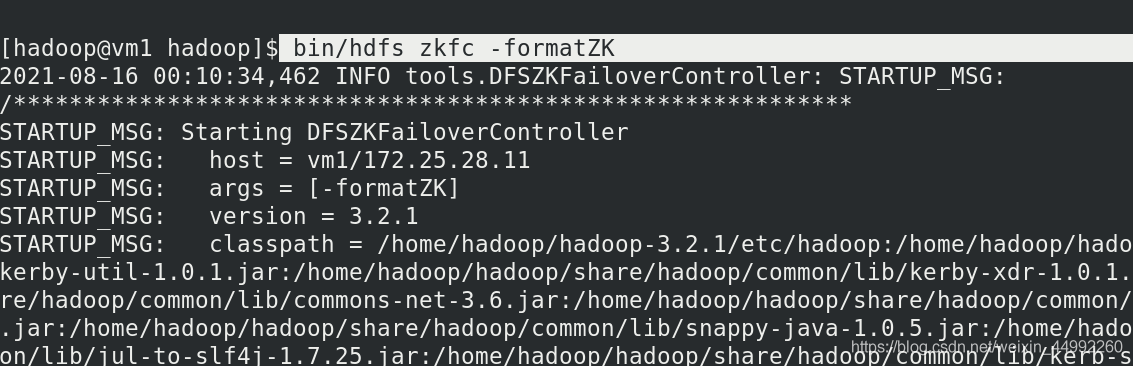 連接zookeeper
連接zookeeper

查看有zookeeper
啟動 hdfs 集群(只需在 h1 上執行即可)
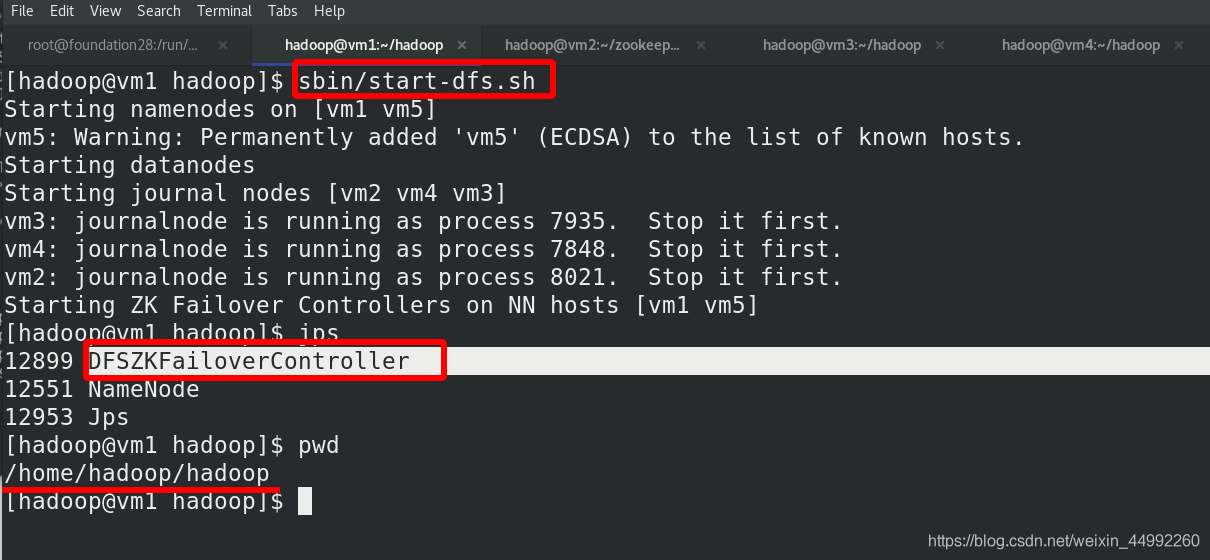 vm5查看行程狀態,主備(vm1和vm5)保持一致!!!
vm5查看行程狀態,主備(vm1和vm5)保持一致!!!

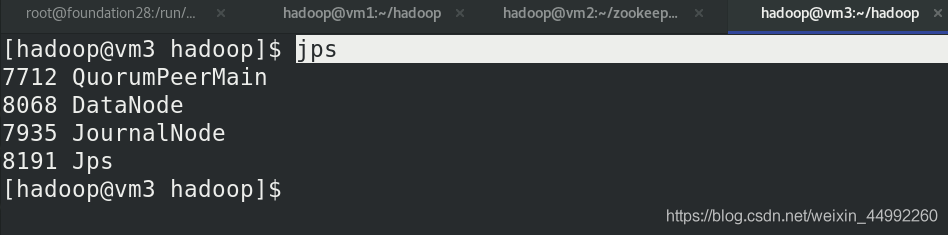
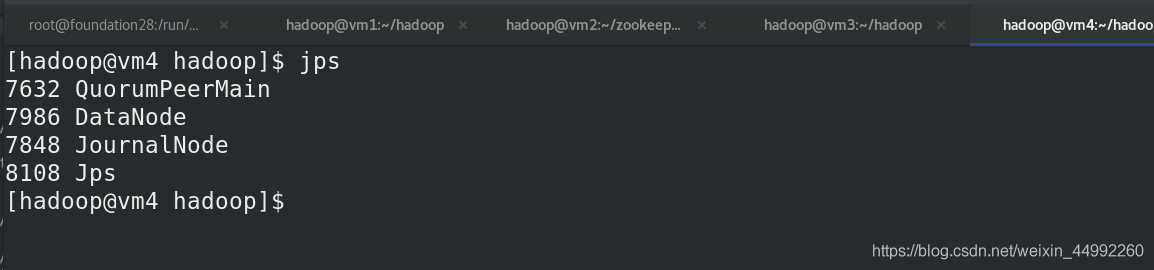
查看各節點狀態,有QuorumPeerMain行程!!!
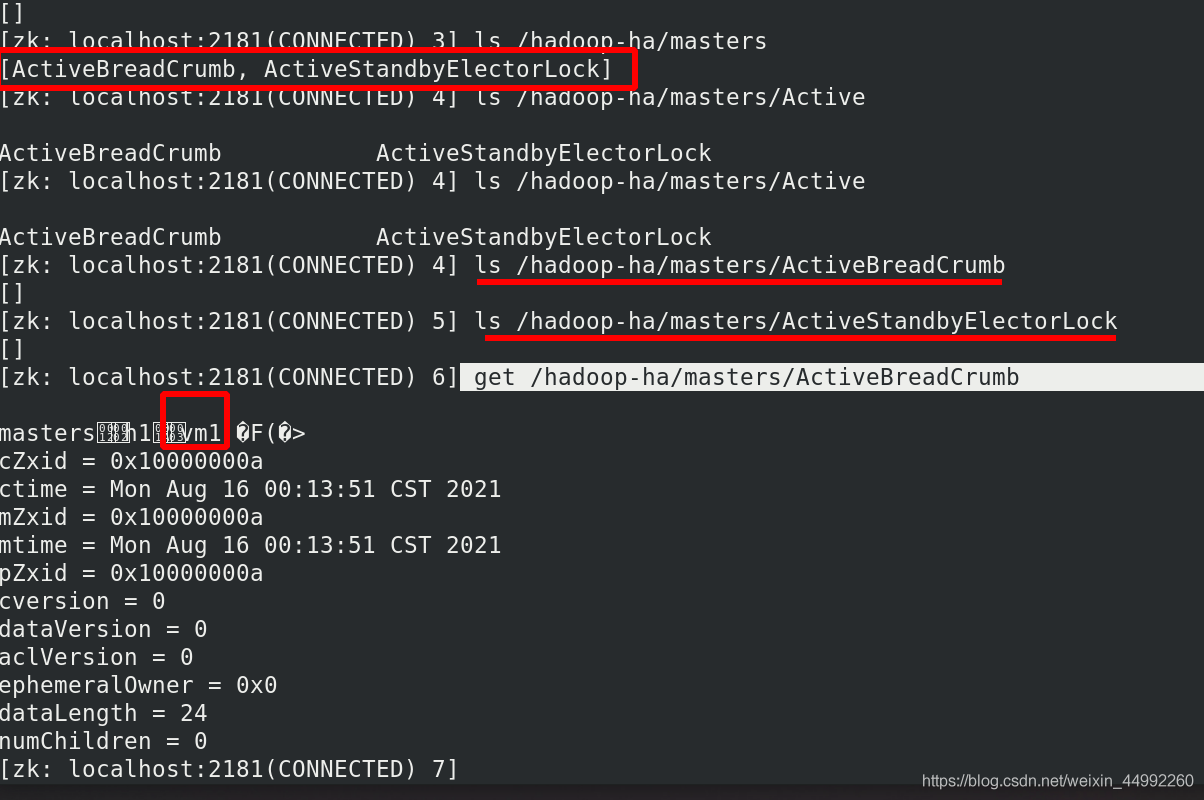
vm2查看NN主備,此時vm1為NN的主
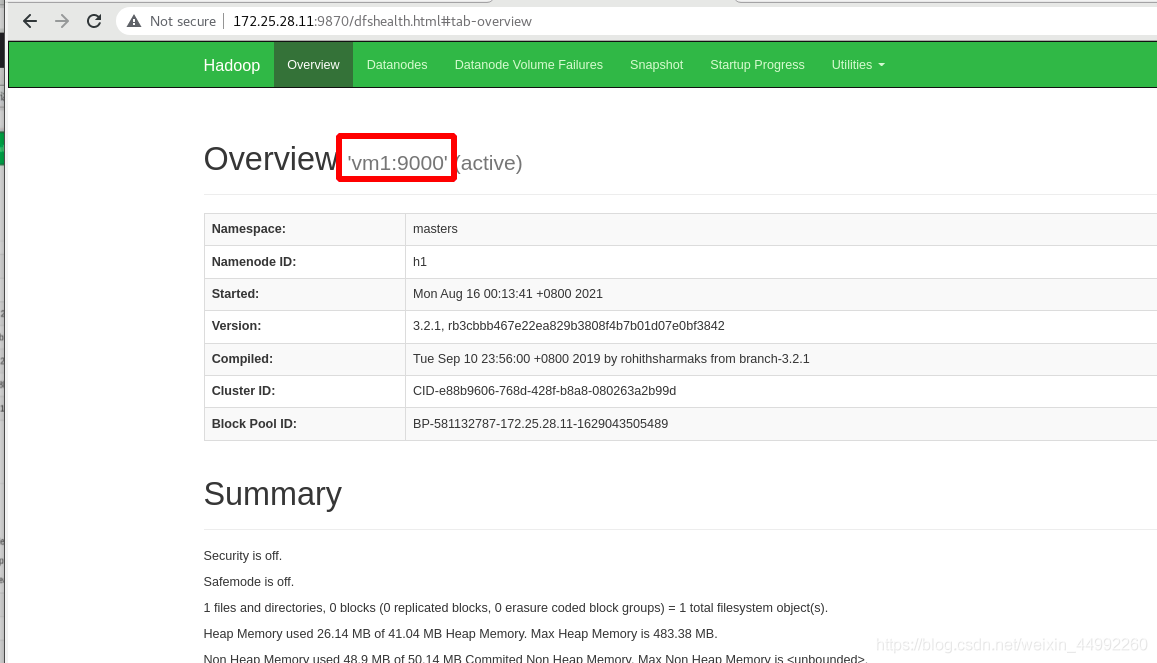
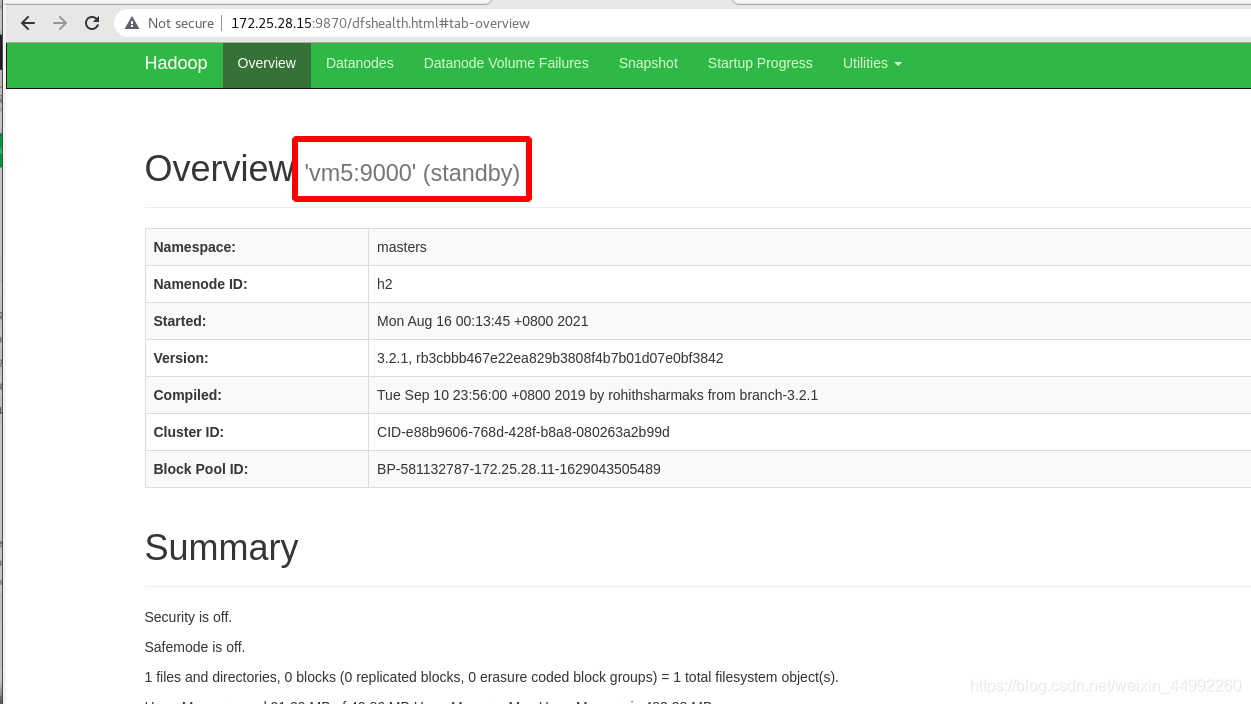
 外部訪問查看,
外部訪問查看,主為vm1!!!備為vm5!!!
上傳input目錄到分布式檔案系統中

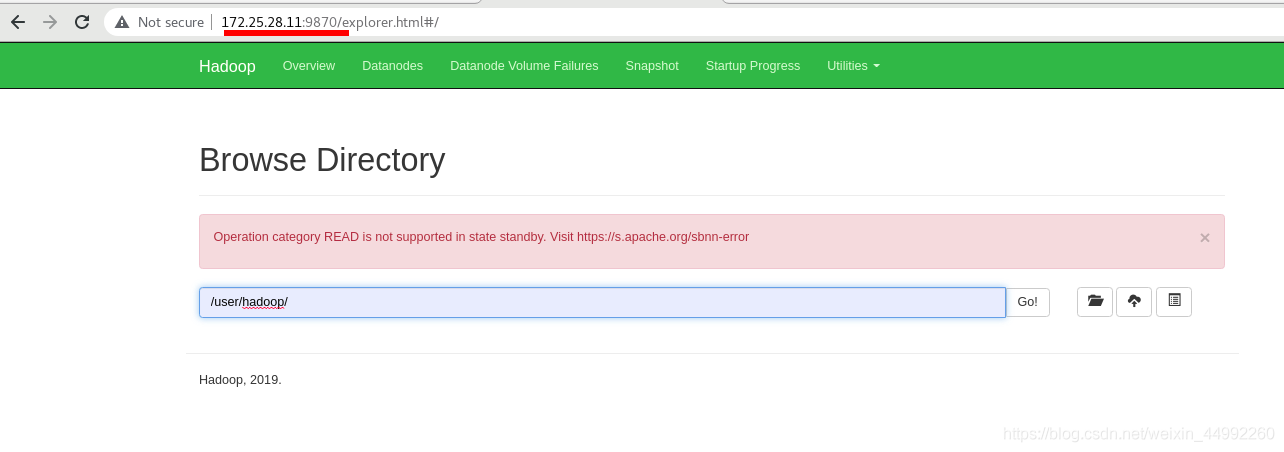
備機vm5無法查看
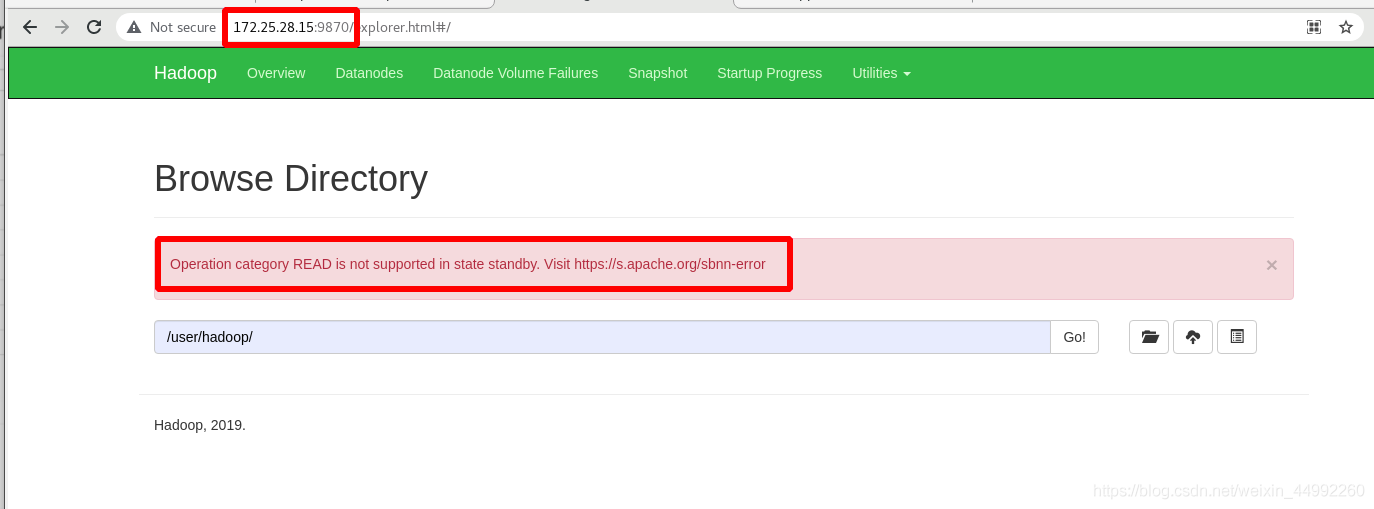
主機vm5無法查看
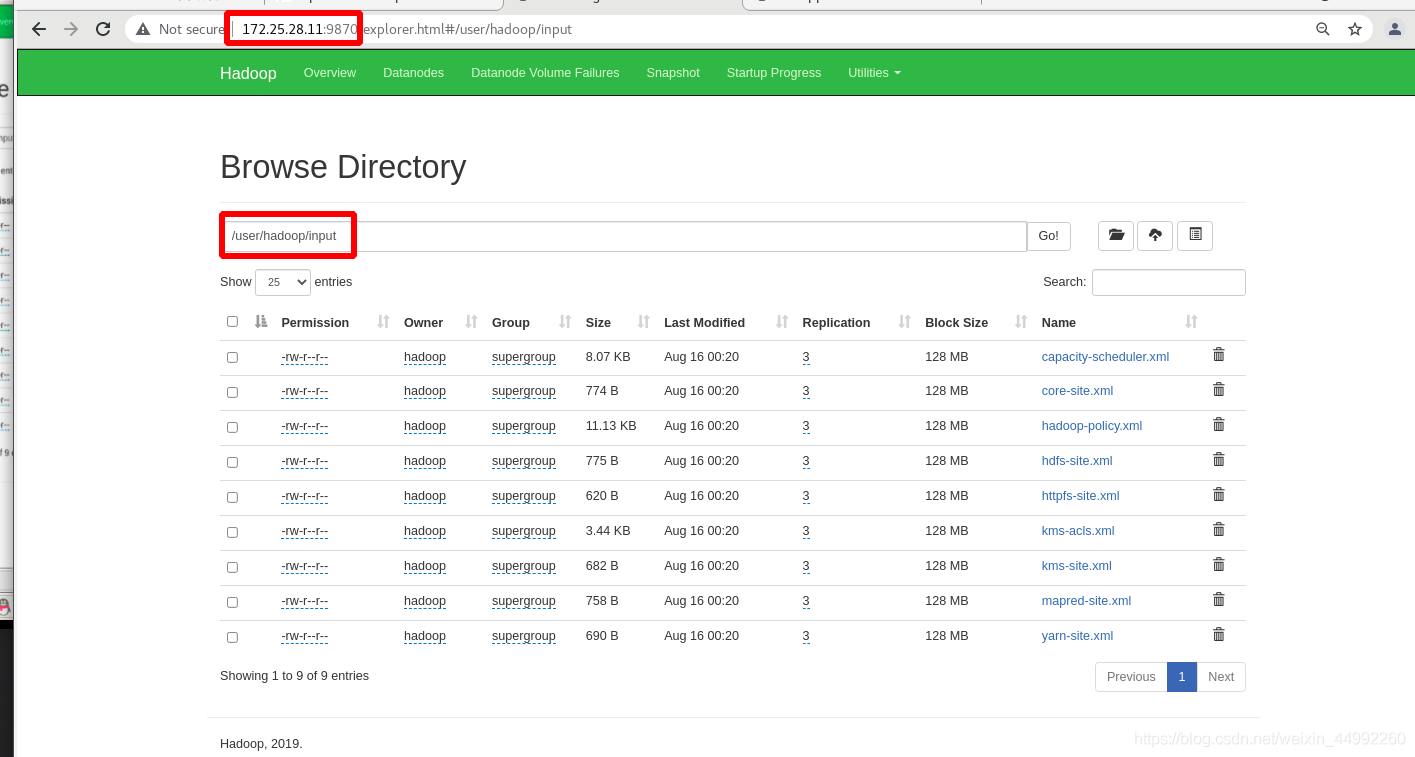
vm2,vm3,vm4 為hadoop集群
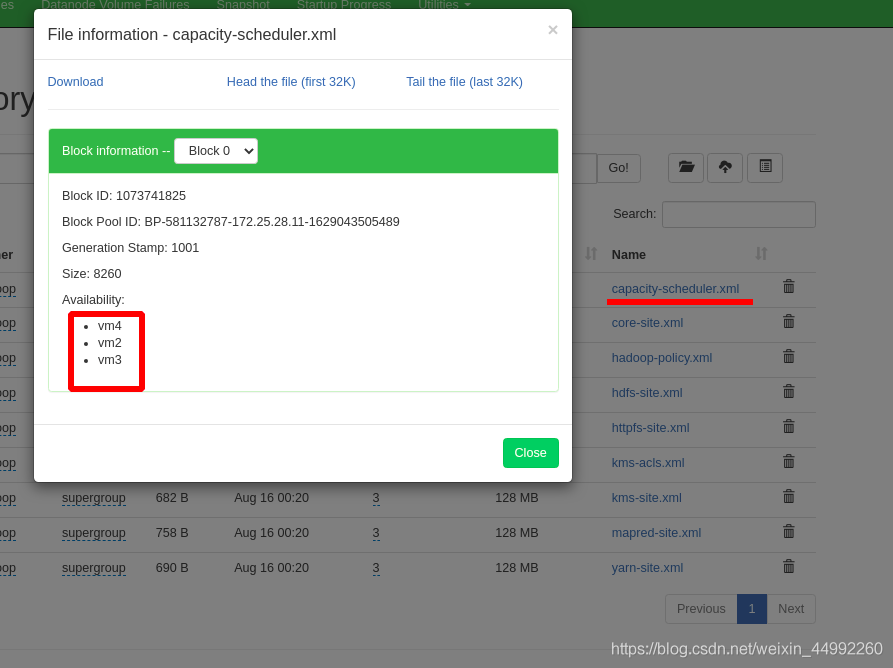 命令列方式查看分布式檔案系統中的內容
命令列方式查看分布式檔案系統中的內容
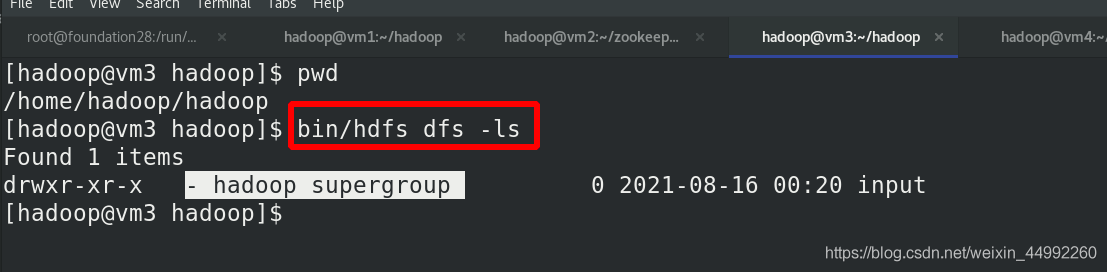
測驗故障自動切換
殺死vm1的NameNode行程
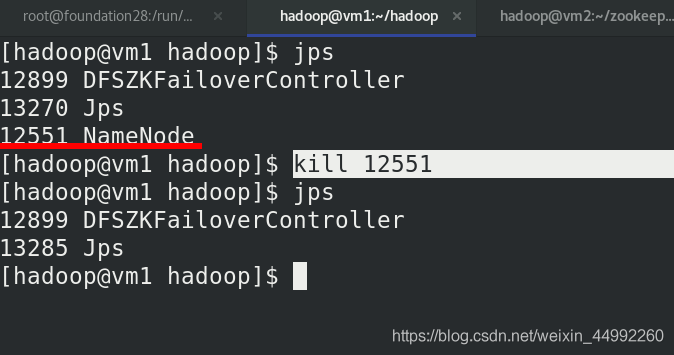
此時此時 h2 (vm5)轉為 active 狀態接管 namenode
 外部訪問查看
外部訪問查看
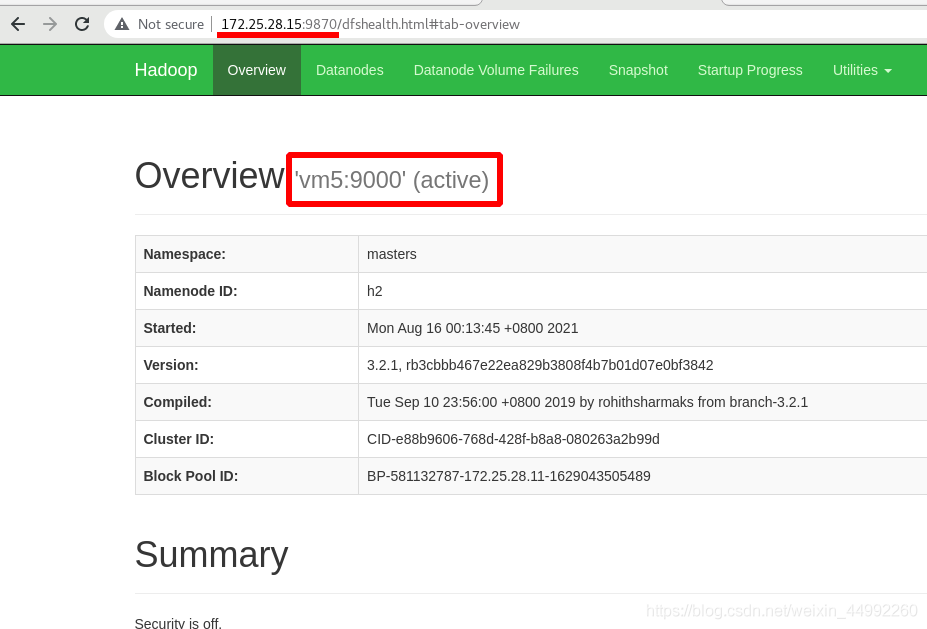
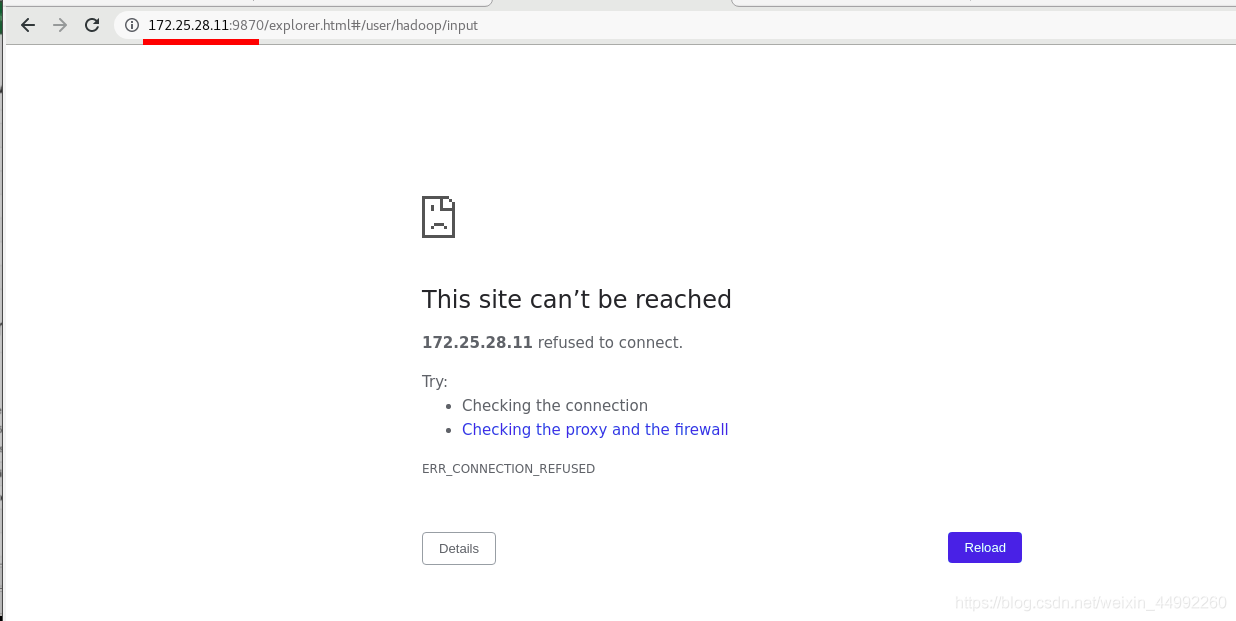
重新啟動vm1的Namenode行程
依舊是vm5接管 namenode,誰先寫進去誰是active!!!
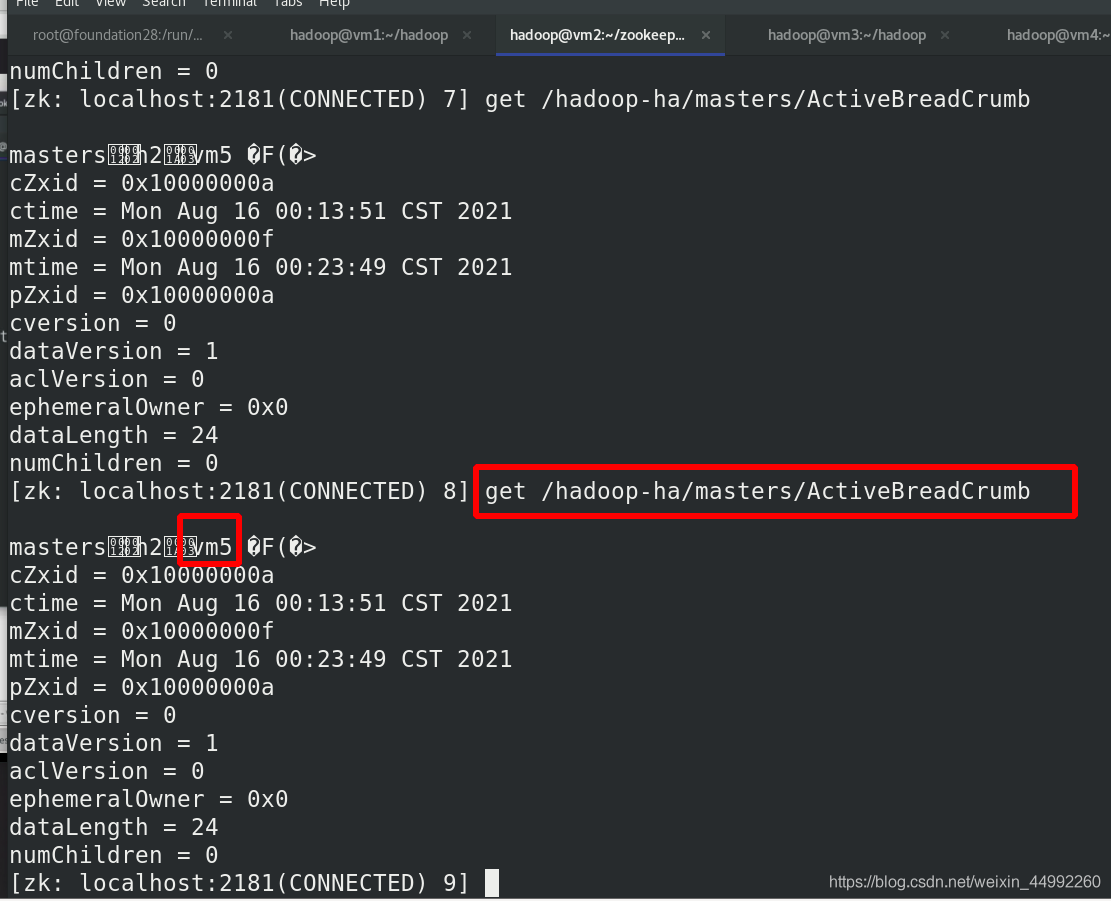
外部訪問:
vm1 為standby
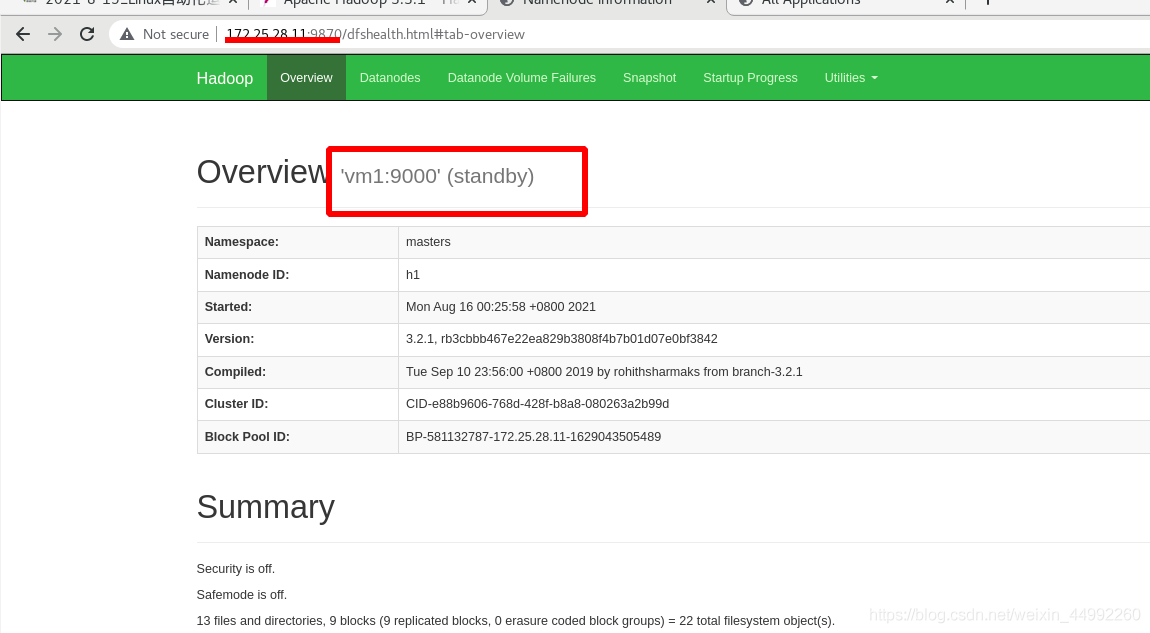
vm5 為active

3 yarn 高可用
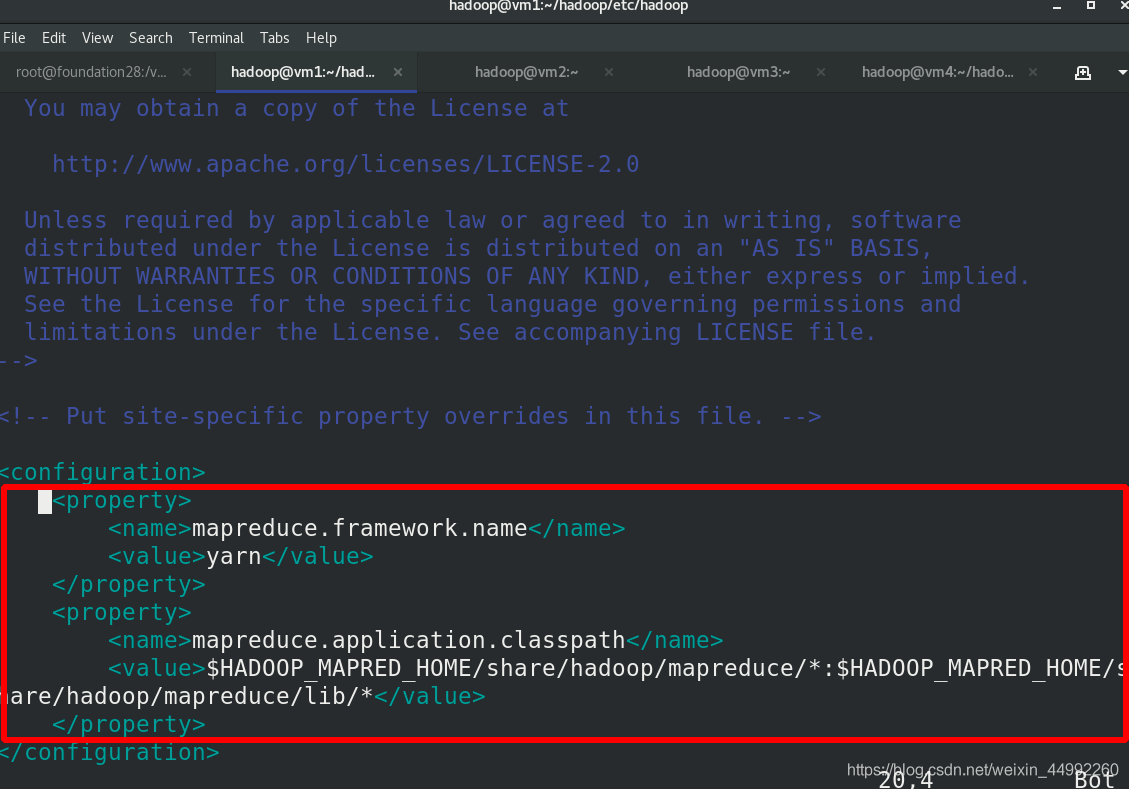
編輯 mapred-site.xml 檔案(上述實驗已經完成編輯)
<configuration>
<!-- 指定 yarn 為 MapReduce 的框架 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
編輯 yarn-site.xml 檔案
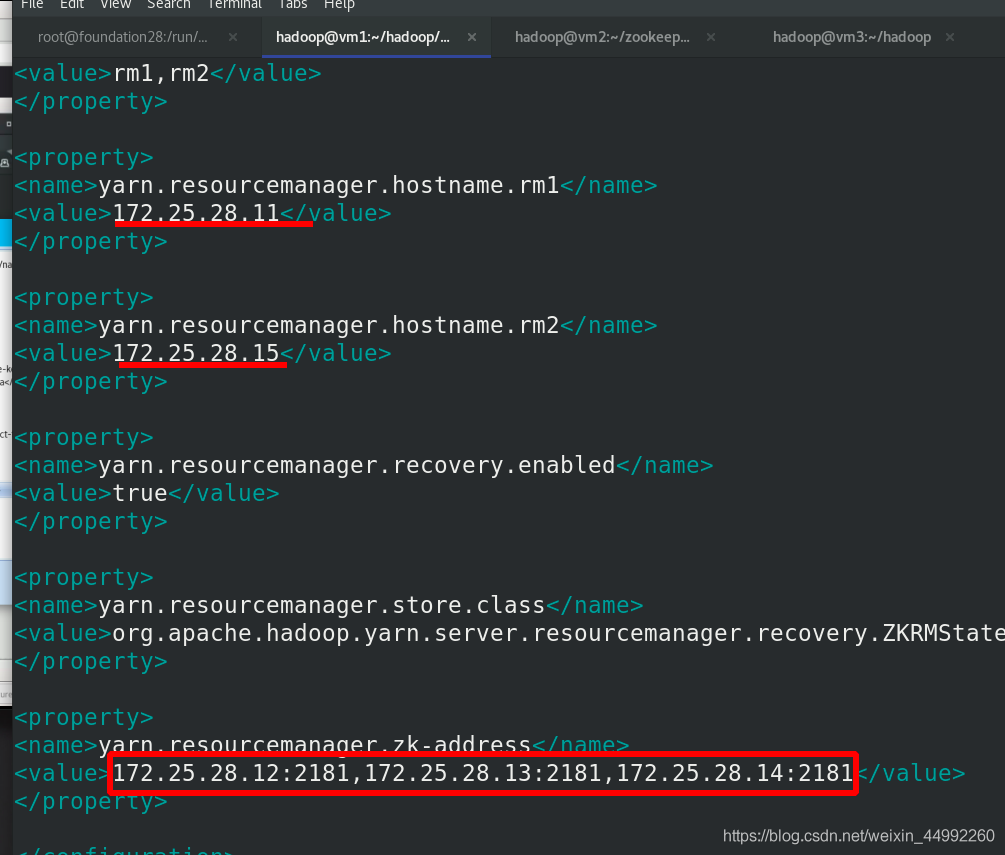
<configuration>
<!-- 配置可以在 nodemanager 上運行 mapreduce 程式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 激活 RM 高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property><!-- 指定 RM 的集群 id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>RM_CLUSTER</value>
</property>
<!-- 定義 RM 的節點-->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 指定 RM1 的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>172.25.0.1</value>
</property>
<!-- 指定 RM2 的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>172.25.0.5</value>
</property>
<!-- 激活 RM 自動恢復 -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- 配置 RM 狀態資訊存盤方式,有 MemStore 和 ZKStore-->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</
value>
</property>
<!-- 配置為 zookeeper 存盤時,指定 zookeeper 集群的地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>172.25.0.2:2181,172.25.0.3:2181,172.25.0.4:2181</value>
</property>
</configuration>
啟動 yarn 服務
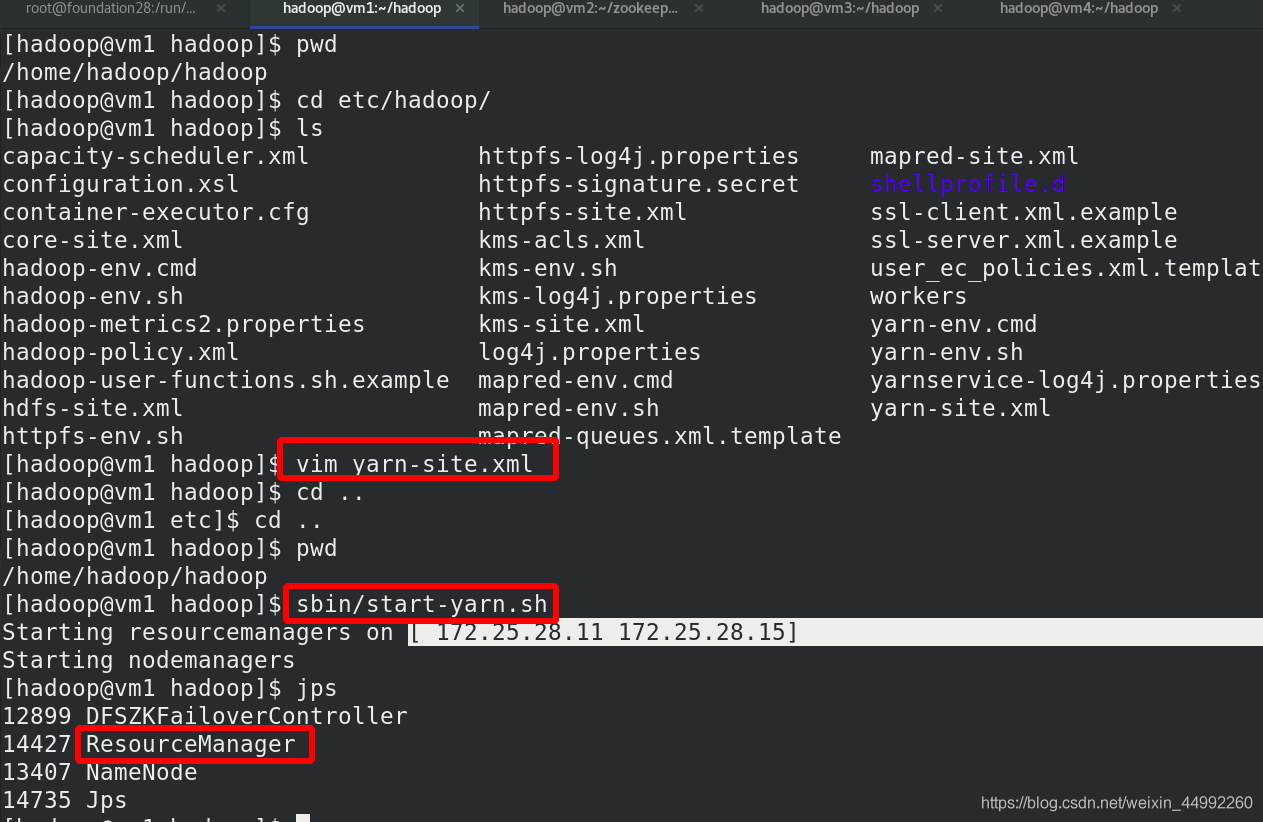
vm1和vm5上查看行程,有Resourcemanager
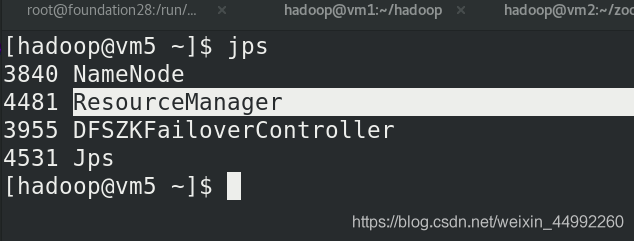
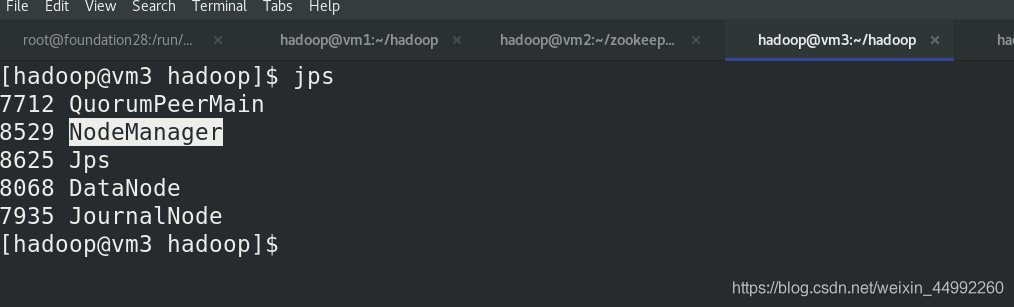
vm2,vm3,vm4上查看行程,有Nodemanager
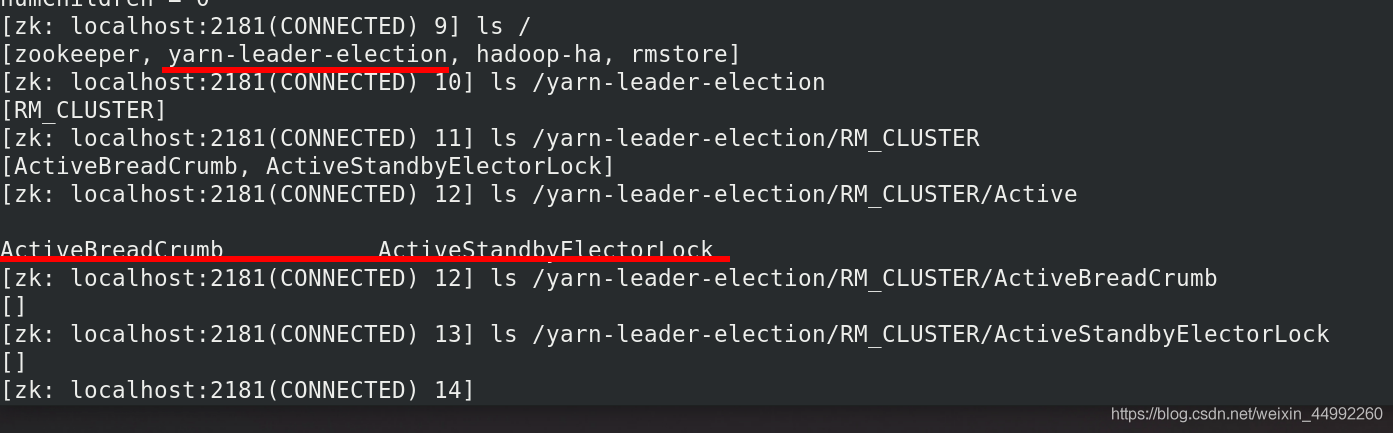
hdfs集群內部查看主備檔案
命令列方式查看主備,是vm1
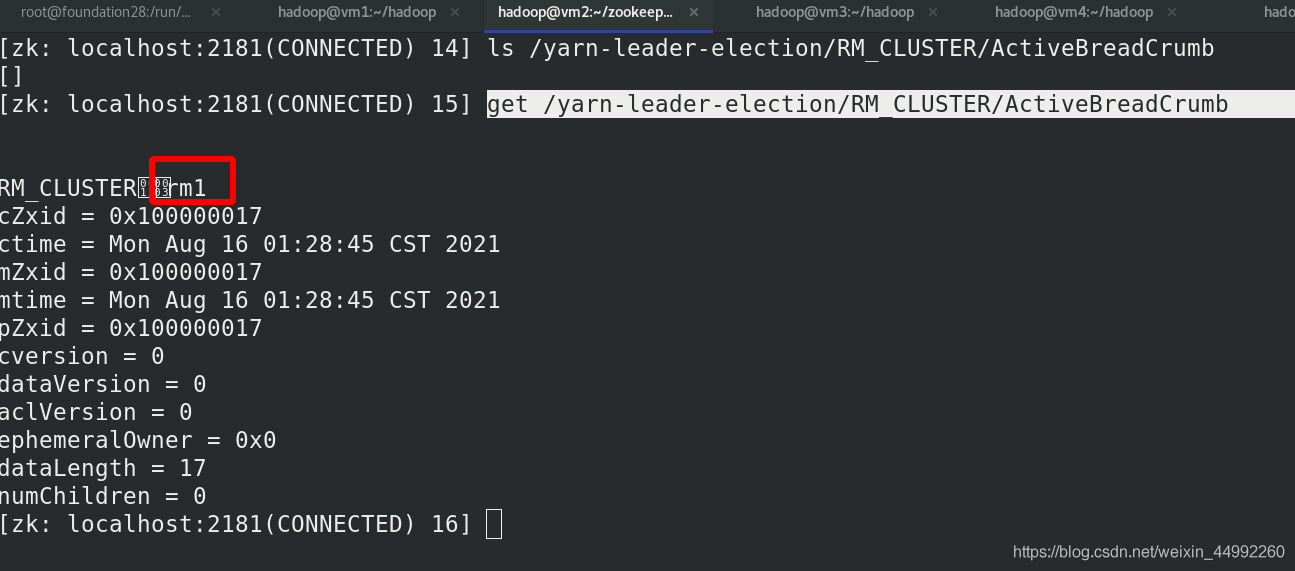
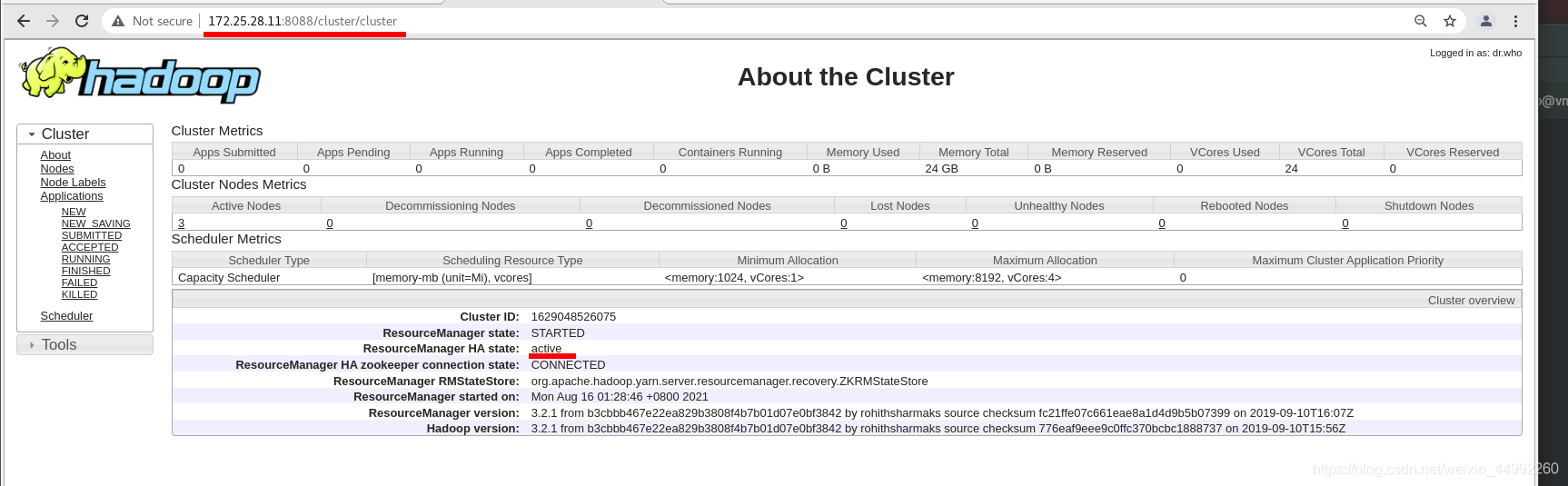
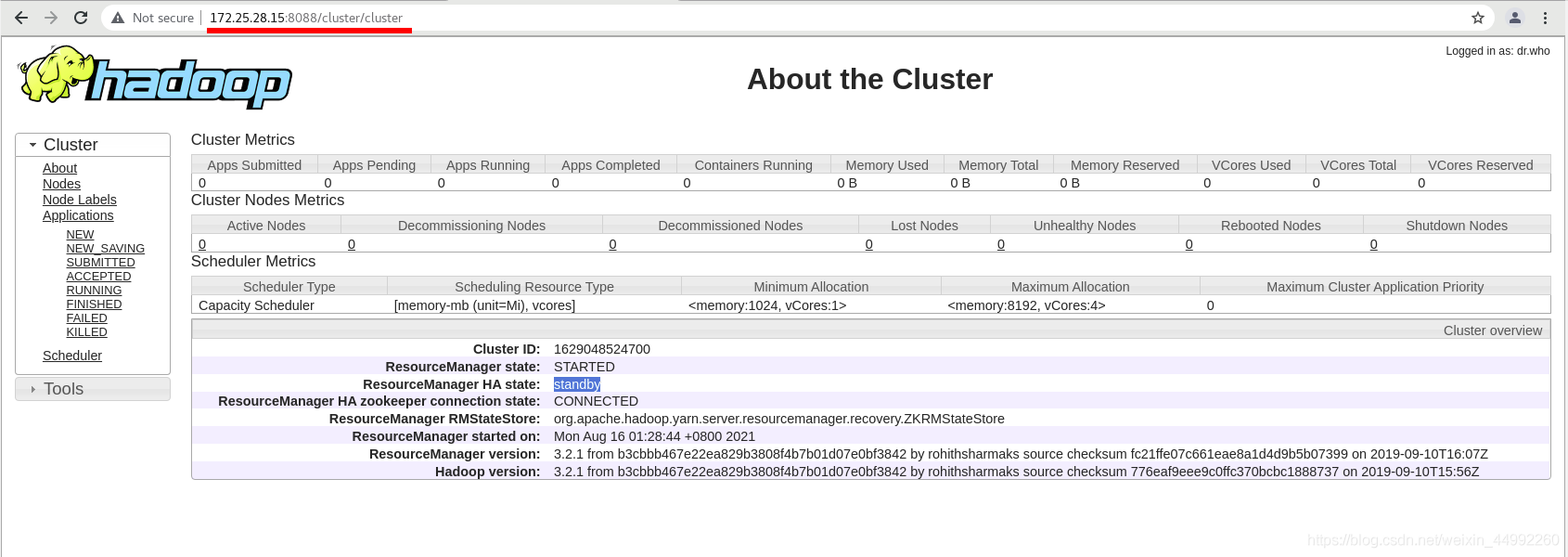
外部訪問查看主備,
vm1:主 vm5:備
測驗 yarn 故障切換
殺死vm1的Resourcemanager行程
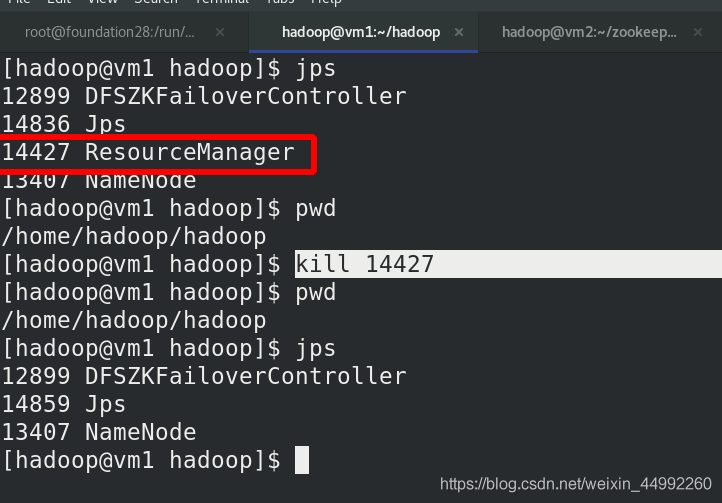
vm1無法訪問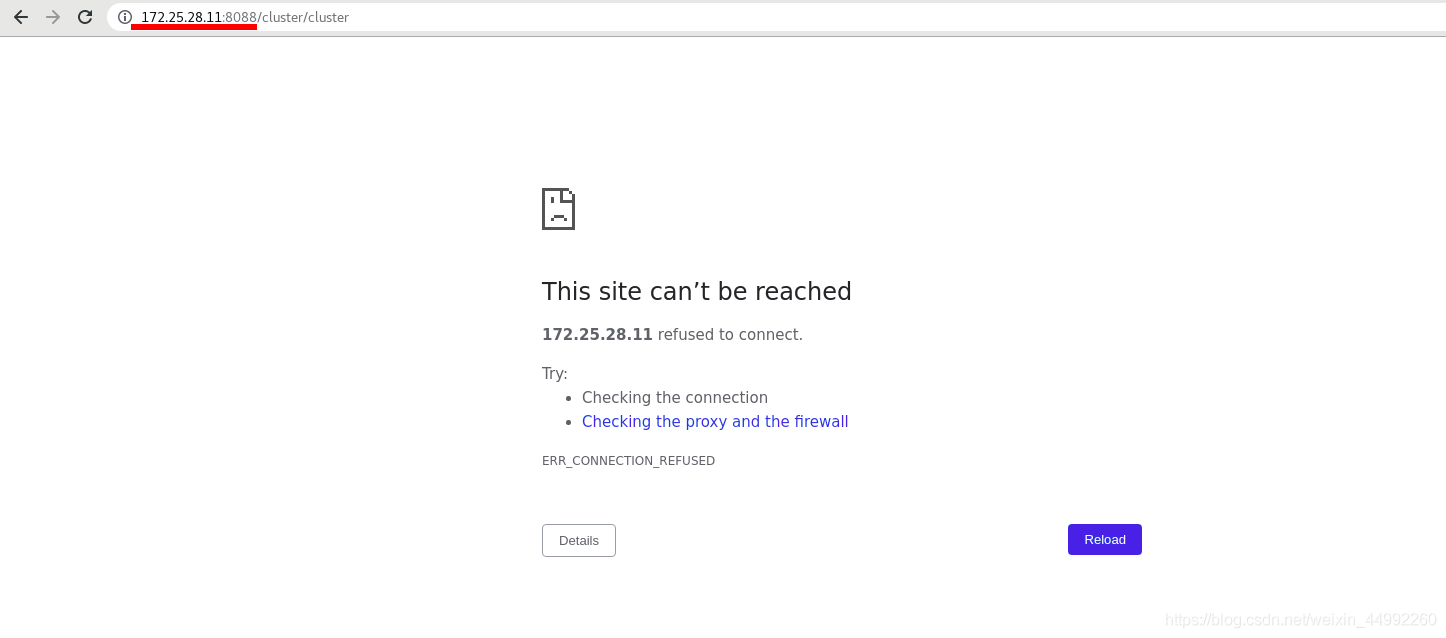
此時主已經切換為vm5

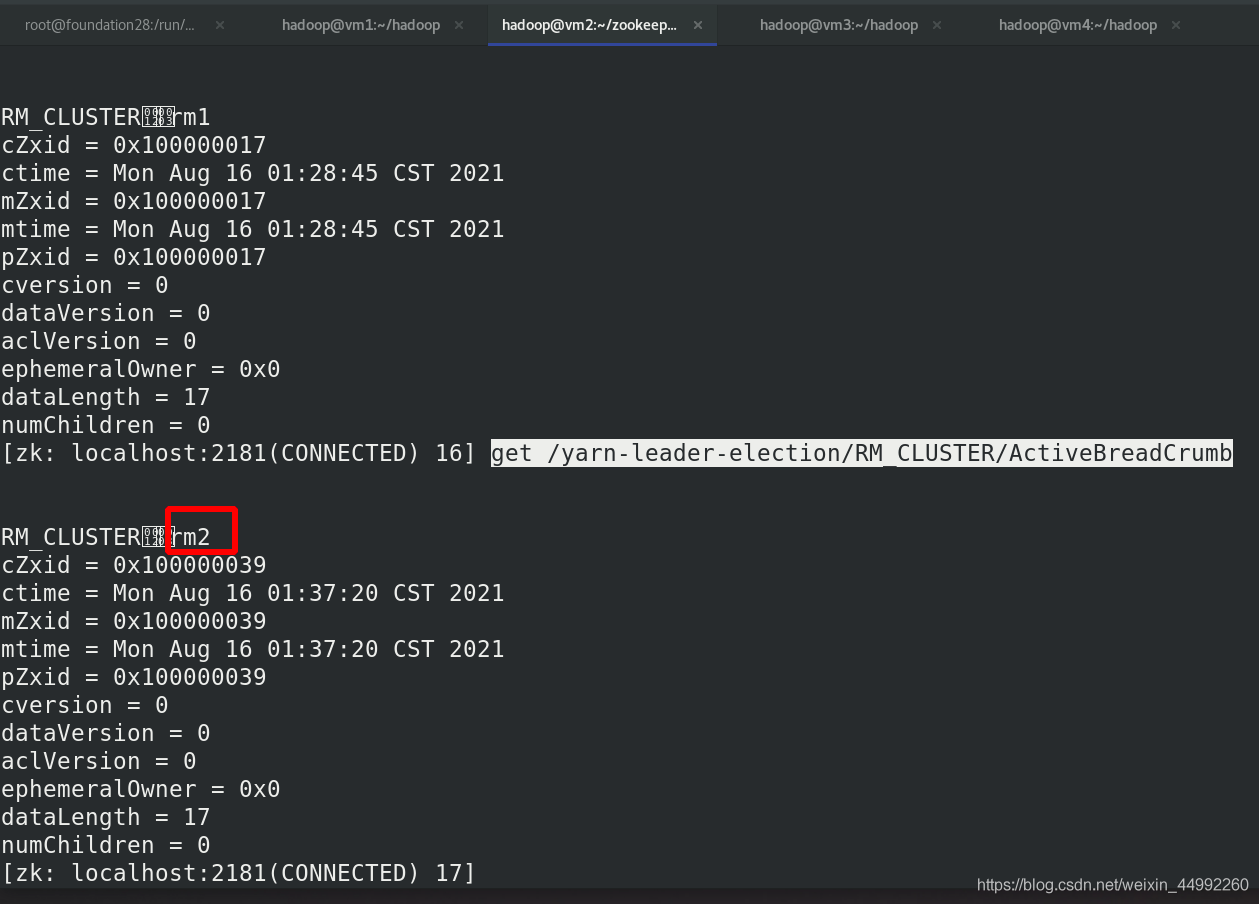
重新啟動vm1的Resourcemanager行程
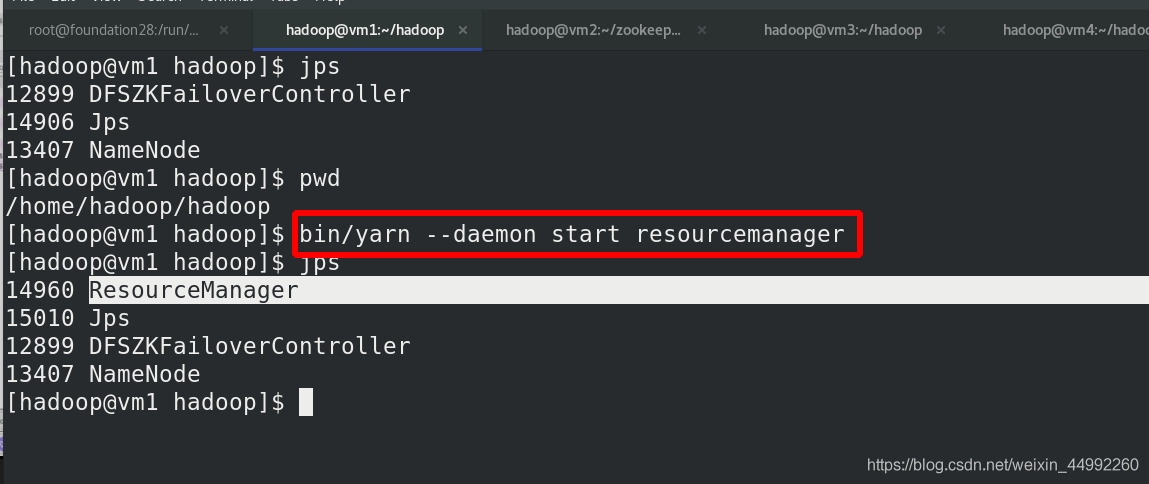
外部訪問:
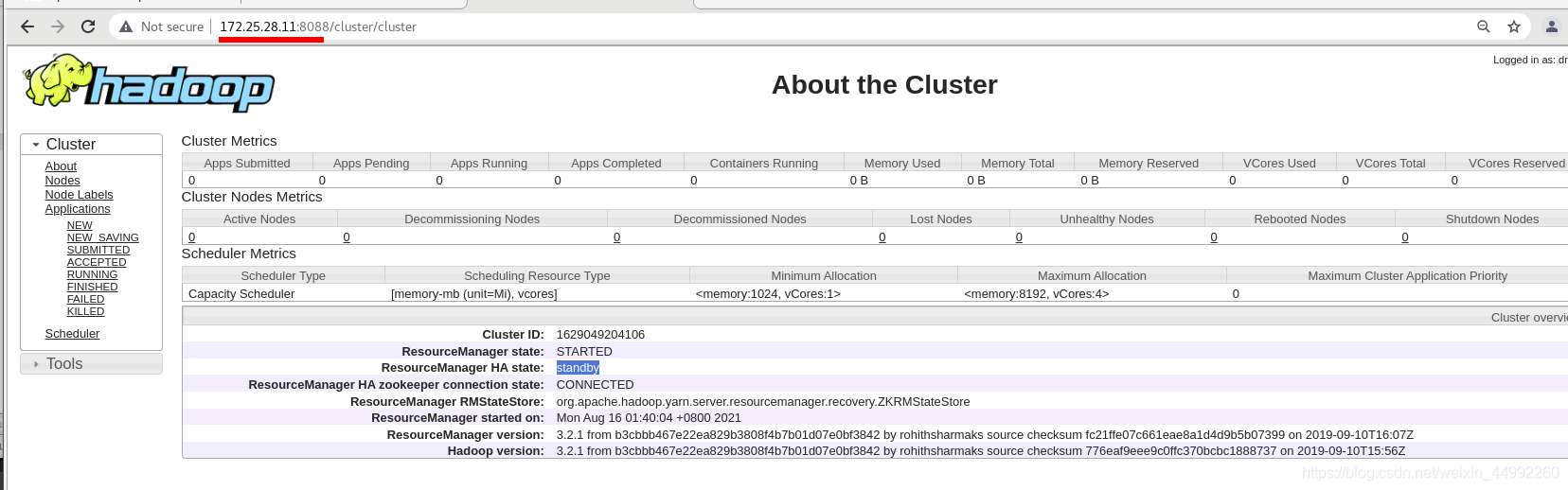
vm1 為standby
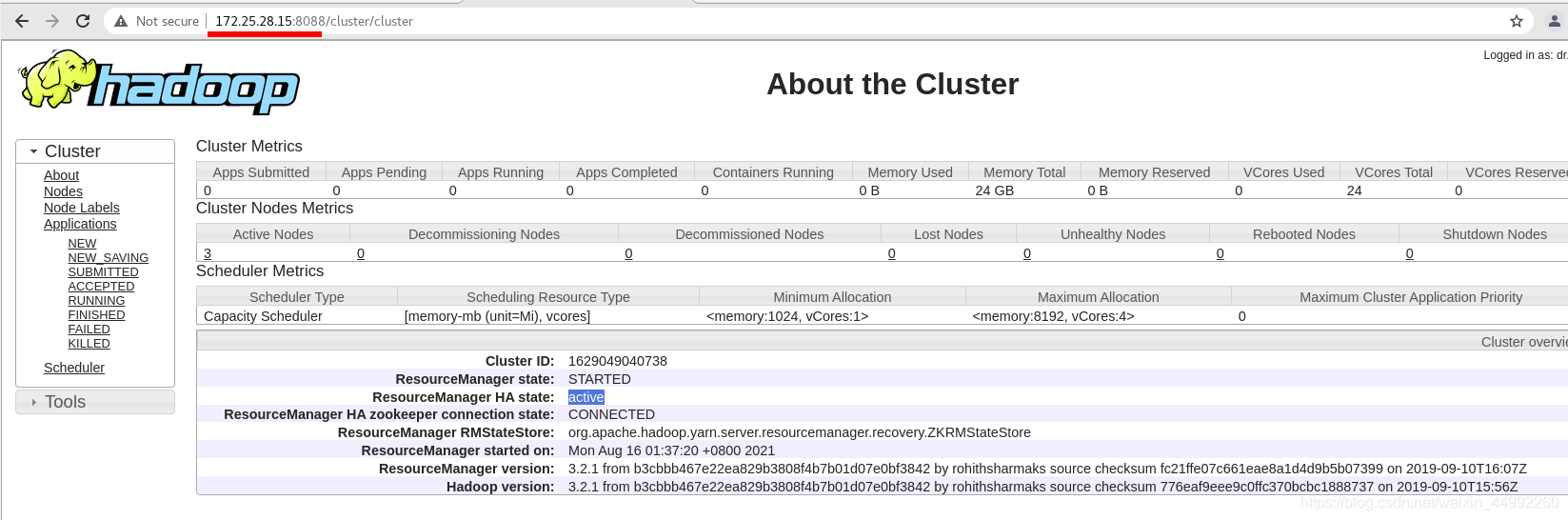
vm5 依舊為active
4 hbase 高可用
解壓縮hbase包

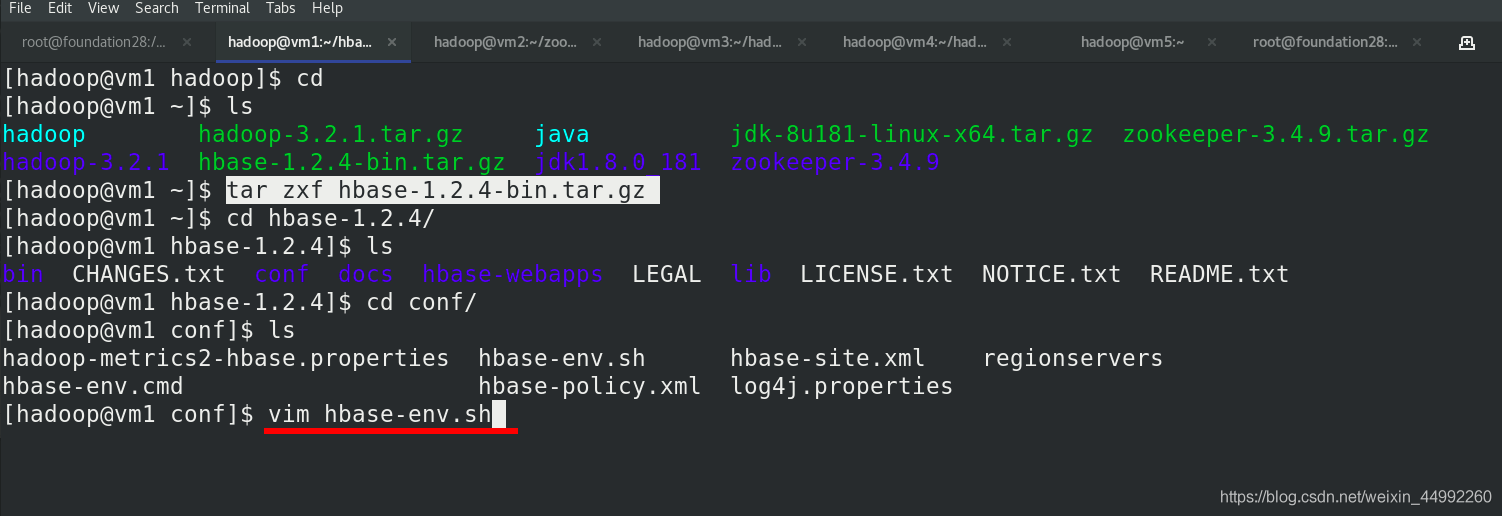
編輯 hbase-env.sh 檔案
false:habase自帶zk,我們已經搭建好zk,自己維護 zookeeper 集群需設定為 false
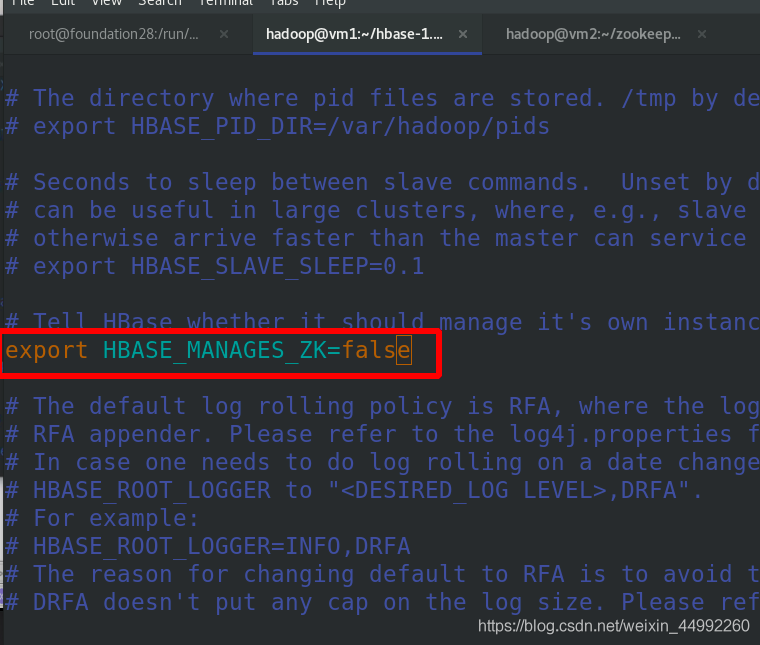
加入環境變數
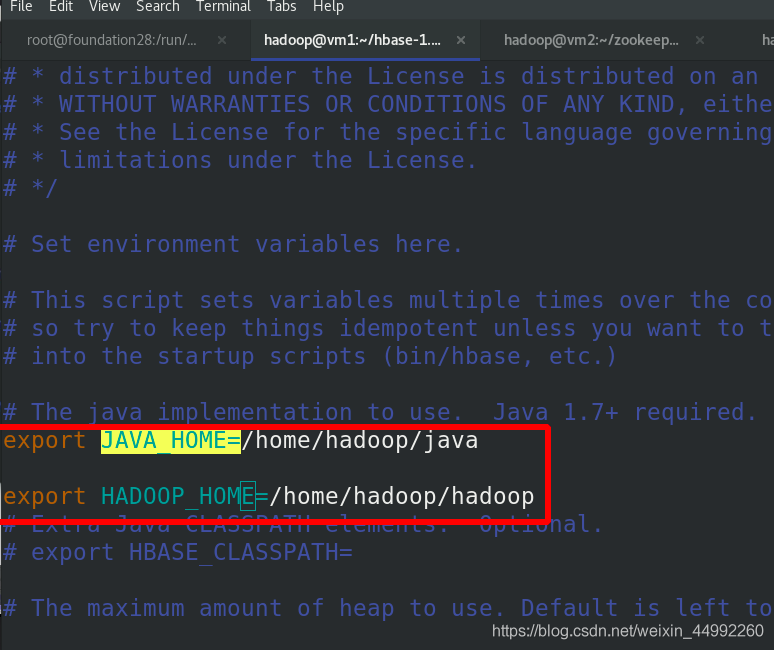
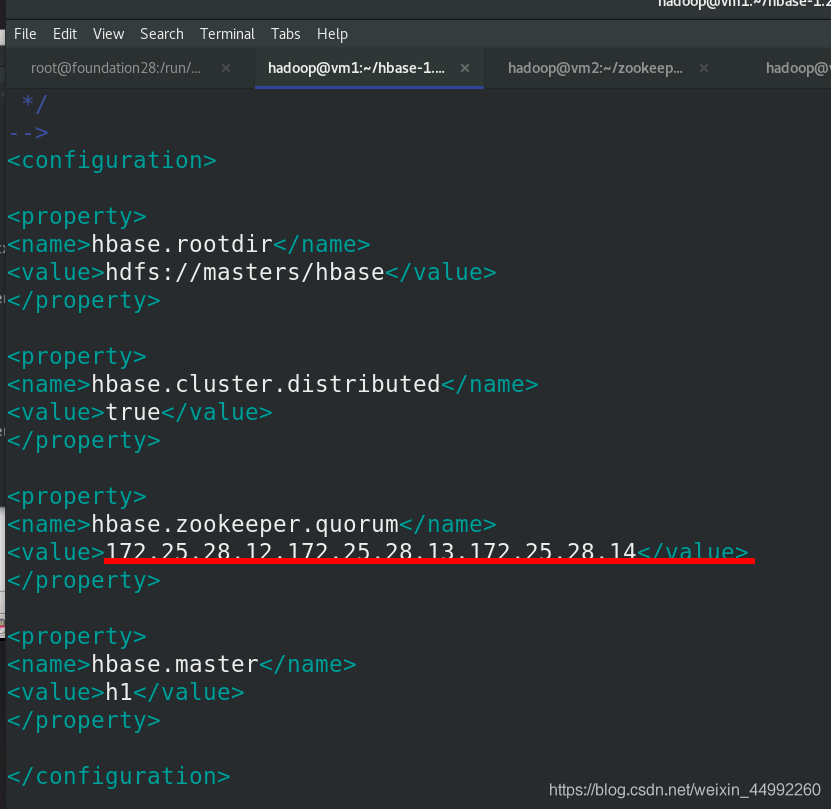
編輯vim hbase-site.xml檔案
<configuration>
<!-- 指定 region server 的共享目錄,用來持久化 HBase,這里指定的 HDFS 地址
是要跟 core-site.xml 里面的 fs.defaultFS 的 HDFS 的 IP 地址或者域名、埠必須一致, -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://masters/hbase</value>
</property>
<!-- 啟用 hbase 分布式模式 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- Zookeeper 集群的地址串列,用逗號分割,默認是 localhost,是給偽分布式用
的,要修改才能在完全分布式的情況下使用, -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>172.25.0.2,172.25.0.3,172.25.0.4</value>
</property>
<!-- 指定資料拷貝 2 份,hdfs 默認是 3 份, -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- 指定 hbase 的 master -->
<property><name>hbase.master</name>
<value>h1</value>
</property>
</configuration>
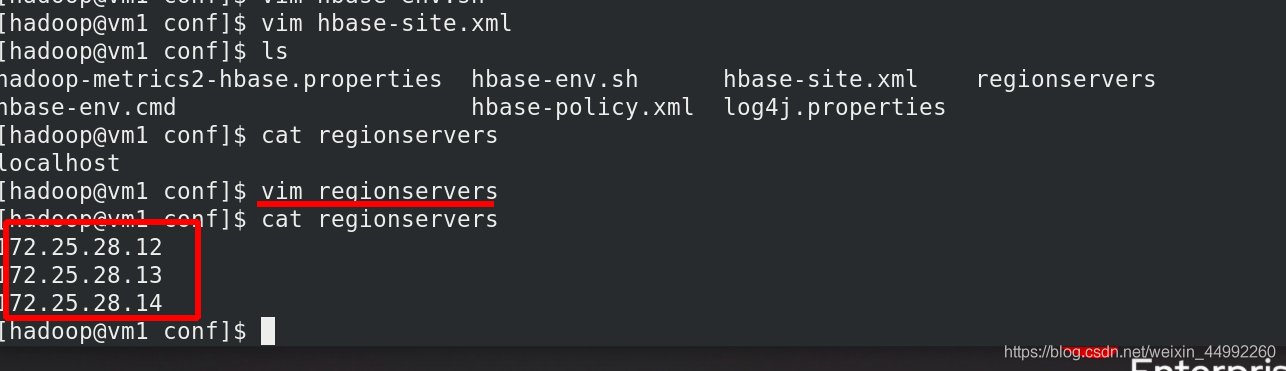
編輯regionservers檔案
輸入集群ip,域名也可以,需要決議
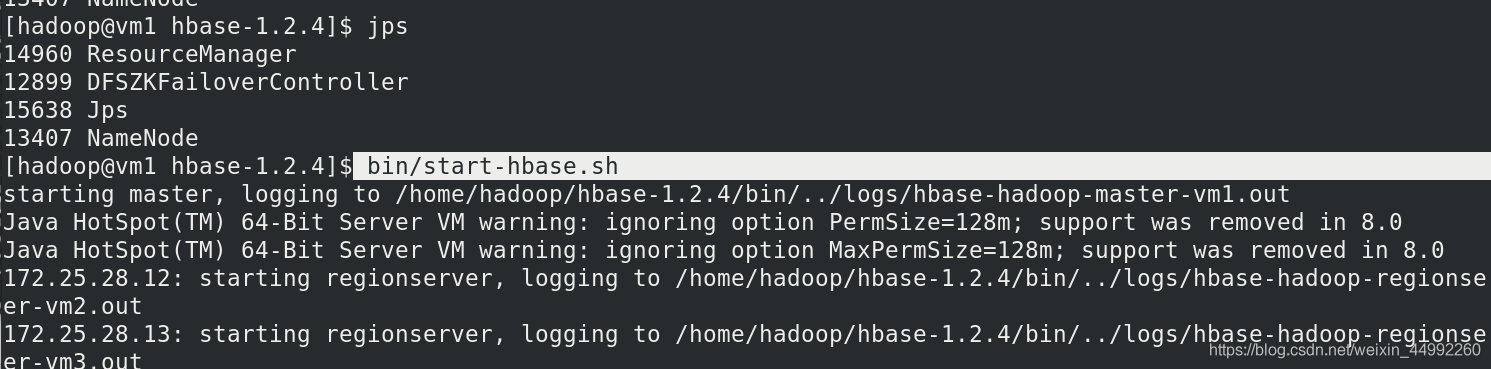
主節點運行:
$ bin/start-hbase.sh
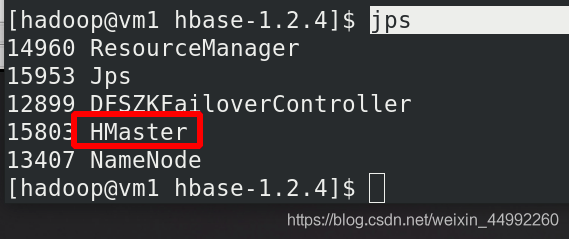
主節點查看
備節點運行:
[hadoop@vm5 hbase]$ bin/hbase-daemon.sh start master
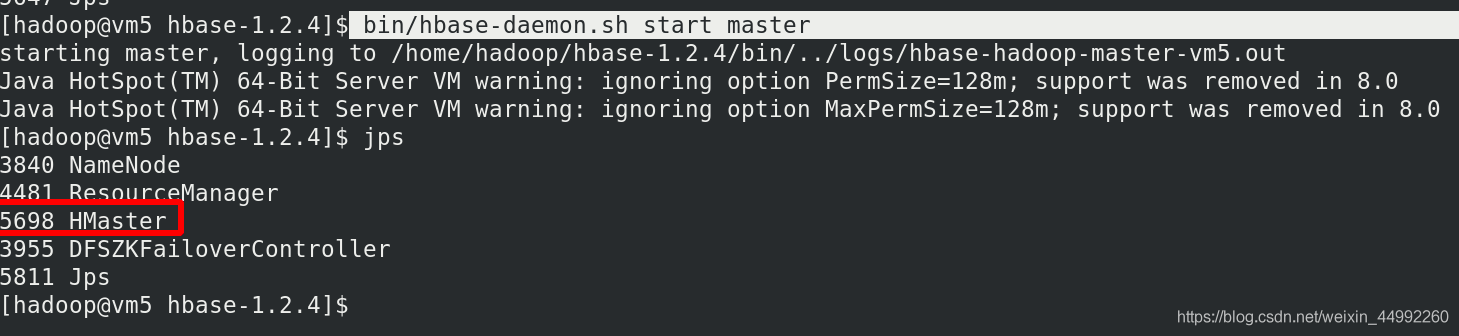
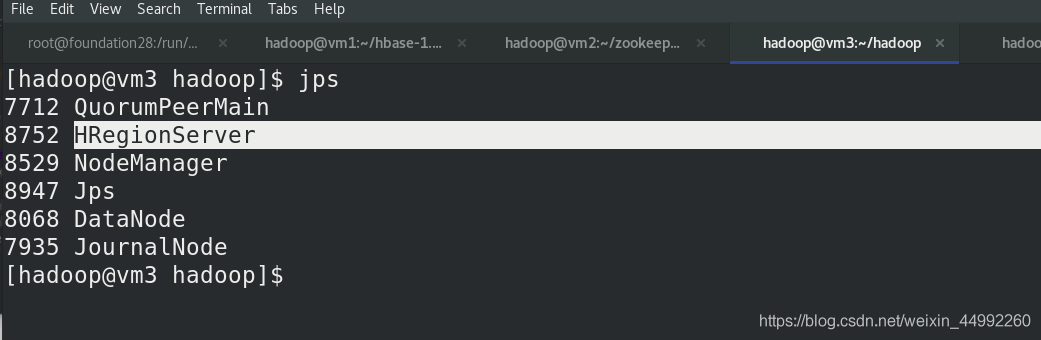
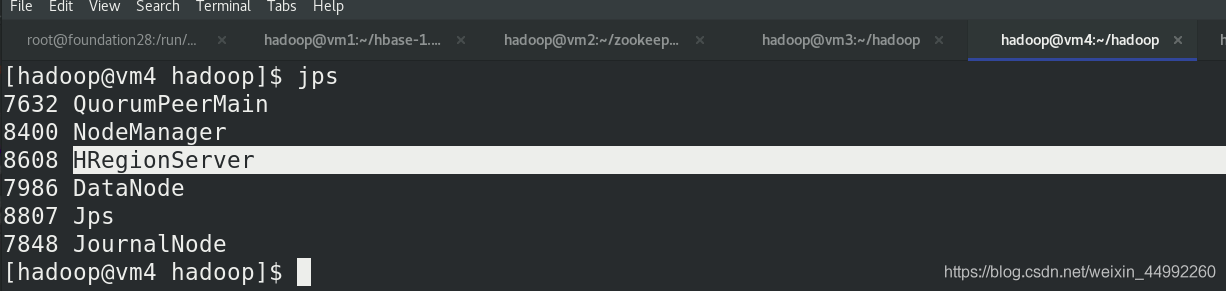
集群節點查看
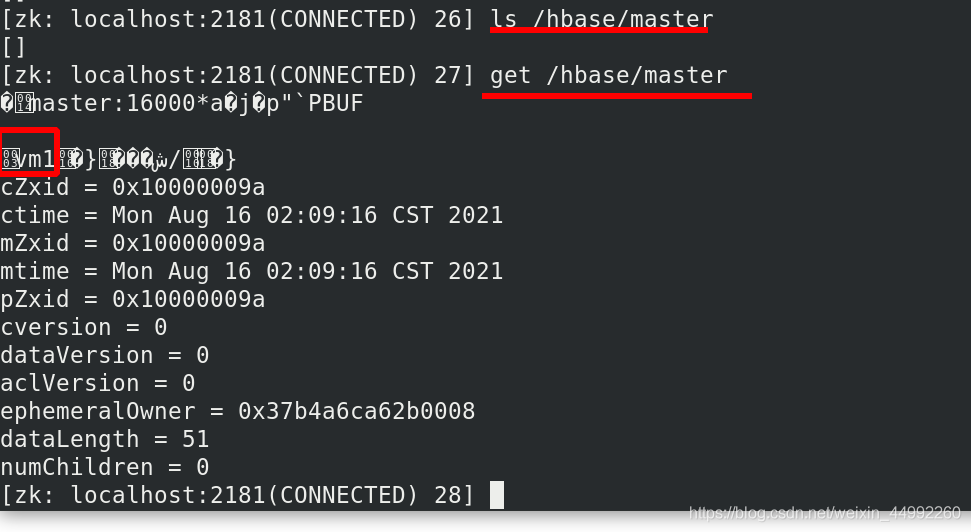
查看主節點為vm1
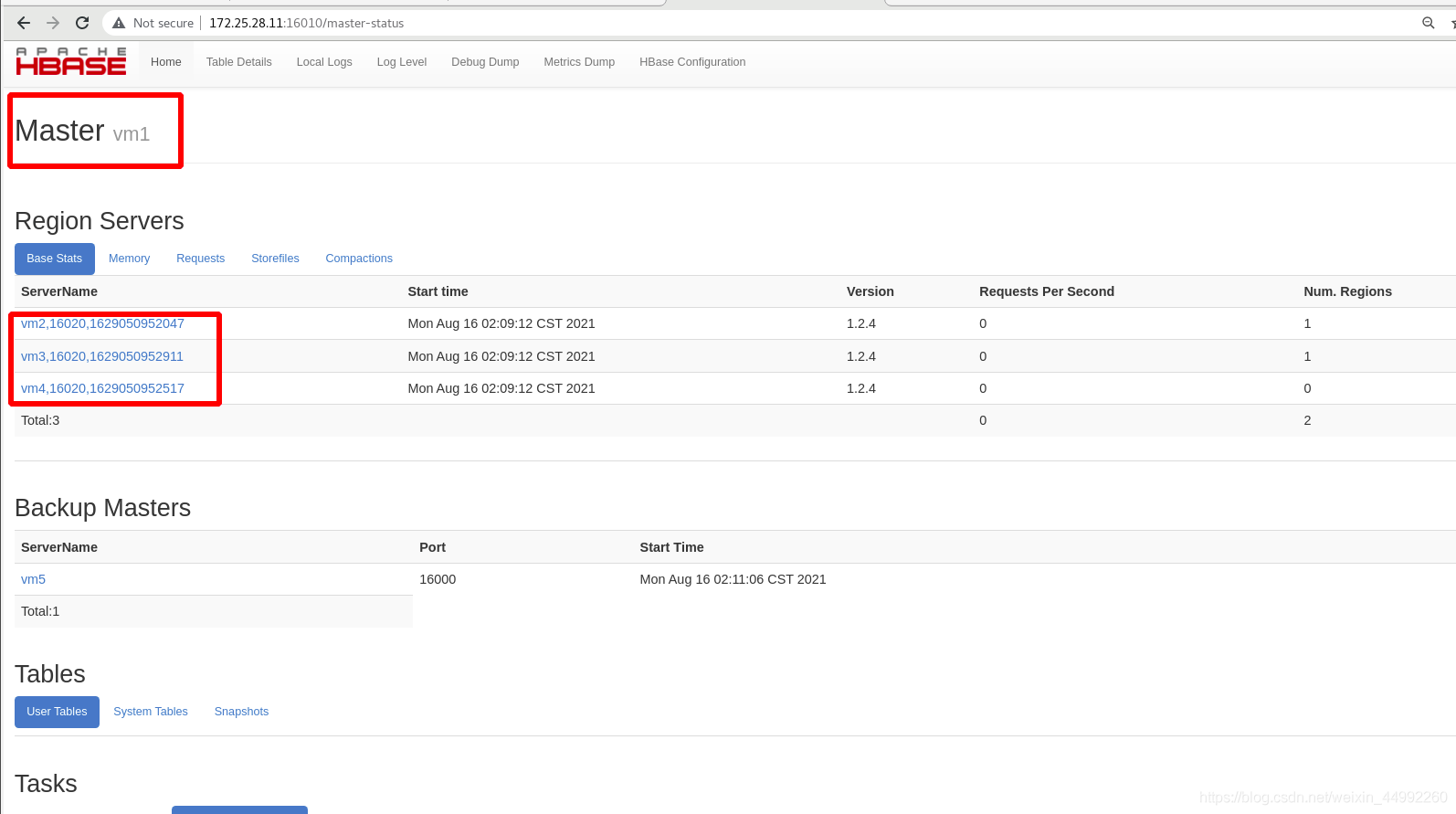
外部查看,主節點為vm1
HBase Master 默認埠時 16000,還有個 web 界面默認在 Master 的 16010 埠上,HBase RegionServers 會默認系結 16020 埠,在埠 16030 上有一個展示資訊的界面,
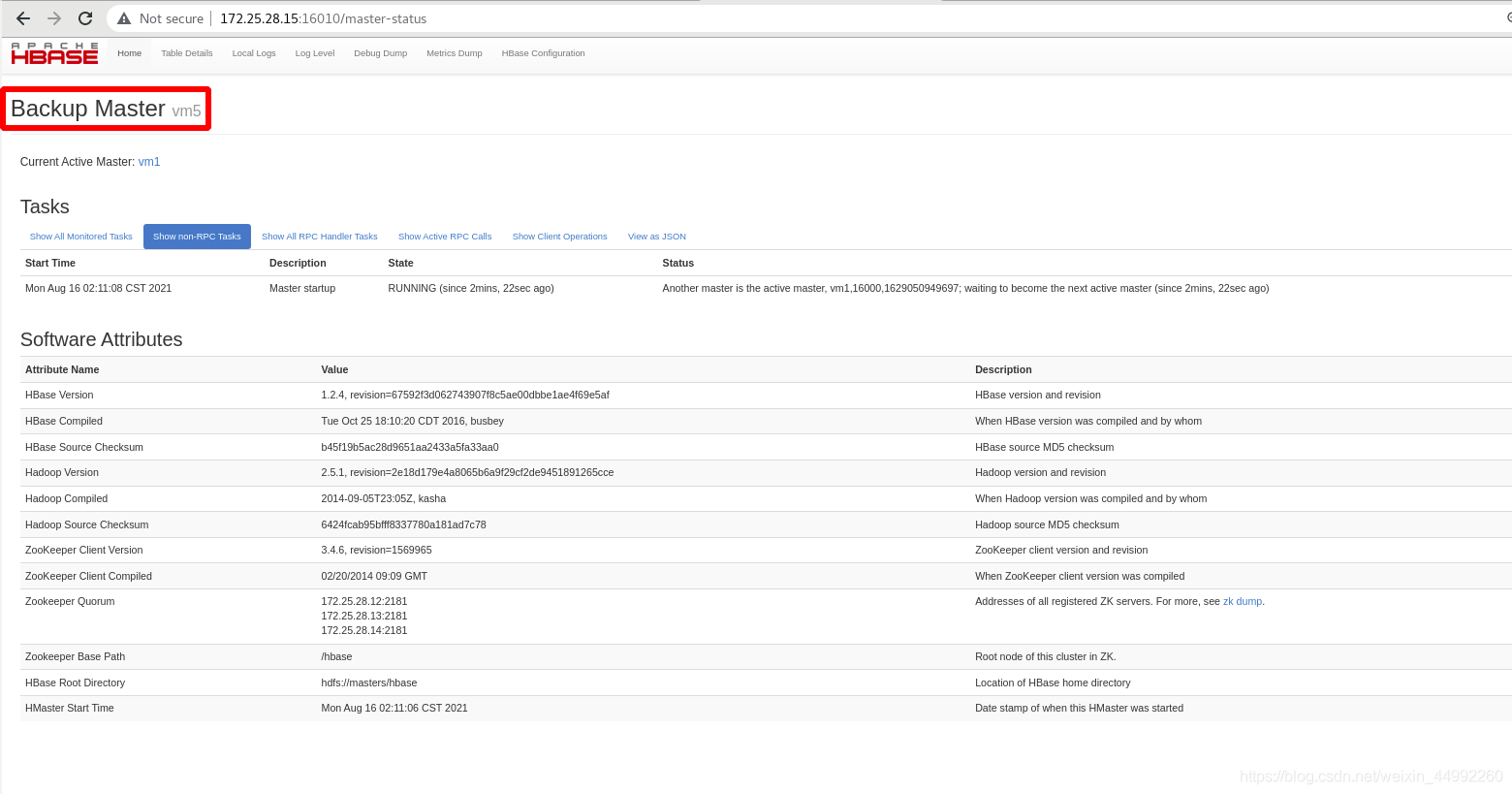
外部查看,備節點為vm5
日志查看
測驗:
重新打開一個shell

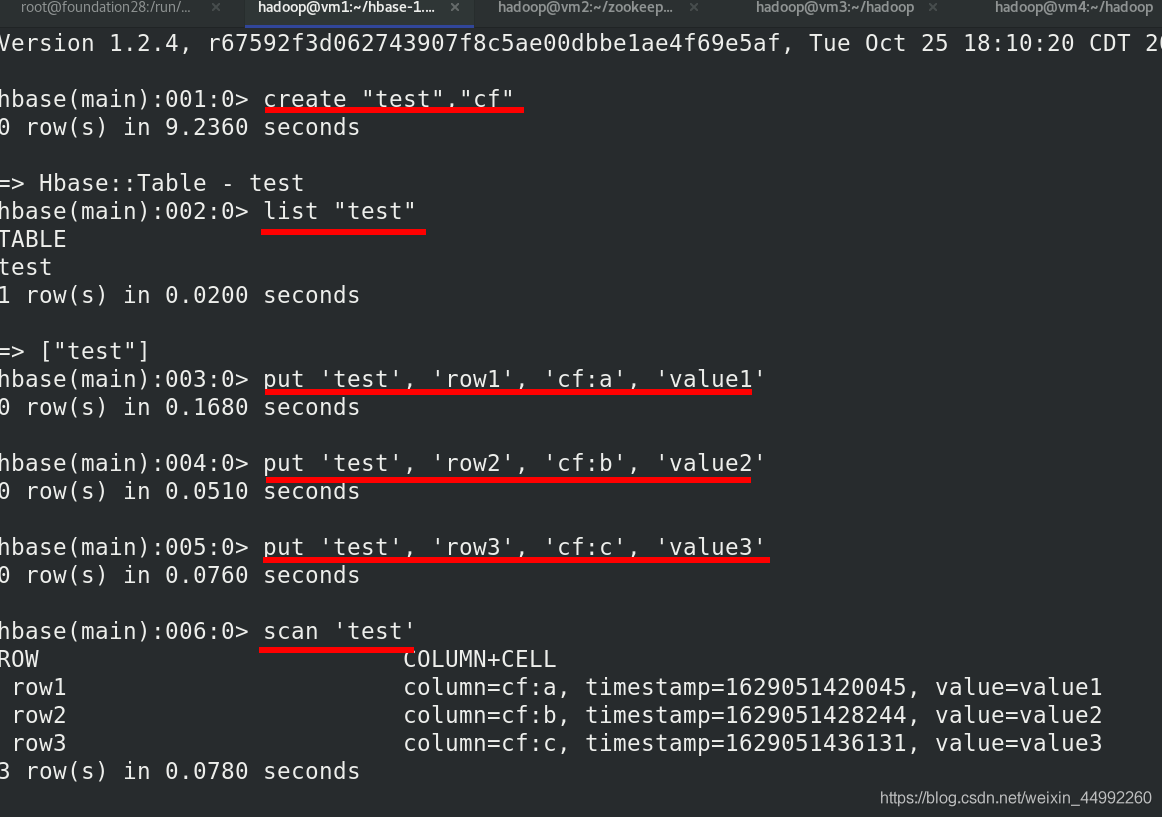
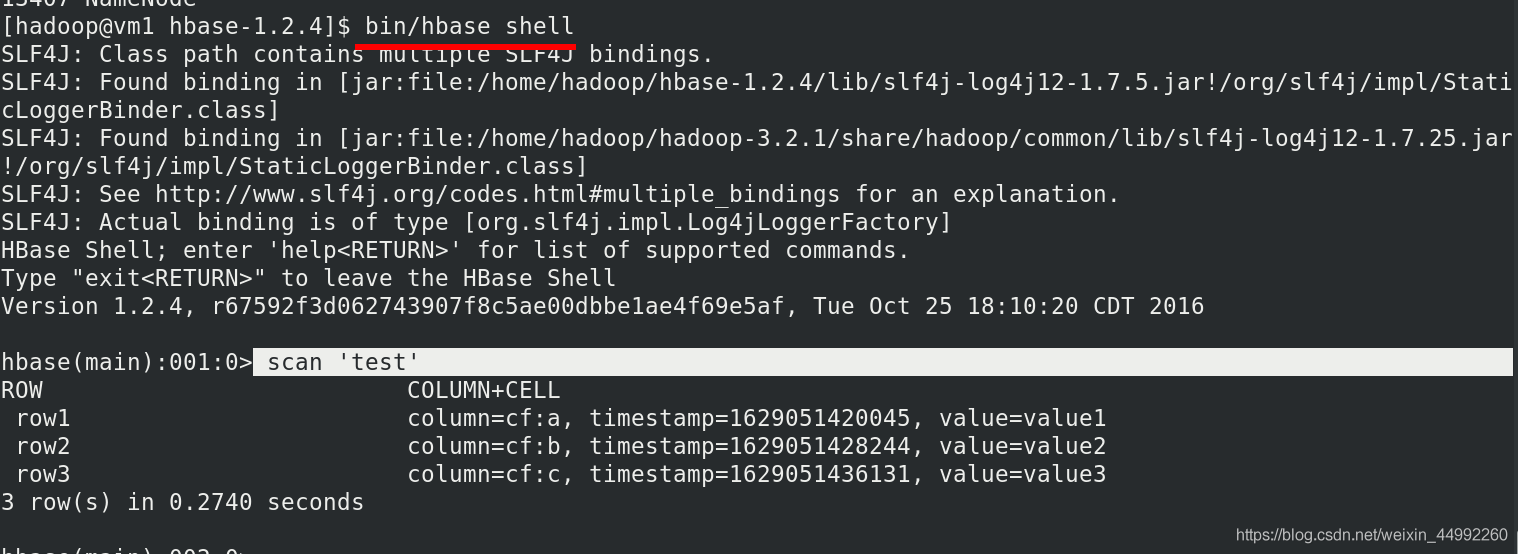
制造資料
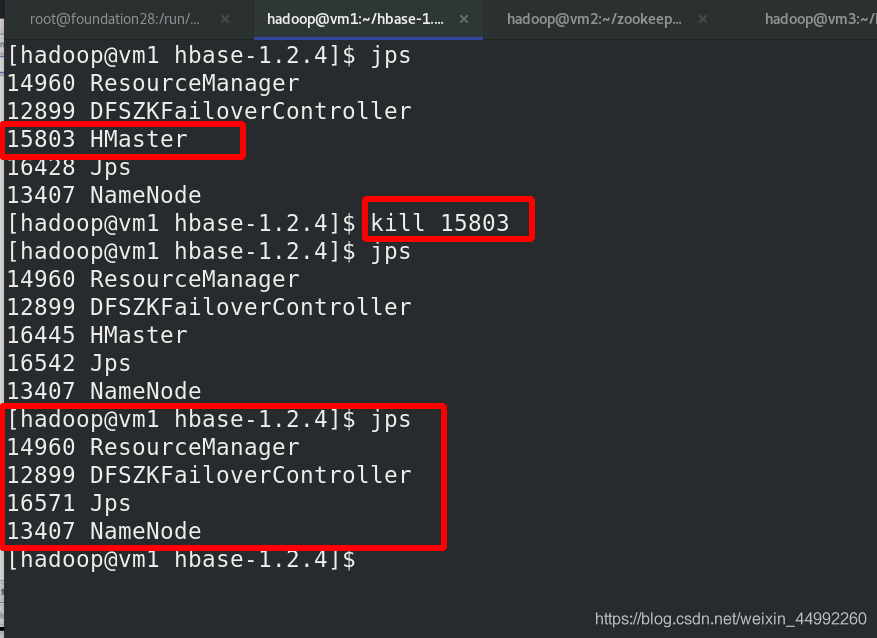
殺死vm1的HMaster行程
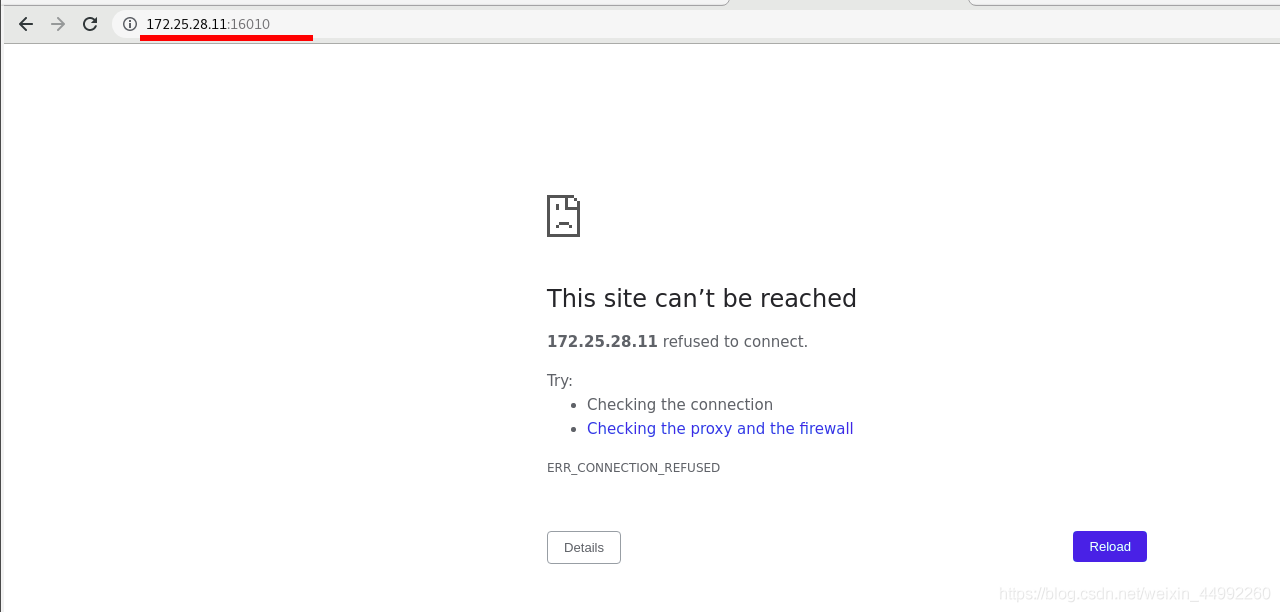
外部訪問vm1失敗
外部訪問vm5,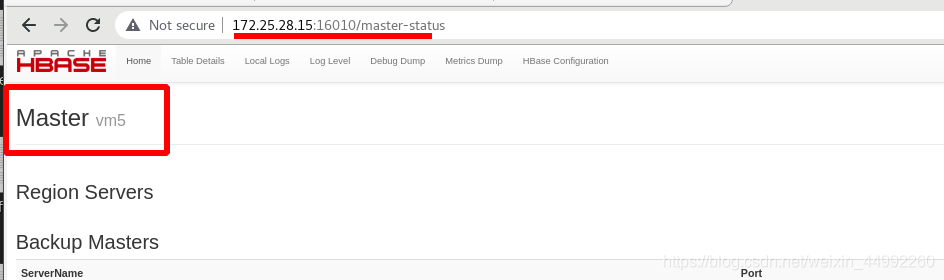

重新啟動vm1的HMaster行程
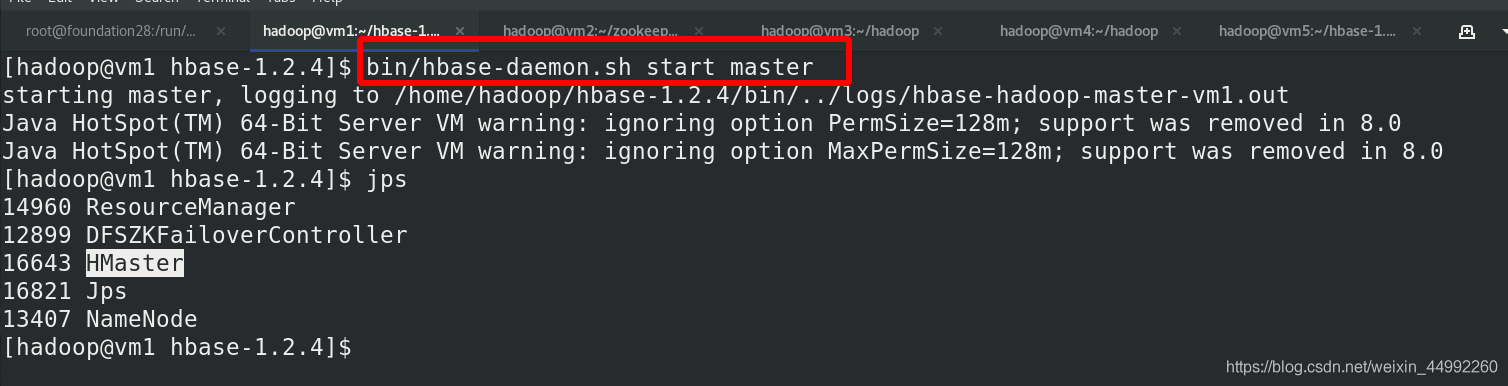
外部訪問:
vm1為備
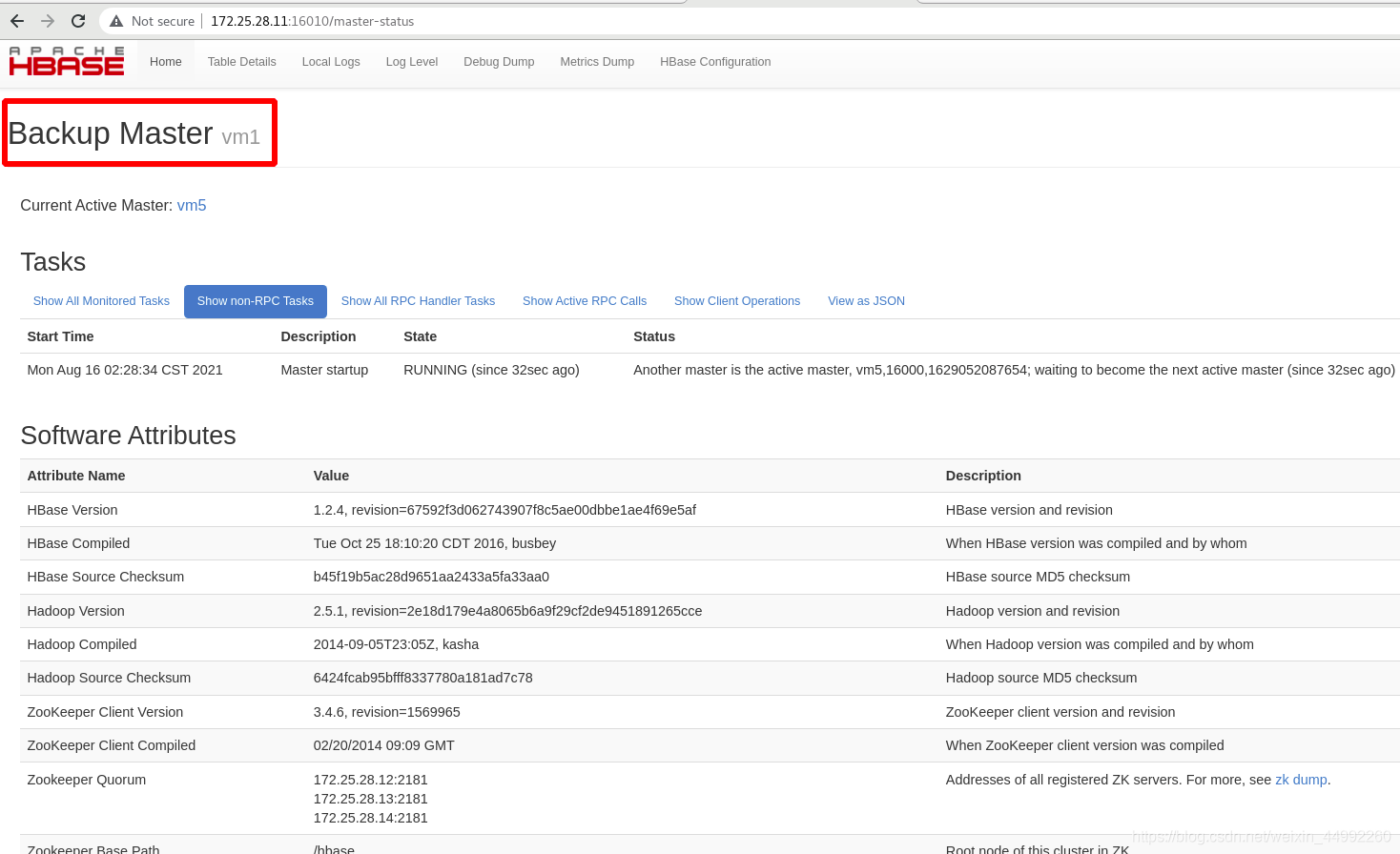
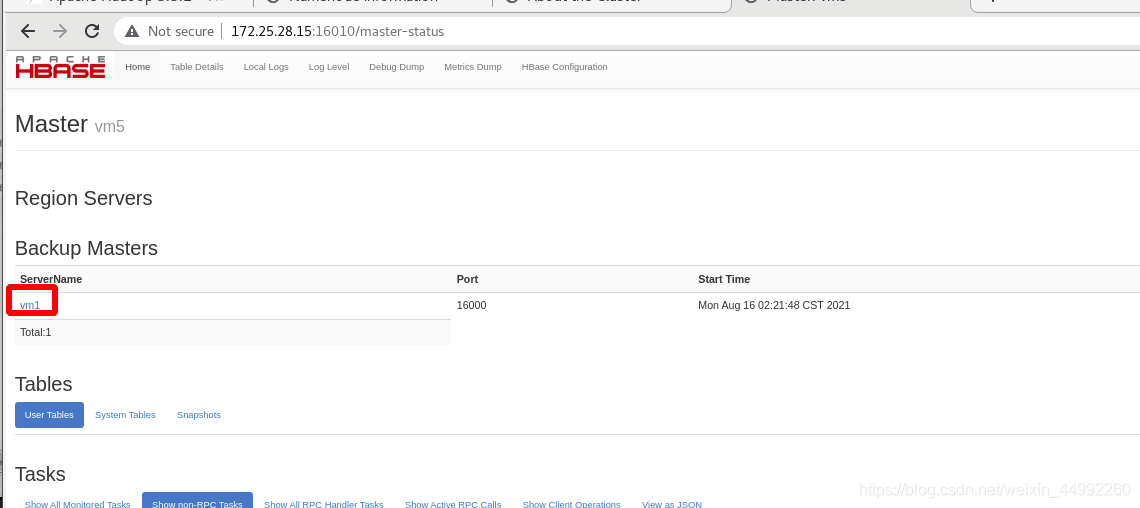
vm5依舊為主!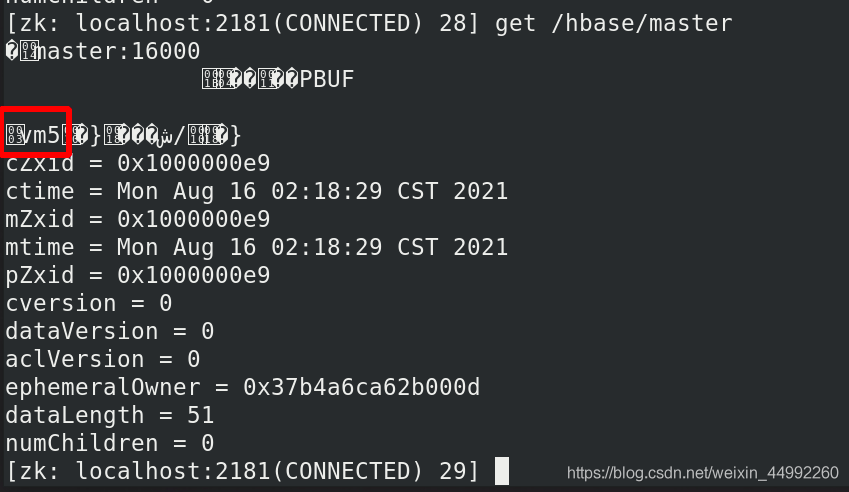
重新打開shell,資料依舊存在!!!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/294427.html
標籤:其他
上一篇:部署ELK+Kafka+Filebeat日志收集分析系統
下一篇:??HBASE的JAVA API操作?? HBASE的過濾器查詢??用到Hbase的時候可以通過本文快速的查看API用途《??記得收藏??》