一、機器學習介紹
1. 機器學習的由來
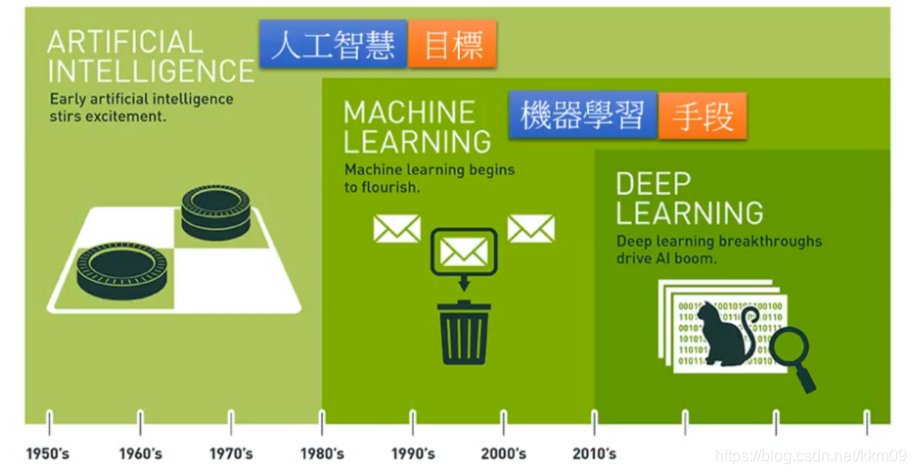
- 人工智能—— 目標
最初在1950年代出現了 “Artificial Intelligence” 這個詞,人們希望機器可以跟人一樣聰明,然而在很長一段時間人們并不知道怎么做, - 機器學習—— 手段
到1980年代后,有了機器學習的方法,顧名思義,其意義為“讓機器具有學習的能力”,即通過機器學習的手段,讓它可以和人一樣聰明, - 深度學習
深度學習是機器學習的其中一個方法,
生物的行為取決于兩件事:先天本能 + 后天學習的結果,在有機器學習之前,人們通過設定好機器的本能來達到預期目的,
生物的本能:
- 河貍筑水壩的能力是天生的:while(聽到流水聲) {筑水壩;}
提前手動設定好的天生本能:
- 聊天機器人:提前設定功能,當看到 “turn off” 就關掉音樂,但是缺點是很僵化,無法考慮到所有規則,
例如:“Please don’t turn off the music.”,本來表達“不要關掉”,機器卻識別成“關掉”——在不同的語境中含有同樣的詞匯,表達了不同的意義,但做出了相同的指令!
2. 什么是機器學習?
考慮一個機器人,現在我們讓它自己具有學習的能力,
語音
像教育小孩一樣,我們給它一段內容為 “Hi” 的音頻A,告訴它這個聲音就是“Hi”,類似地,告訴它音頻B(“How are you”)這段聲音就是 “How are you”,音頻C(“Good bye”)這段聲音就是 “Good bye”,然后它就學會了,希望它得到給出的聲音然后產生對應的結果,
影像
給一些動物的圖片,再給出相應的動物名稱,讓機器人進行學習,經過大量重復的訓練后,我們給出一個動物圖片,機器人就會判斷出是什么動物,
通過以上的比喻,抽象出來得到:機器學習就是在尋找一個function,即,要讓機器具有一個能力: 根據你提供給它的資料,它來尋找出我們要尋找的映射關系——function,
- 在語音識別中,
f(語音) = 對應的文字 - 在影像識別中,
f(影像) = 影像中的事物 - 聊天機器人,
f(使用者的語音) = 機器的回應
3. 如何找出這個映射function?
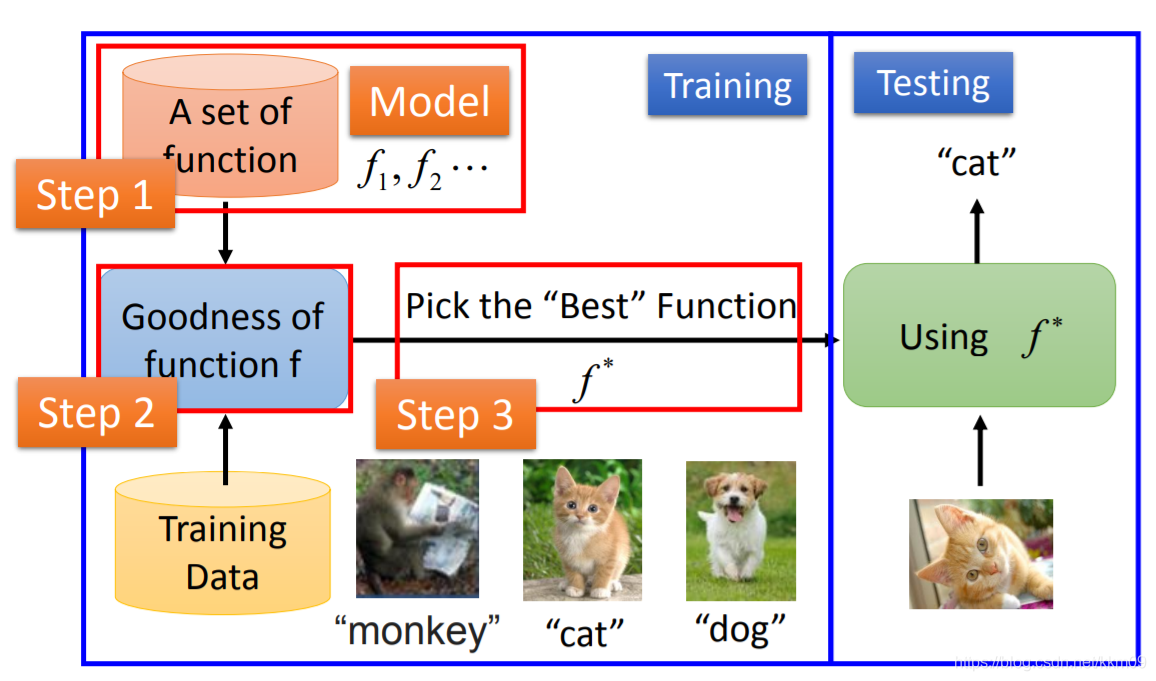
-
Model【學生】:先準備一個function的集合,即模型,如圖所示:

里面有成千上萬個function,分別有不同的輸入和輸出, -
Training Data【教科書】:用于訓練的資料集,包含標注好的輸入 + 輸出

利用訓練資料集,才能判斷出model中的function的好壞,如同老師給學生的作業打分,正確加分,錯誤扣分,(這種給出標注的方法叫做 監督學習) -
從有效率的function中,找出最好的function,記作
f* -
使用
f*,輸入一張未在訓練集中的貓的圖片,測驗它的輸出是否為“貓”
機器學習中一個非常重要的問題:機器是否有舉一反三的能力!
綜上所述,機器學習的步驟概括為如下:
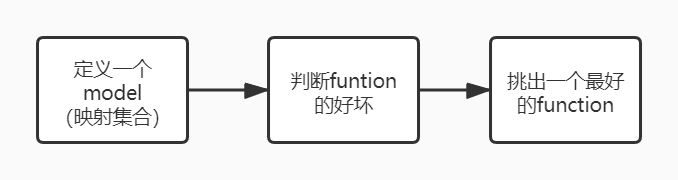
即:模型,策略,演算法,
二、機器學習的相關技術

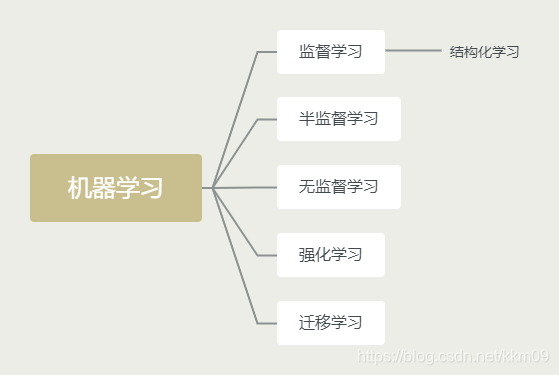
- 監督學習:所用訓練資料都是被標記過的
- 回歸:可用于做天氣PM2.5的預測
- 分類:垃圾郵件篩選(二分類問題)、檔案歸類
- 半監督學習:
- 減少訓練資料集標記作業量
- 訓練資料中部分標記的,部分無標記
- 無監督學習:
- 訓練集中的所有資料都沒有標記
- 根據類別未知的訓練樣本來解決問題
- 強化學習:
- 強化學習是智能體(Agent)以“試錯”的方式進行學習,通過與環境進行互動獲得的獎賞指導行為,目標是使智能體獲得最大的獎賞
- 我們沒有告訴機器正確的答案是什么,機器最終得到的只有?個分數,就是它做的好還是不好,但他不知道??到底哪?做的不好,他也沒有正確的答案,
- 遷移學習:
- 把已訓練好的模型(預訓練模型)引數遷移到新的模型來幫助新模型訓練
- 結構化學習:
- 我們要機器輸出的是,?個有結構性的東西
- 在分類的問題中,機器輸出的只是?個選項;在structured類的problem??,機器要輸出的是?個復雜的物件
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/294620.html
標籤:AI