前言
本文主要記錄關于李宏毅機器學習2021中HW3和HW4的卷積神經網路和自注意力機制網路部分的筆記,主要介紹了CNN在影像領域的作用及如何處理影像資料,Self-Attention在NLP(自然語言處理)領域的作用和處理詞之間的關系,
一、CNN卷積神經網路
- CNN處理影像的大致步驟
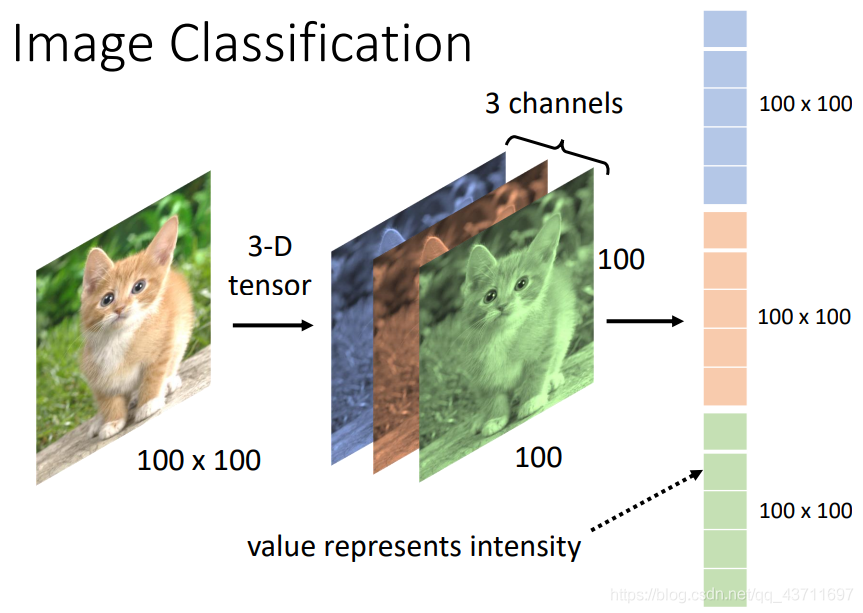
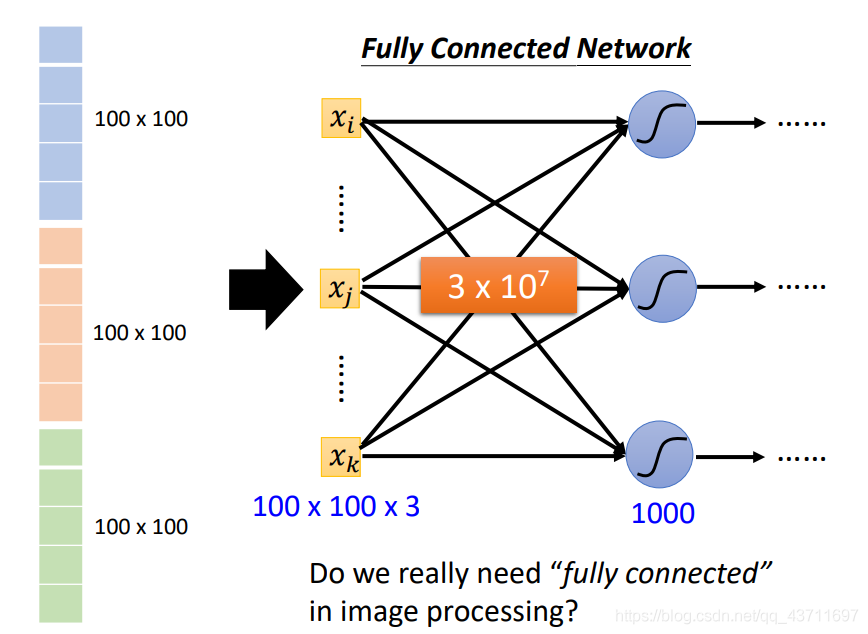
前面介紹的FCN全連接神經網路是通過把一維的向量不斷通過中間的隱藏層的multi和bias最后輸出指定列數的vector,而影像這個多維向量是經過一個卷積神經網路最后再經過flatten展開成一維再通過FCN輸出對應類別數的一個vector,而中間的CNN處理部分由Kernel——pooling——activation組成,當然CNN的提出是為了解決FCN解決不了多維向量大資料量輸入的問題,FCN同樣也可以解決影像但是前提是把這個多維的影像資料flatten展開后再輸入,可想而知其資料量之大,如下圖可表示為CNN大致的處理程序
如下圖展現了使用FCN進行影像處理的資料量大的問題
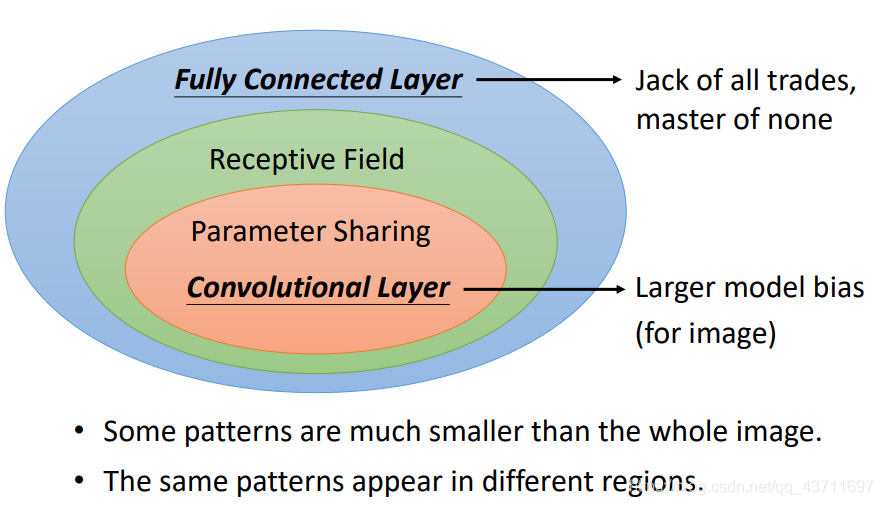
- CNN的特別表現之處
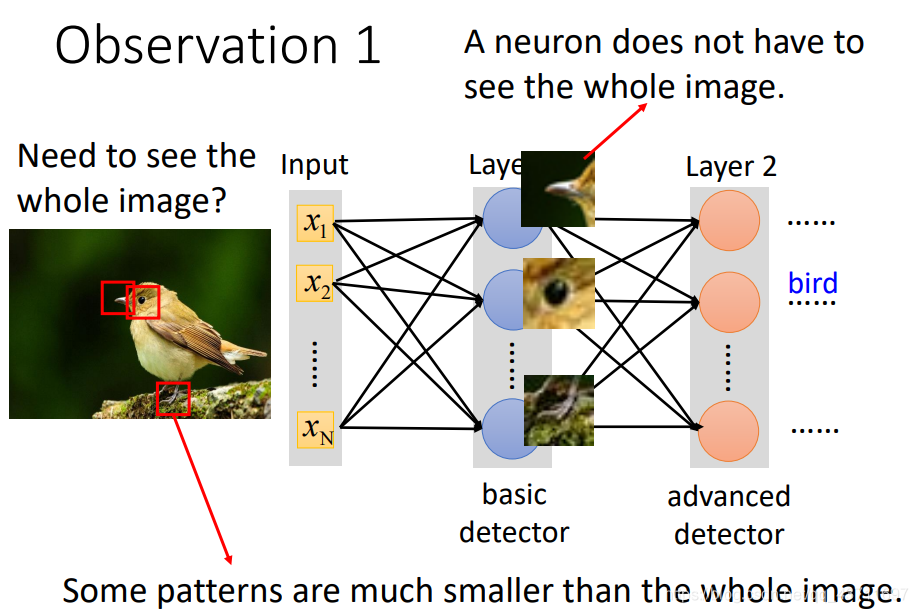
Observation 1:第一個特別表現之處在于其處理資料的區域性,可以明顯和FCN作比較,FCN對于輸入的資料是把每個資料之間都進行了關聯型處理,這樣做的結果不僅資料量大計算量大而且冗余量大,因此CNN中使用filter這樣一個卷積核實作區域相關性,不需要隱藏層中每一個神經節點都去負責全部的部分,只需要負責其中一小塊部分就可以了,最后的時候,每個神經節點負責的部分再綜合考慮起來就可以做到效益最大化,如圖所示:
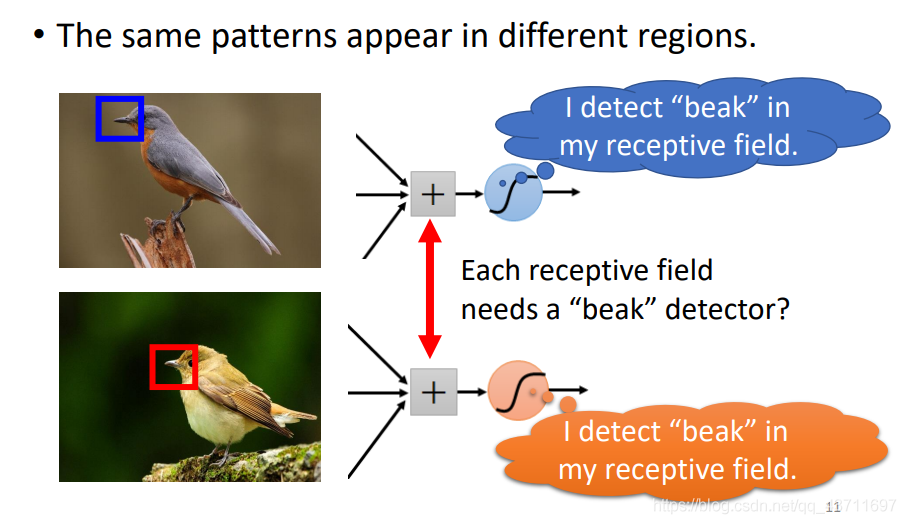
Observation 2:第二個特別表現的地方在于它的位置無關性,比如檢測鳥嘴,但是鳥嘴在圖片中的位置并不是統一的,這時候不需要去訓練多個CNN網路去檢測這個位置的鳥嘴還是那個位置的鳥嘴,CNN中只要鳥嘴存在圖片中,不論哪個位置,可能當前神經元檢測不出來,但是另外一個神經元就可以馬上檢測出來,這也和CNN的權值共享有關,雖然位置不同但是內容一樣表示的含義一樣,經過相同的權值就得到類似的結果檢測出鳥嘴,
Observation 3:第三個特別表現的地方就是它特有的pooling池化,池化的主要目的就是減少資料量,多次的池化將要處理的資料不斷減小,當然是把次要的特征砍掉,只保留主要重要的特征,池化有很多種,最大池化,平均池化等等,其實池化也是卷積的一種特殊操作而已,

- CNN卷積神經網路整體的流程
通過上述說到的幾個CNN相比較FCN特別處理之處就可以整理出CNN卷積神經網路處理影像資料的流程圖了,如圖所示影像經過多次的卷積池化卷積池化再Flatten展開成一維向量最后經過FCN輸出類別,
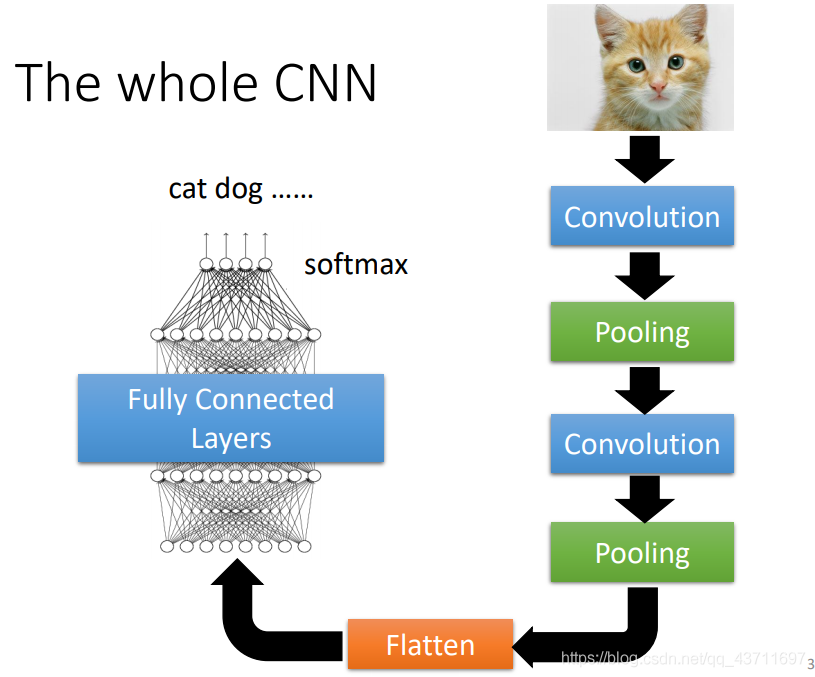
- CNN和FCN的比較
CNN和FCN相比較起來,簡化了許多流程,CNN也可以看成FCN的簡單化,FCN看作是CNN的復雜化,CNN相比較于FCN引入了很多新的方法:卷積核,池化,權值共享,步長等等,CNN可以調整較多的超引數來獲得更好的結果,比如調整卷積核大小,卷積核步長等等,CNN不再需要看整個image而僅僅需要看卷積核覆寫住那個區域的image,并且CNN更好地詮釋了如何將影像特征一層一層的提取出來,當然這里就要說到feature map即特征圖,特征圖就是隱藏層中輸出或提取出來的抽象影像,
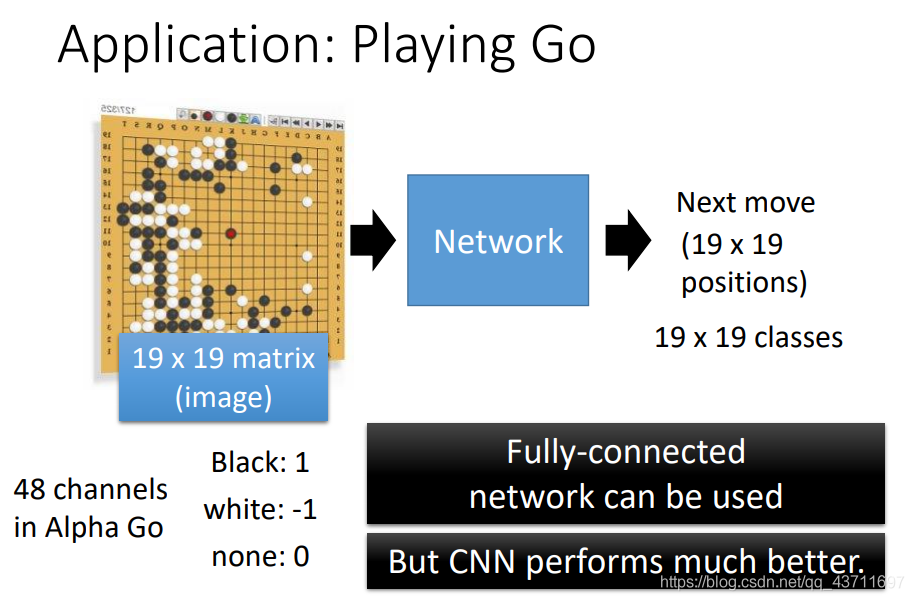
- CNN在圍棋領域的作用
可能看到圍棋沒辦法讓人聯想到影像,但是AlphaGo將圍棋整個19x19棋面作為image,而channel使用48,主要是圍棋面上每個點可能可以走的路數各種可能性作為channel,因此ALphaGO總的來說輸入19x19x48的一個圍棋資料,然后將要接下去要走的棋子作為分類目標,哪個分類目標可能性大就走哪一步,但值得一提的是在AlphaGo中沒有使用到Pooling操作,更多是在做padding,其實可想而知,在圍棋這個場景下需要更精細的目標因此不適合將資料量縮小,
二、Self-Attention自注意力機制
- 語音或詞向量表示
語音和詞語不同于影像等資料有直接的數字意義,通常也需要將語音轉換成向量表達,最經典的就是one-hot編碼,這樣的編碼方式固然簡單但是會產生大量資料,因此又有了詞嵌入式,相比于獨熱編碼,一個詞表示一個向量,詞嵌入通過分類等形式將詞向量表示的維度降低,

- 自注意力機制基本結構
每個詞代表一個向量那么對應的輸出的label可以有多種,比如一個詞對應一個label,一堆詞組成一起對應一個label等等,那么這些詞之間是互相關聯的如果僅僅用FCN完全做不到進行詞之間的互關,比如一個詞可能有多個意思,但是在FCN中相同詞相同向量必定是相同輸出,但是在真實情況下并不是我們所希望的這樣,因此需要引入詞相關的概念,即在輸入向量進入網路處理的時候需要參考背景關系context
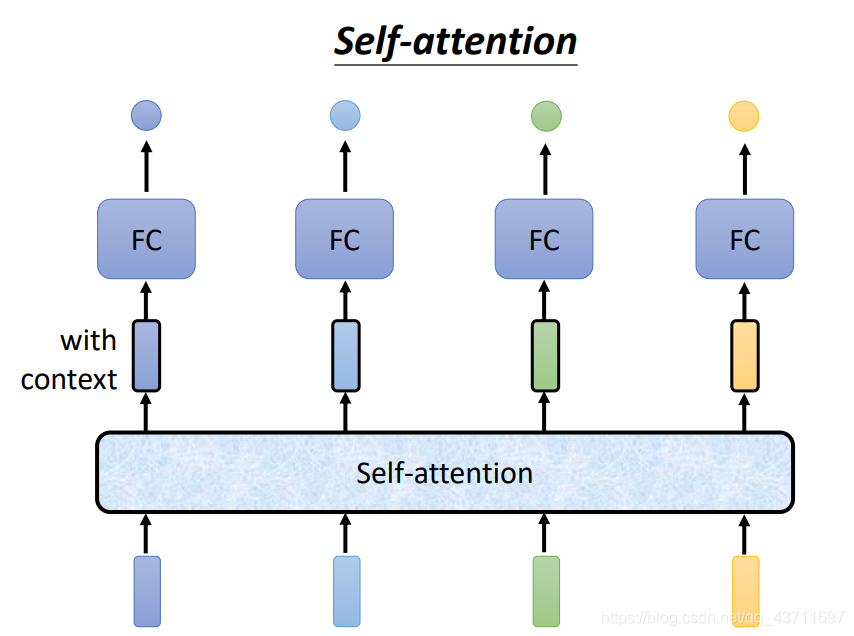
- 自注意力機制具體計算
自注意力機制的具體計算形式主要是通過q,k,v三個引數,來生成attention score,生成的score是經過和其他的詞向量進行關聯相乘相加,值得注意的是自注意力機制的輸入是一整個句子,而不是單個詞向量輸入,即自注意力機制處理的時候可以很好地把背景關系進行關聯,
對于不同的場景可能還會遇到一個詞向量擁有多個head即一個詞向量擁有多個引數

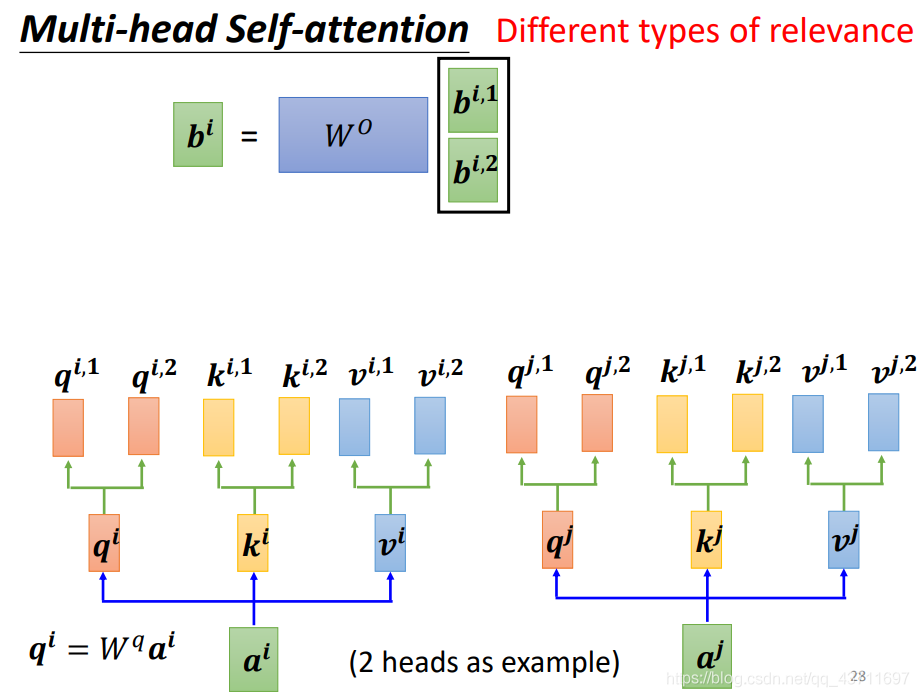
- 自注意力機制機制和卷積神經網路比較
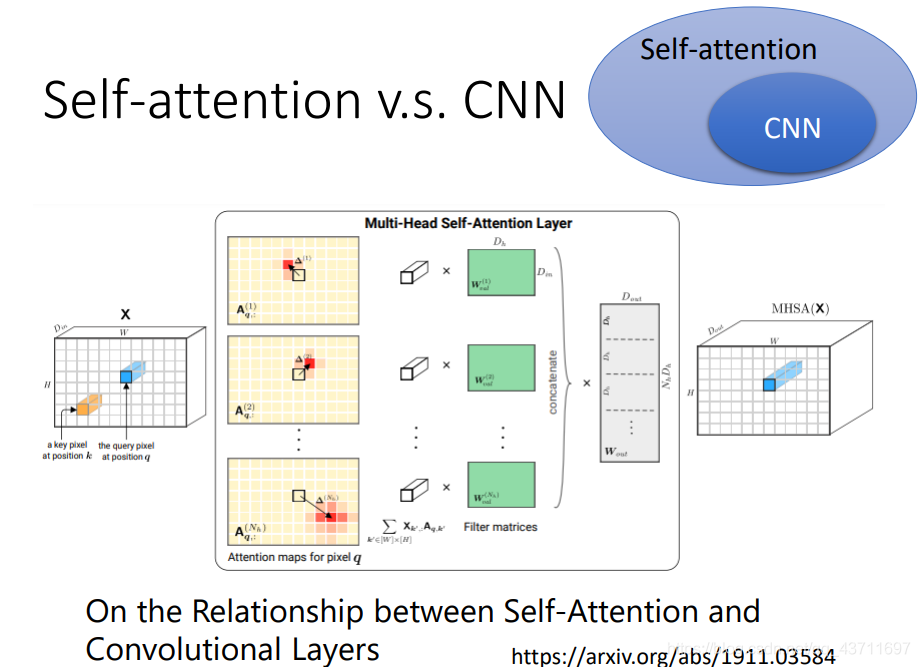
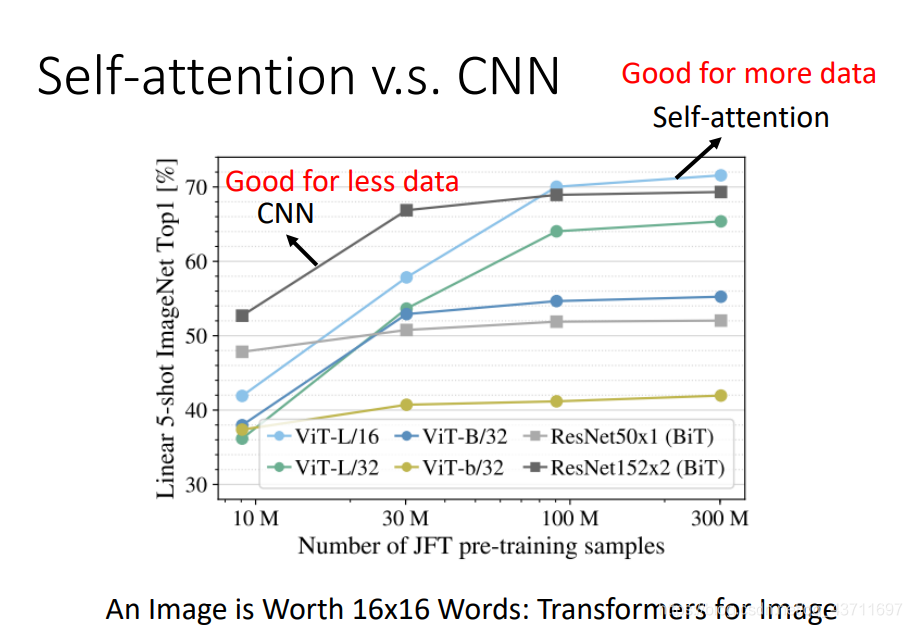
自注意力機制和CNN相比較其實兩者很相似,自注意力機制不一定要用在語音領域也可以用在影像領域,其經過特殊的調參發揮的作用和CNN是一模一樣的,簡單來說,CNN是簡化的self-attention,對于一幅影像而言,CNN只需要區域關聯處理就行,而自注意力機制需要全部輸入然后互關,
- 自注意力機制和RNN的比較
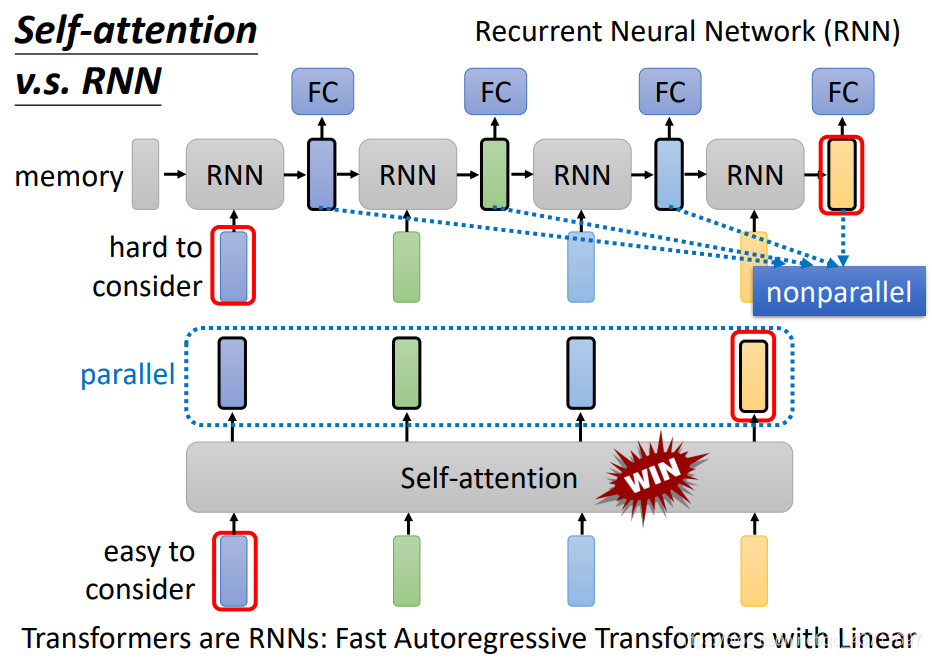
自注意力機制和回圈神經網路共同的特點都是主要用于NLP自然語言處理,并且他們對于詞背景關系都進行了處理,主要不同之處在于RNN對于詞輸入僅局限于前文,對于后文照顧較少,而自注意力機制直接將背景關系都關聯照顧到,而且自注意力機制的處理是并行處理,詞向量同時進入同時輸出,因此整體來說自注意力機制更具有優勢,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/294619.html
標籤:AI
上一篇:動手學深度學習之卷積和卷積層